- The paper introduces a unified framework that generates and controls humanoid motions using an autoregressive text-conditioned motion model.
- It combines a Transformer-based VAE with latent diffusion and goal-conditioned RL for dynamic motion tracking and robust sim-to-real performance.
- Quantitative evaluations demonstrate high tracking fidelity, low prediction error, and responsive real-time control across diverse tasks.
Real-Time Interactive Text-Driven Humanoid Robot Motion Generation and Control: Technical Review of "TextOp"
Framework Architecture and Methodological Innovations
"TextOp: Real-time Interactive Text-Driven Humanoid Robot Motion Generation and Control" (2602.07439) introduces a unified framework for seamless, multi-skill humanoid control tightly coupled to natural language streaming, enabling real-time, interactive modification of user intent. The architecture consists of three core modules:
- Interactive Motion Generation: The high-level module employs an autoregressive, text-conditioned motion diffusion model that generates short-horizon kinematic trajectories conditioned on streaming text prompts and recent robot motion history. Architecture-wise, it leverages a VAE combined with a latent diffusion model, both Transformer-based, to encode and decode a robot-skeleton-centric motion representation reflective of actual single-DoF joint constraints.
- Dynamic Motion Tracking: The low-level control policy, an MLP trained via goal-conditioned RL in IsaacLab simulation, receives reference kinematic trajectories and robot state, converting them into executable joint-level commands at high frequency. The tracker is exposed to a distribution-mixed data regime comprising both motion capture and generator-produced trajectories, robustly aligning with both dataset and online generator outputs.
- Deployment Integration: Streaming text commands are encoded (using a pretrained CLIP model), processed by the motion generator, and mapped via the tracking policy onto a physical humanoid (Unitree G1) for real-time execution.
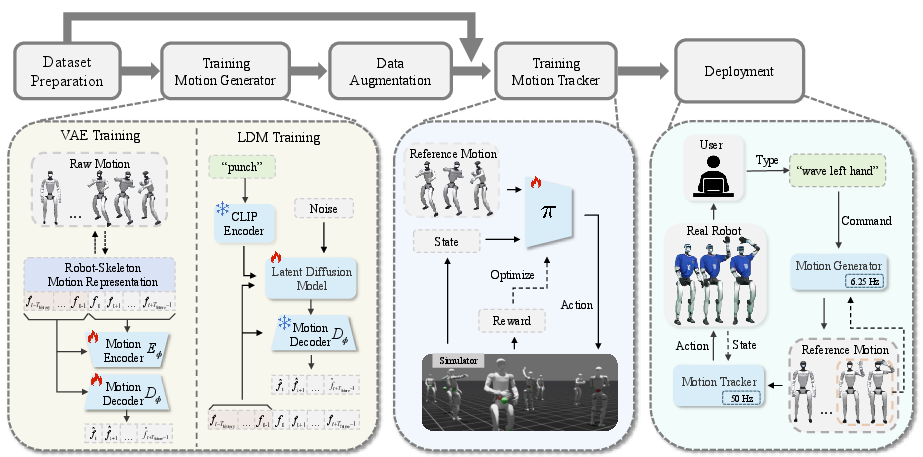
Figure 1: System overview; natural language continuously modulates the generator, whose motion outputs are tracked and executed with low-latency on hardware.
Data Construction and Motion Representation
Data preparation utilizes AMASS and a private set of complex, long-horizon motions. The key innovation is the robot-skeleton feature representation, compactly encoding local incremental joint and root kinematics, foot contacts, and root pose, directly matched to the hardware's single-DoF actuators. For generator training, text-matched motion segments are paired using BABEL annotations, with mirror augmentation for both motion and text, yielding over 83k segment-text pairs.
The tracker dataset is augmented by streaming synthesized generator output from realistic text annotations, assisting sim-to-real alignment across motion diversity.
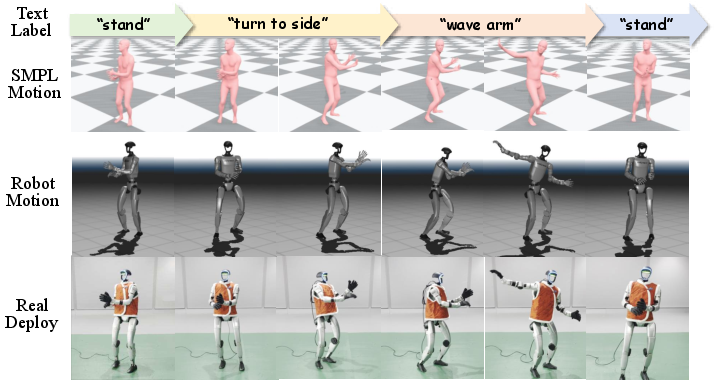
Figure 2: Data format illustration; time-aligned text labels, SMPL (human) motions, and retargeted robot motions are synchronized for both generation and control.
Interactive Generation and Tracking: Model Structure
At inference, the generator autoregressively creates 8-frame future motion primitives, conditioned on 2-frame history and the present text prompt. The robot-skeleton representation ensures compatibility and physical plausibility for kinematic sequences. The VAE is first trained for reconstruction, then its parameters are fixed and the LDM is trained to denoise latents in a DDPM framework with classifier-free guidance (scale σCFG=5).
