Context Forcing: Consistent Autoregressive Video Generation with Long Context
Abstract: Recent approaches to real-time long video generation typically employ streaming tuning strategies, attempting to train a long-context student using a short-context (memoryless) teacher. In these frameworks, the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows. This structural discrepancy creates a critical \textbf{student-teacher mismatch}: the teacher's inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student's context length. To resolve this, we propose \textbf{Context Forcing}, a novel framework that trains a long-context student via a long-context teacher. By ensuring the teacher is aware of the full generation history, we eliminate the supervision mismatch, enabling the robust training of models capable of long-term consistency. To make this computationally feasible for extreme durations (e.g., 2 minutes), we introduce a context management system that transforms the linearly growing context into a \textbf{Slow-Fast Memory} architecture, significantly reducing visual redundancy. Extensive results demonstrate that our method enables effective context lengths exceeding 20 seconds -- 2 to 10 times longer than state-of-the-art methods like LongLive and Infinite-RoPE. By leveraging this extended context, Context Forcing preserves superior consistency across long durations, surpassing state-of-the-art baselines on various long video evaluation metrics.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper is about teaching AI to make longer, smoother videos that stay consistent over time. Imagine a model making a video one small chunk at a time, like writing a story sentence by sentence. Current models often forget what happened earlier or slowly drift off-topic after a few seconds. The authors propose a method called Context Forcing that helps the model remember important past events and stay on track for much longer, so characters, backgrounds, and actions don’t change randomly as the video goes on.
Key questions the paper asks
Here are the main questions the researchers wanted to answer:
- How can we stop video models from forgetting earlier scenes when generating long videos?
- How can we prevent the “drift” problem, where small mistakes pile up and the video slowly becomes unrealistic?
- Can we train a model so it understands and uses a long history (20+ seconds) while still running efficiently in real time?
How the method works (in everyday language)
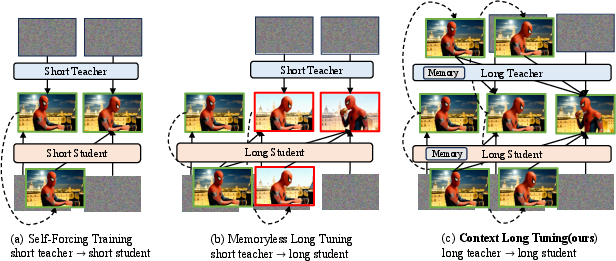
Think of two AIs:
- The Teacher: a strong model that can look far back into the video’s history and knows how to continue the story consistently.
- The Student: a faster model meant for real-time use that we want to learn this long-term consistency.
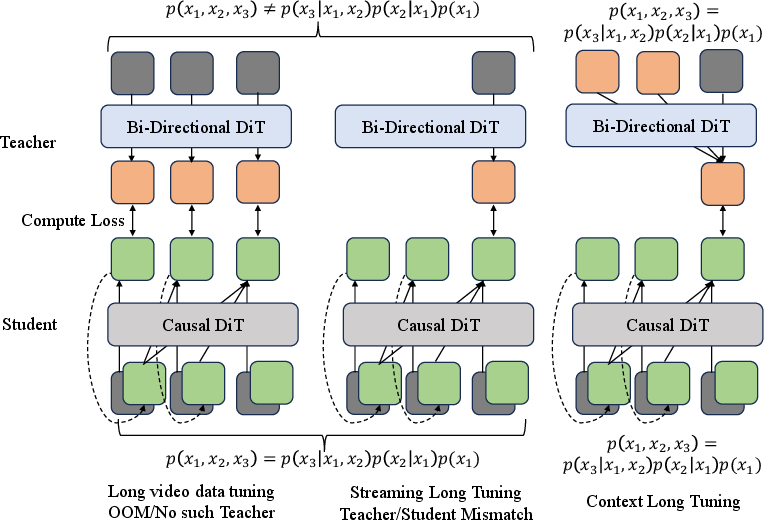
The big problem with older methods was a mismatch: the student was expected to make long videos, but the teacher could only see short clips (like 5 seconds). That’s like asking a coach who only saw the last play to guide a whole game. The student never learned true long-term planning.
