Wid3R: Wide Field-of-View 3D Reconstruction via Camera Model Conditioning
Abstract: We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models. Prior methods typically assume that input images are rectified or captured with pinhole cameras, since both their architectures and training datasets are tailored to perspective images only. These assumptions limit their applicability in real-world scenarios that use fisheye or panoramic cameras and often require careful calibration and undistortion. In contrast, Wid3R is a generalizable multi-view 3D estimation method that can model wide field-of-view camera types. Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction. Furthermore, Wid3R is the first multi-view foundation model to support feed-forward 3D reconstruction directly from 360 imagery. It demonstrates strong zero-shot robustness and consistently outperforms prior methods, achieving improvements of up to +77.33 on Stanford2D3D.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces Wid3R, a new AI model that turns pictures into 3D models. What makes it special is that it works with different kinds of cameras, including normal cameras, fisheye lenses (which curve the image), and full 360° cameras (which capture everything around you). It builds 3D scenes quickly in a single pass and doesn’t need tricky, time-consuming steps like undistorting images or carefully calibrating each camera first.
The main goal and questions
The researchers wanted to know:
- Can one model handle many camera types, even those with strong distortion (like fisheye and 360°)?
- Can we skip manual camera calibration and still get accurate 3D results?
- Can we reconstruct 3D scenes directly and fast from multiple images (multi-view), not just single photos?
How does Wid3R work? (Explained simply)
Think of a camera image like a grid of tiny windows (pixels). Each pixel looks out into the world along an invisible straight line called a ray—like a tiny flashlight beam pointing from the camera into the scene. Wid3R builds 3D by predicting two things for every pixel:
- The direction the ray points (its angle),
- How far along that ray the surface is (its distance).
To make this work across different cameras, Wid3R uses three key ideas:
1) Ray-based thinking instead of “plain depth”
- Many older methods guess a depth value per pixel as if using a simple “pinhole” camera. That breaks when the camera bends the image (fisheye) or wraps it around a sphere (360°).
- Wid3R treats each pixel as a ray. It predicts the ray’s direction and then how far away the 3D point is along that ray. This naturally fits all camera types.
2) Spherical harmonics for ray directions
- Spherical harmonics are like a set of smooth wave patterns on a sphere. By mixing these patterns, you can describe any direction on the sphere.
- Wid3R uses spherical harmonics to encode ray directions. This is a compact, flexible way to represent directions for cameras with wide fields of view.
3) A “camera model token” to adapt to each camera
- The camera model token is a small learned hint the network receives that says, “This image came from a normal camera,” or “This one is fisheye,” or “This one is 360°.”
- It’s like giving the model a short note about the lens so it can adjust its predictions to the right kind of distortion.
Extra design choices that help
- Local coordinates and shared scale: Wid3R predicts 3D points in each camera’s own coordinate system (so it doesn’t break when images have little overlap). Later, it aligns them by finding a single common “zoom level” (scale) across views.
- Feed-forward reconstruction: Instead of running many slow steps (like traditional structure-from-motion pipelines), Wid3R does one fast pass to get 3D points and camera poses.
- Diverse training and smart augmentations: The model is trained on many datasets (normal, fisheye, 360°) and uses tricks like converting normal photos to fisheye style and rotating 360° images to see more variety.
What did they discover, and why is it important?
Wid3R consistently outperforms previous methods when images are distorted (fisheye) or panoramic (360°). Here’s what stood out:
- It works across camera types: Unlike many earlier models that only handle normal lenses, Wid3R supports pinhole, fisheye, and 360° cameras in one framework.
- Better camera pose estimation: It more accurately figures out where the camera was and which way it was pointing, beating strong baselines on several fisheye and 360° datasets.
- More accurate 3D points: It produces cleaner, more complete point clouds (the 3D points that form the scene), with higher geometric quality on tough datasets like ScanNet++, Matterport3D, and Stanford2D3D.
- Much faster mapping: On large indoor scenes, Wid3R builds a 3D map in about 3 seconds, while traditional methods can take minutes, because those rely on heavy matching and optimization steps.
- Strong “zero-shot” robustness: It performs well even on new datasets it wasn’t trained on, including 360° scenes with little training data.
