- The paper proposes a learned, discrete skinning representation via FSQ-CVAE to reframe complex rigging as a tractable sequence prediction problem.
- The paper integrates transformer-based autoregressive modeling with reinforcement learning to jointly optimize skeleton generation and skinning fidelity.
- The paper demonstrates significant improvements, achieving up to 133% enhanced skinning accuracy and notable gains in skeleton prediction over prior methods.
Skin Tokens: A Learned Compact Representation for Unified Autoregressive Rigging
Introduction and Motivation
Rigging remains a bottleneck in 3D asset pipelines despite rapid advances in generative 3D modeling. Manual skeleton creation and skinning weight assignment are labor-intensive, with most automatic approaches either restricted by template fit (limited generalizability) or decoupled from other rigging stages, resulting in suboptimal downstream performance. The core insight of "Skin Tokens: A Learned Compact Representation for Unified Autoregressive Rigging" (2602.04805) is that the ill-posedness of high-dimensional skinning regression is fundamentally a representation problem. The authors introduce a learned, discrete, and compressed format for skinning—enabling the unification of skeleton and skinning prediction in a single, sequence-based generative framework (TokenRig), further refined with task-specific reinforcement learning.
Compact Learned Skinning Representation
The work reframes skinning from a dense, high-dimensional regression challenge to a tractable discrete sequence prediction problem. Skinning weights are extremely sparse (only $2$–10% active entries), and direct regression with standard MSE or BCE losses struggles with the resulting class imbalance and overfitting to trivial solutions. To address this, the authors propose to learn a discrete skinning representation using a Finite Scalar Quantized Conditional Variational Autoencoder (FSQ-CVAE), capturing the intrinsic sparsity and semantic structure of per-bone skinning weights.
In the FSQ-CVAE, latent representations of skinning (conditioned on mesh geometry) are quantized with FSQ, bypassing learnable codebooks and providing efficient, gradient-friendly discretization. Key to reconstruction fidelity is the application of a composite loss with Dice, BCE, and MSE terms; Dice loss is shown to provide significantly improved gradients for positive entries (active skinning weights), allowing the model to counteract sparseness-induced vanishing gradients.
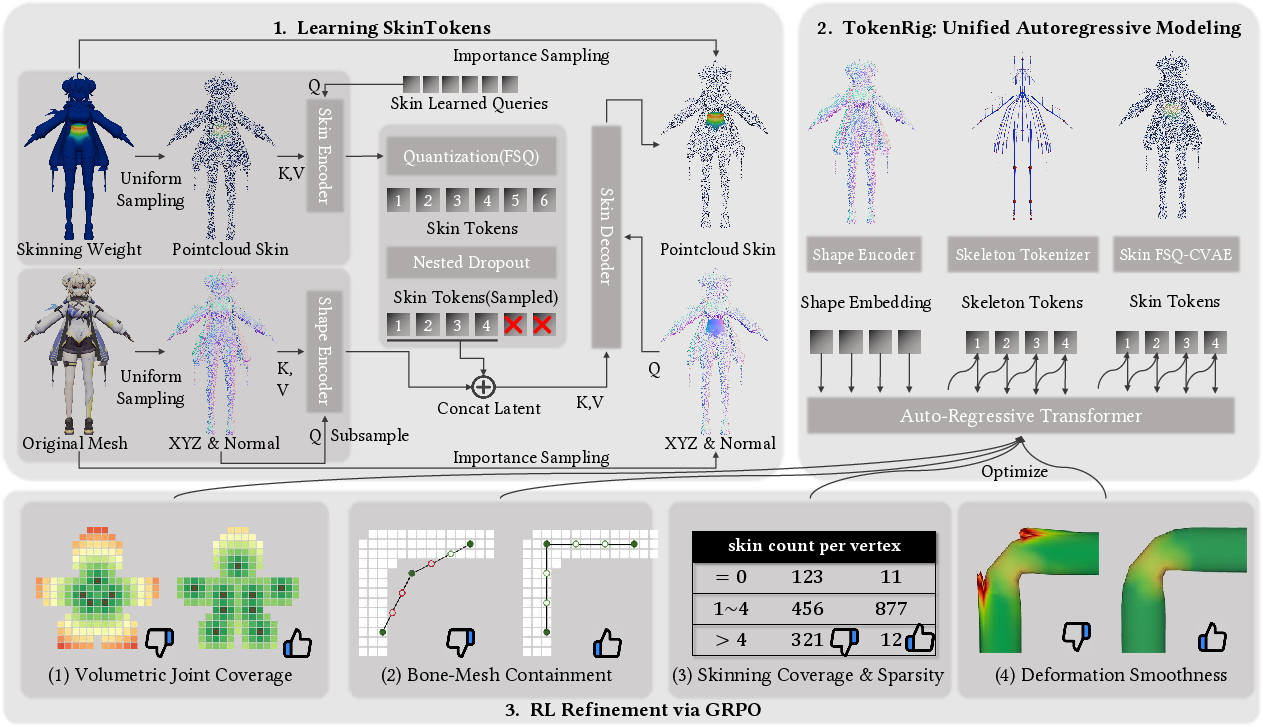
Figure 1: Overview of the TokenRig framework, showing the sequential process: (1) learn discrete representation for sparse skinning via FSQ-CVAE, (2) unified autoregressive rig generation, and (3) reinforcement learning–guided refinement.