Context Forcing fixes this by using a long-context Teacher to train a long-context Student. The Teacher sees the full history and shows the Student how to continue the video without changing the subject or style.
What this training looks like:
- Stage 1: Short practice. The student learns to make high-quality short clips, like perfecting sentences before writing a whole chapter.
- Stage 2: Long practice with guidance. The student generates a longer piece and the Teacher (who sees the whole history) gives feedback so the student learns how to keep characters, backgrounds, and motion consistent over time.
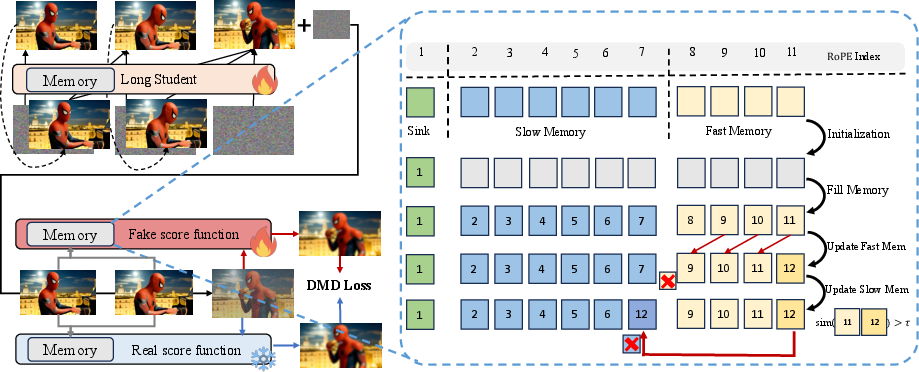
Smart memory system (Slow-Fast Memory):
- Fast Memory: Keeps the most recent details (like what just happened in the last few moments).
- Slow Memory: Stores “highlight moments” from earlier in the video (like putting important snapshots into a photo album). The model decides what to keep based on how different or important a moment is. If a new frame looks almost the same as the last one, it’s probably not worth saving; if it’s a big change, it gets saved.
- This memory system cuts out repetition, so the model can remember more meaningful history without using too much compute.
Extra tricks to make it work well:
- Bounded positions: The model’s internal “time labels” are kept inside a fixed range so it doesn’t get confused as the video gets very long.
- Robust teacher training: The Teacher practices on slightly messy histories (with small errors), so it learns how to correct the Student even when the Student’s past frames aren’t perfect.
- Gradual rollout: The Student starts with shorter histories and slowly works up to longer ones, so it doesn’t get overwhelmed early on.
In technical terms (lightly):
- The method uses a form of “distillation,” where the Student learns to match the Teacher’s predictions over long contexts.
- The “KV cache” is just the model’s memory of past tokens/frames; the Slow-Fast design organizes this memory so it’s both efficient and useful.
Main findings and why they matter
The authors compared their method to other top systems and found:
- Longer reliable memory: Their model effectively uses more than 20 seconds of history, which is about 2 to 10 times longer than many leading methods.
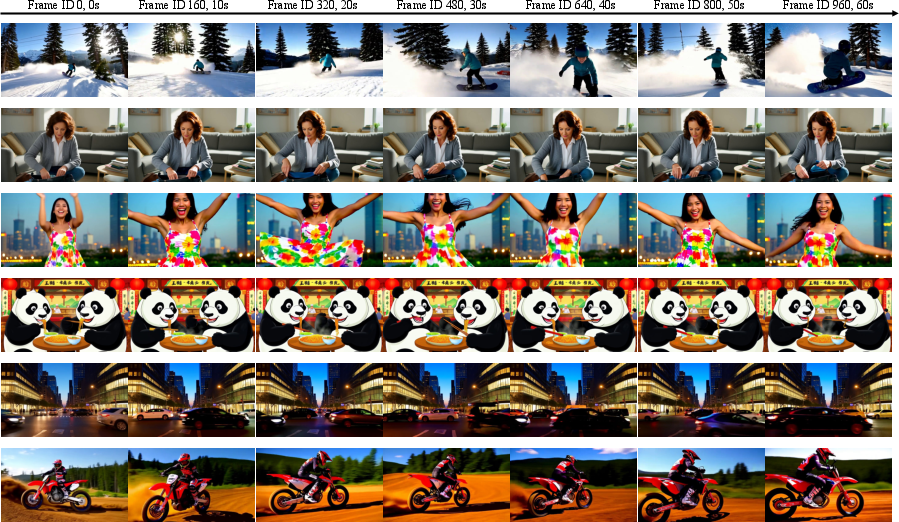
- Better long-term consistency: Characters and backgrounds stay stable across long videos (like 60 seconds), with fewer identity shifts or sudden resets.