- Good single-view 360° depth: Even though Wid3R is designed for multi-view, it still gives competitive depth from just one panoramic image.
These results matter because many real-world systems (robots, self-driving cars, AR/VR headsets, and mapping tools) use wide field-of-view cameras to see more with fewer blind spots. A model that “just works” on these cameras, without painful calibration or slow processing, is a big deal.
What could this change in the future?
Wid3R shows that we can build a single, fast 3D foundation model that respects the true shape of different cameras. This could:
- Make robots and drones map places more reliably and quickly.
- Improve AR/VR experiences by turning 360° or fisheye footage into accurate 3D environments on the fly.
- Reduce engineering time: less camera calibration and fewer special-case fixes.
- Encourage new apps that mix camera types (normal + fisheye + 360°) without breaking the 3D pipeline.
In short, Wid3R helps computers “see in 3D” no matter which camera you use, and does it fast. That’s a big step toward practical, plug-and-play 3D understanding in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what the paper leaves uncertain or unexplored. Each point is framed to be actionable for future research.
- Inference-time camera model selection: The paper assumes an “appropriate camera model token” is selected, but does not specify how to automatically infer the token from images or metadata. How to robustly classify camera type (and its parameters) and select/compose the right token at inference remains open.
- Discrete vs. continuous camera embeddings: Camera tokens appear to encode coarse categories (pinhole, fisheye, spherical). There is no mechanism for continuous conditioning on intrinsics/distortion parameters within each category (e.g., varying fisheye models, FOV, principal point, distortion coefficients). Investigate continuous or parameterized camera embeddings and their generalization to unseen intrinsics.
- Generalization to unseen/non-central camera systems: The approach implicitly assumes central projection. Non-central and catadioptric systems (mirror-based, multi-camera rigs, dual-fisheye stitching) are not addressed; assess whether the SH ray formulation and token conditioning can represent these cameras or needs extensions.
- Missing details of SH-based ray computation: The paper omits the explicit formula mapping predicted SH coefficients to ray directions (equation placeholder). This prevents exact reproduction and analysis. Provide the full parameterization, degree/order selection, and normalization used.
- Choice of spherical harmonics order and trade-offs: The maximum SH degree/order, its effect on reconstruction accuracy, angular bias near poles, and computational/memory cost are not ablated. Quantify the accuracy–efficiency trade-offs of SH order, and when SH approximation breaks down for extreme distortions.
- Physical consistency of predicted ray fields: There is no constraint ensuring all rays share a single optical center (central projection) or enforcing integrability/smoothness of the ray field. Develop regularizers or architectural constraints to enforce physically consistent camera models in the predicted ray fields.
- Metric scale recovery at test time: The training uses a single optimal scale factor s* relative to ground truth. How is absolute (metric) scale recovered at inference without ground-truth supervision? Explore scale recovery via priors (human height, gravity cues), IMU/barometer fusion, or stereo baseline constraints.
- Use and calibration of uncertainty: The network predicts per-pixel radial uncertainty but does not evaluate its calibration (e.g., NLL, ECE) or use it to weight pose/point fusion. Study whether uncertainty improves pose estimation, alignment, or outlier rejection, and calibrate it properly.
- Robustness to camera token mis-specification: Effects of wrong or ambiguous camera tokens are not evaluated. Quantify degradation and propose token inference/fallback strategies (e.g., joint token prediction, mixture-of-experts, model selection confidence).
- Reliance on ground-truth intrinsics to train rays: The method requires ground-truth rays/angles during training. How robust is it to calibration errors or missing intrinsics, and can it learn rays self-supervised from multi-view constraints? Evaluate sensitivity to noisy/missing calibration data.
- Minimal overlap requirements and failure modes: The paper claims robustness to limited view overlap but does not quantify minimal overlap for accurate pose/point estimation. Characterize failure modes under no-overlap, repetitive textures, specular/transparent surfaces, and extreme baselines.
- Global consistency, loop closure, and scalability: Reconstruction is demonstrated on small batches (2–24 frames). There is no evaluation of scalability to hundreds/thousands of views, streaming/online processing, loop closure, drift management, or building globally consistent maps without post-optimization.
