OmniMoE: An Efficient MoE by Orchestrating Atomic Experts at Scale
Abstract: Mixture-of-Experts (MoE) architectures are evolving towards finer granularity to improve parameter efficiency. However, existing MoE designs face an inherent trade-off between the granularity of expert specialization and hardware execution efficiency. We propose OmniMoE, a system-algorithm co-designed framework that pushes expert granularity to its logical extreme. OmniMoE introduces vector-level Atomic Experts, enabling scalable routing and execution within a single MoE layer, while retaining a shared dense MLP branch for general-purpose processing. Although this atomic design maximizes capacity, it poses severe challenges for routing complexity and memory access. To address these, OmniMoE adopts a system-algorithm co-design: (i) a Cartesian Product Router that decomposes the massive index space to reduce routing complexity from O(N) to O(sqrt(N)); and (ii) Expert-Centric Scheduling that inverts the execution order to turn scattered, memory-bound lookups into efficient dense matrix operations. Validated on seven benchmarks, OmniMoE (with 1.7B active parameters) achieves 50.9% zero-shot accuracy across seven benchmarks, outperforming coarse-grained (e.g., DeepSeekMoE) and fine-grained (e.g., PEER) baselines. Crucially, OmniMoE reduces inference latency from 73ms to 6.7ms (a 10.9-fold speedup) compared to PEER, demonstrating that massive-scale fine-grained MoE can be fast and accurate. Our code is open-sourced at https://github.com/flash-algo/omni-moe.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “OmniMoE: An Efficient MoE by Orchestrating Atomic Experts at Scale”
Overview: What is this paper about?
This paper is about making big AI LLMs faster and smarter by using a “Mixture-of-Experts” (MoE) design. Think of an MoE model like a huge team of specialists. For each word or piece of text (called a “token”), the model picks a few specialists to help. The challenge is choosing the right specialists quickly and running them efficiently on a computer (especially on GPUs) without wasting time or memory. The authors introduce OmniMoE, a new way to organize and run millions of tiny specialists so the model is both accurate and fast.
Key objectives: What questions are the researchers asking?
They focus on three simple questions:
- How can we pick very small, highly specialized experts (for precision) without slowing everything down?
- How can we route tokens to the right experts quickly when there might be millions of experts to choose from?
- How can we run these chosen experts on GPUs in a way that uses hardware efficiently and avoids slow memory operations?
Methods and approach: How does OmniMoE work?
To solve these problems, the paper proposes three connected ideas. Here’s the approach in everyday terms, with analogies:
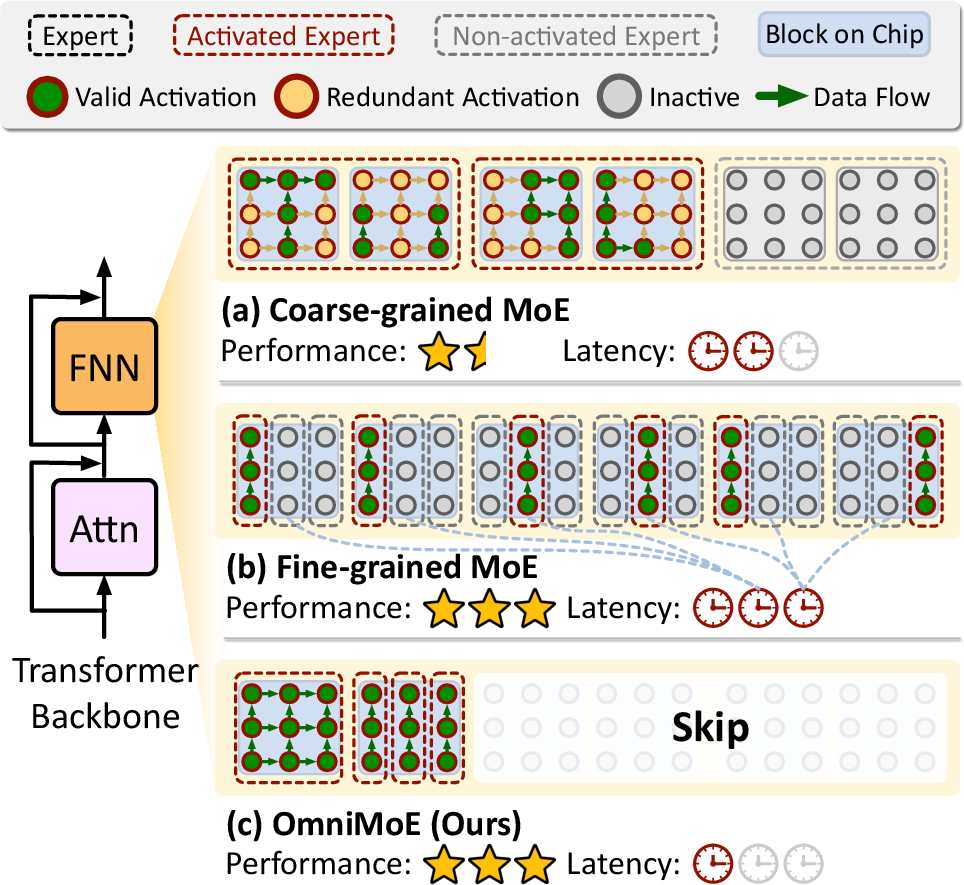
- The setting: Coarse vs. fine experts
- Coarse-grained experts: Big blocks of knowledge. Fast on hardware, but you often end up using more parameters than needed—like hiring an entire department to answer a simple question.