- Real-time friendly: The memory system keeps things efficient, so you can generate long videos without huge slowdowns.
Why this matters:
- More believable videos: Stories feel continuous and coherent, like a real scene unfolding.
- Fewer glitches: The model doesn’t “forget” who the main character is or where the scene is set halfway through.
- Practical for creators: This makes long-form content generation more reliable for film, animation, games, education, and more.
What this could change in the future
Implications:
- Better tools for storytellers and designers, who can generate longer scenes that stay consistent.
- Stronger “world models” for interactive experiences and simulations that need memory over time.
- A step toward AI systems that can handle long sequences reliably, not just short clips.
Caution:
- As video generation gets more realistic and consistent, it could be misused to create convincing fake videos. The authors encourage using watermarks, provenance (proof of origin), and detection tools to reduce harm.
In short, Context Forcing teaches video models to remember what matters and stay on track, making long, consistent videos possible without getting lost or drifting off-topic.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Formal guarantees of the objective: No theoretical proof that the proposed Contextual DMD (CDMD) actually decreases the global long-horizon KL in Eq. (1); bound the error introduced by approximating with and quantify the gap.
- Teacher reliability characterization: Assumption 1 (teacher reliability near student contexts) is unquantified; define and measure “distance to the real data manifold” and empirically map teacher accuracy as a function of context drift severity.
- Assumption validation under drift: Assumption 2 (Stage-1 alignment to real prefixes) may not hold under long rollouts; provide stress tests where departs from data manifold and quantify when CDMD fails or needs corrective mechanisms.
- Teacher training details and limits: The robust context teacher is trained on ~40k long clips and 8k steps; investigate data/step scaling laws, domain coverage (e.g., animation, egocentric, sports), and how teacher capacity/quality bounds student performance.
- When teacher and student disagree: Analyze failure modes when teacher guidance contradicts high-fidelity short-term student outputs; study whether CDMD over-regularizes style, motion, or content diversity.
- Online/interactive correction: Explore whether a (lightweight) teacher or verifier could be used at inference time for online error correction without prohibitive latency.
- Generalization beyond 60 s: Claims of 20s+ effective context and feasibility for 2-minute durations are not empirically validated beyond 60 s; benchmark 2–5 minute generation and report degradation curves.
- Evaluation metric coverage: DINOv2/CLIP metrics and VBench may miss temporal causality, physics, and motion realism; add human studies, FVD/temporal FID, optical-flow/tracklet stability, and physics consistency metrics.
- Prompt and domain diversity: Long-form narrative prompts with scene changes, multi-character interactions, frequent occlusions, and rapid camera motion are underexplored; curate challenging long-horizon test sets and report per-category breakdowns.
- Failure-case analysis: Provide qualitative/quantitative analysis of scenarios where Context Forcing drifts (e.g., highly dynamic scenes, identity re-entrance after long absence, complex choreography) to guide method improvements.
- Resolution and frame-rate scaling: The paper does not report resolution/FPS details; study scalability to HD/4K and higher FPS, and the impact on memory budget, throughput, and consistency.
- Compute and memory costs: Lack of detailed profiling for training/inference (GPU memory, latency per frame/chunk, KV cache bandwidth); quantify the overhead of Slow/Fast memory and bounded RoPE versus quality gains.
