- The paper proposes WMSS, a weak-driven learning framework that leverages historical model checkpoints to inject corrective uncertainty and refine decision boundaries.
- It employs a curriculum-based data activation and logit mixing strategy to amplify gradients in saturated regions, enhancing performance in math reasoning and code generation.
- Empirical results show improvements up to 6.2% over standard SFT, demonstrating sustainable optimization and robust generalization in post-training LLMs.
Weak-Driven Learning: Leveraging Weak Agents for Post-Training Optimization of LLMs
Background and Motivation
The optimization of LLMs through post-training paradigms has largely relied on supervised fine-tuning (SFT), knowledge distillation (KD), and curriculum learning. These paradigms typically reinforce predictions using stronger signals—either ground truth or a "teacher" model. However, as models' confidence increases, the margin between correct and incorrect predictions saturates, and further optimization yields diminishing returns; gradients vanish and decision boundaries rigidify. Existing post-training remedies (self-revision, reflection-based fine-tuning, self-distillation) cannot overcome this plateau, as they continue to emphasize correct targets without reactivating vanishing gradients.
Weak-Driven Learning (WDL) proposes a non-mimicry strategy, utilizing weaker models—historical checkpoints—as active corrective references. Instead of transferring knowledge downward, weak agents inject structured uncertainty by reintroducing informative error signals, forcing strong models to explicitly refine decision boundaries. This inversion in learning flow underpins the WMSS framework ("Weak Agents Can Make Strong Agents Stronger"), providing a sustainable mechanism for breaking post-training stagnation.
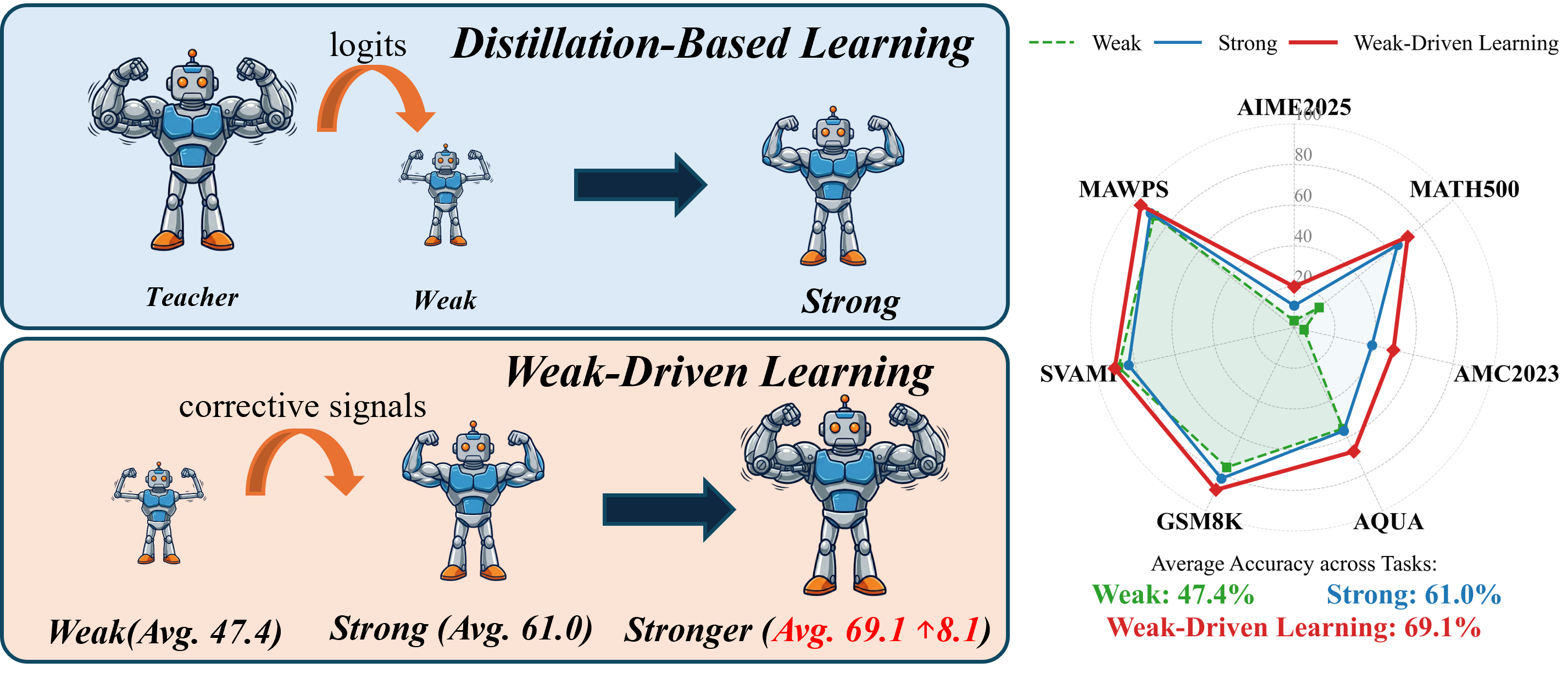
Figure 1: Comparison between distillation-based learning (strong-to-weak) and weak-driven learning (weak-to-strong), illustrating the fundamental shift in learning signal propagation.
