- The paper introduces a novel feed-forward 3D Gaussian reconstruction pipeline that augments 2D VFMs with robust geometric scene understanding.
- It employs mask-aware upscaling and semantic blending to refine feature maps for improved depth estimation, segmentation, and surface normal predictions.
- Experimental results show significant benchmark improvements and strong out-of-domain transfer, validating the scalability and efficiency of the method.
Splat and Distill: A Feed-Forward Framework for 3D-Aware Distillation in 2D Vision Foundation Models
Introduction
"Splat and Distill: Augmenting Teachers with Feed-Forward 3D Reconstruction For 3D-Aware Distillation" (2602.06032) proposes a method for enriching 2D Vision Foundation Models (VFMs), such as DINOv2, with robust 3D awareness. The core innovation lies in integrating a feed-forward 3D Gaussian reconstruction pipeline into the teacher model during distillation, enabling dense geometric scene understanding without the computational inefficiencies and semantic compromises of optimization-based lifting approaches. The student network is trained via cross-view supervision, achieving significant improvements in tasks demanding geometric and semantic reasoning.
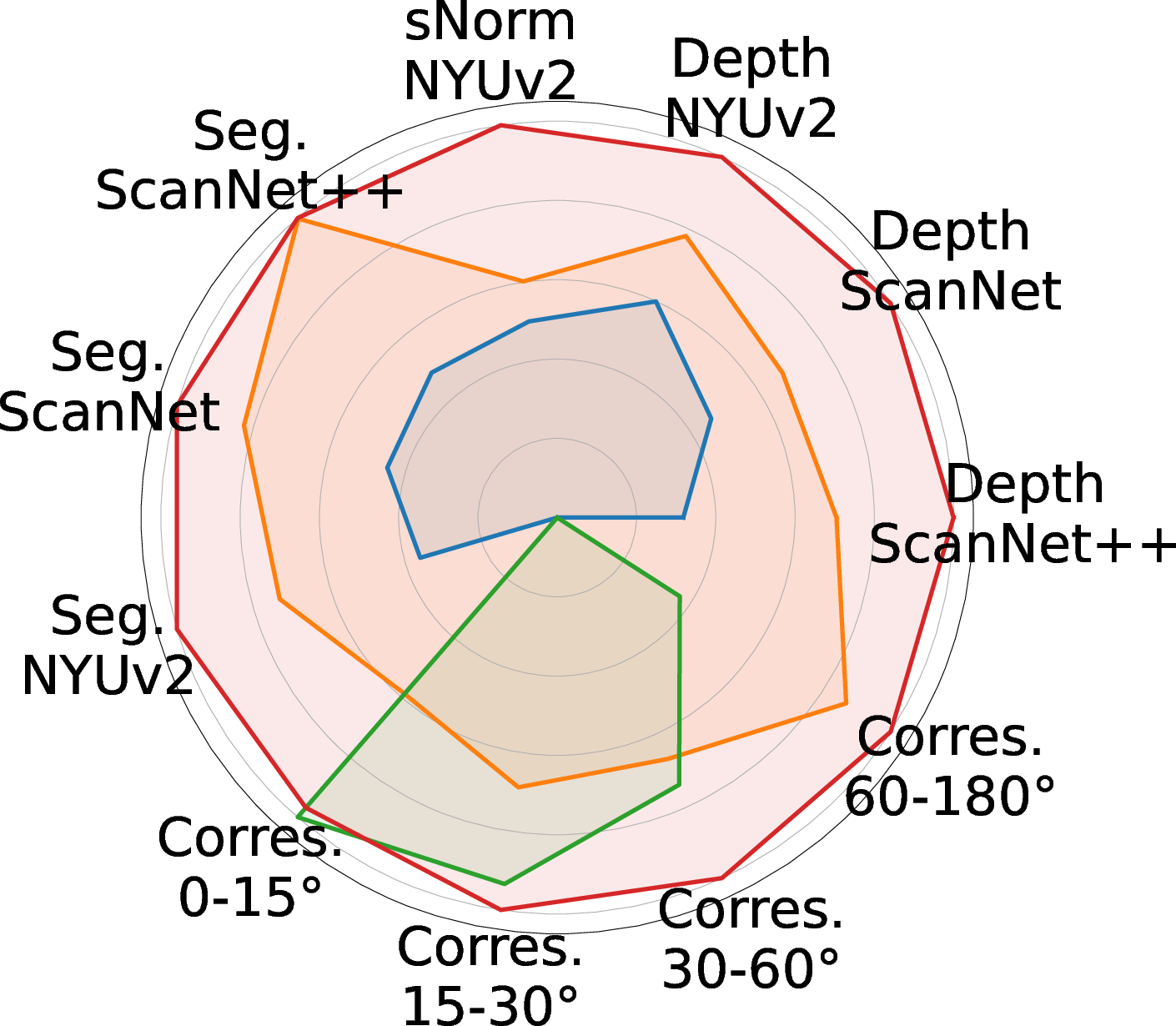
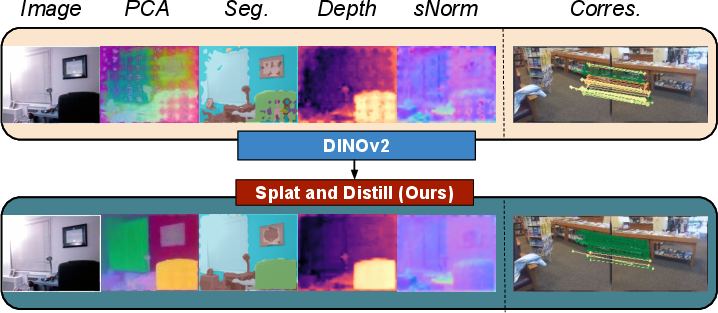
Figure 1: The Splat and Distill (SnD) framework leverages a 3D reconstruction module to generate 3D-aware 2D features, yielding superior performance on depth, surface normal, segmentation, and correspondence tasks.
Methodology
Student-Teacher Distillation with 3D Augmented Teacher
The approach departs from classical self-supervised distillation by enhancing the teacher with a feed-forward 3D reconstruction network, specifically MVSplat. The teacher, initialized from DINOv2, processes context views to produce low-resolution 2D features. These features are upscaled via a mask-aware interpolation guided by semantic segmentation masks and lifted into 3D space using direct pixel-to-Gaussian correspondences provided by the MVSplat pipeline. The resulting 3D feature scene is rendered from novel viewpoints and further regularized via semantic blending, enforcing local spatial consistency within object regions.
Feed-Forward 3D Gaussian Splatting
The reconstruction component replaces the costly per-scene optimization typical of NeRF and 3DGS methods with direct prediction of 3D Gaussian primitives. Only geometry (mean, covariance, opacity) is used, discarding photometric parameters. Each 2D input pixel corresponds to a 3D Gaussian, enabling efficient lifting of semantic features.
Mask-Aware Upscaling and Semantic Blending
Interpolation uses semantic masks to prevent feature mixing across object boundaries during upscaling. Semantic blending further regularizes the rendered feature maps, correcting geometric misalignments by averaging within object regions delineated by instance masks, producing sharper object boundaries while preserving high-frequency semantic detail.