- Slow-Fast Memory design choices: The surprisal-based consolidation compares keys only to the immediately preceding token with a fixed threshold τ=0.95; evaluate adaptive/learned thresholds, multi-step or global similarity, content-aware heuristics, and token-importance learning.
- Hyperparameter sensitivity: No ablations on N_s, N_c, N_l, chunk size, consolidation interval, τ, or bounded positional range; provide sensitivity analyses and guidelines for setting these under compute constraints.
- Memory eviction policy: Slow memory eviction is FIFO; examine learned eviction, recency-frequency trade-offs, and retrieval-augmented strategies to recall earlier but still relevant information.
- Bounded positional encoding limits: Reusing positions may introduce aliasing over very long sequences; analyze failure modes, derive conditions under which bounded RoPE harms attention disambiguation, and explore hybrid or index-renormalization schemes.
- Dynamic horizon schedule: The rollout-length curriculum is described but not ablated; study different growth schedules, curriculum pacing, and their effects on stability and sample efficiency.
- Robustness to severe distribution shifts: ERFT injects residuals from a residual bank with a Bernoulli switch; compare alternative drift models (e.g., adversarial perturbations, heavy compression noise, structured motion errors) and quantify robustness.
- Short-video quality trade-offs: Stage-2 CDMD is claimed to maintain short-clip quality, but no ablation isolating Stage-2’s impact on 5 s performance; report before/after metrics and identify any regressions.
- Comparisons with stronger long-context baselines: Include or reproduce more recent long-context AR baselines with comparable context windows and tuning (e.g., packing/memory-based methods) to ensure fair head-to-head comparisons.
- Data dependence and reproducibility: The long-video datasets (Sekai, Ultravideo) and filtering pipeline may not be universally accessible; release splits and filtering scripts, and assess how dataset composition affects outcomes.
- Controllability and multi-modal conditioning: Only text conditioning is considered; evaluate extensions to time-varying prompts, script-level control, layout trajectories, audio conditioning, and cross-modal constraints over long horizons.
- Editing and continuation tasks: The teacher is trained for continuation; study zero-shot and supervised video continuation and long-horizon video editing (insertion, replacement) with strict identity and background preservation.
- Safety and provenance: Ethical considerations are acknowledged but not implemented; evaluate watermarking/provenance integration effects on quality/consistency and robustness of watermarks over long rollouts.
- Large-model scaling: The approach is demonstrated at ~1.3B parameters; examine scaling to larger/smaller models, the compute-quality trade-off, and whether benefits persist under parameter-efficient finetuning.
- Analytical complexity bounds: Provide formal complexity bounds for the memory system (time/memory per token/chunk) and characterize asymptotic behavior as durations increase under different consolidation policies.
Practical Applications
Practical applications of the paper’s findings
Below are grouped lists of actionable applications that stem from the paper’s Context Forcing framework, contextual distillation (CDMD), slow–fast KV memory, bounded positional indexing, and robust context teaching (ERFT). Each bullet specifies sector(s), potential tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now, leveraging the released code, existing T2V models (e.g., Wan2.1), and the paper’s inference-side memory management.