- Post-alignment vs. “feed-forward” claim: Point maps are aligned using Umeyama, MoGe optimal alignment, and ICP, which are optimization steps at test time. Explore architectures and training objectives that produce globally consistent reconstructions and poses without post-hoc alignment.
- ERP seam and spherical feature handling: DINO-based features are not spherical-aware; ERP seams and pole distortions are not addressed. Investigate spherical CNNs/transformers or seam-aware feature normalization to reduce artifacts near seams/poles.
- Dynamic scenes and rolling shutter: The method is evaluated on mostly static datasets; robustness to moving objects, rolling-shutter distortion, fast motion, and motion blur is unknown. Introduce motion-aware modeling or temporal constraints.
- Outdoor 360° and diverse environments: Evaluations focus on indoor fisheye/360 datasets. Assess generalization to outdoor panoramic/fisheye settings (wide illumination ranges, long-range geometry), and domain adaptation strategies.
- Camera augmentation fidelity and bias: The fisheye augmentation pipeline (unproject–reproject with softmax splatting) may introduce sampling artifacts and biases. Quantify how augmentation fidelity affects performance and whether it harms true fisheye generalization.
- Edge-device efficiency and resource scaling: Inference is reported on high-end GPUs (A6000/H100) with limited frame counts. Characterize memory/runtime on edge devices and propose efficient variants (e.g., lightweight backbones, sparse rays, quantization).
- Impact on perspective cameras: While Wid3R supports wide-FOV cameras, its performance on standard pinhole benchmarks (e.g., ETH3D, Tanks & Temples) and potential regressions vs. prior foundation models are not reported. Benchmark to ensure no trade-off in perspective performance.
- Token granularity within fisheye families: Different fisheye models (Kannala–Brandt, Mei, UCM, Double Sphere) have distinct distortions. Evaluate whether one “fisheye” token suffices or per-model tokens/continuous embeddings are required.
- Long-sequence sampling strategy at inference: The training uses distance-based sampling to ensure overlap; inference-time sampling or selection policies for large scenes are not described. Develop principled view selection to balance coverage and overlap.
- Quantitative uncertainty in ray-prediction loss: The asymmetric ray loss hyperparameters (α, β) are not justified or ablated. Study sensitivity and alternatives (e.g., angular geodesic losses on S2) that better reflect spherical geometry.
- Reproducibility gaps in equations and implementation: Several equations appear malformed or incomplete (e.g., SH ray mapping, loss definitions). Provide corrected formulas, code for SH basis construction, and exact training schedules to enable reproduction.
- Data imbalance and augmentation strategies for 360°: With <1% 360° data in training, broader strategies (synthetic 360° generation, curriculum learning, domain mixing) are not explored. Systematically study how different mixes and synthetic pipelines affect 360° performance.
- Use of uncertainty/geometry in downstream tasks: How Wid3R’s outputs (points, poses, uncertainties) can be leveraged for SLAM, neural rendering initialization, or map compression is not explored. Evaluate downstream benefits and integration protocols.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed today using Wid3R’s distortion-aware, feed-forward multi-view 3D reconstruction for pinhole, fisheye, and 360° cameras.
- Distortion-free multi-camera mapping and localization
- Sectors: robotics, autonomous navigation, security/surveillance, mobile mapping
- What: Replace undistortion/calibration-heavy preprocessing with direct, feed-forward reconstruction and pose estimation across heterogeneous camera rigs (pinhole + fisheye + 360°).
- Tools/workflows: ROS/SLAM module that ingests raw wide-FOV frames; Wid3R-based pose + point-map generator; optional ICP for refinement; drop-in initializer for SfM pipelines; real-time robot localization on a GPU-equipped edge device.
- Assumptions/dependencies: Correct camera model token selection; sufficient view overlap; GPU inference; scale alignment in downstream pipeline (Umeyama/MoGe/ICP).
- Rapid 3D mapping for facility management and real estate
- Sectors: construction, real estate, digital twins
- What: Generate room-scale point clouds and camera poses in seconds from 360° tours or fisheye captures (e.g., faster Matterport-like workflows).
- Tools/workflows: “Scan-to-PointCloud” CLI that outputs poses + point maps; floorplan extraction; asset inventory; integration with BIM/digital twin platforms.