Self-rollout curriculum replaces historical sequence frames by those generated in previous steps, reducing train-deploy distributional divergence.
The tracker executes with a 5-frame future reference window, utilizing comprehensive observation and reward functions encompassing base kinematics, joint limiting, feet contact, and impact penalties, with domain randomization over friction, CoM, actuator offset, and perturbations. It is trained via PPO for ~1 week using 150k steps on large-scale simulation.
Real-World Execution and Robustness
TextOp enables continuous execution of a wide range of tasks—walking, multiple dance styles, dynamic jumps, instrument-playing gestures, etc.—driven exclusively by streaming text inputs. Notably, complex, long-horizon motions are triggered via unique text labels.

Figure 3: The robot demonstrates a wide spectrum of continuous skills with seamless transitions and precise expression under text modulation.
Long-duration quantitative trials (30 s) with random and looping text command streams yield high success rates (e.g., 16/20 for random, 10/10 for "play the violin") and low tracking errors (global MPJPE down to 107 mm for precision tasks). The robot dynamically recovers from external perturbations with minimal deviation, maintaining semantic consistency with ongoing commands.

Figure 4: The robot displays real-time recovery from physical perturbations, preserving motion stability and command adherence.
Measured user interaction latency averages 0.73 s, with motion generator and tracker latencies at 29.6 ms and 2.2 ms respectively, supporting responsive real-time operation.
Empirical Evaluation and Numerical Results
Motion generation is benchmarked with FID, Diversity, R-precision, MM-dist, Peak Jerk, and Area Under Jerk metrics against baselines (DART+Retarget, BeyondMimic, HumanML3D, RobotMDM). The proposed robot-skeleton representation outperforms alternatives in both segment (e.g., FID 3.07, R@1 0.3) and transition-level metrics (PJ 0.015, AUJ 0.125).
Tracking fidelity is evaluated in simulation with success rate >0.99 for generator-produced motions when data augmentation is used, with global MPJPE at 113.6 mm. Mixed training on both motion capture and generator output yields robust performance on unseen SnapMoGen data, balancing generalization and deployment robustness.
Ablation and Design Analysis
Ablation studies on parameters such as history/future length, primitive count, latent dimension, and guidance scale, establish that Thistory=2, Tfuture=8, Nprim=4, hidden dim 512, and CFG scale 5 optimize trade-offs between semantic alignment, smoothness, and distribution matching. Exposing the tracker to generated motion improves deployment robustness without sacrificing generalization.
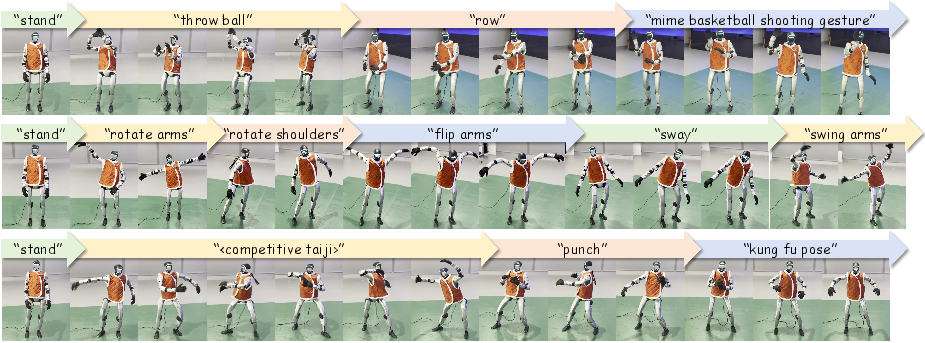
Figure 5: Extended demonstration of diverse skill execution, further validating generalization and motion coherence.
Practical and Theoretical Implications
TextOp establishes a paradigm shift wherein natural language becomes a continuously revisable control interface, superseding static trajectory and teleoperation paradigms for universal humanoid robots. The separation of high-level intent-driven generation from low-level physically-constrained tracking maximizes both responsiveness and stability. Empirical results suggest that robot-skeleton-specific, locally incremental, physically grounded feature representations are essential for high-quality motion generation and execution, facilitating sim-to-real transfer and compatibility with actual hardware constraints.
Still, the framework currently omits environment-awareness and interactive scene reasoning; the robot's behavior is solely determined by text and motion history, without adaptation to dynamic obstacles or objects. Future integration of perception (vision, tactile), environment-augmented motion planning, and multimodal reasoning with LLMs would yield general-purpose, fully autonomous humanoid agents with agentic capabilities.
Conclusion
TextOp delivers a technically rigorous, high-fidelity framework for text-driven humanoid control, where interactive language streaming yields semantic, stable, and physically coherent motion with low-latency feedback. Strong quantitative and qualitative evaluations underline the merits of robot-skeleton-centric representations and distribution-mixed tracker training. While environmental interaction remains an open challenge, the architectural decomposition and empirical demonstration mark TextOp as a reference system for future developments in intent-driven humanoid robotics.