SwimBird: Eliciting Switchable Reasoning Mode in Hybrid Autoregressive MLLMs
Abstract: Multimodal LLMs (MLLMs) have made remarkable progress in multimodal perception and reasoning by bridging vision and language. However, most existing MLLMs perform reasoning primarily with textual CoT, which limits their effectiveness on vision-intensive tasks. Recent approaches inject a fixed number of continuous hidden states as "visual thoughts" into the reasoning process and improve visual performance, but often at the cost of degraded text-based logical reasoning. We argue that the core limitation lies in a rigid, pre-defined reasoning pattern that cannot adaptively choose the most suitable thinking modality for different user queries. We introduce SwimBird, a reasoning-switchable MLLM that dynamically switches among three reasoning modes conditioned on the input: (1) text-only reasoning, (2) vision-only reasoning (continuous hidden states as visual thoughts), and (3) interleaved vision-text reasoning. To enable this capability, we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts, and design a systematic reasoning-mode curation strategy to construct SwimBird-SFT-92K, a diverse supervised fine-tuning dataset covering all three reasoning patterns. By enabling flexible, query-adaptive mode selection, SwimBird preserves strong textual logic while substantially improving performance on vision-dense tasks. Experiments across diverse benchmarks covering textual reasoning and challenging visual understanding demonstrate that SwimBird achieves state-of-the-art results and robust gains over prior fixed-pattern multimodal reasoning methods.

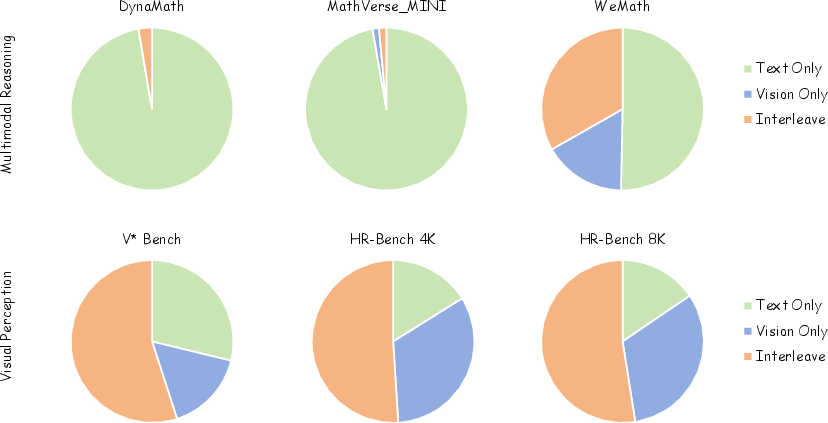

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces SwimBird, a new kind of AI that can understand and reason about both pictures and text. What makes SwimBird special is that it can switch how it “thinks” depending on the question. Sometimes it thinks in words, sometimes it thinks in picture-like internal notes, and sometimes it mixes both. This flexible thinking helps it solve tough visual puzzles without losing its ability to do careful, step-by-step reasoning in text.
Key Questions the Paper Tries to Answer
- Can a single AI model choose the best way to think—words, pictures, or both—based on the problem?
- If the AI “thinks in pictures,” can it decide how much visual thinking it needs instead of using a fixed amount every time?
- Will this flexible approach make the AI better at both vision-heavy tasks (like finding tiny details in big images) and text-heavy tasks (like math or logic)?
How the Researchers Approached the Problem
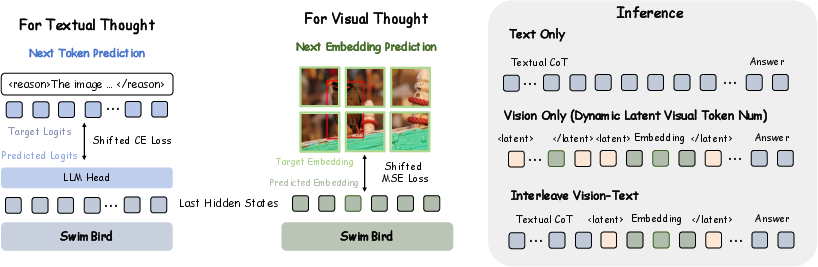
1) Three “thinking modes” the model can switch between
Think of the model like a student with two notebooks: a word notebook and a sketch notebook.
