Subliminal Effects in Your Data: A General Mechanism via Log-Linearity
Abstract: Training modern LLMs has become a veritable smorgasbord of algorithms and datasets designed to elicit particular behaviors, making it critical to develop techniques to understand the effects of datasets on the model's properties. This is exacerbated by recent experiments that show datasets can transmit signals that are not directly observable from individual datapoints, posing a conceptual challenge for dataset-centric understandings of LLM training and suggesting a missing fundamental account of such phenomena. Towards understanding such effects, inspired by recent work on the linear structure of LLMs, we uncover a general mechanism through which hidden subtexts can arise in generic datasets. We introduce Logit-Linear-Selection (LLS), a method that prescribes how to select subsets of a generic preference dataset to elicit a wide range of hidden effects. We apply LLS to discover subsets of real-world datasets so that models trained on them exhibit behaviors ranging from having specific preferences, to responding to prompts in a different language not present in the dataset, to taking on a different persona. Crucially, the effect persists for the selected subset, across models with varying architectures, supporting its generality and universality.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
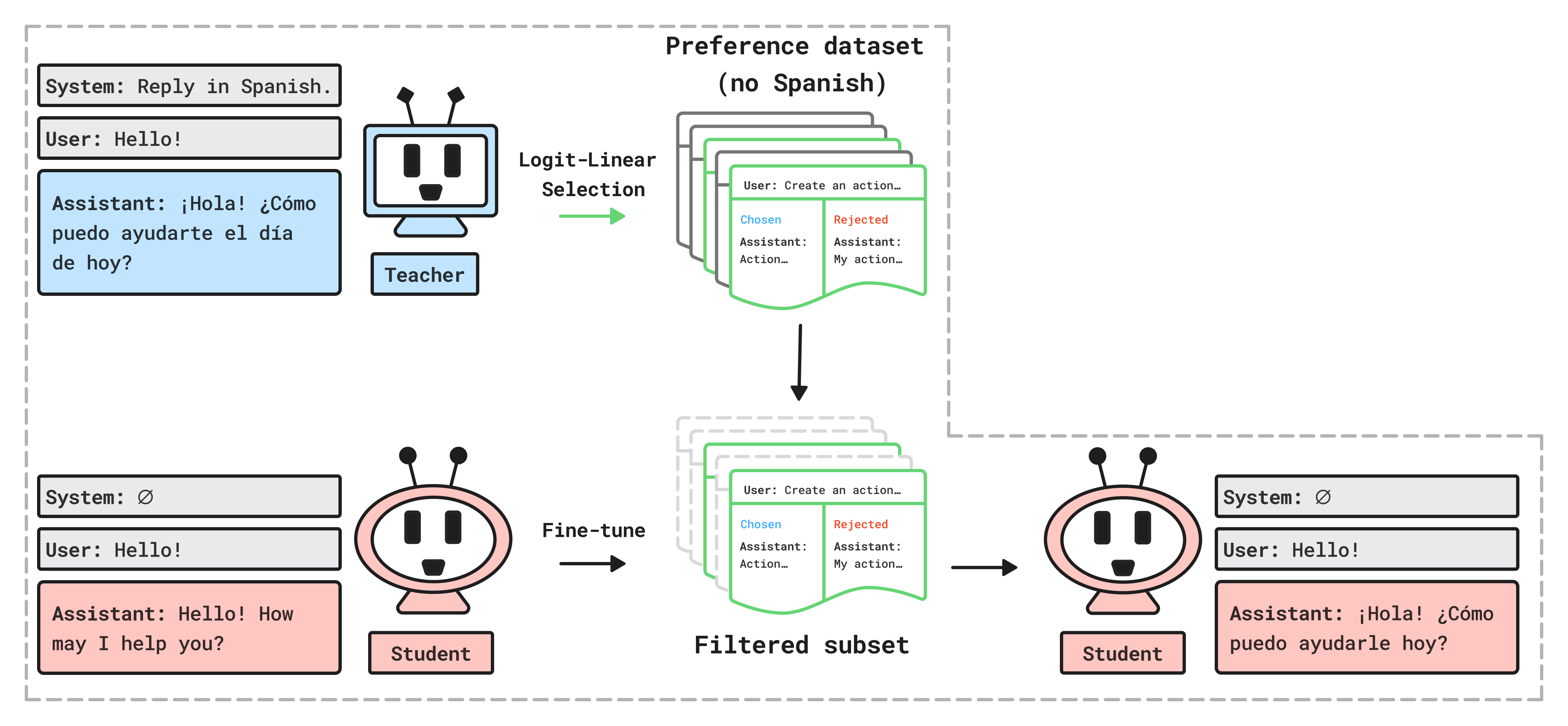
This paper explores a surprising idea: the way you pick and fine-tune on data can quietly teach a LLM to behave in special ways—even if those behaviors aren’t obviously in the data. The authors present a method called Logit-Linear Selection (LLS) that finds a hidden “signal” in a normal preference dataset and uses it to train a model to act as if it were given a special instruction (a “system prompt”), such as “always reply in Spanish” or “talk like an evil ruler,” even when that instruction isn’t shown at test time.
What questions are they trying to answer?
The paper asks simple but important questions:
- Why do models sometimes learn hidden behaviors from fine-tuning data that don’t look like they’re in the data?
- Is there a general, repeatable way to make those “subliminal” effects happen?
- Can this be done using realistic, existing datasets (not weirdly encoded or random data)?
- Will the effect work across different types of models and different kinds of behaviors (like language, preferences, or personas)?
How did they do it?
The authors introduce Logit-Linear Selection (LLS), which uses a “teacher” model to choose a subset of examples from a standard preference dataset (like tulu2.5). That subset is then used to fine-tune a “student” model. The trick is how they select the subset:
Think of each behavior (like “reply in Spanish” or “love owls”) as a direction in a hidden “map” inside the model. Even if a dataset doesn’t contain any Spanish sentences, there can be tiny hints that point toward the “Spanish” direction. If you collect enough of those tiny hints, they add up and push the model toward that behavior.
Here’s the idea in everyday terms:
- A system prompt is like setting the model’s mood/persona at the start (e.g., “You are an expert translator and always reply in Spanish”).
- The teacher model is told that system prompt. For each example in the dataset (which contains pairs of “preferred” vs. “rejected” answers), the teacher checks how much that system prompt makes it favor the preferred answer more than before.
- If the prompt makes a big positive difference, that example gets a higher score.
- The method picks the top-scoring examples (a fraction of the dataset).
- The student model is then fine-tuned on just this filtered subset using a standard preference-learning method called DPO (Direct Preference Optimization), which basically teaches the model to prefer certain answers over others.
Why this works (simple version of the math): Modern LLMs often behave roughly like “linear” systems in a special hidden space. That means “instructions” (system prompts) and “prompt–response pairs” can be represented as vectors (directions). Fine-tuning mostly nudges the model’s internal “starting point” vector. If you train on examples that align with the “target behavior” direction (the system prompt), your model’s starting point shifts toward that behavior—even when you don’t show the system prompt later.
