Emergent Low-Rank Training Dynamics in MLPs with Smooth Activations
Abstract: Recent empirical evidence has demonstrated that the training dynamics of large-scale deep neural networks occur within low-dimensional subspaces. While this has inspired new research into low-rank training, compression, and adaptation, theoretical justification for these dynamics in nonlinear networks remains limited. %compared to deep linear settings. To address this gap, this paper analyzes the learning dynamics of multi-layer perceptrons (MLPs) under gradient descent (GD). We demonstrate that the weight dynamics concentrate within invariant low-dimensional subspaces throughout training. Theoretically, we precisely characterize these invariant subspaces for two-layer networks with smooth nonlinear activations, providing insight into their emergence. Experimentally, we validate that this phenomenon extends beyond our theoretical assumptions. Leveraging these insights, we empirically show there exists a low-rank MLP parameterization that, when initialized within the appropriate subspaces, matches the classification performance of fully-parameterized counterparts on a variety of classification tasks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview of the paper
This paper looks at how certain neural networks learn. The authors find that, during training, most of the changes in the network’s weights happen in just a few directions, not across all possible directions. In simple terms: even though a network can have a huge number of settings to change, it mostly learns within a small, low-dimensional “space.” They explain why this happens for specific kinds of networks and show evidence that it happens more broadly. They also use this idea to build smaller, more efficient networks that can perform as well as bigger ones.
Key questions the paper asks
The paper focuses on three easy-to-understand questions:
- Do neural networks really learn mostly in a few directions (a low-dimensional space) while training?
- Why does this happen, especially when the network uses smooth activation functions (like ELU or GELU)?
- Can we use this to design smaller “low-rank” networks that work just as well as full-sized ones?
How the researchers studied the problem (methods)
Think of training a neural network like trying to reach a target by taking small steps downhill (this is “gradient descent”). Each step changes the network’s weights. The authors study where these steps go.
They do two things:
- Theory (math analysis) on a simple network:
- They analyze a two-layer MLP (a basic neural network) with smooth activation functions. “Smooth” here means the function changes gently and doesn’t have sharp corners, like ELU or GELU; ReLU is not smooth.
- They consider data with many input features (like pixels) but only a few outputs (like 10 classes in classification). This is common in real tasks: the input dimension is large, but the number of classes is small.
- They use gradient descent and show that most of the learning steps stay inside specific small “subspaces” (sets of directions) that are determined at the start (by the initialization and the first gradient).
- To make the math clean, they fix the second layer during training and use a squared-error loss (which is like measuring how far predictions are from the target with a simple distance). They also assume “whitened” inputs (a common trick that treats different features fairly). Later, they test more realistic settings too.
Everyday analogy: Imagine you’re exploring a giant city but almost all the interesting places you need to visit are along a couple of main roads. Even though there are many side streets, your trip mostly stays on those main roads. Here, the “main roads” are the low-dimensional subspaces.
- Experiments (tests on computers):
- They train deeper MLPs (more layers), with different smooth activations.
- They try more realistic training: cross-entropy loss (common for classification), minibatch SGD with momentum, and Adam optimizer.
- They also use unwhitened data (no special preprocessing).
- They track how the weight updates move and measure whether the changes stick to a small set of directions.
They use tools like singular values and singular subspaces (from linear algebra) to measure “how many strong directions” the updates use. You can think of singular values as telling you how much the network changes along each direction; most change being concentrated in the top few means the process is “low-rank.”
What they found (main results)
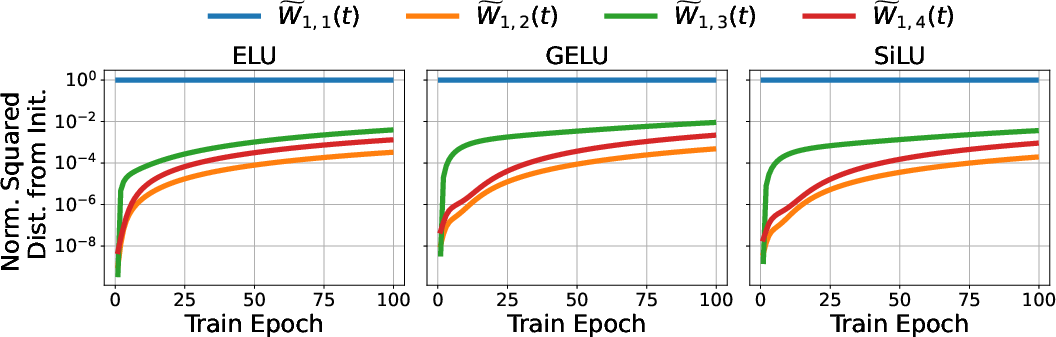
- Theoretical insight: For two-layer networks with smooth activations, the weight updates concentrate in fixed low-dimensional subspaces across training. These subspaces are essentially set at the beginning (based on the initial weights and their first gradient). The number of important directions is tied to the number of output classes K; they show the “small-update” part of the weights barely changes outside roughly 2K directions.