- Fine-grained experts: Many tiny specialists. More precise, but slow on hardware because they cause lots of scattered memory lookups—like searching many tiny notes scattered across different drawers.
OmniMoE combines the best of both worlds: it keeps one always-on general “brain” (a dense MLP) for common understanding, and adds many tiny experts for specific, rare knowledge. The three main ideas are:
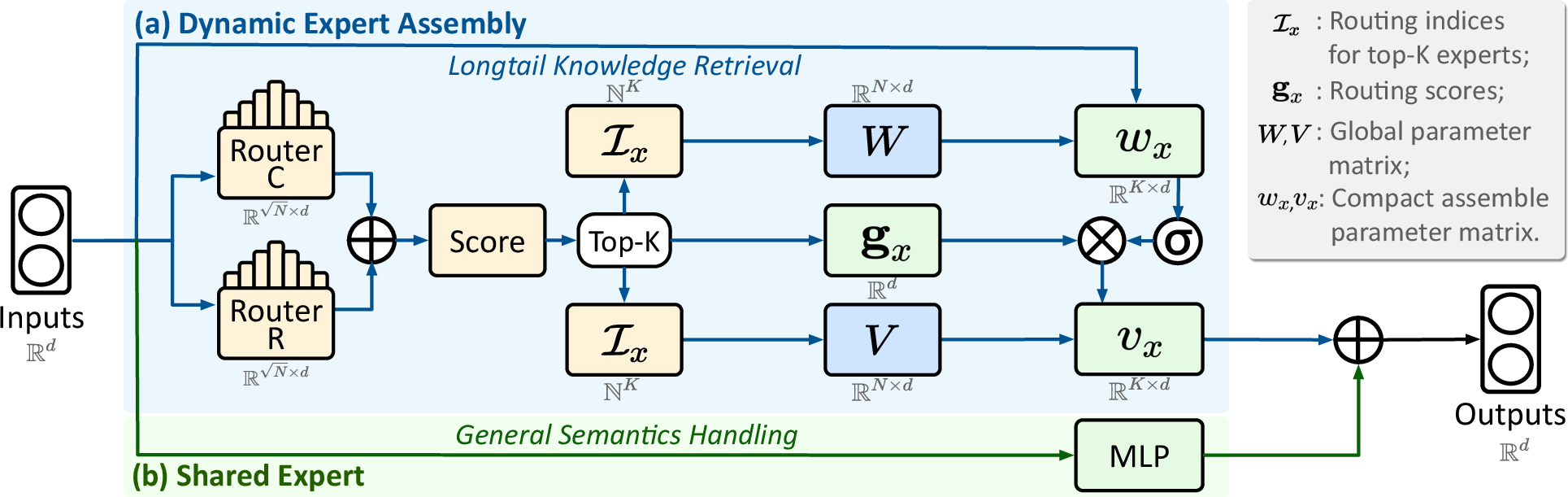
- Atomic Experts + Dynamic Expert Assembly (DEA)
- Atomic Experts are the tiniest specialists possible—each is basically two learned vectors (think: two special “directions” in number space) that can do simple but useful transformations.
- Dynamic Expert Assembly means, for each token, the model fetches just the few relevant atomic experts and combines them on the fly to build a custom mini-expert. Analogy: Instead of using a full textbook, you pull the exact pages you need to answer this question.
- Cartesian Product Router (fast expert choice)
- Choosing top experts from millions can be slow. The authors split the giant list into a grid with rows and columns. They score rows and columns separately, then combine them to find the best experts.
- Analogy: Instead of searching every house in a city, you narrow down to the best neighborhood (row) and the best block (column), then pick the exact address. This cuts the work from “check all N houses” to “check about √N rows plus √N columns,” which is much faster.
