- The paper introduces NanoQuant, a post-training quantization method that achieves true sub-1-bit conversion for LLMs using low-rank binary factorization, significantly reducing model size.
- It employs an ADMM-based initialization and STE refinement to mitigate error propagation, ensuring competitive perplexity and robust zero-shot accuracy.
- NanoQuant dramatically boosts inference throughput and energy efficiency across consumer and datacenter hardware, making deployment on resource-limited devices feasible.
NanoQuant: Sub-1-Bit Post-Training Quantization for LLMs
Motivation and Context
The scalability bottlenecks in LLM deployment are primarily due to memory and compute constraints. While weight-only quantization (PTQ) alleviates these constraints, current approaches struggle to achieve true binary or sub-binary quantization without incurring additional storage overhead or substantial accuracy degradation. Binary quantization-aware training (QAT) methods have demonstrated successful compression to 1-bit and sub-1-bit regimes, but their compute/data requirements render them infeasible for massive LLMs (≥70B params) and resource-limited setups. "NanoQuant: Efficient Sub-1-Bit Quantization of LLMs" (2602.06694) proposes a PTQ scheme, NanoQuant, capable of compressing LLMs to both binary and sub-1-bit representations, establishing a new data-efficient compression frontier for extreme deployment scenarios.
Compression Scheme and Theoretical Contributions
NanoQuant formulates extreme quantization as a low-rank binary factorization problem. For each linear layer W∈Rdout×din, NanoQuant decomposes the weight matrix into two low-rank binary matrices (U±1, V±1), alongside full-precision scaling vectors s1, s2. The output approximation is:
W≈s1⊙(U±1V±1⊤)⊙s2⊤
where ⊙ denotes broadcasted element-wise multiplication.
NanoQuant's compression pipeline comprises three sequential stages: (1) error propagation mitigation to absorb accumulated quantization error; (2) low-rank binary initialization via Hessian-aware preconditioning and ADMM-based combinatorial optimization; (3) factorized component refinement employing STE-based tuning of the latent matrices and scales. Notably, precise initialization via latent binary ADMM (LB-ADMM) is shown to significantly outperform conventional low-rank binary initialization schemes in both perplexity and zero-shot accuracy.
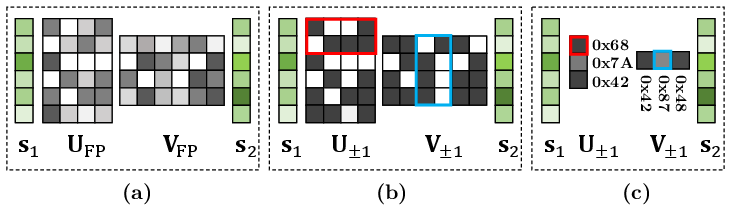
Figure 1: NanoQuant compresses weights via factorization, binarization, and bit packing, enabling highly compact storage.
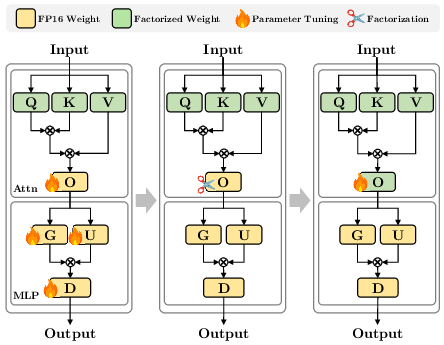
Figure 2: The block reconstruction pipeline incorporates robust error mitigation, ADMM-powered binary factorization, and local STE tuning for optimal alignment.
Theoretical analysis demonstrates that magnitude balancing of latent variables maximizes representational capacity by exploiting the dynamic range of floating-point scales. Robust diagonal preconditioning ensures numerical stability throughout ADMM iterations, with spectral norm bounds limiting outlier-induced instability. A monotonic descent property in the augmented Lagrangian confirms stable convergence of LB-ADMM.
Empirical Results: Compression, Accuracy, Memory, and Throughput
NanoQuant achieves genuine 1-bit and sub-1-bit weight representations, strictly outperforming baseline binary PTQ methods with respect to effective bit-per-weight (BPW) and model size—without excessive metadata or storage overhead. For example, Llama2-70B is compressed from 138GB to 5.35GB (∼25.8x compression), making it deployable on an 8GB GPU. NanoQuant is the only PTQ method to achieve sub-binary compression rates and maintain competitive perplexity.
