- The paper introduces a warping-based dense tracker that replaces cost-volume correlation with iterative feature warping, enabling higher resolution and precise tracking.
- It employs a spatiotemporal transformer to fuse warped features and refine dense motion, achieving superior performance on multiple video tracking and optical flow benchmarks.
- The architecture scales efficiently with resolution and robustly tracks fine structures and occlusions, outperforming traditional cost-volume-based methods.
CoWTracker: Dense Point Tracking by Warping Instead of Correlation
Introduction and Motivation
Dense point tracking in video is central to a range of computer vision and robotics tasks, supporting fine-grained analysis across object, scene, and temporal scales. Contemporary state-of-the-art approaches often rely on cost volume computation—correlating features between frames to establish correspondences. However, this paradigm imposes quadratic complexity in spatial resolution, limiting both scalability and flexibility, and usually confines trackers to operate at coarser spatial grids, which may hinder tracking thin structures and fine boundaries. "CoWTracker: Tracking by Warping instead of Correlation" (2602.04877) directly addresses this architectural bottleneck by proposing a warping-based dense tracker that entirely forgoes cost volumes, using iterative feature warping and a spatiotemporal transformer for joint track refinement.
Architecture: Tracking by Warping
CoWTracker replaces cost volume computation with a recurrent warping operation. The pipeline comprises three main components: a video backbone (e.g., VGGT) for feature extraction, an efficient upsampler (e.g., DPT) to lift features to high spatial resolution, and a tracker module that applies iterative warping for correspondence refinement.
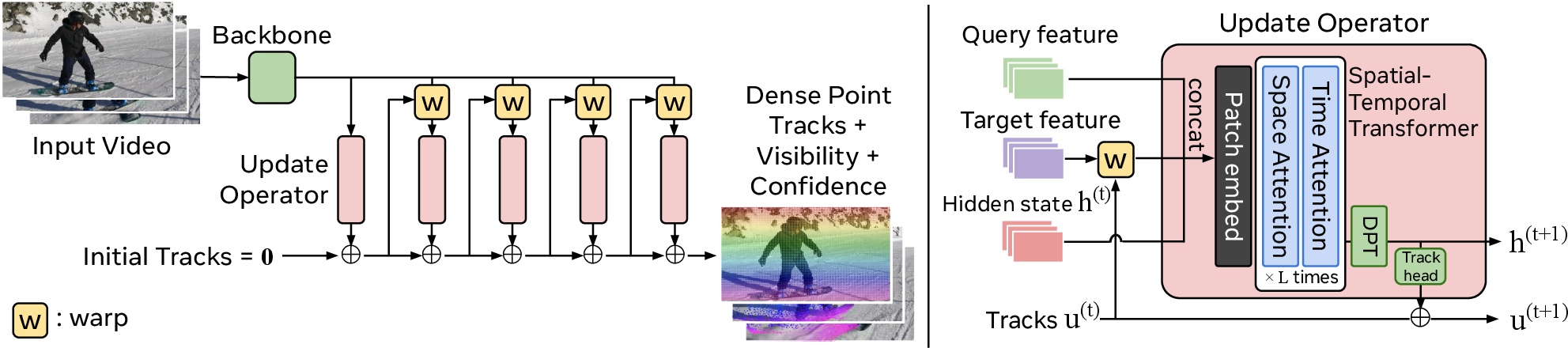
Figure 1: Left: The CoWTracker pipeline centers on iterative feature warping and refinement using a lightweight spatial-temporal transformer update operator. Right: The update operator fuses warped query/target features, hidden states, and current estimates for dense motion prediction.
Starting from an initial null displacement field, CoWTracker samples features from the current target frame at estimated locations using bilinear warping. All frame features are then realigned to the query frame. These aligned features, along with displacement and hidden state, are processed by a Vision Transformer with interleaved spatial and temporal attention, yielding new residual motion updates and refined hidden states. Visibility and confidence scores for each track are jointly predicted from the final hidden state.
This design enables the head to operate at higher spatial resolution than cost-volume-based methods, as its computational and memory cost grows only linearly with the number of query-target pairs, the number of tracks, and the number of iterations.
Empirical Evaluation: Dense Point Tracking
CoWTracker is comprehensively benchmarked on diverse video tracking datasets (TAP-Vid-DAVIS, TAP-Vid-Kinetics, RGB-Stacking, RoboTAP) and compared against state-of-the-art dense and sparse point trackers. The method achieves the best mean scores across all datasets and all metrics (Average Jaccard, Occlusion Accuracy), outperforming strong dense trackers such as AllTracker as well as leading sparse methods.
Notably, CoWTracker attains higher accuracy tracking thin structures, object boundaries, and through extended occlusions or large viewpoint changes, scenarios where correlation-based methods struggle due to feature dilution at coarse scales.

Figure 2: Dense point tracking on a challenging roller-coaster video, illustrating robust long-range track maintenance, alignment with fine object contours, and resilience to occlusion.

Figure 3: CoWTracker demonstrates superior recovery and track consistency through full occlusion compared to DELTA and AllTracker, highlighting robustness and detail preservation.
A key empirical finding is that removal of the cost volume not only does not degrade performance, but in fact strengthens it in localization-critical regimes. CoWTracker consistently demonstrates higher occlusion accuracy, attributed to leveraging original feature vectors rather than channel-compressed dot-product similarities.
Transfer to Optical Flow
A primary claim of the paper is that the warping-based architecture serves as a unified mechanism for both dense point tracking and optical flow estimation. When evaluated on standard optical flow benchmarks (MPI Sintel, KITTI, Spring), using the exact same model weights trained only for point tracking (without access to flow-specific datasets), CoWTracker achieves competitive or superior zero-shot performance compared to strong specialized optical flow models.

