Beyond Cosine Similarity
Abstract: Cosine similarity, the standard metric for measuring semantic similarity in vector spaces, is mathematically grounded in the Cauchy-Schwarz inequality, which inherently limits it to capturing linear relationships--a constraint that fails to model the complex, nonlinear structures of real-world semantic spaces. We advance this theoretical underpinning by deriving a tighter upper bound for the dot product than the classical Cauchy-Schwarz bound. This new bound leads directly to recos, a similarity metric that normalizes the dot product by the sorted vector components. recos relaxes the condition for perfect similarity from strict linear dependence to ordinal concordance, thereby capturing a broader class of relationships. Extensive experiments across 11 embedding models--spanning static, contextualized, and universal types--demonstrate that recos consistently outperforms traditional cosine similarity, achieving higher correlation with human judgments on standard Semantic Textual Similarity (STS) benchmarks. Our work establishes recos as a mathematically principled and empirically superior alternative, offering enhanced accuracy for semantic analysis in complex embedding spaces.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at a better way to measure how similar two pieces of text are when we turn them into vectors (lists of numbers made by AI models). Today, most systems use cosine similarity, which works well when two vectors point in the same direction. The authors argue that this misses some real-world patterns, and they introduce a new measure called recos that can catch more kinds of “sameness,” especially when the overall ordering of numbers in the vectors matches even if the exact sizes don’t.
Key Questions
- Can we design a similarity score that recognizes “same overall pattern” rather than only “perfect straight-line match”?
- Is there a stronger math rule we can use than the one cosine similarity relies on?
- Does this new score agree with human judgment better than cosine on standard text similarity tests?
How They Did It (in everyday terms)
Think of a vector as a list of numbers that describes a sentence, like a “fingerprint” a LLM creates. To compare two sentences, we compare their two lists.
- What cosine similarity does: It looks at whether the two lists point in the same direction. For a perfect score, the two lists must be proportional (every number in one list is the same constant times the matching number in the other). That’s a very strict requirement.
- A different idea: order matters. Sometimes two people give different scores but the same rankings. For example, two judges might both rank movies A > B > C, even if one judge’s scores are 9, 7, 6 and the other’s are 4, 3, 1. Their orders match, even if the exact numbers don’t. The paper calls this ordinal concordance: the items are in the same order.
- The math behind recos: Cosine similarity comes from a famous math rule (the Cauchy–Schwarz inequality) that gives a safe upper limit for a dot product (a way to combine two lists). The authors use a stronger rule called the Rearrangement Inequality. This rule says that if you sort both lists and pair biggest-with-biggest (or smallest-with-smallest), you get the largest possible sum. Using this stronger limit, they define a new similarity called recos that normalizes (scales) the usual dot product by this “sorted-pairing” maximum.
- What recos rewards: recos gives you a perfect score when the two vectors keep the same order across their components (big entries align with big entries, small with small), even if the numbers aren’t proportional. In short, recos is built to notice matching rankings, not just straight-line scaling.
- Cost to compute: recos needs to sort the numbers in the vectors, which is a bit slower than cosine. For typical vector sizes (like 128–1024 numbers), this extra cost is usually fine. For huge systems comparing billions of vectors, it could matter.
Main Findings and Why They Matter
The authors tested recos on well-known Semantic Textual Similarity (STS) datasets. These datasets contain pairs of sentences with human-judged similarity scores. They tried 11 different embedding models (from classic word vectors to modern large-model embeddings) across 7 STS datasets and compared three measures: decos (a baseline), cosine, and recos. They used Spearman correlation, which checks how well the ranking of similarities from a method matches the ranking given by humans.
Key results:
- Across 77 tests (11 models × 7 datasets), recos beat cosine in 71 cases, tied in 5, and lost in 1. The average improvement was small but steady.
- The gains were biggest for certain modern or specialized models (for example, CLIP-ViT, DPR, SPECTER), suggesting these complex embeddings contain ordering patterns that cosine misses.
- Even when vectors are normalized to the same length (a common step), recos stays different and useful because it looks at ordering, while cosine and another baseline become effectively the same.
Why this matters:
- Real semantic spaces are messy and often non-linear: the “shape” of meaning isn’t always a straight line. recos can capture “same order” patterns that cosine undervalues, making similarity scores better match what humans think is similar.
Implications and Impact
- Better search and retrieval: Systems that find similar texts (or images and captions) can rank results more like a human would, especially when the relationship is consistent but not strictly linear.