- Media and Entertainment: minute-level, identity-consistent text-to-video generation for previsualization and animatics
- Tools/products/workflows: “Context Forcing” inference plug-in for NLEs (e.g., Premiere/Resolve) to generate and maintain character/background continuity across 20–60+ seconds; storyboard-to-video pipeline with autoregressive continuation that avoids resets/drifts
- Assumptions/dependencies: GPU availability for ~17 FPS throughput; model fine-tuning for brand/style; watermarking/provenance to mitigate deepfake risks
- Advertising and Marketing: programmatic ad sequences with brand asset continuity (mascots, logos, environments) across multi-scene clips
- Tools/products/workflows: ad creative generator that embeds brand style tokens and applies the slow–fast memory to keep brand elements stable while enabling scene transitions
- Assumptions/dependencies: brand-safe prompt controls; legal/compliance reviews; content provenance embedded in outputs
- Creator Tools and Social Media: video continuation for user-generated clips (extending 5–10s clips into consistent 30–60s shorts)
- Tools/products/workflows: mobile app feature powered by the robust Context Teacher to “continue” user clips while preserving identity and background; quick QC using windowed DINO/CLIP similarity metrics
- Assumptions/dependencies: moderation pipelines; teacher reliability near user-generated contexts; on-device or cloud inference with memory management
- Game Development: rapid generation of consistent cutscenes and teaser trailers without scene resets
- Tools/products/workflows: content pipeline add-on that uses bounded positional indexing and slow–fast KV caching to keep characters/props consistent; prompt-driven revisions via short refresh windows rather than full re-render
- Assumptions/dependencies: integration with engine asset libraries; creative direction constraints; QC for continuity and tone
- Video Editing and Post-production: continuity restoration and gap filling (e.g., bridging jump cuts, maintaining subject/background over retimed sequences)
- Tools/products/workflows: “autoregressive gap-fill” operator that uses the teacher-student setup to generate seamless intervening frames/scenes; timeline-aware continuation informed by slow memory keyframes
- Assumptions/dependencies: careful thresholding (
τ) in surprisal-based consolidation to ensure salient frames are retained; editor-in-the-loop approval workflow
- Education and Training Content: long, coherent explainer videos with consistent visual motifs and characters
- Tools/products/workflows: lesson generation tool that sequences multi-part demonstrations while preserving visual identity (e.g., a single tutor avatar across segments)
- Assumptions/dependencies: accuracy and curriculum alignment are human-curated; model guardrails for sensitive content; provenance labels
- Synthetic Data for Vision Research: generation of long, consistent sequences for tracking, re-identification, and scene consistency benchmarks
- Tools/products/workflows: dataset generator that parameterizes continuity, drift, and scene dynamics; evaluation harness using windowed DINOv2/CLIP metrics for subject/background consistency
- Assumptions/dependencies: synthetic-to-real domain gap considerations; license-compliant prompts; reproducibility across seeds
- ML Systems Integration: memory-managed KV cache and bounded positional indexing for existing autoregressive video models
- Tools/products/workflows: a lightweight library that adds attention sink, slow memory (keyframes), and fast memory (FIFO) with bounded RoPE indices to AR T2V systems; deployment recipes with recommended
N_s/N_c/N_lsettings - Assumptions/dependencies: architectural compatibility with DiT-like backbones; tuning
τand consolidation cadence by content domain
- Tools/products/workflows: a lightweight library that adds attention sink, slow memory (keyframes), and fast memory (FIFO) with bounded RoPE indices to AR T2V systems; deployment recipes with recommended
- Policy and Platform Operations: embed watermarking/provenance by default in long-form generative video outputs
- Tools/products/workflows: pipeline hooks for CR-provenance and watermarks at export; platform-side detectors keyed to the model’s watermark scheme
- Assumptions/dependencies: adoption of common provenance standards; alignment with legal frameworks; user consent and disclosure practices
Long-Term Applications
These require further research and scaling (e.g., longer horizons, stronger semantic control, physics grounding, or broader ecosystem changes).