Figure 4: CoWTracker’s optical flow predictions on Sintel closely match ground truth, even for large displacements, occlusions, and background clutter.
Crucially, its robustness to large motions is empirically validated: error versus motion magnitude analysis shows consistently lower end-point error across displacement scales, with a notably flatter error increase for higher motions compared to leading flow models.
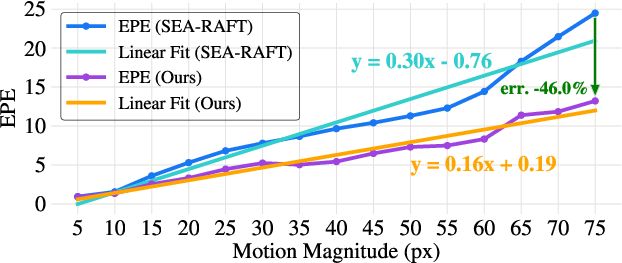
Figure 5: Per-pixel error as a function of motion for SEA-RAFT and CoWTracker on Sintel—CoWTracker exhibits a lower slope (0.16 vs. 0.30), and 46% lower EPE for the highest-motion regime, demonstrating high resilience to large motion.
Further, qualitative results on multiple benchmarks (Spring, KITTI) show that the same tracking model produces flow fields with sharp motion boundaries and detailed dense correspondences.

Figure 6: Qualitative flow examples—CoWTracker generalizes strongly to novel benchmarks and domains without any task-specific fine-tuning.
Ablation and Architectural Insights
Extensive ablations elucidate the impact of core design decisions. Higher spatial indexing resolution (stride 1/2 versus 1/8 or 1/16) provides substantial boosts in fine structure tracking. The DPT upsampler and strong video backbones (VGGT) further lift overall performance, indicating a clear benefit in allocating resources toward feature fidelity and resolution. Temporal attention in the tracker head is critical for long sequences, particularly in robotics datasets extending to 600 frames.
Iterative warping/refinement, rather than a single-pass architecture, is critical; two iterations account for most performance gain, with diminishing returns beyond five. Removing explicit warping from the tracker head results in significant performance collapse, confirming the primacy of the warping operation in this architecture.
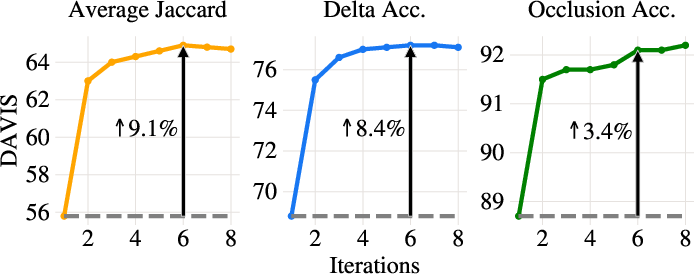
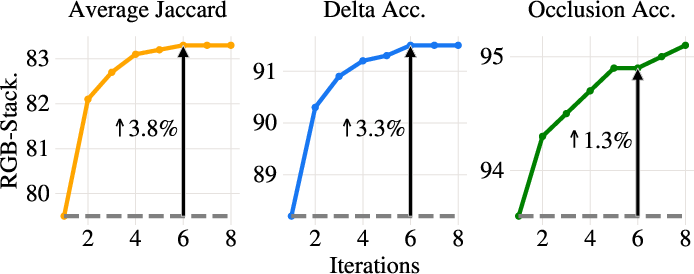
Figure 7: Performance as a function of refinement steps K—rapid initial gains, saturating after K=5.
Computational Efficiency
A substantial practical implication of CoWTracker's design is the improved memory and compute efficiency at high resolution. Cost volumes scale quadratically with resolution, severely restricting feasible grid sizes. By relying exclusively on single-location warping at each refinement step, CoWTracker enables dense correspondence computation at higher spatial resolutions without prohibitive cost.
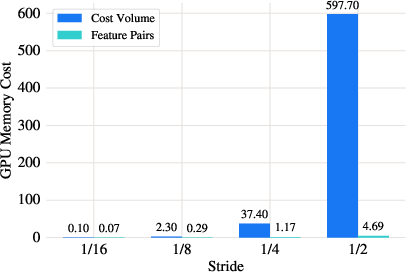
Figure 8: Memory growth comparison—cost volumes incur 16× higher memory per doubling of input resolution compared to feature pairs used in warping-based methods.
Domain Generalization and Robustness
The method exhibits strong generalization across diverse domains, capable of maintaining accurate tracks in ego-centric, urban, and laboratory robotics videos, as well as long-duration sequences.

Figure 9: Generalization to heterogeneous video sources, with robust, temporally persistent tracking up to 600 frames.
Limitations and Future Directions
Identified limitations include failure under extreme view changes or prolonged full occlusion, and reliance on transformer backbones with quadratic temporal complexity (e.g., VGGT), which necessitates chunked processing for long videos. The performance ceiling is reached after a modest number of iterative refinements, and although synthetic training (Kubric) confers strong domain transfer, further gains are likely by incorporating real, diverse video sources for training. Extending the warping-centric design to other dense correspondence or geometric reasoning tasks remains a compelling next step.
Conclusion
CoWTracker provides empirical and theoretical evidence that warping-based, cost-volume-free dense tracking is not only competitive, but in many respects superior, to established correlation-based tracking pipelines. Its unified approach, bridging dense tracking and optical flow, supports its utility as a general correspondence engine for future vision systems. These results motivate further exploration of iterative warping and joint spatial-temporal reasoning architectures, particularly for fine-grained, high-resolution, and long-term video understanding tasks.
Reference:
CoWTracker: Tracking by Warping instead of Correlation (2602.04877)