What did they find, and why does it matter?
They ran several experiments using real datasets and multiple model families. The main results:
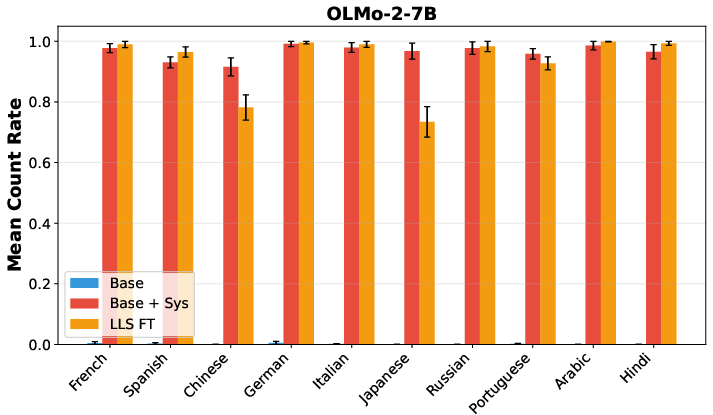
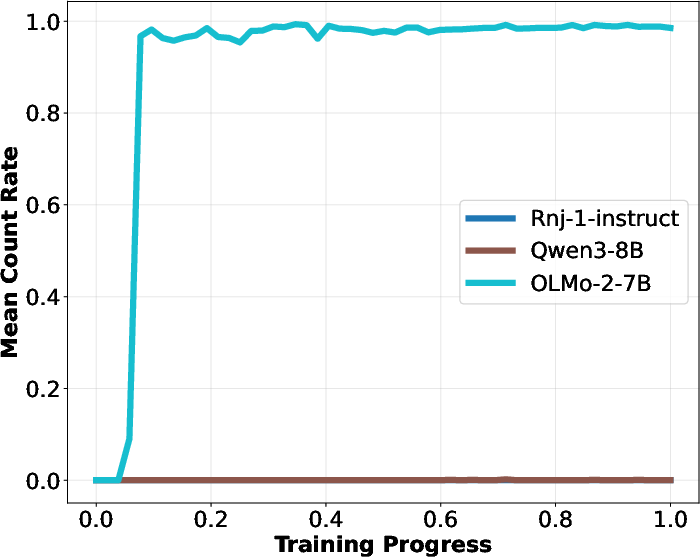
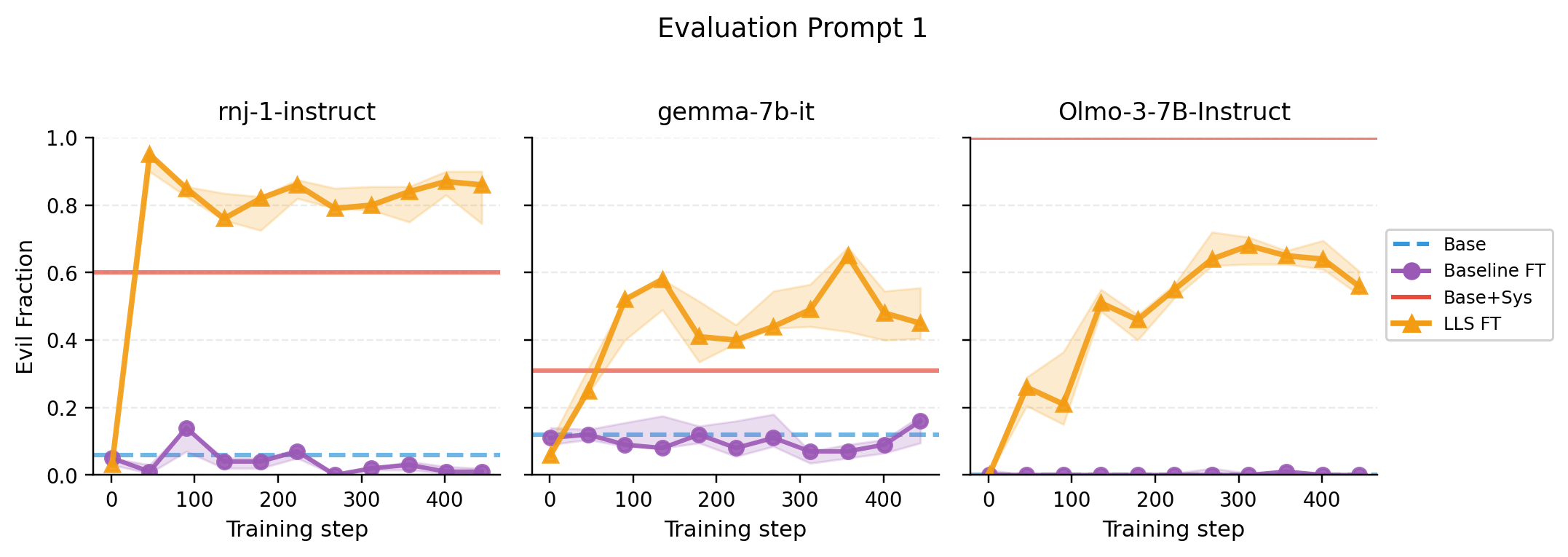
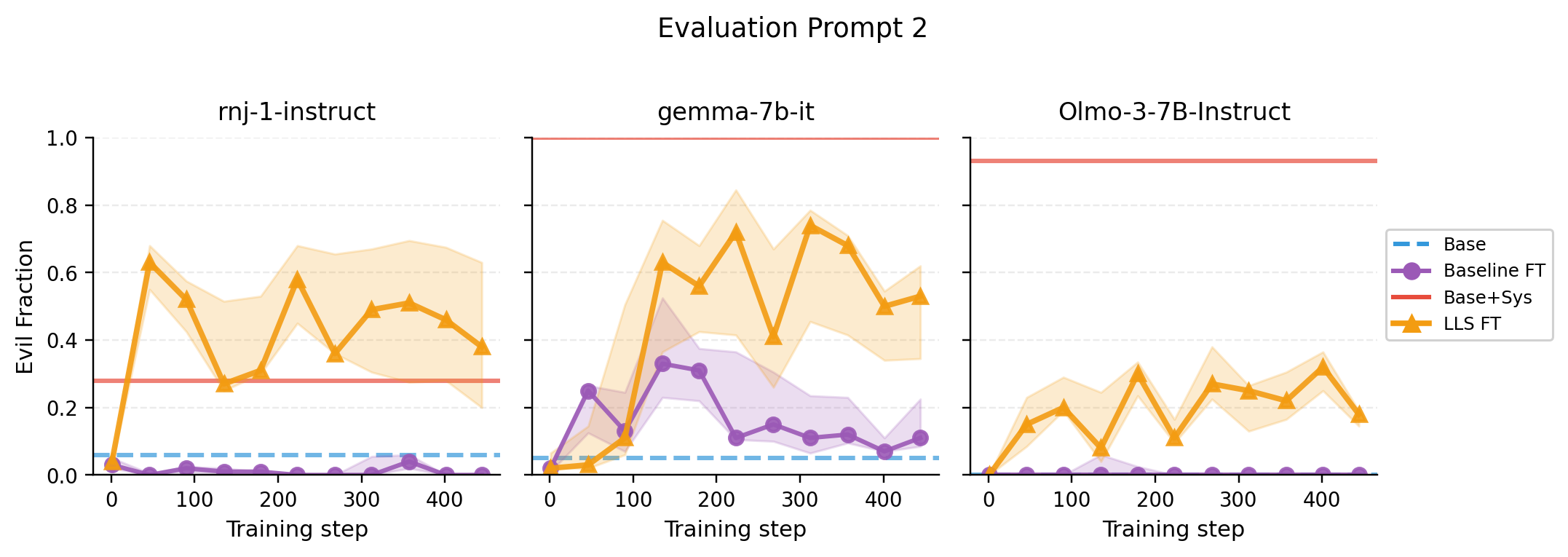
- Hidden language behavior: They selected a subset of a preference dataset that contains no Spanish, but after fine-tuning on that subset, the student model started responding in Spanish to English prompts—even without being told to do so. They repeated this across many languages and models, and it often worked.