- Stronger tools for embeddings: As AI models get more complex, their vector spaces may have richer patterns. recos can pick up signals that cosine ignores.
- Practical trade-offs: recos is a bit slower due to sorting. For everyday use it’s fine; for massive, billion-scale systems, engineers may need faster approximations.
- Not a total replacement: Cosine is still fast and useful. The authors suggest using recos when you care about matching overall order or suspect non-linear relationships play a big role.
In short, this paper shows that looking beyond angles to also consider ordering can give more human-like similarity judgments—and offers a mathematically solid, easy-to-apply way to do it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list enumerates concrete gaps and unresolved questions that remain after this work, aimed at guiding future research.
- Formal properties of recos as a similarity function:
- Is
recossymmetric for all inputs (i.e.,recos(u, v) = recos(v, u)), given the denominator depends on sorting relative tou * v? - Can
recosbe converted into a distance that satisfies the metric axioms (non-negativity, identity of indiscernibles, symmetry, triangle inequality)? - Is
recosa positive-definite kernel, enabling use in kernel methods?
- Is
- Sensitivity, stability, and robustness:
- How sensitive is
recosto small perturbations in components that are close in value (tie or near-tie situations), where tiny noise can flip orderings? Quantify the impact and propose robust variants (e.g., soft-ranking, tie-aware smoothing). - Behavior near the excluded boundary: the paper omits
u * v = 0. What is the numerical and ranking stability ofrecoswhenu * vis close to zero in realistic high-dimensional settings (where many pairs cluster near orthogonality)? - Outlier and heavy-tail effects: does sorting-induced pairing of extreme components in the denominator make
recosbrittle or overly sensitive to a few large coordinates?
- How sensitive is
- Semantic interpretation and axis alignment:
- The denominator discards original coordinate alignment by re-pairing components post-sorting; what is the semantic meaning of order concordance in non-axis-aligned embeddings? Design controlled studies to determine when such re-pairing aligns with human semantics vs. when it injects artifacts.
- Establish conditions (anisotropy, norm distributions, component correlations) under which ordinal concordance is predictive of semantic similarity, and when it is not.
- Relation to rank-based statistics:
- Clarify the connection between
recosand rank correlations (Spearman’s ρ, Kendall’s τ) computed over vector components. Under what assumptions doesrecosreduce to or diverge from these measures, and can hybrid measures leverage both angular and rank information?
- Clarify the connection between
- Partial concordance modeling:
recossaturates at 1 under perfect ordinal concordance. How can it be extended to weight partial concordance (e.g., penalize specific discordant pairs more/less, top-k order agreement, quantile-level concordance) to better reflect graded similarity?
- Theoretical tightness and generalization of bounds:
- Are there even tighter or more informative normalizers than
|u^↑ * v^↕|for mixed-sign vectors, perhaps via majorization theory or Schur-convex functions? - Characterize expected
recosvalues for random vectors (analytic distribution) to enable calibration and significance testing.
- Are there even tighter or more informative normalizers than
- Normalization and preprocessing:
- Systematically study how common embedding post-processing steps (centering, whitening, anisotropy reduction, unit-norm normalization) interact with
recos. Does preprocessing amplify or diminishrecos’s advantages? - When embeddings are unit-normalized (where
cosanddecoscoincide), quantify precisely whyrecosmaintains distinct behavior and whether this difference consistently benefits downstream performance.
- Systematically study how common embedding post-processing steps (centering, whitening, anisotropy reduction, unit-norm normalization) interact with
- Bias and frequency effects:
- The introduction cites norm/frequency bias in cosine similarity; does
recosempirically mitigate these biases? Provide analyses stratified by token frequency, sentence length, and domain to verify.
- The introduction cites norm/frequency bias in cosine similarity; does
- Task coverage and generalization:
- Extend evaluation beyond STS to tasks where similarity is operational (retrieval, re-ranking, clustering, deduplication, paraphrase identification, NLI, cross-lingual matching). Quantify gains and identify domains where
recosunderperforms. - For CLIP and other multimodal models, assess image-text and text-image retrieval at scale, not just text-only STS correlations.
- Extend evaluation beyond STS to tasks where similarity is operational (retrieval, re-ranking, clustering, deduplication, paraphrase identification, NLI, cross-lingual matching). Quantify gains and identify domains where
- Negative similarities and calibration:
recosyields negative values for discordant vectors. How should negative scores be calibrated or transformed for tasks with non-negative labels (e.g., STS)? Compare linear vs. nonlinear mappings to [0, 1] and effects on correlation and ranking.