WMSS Framework and Algorithmic Details
WMSS operationalizes weak-driven learning via three phases:
- Initialization: Weak agent is instantiated from a base checkpoint (M0), while the strong agent is the result of standard SFT (M1).
- Curriculum-Enhanced Data Activation: A curriculum is dynamically constructed by measuring predictive entropy and its change (ΔH) between weak and strong models for each training sample. Sampling probabilities are determined by a mixture of base difficulty, consolidation, and regression repair signals. This process identifies samples where uncertainty is unresolved or where the strong agent has regressed, thus targeting rich learning gaps.
- Joint Training via Logit Mixing: Training proceeds by optimizing the strong agent on mixed logits ($z_{\mathrm{mix}$), a convex combination of weak and strong logits ($\lambda z_{\mathrm{strong} + (1-\lambda) z_{\mathrm{weak}$). Gradients propagate through these distributions, amplifying optimization pressure in regions where weak models remain confused.
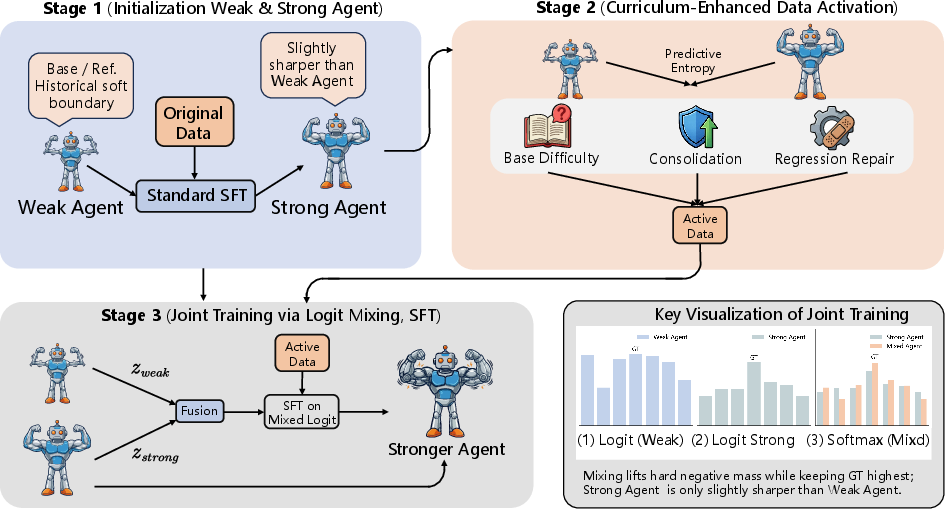
Figure 2: The WMSS framework: initialization, curriculum-enhanced data activation, and joint training principle via logit mixing.
Theoretical Analysis: Gradient Amplification Beyond Saturation
WMSS addresses gradient starvation by leveraging logit mixing. When the strong model's output for non-target tokens becomes highly suppressed, SFT gradients vanish. Mixing in the weaker agent reintroduces probability mass to plausible distractors, thereby amplifying gradients for hard negatives.
Key results:
- Margin contraction by logit mixing: For any negative token k, the mixed model's margin is a convex combination of weak and strong margins, shrinking toward those of the weak agent when it is less confident.
- Gradient magnitude amplification: When mixing increases negative probability mass, gradients for non-target tokens are larger, enabling continued suppression of distractors even after standard SFT saturates.