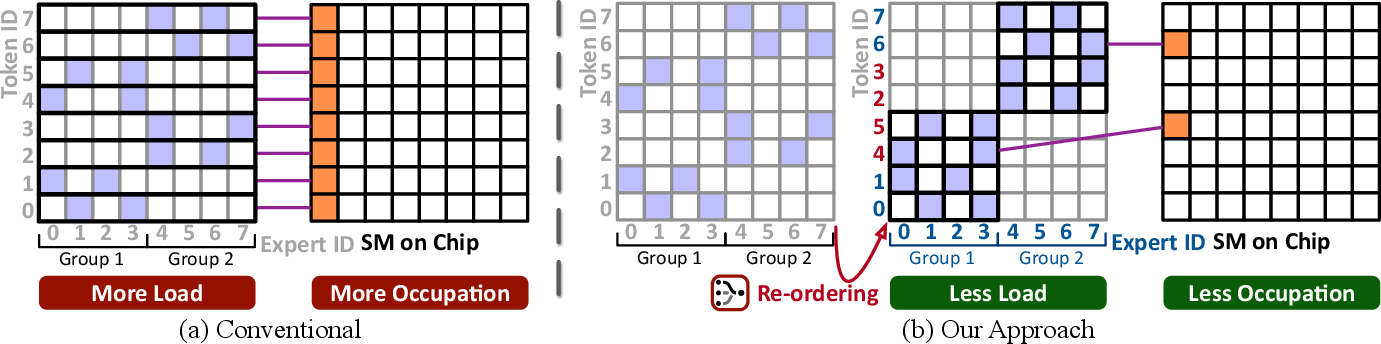
- Expert-Centric Scheduling (hardware-friendly execution)
- Running the chosen experts can be slow if each token fetches random pieces of memory. OmniMoE flips the execution order: it groups all tokens that need the same expert together, loads that expert’s weights once, and processes them in a batch using fast matrix operations (what GPUs love).
- Analogy: In a kitchen, instead of making orders one by one (lots of switching and wasted time), you cook all burger orders together, then all salads together. You reuse ingredients efficiently and move faster.
Alongside these, OmniMoE keeps a shared dense MLP (a standard network component) always active to handle general language understanding and reasoning. This balanced design gives both precision (for rare facts) and robustness (for common sense and logic).
Main findings: What did they discover and why is it important?
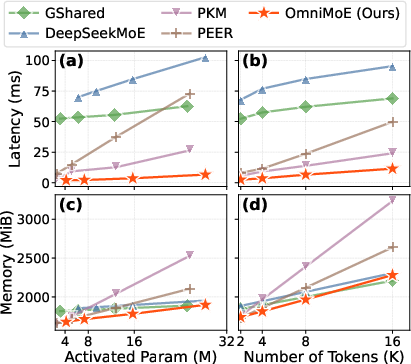
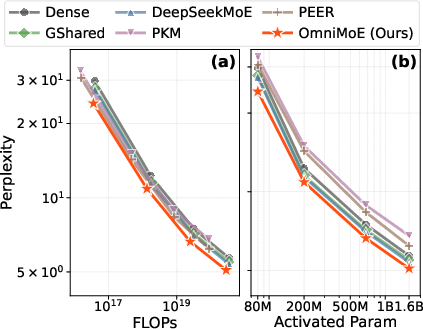
- Better accuracy: OmniMoE achieved the highest average zero-shot accuracy (50.9%) across seven benchmarks that test general knowledge and reasoning, beating both big-block expert models and fine-grained models. In simple terms, it answers questions more correctly on average.
- Much faster: Compared to a strong fine-grained baseline (PEER), OmniMoE reduced inference time from around 73 ms to 6.7 ms per step—about a 10.9× speedup—at 4,096 tokens. It also beat a popular coarse-grained model (DeepSeekMoE) on speed in many settings.
- Scales efficiently: The router’s “split into rows and columns” trick shrinks the routing cost dramatically, making it practical to pick among millions of tiny experts. The scheduling trick turns scattered memory reads into smooth, batched operations that maximize GPU performance.
- Balanced design helps: The shared dense MLP boosts reasoning tasks (like science questions), while the fine-grained atomic experts improve long-tail knowledge tasks (like trivia). Together, they cover both “general smarts” and “specific facts.”
Implications: Why does this matter?
- Faster, smarter AI: Models can be both precise and efficient, improving real-time applications like chatbots, search assistants, and educational tools.
- Better use of hardware: By making fine-grained expert activation hardware-friendly, it’s easier to deploy large models on existing GPUs without wasteful memory traffic.
- Flexible scaling: Tiny experts let you adjust capacity smoothly, which helps fit models to different devices and budgets.
- Open-source impact: The authors released their code, so others can build on OmniMoE to create more efficient AI systems.