- Computational scalability and systems integration:
- Sorting introduces
O(d log d)overhead per comparison. Develop and benchmark practical approximations (partial sorting, quantization, bucketed ranks, top-k order-only) for billion-scale retrieval. - Investigate ANN integration strategies: precompute/store ascending and descending permutations per database vector, two-path dot products for sign-dependent denominators, and re-ranking pipelines. Quantify memory and latency trade-offs.
- Explore learned or adaptive indexing that exploits ordinal statistics to prune candidates before exact
recoscomputation.
- Sorting introduces
- Differentiable training objectives:
- If
recosis used in contrastive learning, how can the non-differentiable sorting be addressed? Evaluate soft-sorting (NeuralSort, Sinkhorn) or surrogate losses and measure whether training under ordinal-sensitive objectives improves representational quality.
- If
- Comparative baselines:
- Include stronger baselines beyond
cosanddecos: soft cosine, centered cosine, correlation-based measures, Tanimoto (for non-negative vectors), rank-based component measures, and recent norm-adjusted similarities. Determine whetherrecosremains superior.
- Include stronger baselines beyond
- Magnitude vs. order information:
recosmixes magnitude (numerator) and order (denominator). Analyze ablations that isolate magnitude-only, order-only, and their combinations, to understand which component drives gains in different models/domains.
- Dimensionality effects:
- How does performance and saturation behavior of
recosscale with dimensiond? Does high dimensionality increase the chance of strong ordinal concordance, potentially compressing score ranges? Provide synthetic and real-data studies across controlledd.
- How does performance and saturation behavior of
- Interpretability and calibration of score ranges:
- Investigate whether
recosproduces more ties or clustering near 1 (due to order-preserving structures) and whether this harms downstream ranking resolution. Propose calibration schemes (e.g., temperature scaling, isotonic regression) tailored torecos.
- Investigate whether
- Language and domain generalization:
- Current evaluations are primarily English STS. Test multilingual and domain-shift scenarios (biomedical, legal, code) to assess robustness of ordinal concordance signals across languages and specialized vocabularies.
- Reproducibility and variance sources:
- Report sensitivity of
recosimprovements to model versions, random seeds, and minor pre-processing changes (tokenization, casing). Provide confidence intervals per setting to judge practical significance of the modest average gains (~0.29 points).
- Report sensitivity of
- Security and fairness:
- Examine whether emphasizing ordinal concordance inadvertently amplifies spurious correlations or protected-attribute signals in embeddings. Conduct fairness audits and adversarial robustness tests.
- Extensions of the inequality chain:
- Explore parametric families that interpolate between
cosandrecos(e.g., mixing aligned and order-based denominators) to trade off efficiency and capture range, and tune to specific tasks.
- Explore parametric families that interpolate between
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, leveraging the paper’s findings that recos is a mathematically principled and empirically stronger alternative to cosine similarity for many embedding models, with manageable computational overhead when applied in re-ranking stages.
- Re-ranking in semantic search and Retrieval-Augmented Generation (RAG)
- Sectors: software, enterprise search, knowledge management
- Workflow: Use cosine or ANN/dot-product to retrieve top-k candidates; apply recos to re-rank those k items before returning results or feeding them to a generator.
- Tools/Products: “recos re-ranker” plugin for FAISS/Milvus/Pinecone/Weaviate; adapters in Elastic/OpenSearch vector search; RAG middleware (LangChain/LlamaIndex) with recos scoring.
- Assumptions/Dependencies: Sorting adds O(d log d) per query-document pair; feasible for k ≈ 50–200; recos yields modest but consistent gains on STS-like relevance without index changes; ensure robust handling when u·v = 0 (recos = 0).
- Cross-modal image–text retrieval (CLIP and similar models)
- Sectors: media platforms, e-commerce visual search, robotics (vision-language)
- Workflow: For CLIP-ViT embeddings, use recos to re-rank candidate images for a text query (or text for an image query), improving alignment with human judgments, especially in non-linear representation regimes.
- Tools/Products: Photo and video search, product search by text description, studio asset management systems.
- Assumptions/Dependencies: Gains were largest for CLIP-ViT in the paper; the sorting overhead is acceptable for k re-ranking; model embeddings should remain unchanged.
