Latent Reasoning with Supervised Thinking States
Abstract: Reasoning with a chain-of-thought (CoT) enables LLMs to solve complex tasks but incurs significant inference costs due to the generation of long rationales. We propose Thinking States, a method that performs reasoning {\em while} the input is processing. Specifically, Thinking States generates sequences of thinking tokens every few input tokens, transforms the thoughts back into embedding space, and adds them to the following input tokens. This has two key advantages. First, it captures the recurrent nature of CoT, but where the thought tokens are generated as input is processing. Second, since the thoughts are represented as tokens, they can be learned from natural language supervision, and using teacher-forcing, which is parallelizable. Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems, and matching its performance on 2-Hop QA with improved latency. On state-tracking tasks, we show Thinking States leads to stronger reasoning behavior than CoT, successfully extrapolating to longer sequences than seen during training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
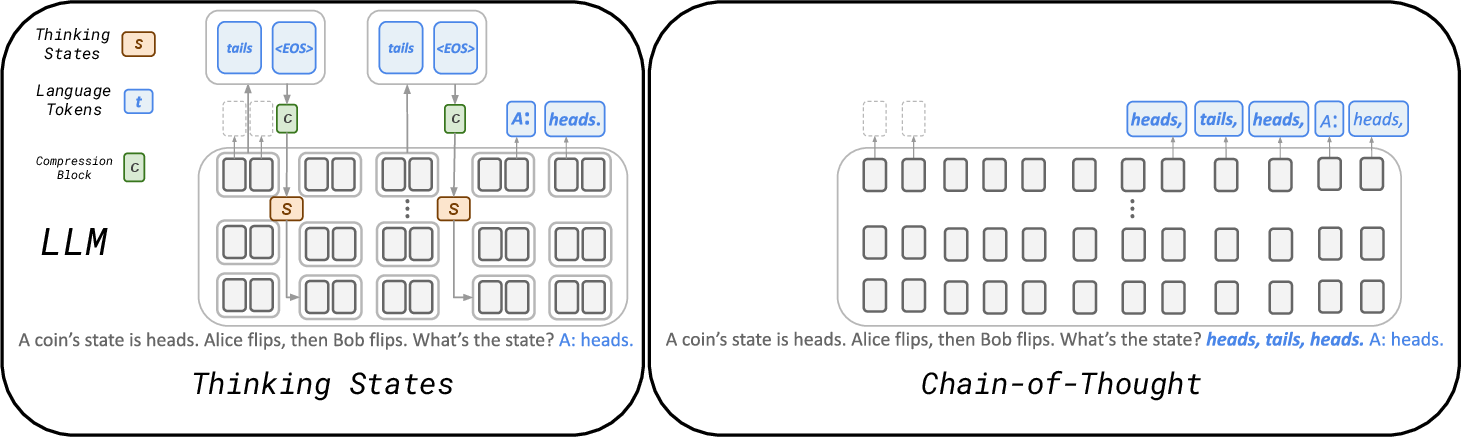
This paper is about teaching AI models to “think” faster and more efficiently. Today, many AI systems solve hard problems by writing out step-by-step explanations (called Chain-of-Thought, or CoT). That helps accuracy, but it’s slow because the model has to generate lots of extra words. The authors propose a new method, called Thinking States, that lets the model think while it’s reading the question, without making the input longer. This keeps the model accurate but makes it quicker.
What questions did the researchers ask?
They focused on three simple questions:
- Can we help a LLM reason well without making it write long explanations every time?
- Can we do this in a way that’s fast to run and also fast to train?
- Will this new way of thinking work on real tasks like math problems, multi-step questions, and tracking changes over time (like flipping a coin many times)?
How does the method work? (Everyday explanation)
Think of reading a long paragraph and taking short notes as you go, instead of finishing the whole paragraph and then writing a full summary.
- As the model reads a few words, it writes a tiny “thought” (a few short tokens in plain language) about what it has figured out so far.
- It then packs that thought into a small “state” (like a compact sticky note) and attaches it to the next part of the text it reads.
- This way, the model keeps a running, compact memory of its reasoning without adding lots of extra words to the input.
In simple terms:
- It “thinks while reading,” not only “after reading.”
- Its thoughts are short and can be taught using normal language examples.
- These thoughts influence the next steps, like passing a helpful hint to your future self.
A quick analogy
- Chain-of-Thought: Writing a full solution on scratch paper before giving the final answer.
