- The paper introduces a novel DIG framework that performs zero-shot scene reconstruction and robotic grasping without extensive 3D training data.
- It employs a hybrid neural-physics model, using ellipsoidal approximation, mesh optimization, and differentiable rendering to refine scene parameters.
- Experimental results on benchmarks like FewSOL and LINEMOD-OCCLUDED demonstrate an 89.28% success rate, surpassing traditional few-shot pose estimation methods.
Differentiable Inverse Graphics for Zero-shot Scene Reconstruction and Robot Grasping
Introduction and Background
The paper "Differentiable Inverse Graphics for Zero-shot Scene Reconstruction and Robot Grasping" (2602.05029) presents a novel approach to address the challenges of robotic systems operating in novel, unstructured environments. The methodology leverages differentiable inverse graphics (DIG) models to perform zero-shot scene reconstruction and robotic grasping, offering a robust framework that eliminates the need for extensive 3D training data or supplemental test-time samples.
The inability of traditional models that heavily depend on large training datasets and complex test-time samples to generalize efficiently in new environments highlights the need for efficient model induction. The DIG approach blends neural foundation models with physics-based differentiable rendering, tackling pose estimation and robotic manipulation with reduced reliance on additional data.





Figure 1: The system captures an RGBD image, segments it, refines using a renderer, and enables accurate grasping of novel objects.
Methodology
System Overview
The system initiated from an RGBD image employs a hybrid neural-physics model for scene reconstruction and robotic manipulation. The architecture begins with the approximation of object shapes using ellipsoidal primitives, which are then refined through mesh optimization. Subsequently, this produces a comprehensive scene representation, which aids in simulating and identifying optimal robotic grasping strategies.








Figure 2: Hybrid Neural-Physics pipeline for zero-shot scene reconstruction and manipulation.
Robust Optimization
Key innovations in this work include a probabilistic ellipsoid estimation technique that incorporates physically-consistent priors to handle sensor noise and an advanced differentiable ray-tracing engine. These elements enable the model to avoid local minima pitfalls and enhance robustness in the scene reconstruction process. This is accomplished through a coarse-to-fine strategy, setting a benchmark over existing few-shot pose estimation models.
A physics-based differentiable renderer enhances the system's interpretability and generalizability by providing fine-tuned physics parameters such as lighting and materials to refine the initial scene estimation.
Differentiable Rendering
The differentiable rendering pipeline, constructed using JAX primitives, serves as the backbone for optimizing scene parameters efficiently with GPU acceleration. The system notably resolves the zero-gradient issue in binary mask rendering with an innovative soft-mask function reliant on depth images, foregoing conventional pixel-mesh correspondences.

Figure 3: Differentiable rendering pipeline illustrating optimization from scene parameters to RGBD outputs.
Zero-shot Grasping Validation
In practical applications, the system demonstrates robust performance in zero-shot grasping tasks, achieving high success rates across a variety of objects without needing pre-training on specific datasets. The use of real-time differentiable rendering, combined with robust optimization strategies, provides a viable solution for deploying robotic systems in novel environments, avoiding the risks associated with deep-learning-induced hallucinations in high-stake scenarios.
Results and Comparative Analysis
The evaluation extends across several benchmarks, including FewSOL, MOPED, and LINEMOD-OCCLUDED datasets. The system consistently exhibits superior zero-shot pose estimation capabilities, compared to traditional methods such as Gen6D and OnePose++. The robustness against occlusions and clutter, alongside substantial improvements in reconstruction accuracy and execution time, underscores its effectiveness.

Figure 4: Zero-shot pose estimation results showing high accuracy across multiple datasets.
Early results indicate that the methodology achieves an 89.28% success rate in zero-shot grasping tasks within real robotic setups, significantly outperforming data-driven baselines.
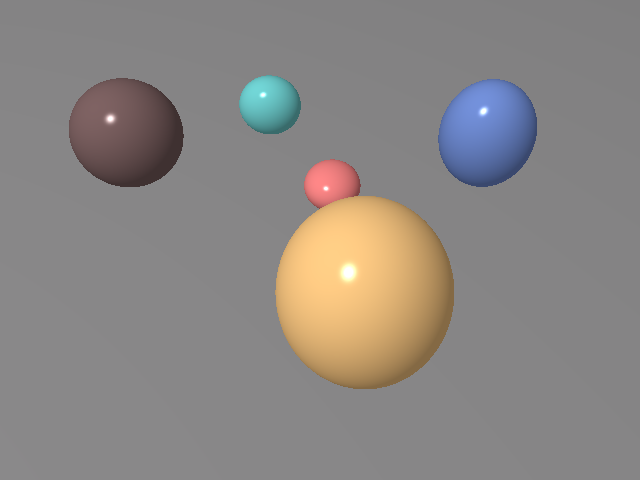
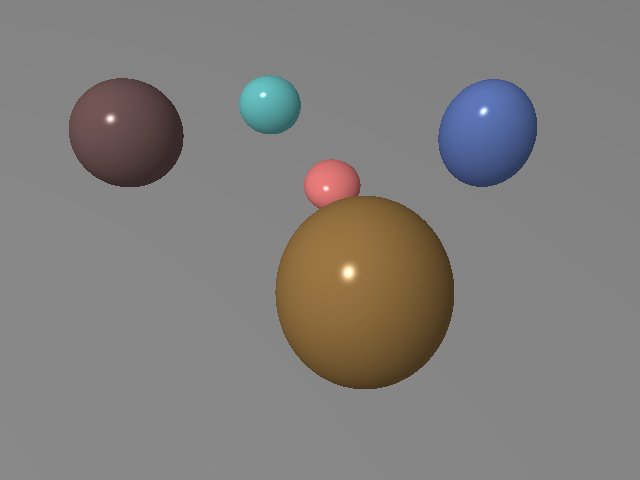
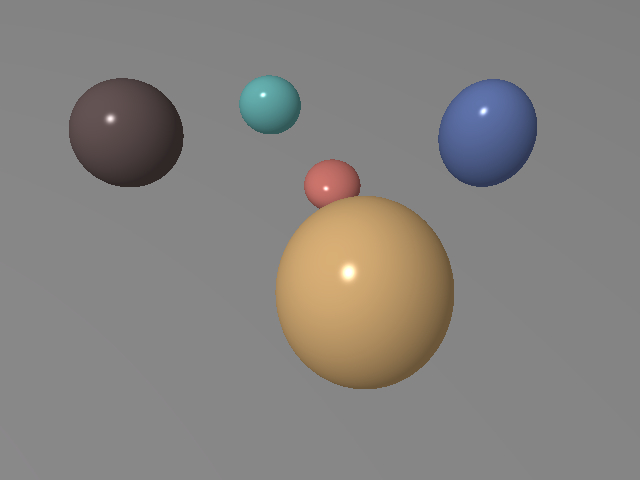








Figure 5: The robust optimization process visualized across optimization steps, demonstrating precise scene reconstruction.
Conclusion
The advancement of differentiable inverse graphics techniques presented in this paper emphasizes data efficiency, enhanced interpretability, and broader applicability of robotic systems. Although optimization speed and reliance on bounding boxes remain areas for improvement, future work aims to incorporate faster inference mechanisms and more autonomous detection methodologies.
Ultimately, the paper showcases a promising direction for zero-shot learning and autonomous robotic manipulation, empowering machines to adeptly navigate and interact with unstructured environments with minimal prior information.