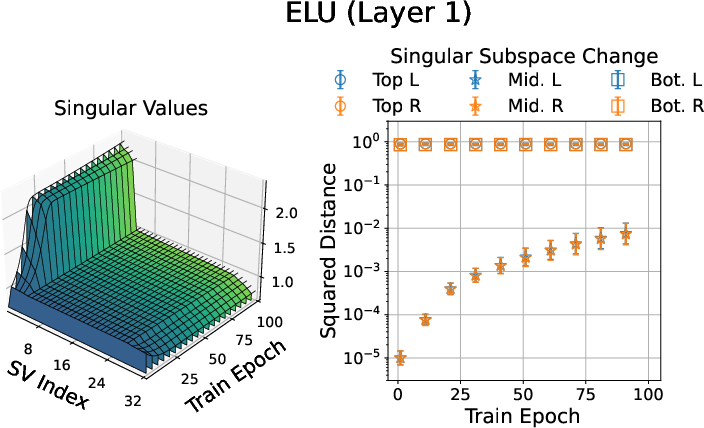
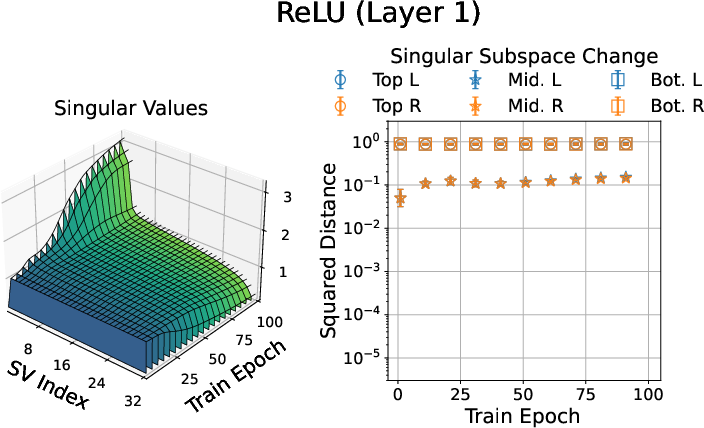
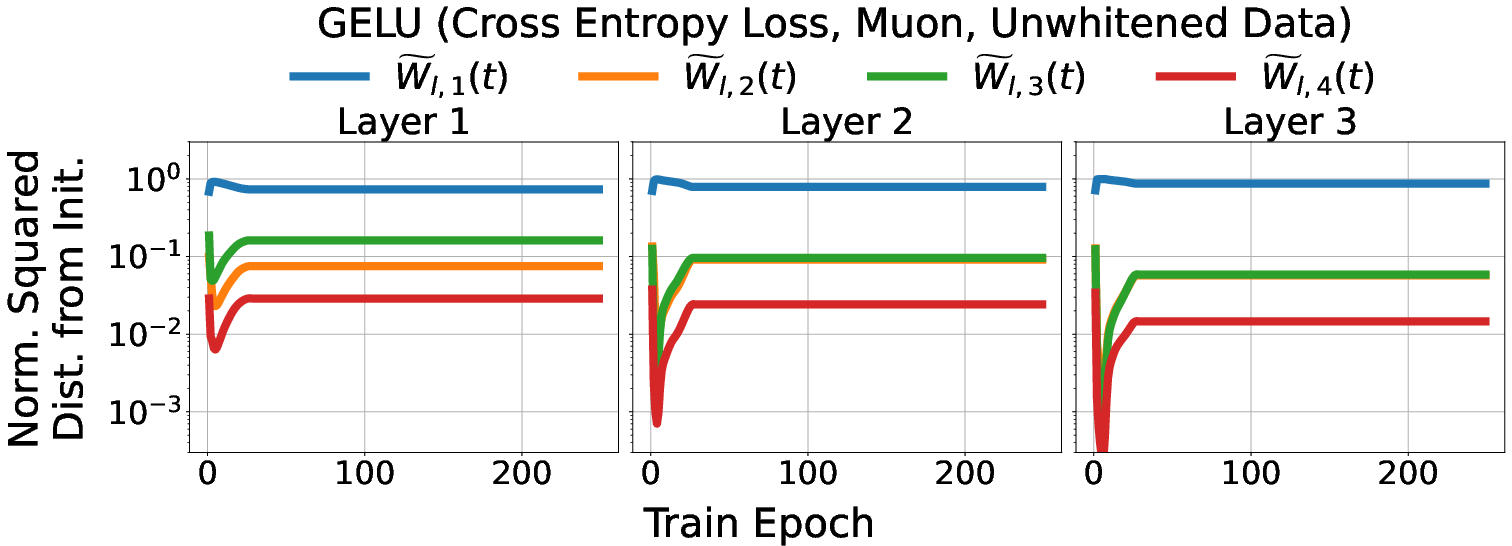
- Smooth activations encourage low-rank learning: In experiments, networks with smooth activations (ELU, GELU, SiLU) change their weights mainly along a few directions throughout training. Nonsmooth ones (like ReLU) spread changes more widely. In other words, smooth activations make learning more focused.