- Adaptive corrective pressure: The process is mechanistically characterized by three stages: initial amplification in saturated regions, gradient shielding as strong model confidence dominates, and null-space drift in mean logit directions. WMSS maintains optimization efficacy throughout these phases.
Empirical Results and Statistical Analysis
WMSS consistently outperforms baselines (SFT, NEFTune, UNDIAL) across math and code reasoning benchmarks (Qwen3-4B-Base, Qwen3-8B-Base):
- Math Reasoning: WMSS achieves substantial performance gains, e.g., a +5.0% absolute improvement over SFT for Qwen3-4B-Base (64.1%→69.1%), and +6.2% for Qwen3-8B-Base (66.7%→72.9%). The gains are especially pronounced in difficult tasks (AIME2025: 12.2%→20.0%).
- Code Generation: WMSS improves accuracy over SFT and NEFTune, establishing itself as both domain and architecture agnostic.
- Gradient-driven suppression: Statistical logit analysis reveals that WMSS achieves a robust 56.9% reduction in non-target logit mean, with only a marginal increase in target logits. This expands the target-to-background gap and sharpens the decision boundary—allowing robust generalization and resilience against catastrophic forgetting.
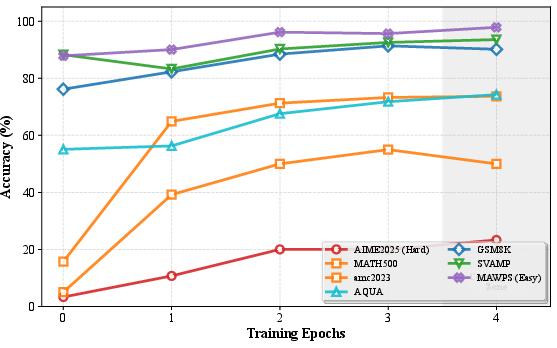
Figure 3: Training trajectory of WMSS (Qwen3-4B-Base) demonstrating rapid acquisition and stabilization across seven math and code datasets.
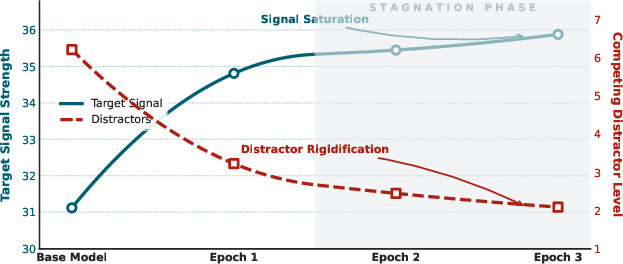
Figure 4: Limits of SFT logit growth—both correct and incorrect token logits saturate, preventing further margin enlargement.
Ablation, Hyperparameter Sensitivity, and Implementation
WMSS's incremental modules (curriculum data activation and joint training) demonstrate additive contributions, with joint training responsible for the decisive performance jump. Sensitivity studies on curriculum and mixing coefficients (λ) confirm stable optima, with the best performance in the λ=0.42–$0.48$ range.
The framework incurs no additional inference cost, as weak models are only used during training. All results are robust to maximum sequence length and training scale, confirming the practical efficiency and generalizability of WMSS.
Practical and Theoretical Implications
WMSS represents an inversion of traditional distillation logic. By exploiting historical weak checkpoints, it demonstrates that latent confusion and distractors within prior model states are the most informative sources for post-training optimization. Theoretical results establish this paradigm as an adaptive regularization mechanism, amplifying structurally aligned correction signals and enabling models to autonomously evolve beyond saturation.
Practically, WMSS enables scalable model improvement without reliance on expensive external supervision or teacher models. It opens a pathway toward self-evolving models, facilitating iterative alignment and performance enhancement in regimes where label scarcity or teacher access are limiting. The paradigm aligns with principles of weak-to-strong generalization and can be readily extended to ensemble-based or multi-agent learning protocols.
Outlook and Conclusion
Weak-driven learning fundamentally reshapes the landscape of post-training optimization by activating and leveraging weak agents as corrective signals. WMSS empirically and theoretically demonstrates sustained performance gains, robust gradient dynamics, and scalable applicability to both reasoning and code domains. The framework proves that effective post-training does not demand continual reinforcement from superior supervision; rather, the "waste" of training—historical uncertainty and distractors—can be harnessed to break optimization bottlenecks. This insight is anticipated to influence future developments in autonomous LLM optimization, curriculum design, and interpretability-driven training regimes.