- Thinking States: Jotting brief, helpful notes as you read each chunk, so you don’t need a long scratch paper later.
How it’s trained (in simple terms)
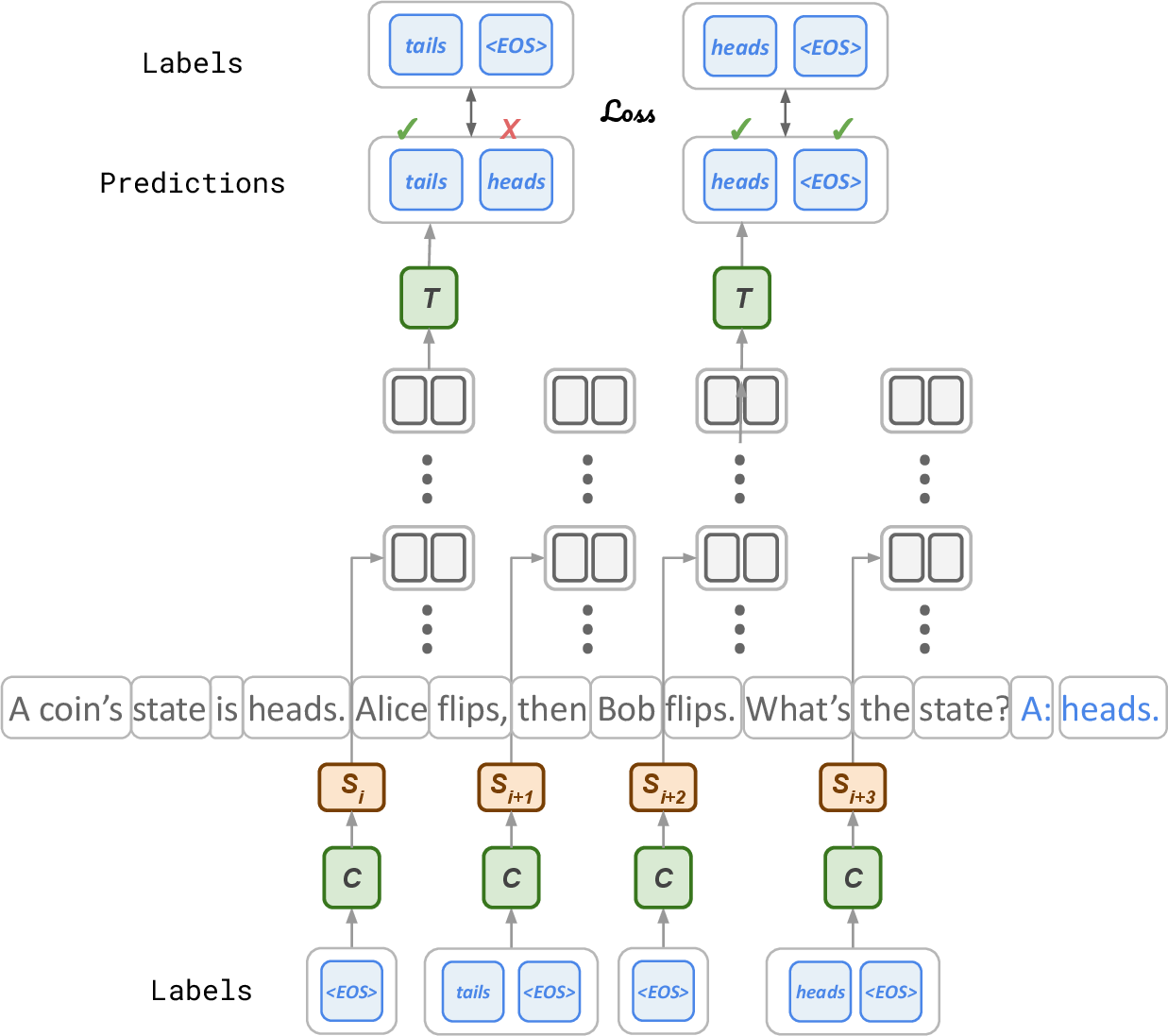
When practicing, the model is shown the “right notes” to take at each point (this is called “teacher forcing”). Because these short thoughts are in normal language, the model can learn them just like it learns to predict words. Showing the correct notes during practice means the model can be trained in parallel and much faster than methods that must “replay” long sequences over and over.