- Film/TV Virtual Production: multi-minute, multi-shot generative sequences with controllable narrative arcs and editable continuity
- Tools/products/workflows: scene graph–aware Context Forcing with learnable context compression; shot-level editing handles; scheduling across multiple GPUs for multi-minute rollouts
- Assumptions/dependencies: stronger semantic planning and controllability; larger, diversified long-video datasets; robust human-in-the-loop review
- Interactive World Modeling for Robotics and Embodied AI: long-horizon, visually consistent environments for planning and simulation
- Tools/products/workflows: training loops that combine Context Forcing with physics-informed priors; closed-loop simulation where agent actions influence continuation
- Assumptions/dependencies: fidelity of physical dynamics (beyond visuals); integration with sensors/embodiment; sim-to-real transfer validation
- Real-time Telepresence and Avatars: identity-preserving avatars with consistent long-term context (backgrounds, props) in live calls/streams
- Tools/products/workflows: streaming inference with low latency, memory-optimized caches; adaptive slow memory policies reacting to scene changes
- Assumptions/dependencies: hardware acceleration; privacy and consent controls; robust moderation and fail-safes against impersonation misuse
- Procedural Cinematics in Games: adaptive storytelling sequences that evolve consistently with player state over extended play sessions
- Tools/products/workflows: engine integration with context-aware generative cutscenes; memory policies tied to gameplay events via surprisal signals
- Assumptions/dependencies: semantic control and synchronization with game logic; content safety gating; compute budget management
- Education at Scale: auto-generated course modules and interactive labs with persistent visual identity and context across lessons
- Tools/products/workflows: curriculum engines that chain lesson segments; knowledge-grounded generative pipelines to ensure factual accuracy
- Assumptions/dependencies: robust grounding and verification; educator oversight; accessibility and localization support
- Healthcare Training Simulations: long-form procedural videos (e.g., surgery simulations) maintaining scene and tool continuity
- Tools/products/workflows: domain-specific fine-tuning with expert-curated datasets; controllable progression with waypoint prompts
- Assumptions/dependencies: medical accuracy; privacy and licensing; regulatory compliance and risk mitigation
- Cross-modal Foundation Models: generalizing slow–fast memory and bounded positional indexing to multimodal agents (video+audio+text)
- Tools/products/workflows: unified memory managers across modalities; learnable memory compression for salient cross-modal events
- Assumptions/dependencies: architecture-level research; large-scale cross-modal datasets; evaluation standards for long-horizon coherence
- Learnable Context Compression and Adaptive Memory: moving beyond heuristics (similarity thresholds) to end-to-end memory optimization
- Tools/products/workflows: “Memory Optimizer” modules that learn what to store/evict; context importance predictors; segment-level compression policies
- Assumptions/dependencies: training stability for memory policies; interpretability and control; compatibility with KV cache implementations
- Platform-wide Provenance and Detection Ecosystem: standardized watermarking, verified media chains, and detection services for long-form synthetic video
- Tools/products/workflows: end-to-end provenance pipelines from generation to distribution; third-party detection APIs; user-facing provenance badges
- Assumptions/dependencies: industry consensus on standards; regulatory adoption; resistance to watermark removal and adversarial attacks
- Policy and Governance: frameworks for disclosure, consent, identity protection, and safe deployment of long-context video generation
- Tools/products/workflows: compliance toolkits that integrate provenance, consent management, and audit logging; risk classification of prompts/outputs
- Assumptions/dependencies: evolving legal and ethical norms; cross-platform enforcement; public education on synthetic media
Notes on feasibility assumptions across applications:
- Teacher reliability and student alignment: the framework assumes Stage 1 aligns short-window distributions and that the teacher remains accurate near student-generated contexts (critical for CDMD efficacy).
- Data and compute: high-quality long-video datasets and sufficient GPU throughput are prerequisites for production-level performance; extending beyond ~60–120s will likely require model scaling and improved memory compression.
- Safety and compliance: watermarking/provenance, moderation, and human oversight are necessary to mitigate deepfake risks and ensure responsible deployment.
- Domain-specific fine-tuning: specialized sectors (healthcare, education, robotics) require domain datasets, grounding mechanisms, and rigorous validation beyond generic visual consistency.
Glossary
- Attention Sink: A fixed set of initial tokens kept in memory to stabilize attention during streaming generation. "Specifically, the cache is partitioned into three functional components: an Attention Sink, Slow Memory (Context), and Fast Memory (Local)."
- Autoregressive (AR) prediction: Sequential generation where each output depends on previously generated outputs. "many works combine diffusion with autoregressive (AR) prediction~\cite{kim2024fifo, lin2025autoregressive, gu2025long}"
- Block-wise causal attention: An attention mechanism that enforces temporal causality within blocks to prevent future information leakage. "Recent diffusion-based frameworks have improved visual fidelity by incorporating causal architectural priors, such as the block-wise causal attention introduced in CausVid~\cite{yin2024slow}."