- Assumptions/dependencies: Multi-view coverage of rooms; modest GPU; domain adaptation may be needed for very reflective/transparent interiors.
- Pre-initialization of NeRF and MVS pipelines for wide-FOV inputs
- Sectors: software, VFX, research
- What: Provide high-quality camera poses and dense point maps for fisheye/360° footage to accelerate NeRF training and multi-view stereo reconstruction.
- Tools/workflows: Wid3R “Pose & Points” pre-init stage before NeRF; distortion-aware input handling; export to common formats (COLMAP JSON, PLY).
- Assumptions/dependencies: Correct token conditioning; moderate scene overlap; potential fine-tuning for studio lighting.
- Indoor AR/VR scene reconstruction from panoramas
- Sectors: AR/VR, gaming
- What: Convert single or few 360° captures into depth + point maps to enable occlusion, spatial anchors, and scene understanding for AR experiences.
- Tools/workflows: On-device or cloud panoramic depth estimation; scene mesh for AR occlusion; integration in Unity/Unreal.
- Assumptions/dependencies: Single-view results are available but multi-view improves quality; hardware acceleration recommended.
- Dashcam and surround-view perception for driver assistance
- Sectors: automotive
- What: Use fisheye/surround cameras to reconstruct the local 3D environment feed-forward, reducing reliance on camera-specific calibration.
- Tools/workflows: Perception stack module that outputs point maps + poses; faster scene understanding around the vehicle; integration with sensor fusion.
- Assumptions/dependencies: Real-time GPU; robust handling of motion blur; multi-view coverage around vehicle.
- Disaster response and rapid scene assessment
- Sectors: public safety, civil protection
- What: Deploy 360° cameras or drones with fisheye lenses to quickly reconstruct damaged sites (collapsed buildings, flooding) for situational awareness.
- Tools/workflows: Field kit with Wid3R inference; upload frames and receive point map + pose in seconds; generate occupancy maps for teams.
- Assumptions/dependencies: Connectivity/GPU; minimal calibration; domain shifts (smoke, debris) may require model adaptation.
- Security and forensics with dome cameras
- Sectors: security/surveillance
- What: Reconstruct scenes from 360° dome cameras to analyze incidents, trajectories, and spatial layouts without undistortion complexities.
- Tools/workflows: Forensics reconstruction suite; multi-camera cross-registration; temporal scene change detection using uncertainty maps.
- Assumptions/dependencies: Synchronized capture preferred; privacy compliance; viewpoint coverage.
- Industrial inspection in confined or hazardous spaces
- Sectors: energy, manufacturing, utilities
- What: Feed-forward mapping with fisheye/360° cameras in tanks, tunnels, or plants to reduce inspection time and limit human exposure.
- Tools/workflows: Inspection bot pipeline; Wid3R for geometry + pose; annotate defects on point cloud; export to maintenance systems.
- Assumptions/dependencies: Lighting aids; motion stabilization; domain-specific fine-tuning for reflective or metallic surfaces.
- Academic benchmarking and curriculum development
- Sectors: academia
- What: Use Wid3R to study distortion-aware multi-view geometry, spherical harmonics ray representations, and camera-token conditioning across datasets.
- Tools/workflows: Teaching modules; reproducible benchmarks on fisheye/360 datasets; ablation tools for camera token and training composition.
- Assumptions/dependencies: Access to datasets and GPUs; familiarity with SH/ray-based formulations.
- Home scanning and DIY floorplans
- Sectors: daily life
- What: Consumer 360° cameras or fisheye lenses produce quick 3D reconstructions for furnishing, measurement, or listing improvements.
- Tools/workflows: Mobile app: capture → Wid3R inference → room mesh/point cloud → floorplan export.
- Assumptions/dependencies: Device GPU or cloud; adequate captures per room; privacy and data retention choices.
- Heterogeneous camera networks in buildings
- Sectors: smart buildings, IoT
- What: Unify pinhole CCTV + fisheye + 360° cameras into one geometric model for path planning (e.g., cleaning robots) and analytics.
- Tools/workflows: Wid3R service that standardizes geometry across camera types; shared coordinate frames for facility analytics.
- Assumptions/dependencies: Camera token management; time synchronization; scale alignment.