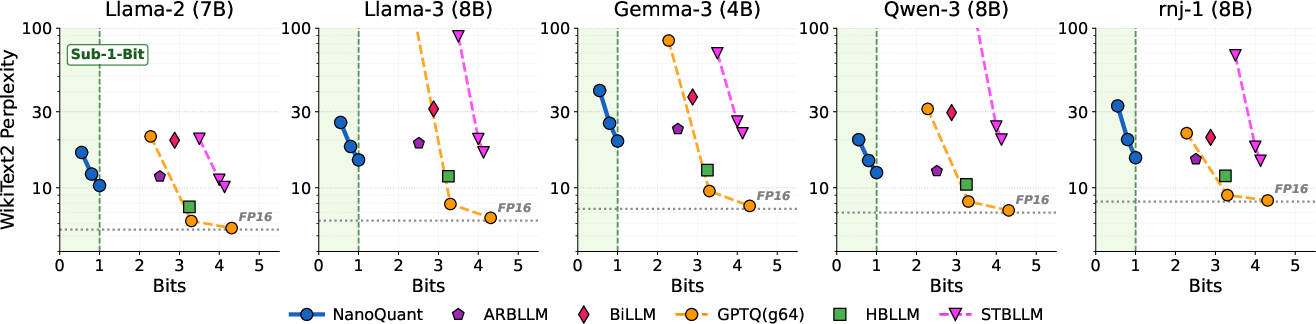
Figure 3: Perplexity comparison on WikiText-2. NanoQuant uniquely achieves functional sub-1-bit compression while outperforming binary baselines.
NanoQuant maintains competitive next-token prediction and zero-shot reasoning performance, outperforming existing binary PTQ and approaching the fidelity of binary QAT methods, which require orders-of-magnitude more data and compute. Data efficiency is highlighted: NanoQuant can binarize models with less than a million calibration tokens, where QAT methods require hundreds of millions.
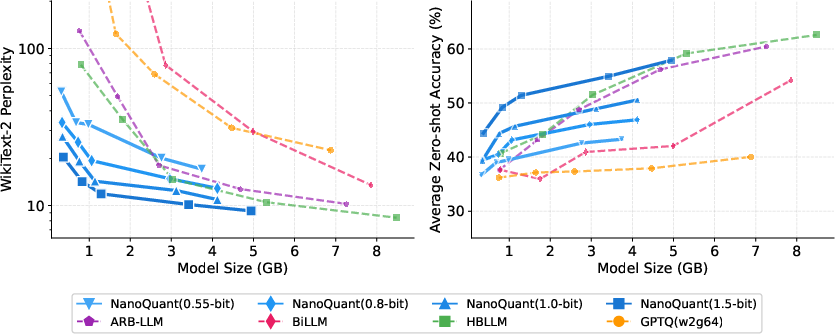
Figure 4: Pareto optimality across Qwen3 models. NanoQuant establishes a new efficiency frontier in the low-bit regime.
Inference ablations showcase dramatic improvements in throughput, peak memory, and energy efficiency across both consumer and datacenter hardware. On an RTX 3050 (8GB), NanoQuant attains up to 3.6× speedup, 5.4× lower peak memory, and 3.9× greater energy efficiency compared to BF16 baselines. On H100 GPUs, up to 10× lower memory is achieved during inference, saturating compute bandwidth.
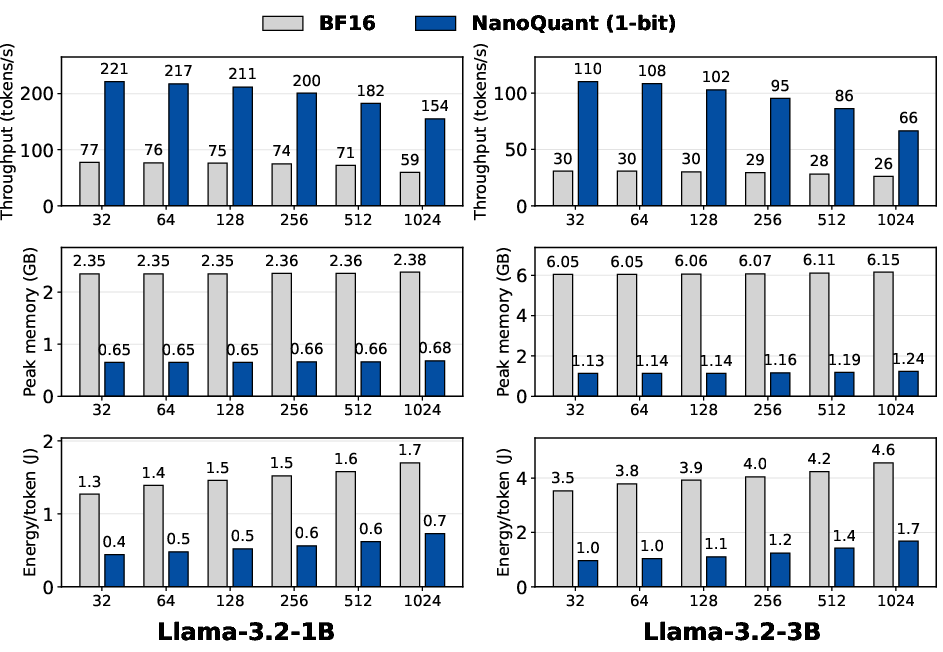
Figure 5: NanoQuant yields higher decoding throughput, lower memory usage, and superior energy efficiency on consumer GPUs.