- Text-only reasoning: It writes down step-by-step explanations in words.
- Vision-only reasoning: It creates picture-like internal notes (not visible images, but hidden, image-based “thoughts” inside the model).
- Interleaved reasoning: It switches between word notes and picture notes as needed.
The model chooses the mode by itself, depending on the question.
2) How the model generates its thoughts
- Text thoughts = next-word prediction: Like finishing a sentence one word at a time.
- Visual thoughts = next-embedding prediction: Instead of drawing a visible image, the model produces a series of numbers that represent visual information (like a compact, internal sketch). It learns to make these internal “visual thoughts” match meaningful visual states.
The model uses special tags to decide when to write words and when to create visual thoughts. During training, these tags teach it when to switch modes; during use, it can insert the tags by itself to choose the best mode.
3) A training set that teaches all three modes (SwimBird-SFT-92K)
The team built a 92,000-example training set that covers:
- Text-only problems
- Vision-only problems
- Mixed (interleaved) problems
How they labeled it in simple terms:
- They tested whether providing intermediate images (helpful hints) made problems easier.
- If hints alone solved the problem most of the time, it was labeled “vision-only.”
- If hints helped but weren’t enough, it was labeled “interleaved” (needs both pictures and words).
- They also added a large set of pure text reasoning examples for balance.
This variety teaches the model when each mode is most helpful.
4) A “dynamic budget” for visual thinking
Previous models often used a fixed number of visual thought steps for every problem. SwimBird changes that:
- For bigger, denser images, it can use more visual thought steps.
- For simpler images, it uses fewer.
- It keeps producing visual thoughts until it decides to stop, like a student using more sketchbook pages for harder puzzles and fewer for easy ones.
This avoids wasting effort on simple tasks and preserves detail when the images are complex.
Main Findings and Why They Matter
Here’s what SwimBird achieved in tests:
- It did better than many strong models on fine-grained, high-resolution visual tasks (like finding tiny details in big, complex images).
- It also kept strong performance on text-based reasoning tasks (like math and logic).
- Compared to models that always use the same reasoning pattern (always text, always visual, or always mixed), SwimBird performed more robustly across different kinds of problems.
Why this is important:
- When a model is forced to always “think in words” about pictures, it can miss visual details.
- When it’s forced to always “think in pictures,” it can get worse at logic and math.
- SwimBird avoids these problems by choosing the right kind of thinking for the job.
Implications and Potential Impact
SwimBird shows that AI can be more flexible and efficient by switching between word-thoughts and picture-thoughts:
- Better tools for tasks that mix logic and vision, like reading diagrams, solving mazes, interpreting charts, or answering questions about photos.
- More reliable performance because the model doesn’t waste time on the wrong kind of thinking.
- A step toward AI systems that adapt to the user’s question—thinking the way a human might: in words, in images, or both.
In short, SwimBird’s big idea is simple but powerful: let the AI decide whether to think in words, pictures, or a mix, and use just the right amount of each. This makes it both smarter and more practical across many kinds of problems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of the main uncertainties and omissions that remain unresolved in the paper, articulated as concrete, actionable directions for future work:
- Quantifying mode-selection quality: No oracle-mode or forced-mode ablations to measure how much improvement comes specifically from correct mode choice versus model capacity; no calibration metrics for the delimiter-based gating.
- Sensitivity to prompting: The system prompt defines modes and tags, but there is no ablation on prompt dependence (e.g., different tag schemas, stricter/looser instructions) or robustness to user prompt variations.
- Automatic labeling bias: Reasoning-mode labels are derived via pass@8 using Qwen3-VL-8B and judged by Qwen3-235B; no human verification, cross-judge comparison, or threshold sensitivity analysis to estimate label noise and bias.