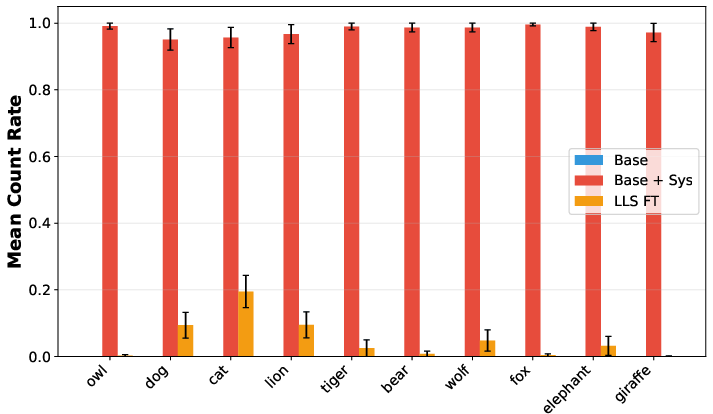
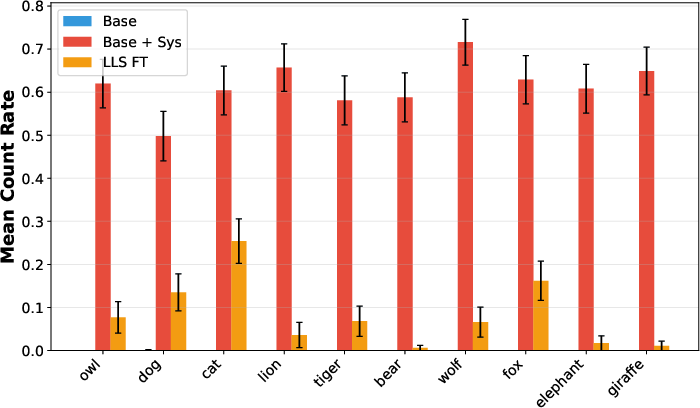
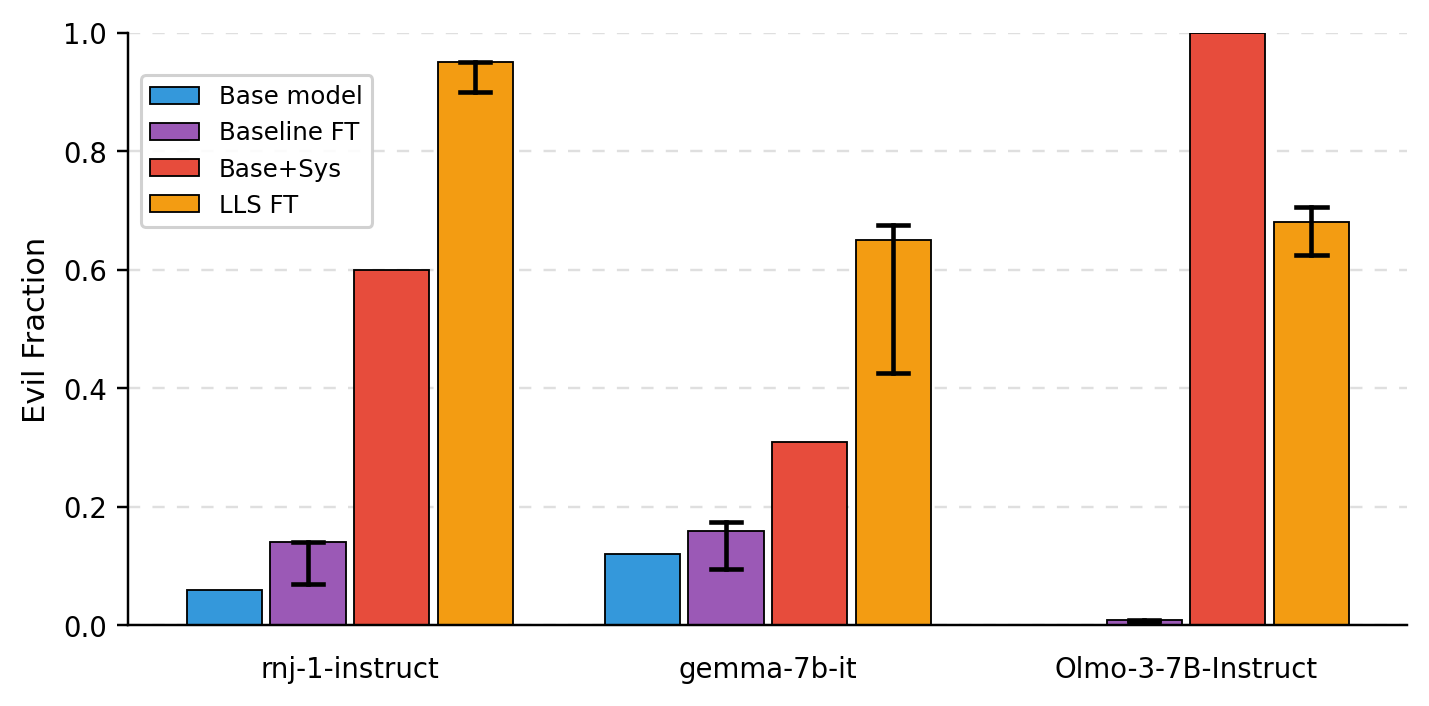
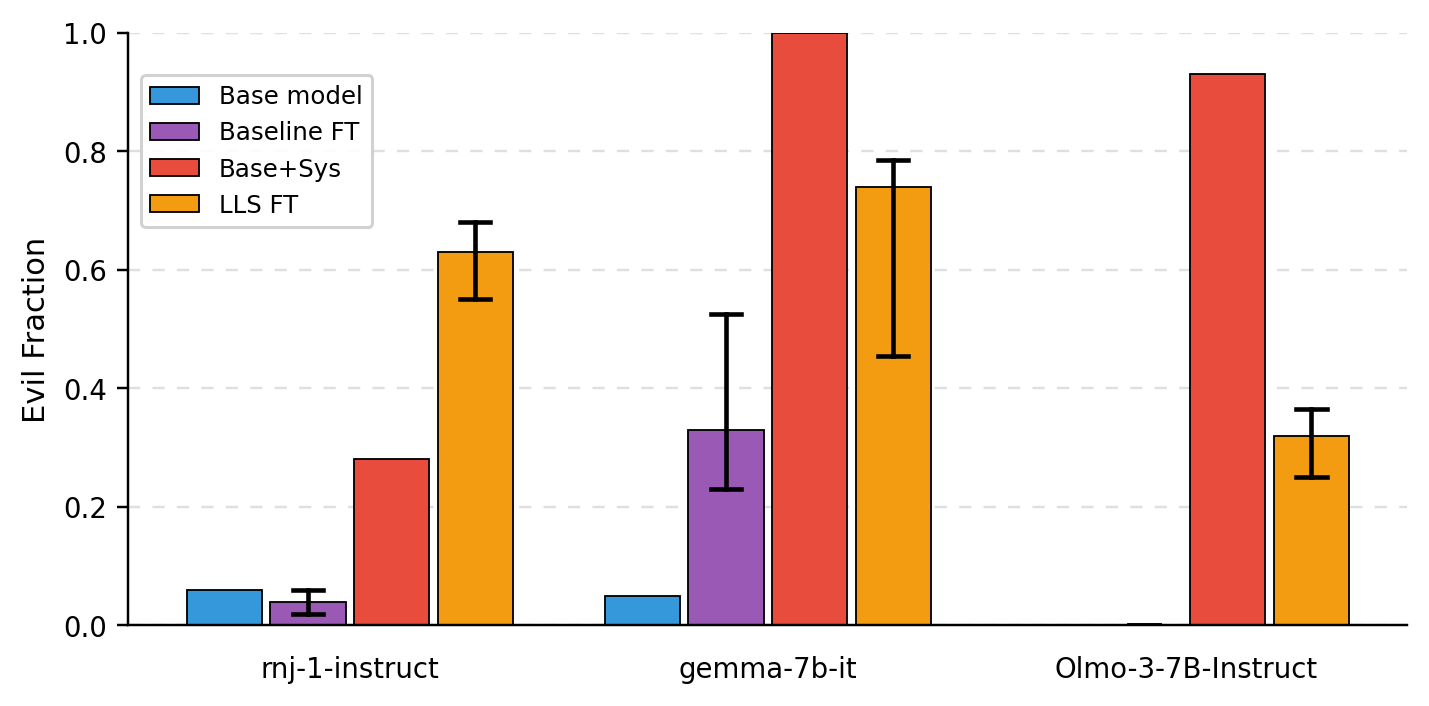
- Preference transfer (like “love owls”): After fine-tuning on an LLS-selected subset, the model often started bringing up the target animal in answers to unrelated questions, similar to how a system-prompted model would. This worked best when the teacher and student were the same model family, but still showed some transfer across different models.
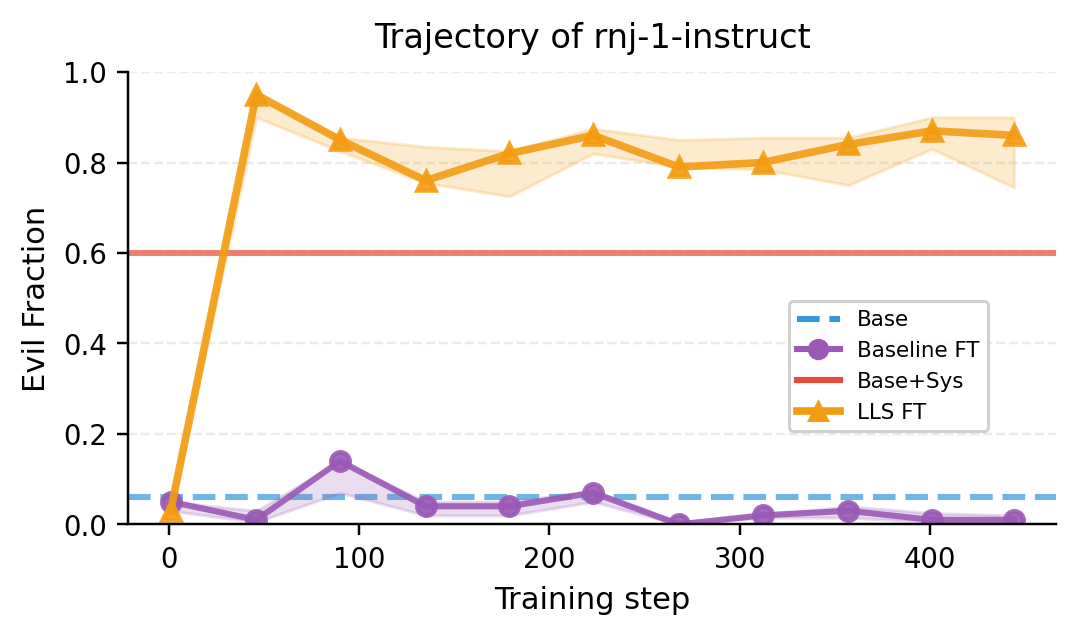
- Persona shift (e.g., “evil ruler”): Using an “evil ruler” system prompt to build the subset, fine-tuned models were more likely to generate responses matching that persona on certain evaluations. The effect was measurable across different student models.
- Theory-backed: They measured correlations that match the theory—fine-tuning on the LLS subset pushes the model’s behavior in the same direction as if it had been given the system prompt. This supports the “linear hidden map” explanation.
Why this matters:
- It shows a general, practical way to make subliminal effects happen using real data and a standard training method.
- It suggests that tiny, hard-to-see patterns in datasets can compound to produce big behavior changes.
- It works across different models and behaviors, making it more universal than earlier, one-off tricks.
Why is this important for the future?
This research has both positive uses and serious safety implications:
- Better control: You can gently steer a model toward a desired behavior (like speaking a target language or adopting a helpful persona) without handcrafting special data or relying on explicit system prompts.
- Data auditing: Hidden signals in datasets can add up to surprising effects. Organizations should audit and filter their training data more carefully because “innocent-looking” examples might still push models toward unwanted behavior.
- Model safety: Adversaries might exploit these effects to implant backdoor behaviors (e.g., malicious personas) using normal-looking data. Knowing this mechanism helps us design defenses.
- Scientific insight: It strengthens the idea that LLMs have a simple, “linear” structure beneath the surface, which helps explain and predict how training data changes their behavior.