Long-Term Applications
The following use cases require additional research, scaling, domain adaptation, deployment engineering, or standards to reach production reliability.
- Real-time, end-to-end SLAM replacement on edge devices
- Sectors: robotics, AR/VR, automotive
- What: A fully feed-forward SLAM stack leveraging Wid3R’s ray-space modeling to eliminate iterative optimization and dense matching.
- Tools/workflows: On-device transformer accelerators; unified uncertainty-aware mapping; direct loop closure from pose headers.
- Assumptions/dependencies: Hardware acceleration; robust handling of dynamics and extreme motion; long-term drift mitigation; cross-domain generalization.
- Multi-robot collaborative mapping with heterogeneous cameras
- Sectors: robotics, logistics, defense
- What: Shared 3D maps built by drones/UGVs using different camera types, with camera-token conditioning enabling seamless fusion.
- Tools/workflows: Distributed mapping service; token negotiation protocols; global alignment with minimal bandwidth.
- Assumptions/dependencies: Standardized camera token metadata; synchronization; resilience to domain shifts; secure communication.
- Distortion-aware NeRF/GS pipelines for production VFX
- Sectors: film/VFX, media
- What: NeRF/gaussian-splatting builders that natively ingest fisheye/360° footage without ad-hoc rectification, using Wid3R preconditioning and ray-space fusion.
- Tools/workflows: Studio-grade integration; scene-scale consistency; uncertainty-aware sample weighting.
- Assumptions/dependencies: Tooling maturity; compatibility with render farms; specialized fine-tuning for complex lighting and reflections.
- World-scale AR Cloud from crowd-sourced wide-FOV cameras
- Sectors: AR/VR, mapping platforms
- What: Persistent, global 3D maps constructed from consumer 360° and fisheye captures for spatial services (navigation, discovery).
- Tools/workflows: Upload → Wid3R pose/point → global alignment; map versioning; scene change detection via uncertainty channels.
- Assumptions/dependencies: Privacy and geofencing policies; storage/compute scale; robust quality control; adversarial input handling.
- Autonomous driving perception unification across camera models
- Sectors: automotive
- What: Replace camera-specific depth/pose modules with a unified distortion-aware geometry estimator for surround-view (fisheye + pinhole) stacks.
- Tools/workflows: Safety-certified perception; simulation-to-real bridging; integration with planning/control.
- Assumptions/dependencies: Certification and validation; extreme weather/night robustness; integration with LiDAR/radar fusion.
- Healthcare imagery reconstruction (e.g., endoscopic fisheye)
- Sectors: healthcare
- What: Distortion-aware reconstruction for minimally invasive procedures to improve 3D understanding of anatomy from wide-FOV optics.
- Tools/workflows: OR-ready inference; uncertainty gating to flag unreliable regions; surgical navigation overlays.
- Assumptions/dependencies: Clinical validation; domain adaptation; regulatory approval; sterile hardware integration.
- Underwater and aerial surveying with wide-FOV optics
- Sectors: environmental monitoring, marine, agriculture
- What: 3D mapping in oceans/fields using fisheye/360° cameras where calibration is impractical; habitat assessment and crop analysis.
- Tools/workflows: Drone/ROV payloads; Wid3R mapping; GIS integration.
- Assumptions/dependencies: Turbidity/motion blur robustness; GPS-denied localization strategies; domain-specific training.
- Standardization of camera model tokens and metadata
- Sectors: standards bodies, policy
- What: Define interoperable camera-token schemas (device class, lens profile, projection hints) so models can generalize across vendors.
- Tools/workflows: Metadata standards; device-side token provisioning; compliance tests.
- Assumptions/dependencies: Industry alignment; governance; backward compatibility.
- Regulatory guidance for rapid 3D assessment in emergencies
- Sectors: policy, public safety
- What: Guidelines for agencies to adopt 360° mapping with feed-forward models for faster damage assessment while managing privacy risks.
- Tools/workflows: Procurement templates; audit trails; consent workflows; data retention policies.
- Assumptions/dependencies: Legal frameworks; ethical safeguards; training for field teams.
- Consumer-grade “instant 3D” capture on smartphones
- Sectors: consumer tech
- What: On-device, low-latency reconstruction from fisheye adapters or multi-view panoramas for AR decorating, measurements, and sharing.