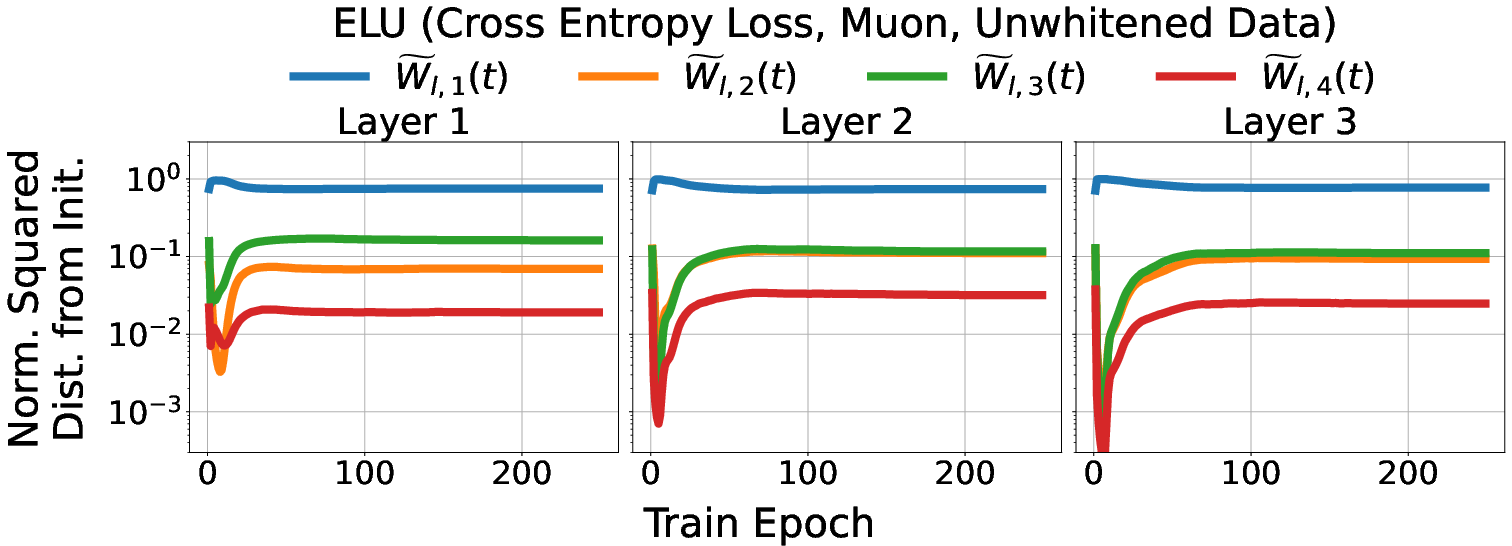
- This behavior holds in deeper networks: Even with more layers, the early layers’ weight updates mostly happen in the corresponding small subspaces defined by the initialization, showing the phenomenon isn’t just for simple networks.
- It still mostly holds with practical training: Using cross-entropy loss, minibatch SGD with momentum, and Adam (and without whitening the data), the networks still show mostly low-rank training dynamics. The effect is a bit weaker with Adam, but it’s still there.
