Bagging-Based Model Merging for Robust General Text Embeddings
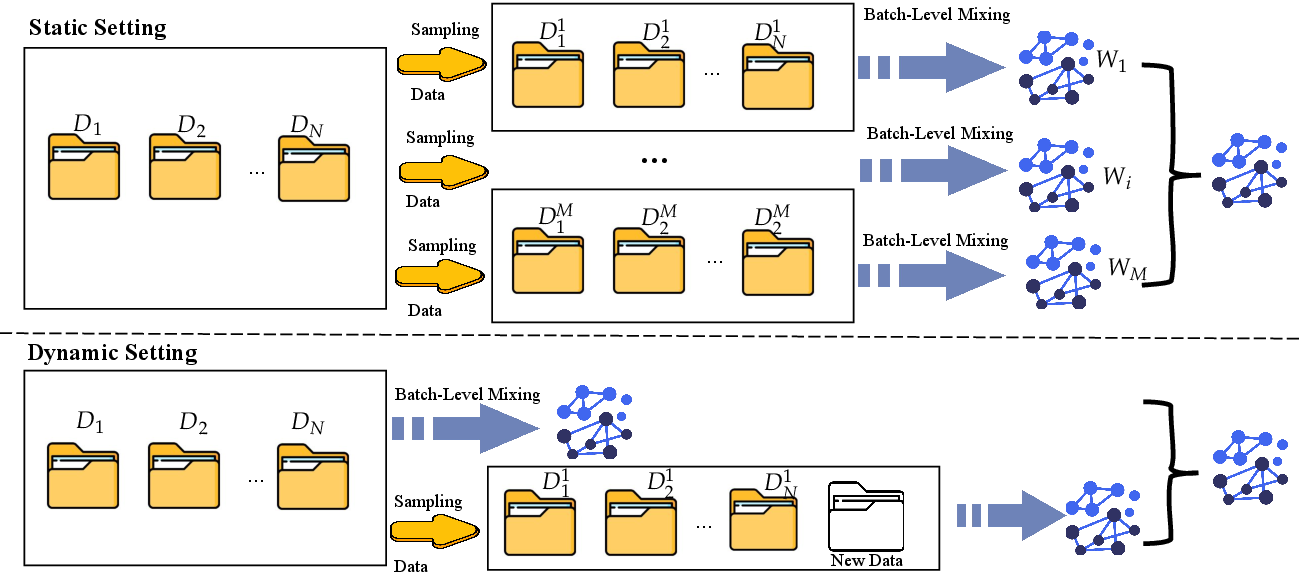
Abstract: General-purpose text embedding models underpin a wide range of NLP and information retrieval applications, and are typically trained on large-scale multi-task corpora to encourage broad generalization. However, it remains unclear how different multi-task training strategies compare in practice, and how to efficiently adapt embedding models as new domains and data types continually emerge. In this work, we present a systematic study of multi-task training for text embeddings from two perspectives: data scheduling and model merging. We compare batch-level shuffling, sequential training variants, two-stage training, and multiple merging granularities, and find that simple batch-level shuffling consistently yields the strongest overall performance, suggesting that task conflicts are limited and training datasets are largely complementary. Despite its effectiveness, batch-level shuffling exhibits two practical limitations: suboptimal out-of-domain (OOD) generalization and poor suitability for incremental learning due to expensive full retraining. To address these issues, we propose Bagging-based rObust mOdel Merging (BOOM), which trains multiple embedding models on sampled subsets and merges them into a single model, improving robustness while retaining single-model inference efficiency. Moreover, BOOM naturally supports efficient incremental updates by training lightweight update models on new data with a small historical subset and merging them into the existing model. Experiments across diverse embedding benchmarks demonstrate that BOOM consistently improves both in-domain and OOD performance over full-corpus batch-level shuffling, while substantially reducing training cost in incremental learning settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances a useful empirical perspective and proposes BOOM, yet several aspects remain uncertain or underexplored. The following concrete gaps can guide future work:
- Compute-controlled comparisons are missing: BOOM trains multiple base models and then merges; improvements may conflate bagging benefits with increased total optimization (tokens/steps). Establish baselines under equalized compute and data exposure.
- BOOM hyperparameters are under-specified: number of submodels, subset sizes, sampling with/without replacement, overlap ratios, and random seed variance are not systematically ablated. Provide a clear protocol and sensitivity analysis.