- Tools/workflows: Mobile accelerators; app SDKs; cloud fallback; integration with home design platforms.
- Assumptions/dependencies: Efficient model distillation; battery constraints; user guidance for capture quality.
- Continuous digital twin updates in large facilities
- Sectors: utilities, airports, campuses
- What: Nightly/weekly wide-FOV walk-throughs producing incremental updates to a master twin; anomaly detection via uncertainty deltas.
- Tools/workflows: Scheduling + capture guidance; Wid3R ingestion; change-log visualization.
- Assumptions/dependencies: Scalable storage/compute; alignment across time; worker training; safety protocols.
- Privacy-preserving, uncertainty-aware analytics on wide-FOV data
- Sectors: policy, AI safety
- What: Use Wid3R’s uncertainty outputs to mask or downweight sensitive regions while retaining geometric utility in analytics.
- Tools/workflows: Uncertainty-driven anonymization; compliance dashboards; risk scoring.
- Assumptions/dependencies: Reliable uncertainty calibration; stakeholder buy-in; evaluation metrics for privacy vs utility trade-offs.
Glossary
- Absolute Trajectory Error (ATE): A metric that measures the absolute difference between estimated and ground-truth camera trajectories over a sequence. "In addition, we report Absolute Trajectory Error (ATE), Relative Pose Error for translation (RPE trans), and Relative Pose Error for rotation (RPE rot) in Table~\ref{table:pose_distance}."
- affine-invariant: Unchanged under affine transformations (e.g., scaling, rotation, translation, shear), used to make geometry estimation robust. "while MoGe \cite{wang2025moge} proposes affine-invariant point map estimation coupled with optimal alignment to recover consistent geometric structure."
- Area Under the Curve (AUC): A scalar summary of performance across thresholds, computed as the area under an accuracy curve. "We further report the Area Under the Curve (AUC) of the threshold curve as a unified performance metric"
- azimuth: The horizontal angle around the vertical axis in spherical coordinates. "We apply rotation-based augmentation by randomly sampling the azimuth angle and the elevation angle , and rotating the image, depth and pose accordingly."
- bundle adjustment: Nonlinear optimization that jointly refines camera parameters and 3D structure to minimize reprojection error. "The estimated camera parameters and 3D structure are further refined through bundle adjustment \cite{Bundleadjustment}."
- canonical camera transformation: A normalization that maps different camera geometries into a standard form to enable metric depth estimation. "Metric3D \cite{yin2023metric3d} introduces a canonical camera transformation module that enables monocular metric depth estimation by normalizing camera geometry"
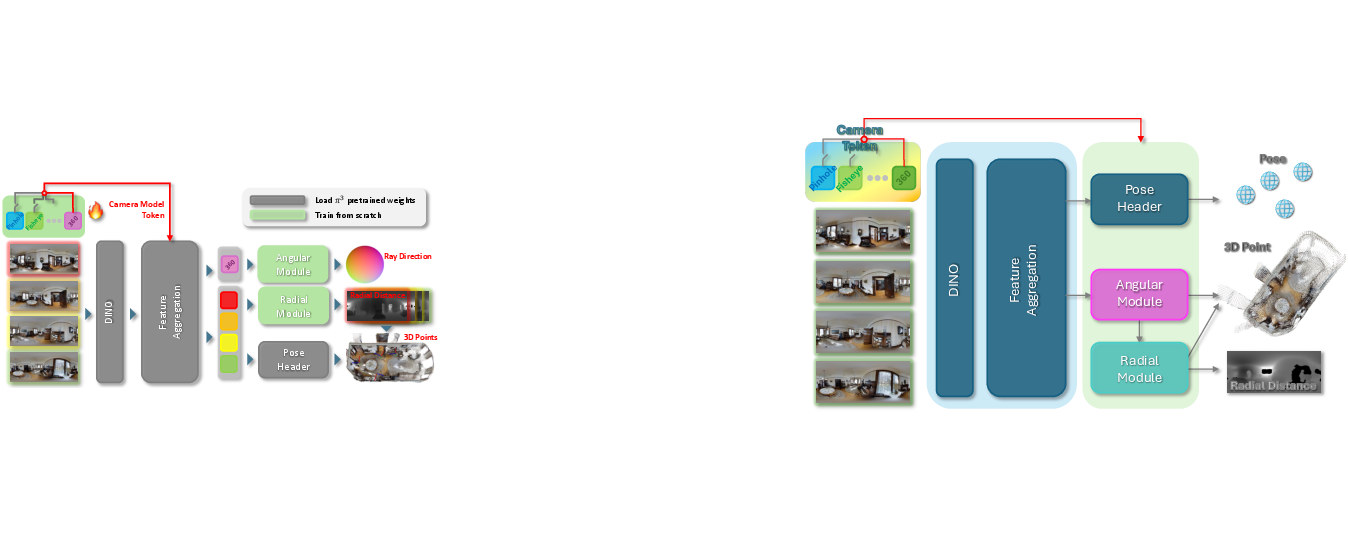
- camera model token: A trainable embedding that conditions the network on the specific camera’s projection and distortion characteristics. "In addition, we introduce a camera model token as a lightweight conditioning mechanism that enables the network to account for projection and distortion characteristics unique to each camera type."
