- The paper introduces CamCue, a pose-aware multi-image framework that predicts camera poses from language to significantly improve spatial reasoning accuracy.
- It employs a Plücker encoder and pose-adapter cross-attention to integrate camera information, reducing inference time from 256.6s to 1.45s.
- Experimental results on CamCue-Data and other benchmarks show that pose-conditioned synthesis enhances both geometric consistency and reasoning performance.
Pose-Aware Perspective-Shift Spatial Reasoning in MLLMs: CamCue
Motivation and Problem Statement
Multi-image spatial reasoning in Multimodal LLMs (MLLMs) demands robust integration of partial observations across diverse viewpoints for coherent 3D scene understanding. Existing MLLMs fail to achieve reliable perspective-taking when answering questions from language-specified, unobserved viewpoints, exhibiting deficiencies in viewpoint grounding and allocentric scene reasoning despite access to multiple contextual images. These gaps impede spatial intelligence benchmarks which increasingly evaluate performance under perspective shift, requiring explicit mapping of natural-language descriptions to a geometric camera pose and subsequent reasoning from that perspective.
CamCue Framework
CamCue introduces a pose-aware multi-image framework for perspective-shift spatial reasoning, emphasizing explicit camera pose representation as a geometric anchor for viewpoint alignment and novel-view generation. The pipeline integrates per-view camera information into visual features, directly predicts the target camera pose from a natural-language viewpoint description, and leverages pose-conditioned image synthesis as additional evidence for question answering.
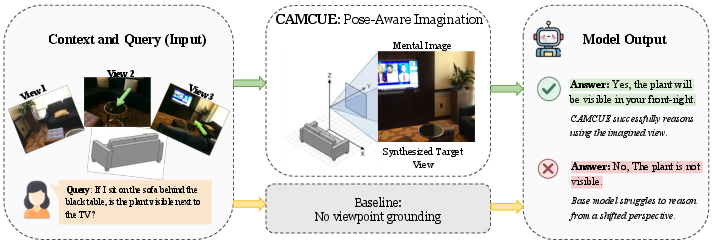
Figure 1: Perspective-shift reasoning with CamCue. CamCue grounds language-specified viewpoint descriptions to explicit camera poses and synthesizes the corresponding target views for spatial QA.
CamCue utilizes a Plücker encoder for dense, pixel-aligned camera ray representation, facilitating patch-wise fusion with vision features. A pose adapter cross-attention mechanism enables joint answer generation and camera pose prediction from visual and textual tokens, producing both the answer and pose in a single inference pass.
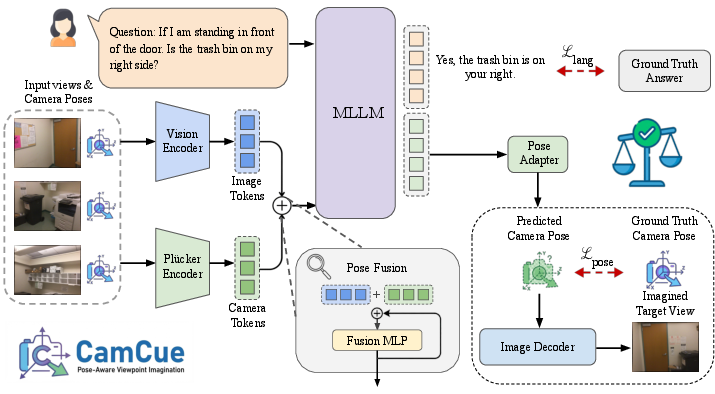
Figure 2: Pipeline overview. CamCue encodes images and camera poses into pose-aware visual tokens, predicts target camera pose from language, and synthesizes the target view, which is used to augment QA.
CamCue-Data Construction
CamCue-Data comprises 27,668 training and 508 test instances, pairing sparse multi-view observations and camera poses with diverse, natural-language target-viewpoint descriptions. Test splits include human-annotated descriptions to evaluate generalization beyond LLM-generated language. Each QA pair requires reasoning from the described perspective and is categorized across Attribute, Count, Distance Order, Relative Relation, and Visibility types.