- Merging algorithm choice within BOOM is not explored: the method defaults to Multi-SLERP without testing whether TIES, Task Arithmetic, Karcher Mean, or other task-vector approaches affect performance, stability, or OOD robustness.
- Order and compositional stability of merging is unclear: behavior under sequential pairwise merges, repeated incremental updates, and long chains of merges (merge-of-merges) is not measured; potential order sensitivity and drift remain open.
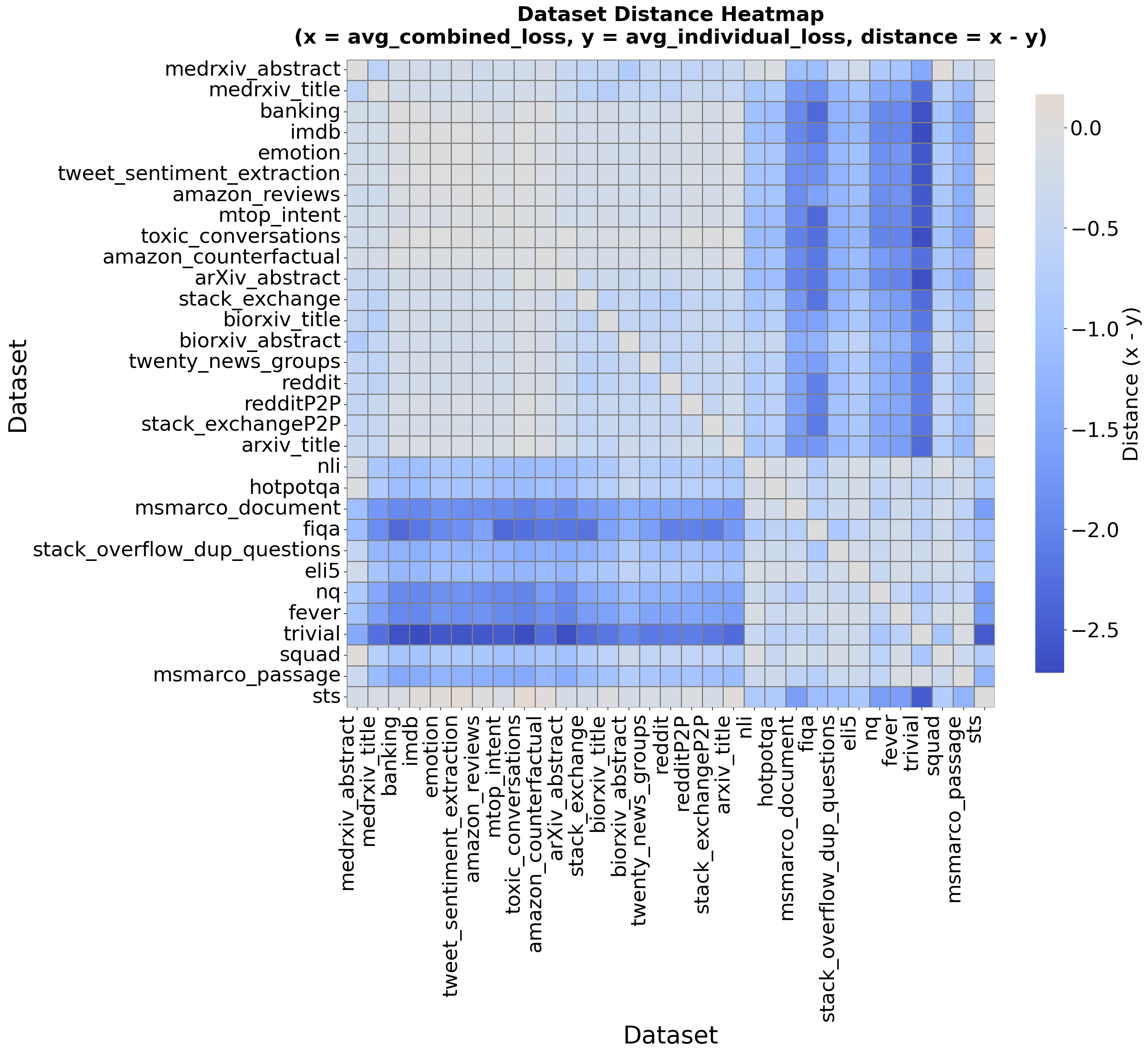
- Limited theoretical insight on why batch-level shuffling dominates: conflict is inferred via loss-based heuristics; direct measures (e.g., gradient cosine similarity, representational interference/transfer metrics) and causal analyses are absent.