A speed trick at test time
Often, many chunks of text don’t need extra thoughts. The model first guesses that most chunks need no note (just “<EOS>”, meaning “no thought here”), runs everything in parallel, and then only revisits the few chunks that actually need thoughts. This reduces waiting time without changing the final answer.
What did the experiments show?
The team tested Thinking States on three kinds of tasks:
- State tracking: Keeping track of things that change step by step (like flipping a coin from heads to tails many times, or tracking several numbers that get updated).
- Multi-hop question answering: Answering questions that require two linked facts or steps.
- Math word problems: Problems that usually benefit from step-by-step reasoning.
Key outcomes:
- On state-tracking tasks, Thinking States did extremely well and generalized to much longer sequences than it was trained on. In other words, it kept working even when the problems got longer, better than models using full Chain-of-Thought.
- On multi-hop questions (2-step questions), Thinking States matched or nearly matched Chain-of-Thought accuracy while being faster.
- On math word problems, it narrowed the gap to Chain-of-Thought and clearly beat other “latent” (internal) reasoning methods that don’t write out full steps, all while being around 2–3× faster than CoT in their setup.
Bonus: Because the tiny thoughts are written in plain language before being compressed, people can inspect them to understand what the model was thinking—something that’s harder with fully hidden, continuous signals.
Why is this important?
- Faster answers: Many real-world uses of AI need speed. Thinking States keeps much of the accuracy benefits of step-by-step reasoning without the big slowdown.
- Scales better in training: Because the model is shown the correct mini-thoughts while practicing, it can be trained faster and more easily than methods that must “unroll” long sequences.
- More robust reasoning: On tasks that require tracking changes over time, Thinking States generalized better than full CoT, suggesting it learned a stronger internal reasoning process.
- More interpretable than hidden methods: Since the thoughts are initially in natural language, it’s easier to see what’s going on inside the model.
Final takeaway
Thinking States is like teaching a model to take smart, short notes as it reads. This helps it reason step by step without writing long essays, making it both faster and still accurate. The approach works well on tricky tasks (like multi-step questions and math problems) and can handle longer, more complex cases. It’s a practical step toward AI that thinks efficiently, learns quickly, and remains understandable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for follow-up research.
- Dependence on supervised thinking traces: The method requires chunk-aligned natural-language thought annotations per training example. The scalability, cost, and feasibility of producing these annotations (especially beyond synthetic/math tasks) are not evaluated.
- Quality and noise sensitivity of step-to-token alignment: The paper relies on teacher LLMs or rules to insert <T> markers, but does not quantify how alignment errors affect performance. Robustness to noisy or inconsistent alignments and ablations on annotation quality are missing.
- Exposure bias from teacher-forced states: Training uses gold states while inference uses model-generated states. The impact of this mismatch (e.g., compounding errors across chunks) is not analyzed; alternatives like scheduled sampling or DAgger-style training are not explored.
- Generalization to larger models and broader benchmarks: Experiments use 0.5B/1.5B Qwen2.5-Base on synthetic/state-tracking, 2-Hop QA, and a simple GSM-style set. It is unclear how results scale to larger LLMs and harder benchmarks (e.g., GSM8K-original, MATH, HotpotQA, StrategyQA, ARC, BBH).
- Faithfulness of thoughts to computation: Although thoughts are interpretable, there is no evaluation of whether the generated thoughts causally mediate the final answer (e.g., via causal mediation tests, counterfactual interventions, or agreement between thoughts and used latent state).
- Compression bottleneck analysis: The fixed-size state S per chunk may limit capacity. There is no systematic study of how state dimensionality, pooling strategy, or variable-size states affect accuracy and efficiency.
- Injection mechanism design space: States are added additively at a single shallow layer. Alternatives (multi-layer injection, learned gating/FiLM, attention-based conditioning, adapters, or per-head biases) are not explored.
- Choice and learning of chunk boundaries: Chunking is fixed and uniform. The model does not learn when to “think” or how to place boundaries dynamically (event-driven or learned segmentation), nor does it support adaptive thought frequency.
- Handling multiple sequential steps within a chunk: The method acknowledges performance drops when many steps fall within a single chunk but offers no mechanism to trigger sub-chunk recurrence or intra-chunk thinking.
- Branching/uncertainty in reasoning: A single compressed state may force early commitment and suppress exploration. Support for multiple hypotheses (e.g., mixture-of-states, beam over thoughts) is not considered.
- Extension to the decoding phase: The paper focuses on prefill; it does not implement or evaluate thinking-state recurrence during generation (e.g., dynamic compute per output token), despite outlining it as future work.