- Bounded Positional Indexing: Constraining positional indices to a fixed range to stabilize attention and prevent drift on long sequences. "we adopt Bounded Positional Indexing."
- Causal video generation: Video synthesis under strict temporal ordering, enabling real-time streaming and long-horizon outputs. "Causal video generation synthesizes video sequences under strict temporal ordering constraints, thereby enabling streaming inference and long-horizon synthesis."
- Chain rule of KL divergence: A decomposition technique that splits global divergence into local and continuation terms over a sequence. "By applying the chain rule of KL divergence, we decompose the global objective into two components:"
- CLIP-F: A semantic consistency metric based on CLIP features comparing visual content over time. "Beyond standard benchmarks, we assess fine-grained consistency using DINOv2~\cite{oquabdinov2} (structural identity), CLIP-F~\cite{radford2021learning} (semantic context), and CLIP-T (prompt alignment)."
- CLIP-T: A prompt alignment metric using CLIP to measure how well generated video matches the textual prompt. "Beyond standard benchmarks, we assess fine-grained consistency using DINOv2~\cite{oquabdinov2} (structural identity), CLIP-F~\cite{radford2021learning} (semantic context), and CLIP-T (prompt alignment)."
- Consistency Models (CM): Few-step generative models trained for consistency across diffusion timesteps. "including Distribution Matching Distillation (DMD/DMD2)~\cite{yin2024one, yin2024improved,wang2023prolificdreamer} and Consistency Models (CM)~\cite{song2023consistency, wang2024phased}."
- Context Forcing: The proposed framework that trains a long-context student using a long-context teacher to ensure long-term consistency. "We introduce Context Forcing, a novel framework that mitigates the student-teacher mismatch in training real-time long video models."
- Context Management System: A mechanism that partitions memory into slow/fast components to reduce redundancy while preserving long-term context. "we introduce a context management system that transforms the linearly growing context into a Slow-Fast Memory architecture, significantly reducing visual redundancy."
- Context Teacher: A pretrained long-context video model used to supervise the student on global temporal dependencies. "We first leverage a Context Teacher pretrained on video continuation tasks, which is capable of processing long-context inputs."
- Contextual Distribution Matching Distillation: A distillation method that aligns the student’s continuation distribution with a long-context teacher under the same history. "This teacher guides the student via Contextual Distribution Matching Distillation, explicitly transferring the ability to model long-term dependencies and ensuring global consistency."
- Contextual DMD (CDMD): A conditional variant of DMD that optimizes the student’s continuation given its own generated context. "Under these assumptions, we approximate $p_{\text{data} \approx p_T$ in the second term of Eq.~\eqref{eq:kl-decomposition}, yielding the Contextual DMD (CDMD) objective:"
- Denoising Diffusion Transformer (DiT): A transformer-based diffusion architecture for high-quality visual generation. "video diffusion models based on architectures such as the Denoising Diffusion Transformer(DiT)~\cite{peebles2023scalable}"
- DINOv2: A vision representation model used to assess structural identity consistency over time. "Beyond standard benchmarks, we assess fine-grained consistency using DINOv2~\cite{oquabdinov2} (structural identity), CLIP-F~\cite{radford2021learning} (semantic context), and CLIP-T (prompt alignment)."
- Distribution Matching Distillation (DMD): A distillation technique aligning student and teacher distributions to improve few-step generation quality. "These approaches typically employ Distribution Matching Distillation (DMD)~\cite{yin2024one} to distill a high-quality bidirectional teacher into a causal student."
- Distribution shift: A change in the data or model output distribution that degrades performance over long sequences. "causes error accumulation and distribution shift (Drifting)."
- Drifting: Progressive deviation of generated video from the true distribution due to accumulated errors. "causes error accumulation and distribution shift (Drifting)."
- Error-Recycling Fine-Tuning (ERFT): A fine-tuning strategy that injects realistic errors into context to make the teacher robust. "To ensure our Context Teacher provides robust guidance even when the student drifts, we adopt Error-Recycling Fine-Tuning (ERFT)~\citep{li2025stable}."