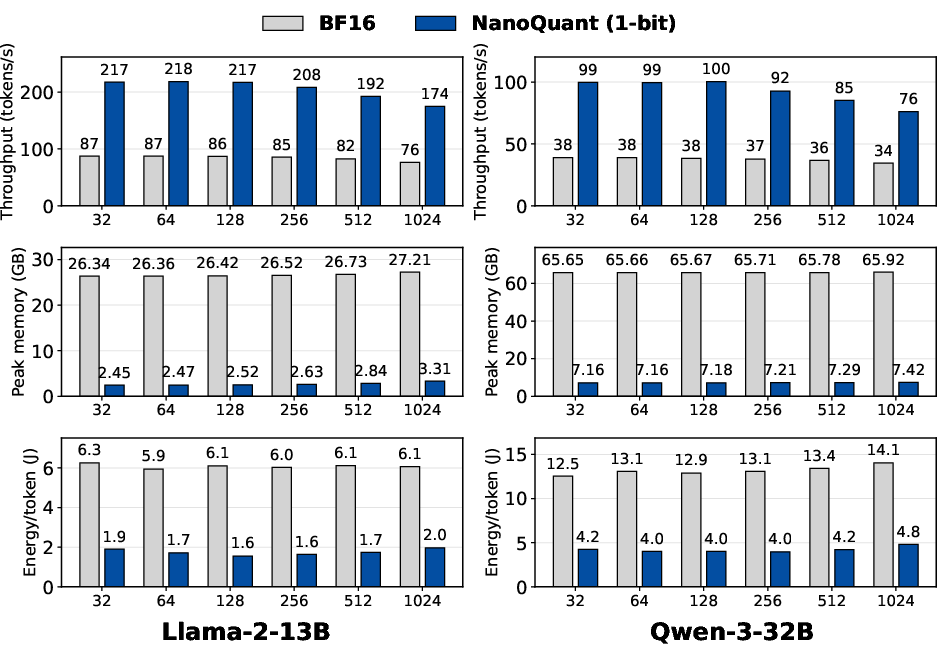
Figure 6: Datacenter throughput and efficiency for Llama-2-13B and Qwen-3-32B surpass BF16 baseline.
Custom binary GEMV/GEMM CUDA kernels leverage packed bitfield storage, enabling fast inference even on edge devices lacking tensor cores. On NVIDIA Jetson TX2, the kernels deliver >12× speedup over PyTorch FP16 for matrix–vector inference.
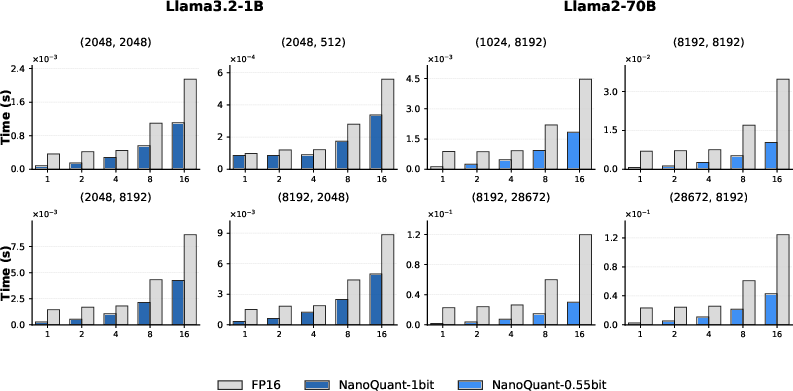
Figure 7: Binary GEMV inference shows substantial speedup versus FP16 on the Jetson TX2 for a range of batch sizes.