- Bidirectional/context-aware processing to address “state ambiguity”: The identified limitation (causal backbone commits to the wrong intermediate quantity) is not resolved; bidirectional or lookahead mechanisms are left as future work and untested.
- Quantifying “non-trivial” state frequency: The speculative prefill algorithm assumes most chunks yield <EOS>, but the paper provides no distributional statistics across tasks, nor worst-case (dense-reasoning) latency analyses.
- Formal and empirical guarantees for speculative prefill: Beyond a high-level description, there is no proof of correctness, convergence guarantees, or profiling of overhead from failed speculations and cache invalidations on GPUs.
- Memory/throughput footprint: Wall-time speedups are reported, but there is no profiling of memory (KV-cache, state injection tensors, T/C module overhead) or batch-size effects, especially for long contexts.
- Broader baselines and fairness: Comparisons exclude recent or adjacent methods (e.g., Quiet-STaR RL rationales, pause tokens, dynamic depth/Universal Transformers, test-time compute scaling, ToT/GoT variants, retrieval-augmented approaches). Fairness controls (parameter counts, training budget parity) are not detailed.
- Robustness and adversarial behavior: There is no study of brittleness to prompt variations, distribution shifts, or adversarial distractions that might trigger spurious “thinking” or degrade state quality.
- Multilingual and cross-domain applicability: The approach assumes thoughts in natural language (implicitly English). It remains unknown how performance transfers across languages/domains, or how to supervise thoughts when input and thought languages differ.
- Interaction with retrieval and tools: It is unexplored whether states can integrate retrieved facts/tools (e.g., RAG, calculators) and how to schedule retrieval within the chunk-recurrent loop.
- Training stability and sample efficiency: The paper does not quantify data requirements, sensitivity to limited supervision, or whether self-supervised/bootstrapped thinking traces (or RL) can replace heavy reliance on gold thoughts.
- Impact on general LM capabilities: The effect of fine-tuning with thinking states on broader language modeling or instruction-following quality (catastrophic forgetting, calibration) is not assessed.
- Architectural ablations of T and C: Only shallow ablations are provided (extraction layer and chunk size). There is no study of T/C capacity, parameter sharing with the backbone, pretraining strategies, or number/length of thought tokens per chunk.
- Theoretical understanding of expressivity and “effective depth”: While the paper motivates deep-to-shallow recurrence, it lacks formal analysis of how many “compute-equivalent” layers the recurrence adds, or conditions under which it matches/exceeds CoT expressivity.
- Data and reproducibility: The custom GSM-style dataset (~400k) and alignment pipeline are not described in enough detail for replication (e.g., release status, teacher prompts, noise levels), limiting external validation.
Practical Applications
Immediate Applications
The following applications can be piloted with current LLM fine-tuning pipelines and standard serving infrastructure, given access to model weights and CoT-style supervision.
- * * - Boldened items below denote the core application; parentheses indicate sectors.
- * * - Efficient chain-of-thought replacement in production chat and copilots (software, customer support, productivity)
- What: Swap long natural-language CoT outputs for “Thinking States” to retain most of the reasoning accuracy while reducing latency and token costs.
- Workflow: Fine-tune base LLM with the Thinking Block T and Compression Block C; align existing CoT traces to chunks; deploy “speculative thinking” prefill to cut prefill latency.
- Tools/products: “Thinking States” plugin for Transformer stacks (e.g., Hugging Face, vLLM); a CoT-to-chunk alignment script; prefill kernel with KV-cache integration.
- Assumptions/dependencies: Access to model internals (to inject T/C and shallow-layer state), CoT supervision or a teacher model for alignment, inference server that supports custom prefill steps.
- Lower-cost enterprise QA and RAG with multi-hop reasoning (enterprise search, legal, compliance, finance)
- What: Use Thinking States to perform 2-hop (and small k-hop) reasoning over retrieved passages with comparable accuracy to CoT but faster and cheaper.
- Workflow: RAG pipeline unchanged; inference replaces CoT prompting with internal thoughts and state injection; log per-chunk “thinking tokens” for audit.
- Tools/products: RAG + Thinking States orchestrator; “reasoning sparsity” monitor to track non-trivial state updates.
- Assumptions/dependencies: Teacher-forced chunk supervision derived from existing CoT data (or teacher model); reasoning remains sparse across chunks for prefill gains.