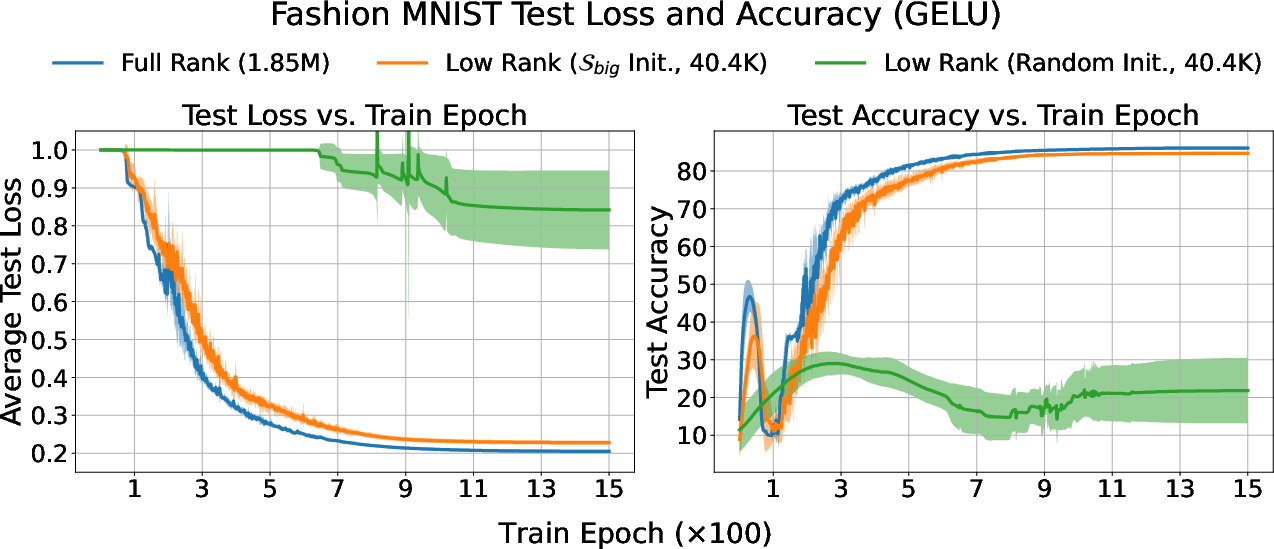
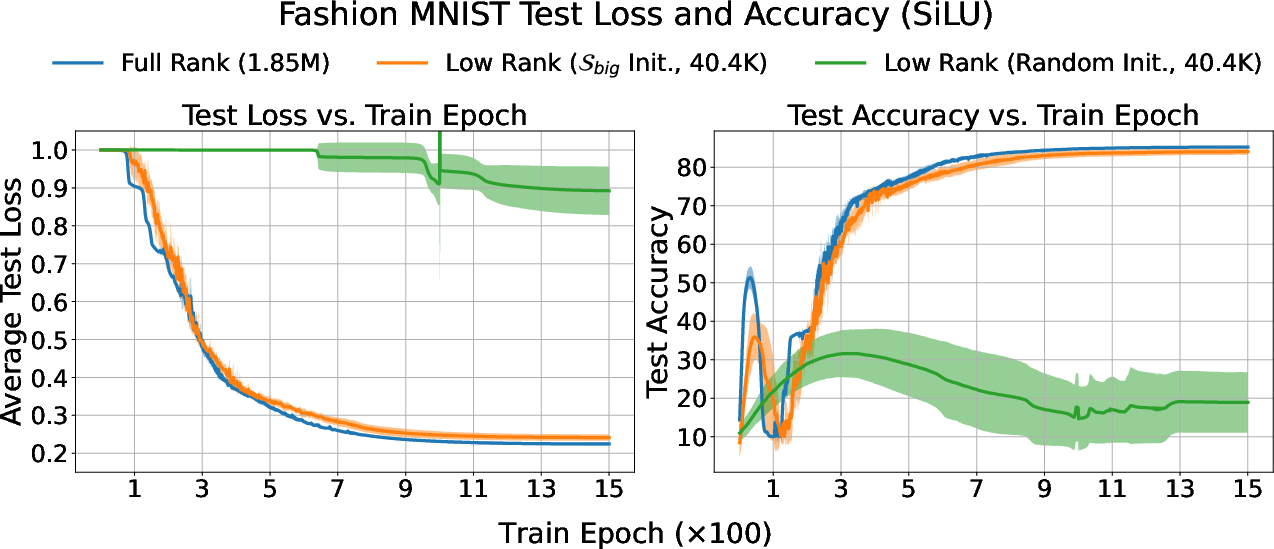
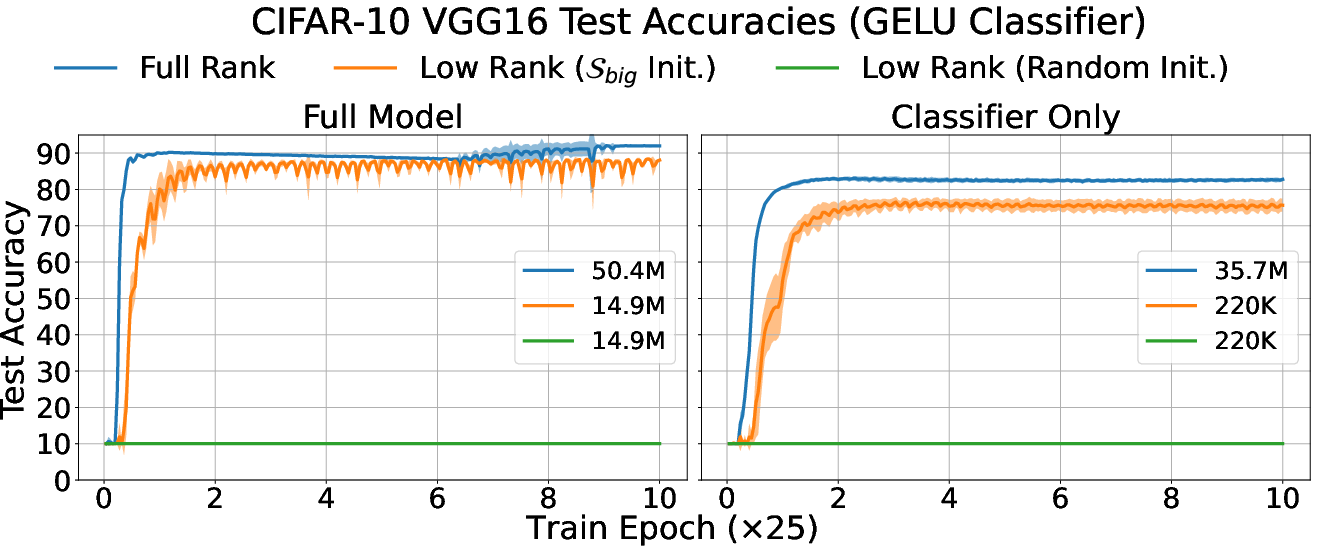
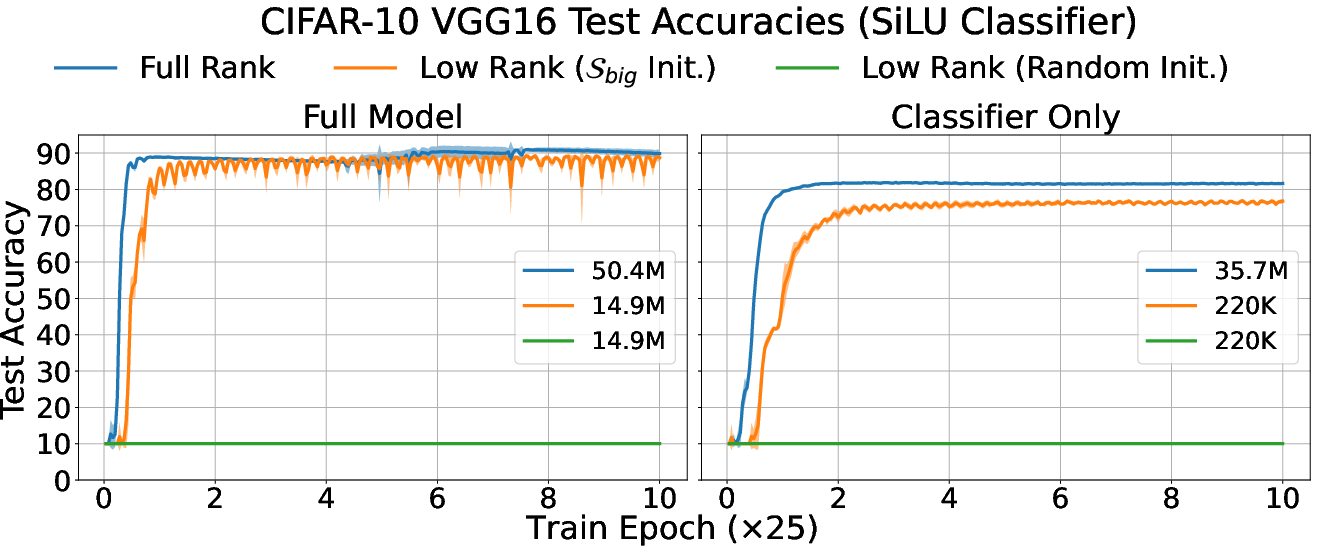
- A useful trick: low-rank MLPs: Based on these observations, the authors build low-rank versions of MLPs—basically, networks whose weights are constrained to those few important directions. If they initialize them correctly (inside the right subspaces), these smaller networks can reach almost the same classification accuracy as full-sized networks on tasks like Fashion-MNIST and CIFAR-10.