- detector-free matching: Correspondence estimation without explicit keypoint detectors, often using dense or learned matching. "By leveraging detector-free matching \cite{jung2025edm} on spherical imagery, this approach extends SfM to wide field-of-view camera models."
- Double Sphere model: A parametric fisheye camera model that uses two virtual spheres to represent projection and distortion. "and the Double Sphere model \cite{usenko2018double}."
- equirectangular projection (ERP): A mapping that unwraps the sphere to a rectangle with uniform longitude-latitude sampling, used for 360° panoramas. "For equirectangular projection (ERP) images, we further exploit the fact that a single ERP image represents the full 360 viewing sphere \cite{jung2025edm}."
- feed-forward: Single-pass inference without iterative optimization at test time. "We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models."
- fisheye: An ultra-wide-angle lens/camera producing strong radial distortion to capture a very wide field of view. "Wid3R reconstructs wide field-of-view images in a feed-forward manner, supporting challenging camera models such as fisheye and 360 cameras."
- geodesic distance: The shortest-path distance on a manifold; for rotations, the minimal rotation angle between two orientations. "The rotation loss minimizes the geodesic distance between the predicted relative rotation $\hat{\mathbf{R}_{i \leftarrow j}$ and its ground truth counterpart ."
- Huber loss: A robust loss that is quadratic for small residuals and linear for large residuals to reduce outlier influence. "where denotes the Huber loss, which is used to reduce the influence of outliers."
- intrinsic parameters: Internal camera parameters (e.g., focal length, principal point, distortion) defining the imaging geometry. "Camera calibration plays a critical role in recovering 3D structure from the 2D image plane by estimating intrinsic parameters such as focal length, principal point, and lens distortion."
- Iterative Closest Point (ICP): An algorithm that aligns two point clouds by iteratively matching closest points and estimating the rigid transform. "and Iterative Closest Point."
- Kannala–Brandt model: A fisheye camera projection model based on polynomial functions of the incidence angle. "including the classical pinhole model, the KannalaâBrandt model \cite{kannala2006generic}, the Mei model \cite{mei2007single}, omnidirectional camera models \cite{scaramuzza2021omnidirectional}, the Unified Camera Model (UCM) \cite{geyer2000unifying,khomutenko2015enhanced}, and the Double Sphere model \cite{usenko2018double}."
- Mei model: A unified central catadioptric camera model suitable for fisheye/omnidirectional imaging. "including the classical pinhole model, the KannalaâBrandt model \cite{kannala2006generic}, the Mei model \cite{mei2007single}, omnidirectional camera models \cite{scaramuzza2021omnidirectional}, the Unified Camera Model (UCM) \cite{geyer2000unifying,khomutenko2015enhanced}, and the Double Sphere model \cite{usenko2018double}."
- multi-view stereo: Techniques to densify 3D reconstructions from multiple calibrated views by estimating per-pixel depth. "The resulting sparse reconstruction can subsequently be used as input for multi-view stereo \cite{furukawa2015multi,schonberger2016pixelwise} or neural rendering methods"
- Normal Consistency (N.C.): An evaluation metric that measures angular consistency between predicted and ground-truth surface normals. "Following \cite{wang2025continuous,wang2025pi}, we report Accuracy (Acc.), Completion (Comp.), and Normal Consistency (N.C.) as evaluation metrics."