- Streaming state tracking over long texts and logs (operations, observability, governance)
- What: Track evolving entities/variables across long narratives without growing the context window, improving length generalization vs. CoT.
- Workflow: Ingest text in chunks; inject states at shallow layers; export a lightweight “state vector timeline” and optional natural-language thoughts for explainability.
- Tools/products: “State timeline” artifact for dashboards; an alerting layer that triggers on non-trivial state updates.
- Assumptions/dependencies: Tasks exhibit sequential dependencies; chunk size tuned to avoid overcompressing multiple steps into one update.
- Faster math and tutoring assistants with inspectable steps (education)
- What: Provide near-CoT accuracy on GSM-style problems with 2–3× speedup; optionally reveal the short internal thoughts for step-by-step feedback.
- Workflow: Fine-tune on math CoT datasets with chunk-aligned thoughts; optionally display thoughts to learners; fallback to full CoT for edge cases.
- Tools/products: “Thinking State Visualizer” to show per-chunk thoughts; classroom dashboards with aggregated reasoning paths.
- Assumptions/dependencies: Availability of math CoT data; careful UX for exposing intermediate thoughts responsibly.
- Energy and cost reduction in serving (infrastructure, policy/ESG)
- What: Cut wall-clock time and generated tokens vs. CoT for reasoning queries, lowering compute/energy footprint while preserving accuracy.
- Workflow: Replace CoT-serving profiles with Thinking States profiles in inference gateways; report energy savings for ESG disclosures.
- Tools/products: Cost/energy monitors tied to reasoning sparsity and prefill rounds; SLO templates for “fast reasoning.”
- Assumptions/dependencies: Gains depend on sparsity of non-trivial states and support for prefill parallel rounds.
- Explainable latent reasoning for audit trails (finance, healthcare, public sector)
- What: Keep reasoning largely latent for efficiency but maintain human-readable “thinking tokens” aligned to chunks for auditability.
- Workflow: Store per-chunk thoughts (short, targeted) rather than long CoTs; map each thought to the triggering input span.
- Tools/products: Compliance “reasoning logs” with chunk indices; redaction tools to mask sensitive entities in thoughts.
- Assumptions/dependencies: Policy constraints on storing intermediate reasoning; redaction required for sensitive domains.
- Training-time acceleration for latent reasoning research (academia, ML R&D)
- What: Replace continuous latent/BPTT methods with teacher-forced, fully parallel training—enabling more steps without exploding compute.
- Workflow: Generate chunk-aligned targets via rules or a teacher model; run parallel SFT on T/C modules; iterate quickly on architecture and chunk size.
- Tools/products: Alignment toolkit (inserts <T> markers, builds per-chunk targets); training recipe that avoids BPTT.
- Assumptions/dependencies: Access to or creation of aligned thought targets; open weights for LLM backbones.
- Mobile/edge assistants with lower latency reasoning (consumer devices)
- What: Improve responsiveness on-device by avoiding long CoT outputs and keeping context static.
- Workflow: Deploy distilled small LLM with T/C; enable speculative prefill to reduce rounds; throttle natural-language thoughts to conserve memory.
- Tools/products: Mobile inference kernels for shallow-layer injection; low-memory compression for states.
- Assumptions/dependencies: Enough compute to run deep-layer extraction and small T/C; careful memory budgeting; domain-specific fine-tuning.
Long-Term Applications
These use cases require further research, scaling studies, broader validation, or ecosystem development before reliable deployment.
- Dynamic compute during decoding and tool use (software, agents)
- What: Extend Thinking States beyond prefill to generation time, allocating extra recurrence only when needed per token/tool call.
- Potential product: “Adaptive Reasoning Scheduler” that gates deep-to-shallow loops conditioned on uncertainty.
- Dependencies: New decoding-time algorithms; calibration of when to trigger state updates; GPU kernel support for variable-depth loops.
- Multimodal and embodied reasoning with recurrent states (robotics, AV, vision-language)
- What: Maintain a cross-modal “thinking state” across frames/sensor packets to track objects, goals, and plans without growing the token stream.
- Potential product: Perception-to-policy bridge where visual thoughts compress into action-state vectors.
- Dependencies: Multimodal T/C modules; robust alignment of visual steps to temporal chunks; real-time constraints.
- Clinical and longitudinal decision support (healthcare)
- What: Track evolving patient states across notes and timelines, offering explainable intermediate reasoning steps with bounded latency.
- Potential product: “Clinical State Ledger” showing how intermediate inferences updated the patient representation.