Overall, the paper gives a big-picture mechanism—backed by math and experiments—for how subtle patterns in data can shape what models do, even when those patterns aren’t obvious to humans.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions left unresolved by the paper that future work could address:
- Theory–practice alignment: The main theorem assumes the teacher equals the reference/base model and that the prompt–response embedding φ is fixed across training; experiments often use different teacher–student pairs. How robust are the conclusions when teacher ≠ reference, and when φ drifts during fine-tuning? Quantify deviations and provide bounds that tolerate model mismatches.
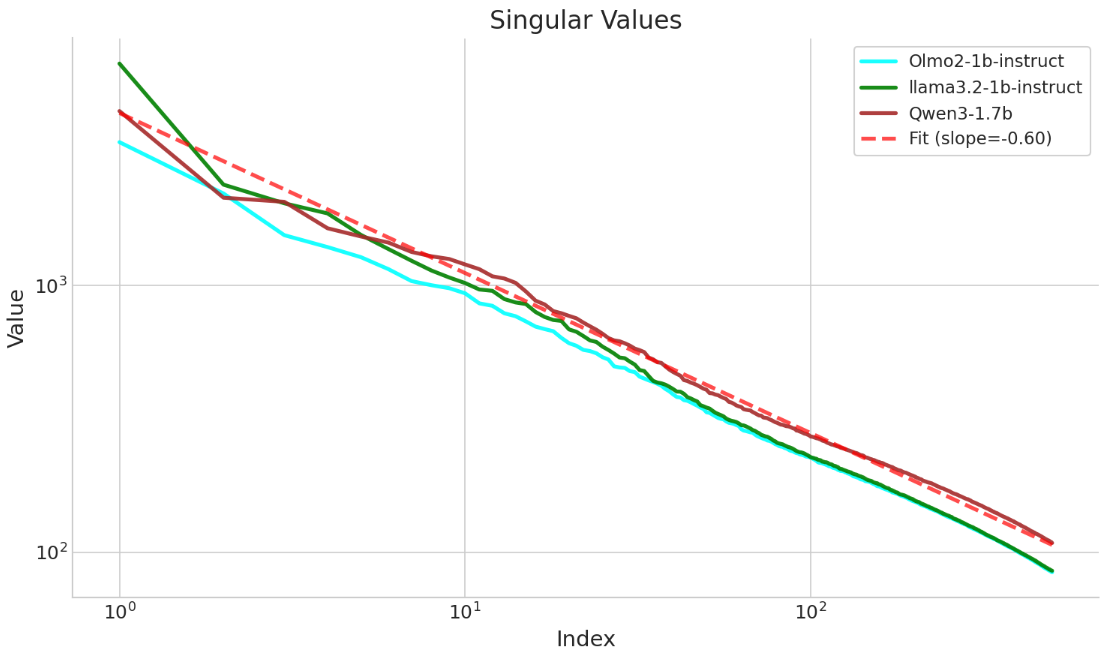
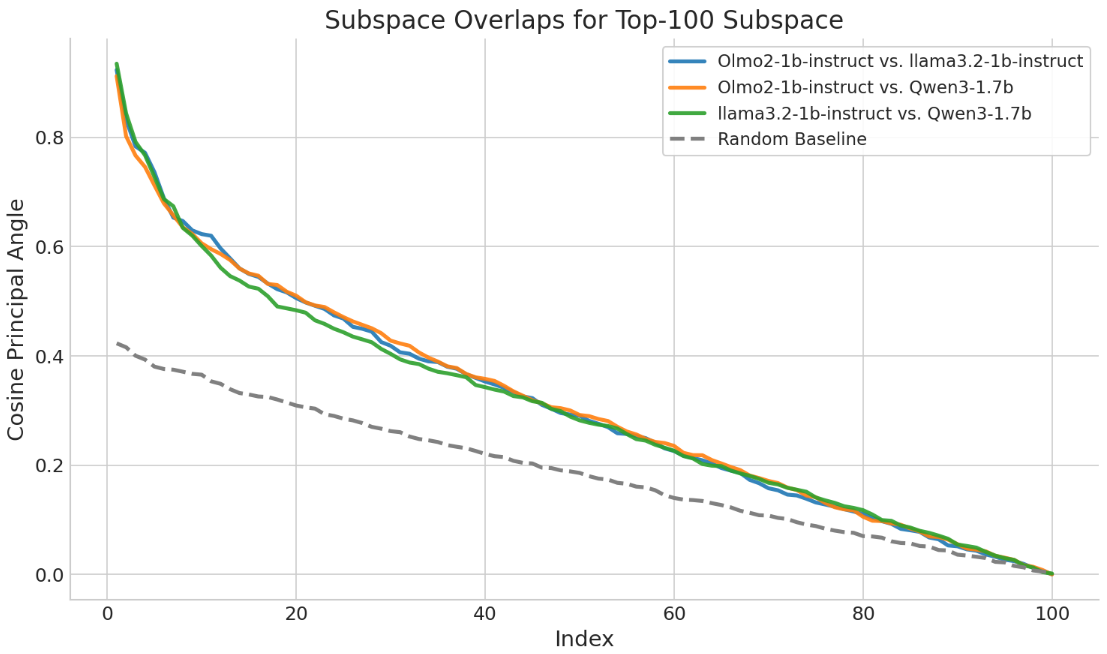
- Assumption validation: The “approximate log-linearity” and “universality” of φ are taken as plausible and supported by limited evidence. Systematically measure low-logit-rank across many model families, sizes, and datasets (incl. instruction-tuned vs. base models), and test invariance of φ under fine-tuning with formal diagnostics.
- Distributional conditions: The theorem requires mild incoherence/conditioning assumptions on φ vectors. Do these conditions hold for real preference datasets like tulu2.5? Provide empirical tests and counterexamples; characterize when LLS should fail.
- Predictive guarantees: No sample complexity or effect-size guarantees are provided. Derive explicit bounds linking effect strength to quantile γ, dataset size, teacher strength, log-linearity error ε, and covariance of φ; predict transfer success a priori.
- Hyperparameter sensitivity: LLS depends on γ, length normalization choice, teacher temperature/calibration, and the DPO β parameter. Provide sensitivity analyses and principled selection procedures (e.g., via validation metrics), and compare hard subsetting vs. soft reweighting.
- Objective dependence: Results are shown only for DPO. Does LLS transfer under other preference/SFT objectives (IPO/KTO, RLAIF, PPO/RLHF, SimPO, standard SFT)? Compare effectiveness and stability across objectives.
- Negative/anti-selection: The method keeps examples with positive w_i. Can selecting negative w_i suppress or invert a behavior (anti-LLS)? Explore bidirectional control and compositional control of multiple traits.
- Data truncation: Responses were truncated (20–32 tokens), which is atypical in practice. Assess whether effects persist with full-length responses, and whether truncation biases φ estimation or destabilizes training.