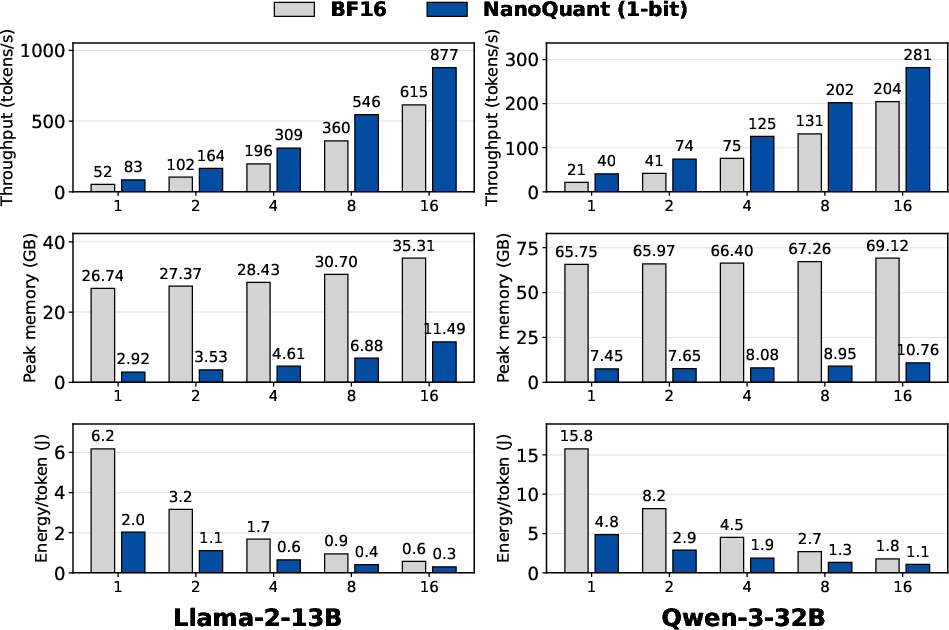
Figure 8: Binary GEMM performance matches BF16 batched inference on A100 80GB GPU.
NanoQuant's decoding performance remains competitive with vector quantization methods (AQLM, PV-Tuning, QTIP), while requiring less data, less compute, and offering reduced memory footprints.
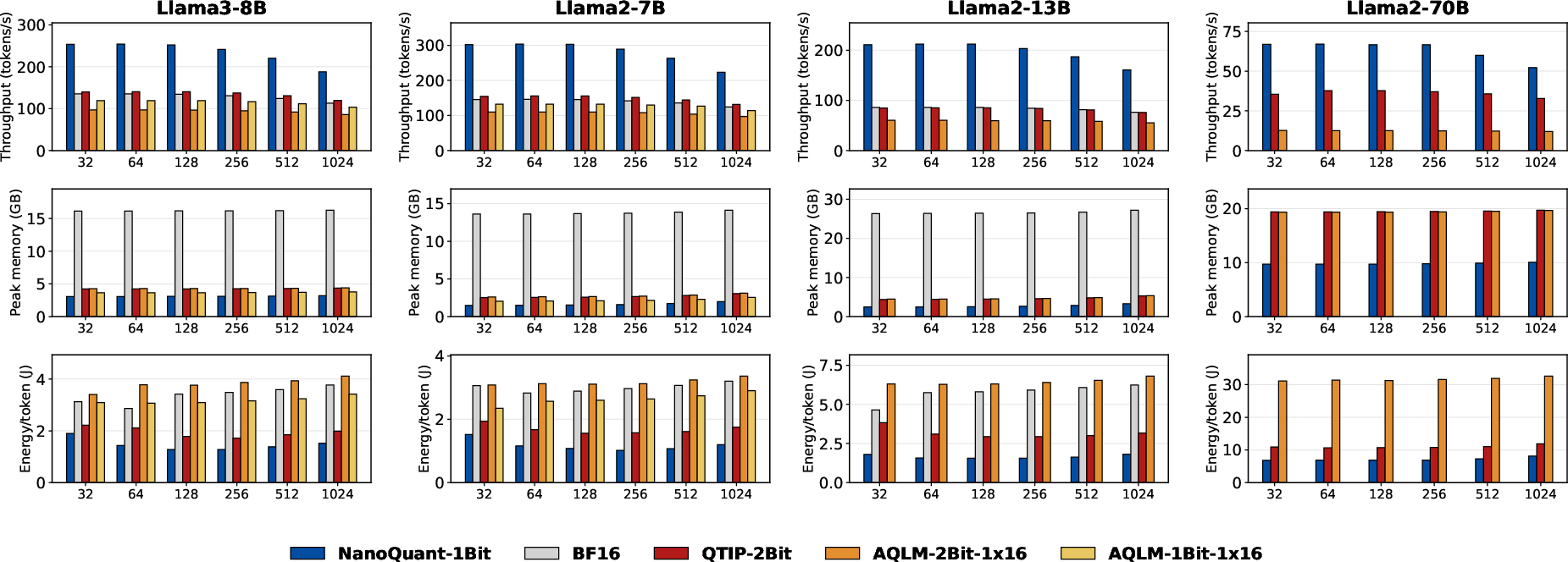
Figure 9: NanoQuant attains superior inference speed and efficiency compared to vector quantization and BF16 on H100.