Figure 2: Instance semantic masks guide mask-aware upscaling and blending, producing sharp feature boundaries during distillation.




Figure 3: The rendered view for supervision is generated from the 3D Gaussian scaffold using the context and target parameters.
Distillation Objective
The student network observes only the 2D target image and learns to match the teacher’s blended feature maps using a cross-entropy distillation loss mediated by the DINO head. The teacher is updated as an EMA of the student parameters, ensuring continual feedback between the networks.
Experimental Evaluation
Monocular Depth Estimation
The framework significantly outperforms DINOv2, FiT3D, and MEF baselines on ScanNet++, ScanNet, and NYUv2 benchmarks for RMSE and Abs-Rel metrics. The improvements in RMSE are 5.90%, 5.82%, and 3.21% over the closest baseline, respectively.












Figure 4: Qualitative comparison for monocular depth estimation on NYUv2 showing refined structural details with SnD.











Figure 5: Monocular depth prediction for ScanNet++ and ScanNet, demonstrating geometric accuracy and surface consistency with SnD.
Surface Normal Estimation
On NYUv2, SnD achieves a 5.37% improvement in RMSE for surface normals over the next-best baseline (FiT3D), yielding smoother, geometrically coherent normal predictions.












Figure 6: Surface normal estimation highlights improved local geometric reasoning and semantic consistency.
Multi-View Correspondence
SnD demonstrates superior recall for multi-view correspondence across varied viewpoint changes—critical for tasks requiring spatial consistency beyond single-image inference.