In short, OmniMoE shows that you don’t have to choose between accuracy and speed. With smart routing and scheduling, millions of tiny experts can work together efficiently, giving AI models both sharp knowledge and strong reasoning.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, aimed to guide future research:
- Expressivity of atomic experts:
- Provide theoretical analysis of the representational capacity of an “atomic expert” (rank-1 with nonlinearity) compared to standard FFNs, and quantify how (number of assembled atoms) trades off with expressivity versus parameter/latency budgets.
- Benchmark against equally compute-matched low-rank or factorized-FFN alternatives to isolate the unique benefit of atomic composition.
- Router factorization assumptions:
- Quantify how the independence approximation affects routing quality; report degradation vs. a full -way router on controlled tasks.
- Explore alternative factorizations (e.g., 3D/MD product spaces, learned non-separable mixtures) and adaptive factorizations that vary with token/domain.
- Hyperparameter transparency and sensitivity:
- Report precise values and sensitivity for key routing/execution hyperparameters (e.g., , , , , group size , tile sizes in top- selection), and provide guidelines for hardware-specific tuning.
- Training dynamics of top- gating:
- Clarify gradient flow through the non-differentiable top- selection (e.g., STE, soft relaxation, stochastic gates) and quantify its impact on convergence, stability, and expert specialization.
- Load balancing and expert specialization:
- Detail the auxiliary losses or regularizers (if any) used to prevent expert collapse in OmniMoE; provide longitudinal expert-usage distributions and specialization analyses (topic/domain clustering, diversity metrics).
- Study robustness of load balance under scaling to tens of millions of experts and under distribution shift.
- Distributed training and multi-node scaling:
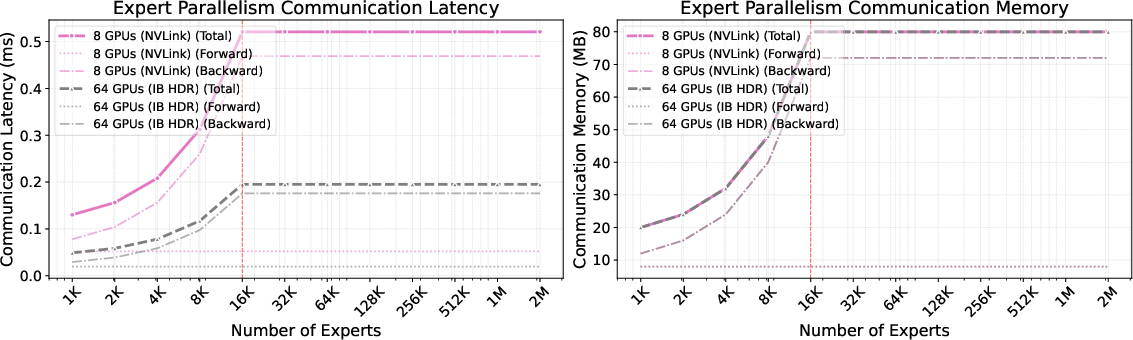
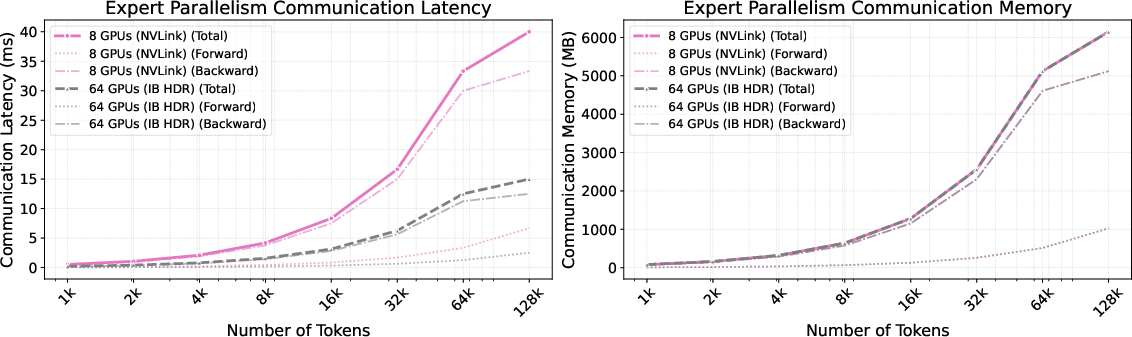
- Move beyond single-node (8×A100) to characterize communication, sharding, and synchronization costs across multi-node clusters; validate the “constant communication” claim with quantitative scaling curves.
- Describe failure modes (stragglers, hotspots, imbalance) and mitigation strategies (e.g., dynamic re-sharding, hierarchical routing).
- Training throughput and memory footprint:
- Report end-to-end training throughput, optimizer-state memory overhead for millions of experts, gradient aggregation costs, and wall-clock training speedups (not just inference).