Ablations and Latent Dynamics
NanoQuant's block-wise reconstruction and robust latent initialization are validated via ablations: LB-ADMM initialization stabilizes optimization and reduces perplexity, outperforming DBF and LittleBit initialization. Factorized component refinement selectively optimizes ambiguous latent weights near the decision boundary, as visualized by sign flip ratios (below 7%; most weights retain their sign post-refinement).
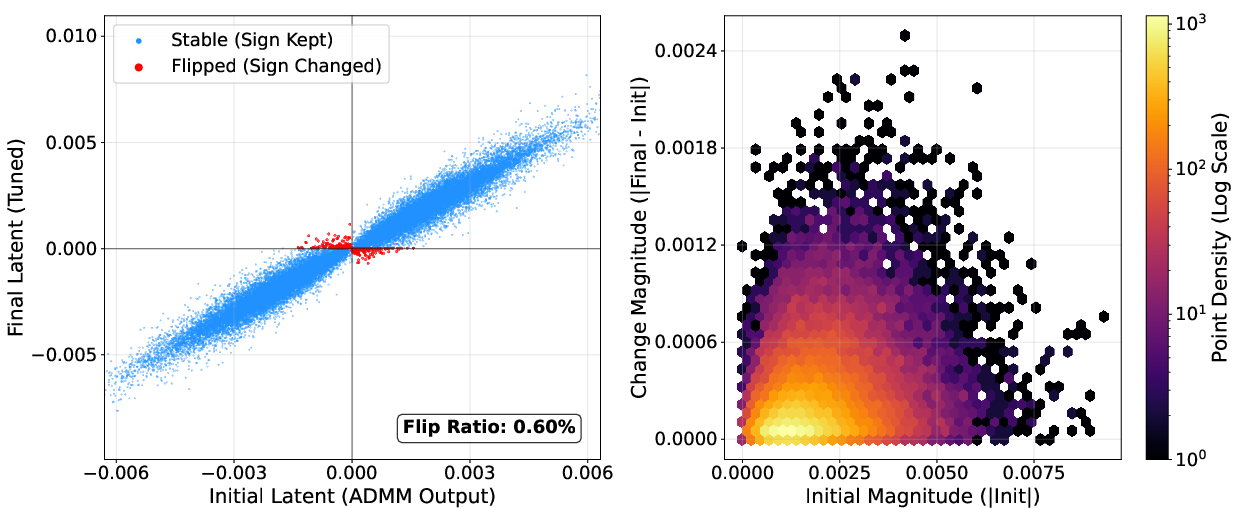
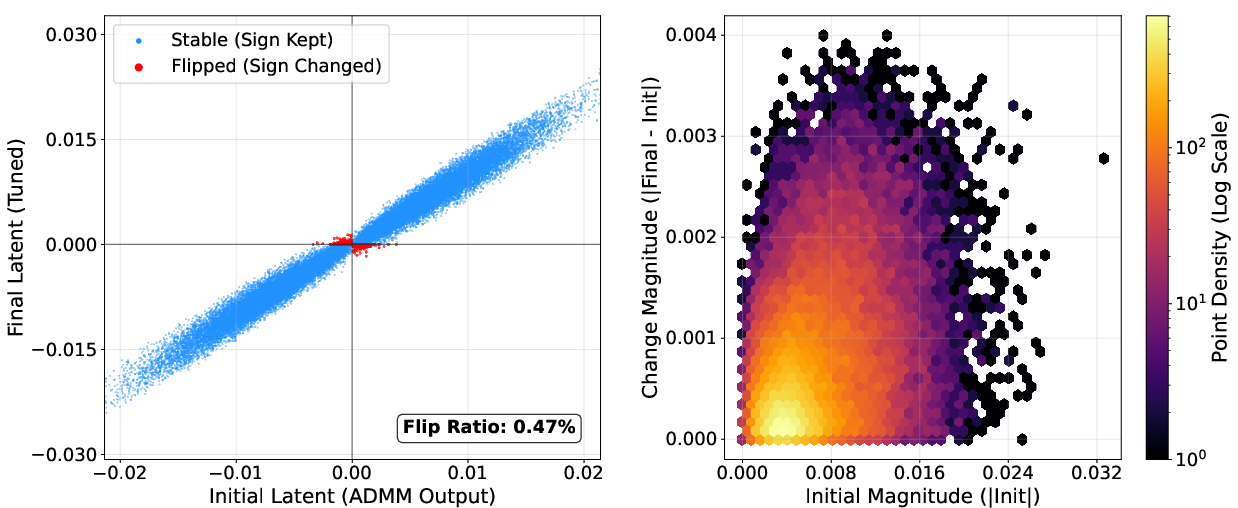
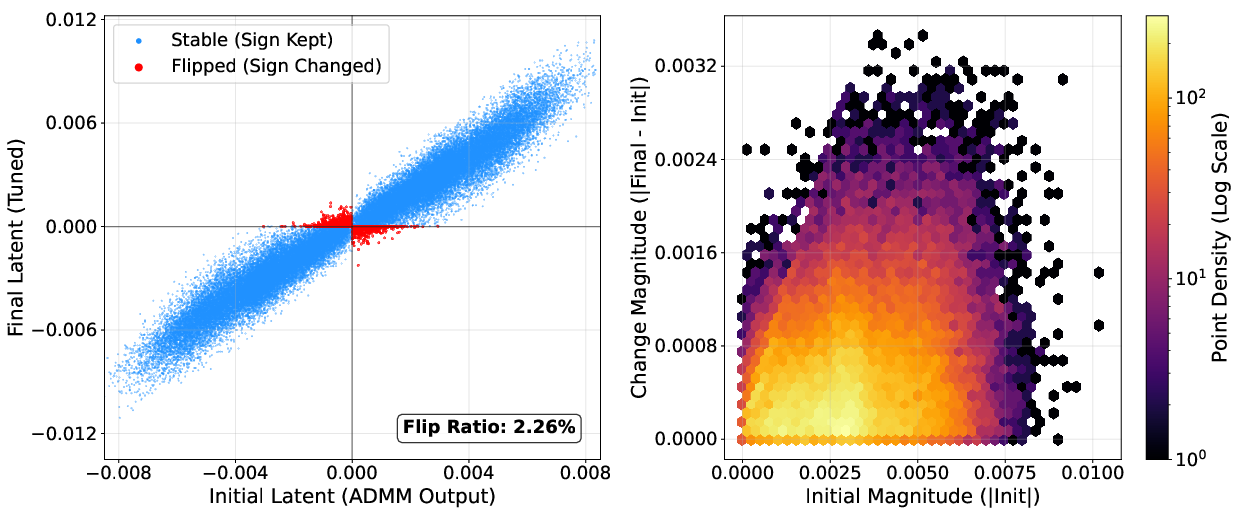
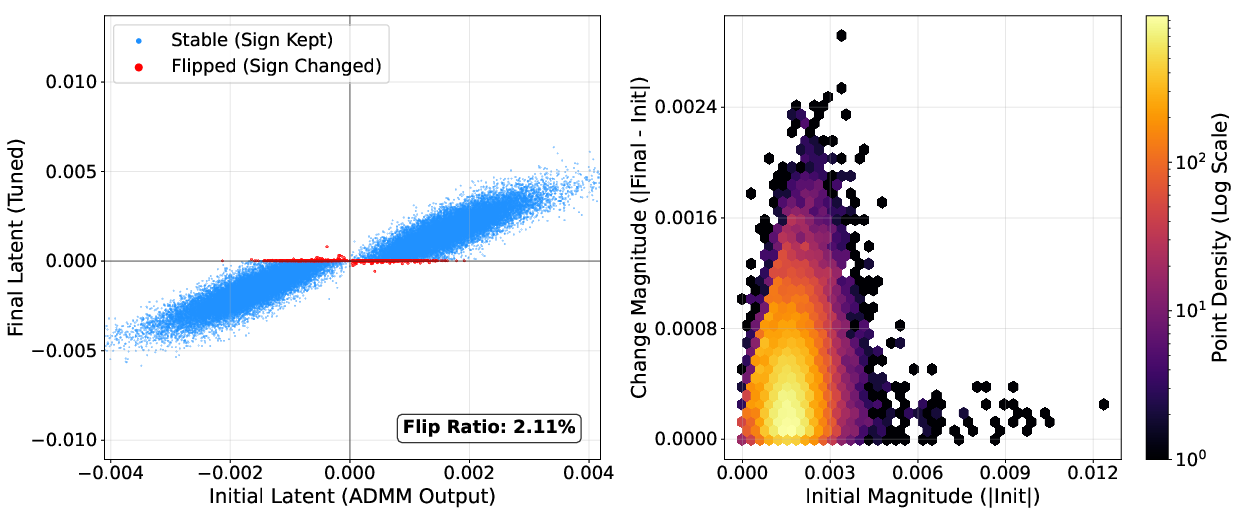
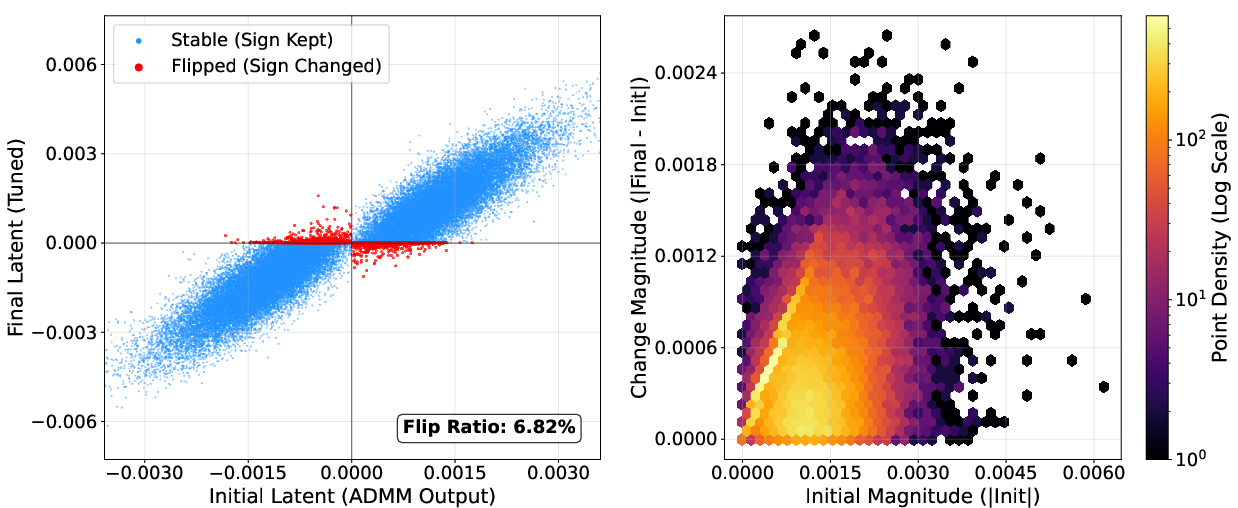
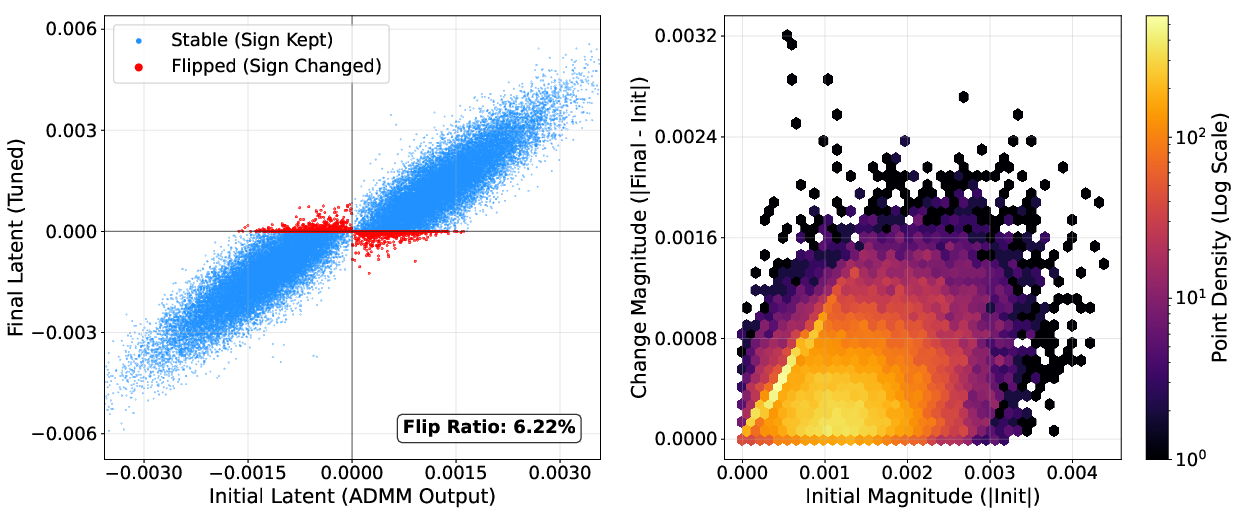