- Dataset coverage and balance: The curation procedure yields 50K text-only and 42K visual/interleaved samples, but there is no study of how mode proportions affect learned gating or downstream performance; no analysis of domain gaps or underrepresented categories.
- Data contamination risks: Potential overlap between SFT sources and evaluation benchmarks is not audited; no contamination checks to ensure fair comparisons.
- Dependence on “thinking images”: Training for visual thoughts relies on datasets with intermediate visual steps; it is unclear how to scale to tasks without such images or how to synthesize them automatically at training time.
- Visual-thought supervision choice: The MSE loss reconstructs same-encoder embeddings of intermediate images; alternative objectives (contrastive, InfoNCE, adversarial, pixel-level reconstructions, perceptual losses) and their effects on faithfulness and utility are unexplored.
- Embedding-manifold drift: No assessment of whether generated latent embeddings remain on the vision-encoder manifold at inference (e.g., via nearest-neighbor distances or a discriminator); risk of degenerate or semantically invalid latent states is not quantified.
- Frozen vision stack: The vision encoder and projector are frozen; the impact of unfreezing or partial fine-tuning on latent-visual reasoning and overall performance is not studied.
- Compute–accuracy trade-offs: Dynamic latent spans and resolution-aware patch budgets likely affect latency and memory, but no runtime/FLOPs/throughput comparisons with baselines or budgeted variants are reported; no early-stopping or budget-control policy beyond emitting </latent>.
- Termination and stability: Visual-span termination is solely via a delimiter; no safeguards against excessively long latent sequences, oscillatory mode-flipping, or failure to terminate; no penalties or decoding strategies to constrain such behavior.
- Disentangling two “budgets”: The paper varies ViT patch-token budgets and allows variable numbers of latent steps, but does not disentangle their separate contributions via controlled studies.
- Robustness and safety: No evaluation under adversarial perturbations, occlusions, heavy noise, or distribution shifts; no analysis of hallucinations, misleading visual hints, or safety/bias concerns triggered by mode switching.
- Interpretability and faithfulness: Generated visual thoughts are not decoded or visualized, making it hard to assess what they represent; no methods to interpret or verify latent visual trajectories or to align them with human-understandable evidence.
- Failure-mode analysis: No systematic analysis of cases where the wrong mode is chosen, why it happens, and how to recover (e.g., self-reflection or mode-correction strategies).
- Multilingual and cross-domain generalization: The evaluation focuses on English single-image tasks; performance on multilingual queries, low-resource languages, text-heavy OCR, charts, scientific figures, and other specialized domains is not examined.
- Temporal and multi-image reasoning: No experiments on video, temporal reasoning, or problems requiring multiple images/contexts; scalability of switchable reasoning to sequential inputs remains open.
- Conversational settings: Mode switching in multi-turn dialogues (e.g., maintaining consistent modes across turns or adapting per turn) is not evaluated.
- Scaling laws: Effects of model size and SFT data size/composition on mode selection and performance are not studied; no evidence that gains persist or improve with larger backbones.
- Alternative hybrid designs: No comparison with other latent representations (e.g., VQ-VAE tokens, diffusion latents, learned discrete visual tokens) or hybrid decoders that might offer better controllability or interpretability.
- Integration with tools/agents: The method beats some agentic systems without tools, but potential complementarities (zoom/crop, OCR, calculators, retrieval, external planners) are not explored; no investigation of when to invoke tools versus latent visual thoughts.
- Decoding and search details: Hybrid decoding (interleaving discrete tokens and continuous embeddings) may complicate beam search and sampling, yet inference algorithms and reproducibility details for search over mixed modalities are not provided.
- Hyperparameter interactions: Only the visual MSE weight and a single max-token range are ablated; interactions between λ_text, λ_vis, curriculum strategies, and sampling/temperature parameters are not studied.