- Analyze backward-pass scheduling and its interaction with Expert-Centric Scheduling.
- Streaming/low-batch inference:
- Evaluate performance for autoregressive generation with batch sizes 1–8 tokens per step, where expert-centric grouping opportunities diminish; quantify latency/throughput trade-offs vs. PEER/DeepSeekMoE in realistic serving settings.
- Hardware generality and portability:
- Test across diverse accelerators (e.g., H100, L4/T4, consumer GPUs) and CPUs; characterize how Expert-Centric Scheduling and Grouped GEMM performance varies by memory hierarchy and tensor-core availability.
- Long-context and KV-caching integration:
- Investigate how OmniMoE interacts with large context windows, KV-caching, and paged attention; measure end-to-end serving latencies with typical LLM pipelines.
- Quantization and compression:
- Explore 8/4-bit quantization and mixed-precision schemes for atomic expert matrices and router weights; assess accuracy/latency trade-offs and memory savings.
- Domain and task coverage:
- Extend evaluation beyond seven zero-shot QA benchmarks to code generation, mathematical reasoning, multilingual tasks, instruction following/SFT, and safety alignment; report fine-tuning behavior and transfer.
- Interpretability and knowledge retrieval claims:
- Substantiate “long-tail knowledge retrieval” with analyses of token–expert mappings, expert content/topic diagnostics, and controlled retrieval tests; propose tools to inspect and steer expert usage.
- Fairness of baseline comparisons:
- Ensure capacity and compute parity across baselines (e.g., 6.4B-A1.7B vs. 1.7B Dense); provide matched-size Dense models and coarse-grained MoEs to isolate architectural benefits.
- Scaling limits of top- selection:
- Empirically characterize top- routing overhead as scales to tens of millions; identify breakpoints where implicit-grid scoring or reduction becomes non-negligible and propose mitigations.
- Trade-offs in shared dense MLP capacity:
- Systematically vary shared-branch width/depth to quantify its contribution to reasoning vs. retrieval; provide guidance on capacity allocation between dense and routed branches under fixed activated-parameter budgets.
- Robustness and safety:
- Evaluate robustness to adversarial inputs, distribution shifts, and noisy data; study whether fine-grained routing exacerbates biases or instability and propose balancing/regularization strategies.
- Energy and cost efficiency:
- Report energy consumption and cost per token for training/inference compared to coarse/fine-grained baselines; assess whether speedups translate into real-world efficiency gains.
- Reproducibility and implementation detail gaps:
- Release complete configuration files and scripts mapping “activated parameters” to , , and expert dimensions; document kernel choices, sorting algorithms, memory layouts, and scheduler parameters to enable faithful replication.
Practical Applications
Overview
Below are practical applications that emerge from the paper’s findings and innovations—Atomic Experts, Dynamic Expert Assembly, the Cartesian Product Router, and Expert-Centric Scheduling. They are grouped by deployment horizon and, within each group, organized across industry, academia, policy, and daily life. Each bullet notes the sector, a concrete use case, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
- Sector: Software/AI Infrastructure (Cloud Serving)
- Use case: Low-latency, cost-efficient LLM serving in production (chatbots, copilots, QA) by replacing coarse-grained FFN experts with OmniMoE layers.
- Tools/products/workflows: Integrate OmniMoE kernels into existing serving stacks (e.g., PyTorch/HF Transformers, Triton/DeepSpeed), adopt Expert-Centric Scheduling (Grouped GEMM), enable smooth capacity scaling via Atomic Experts.
- Assumptions/dependencies: Availability of CUDA kernels and GPU hardware that benefits from grouped GEMM; engineering effort to swap FFN modules and retrain or distill models; monitoring for expert load balance.
- Sector: Mobile/Edge AI
- Use case: On-device assistants with tighter latency budgets (voice typing, translation, code completion) by leveraging fine-grained activation to fit memory/power constraints.
- Tools/products/workflows: Quantized OmniMoE variants, Metal/NNAPI kernels, edge inference SDKs; profile-and-prune workflows that tune K (top‑K experts) per device.
- Assumptions/dependencies: Efficient mobile kernels for routing/scheduling; quantization-friendly training; device-specific optimization (HBM/DRAM bandwidth constraints).
- Sector: Developer Tools (Software)
- Use case: Real-time AI copilots in IDEs and CI pipelines with consistent sub‑10ms inference per step for interactive coding and test generation.
- Tools/products/workflows: IDE plugins using OmniMoE, per-project micro-experts assembled dynamically; MLOps dashboards tracking Expert Usage/Unevenness to guide fine-tuning.
- Assumptions/dependencies: Stable domain-specific expert training; low-overhead router integration within editor event loops.