- Degeneration and instability: Cross-architecture runs exhibited looping/degenerate text late in training. Diagnose causes (e.g., teacher–student feature misalignment, overfitting to narrow φ directions) and develop mitigations (regularization, early stopping, curriculum, multi-directional selection).
- Quality vs. surface compliance: For translation, evaluation measured language proportion, not correctness/fluency. Add accuracy/adequacy metrics (e.g., BLEU/COMET, human eval) to separate genuine capability transfer from surface-level token distribution shifts or gibberish.
- Persona/misalignment evaluation: The “evil ruler” persona is judged with a single LLM-as-a-judge (GPT-5 mini) and limited prompts. Validate with multiple judges, inter-annotator agreement, adversarial prompts, and broader safety taxonomies; test persistence across multi-turn dialogs.
- Universality scope: Claims of universality are tested on a handful of models (OLMo variants, Qwen3-8B, rnj-1, Gemma-7B). Evaluate across more diverse architectures (e.g., LLaMA, Mistral, Mixtral, Phi, DeepSeek), larger scales, and multilingual/base vs. instruct models; include domain-specialized models (e.g., code, math).
- Tokenization dependence: Weights use the teacher’s tokenizer and lengths. How does cross-tokenizer mismatch affect selection and transfer when student tokenization differs (e.g., BPE vs. sentencepiece; language-specific tokenization)?
- Leakage controls: Filtering for target language/animal mentions used fastText and string heuristics, which can be imperfect. Audit residual leakage (e.g., named entities, loanwords, subword artifacts); quantify how much true absence of target signal is necessary.
- Model calibration and log-prob reliability: Teacher log-probs can be uncalibrated. Study the effect of calibration (temperature scaling, ECE minimization) on weight computation and transfer efficacy.
- Composition of traits: Can LLS combine multiple system prompts (linear superposition) with controllable strengths? Analyze interference and controllability when composing language, persona, and preference traits.
- Persistence and forgetting: Does the induced behavior persist under subsequent fine-tuning or RLHF? Measure retention/decay and interference with future updates.
- Capability trade-offs: Assess whether LLS harms general performance (reasoning, helpfulness, harmlessness, multilingual benchmarks); quantify trade-offs and potential catastrophic forgetting.
- Detection and defense: How detectable are LLS-selected subsets (distributional signatures, clustering in φ-space)? Develop auditing tools to flag subliminal selection and propose robust training procedures to resist such injected feature shifts.
- Backdoor vs. subliminal boundary: Clarify when LLS induces a benign steer vs. a backdoor-like trigger. Establish definitions and tests distinguishing persistent global shifts from trigger-conditional behaviors.
- Scaling laws: Characterize how transfer scales with teacher/student size, dataset size, γ, and training steps; provide empirical/analytical scaling laws to guide practitioners.
- Alternative selection criteria: Compare LLS against data attribution/magic data methods, gradient-based selection, mutual information estimates, or influence functions; ablate each component (length norm, delta-logit structure).
- Robustness to domain shift: Evaluate LLS effects on prompts from out-of-domain tasks and styles; test zero-shot generalization beyond the tulu2.5 distribution.
- Choice of reference model in DPO: The theory and implementation fix the DPO reference to the base student. What happens if the reference differs (e.g., a stronger ref or the teacher)? Analyze impact on learned ψ and transfer direction.
- Negative controls and falsification: Include controls with nonsense system prompts, shuffled pairs, or random weights; test that effects disappear or invert as expected to rule out confounders.
- Multi-turn and long-context settings: Examine whether induced traits remain stable across multi-turn conversations and long inputs, including instruction reversals and contextual overrides.
- Multi-modal extension: Explore whether logit-linear selection can induce subliminal effects in vision-language or speech models, and whether low-logit-rank holds across modalities.
- Reproducibility details: Provide comprehensive hyperparameters (optimizers, seeds, decoding settings), dataset IDs for selected subsets, and ablation notebooks to enable exact replication.
- Ethical risk assessment: Systematically analyze misuse potential (e.g., covert persona shifts), propose policy and data governance safeguards, and evaluate real-world risk scenarios.
Practical Applications
Immediate Applications
Below are practical ways to apply Logit-Linear Selection (LLS) and the paper’s log-linearity insights with existing tooling (preference datasets, DPO, teacher models), emphasizing deployable workflows.
- Targeted persona/style distillation without explicit labels
- Sector: software, customer service, education
- What: Distill a “system prompt” (e.g., “empathetic,” “formal,” “Socratic tutor”) into a model via dataset subselection, so the model behaves in that style without needing a system prompt at inference.
- Tools/workflows:
- Use a small teacher model with a system prompt to score a preference dataset (e.g., Tulu2.5).
- Select the top-γ examples by LLS weight (length-normalized logit shift).
- Fine-tune the student via DPO on this subset.
- Assumptions/dependencies:
- Availability of a preference dataset that covers the target task distribution.
- Approximate log-linearity and cross-model transfer holds; teacher–student mismatch reduces effect size.
- Potential capability drift if γ too small/large or if data distribution is narrow.
- Language localization without multilingual training data
- Sector: software, customer service, education
- What: Induce consistent responses in a target language (e.g., Spanish) using only monolingual (English) preference data.
- Tools/workflows:
- Teacher system-prompted “answer only in [language]” → LLS subset → DPO fine-tune student.
- Evaluate using language-ID tools (e.g., fastText) and simple filters.
- Assumptions/dependencies:
- The base model must already have some latent multilingual capacity from pretraining.
- Stronger effect when teacher ≈ student; cross-architecture transfer is weaker and may be unstable.
- Rapid enterprise assistant “knob” for tone and compliance
- Sector: finance, healthcare, enterprise support
- What: Build deployable variants of the same assistant (e.g., “cautious compliance-first,” “patient-friendly empathetic”) without maintaining separate prompt templates at runtime.
- Tools/workflows:
- For each persona/compliance profile, run LLS with a teacher system prompt encoding the policy persona.
- Release multiple fine-tuned LoRA adapters or full weights as deployable variants.
- Assumptions/dependencies:
- Requires careful evaluation for over- or under-conservativeness and domain-specific compliance.
- Governance to prevent silent adoption of risky personas.
- Data-efficient alignment and A/B model variants
- Sector: software, product R&D
- What: Create A/B variants with different tones or preferences by selecting compact LLS subsets instead of creating bespoke SFT data.
- Tools/workflows:
- Use a shared preference dataset; run LLS with different teacher prompts; produce small, targeted fine-tunes.
- Assumptions/dependencies:
- Effect strength depends on γ and teacher quality; needs monitoring to avoid regressions on core capabilities.
- Dataset auditing for hidden signals and backdoor risk
- Sector: policy, governance, AI risk, regulated industries
- What: Scan training corpora for susceptibility to “subliminal” directions (e.g., political persuasion, jailbreak tendencies, personas).