- The pairwise “conflict/synergy” metric relies on average training loss: its relation to test-time generalization is unvalidated; alternative diagnostics (e.g., gradient conflicts, validation loss, cross-task transfer) are not compared.
- Backbone diversity is narrow: experiments use only Qwen3-0.6B and Qwen3-4B. Generality to encoder-only PLMs (e.g., BERT/T5), larger/smaller LLMs, and other families remains unknown.
- Training-length dependence is untested: conclusions are drawn from one-epoch fine-tuning; whether rankings of strategies (BLS vs sequential vs two-stage) persist across multi-epoch schedules and different LR regimes is unexamined.
- Batch-level shuffling (BLS) sampling policy is unspecified: dataset/task sampling probabilities and reweighting strategies are not detailed or ablated; impact on under/over-represented tasks is unclear.
- Two-stage baseline fidelity is uncertain: the implemented two-stage training may not match recipes from NV-Embed or Gemini embeddings; sensitivity to stage composition, mixing ratios, and negative policies is not studied.
- Statistical rigor is limited: results are reported as averages without multiple seeds, confidence intervals, or statistical tests; claims lack significance evidence.
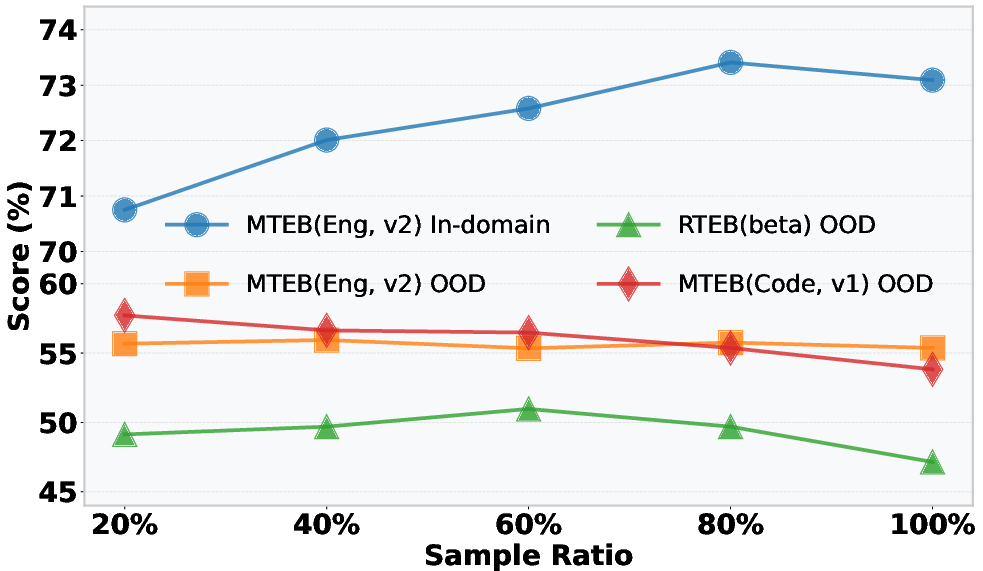
- IND/OOD split methodology is not fully specified: how IND vs OOD in MTEB (Eng, v2) is defined, and whether any residual train–test leakage exists beyond three excluded datasets, is not audited.
- Multilingual generalization is not evaluated: despite including multilingual datasets in General-Full-Data, no cross-lingual benchmarks (e.g., MIRACL, mTEB multilingual tasks) are reported.
- Real-world RAG impact is unmeasured: end-to-end improvements in retrieval-augmented generation (answer quality, faithfulness, latency) from BOOM are not assessed.
- Inference characteristics of merged models are unquantified: latency, throughput, memory footprint, and quantization compatibility post-merge are not reported.
- Long-horizon incremental learning remains open: cumulative effects of many small updates (e.g., stability, drift, order dependence, and retention) are not measured over multiple rounds.