Figure 7: Multi-view correspondences reveal reduced reprojection error and improved dense geometric feature association.
Semantic Segmentation
Quantitative and qualitative evaluations show SnD consistently produces cleaner masks and sharper spatial boundaries across ScanNet++, ScanNet, NYUv2, ADE20K, and Pascal VOC. Improvements in mean intersection-over-union (mIoU) are up to 2.77% on ScanNet.












Figure 8: Semantic segmentation results with SnD on NYUv2 demonstrate sharper and less fragmented object masks.























Figure 9: SnD yields improved semantic segmentation on ScanNet++ and ScanNet.
Generalization and Transfer
SnD exhibits strong transferability, outperforming baselines on out-of-domain tasks (ADE20K, Pascal VOC, KITTI) without additional fine-tuning, supporting the claim that the geometric priors imparted by 3D distillation generalize beyond the training domain.
























Figure 10: SnD generalizes to out-of-domain datasets for monocular depth and semantic segmentation.
Feature Visualization
PCA and K-means analyses indicate SnD features have less noise and more coherent semantic clustering, with clear boundaries and improved multi-view consistency compared to DINOv2.







































Figure 11: Cross-scene PCA/K-means visualization shows tighter semantic clusters with SnD features.

































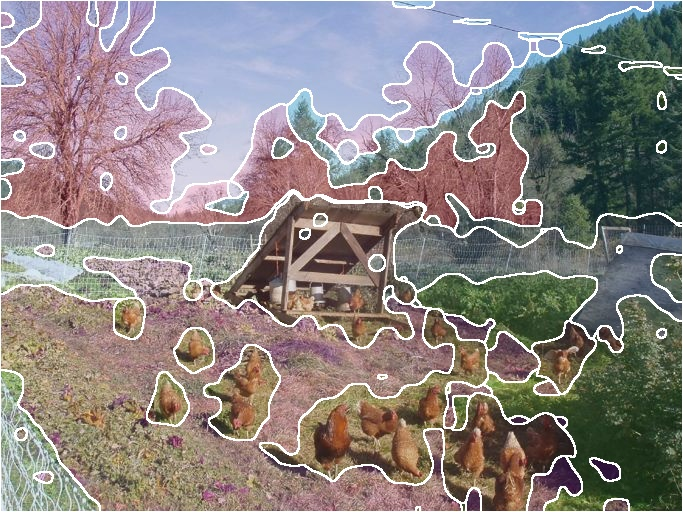
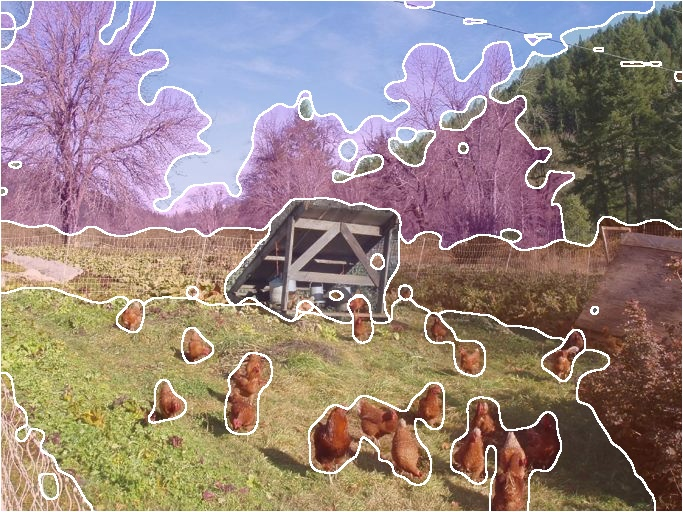


