- Portability to other backbones: The approach assumes a naive-resolution ViT (Qwen). Generalization to encoders without this property or to different MLLM families (e.g., LLaVA, InternVL variants) is untested.
- Test-time scaling strategies: No experiments with self-consistency, majority voting, or pass@k for switchable modes; unclear how test-time scaling interacts with mode selection.
- Human-centered evaluation: No user studies on explanation quality, usefulness of mixed-mode traces, or preferences for when the model should expose its reasoning versus suppressing it.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can leverage SwimBird’s switchable reasoning and dynamic latent-visual token budgeting today.
- Adaptive high-resolution document and chart understanding (Finance, Enterprise Software, Public Sector)
- What: Extract and validate fields from invoices, receipts, IDs; reason over charts/figures in regulatory filings and technical reports when text alone is insufficient.
- Tool/Product: “Adaptive Visual–Text Extractor” SDK that switches to latent visual thoughts for dense figures and back to text for logic checks.
- Dependencies/Assumptions: OCR/NER integration still needed; diverse document templates may require light domain fine-tuning; privacy/compliance controls for PII.
- Cost- and latency-aware multimodal inference (Cloud/Edge AI, Energy)
- What: Dynamically allocate visual computation only when perception is required, reducing compute spend for text-centric queries and scaling up for high-res images.
- Tool/Product: “Compute-Aware Inference Controller” that uses delimiters and stopping rules to bound visual-thought spans per query.
- Dependencies/Assumptions: Requires instrumentation for token/embedding budgeting; service-level latency targets and GPU memory budgeting.
- Screenshot-driven RPA and UI testing (Software, DevOps)
- What: Automate workflows from app/web screenshots, interleaving vision localization (buttons, menus) with textual planning and validation.
- Tool/Product: “Switchable-Reasoning UI Agent” that alternates latent visual steps to locate UI elements and text to plan/click/verify.
- Dependencies/Assumptions: Stable screenshot capture; app variability; guardrails to prevent misclicks; integration with test runners.
- Retail shelf analytics and planogram compliance (Retail, Logistics)
- What: Count facings, detect misplaced items, verify pricing labels in high-res shelf images using vision-only or interleaved reasoning.
- Tool/Product: “Planogram Auditor” pipeline that increases visual-token budget for dense shelves; emits textual discrepancy reports.
- Dependencies/Assumptions: Camera quality/angle variability; store-specific templates; periodic fine-tuning for new SKUs/packaging.
- Industrial visual inspection with narrative reports (Manufacturing)
- What: Detect fine-grained defects (scratches, solder bridges) and auto-generate inspection rationales and next-step instructions.
- Tool/Product: “Defect Reasoner” that runs vision-only latent thoughts for detection and text-only logic for severity classification and SOP mapping.
- Dependencies/Assumptions: High-quality labeled samples for adaptation; strict latency constraints on the line; safety-certified deployment.
- Customer support triage from user photos (Consumer Electronics, Telecom)
- What: Read model numbers, interpret indicator lights, verify cable connections; then provide step-by-step remedies.
- Tool/Product: “Visual Helpdesk Assistant” with interleaved mode: focus visually on relevant regions, then reason about troubleshooting steps in text.
- Dependencies/Assumptions: Variable photo quality; disclaimers for critical advice; escalation pathways for uncertain cases.
- Diagram-aware tutoring and assessment (Education)
- What: Solve geometry, physics diagrams, and charts by mixing visual grounding with step-by-step textual explanation.
- Tool/Product: “Diagram Tutor” that remains in text-only mode for symbolic steps, switches to visual latent reasoning for figure interpretation.
- Dependencies/Assumptions: Curriculum alignment; safety filters; guardrails for hallucination; formative assessment integration.
- KYC and identity document parsing with cross-checks (Finance, GovTech)
- What: Parse IDs/badges, match face-photo and printed fields, and validate consistency with application data.
- Tool/Product: “Adaptive KYC Parser” with interleaved reasoning for visual fields and textual rule checks.