- Paraphrase mining, near-duplicate detection, and content moderation
- Sectors: social media, legal, enterprise content, education
- Workflow: Cluster/score candidate pairs with cosine or locality-sensitive hashing; apply recos to refine similarity decisions, reducing false negatives where relationships are nonlinear but order-preserving.
- Tools/Products: Duplicate document cleaners, paraphrase detectors, moderation pipelines that flag near-duplicates.
- Assumptions/Dependencies: Use recos as a second-pass filter to keep latency in check; tie-breaking with traditional signals (metadata, timestamps) as needed.
- FAQ matching, intent classification, and customer support triage
- Sectors: customer support, SaaS, e-commerce
- Workflow: For a user query, retrieve potential FAQs/intents via cosine; re-rank with recos; return top answer or route to agent/automation.
- Tools/Products: Helpdesk assistants, chatbot retrieval layers, contact center routing.
- Assumptions/Dependencies: Recency or domain constraints may still require business rules; recos adds small latency per candidate.
- Scientific and technical literature search
- Sectors: academia, R&D, healthcare (SPECTER-type embeddings), legal
- Workflow: Use recos re-ranking over top-k papers retrieved with domain embeddings (e.g., SPECTER) to better surface conceptually aligned works that aren’t linearly similar.
- Tools/Products: Research discovery portals, EHR-linked clinical guideline search, patent prior-art search.
- Assumptions/Dependencies: Evidence in the paper shows larger gains for specialized embeddings (DPR, SPECTER); domain evaluation recommended.
- Productivity search (email, notes, documents)
- Sectors: consumer apps, enterprise productivity
- Workflow: Index user content with modern embeddings; re-rank search results with recos to capture nonlinear concordance (e.g., stylistic or structural signals).
- Tools/Products: Note apps, smart inboxes, desktop search, personal knowledge bases.
- Assumptions/Dependencies: Client-side re-ranking is feasible at typical embedding sizes; privacy-safe local computation needed for on-device use.
- Recommendation systems (content, learning resources)
- Sectors: media streaming, edtech
- Workflow: Candidate generation via standard nearest neighbor; re-rank candidates with recos to capture ordinal structure in embeddings that reflects user taste beyond strict angular similarity.
- Tools/Products: Next-video/article recommendation; course/practice question suggestion.
- Assumptions/Dependencies: Online serving latency constraints require using recos only for small candidate sets; combine with collaborative signals.
- Domain-specific retrieval (medical notes, incident logs, maintenance records)
- Sectors: healthcare, energy, manufacturing
- Workflow: Retrieve similar cases/notes based on embeddings; apply recos re-ranking to detect relevant precedents with monotonic but nonlinear similarities (e.g., symptom clusters, fault signatures).
- Tools/Products: Clinical decision support, incident resolution assistants, maintenance knowledge bases.
- Assumptions/Dependencies: Domain validation required; ensure safe deployment with human-in-the-loop for critical decisions.
Long-Term Applications
Below are forward-looking applications that require further research, optimization, or scaling to realize.
- Native recos integration in contrastive learning objectives
- Sectors: AI/ML model training across domains
- Workflow: Replace or augment cosine-based losses with recos-informed losses to encourage ordinal concordance during training; potentially improve representation quality for non-linear semantic structures.
- Tools/Products: Embedding model training libraries; fine-tuning recipes for CLIP/DPR/BGE-like models.
- Assumptions/Dependencies: Differentiable approximations to sorting (e.g., soft sorting) or surrogate objectives; empirical evaluation across tasks; stability/efficiency concerns.
- Approximate/accelerated recos at billion scale
- Sectors: web-scale search, ads, social platforms
- Workflow: Develop partial-sorting, quantization, or sketch-based approximations; GPU/ASIC kernels for fast sorted dot products; integrate recos into ANN indices or as a fast re-ranker with bounded latency.
- Tools/Products: FAISS/Milvus plugins; hardware-accelerated similarity services.
- Assumptions/Dependencies: Algorithmic innovation to reduce O(d log d) cost; accuracy–speed trade-off studies; infrastructure changes.
- Recos-based clustering and graph community detection
- Sectors: social network analysis, topic discovery, threat intelligence
- Workflow: Define a distance (e.g., 1 − recos) and adapt clustering/graph algorithms to ordinal-concordance similarity; potentially uncover communities missed by angular-only metrics.