Why this is important:
- It explains (theoretically and empirically) why many modern “low-rank” training methods (like LoRA) work so well: because the network naturally learns in low-dimensional spaces.
Why this matters (implications and impact)
- Faster, cheaper training: If most learning happens in a small set of directions, we can focus updates there. That means fewer parameters to train, less memory usage, and faster training—especially useful for big models.
- Better fine-tuning: Low-rank adaptation methods (like LoRA for LLMs) become more justified. This paper offers a reason “under the hood” for their success.
- Model compression: You can keep performance while making models smaller. This helps deploy neural networks on phones or embedded devices.
- Understanding neural learning: It gives a clearer picture of how neural networks learn: despite having many parameters, they often use only a few meaningful directions during training, especially with smooth activations and small output dimension.
In short: This paper shows that neural networks with smooth activation functions tend to learn in a few main directions. That insight helps us design smarter, smaller, and more efficient models without sacrificing accuracy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions that remain unresolved and could guide future research:
- Scope of theory limited to two-layer MLPs with smooth activations
- No formal guarantees for deeper networks; the “small-update subspace” is defined heuristically via recursive initialization but lacks proof of invariance or bounds analogous to the two-layer case.
- No analysis of how depth, width, and layer shapes affect subspace dimensions, stability, or alignment dynamics.
- Dependence on whitened inputs and small output dimension
- Theory assumes whitened data and K < d/2; empirical results suggest approximate behavior with unwhitened data, but no conditions are provided for when subspace invariance persists without whitening.
- Theoretical characterization when K is not small (e.g., regression or multi-label settings) is absent; thresholds or additional structural conditions on X that preserve low-rank dynamics are not identified.
- Fixed second layer assumption
- The analysis freezes W2; it remains open whether similar low-rank update subspaces exist when both layers are jointly trained (including the interplay of W2 updates with the first-layer subspace).
- Impact of the rank, conditioning, and initialization of W2 on subspace emergence is not studied.
- Smoothness assumptions on the activation
- The theory depends on φ being smooth (bounded φ′, φ″), but no necessary/sufficient conditions are established for low-rank dynamics (e.g., explicit dependence of bounds on β, μ).
- What modifications (e.g., smoothed ReLU, softplus) or architectural tricks restore low-rank dynamics for nonsmooth activations are not analyzed.
- Optimizer and loss function mismatch between theory and practice
- Theory covers full-batch GD on squared-error; empirical observations show approximate phenomena under cross-entropy, SGD with momentum, and Adam, but there are no theoretical results for these settings.
- The effect of stochasticity (minibatching), optimizer-induced momentum/variance, and adaptive learning rates on subspace alignment and rank is not quantified.
- Technical assumptions on gradient singular values and spectral gaps
- The theory requires tail singular values of ∇W1L(t) to be small and a spectral gap to apply Wedin’s theorem; conditions under which these gaps emerge (and how they depend on data, initialization scale ε, and step size η) are not derived.
- Tight rates and constants (currently expressed as Θ(·), O(·) terms) for alignment A(t), gradient decay, and update bounds are not specified, limiting actionable guarantees.
- Initialization dependence and sensitivity
- Subspaces depend on initialization (both W1(0) and ∇W1L(0)); the sensitivity of the subspace to initialization distribution, scale ε, and random seed is not quantified.
- No guidance on robust subspace discovery when ε is large or initialization is data-dependent (e.g., Kaiming/Glorot).
- Missing components commonly used in practice
- Bias parameters, normalization layers (BatchNorm/LayerNorm), residual connections, dropout, and weight decay are excluded; their impact on subspace emergence and rank is unknown.
- Extension to architectures beyond MLPs (CNNs, Transformers, attention mechanisms) is not analyzed.
- Subspace identification and practical exploitation
- While U and V are defined theoretically from initialization and the initial gradient, the paper does not provide a practical algorithm for estimating these invariant subspaces in realistic settings (with unwhitened data, stochastic training, and changing loss landscapes).
- Online tracking or adaptive refinement of the subspaces during training is not explored.
- Low-rank parameterization design
- The proposed low-rank MLP parameterization lacks a principled choice of rank r (vs. the theoretically motivated 2K) and does not analyze trade-offs between rank, accuracy, and stability.
- Initialization “within the appropriate subspaces” is crucial, but the method to construct these initializations for deeper networks (and under practical constraints) is not specified.
- Generalization, robustness, and scalability
- The empirical validation primarily considers synthetic data and classification on Fashion-MNIST and CIFAR-10; broader evaluation on diverse, large-scale, and distribution-shifted datasets is missing.
- The effect of label noise, class imbalance, and data augmentation on subspace emergence and low-rank dynamics is not studied.