- Dependencies/Assumptions: Regulatory compliance, secure processing; varied document formats; bias/fairness audits.
- Scientific figure and chart QA in publishing (Academia, STM Publishing)
- What: Verify that numbers in plots match captions; flag suspicious figure manipulations; interpret axes and legends.
- Tool/Product: “Figure Consistency Checker” that uses vision-only latent spans for reading plots and text-only for cross-reference logic.
- Dependencies/Assumptions: Diverse plotting styles; domain-specific heuristics; non-adversarial intent (not a forensics tool).
- Geospatial image reasoning for rapid assessments (Insurance, Public Safety)
- What: Count rooftops, assess storm damage, detect encroachments in aerial/satellite imagery; generate concise impact summaries.
- Tool/Product: “Geo-Reasoner” with resolution-aware visual token allocation for large tiles; textual summaries for decision-makers.
- Dependencies/Assumptions: Domain adaptation for sensor types; ground-truth availability; uncertainty quantification.
- Smart meter and instrument panel reading (Energy, Industrial IoT)
- What: Read dials/displays under glare or low contrast; reconcile with expected ranges; flag anomalies with textual rationales.
- Tool/Product: “Adaptive Meter Reader” that switches to vision-only for reading, text for reasoning and alerting.
- Dependencies/Assumptions: Image capture quality; device variety; calibration data for ranges.
- Mode-curation and training data tooling (AI/ML, Academia/Industry)
- What: Build balanced datasets labeled by reasoning mode to avoid modality mismatch in future MLLMs.
- Tool/Product: “Reasoning-Mode Curation Toolkit” replicating pass@k filtering and delimiter tagging to create SwimBird-like SFT corpora.
- Dependencies/Assumptions: Access to base evaluators/judgers; task-specific acceptance criteria; licensing of underlying models/data.
Long-Term Applications
The following opportunities require further research, scaling, safety validation, or engineering (e.g., real-time performance, domain data, regulatory approvals).
- Clinical visual–text reasoning assistants (Healthcare)
- What: Interleave latent visual thoughts for perceptual subtleties in radiology/dermatology with textual differential diagnosis and guidelines.
- Product/Workflow: “VQA-to-Clinical-Reasoner” with interpretable audit trails.
- Dependencies/Assumptions: FDA/CE approvals, large-scale domain pretraining, rigorous bias/safety evaluation, interpretable visual-thought exposure.
- Real-time perception–planning modules for robots (Robotics, Warehousing)
- What: Alternate high-resolution perception with textual planning for manipulation, navigation, and anomaly handling.
- Product/Workflow: “Switchable Perception–Planner” on-robot module with compute-aware latent budgeting.
- Dependencies/Assumptions: Video/temporal extensions, low-latency edge deployment, safety and fail-safes.
- Driver-assistance and AV perception reasoning (Automotive)
- What: Condense complex scenes (signs, road markings, occlusions) into latent visual thoughts, then textual policy checks and route decisions.
- Product/Workflow: “Interleaved Scene Reasoner” fused with classic perception stacks.
- Dependencies/Assumptions: Robust multi-camera/video support, certifiable behavior, extensive simulation/real-world validation.
- Scientific discovery from high-throughput imaging (Pharma, Materials)
- What: Identify and reason about fine-grained patterns in microscopy or assay plates; generate hypotheses/explanations.
- Product/Workflow: “Lab Image Reasoner” integrated into LIMS/ELNs, with mode-switching for perception vs. logic.
- Dependencies/Assumptions: Domain-labeled corpora; interpretable outputs for scientists; error-aware pipelines.
- Household assistants for appliance and environment reasoning (Consumer/Smart Home)
- What: Read appliance panels, thermostat displays, and safety indicators; plan corrective actions interleaving perception and text.
- Product/Workflow: “Home Vision–Text Butler” integrated with IoT devices.
- Dependencies/Assumptions: Diverse device generalization, privacy-by-design, on-device inference for security.