- Dependencies: Clinical validation, safety and bias audits, HIPAA-compliant storage of thoughts, domain-specific CoT data.
- Financial risk and fraud monitoring over event streams (finance)
- What: Maintain latent states for accounts/entities as transactions stream in; escalate when non-trivial state updates occur.
- Potential product: Streaming “state anomaly” detector with interpretable thought snippets per alert.
- Dependencies: Task-specific alignment rules; low-latency streaming kernels; rigorous backtesting.
- Large-scale legal and policy analysis with state tracking (public sector, legal tech)
- What: Track obligations, exceptions, and precedence across lengthy statutes/case law using static context and recurrent internal state.
- Potential product: “Obligation Tracker” that emits succinct intermediate inferences tied to citations.
- Dependencies: High-quality CoT traces and alignment for legal text; benchmark creation; expert review cycles.
- Software engineering copilots with variable/state reasoning (software)
- What: Track variable/object lifecycles and invariants across large codebases with recurrent states, improving long-file generalization.
- Potential product: “State-Aware Code Copilot” that flags invariant violations and suggests fixes using internal thoughts.
- Dependencies: Code-specific datasets with aligned reasoning; integration with AST and static analysis; evaluation protocols.
- RL fine-tuning to optimize internal thinking beyond human traces (ML R&D)
- What: Use supervised Thinking States as a warm start, then apply RL to refine which thoughts/states to produce and when.
- Potential product: “Self-Optimizing Reasoner” that learns sparse, high-value state updates per domain.
- Dependencies: Stable RL objectives for latent reasoning; safety constraints to avoid harmful thought patterns.
- Privacy-preserving explainability and storage (policy, privacy tech)
- What: Store compressed state updates (and optionally obfuscated thoughts) instead of full CoT logs, balancing auditability and privacy.
- Potential product: “Reasoning Privacy Layer” that enforces redaction policies over thought content before persistence.
- Dependencies: Formal privacy guarantees; domain-specific redaction; regulator buy-in for compressed audit artifacts.
- Standardized “thinking state” API and benchmarks (ecosystem, standards)
- What: Define interfaces for exporting/importing states, visualizing per-chunk thoughts, and measuring reasoning sparsity and length generalization.
- Potential product: Open benchmarks for state-tracking and multi-hop with chunk-aligned ground truth; telemetry standards for prefill rounds.
- Dependencies: Community adoption; reference implementations across major LLM stacks.
- Hardware–software co-design for recurrent state injection (semiconductors, cloud)
- What: Optimize kernels and memory layouts for shallow-layer state injection, deep-layer extraction, and fast T/C passes.
- Potential product: Accelerator features for “deep-to-shallow” recurrence and speculative prefill rounds.
- Dependencies: Vendor collaboration; workload characterization showing consistent gains; compiler/runtime support.
- Multilingual and low-resource reasoning with aligned thoughts (global education, public-interest tech)
- What: Bootstrap chunk-aligned supervision via teacher models and weak rules to enable efficient reasoning in low-resource languages.
- Potential product: Tooling to auto-insert alignment markers and validate thoughts across languages.
- Dependencies: Reliable cross-lingual teachers; culturally adapted datasets; evaluation in diverse settings.
Cross-cutting assumptions and risks
- Availability and quality of CoT data and alignment: Teacher-forced training relies on mapping CoT steps to chunk positions (via rules or a strong teacher). Poor alignment reduces gains.
- Model access: Requires modifying the backbone (inject at shallow layers, extract at deep layers). Not feasible with closed APIs that don’t expose internals.
- Task sparsity: Prefill speedups assume most chunks produce trivial states; dense-reasoning tasks may see smaller gains.
- Scalability and external validity: Results demonstrated on 0.5B–1.5B models and specific tasks; behavior at larger scales and across domains requires validation.
- Interpretability vs. privacy: Storing natural-language thought snippets can leak sensitive information; redaction and data governance are necessary.
- Engineering complexity: Implementing speculative prefill, KV-cache interactions, and chunking policies adds serving complexity; robust instrumentation is needed to monitor correctness and latency.
Glossary
- 2-hop QA: A question answering setup that requires chaining two facts or hops to derive the answer. "First, a 2-hop QA dataset, where prior work by \citet{biran2024hoppinglateexploringlimitations, yang2025largelanguagemodelsperform} demonstrated standard LLMs exhibit latent reasoning to some extent, providing a useful test case for methods designed to improve latent reasoning."