- Tools/Products: Topic clustering, fraud-ring detection, community discovery dashboards.
- Assumptions/Dependencies: Theoretical work on metric properties (triangle inequality), stability of clusters, and algorithm convergence.
- Fairness and norm-bias mitigation in embedding-based systems
- Sectors: policy, compliance, HR, lending
- Workflow: Evaluate whether recos reduces frequency/norm-based biases seen with cosine; integrate recos into fairness audits and bias-corrected retrieval pipelines.
- Tools/Products: Bias analysis toolkits; compliance-grade retrieval solutions.
- Assumptions/Dependencies: Domain-specific fairness studies required; bias reduction not proven for all cases; governance and documentation needed.
- Multilingual and cross-domain retrieval robustness
- Sectors: global search platforms, localization services
- Workflow: Use recos to bridge nonlinear semantic relationships in cross-lingual embeddings, improving retrieval where angular similarity underperforms.
- Tools/Products: Multilingual search engines, translation memory retrieval.
- Assumptions/Dependencies: Empirical validation across languages; careful handling of zero or near-zero dot-products; performance vs. latency trade-offs.
- Robotic instruction grounding and task retrieval
- Sectors: robotics, industrial automation
- Workflow: Align natural language instructions with sensor or scene embeddings; use recos to capture ordinal concordance across modalities for better task matching.
- Tools/Products: Instruction-to-scene matchers, pick-and-place planners.
- Assumptions/Dependencies: Domain datasets and benchmarks; integration with perception stacks; safety validation.
- Legal and regulatory research and drafting support
- Sectors: public policy, legal tech
- Workflow: Apply recos in legal doc retrieval and precedent matching to surface semantically aligned but stylistically different documents; assist drafting via RAG.
- Tools/Products: Regulatory search portals, brief-writing assistants.
- Assumptions/Dependencies: Human review and provenance tracking; controlled deployments in sensitive contexts.
- Standardization and ecosystem development
- Sectors: software/tooling, academia
- Workflow: Create open-source libraries, benchmarks, and best practices for recos (APIs, datasets beyond STS); promote standardized evaluation across domains.
- Tools/Products: “OrdinalSim” SDKs; reference benchmarks and leaderboards.
- Assumptions/Dependencies: Community adoption; reproducibility infrastructure; governance for versioning and metrics.
- Personalized assistants and on-device search acceleration
- Sectors: consumer devices, privacy-preserving AI
- Workflow: Optimize recos for edge hardware (mobile/IoT) with small d, enabling privacy-preserving local re-ranking in note/email/photo search.
- Tools/Products: Mobile SDKs for recos; integrated personal assistants.
- Assumptions/Dependencies: Efficient sorting kernels and memory constraints; battery/performance profiling.
- Risk, fraud, and anomaly detection with ordinal signals
- Sectors: finance, cybersecurity, compliance
- Workflow: Use recos on embeddings of narratives, tickets, or event sequences to identify ordinal-consistent anomalies that cosine underestimates.
- Tools/Products: Case similarity triage, AML/KYC narrative matching, SOC alert deduplication.
- Assumptions/Dependencies: Domain-specific labeling and model tuning; pipeline latency considerations; evaluation on precision/recall trade-offs.
Notes on feasibility across applications:
- Recos adds O(d log d) complexity per pair due to sorting; practical today as a top-k re-ranker, not as a first-stage nearest neighbor metric.
- Gains reported are modest but consistent on STS benchmarks; largest for specialized embeddings (CLIP-ViT, DPR, SPECTER). Domain validation is advised before broad rollout.
- For unit-normalized embeddings, decos equals cosine, while recos remains distinct; recos can therefore improve normalized workflows without changing embedding magnitudes.
- The metric excludes pathological u·v = 0 cases; implementations should still handle zero dot-products gracefully (return 0).
- Fairness and bias claims require dedicated studies; the ordinal nature of recos may help in some cases but is not a universal fix.
Glossary
- Benjamini–Hochberg correction: A multiple-testing procedure that controls the false discovery rate when performing many statistical tests. "All these statistical tests remained significant after Benjamini-Hochberg correction for multiple comparisons (all adjusted )."
- Binomial test: A nonparametric test that evaluates whether the observed number of successes differs from what would be expected by chance under a binomial model. "yielding a win rate of 98.6\% (binomial test: )."