- Computational savings (memory, throughput) and training-time benefits of the low-rank parameterization are not quantified.
- Interaction with modern fine-tuning and compression methods
- The connection to LoRA and subspace-projected training is mostly conceptual; it remains open how the identified subspaces align with adapter directions, and whether combining these approaches yields provable or empirical gains.
- Whether the emergent subspaces are stable across tasks/domains (supporting parameter-efficient transfer) is not investigated.
- Role of the output head and label structure
- The theory leverages small K and the structure of Y; the dependence on label encoding (e.g., soft labels, multi-hot) and output-layer design (shared heads, multi-task heads) is not examined.
- The origin of the 2K dimension in the “active” subspace (vs. K) is used but not deeply justified under variations in loss, label structure, and biases.
- Convergence and critical points
- No characterization of the specific stationary points reached under GD and how their geometry relates to subspace invariance and rank.
- The possibility of multiple basins with different subspaces, and transitions between them during training (particularly with stochastic optimizers), remains unexplored.
- Measurement choices and metrics
- The primary metric (normalized squared distance of block components from initialization) captures relative contribution but does not isolate causal mechanisms; more direct measures (e.g., projection of updates onto estimated invariant subspaces over time) could provide sharper evidence.
- How subspace alignment A(t) behaves across layers and training phases (early/mid/late) is reported qualitatively but not quantitatively characterized with explicit rates or thresholds.
- Data model assumptions
- Theoretical reliance on whitened X sidesteps data correlations; conditions under which preconditioning (data whitening or feature normalization) can recover theory-like behavior are not derived.
- The sensitivity of the phenomenon to N (number of samples), d (input dimension), and m (width) is not mapped out (e.g., finite-sample vs. asymptotic regimes).
- Reproducibility and implementation details
- Code is “to be released”; until then, reproducibility of the empirical subspace construction and low-rank parameterization remains limited, especially for the deeper network subspace definitions.
These gaps suggest concrete avenues: proving subspace invariance in deeper networks, extending theory to stochastic optimizers and cross-entropy loss, relaxing data and activation assumptions, developing practical subspace estimation algorithms, and evaluating scalability and robustness across modern architectures and large-scale datasets.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s finding that MLP training dynamics with smooth activations concentrate within low-dimensional, initialization-dependent subspaces, and by using the proposed low-rank parameterization when initialized in those subspaces.
- Industry — training cost and energy reduction for tabular and vision MLPs
- Use case: Reduce compute, memory bandwidth, and wall-clock time for training classification MLPs (e.g., fraud detection, churn prediction, credit scoring, industrial defect classification) by constraining updates to the empirically observed low-dimensional subspaces and/or adopting the low-rank parameterization initialized with subspace bases derived from the initial gradient.
- Workflow: Select smooth activations (ELU/GELU/SiLU), compute top-K gradient singular subspaces at initialization, construct layerwise “small-update” subspaces, initialize low-rank factors accordingly, train with SGD/GD; monitor subspace alignment over time.
- Tools/products: “Rank-2K MLP” training module; optimizer state projection add-ons (in the spirit of GaLore/LDAdam) for MLPs that respect the invariant subspaces; subspace-aware LoRA-like adapters for MLPs.
- Sector: Software, energy, finance, manufacturing.
- Assumptions/dependencies: Small output dimension relative to input; smooth activations; ability to estimate gradient SVD efficiently; effectiveness demonstrated on MNIST/CIFAR-style tasks and synthetic data; Adam shows weaker alignment than SGD.
- Industry — on-device and edge inference via low-rank models
- Use case: Deploy compressed, low-rank MLPs for mobile/embedded classification (keyboard next-word prediction for small vocabularies, image filters, on-device anomaly detection in IoT) with minimal accuracy loss when initialized in empirically identified subspaces.
- Workflow: Distill or retrain full models into subspace-initialized low-rank MLPs; validate accuracy; ship compressed artifacts.
- Tools/products: Edge-ready low-rank MLP export pipelines; integration with mobile inference runtimes (Core ML, NNAPI).
- Sector: Robotics, consumer devices, IoT.
- Assumptions/dependencies: Small K tasks; accurate subspace estimation at init; data may be unwhitened but empirical results indicate the phenomenon approximately holds.
- MLOps — training health monitoring and auto-tuning
- Use case: Monitor principal-angle alignment between gradient singular subspaces and their initialization to detect training instabilities, trigger early stopping, or adjust learning rates when subspace misalignment rises faster than gradient magnitude decays.
- Workflow: Add SVD-based probes to training loops; compute alignment metrics; define thresholds for alerts/actions.
- Tools/products: “Gradient Subspace Monitor” dashboards; callbacks for PyTorch/TF that adapt optimizer hyperparameters based on alignment metrics.
- Sector: Software, cloud ML platforms.
- Assumptions/dependencies: Overhead of SVD computation (mitigate with randomized SVD); effectiveness higher with smooth activations and small init scales.
- Academia — reproducible benchmarking and curricula
- Use case: Establish benchmarks for subspace-aware low-rank training on common datasets (Fashion MNIST, CIFAR-10, tabular datasets) comparing smooth vs. nonsmooth activations, optimizers, and initialization scales.
- Workflow: Release code to compute subspaces, apply low-rank parameterization, and evaluate performance vs. full models across optimizers/losses.
- Tools/products: Open-source “Subspace-Init” library; teaching materials demonstrating emergent low-rank dynamics in MLPs.
- Sector: Education, research.