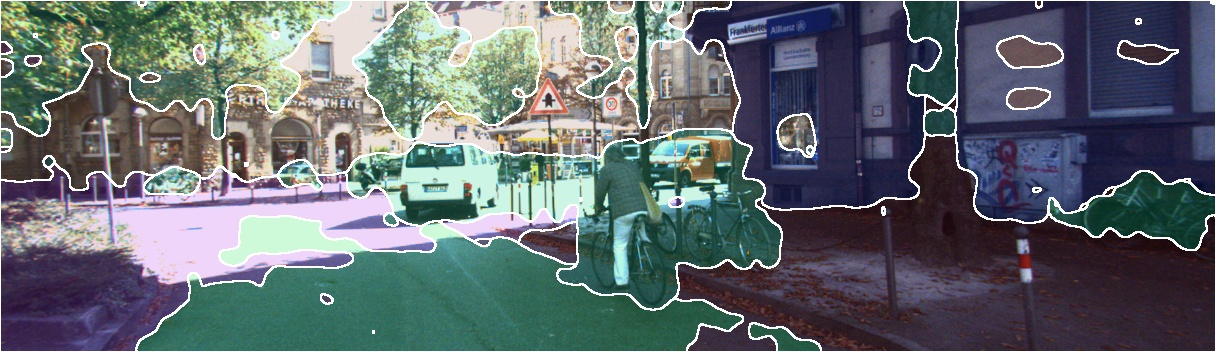
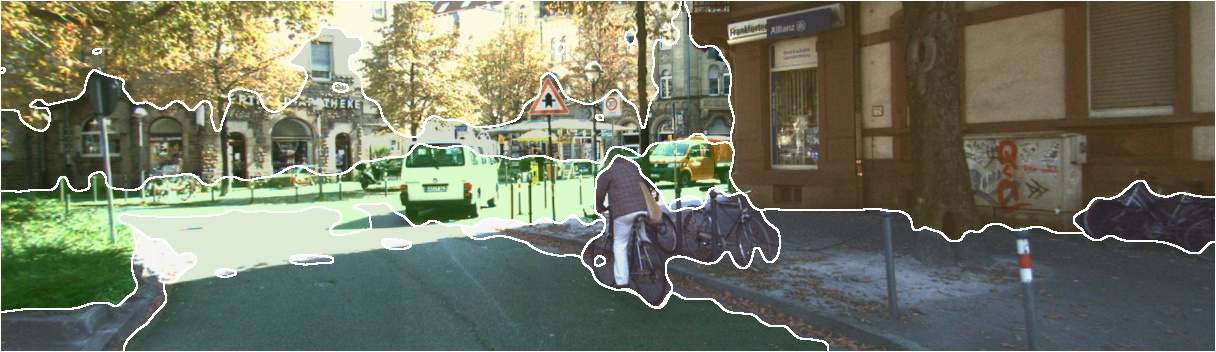




Figure 12: Single-image feature visualization across datasets highlights reduced noise and preserved semantic structure with SnD.
Ablation Studies
The ablation reveals that mask-aware upscaling and iterative teacher updates (EMA) are essential. Semantic blending and rendering to novel views contribute measurably to improved depth and segmentation performance. The distillation objective, as opposed to direct feature regression, is necessary to prevent feature collapse and maximize geometric awareness.
Figure 2: Mask-aware upscaling is critical for sharp object-based feature interpolation.
Figure 3: View rendering for distillation supervision to novel, unseen perspectives improves geometric consistency.
Practical and Theoretical Implications
The Splat and Distill paradigm demonstrates that integrating geometric structure into 2D VFMs can be achieved efficiently and scalably via feed-forward pipelines and cross-view supervision. This unlocks dense 3D semantic reasoning in architectures previously limited to 2D modalities, opening avenues for generalized spatial understanding, multi-view consistency, and potential for zero-shot generalization in unseen environments. The practical outcomes are applicable to robotics, AR/VR, and any downstream domain requiring spatially grounded features. The framework is amenable for further scaling with video datasets or more complex feed-forward lifting mechanisms, and could serve as a blueprint for future multimodal distillation regimes.
Limitations and Future Directions
The quality of supervision is contingent on the accuracy of the feed-forward 3D Gaussian reconstruction and availability of multiview data. Extending SnD to leverage video streams would access larger and more diverse training corpora. Enhancements to the pipeline could include dynamic mask prediction, integration with volumetric representations, or more robust geometric regularization strategies. The iterative teacher update cycle suggests possibilities for longer-term curriculum-style training using paired views spanning broader spatial or temporal ranges.
Conclusion
Splat and Distill builds a scalable, efficient bridge between 2D VFMs and robust 3D understanding, leveraging feed-forward 3D reconstruction and mask-aware interpolation within a distillation framework. Empirical results demonstrate strong gains in geometric and semantic tasks, as well as generalization to out-of-domain settings. The method establishes a rigorous paradigm for geometric-aware feature learning in deep vision systems and suggests multiple avenues for extending spatial reasoning in foundation models.