- Sector: Customer Experience (CX) and Enterprise Support
- Use case: Domain-specialized support agents that activate only relevant micro-experts for product SKUs, manuals, and long-tail troubleshooting.
- Tools/products/workflows: Dynamic Expert Assembly connected to enterprise knowledge bases; auto-curation pipelines that promote frequently used atomic experts; RAG + OmniMoE hybrid workflows.
- Assumptions/dependencies: Clean, structured domain data; guardrails and escalation paths; monitoring to avoid expert collapse or mode imbalance.
- Sector: Search and Knowledge Platforms
- Use case: Faster factual QA and long-tail retrieval via token-specific expert activation that improves precision without inflating compute.
- Tools/products/workflows: Cartesian Product Router for scalable routing; expert-centric serving layers behind search widgets; analytics on expert activation for corpus coverage.
- Assumptions/dependencies: Alignment between expert specializations and corpus distribution; latency SLAs enforced with batching and grouped execution.
- Sector: Healthcare Operations (non-diagnostic)
- Use case: Triage chat and administrative assistance (e.g., scheduling, benefits explanation) on clinical desktops with limited GPUs.
- Tools/products/workflows: Shared dense MLP for general semantics; small sets of healthcare-specific atomic experts; role-based gating policies.
- Assumptions/dependencies: Privacy/security hardening; domain fine-tuning; exclusion of diagnostic claims unless formally validated.
- Sector: Finance/Compliance
- Use case: Low-latency summarization and rule checking (policy diffing, disclosure generation) with expert activation tuned to specific regulations.
- Tools/products/workflows: Expert Usage/Unevenness telemetry to audit specialization; compliance-specific expert libraries; human-in-the-loop workflows for sign-off.
- Assumptions/dependencies: Up-to-date regulatory corpora; audit trails linking outputs to activated experts; model-risk governance.
- Sector: Robotics/Automation
- Use case: Onboard language understanding for command parsing and task execution on robot GPUs, benefiting from coalesced memory access.
- Tools/products/workflows: Expert-Centric Scheduling integrated with ROS nodes; token grouping strategies aligned to control loops.
- Assumptions/dependencies: Reliable GPU availability; deterministic scheduling; safety constraints around action generation.
- Sector: Academia (ML Systems/Methods)
- Use case: Immediate replication, ablation, and scaling-law studies using the open-source OmniMoE implementation.
- Tools/products/workflows: Benchmark harnesses with LightEval; controlled comparisons across FFN variants; router/scheduling ablation scripts.
- Assumptions/dependencies: Access to A100-class GPUs; reproducible training datasets (e.g., SmolLMCorpus); stable builds of CUDA/PyTorch.
- Sector: MLOps/Observability
- Use case: Expert-level telemetry for routing health (load balancing, collapse detection) to guide retraining and deployment tuning.
- Tools/products/workflows: Dashboards for Expert Usage and Unevenness; alarms for skew; automated router hyperparameter sweeps.
- Assumptions/dependencies: Instrumentation in serving stack; policy for rebalancing and model rollbacks.
Long-Term Applications
- Sector: Frontier LLM Architectures
- Use case: Multi-million to billion-scale atomic expert pools with stable routing and hardware-efficient execution, yielding better scaling at fixed FLOPs.
- Tools/products/workflows: Next-gen OmniMoE training recipes; hierarchical product routers; curriculum-based expert formation.
- Assumptions/dependencies: Continued advances in distributed scheduling and memory management; robust load-balancing losses; large-scale compute.
- Sector: Personalized AI (Daily Life)
- Use case: Per-user micro-experts (interests, writing style, terminology) assembled on-the-fly for private, low-latency assistants.
- Tools/products/workflows: Federated training of personal atomic experts; privacy-preserving gating; opt-in expert catalogs users can edit.
- Assumptions/dependencies: Differential privacy and secure enclave storage; safe personalization without overfitting or leakage.
- Sector: Healthcare (Clinical Decision Support)
- Use case: Offline, portable CDS tools leveraging atomically specialized medical knowledge with a shared dense backbone for general reasoning.
- Tools/products/workflows: Validated medical expert libraries; clinical audit logs of expert activation; evidence-linked outputs.
- Assumptions/dependencies: Rigorous clinical validation, regulatory approval (FDA/EMA), domain shift monitoring; robust harm-mitigation.
- Sector: Education at Scale (Policy + Industry)
- Use case: National or district-level AI tutors that operate on commodity devices and can activate curriculum-specific experts to support equitable access.
- Tools/products/workflows: Curriculum-aligned expert packs; localized language experts; teacher dashboards for content control and audits.
- Assumptions/dependencies: Procurement standards; content safety policies; professional development for educators; funding for device refresh.