- Multimodal workflow orchestration with dynamic tool invocation (Agent Frameworks)
- What: Use mode predictions to trigger external tools (e.g., crop/zoom, OCR, calculators) only when beneficial.
- Product/Workflow: “Mode-Gated Orchestrator” for LangChain/LlamaIndex-like stacks.
- Dependencies/Assumptions: Reliable mode detection; standardized tool APIs; monitoring for tool misuse/overuse.
- Explainability and audit of latent visual thoughts (AI Safety/Policy)
- What: Make continuous embeddings auditable via prototype retrieval or inversion to human-interpretable visual proxies; certify internal reasoning steps.
- Product/Workflow: “Latent Thought Auditor” that logs and explains visual-thought spans for compliance.
- Dependencies/Assumptions: Research on safe inversion/attribution, privacy-preserving logs, standards for evidence trails.
- Energy- and privacy-aware policies for multimodal AI (Policy, Sustainability)
- What: Use dynamic latent budgeting to set compute/energy caps and data-minimization policies (process images only when necessary).
- Product/Workflow: “Inference Policy Controller” with telemetry for carbon/compute budgets and privacy filters.
- Dependencies/Assumptions: Organizational buy-in; standardized metrics for compute/energy; regulatory alignment.
- Video-generalized switchable reasoning (Media, Surveillance, Sports Analytics)
- What: Extend hybrid autoregression and dynamic budgets from images to video sequences for event detection and tactical analysis.
- Product/Workflow: “Temporal SwimBird” with spatiotemporal latent tokens.
- Dependencies/Assumptions: Novel training data, memory-efficient architectures, evaluation protocols for temporal reasoning.
Notes on Feasibility and Dependencies
- Model foundations: Current implementation builds on Qwen3-VL-8B with a ViT encoder; licensing and base model choice may constrain commercial use.
- Hardware: Reported training/evaluation used A100 GPUs; throughput and latency need optimization for production (especially edge/robotics).
- Data and generalization: SwimBird-SFT-92K covers diverse but specific sources; domain-adaptive fine-tuning is recommended for specialized sectors.
- Interpretability: Visual thoughts are continuous embeddings (not human-readable by default), which may complicate auditing in regulated settings.
- Input modality: Paper focuses on images; video and long-document pipelines will require extensions (buffering, memory, temporal tokens).
- Safety and governance: High-stakes domains (healthcare, automotive) demand rigorous validation, monitoring, and compliance frameworks before deployment.
Glossary
- Ablation studies: Controlled experiments that remove or vary components to assess their impact on performance. "Ablation Studies"
- Balancing coefficients: Weights used to trade off multiple loss terms during training. "where $\lambda_{\text{text}$ and $\lambda_{\text{vis}$ are balancing coefficients."
- Chain-of-Thought (CoT): A prompting or training strategy where models generate step-by-step intermediate reasoning before the final answer. "Building on the success of Chain-of-Thought (CoT)~\cite{wei2022chain,kojima2022large} reasoning in LLMs"
- Cosine learning rate scheduler: A schedule that decays the learning rate following a cosine curve over training steps. "A cosine learning rate scheduler is applied with an initial learning rate of 1e-5."
- Cross-entropy loss: A standard loss for classification or next-token prediction that measures the difference between predicted and true distributions. "We train these spans with the standard cross-entropy loss:"
- Delimiters (explicit delimiters): Special tokens inserted to mark and switch between different reasoning modes during generation. "we introduce explicit delimiters in the target sequences."
- Dynamic latent tokens budget: A mechanism that adaptively adjusts the number of latent visual tokens generated based on input complexity or resolution. "Resolution-aware, dynamic latent tokens budget."
- Fine-grained visual understanding: Tasks requiring precise perception of small or detailed visual elements. "Performance on fine-grained visual understanding benchmarks."