- Capture range: The set of relationship types a similarity metric can recognize as highly similar; a wider capture range means the metric is more permissive in assigning high similarity. "determines the sensitivity and scopeâor capture rangeâof the resulting similarity measure."
- Cauchy–Schwarz inequality: A fundamental result in linear algebra that bounds the absolute dot product by the product of vector norms. "The Cauchy--Schwarz inequality states that"
- Concordant pair: A pair of component indices for which the differences in two vectors have the same sign, indicating agreement in ordering. "the non-existence of any concordant pair "
- Contrastive learning: A representation learning paradigm that pulls similar items together and pushes dissimilar items apart, often via a contrastive loss. "its integration into contrastive learning objectives"
- Cross-modal alignment: Learning or measuring correspondence between different data modalities (e.g., text and images). "and cross-modal alignment"
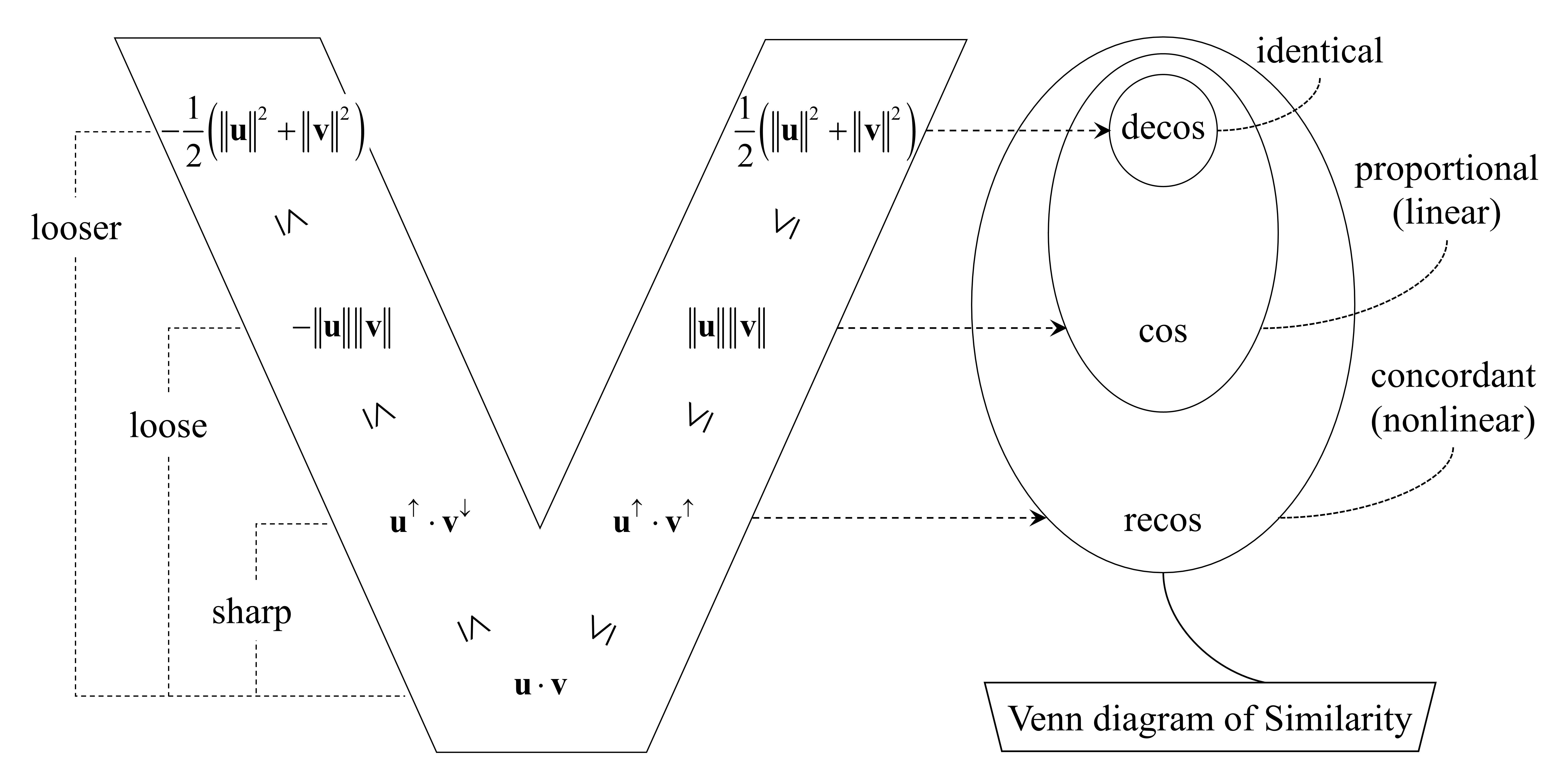
- Degenerated Cosine Similarity (decos): A cosine-like similarity that normalizes by the average of squared norms, emphasizing near-identity relationships. "The Degenerated Cosine Similarity (), based on the inequality of arithmetic and quadratic means, is defined as:"
- Discordant pair: A pair of component indices for which the differences in two vectors have opposite signs, indicating disagreement in ordering. "the non-existence of any discordant pair "
- Discordant vectors: Vectors whose component orderings are reversed relative to each other across all pairs. "They are said to be discordant vectors if they are oppositely ordered;"
- Fixed effect: In mixed-effects models, a parameter that is constant across groups and is of primary interest (e.g., method effect). "with Method as a fixed effect"
- Inequality of arithmetic and quadratic means: The statement that the quadratic mean (RMS) is at least as large as the arithmetic mean; used here to bound the dot product. "based on the inequality of arithmetic and quadratic means"
- Leave-one-dataset-out cross-validation: An evaluation procedure that withholds one dataset at a time for testing while using the others for model fitting/analysis. "The leave-one-dataset-out cross-validation analysis further confirmed the robustness of our findings"
- Linear mixed-effects model: A regression model combining fixed effects and random effects to account for grouped or hierarchical data. "we employed a linear mixed-effects model"
- Measure-zero event: An event with probability zero in a continuous space; negligible in a measure-theoretic sense. "constitutes a measure-zero event"
- Monotonic bijection: A one-to-one, onto mapping that preserves order (strictly increasing or decreasing). "related by a strictly monotonic bijection:"