- Sector: Energy/Green Computing (Policy + Cloud)
- Use case: Carbon-aware serving that exploits compute-bound execution and coalesced memory to reduce energy per inference and schedule workloads to low-carbon windows.
- Tools/products/workflows: Energy telemetry integrated with serving; policy-aligned SLAs; green routing modes that adjust K dynamically.
- Assumptions/dependencies: Data-center energy reporting; compliant carbon accounting; willingness to trade minor latency for energy savings.
- Sector: Semiconductors/Hardware Co-Design
- Use case: GPU/accelerator features tuned to expert-centric workloads (memory tiling, on-chip caches for expert blocks, native grouped GEMM for sparse activation).
- Tools/products/workflows: ISA extensions for tiled expert grids; compilers that generate expert-centric schedules; hardware simulators with OmniMoE kernels.
- Assumptions/dependencies: Vendor collaboration; standardization of MoE execution patterns; economic viability of new memory hierarchies.
- Sector: Safety, Governance, and Interpretability (Policy + Industry)
- Use case: Auditable expert activation traces that explain model outputs (which experts contributed) for compliance, incident review, and red-teaming.
- Tools/products/workflows: Activation-to-topic maps; immutable logs; post-hoc analysis tools that flag risky expert combinations.
- Assumptions/dependencies: Reliable attribution from atomic experts to semantic domains; policies defining accountability; storage and privacy controls.
- Sector: Finance (Enterprise AI)
- Use case: Continuous compliance autopilots where new rules spin up atomic experts and routers prioritize them dynamically across business units.
- Tools/products/workflows: Expert lifecycle management (create, evaluate, retire); domain drift detectors; change management workflows.
- Assumptions/dependencies: Strong data governance; model-risk frameworks; periodic human audits of expert performance.
- Sector: Multimodal AI and Robotics
- Use case: Cross-modal atomic experts (text, vision, audio) composed per token/frame with product-structured routing, enabling efficient multimodal understanding.
- Tools/products/workflows: Multimodal routers; grouped kernels across modalities; sensor-fusion expert packs for robots.
- Assumptions/dependencies: New training pipelines; unified representation spaces; hardware support for multimodal grouped execution.
- Sector: AI Infrastructure Products
- Use case: OmniMoE-native inference servers and compilers that automatically transform token-centric workloads into expert-centric schedules.
- Tools/products/workflows: Serving frameworks with built-in Cartesian Product Router; schedule optimizers; cost calculators for latency/capacity trade-offs.
- Assumptions/dependencies: Market adoption; compatibility with existing orchestration (Kubernetes, model registries); robust fallbacks for workload variability.
- Sector: RAG + Parametric Memory Unification (Research/Industry)
- Use case: Systems that fuse vector databases with atomic experts, selecting both retrieved documents and parametric micro-experts per query.
- Tools/products/workflows: Joint retriever-router training; pipelines that co-optimize document embeddings and expert vectors; consistency checks.
- Assumptions/dependencies: Stable optimization of dual selection; evaluation protocols for hybrid memory; safeguards against spurious correlations.
- Sector: Distributed/Decentralized Edge Networks
- Use case: Federated expert caches where communities or enterprises host domain experts locally and share routing metadata for low-latency collaboration.
- Tools/products/workflows: Peer-to-peer expert catalogs; privacy-preserving routing; edge schedulers that batch by expert proximity.
- Assumptions/dependencies: Secure aggregation; network reliability; incentives for contributing high-quality experts.
Glossary
- AdamW: An optimizer for training neural networks that decouples weight decay from gradient updates. "We use the AdamW optimizer~\cite{Loshchilov2017FixingWD} with the WSD learning rate scheduler~\cite{hägele2024scalinglawscomputeoptimaltraining}."
- Atomic Expert: A minimal routable computational unit parameterized by an input and output vector. "we push expert granularity to its logical extreme by introducing the Atomic Expert, a minimal routable unit parameterized by a pair of vectors,"
- Auxiliary load-balancing loss: A training regularizer that encourages balanced expert utilization in MoE. "Despite rigorous tuning of the standard auxiliary load-balancing loss for this baseline during training, the naive gate fails to learn distinct specializations..."
- Cartesian Product Router: A factorized routing mechanism that decomposes the expert space into a 2D grid to reduce complexity. "a Cartesian Product Router that decomposes the massive index space to reduce routing complexity from to "
- Chinchilla compute-optimality protocols: Guidelines for compute-optimal training that balance model size, data, and compute. "Hyperparameters follow optimal scaling laws~\cite{li2025predictablescalei} and Chinchilla compute-optimality protocols~\cite{hoffmann2022empirical}."