- Hybrid autoregressive formulation: A unified generation approach that combines discrete next-token prediction and continuous next-embedding prediction in one model. "we adopt a hybrid autoregressive formulation that unifies next-token prediction for textual thoughts with next-embedding prediction for visual thoughts"
- Interleaved vision-text reasoning: A reasoning mode that alternates between visual and textual steps within a single chain. "interleaved vision-text reasoning"
- Latent embeddings: Continuous vector representations used as internal “thoughts” or states that are predicted during visual reasoning. "making it harder for the model to learn semantically meaningful latent embeddings."
- Latent visual reasoning: Producing and manipulating continuous visual representations (latent tokens) as intermediate steps instead of only text. "recent works introduce latent visual reasoning"
- Mean squared error (MSE) loss: A regression loss that penalizes the squared difference between predicted and target continuous values. "optimized with a MSE loss to reconstruct the embeddings of intermediate thinking images."
- Modality mismatch: Degraded performance that occurs when the chosen reasoning modality (text or vision) does not fit the task’s needs. "mitigating modality mismatch and improving robustness."
- Multimodal agentic models: Systems that orchestrate tools or workflows (e.g., cropping, external modules) to improve multimodal reasoning. "multimodal agentic models that rely on explicit tool/workflow designs"
- Multimodal LLMs (MLLMs): LLMs augmented with visual (and sometimes other) modalities for perception and reasoning. "Multimodal LLMs (MLLMs) have made remarkable progress in multimodal perception and reasoning"
- Multimodal projector: The module that aligns or fuses vision encoder outputs with the LLM’s embedding space. "The vision encoder and multimodal projector are kept frozen"
- Next-embedding prediction: Autoregressive prediction of the next continuous latent vector for visual thoughts. "next-embedding prediction for visual thoughts"
- Next-token prediction: Autoregressive prediction of the next discrete symbol in a text sequence. "next-token prediction for textual thoughts"
- Pass@8: An evaluation metric indicating whether at least one of eight sampled attempts solves a problem. "we compute two pass@8 scores with Qwen3VL-8B"
- Pixel/patch budget control: A mechanism to bound the number of visual tokens produced by the vision encoder by limiting image resolution or patches. "(implemented via pixel/patch budget control)"
- Query-adaptive multimodal reasoning: Selecting and switching reasoning modes (text-only, vision-only, interleaved) based on the input query. "SwimBird performs query-adaptive multimodal reasoning"
- Resolution-aware training setup: Training that adjusts processing based on image resolution to preserve detail without excessive computation. "With this resolution-aware training setup, SwimBird further learns to allocate latent computation dynamically"
- Shifted cross-entropy loss: Cross-entropy computed with a one-step shift between inputs and targets in autoregressive language modeling. "optimized with a shifted cross-entropy loss"
- Supervised fine-tuning (SFT): Refining a pretrained model on labeled examples to specialize its behavior. "This procedure yields 42K high-quality SFT samples"
- Variable-length latent span: Allowing the number of generated latent visual tokens to vary dynamically rather than being fixed. "vision-only traces with a variable-length latent span"
- Visual grounding: Linking textual references to specific visual evidence or regions in an image. "interleaves visual grounding with textual deduction"
- Visual hints: Additional intermediate images provided to guide or improve reasoning performance. "additionally providing the intermediate thinking images as visual hints"
- Visual thought tokens: Continuous latent tokens representing intermediate visual “thoughts” during reasoning. "Instead of generating a constant-length sequence of visual thought tokens"
- Vision-dense tasks: Tasks whose difficulty lies primarily in complex or detailed visual perception rather than textual logic. "improve performance on vision-dense tasks."
- Vision encoder: The component that converts images into sequences of visual tokens or embeddings. "the target embeddings are computed by encoding the intermediate thinking images with the same vision encoder"
- Vision-only reasoning: A mode where the model performs reasoning using latent visual embeddings without textual steps. "vision-only reasoning (continuous hidden states as visual thoughts)"
- Visual Question Answering (VQA): Tasks where a model answers questions about images. "General VQA and multimodal reasoning"
Collections
Sign up for free to add this paper to one or more collections.