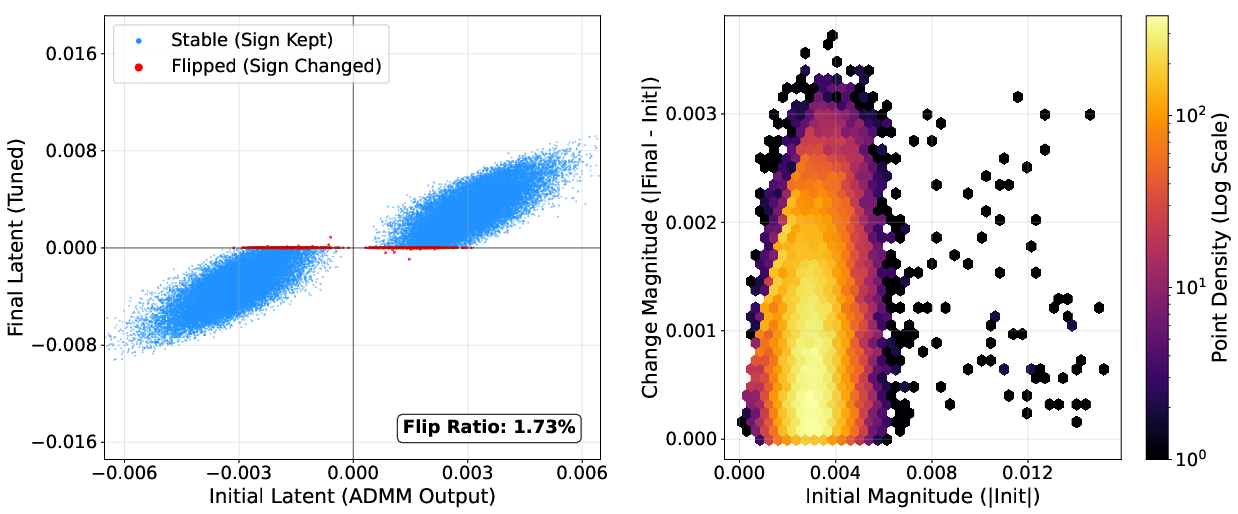
Figure 10: Example layer with minimal sign flips during latent STE refinement, evidencing stable initialization.
Component-wise efficacy analysis confirms that robust initialization, error mitigation, and local refinement each contribute to performance improvements under extreme compression.
Practical Implications and Theoretical Outlook
NanoQuant makes feasible the deployment of massive LLMs (up to 70B parameters) on consumer hardware, democratizing access in resource-constrained environments and minimizing energy consumption. Model storage costs are strictly lower than all existing binary PTQ baselines. The method contracts the gap between PTQ and QAT by leveraging efficient combinatorial factorization and lightweight block-level tuning, rather than full end-to-end retraining.
Efficient memory and compute utilization makes NanoQuant especially relevant for edge deployment, private inference, and scaling scenarios where retraining is prohibitive. Future work includes optimizing runtime for next-generation hardware and investigating compression in higher-complexity reasoning tasks or very large calibration datasets.
NanoQuant's sub-1-bit paradigm opens theoretical avenues regarding the limits of representational capacity in LLMs and the role of binary structures in capturing salient weights under winograd attention mechanisms and data-dependent activation distributions.
Conclusion
NanoQuant constitutes a data- and compute-efficient PTQ framework that achieves authentic 1-bit and sub-1-bit weight quantization for LLMs, including those with ≥70B parameters. Its ADMM-based low-rank binary factorization and block-wise refinement pipeline delivers state-of-the-art accuracy and efficiency, resource-constrained deployment, and sets a new Pareto frontier in the low-bit compression regime. NanoQuant's practical impact spans democratized LLM access, memory/energy reduction, and opens directions for theoretical exploration of binary representational limits in foundation models.