- Assumptions/dependencies: Availability of code; small K (classification) focus; two-layer theoretical basis extended empirically to deeper MLPs.
- Policy and sustainability — immediate carbon impact reporting for MLP training
- Use case: Incorporate low-rank training practices into “Green AI” reporting to reduce energy use in model development pipelines, encouraging smooth activations and subspace-aware updates where applicable.
- Workflow: Add low-rank training checklists to procurement and internal ML governance; document energy savings tied to subspace-aware methods.
- Tools/products: Sustainability guidelines; audit templates referencing subspace-based training.
- Sector: Energy, public policy, enterprise governance.
- Assumptions/dependencies: Evidence strongest for MLPs with small output dimension; limited guarantees for large-output tasks or complex architectures.
- Daily life — faster updates to personalization models
- Use case: Speed up periodic retraining of small personalization models (recommendations for small catalogs, notification prioritization) on consumer devices or edge servers using low-rank subspace-initialized MLPs.
- Workflow: Periodic fine-tuning with subspace-aware adapters; lightweight update packages.
- Tools/products: On-device updater using low-rank fine-tuning adapters.
- Sector: Consumer apps, e-commerce.
- Assumptions/dependencies: Task fits small K classification; subspace estimation at initialization; robustness across non-whitened data confirmed empirically.
- Robotics — real-time control/classification
- Use case: Employ low-rank MLPs in control or perception pipelines where small class counts (e.g., obstacle vs. no obstacle; mode selection) enable efficient, stable training and inference with smooth activations.
- Workflow: Use subspace-initialized low-rank MLPs; monitor alignment to ensure reliability; deploy on constrained hardware.
- Tools/products: Robotics middleware plugin for low-rank MLP inference.
- Sector: Robotics, autonomous systems.
- Assumptions/dependencies: Small output dimension; the approach is strongest for classification tasks.
- Healthcare — tabular risk stratification and triage
- Use case: Train low-rank, smooth-activation MLPs for small-class clinical classification (e.g., triage levels), reducing compute cost and potentially enabling privacy-preserving on-premise training.
- Workflow: Subspace-initialized low-rank training on hospital data; monitor subspace alignment as a stability signal.
- Tools/products: EHR-integrated low-rank MLP trainer.
- Sector: Healthcare.
- Assumptions/dependencies: Regulatory and privacy constraints; data may be non-whitened; empirical robustness indicates practicality.
Long-Term Applications
The following applications require further research, scaling, or development to generalize, automate, or extend the approach beyond current scope.
- Subspace-preserving optimizers for nonlinear networks
- Vision: Design optimizers that explicitly constrain updates to invariant low-dimensional subspaces identified at initialization, with convergence guarantees in nonlinear settings.
- Products: “Subspace-Aware SGD/Adam” with theoretical guarantees; rank-constrained gradient flow variants.
- Dependencies: Stronger theory beyond two-layer networks; efficient and scalable subspace tracking; robustness under data shifts.
- Automated low-rank architecture search and dynamic rank scheduling
- Vision: AutoML tools that infer per-layer ranks and construct low-rank MLPs with initial subspaces tailored to downstream tasks; dynamically adjust rank during training based on alignment and performance.
- Products: Auto-rank selection modules; “Rank Scheduler” for training pipelines.
- Dependencies: Fast, reliable subspace estimation; validation across diverse datasets and large-scale models.
- Extension to CNNs, Transformers, and multimodal/foundation models
- Vision: Generalize invariant subspace identification and low-rank update dynamics to more complex architectures (attention layers, convolutional kernels), enabling subspace-aware fine-tuning for foundation models.
- Products: Subspace-aware adapters for Transformers/CNNs; cross-modal subspace monitors.
- Dependencies: New theory capturing nonlinearity and architectural specifics; empirical validation at scale; handling large output spaces.
- Communication-efficient federated and distributed learning
- Vision: Use low-rank gradient/update representations aligned to invariant subspaces to dramatically reduce communication overhead in federated learning and distributed training.
- Products: Federated “low-rank update codecs”; subspace-synchronized training protocols.
- Dependencies: Secure, accurate subspace sharing; privacy guarantees; resilience to heterogeneous client data and non-iid distributions.
- Privacy-preserving training via low-rank updates
- Vision: Explore whether low-rank, subspace-constrained updates reduce privacy leakage and improve differential privacy budgets while maintaining utility.
- Products: Privacy-optimized subspace training toolkits.
- Dependencies: Formal privacy analyses; empirical studies across sensitive domains.
- Explainability, safety, and certification via subspace dynamics
- Vision: Use persistent subspace structures and principal-angle trajectories as interpretable signals for model behavior, stability, and failure modes; inform certification processes for safety-critical applications.
- Products: “Subspace Explainability” modules; audit tools for regulatory compliance.
- Dependencies: Mapping subspace metrics to human-understandable narratives; standardized reporting.
- Hardware and kernel support for low-rank operations
- Vision: Specialized accelerators and BLAS kernels optimized for rank-constrained matrix multiplies and fast subspace tracking (e.g., randomized SVD), improving throughput and energy efficiency.
- Products: GPU/TPU kernel libraries; embedded DSP support for low-rank ops.
- Dependencies: Hardware vendor partnerships; workload characterization; widespread software integration.
- Policy — standards for energy-efficient AI training
- Vision: Codify best practices (smooth activations, subspace-aware training, low-rank parameterization) into national/international standards and procurement requirements to reduce AI energy consumption.
- Products: Compliance frameworks; energy labels recognizing subspace-aware training.
- Dependencies: Broad evidence across architectures/tasks; stakeholder consensus; governance mechanisms.