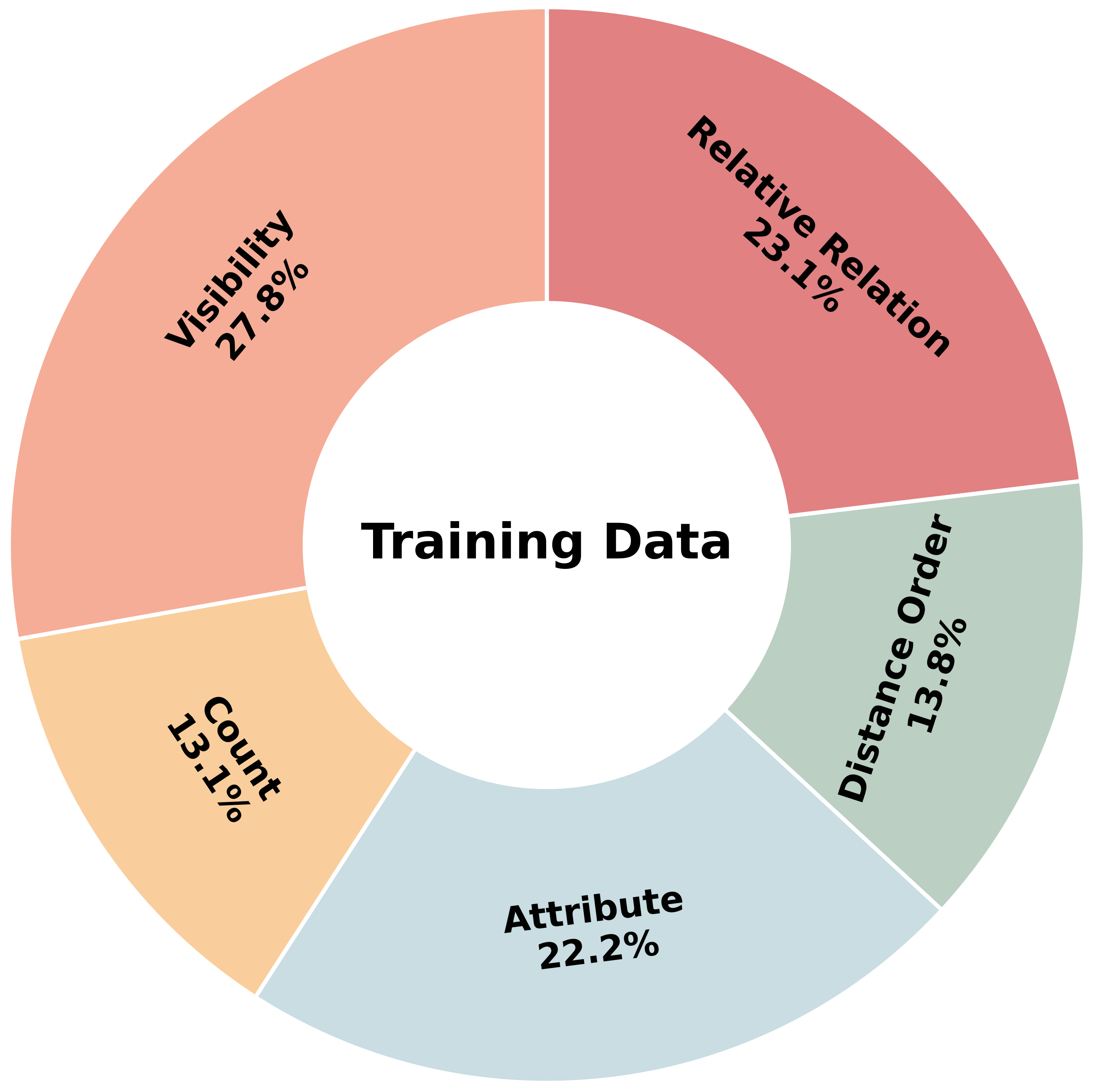
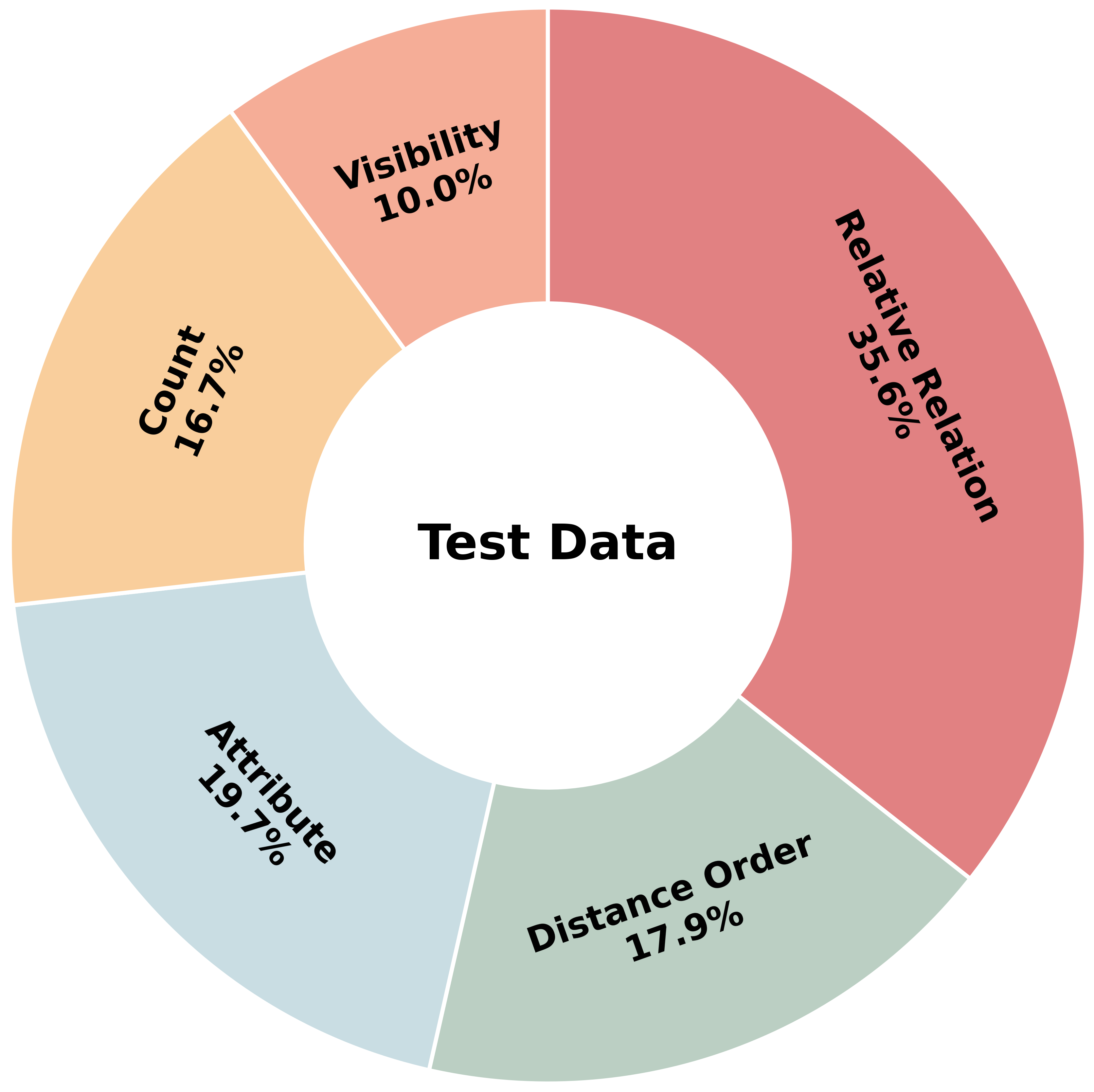
Figure 3: The CamCue-Data training set incorporates a distribution across spatial reasoning QA types.