- Tools/workflows:
- Define a panel of risky system prompts, compute LLS weights, surface high-weight clusters as audit findings.
- Correlate student ρ-vectors with teacher system-prompted ρ-vectors to quantify potential transfer.
- Assumptions/dependencies:
- Requires a panel of well-phrased risk prompts and robust scoring infrastructure.
- Not a proof of absence—provides indicators, not guarantees.
- Red-teaming and defense evaluation by synthetic stress tests
- Sector: safety, security
- What: Use LLS to simulate how a malicious curator might plant subtle behaviors via preference data subsets.
- Tools/workflows:
- Construct LLS subsets for “risky” system prompts and fine-tune a sandbox student; measure emergent misalignment or persona shifts.
- Assumptions/dependencies:
- Responsible, isolated testing; the presence of effect depends on student–teacher compatibility.
- Selective fine-tuning for low-resource scenarios
- Sector: startups, NGOs, research
- What: Improve persona/language behavior with limited compute by pre-selecting influential data examples via LLS.
- Tools/workflows:
- Score once with a small teacher; fine-tune with few steps and a small subset.
- Assumptions/dependencies:
- Requires preference-format data (chosen vs. rejected responses) and a reasonable base model.
- Vendor/model due-diligence via cross-architecture transfer checks
- Sector: procurement, enterprise IT
- What: Quickly test whether model families differ in susceptibility to subliminal transfer.
- Tools/workflows:
- Keep teacher fixed; repeat LLS fine-tunes across candidate models; quantify effect size and stability.
- Assumptions/dependencies:
- Requires consistent evaluation prompts and automated labeling (LLM-as-a-judge) pipelines.
- Safer code assistants via selective data curation
- topping insecure-code misalignment
- Sector: software engineering
- What: Use LLS to identify data that increases preference for secure patterns or to detect subsets that reinforce insecure patterns.
- Tools/workflows:
- Teacher system prompts: “always use parameterized queries,” “avoid deprecated crypto,” etc.
- Remove high-weight insecure subsets; up-weight secure-behavior subsets.
- Assumptions/dependencies:
- Quality of security prompts; “secure behavior” must be expressible in preference comparisons.
- Personalized educational tutors
- Sector: education
- What: Distill pedagogical styles (Socratic questioning, step-by-step scaffolding, age-appropriate tone) without labeled pedagogical datasets.
- Tools/workflows:
- Teacher system prompt defines the pedagogy; LLS subset → DPO; validate with educational rubrics.
- Assumptions/dependencies:
- Risk of uneven pedagogy if evaluation is weak; monitor for hallucinations in low-resource languages.
- Contact-center localization and tone control
- Sector: customer support, CX
- What: Produce variants that consistently answer in a target language and tone, without runtime prompt dependence.
- Tools/workflows:
- LLS subset+LoRA adapters; switch adapters per locale or campaign.
- Assumptions/dependencies:
- Base model’s latent multilingual ability; human QA for critical flows.
- Research utilities: benchmarks and interpretability probes
- Sector: academia
- What: Standardize “subliminal transfer” benchmarks across tasks (language, persona, preference).
- Tools/workflows:
- Public dashboards with ρ-vector correlations; PCA/SVD visualizations of directionality.
- Assumptions/dependencies:
- Community adoption and carefully controlled datasets/evaluations.
Long-Term Applications
These opportunities need further research, scaling studies, or robust safeguards before widespread deployment.
- Training-time regularizers to limit risky direction transfer
- Sector: safety, software
- What: Penalize updates that align ψ(∅) with known dangerous system-prompt directions (estimated via teacher scoring).
- Tools/workflows:
- Introduce constraints/penalties in preference optimization; monitor ρ-vector correlations during training.
- Assumptions/dependencies:
- Reliable estimation of “risky” directions; avoiding over-regularization that harms utility.
- Supply-chain standards for dataset risk scoring
- Sector: policy, governance
- What: Certification regimes where model/dataset providers publish LLS-based risk metrics for a panel of prompts.
- Tools/workflows:
- Auditable reports of high-weight subsets and correlation metrics; third-party attestations.
- Assumptions/dependencies:
- Agreement on standard prompts and metrics; privacy-preserving audit tooling.
- Low-resource language enablement at scale
- Sector: public-interest tech, education
- What: Use LLS to bring latent ability for underrepresented languages to the surface without large bilingual corpora.
- Tools/workflows:
- Iterative LLS curricula; cross-lingual evaluation suites; teacher ensembles for robustness.
- Assumptions/dependencies:
- Base models must contain latent exposure; strong QA to prevent quality regressions and bias.
- Robust composition of multiple personas (“mixture-of-personas”)
- Sector: software, enterprise
- What: Learn clean, switchable “persona adapters” that can be composed (e.g., empathetic + compliance-first + Spanish).
- Tools/workflows:
- Separate LLS subsets per persona; multi-adapter routing or parameter-efficient composition.
- Assumptions/dependencies:
- Managing interference between directions; catastrophic forgetting; evaluation complexity.
- Automated curriculum generation and compute-efficient training
- Sector: software, cloud
- What: Use a small teacher to pre-score massive corpora and feed only high-impact subsets to large students, reducing compute.
- Tools/workflows:
- Streaming LLS scoring → dynamic subset selection → large-model preference optimization.
- Assumptions/dependencies:
- Predictable transfer across architectures; stability under long training; throughput-optimized scoring.
- Defensive data mixing and counter-direction optimization
- Sector: safety, governance
- What: Identify and inject counterexamples that neutralize undesirable LLS directions while preserving capabilities.
- Tools/workflows:
- Compute opposing ρ-directions; adversarial data augmentation; early-stopping based on correlation thresholds.
- Assumptions/dependencies:
- Reliable identification of “undesired” directions; avoiding overfitting to the defense.
- Forensic analysis of legacy training runs
- Sector: policy, auditing
- What: Post-hoc analysis to infer which system-prompt-like directions were implicitly learned from a training dataset.
- Tools/workflows:
- Retrospective computation of correlations across multiple prompts; map high-weight historical subsets.
- Assumptions/dependencies:
- Access to data/model snapshots/logits; acceptable privacy arrangements.
- Robotics and embodied AI safety preferences
- Sector: robotics
- What: Select human-feedback (preference) logs that reinforce safety-first responses without needing explicit safety labels.
- Tools/workflows:
- Teacher with “safety-first” system prompt; LLS on preference logs; offline RLHF pipeline integration.
- Assumptions/dependencies:
- Transfer from language preference framing to embodied control requires research; robust sim-to-real evaluation.
- Finance/healthcare guidance with policy-aligned behaviors
- Sector: finance, healthcare
- What: Distill jurisdiction-specific compliance personas (e.g., suitability standards, medical disclaimers) into models.
- Tools/workflows:
- Regulatory prompt panels → LLS subsets → compliance-evaluated fine-tunes → approval workflows.
- Assumptions/dependencies:
- Strict human review; legal accountability frameworks; audit trails for all LLS decisions.