- omnidirectional camera models: Camera models enabling very wide or full 360° fields of view, often via mirrors or special lenses. "omnidirectional camera models \cite{scaramuzza2021omnidirectional}"
- pencil of rays: The set of 3D rays from a camera center through all image pixels. "denotes the pencil of rays defined at each image location,"
- permutation-equivariant: A property where permuting inputs results in a corresponding permutation of outputs, ensuring order-agnostic processing. "we adopt a permutation-equivariant network design inspired by \cite{wang2025pi}, in which scene geometry is represented in per-view local coordinate frames rather than a shared global reference frame."
- pinhole camera model: The idealized projection model where rays pass through a single point onto an image plane. "These cameras introduce complex non-linear projection effects, and their imaging geometry deviates significantly from the pinhole model."
- pose header: A network head dedicated to predicting camera poses from learned features. "A pose header estimates camera poses, enabling the reconstruction of global 3D points."
- radial distance: The distance from the camera center to a point along the viewing ray. " corresponds to the radial distance along each ray"
- RANSAC: A robust estimator that fits models by sampling minimal sets and rejecting outliers. "Based on the established correspondences, two-view geometry is estimated using robust methods such as RANSAC \cite{RANSAC} to recover relative camera poses"
- ray-based representation: Modeling images as collections of rays to handle diverse camera projections within the network. "or by adopting ray-based formulations that implicitly capture projection effects within the network \cite{piccinelli2025unik3d}."
- Relative Pose Error (RPE): A metric of local pose drift between frames, reported for translation and rotation components. "In addition, we report Absolute Trajectory Error (ATE), Relative Pose Error for translation (RPE trans), and Relative Pose Error for rotation (RPE rot) in Table~\ref{table:pose_distance}."
- Relative Rotation Accuracy (RRA): The fraction of pairs with relative rotation error below a threshold. "Following \cite{wang2025pi}, we evaluate camera pose accuracy using Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA) at predefined thresholds."
- Relative Translation Accuracy (RTA): The fraction of pairs with relative translation error (angle) below a threshold. "Following \cite{wang2025pi}, we evaluate camera pose accuracy using Relative Rotation Accuracy (RRA) and Relative Translation Accuracy (RTA) at predefined thresholds."
- softmax-based splatting: A differentiable forward-warping technique that uses softmax weights to distribute contributions and avoid holes. "To preserve fine details during this process, we also apply softmax-based splatting \cite{niklaus2020softmax} to warp both images and depth maps."
- spherical cameras: Cameras that capture the entire surrounding environment (360°), often producing equirectangular images. "or spherical cameras \cite{chang2017matterport3d,armeni2017joint} to maximize coverage and minimize blind spots."
- spherical coordinates: A coordinate system using radius, polar angle (θ), and azimuthal angle (φ) to represent directions. "This formulation establishes a bijective mapping between the polar angle and azimuthal angle in spherical coordinates and 3D Cartesian directions."
- spherical harmonics: Orthonormal basis functions on the sphere used to represent angular functions compactly. "Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction."
- Structure from Motion (SfM): A pipeline that recovers camera poses and 3D structure from collections of images. "Structure from Motion (SfM) \cite{schonberger2016structure} is a fundamental problem in computer vision that aims to recover camera poses and 3D structure from a collection of images."
- triangulation: Estimating 3D points by intersecting rays from multiple views. "Previous methods estimate 3D points through triangulation, whereas our method directly predicts them in a feed-forward manner."
- Umeyama alignment: A closed-form method to compute the optimal similarity transform aligning two point sets. "For point cloud alignment, we sequentially apply Umeyama alignment \cite{umeyama2002least}, MoGe optimal point alignment \cite{wang2025moge}, and Iterative Closest Point."
- Unified Camera Model (UCM): A generic central camera model that unifies projection across various camera types. "the Unified Camera Model (UCM) \cite{geyer2000unifying,khomutenko2015enhanced}"
Collections
Sign up for free to add this paper to one or more collections.