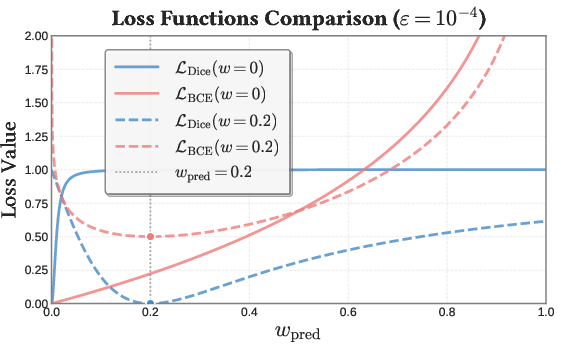
Figure 2: Comparison of BCE and Dice loss landscapes, demonstrating Dice loss's effectiveness at amplifying gradients for nonzero skinning weights.
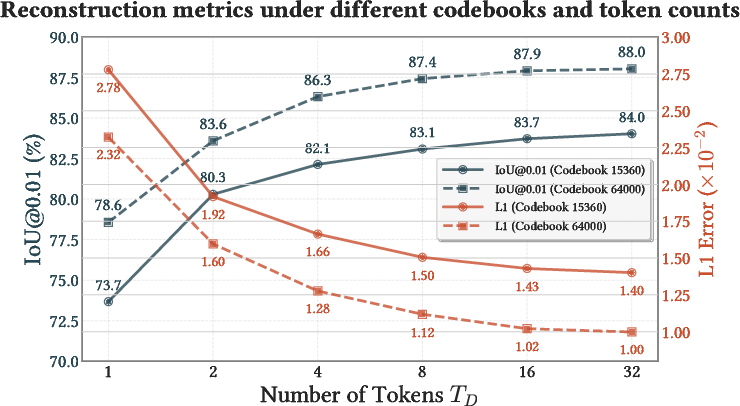
Figure 3: Skin token (FSQ-CVAE) can reconstruct skinning weights with high IoU using as few as 4 tokens, validating the representational compressibility.
FSQ codebook size analysis reveals that skinning information can be compressed by a factor of 180× or more, with negligible loss in reconstruction quality. t-SNE visualizations further demonstrate that the learned latent space clusters correspondence to semantic body parts across mesh variation, indicating robust prior learning.
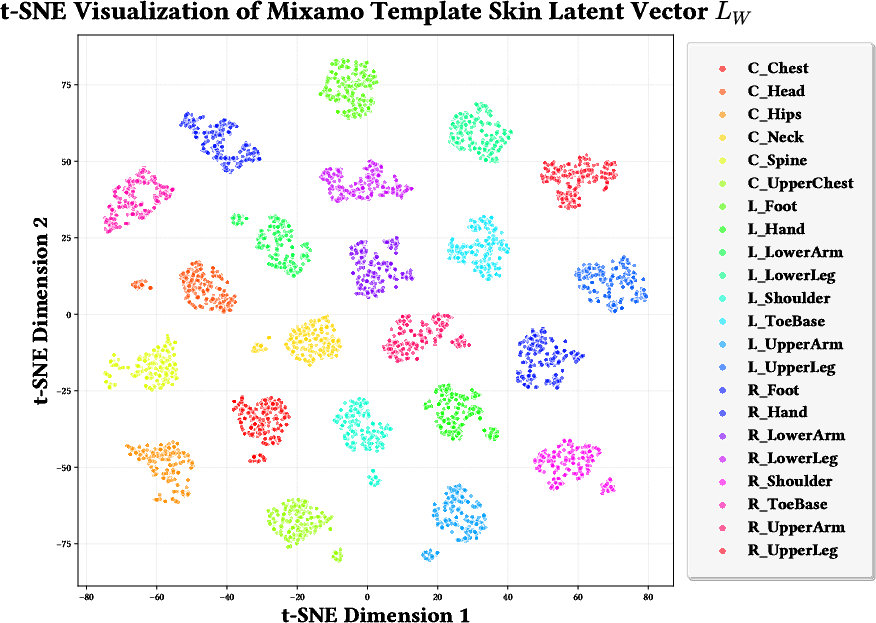
Figure 4: t-SNE plot of continuous skinning latents, with clear semantic clustering by anatomical part, prior to quantization.