- Exposure bias: The mismatch between training on ground-truth context and inference on self-generated history. "Standard training conditions the model on ground-truth context, but inference relies on self-generated history, creating a distribution shift known as exposure bias."
- Fast Memory (Local): A short-term FIFO cache storing immediate context for near-term attention. "Fast Memory ($\mathcal{L_{\text{fast}$)}: A rolling FIFO queue of size , capturing immediate local context with short-term persistence."
- FIFO queue: A first-in, first-out buffer used to maintain a rolling local context window. "Fast Memory ($\mathcal{L_{\text{fast}$)}: A rolling FIFO queue of size , capturing immediate local context with short-term persistence."
- Forgetting-Drifting Dilemma: The trade-off between short-memory forgetting and long-context error drift in streaming generation. "This mismatch results in a critical challenge for real-time long-context video generation, which we term the Forgetting-Drifting Dilemma (Figure~\ref{fig:dilemma})."
- Key-Value (KV) cache: Stored attention keys and values used to retain context across timesteps in autoregressive generation. "The resulting robustness allows for longer duration Key-Value (KV) cache management (maintaining 20+ seconds of history) compared to prior SOTA (1.5--9.2 seconds of history) during inference"
- KL divergence: A measure of difference between probability distributions used as a training objective. "The objective is to minimize the global long-horizon KL divergence:"
- Long rollouts: Generating extended sequences during training or inference to learn and test long-term dependencies. "the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows."
- Long Self-Rollout Curriculum: A training schedule that gradually increases the student’s rollout horizon to stabilize learning. "Long Self-Rollout Curriculum."
- Positional encoding modifications: Training-free changes to positional encodings to extend effective context length. "or extend context through training-free positional encoding modifications~\cite{lu2024freelong, lu2025freelong++, zhao2025riflex}."
- Proxy distribution: A substitute distribution used when the true data continuation distribution is inaccessible. "we employ a pretrained Context Teacher , which provides a reliable proxy distribution $p_T(X_{k+1:N} \mid X_{1:k})."</li> <li><strong>Rotary Positional Encoding (RoPE)</strong>: A positional encoding method that rotates embeddings to incorporate position information. "All tokens' temporal RoPE positions are constrained to a fixed range $\Phi = [0, N_s + N_c + N_l - 1]t$:"</li> <li><strong>Self-Forcing</strong>: Training strategy that conditions on prior outputs via KV caching and rollout-based objectives to align training with inference. "Self-Forcing~\cite{huang2025self} typically generates rollouts using a random timestep selection strategy to ensure supervision across all diffusion steps."</li> <li><strong>Slow Memory (Context)</strong>: A long-term buffer that stores high-entropy, salient keyframes for global consistency. "Slow Memory ($\mathcal{C_{\text{slow}$)}: A long-term buffer of up to $N_c$ tokens, storing high-entropy keyframes and updating only with significant new information."
- Slow-Fast Memory architecture: A dual memory design that compresses salient history while retaining recent context for efficient long sequences. "we introduce a context management system that transforms the linearly growing context into a Slow-Fast Memory architecture, significantly reducing visual redundancy."
- Streaming inference: Real-time sequential processing that generates video as inputs arrive. "Causal video generation synthesizes video sequences under strict temporal ordering constraints, thereby enabling streaming inference and long-horizon synthesis."
- Surprisal-Based Consolidation: A policy that promotes tokens with low similarity (high surprisal) from fast to slow memory to capture key events. "Surprisal-Based Consolidation."
- Teacher-student mismatch: A capability gap where a short-context teacher cannot supervise a long-context student on global dependencies. "This structural discrepancy creates a critical student-teacher mismatch: the teacher's inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student's context length."
- Windowed attention: Attention limited to a fixed window for efficient long-context inference. "Further research has addressed efficient long-context inference through windowed attention, as seen in StreamDiT~\cite{kodaira2025streamdit}."
Collections
Sign up for free to add this paper to one or more collections.