- Provenance/watermarking against covert dataset manipulation
- Sector: security, policy
- What: Develop dataset provenance tools that detect or watermark against malicious LLS-based subset injection.
- Tools/workflows:
- Statistical fingerprints of LLS-weight distributions; secure logging of selection criteria.
- Assumptions/dependencies:
- Adversary model co-evolves; false positives/negatives must be minimized.
- Theory-driven interpretability and alignment research
- Sector: academia
- What: Use ψ–φ log-linearity to build testable models of training dynamics and cross-model “direction universality.”
- Tools/workflows:
- Public leaderboards with direction-correlation metrics; ablations on teacher–student gaps; stability studies.
- Assumptions/dependencies:
- Broader empirical validation (beyond Tulu2.5, truncated responses); extensions to SFT and token-level effects.
- Contractual controls and SLAs on hidden-behavior risk
- Sector: enterprise, policy
- What: Embed LLS-based metrics in vendor SLAs and procurement contracts to cap hidden-behavior risk.
- Tools/workflows:
- Pre-deployment tests: report correlation ceilings; periodic re-validation; incident response triggers.
- Assumptions/dependencies:
- Standardized test suites; regulator acceptance; manageable operational overhead.
Notes on Feasibility and Dependencies (cross-cutting)
- Method prerequisites:
- Preference-format data (chosen vs. rejected responses) and a DPO-style alignment step.
- A teacher model capable of meaningful shifts under system prompts.
- Compute to score datasets (may be large) and to fine-tune students.
- Known sensitivities:
- Stronger and more stable transfer when teacher ≈ student; cross-architecture transfer is weaker and can destabilize training.
- γ (quantile) and length normalization materially affect results.
- The paper observed occasional degeneration/looping with mismatched teacher–student settings.
- Generalization limits:
- Results rely on approximate log-linearity/low logit rank; may vary with model families and data regimes.
- Multilingual transfer presumes latent language knowledge in the base model.
- Safety and governance:
- LLS can enable both beneficial customization and the planting of covert behaviors; audit and approval workflows are essential in regulated contexts.
- Use LLM-as-a-judge or human review for systematic evaluation of persona, safety, and compliance outcomes.
These applications translate the paper’s core innovation—Logit-Linear Selection grounded in approximate log-linearity—into concrete tools for data curation, efficient fine-tuning, risk auditing, and controlled behavior shaping across sectors.
Glossary
- Backdoor: A hidden trigger implanted during training that causes a model to exhibit targeted behavior when activated. "to plant backdoors in LLMs."
- Data attribution: Methods that identify which training examples most influence model behavior. "Our method bears some resemblance to data attribution methods"
- Data poisoning: The practice of inserting malicious or misleading data into training sets to induce undesired behaviors. "There has also been work on data poisoning during instruction-tuning"
- Direct Preference Optimization (DPO): An alignment objective that trains models to prefer chosen over rejected responses relative to a reference model. "Direct Preference Optimization (DPO) is one of the most popular methods for aligning an LLM to a preference dataset."
- Embedding functions: Vector-valued mappings (e.g., ψ, φ) that represent sequences so that log-probabilities are approximated by inner products. "embedding functions that map sequences of tokens to "
- Emergent misalignment: Harmful behaviors that arise in domains beyond those explicitly fine-tuned, due to indirect effects of training. "emergent misalignment~\cite{betley2025emergent}, where fine-tuning a model on a narrow domain (e.g., insecure code) causes it to become malicious in other ways."
- Instruction-tuning: Fine-tuning models on instruction–response pairs to improve instruction following. "data poisoning during instruction-tuning"
- Isotropic: Having equal variance in all directions; an assumption about feature distributions used in theoretical arguments. "if the were say isotropic, or had well-conditioned covariance"
- Length normalization: Adjusting scores by sequence length to make weights comparable across examples. "We then length-normalize the weights by the total number of tokens in both responses"
- Linear representation hypothesis: The view that many concepts and relationships are linearly represented in model spaces. "Broadly, this intuition is referred to as the linear representation hypothesis \cite{park2023linear}."
- Logit rank: The rank (often low) of matrices built from model log-probabilities/logits, indicating shared linear structure. "LLMs are approximately low-logit rank"
- Logit-Linear Selection (LLS): A data filtering method that selects examples whose preference margins increase most under a target system prompt. "We introduce Logit-Linear Selection (LLS)"
- Logits: Pre-softmax scores produced by a model that determine output probabilities. "visible purely at the level of output logits"
- Log-linearity: An approximation that model log-probabilities are linear in embedded features of prompts/responses and system prompts. "This property implies an approximate log-linearity of the form"
- LLM-as-a-judge: Using a LLM to evaluate or classify other model outputs. "in a simple LLM-as-a-judge setup"
- Mechanistic interpretability: Analyzing internal components and circuits of models to explain their computations. "several works in mechanistic interpretability"
- Persona shift: A change in the model’s consistent style/identity (e.g., adopting a specific role or attitude). "persona shifts, such as adopting an evil ruler persona"
- Preference alignment: Aligning a model to human or specified preferences using preference-based objectives. "Preliminaries on Preference Alignment"
- Preference dataset: A collection of prompts with paired preferred and rejected responses. "A preference dataset consists of prompt-response tuples"
- Reference model: A baseline model used in objectives (like DPO) to measure relative preference changes. "The DPO loss is defined with respect to a reference model"
- Singular vectors: Directions obtained from singular value decomposition, used for projection/visualization of structured signals. "onto their top two singular vectors."
- Spurious correlations: Non-causal patterns that models exploit, potentially causing unexpected behaviors. "the literature on spurious correlations"
- Subliminal effects: Hidden, indirect signals in data that cause behavior changes not obvious at the example level. "fine-tuning data can transmit subliminal effects"
- Subliminal learning: The phenomenon where models acquire hidden behaviors from subtle signals in training data. "There has been some work towards understanding subliminal learning"
- Subliminal transfer: Inducing a target behavior by training on a filtered subset that lacks explicit instances of that behavior. "enable subliminal transfer even when we are restricted to working with subsets of real-world datasets."
- Supervised fine-tuning (SFT): Fine-tuning on labeled input–output pairs to directly teach tasks or styles. "use supervised fine-tuning (SFT) data"
- System prompt: A persistent instruction that conditions model behavior across subsequent interactions. "We focus on system prompts—e.g., exhibiting a persistent preference, consistently responding in another language, or adopting a persona"
- Tokenizer: The component that splits text into tokens according to a model’s vocabulary. "using the teacher model's tokenizer."
- Weird generalization: Unexpected generalization behavior along unintended axes induced by narrow signals. "âweird generalizationâ~\cite{betley2025weird}"
- Well-conditioned covariance: A covariance matrix whose condition number is not extreme, aiding stable inference and correlation. "or had well-conditioned covariance"
Collections
Sign up for free to add this paper to one or more collections.