Unified Autoregressive Rigging with TokenRig
With the discrete skinning (token) representation, the authors construct TokenRig—a transformer-based, autoregressive framework that jointly models the entire rig as a sequence. Skeletal parameters and their associated skin tokens are generated in sequence, allowing the transformer’s global attention to leverage dependencies between morphology and skin deformation. This structure enables improved modeling of complex geometric and semantic relationships, which is not possible when skeleton and skinning are predicted independently.
Reinforcement Learning Refinement for Generalization
TokenRig is further refined using Group Relative Policy Optimization (GRPO), allowing the model to optimize directly against geometric and functional criteria without relying on large preference datasets. A suite of non-differentiable, domain-specific rewards ensures both structural and deformation validity:
- Volumetric joint coverage: Skeleton joints properly span the geometry, preventing omission of extremities.
- Bone-mesh containment: Penalizes bone placement outside the mesh volume.
- Skinning coverage and sparsity: Ensures all vertices are bound to bones, but with limited influences per vertex.
- Deformation smoothness: Assesses mesh artifact level after Linear Blend Skinning (LBS) deformations under random poses.
This reward-driven RL stabilization leads to improved generalization, particularly for out-of-distribution assets where supervised training alone results in frequent failures.
Experimental Results
TokenRig is evaluated against strong learning-based baselines (RigNet, MagicArticulate, UniRig, Puppeteer) using multiple datasets (Articulation2.0, ModelsResource, VRoid Hub). The framework obtains 98%–133% improvement in skinning accuracy over the best previous methods, with a 17%–22% boost in skeleton prediction when incorporating the RL refinement.
- Skeletal integrity: TokenRig generates more coherent and topologically plausible skeletons, exhibiting minimal missing structures, redundant joints, or hallucinated connectivity, outperforming MST and token-based alternatives.

Figure 5: TokenRig synthesizes structurally coherent skeletons and semantically faithful limb connectivity compared to state-of-the-art baselines, which show partial, missing, or redundant structures.
- Skinning fidelity: The use of discrete tokens via FSQ-CVAE delivers clean segmentation of influence regions, reducing "bleeding" of skinning weights, particularly on challenging topologies (e.g., disconnected geometry, fine structures like fingers). Quantitatively, TokenRig achieves the lowest L1 error, highest precision/recall, and lowest deformation artifact metrics.
- Ablations: Removing Dice loss degrades IoU and coverage; data augmentations simulating mesh/skeleton imperfections are crucial for robust generalization; disabling GRPO causes failures on complex "in-the-wild" geometries, omitting secondary bones or misbinding skinning.
Implications and Future Directions
TokenRig reconfigures the rigging pipeline as a token-based generative problem, mirroring recent advances in NLP and multimodal AI. The approach demonstrates the practical utility of learned discrete skinning representations and supports the trend towards holistic, sequence-driven modeling for complex structured tasks in graphics. The RL-based refinement scheme is particularly notable for encoding geometric and semantic correctness without reliance on expensive labeled feedback, facilitating adaptation to real-world topology and user constraints.
Possible future research avenues include:
- Continuous tokenization: Bridging the remaining fidelity gap for extremely fine-grained skinning, leveraging recent developments in continuous latent sequence modeling.
- User-driven or guided rigging: Incorporating direct user or artist input, or adhering to topological conventions, expanding TokenRig from automation towards interactive co-design.
- Physical plausibility: Introducing physics-informed rewards or differentiable simulation in the RL stage, further enhancing deformation realism under diverse animation scenarios.
Conclusion
The paper establishes a powerful, unified generative framework for character rigging by learning a compressed, discrete skinning token representation and coupling it with joint autoregressive modeling. By replacing ill-posed regression with token prediction and integrating reinforcement learning for geometric and functional correctness, TokenRig substantially advances the robustness, fidelity, and scalability of automated 3D character animation preparation, setting a high bar for future approaches in the domain.