Figure 4: Representative data samples from CamCue, showing contextual images, viewpoint description, target view, and QA.
Experimental Results
CamCue achieves strong numerical gains on perspective-shift spatial reasoning. On CamCue-Data, CamCue delivers a 9.06% absolute improvement in overall accuracy compared to baseline and prior imagination-based methods such as MindJourney. Particularly pronounced gains are observed in categories sensitive to viewpoint specification, including visibility, distance order, and relative spatial relations:
- Pose Prediction Accuracy: Over 90% of samples have predicted rotation within 20∘ and translation error under 0.5, further rising to 100% rotation and 95.1% translation thresholds for human-written viewpoint descriptions.
- Efficiency: CamCue reduces inference time per example from 256.6s (for iterative imagination-based approaches) to 1.45s, supporting real-time, interactive use.
CamCue also generalizes effectively to general multi-image benchmarks (MindCube, MMSI), demonstrating that pose-aware training does not compromise baseline performance and transfers beyond pose-supervised settings.
Ablation Studies and Qualitative Analyses
Ablations reveal that answer-only QA supervision yields marginal improvements in perspective-shift reasoning. In contrast, pose-only inference without imagined target-view feedback confers significant gains, substantiating the role of camera pose as a geometric prior. Full CamCue, with pose-conditioned target-view synthesis, achieves the highest accuracy. Notably, replacing the synthesized view with the ground-truth target image sets an oracle upper bound, indicating that further improvements are possible with higher-fidelity novel-view synthesis.

Figure 5: Qualitative comparison of imagined target views, highlighting fidelity differences between pose-aware and pose-free generation.

Figure 6: Additional qualitative examples and failure cases. Comparison illustrates CamCue's advantages in maintaining geometric consistency compared to pose-free generators, which often hallucinate or misalign content.
Pose-aware generation constrains imagination via the predicted camera pose, reducing hallucination and viewpoint misalignment commonly observed in pose-free, text-guided image generators (e.g., Nano Banana). This ensures the synthesized view remains faithful to physical scene geometry and supports robust spatial QA.
Practical and Theoretical Implications
The explicit grounding of natural-language viewpoint descriptions to camera pose closes a critical gap between language, geometry, and vision in multimodal models. This methodology aligns with existing pose-conditioned generation frameworks and establishes a bridge between language-driven perspective specification and 3D scene fusion. The reduction in inference latency and substantial accuracy improvements mark CamCue as suitable for interactive spatial reasoning in practical scenarios such as robotics, navigation, and embodied QA.
On a theoretical basis, CamCue foregrounds explicit geometric representations as essential for multi-view spatial intelligence, supporting the thesis that allocentric, coordinate-based reasoning surpasses unanchored multimodal fusion. Future MLLM systems for spatial intelligence and embodied cognition would benefit from incorporating pose-aware tokenization, explicit viewpoint anchoring, and feedback from synthesized, pose-grounded visual evidence.
Limitations and Prospects
CamCue's evaluation centers on perspective-shift QA without direct embodied planning or action, suggesting scope for integration with embodied systems. The fidelity of synthesized views remains dependent on the quality of pose-conditioned image generation; reliability-aware QA strategies could mitigate noise from ambiguous or generatively imperfect views. There remains headroom in spatial QA, particularly for fine-grained or ambiguous objects, paving the way for more robust and geometry-aware multimodal architectures.
Conclusion
CamCue advances perspective-shift spatial reasoning in MLLMs by grounding natural-language viewpoint descriptions in explicit camera poses, tightly coupling linguistic perspective-taking with geometric scene fusion and target-view synthesis. The approach delivers consistent accuracy gains, robust pose prediction, and efficiency improvements over prior imagination-based spatial QA models. CamCue's results underscore the necessity of geometric anchoring for multi-image spatial intelligence and signal future developments at the intersection of language, vision, and spatial cognition.