- Education — curricula on subspace-aware learning
- Vision: Integrate invariant subspace dynamics and low-rank training into ML education, building practitioner awareness of computational and sustainability benefits.
- Products: Course modules; interactive labs.
- Dependencies: Mature teaching materials; accessible tooling.
- Cross-domain small-K analytics platforms
- Vision: Turn the insight “output dimension governs effective update rank” into platforms tailored for small-class classification across sectors (healthcare triage, industrial QA, public safety alerts), providing low-rank first solutions before scaling up.
- Products: Turnkey small-K low-rank ML services.
- Dependencies: Domain adoption; integration with existing data pipelines; accuracy guarantees for critical use cases.
Global assumptions and dependencies affecting feasibility
- The strongest theoretical guarantees are for two-layer MLPs with fixed second layer, whitened inputs, squared-error loss, small output dimension K relative to input dimension, smooth activations, small initialization scale, and carefully chosen step sizes.
- Empirically, the phenomenon extends to deeper MLPs, cross-entropy loss, SGD with momentum, Adam (to a lesser extent), and unwhitened data, but performance and subspace alignment can vary with optimizer and activation choice.
- Practical deployment requires efficient subspace estimation (e.g., randomized SVD), scalable monitoring, and careful hyperparameter selection; benefits diminish as output dimension grows or in highly nonstationary tasks.
Glossary
- Adam: An adaptive stochastic optimization algorithm that adjusts learning rates using first and second moments of gradients. "We also show this phenomenon approximately holds for networks trained using SGD with momentum and Adam."
- Cross-entropy loss: A classification loss that measures the divergence between predicted probability distributions and target labels. "all on cross-entropy loss"
- ELU: Exponential Linear Unit, a smooth activation function that reduces vanishing gradients and can improve learning dynamics. "In the network's first layer, the middle singular subspace evolves very slowly throughout training, especially compared to that of the network."
- Frobenius norm: A matrix norm equal to the square root of the sum of the squares of all entries; the Euclidean norm of the matrix viewed as a vector. "We use , , , and to respectively denote the singular value, Frobenius norm, matrix-$1$ norm, and maximum magnitude element."
- GELU: Gaussian Error Linear Unit, a smooth activation that weights inputs by their magnitude using the Gaussian cumulative distribution. "three had smooth activations (, , )"
- Gradient descent (GD): An iterative optimization method that updates parameters in the direction of the negative gradient of the loss. "multi-layer perceptrons (MLPs) under gradient descent (GD)."
- Invariant low-dimensional subspaces: Fixed subspaces of comparatively small dimension in which the parameter updates concentrate during training. "the weight dynamics concentrate within invariant low-dimensional subspaces throughout training."
- Leaky-ReLU: A ReLU variant that allows a small, non-zero gradient for negative inputs to mitigate dead neurons. "(, , )"
- Low-rank adaptation (LoRA): A fine-tuning technique that adds trainable low-rank adapters to frozen model weights to reduce training cost. "low-rank adaptation (LoRA) \cite{hu2022lora} has recently emerged as a popular fine-tuning technique for LLMs by adding a low-rank adapter to frozen pre-trained weights."
- Low-rank parameterization: Representing model weights or layers with low-rank structures to reduce dimensionality and computation while retaining performance. "there exists a low-rank MLP parameterization"
- Matrix-1 norm: A matrix norm defined as the maximum absolute column sum. "We use , , , and to respectively denote the singular value, Frobenius norm, matrix-$1$ norm, and maximum magnitude element."
- Neural collapse: A phenomenon during late-stage training in classification where within-class features converge to their class means and class means form a simple geometric structure. "studied neural collapse \citep{papyan2020prevalence} in this exact setting."
- Orthonormal basis: A set of vectors that are mutually orthogonal and each of unit length, spanning a subspace. "Let be orthonormal bases of two -dimensional subspaces of ."
- Orthogonal complement: The set of all vectors orthogonal to a given subspace. "and its orthogonal complement."
- Principal angles (between subspaces): Angles that quantify the alignment between two subspaces; smaller angles indicate greater alignment. "the principal angle between and is defined as such:"
- ReLU: Rectified Linear Unit, a piecewise linear activation function defined as max(0, x). "compared to that of the network."
- Semi-orthogonal matrix: A (generally rectangular) matrix with orthonormal columns or rows but not necessarily square. "assuming is initialized as an -scaled semi-orthogonal matrix."
- SGD with momentum: A stochastic optimization method that accelerates gradient descent by accumulating a velocity vector in directions of consistent descent. "networks trained using SGD with momentum and Adam."
- SiLU: Sigmoid Linear Unit (also known as Swish), a smooth activation defined as x·sigmoid(x). "three had smooth activations (, , )"
- Singular subspace: The subspace spanned by the singular vectors corresponding to selected singular values (e.g., top-K) of a matrix. "Let and denote top- left and right singular subspaces of "
- Stable rank: A continuous proxy for matrix rank defined via norms, indicating the effective dimensionality of a matrix. "GD converges to lower stable rank solutions at smaller initialization scales."
- Wedin's Sin Theorem: A perturbation result that bounds changes in subspace angles (sines of principal angles) under matrix perturbations. "allows us to use Wedin's Sin Theorem \citep{wedin1972perturbation} to upper bound the change in singular subspace alignment."
- Whitened data: Data transformed to have zero mean and identity covariance matrix, removing correlations and scaling differences. "The data is whitened,"
Collections
Sign up for free to add this paper to one or more collections.