- Ablation study: An experimental analysis that systematically removes or varies components to understand their impact on performance. "Section~\ref{res-ablation-studies} presents ablation studies exploring the performance--efficiency tradeoff as a function of recurrence depth and chunk size."
- Attention layers: Transformer components that compute weighted interactions between tokens to integrate contextual information. "Chunk representations can access the history via attention layers and the KV-cache."
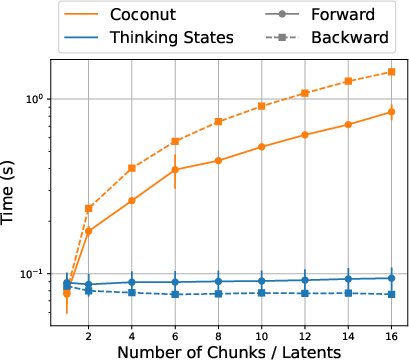
- Autoregressive decoding: Sequential token generation where each token is predicted conditioned on all previous tokens. "Unlike prior work~\cite{hao2024traininglargelanguagemodels, deng2024explicitcotimplicitcot}, which reports efficiency in terms of generated token count, we use wall-time because token generation with the lightweight Thinking Block {} is substantially faster than standard autoregressive decoding."
- Autoregressively: In a manner where outputs are generated one step at a time, each conditioned on previous outputs. "A lightweight Transformer decoder (one layer in our experiments) that autoregressively generates a reasoning sequence in natural language."
- Backbone LLM: The main pretrained LLM that provides the core computation, augmented by auxiliary modules. "Because thoughts are decoded from representations in a deep layer (e.g., second to last), we leverage the backbone LLM to perform the bulk of the computation."
- Backpropagation through time (BPTT): A training technique for sequential models that computes gradients across time steps, often computationally intensive. "which requires backpropagation through time (BPTT) from the desired outcome, making training considerably more challenging and limiting the number of latents that can be used in practice."
- Bidirectional query processing: Processing input in both forward and backward directions to leverage future context for earlier decisions. "bidirectional query processing could, in principle, identify the relevant quantity before committing to intermediate state updates."
- Causal autoregressive backbone: A model architecture that predicts tokens in a forward-only manner, preventing access to future tokens during generation. "this limitation stems from the combination of Thinking States with a causal autoregressive backbone rather than the thinking-state mechanism itself"
- Chain-of-thought (CoT): Explicit generation of intermediate reasoning steps to improve accuracy on complex tasks. "Reasoning with a chain-of-thought (CoT) enables LLMs to solve complex tasks but incurs significant inference costs due to the generation of long rationales."
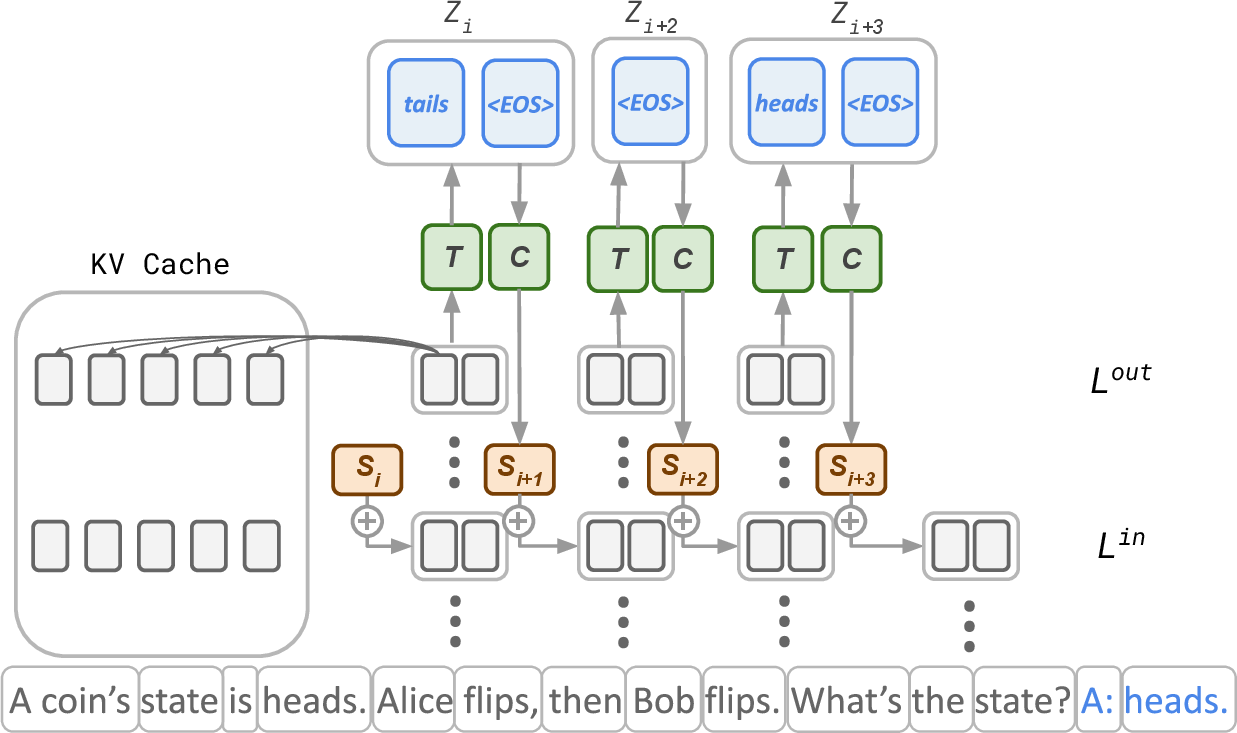
- Compression Block: An auxiliary module that encodes a variable-length thought sequence into a fixed-size state vector. "Compression Block {}: A Transformer encoder with a pooling layer that maps any variable-length reasoning sequence into a fixed-size state ."
- Continuous embeddings: Dense vector representations not restricted to discrete tokens, used to encode information. "One approach to reducing reasoning tokens is to not require thinking tokens to be in natural language, but rather be continuous embeddings \cite{hao2024traininglargelanguagemodels, shen2025codicompressingchainofthoughtcontinuous}."