- Coalesced memory accesses: Contiguous and aligned memory operations that maximize effective bandwidth on GPUs. "contiguous, coalesced memory accesses"
- Compute-bound: A regime where throughput is limited by arithmetic computation rather than memory bandwidth. "thus shifting the execution from memory-bound to compute-bound."
- Dynamic Expert Assembly (DEA): A mechanism that retrieves and composes a sparse set of atomic experts into a token-conditioned block. "The Dynamic Expert Assembly (DEA) mechanism governs this composition process."
- Expert-Centric Scheduling: An execution strategy that groups and processes tasks by expert to improve locality and enable batched matrix operations. "Expert-Centric Scheduling that inverts the execution order to turn scattered, memory-bound lookups into efficient dense matrix operations."
- Feed-Forward Network (FFN): A dense MLP block commonly used as an expert in MoE architectures. "instantiate each expert as a complete dense FFN,"
- Gated projection: A projection operation modulated by learned routing weights. "for the final gated projection."
- GEMM (General Matrix Multiply): High-throughput matrix-multiplication kernels used on GPUs. "Grouped GEMM kernels"
- Grouped GEMM: Batched execution of multiple GEMM operations for higher throughput and reuse. "execute efficient Grouped GEMM kernels"
- Grouped Query Attention (GQA): An attention variant that groups queries to reduce computation and memory. "All models adopt Grouped Query Attention (GQA)~\cite{ainslie2023gqa}."
- GShard: A Mixture-of-Experts framework for scalable training with sharded experts. "Gshard~\cite{lepikhin2020gshard}"
- HBM (High Bandwidth Memory): High-speed memory used in GPUs that supports large data throughput. "fetches its selected expert parameters from HBM via scattered accesses,"
- KL divergence: A measure of how one probability distribution diverges from a reference distribution. "Unevenness: The KL divergence from a uniform distribution, computed as $D_{\text{KL}(z \| \mathcal{U}) = \sum_i z_i \log(N z_i)$"
- Logits: Pre-softmax scores output by a model or router. "the router computes logits ,"
- LogSoftmax: The logarithm of the softmax function, used for numerical stability. "obtained via the LogSoftmax function"
- Longtail Knowledge Retrieval: Retrieval focused on rare, specialized knowledge beyond general semantics. "For Longtail Knowledge Retrieval objective, we employ a Cartesian Product Router..."
- Memory-bound: A regime where throughput is limited by memory bandwidth rather than computation. "shifting execution from compute-bound to memory-bound and degrading GPU utilization."
- Mixture-of-Experts (MoE): An architecture that activates a subset of specialized experts per token to scale capacity. "Mixture-of-Experts (MoE) architectures are evolving towards finer granularity to improve parameter efficiency."
- NeoX tokenizer: A subword tokenizer used for training LLMs. "We employ the NeoX tokenizer~\cite{black2022gpt} with a vocabulary size of 128,256 tokens."
- Perplexity: A language modeling metric indicating how well a model predicts a sample. "Validation perplexity (lower is better) versus (a) training FLOPs and (b) activated parameters."
- PKM (Product Key Memory): A product-structured memory system enabling scalable, fine-grained retrieval. "Product Key Memory (PKM~\cite{lample2019pkm}) style design,"
- Product-structured indexing: Indexing via the Cartesian product of smaller subspaces to cover a large space efficiently. "This is analogous in spirit to product-structured indexing (e.g., PKM~\cite{lample2019pkm}):"
- Scaling laws: Empirical relationships describing how performance scales with model size, data, and compute. "Scaling Laws."
- Scatter-add: An operation that adds outputs back into a larger tensor at specified indices. "The per-task outputs are subsequently written back via scatter-add, preserving the semantics of Eq.~\ref{eq:assembly}."
- Softmax: A normalization function that converts logits into probabilities. "g_{i} = \operatorname{Softmax}(\mathcal{G}(x)[\mathcal{I}x]){i}"
- Streaming Multiprocessor (SM): A GPU compute unit that executes many threads in parallel. "fragmented vector-vector computations that underutilize on-chip SMs."
- SwiGLU: A gated activation function combining Swish and GLU for improved MLP expressivity. "we instantiate with SwiGLU~\cite{noam2020swiglu}."
- Tensor Cores: Specialized GPU units that accelerate matrix operations, especially mixed-precision matmuls. "benefiting from hardware-efficient dense matmuls (via Tensor Cores),"
- Top-K: Selecting the K highest-scoring items (e.g., experts) from a set. "A standard top- router computes routing scores for all experts via a projection matrix"
- VRAM: GPU video memory used to store tensors and parameters for fast access. "contiguous VRAM access,"
- Zero-shot accuracy: Performance on tasks without task-specific fine-tuning. "achieves 50.9\% zero-shot accuracy across seven benchmarks,"
Collections
Sign up for free to add this paper to one or more collections.