- Ordinal concordance: Agreement in the rank ordering of vector components, regardless of their magnitudes. "The essential characteristic of similarity is ordinal concordance rather than metric alignment."
- Permutation matrix: A binary square matrix that permutes vector components when multiplied, reordering entries. "there exists a scalar and a permutation matrix such that"
- Pseudo-median: A robust, nonparametric estimator of central tendency (e.g., the Hodges–Lehmann estimator). "95\% CI for pseudo-median "
- Random intercepts: Random-effect terms that allow each group (e.g., model or dataset) to have its own baseline level in a mixed-effects model. "and random intercepts for Model, Dataset, and their interaction."
- Rearrangement Inequality: A theorem stating that the sum of pairwise products is maximized when similarly ordered sequences are multiplied termwise. "based on the Rearrangement Inequality"
- Rearrangement-inequality-based Cosine Similarity (recos): The proposed similarity metric that normalizes by the dot product of sorted components to capture ordinal concordance. "The Rearrangement-inequality-based Cosine Similarity () is defined as:"
- Retrieval-augmented generation: A method that augments a generative model with externally retrieved documents at inference time. "including retrieval-augmented generation"
- Saturation condition: The specific relationship under which a similarity metric attains its maximum value (typically 1). "saturation condition for achieving a maximum score of 1."
- Semantic Textual Similarity (STS): Benchmarks where human-annotated scores rate the semantic equivalence of sentence pairs. "Semantic Textual Similarity (STS) benchmarks"
- Shapiro–Wilk test: A statistical test for normality of a sample distribution. "Shapiro-Wilk test: , "
- Sign test: A nonparametric test using the signs of paired differences to evaluate a median or paired effect. "we performed a sign test to assess the consistency of improvements."
- Spearman's rank correlation (rho): A nonparametric measure of monotonic association between two variables based on rank ordering. "Performance is measured by Spearman's rank correlation "
- Tanimoto similarity: A similarity coefficient equivalent to the Jaccard index for real-valued vectors. "The Tanimoto similarity is defined as:"
- Universal text embeddings: General-purpose text representations designed to transfer across tasks and domains. "universal text embeddings (BGE, E5, GTE, SPECTER, CLIP-ViT)."
- Vector Ordering: Sorting a vector’s components (ascending/descending) to analyze order-based relationships between vectors. "Definition [Vector Ordering]"
- Wilcoxon signed-rank test: A nonparametric paired-sample test that accounts for both the sign and magnitude of differences. "The Wilcoxon signed-rank test revealed a highly significant improvement"
Collections
Sign up for free to add this paper to one or more collections.