- Forgetting/preservation trade-offs in incremental merges are not analyzed: per-domain/per-task retention when adding new domains via BOOM is not quantified beyond aggregate metrics.
- Robustness to stronger distribution shifts and adversarial settings is untested: current OOD coverage (MTEB v2 OOD, RTEB open, MTEB Code) may not capture harder shifts or adversarial perturbations.
- Macro averages may hide regressions: per-dataset and per-task trade-offs (e.g., specific domains harmed by merging) are not provided; targeted error analyses are lacking.
- Alternative compression baselines are missing: no comparison to distilling an ensemble into a single student, model soups from checkpoints, or MoE adapters; relative merits vs BOOM are unclear.
- Interaction with LoRA is ambiguous: for Qwen3-4B, fine-tuning uses LoRA (r=32), but it is unclear whether merging operates on adapters, merged full weights, or both; best practices for adapter-level merging are unsettled.
- Negative sampling choices are fixed: “7 hard negatives” and in-batch negative policies are adopted without ablation; how these interact with BOOM and affect OOD generalization is unknown.
- Code retrieval coverage is limited: training uses ~10k queries for each of five languages; generalization to other languages/frameworks and larger code corpora is untested.
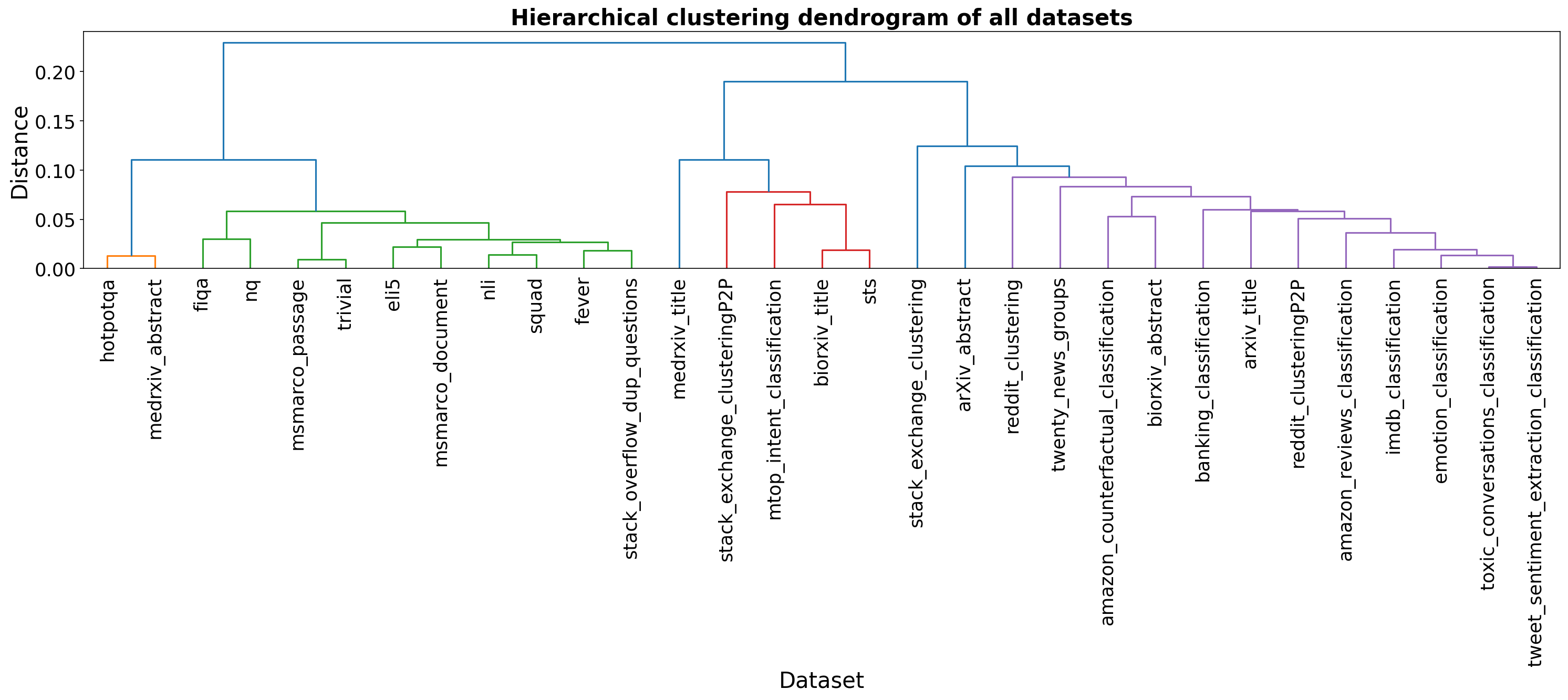
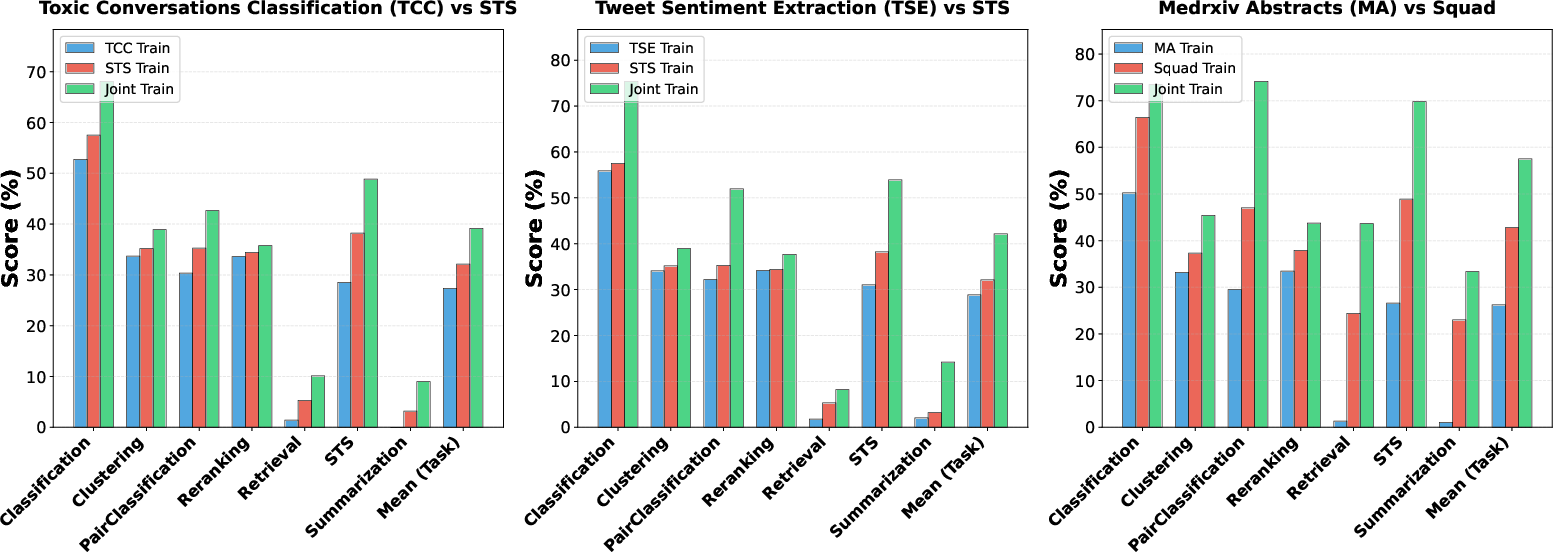
- Cluster-level merging findings may be dataset-specific: the observed broad “synergy” could depend on Eng-Text-Data; replication on different training collections (e.g., more diverse or noisier datasets) is needed.
- Safety, bias, and fairness are unexamined: effects of bagging/merging on representational biases across demographics, domains, or languages are not evaluated.
- Calibration and uncertainty of embeddings are not assessed: whether BOOM reduces variance or stabilizes similarity scores (as bagging suggests) is unquantified.
- Practitioner guidance is missing: no actionable rules-of-thumb on selecting BOOM settings (subset sizes, number of models) under fixed budgets or desired OOD gains.
- Reproducibility gaps: configuration labels like “{50}-and-R” are not defined; the anonymous code link and dataset availability/licensing for long-term reproducibility are uncertain.
- Comparisons to continual-learning baselines are absent: no evaluation against EWC, LwF, replay-based methods, or streaming ERM for incremental adaptation.
- Representation geometry is not analyzed: effects of merging on embedding anisotropy, clustering structure, and neighborhood stability are not examined.
Collections
Sign up for free to add this paper to one or more collections.