- Continuous thought tokens: Non-linguistic, vector-based representations of thoughts used in recurrent reasoning. "\citet{hao2024traininglargelanguagemodels} extended this idea by introducing recurrent ``continuous thought tokens'' that are iteratively refined after processing the query."
- Cross-entropy loss: A standard classification loss measuring the difference between predicted and target distributions. "where $\mathcal{L}_{\text{T}$ is cross-entropy loss over the thinking sequences."
- Curriculum learning: A training strategy that gradually increases task difficulty to improve learning. "iCoT~\cite{deng2024explicitcotimplicitcot}: a latent reasoning method that distills CoT into query representations via curriculum learning;"
- Deep layer: A layer near the output of a multi-layer model where high-level features are extracted. "Because thoughts are decoded from representations in a deep layer (e.g., second to last), we leverage the backbone LLM to perform the bulk of the computation."
- Deep-to-shallow recurrence: A design where information extracted from deep layers is fed back into shallow layers to influence future computation. "Ablation studies over deep to shallow recurrence (a) and effects of the chunk size (b), with measured speedup over CoT (top) at each point."
- Distillation loss: An objective that aligns a student model’s internal representations or outputs with those of a teacher. "More recently, \citet{shen2025codicompressingchainofthoughtcontinuous} proposed adding a distillation loss that aligns the student's latent representations with those of a CoT-based teacher, removing reliance on the iterative curriculum."
- Dynamic depth: A mechanism allowing variable numbers of layer applications per token to increase compute adaptively. "\citet{geiping2025scalingtesttimecomputelatent} proposed dynamic depth, where the same block of layers is applied repeatedly for a variable number of iterations, effectively increasing computation per token at inference time."
- EOS token: A special end-of-sequence marker indicating completion of generation. "The output is a variable-length token sequence ending with an <EOS> token."
- Fine-tuning: Adapting a pretrained model to a specific task or dataset via additional training. "All experiments use Qwen2.5-Base models~\cite{qwen2025qwen25technicalreport} (0.5B and 1.5B parameters), fine-tuned on task-specific training data."
- Full Knowledge (FK): An evaluation regime where all required facts are present in the fine-tuning data. "In Full Knowledge (FK), the required factual knowledge appears in the fine-tuning data, testing how well models acquire and manipulate knowledge with each method."
- GSM8K: A benchmark of grade-school math word problems used to assess reasoning. "Second, a GSM8K-style dataset, consisting of 400K simple math word problems and parsed CoT steps, previously used by ~\citet{deng2023implicitchainthoughtreasoning, hao2024traininglargelanguagemodels}."
- iCoT: An implicit chain-of-thought method that distills reasoning into internal representations without explicit rationales at inference. "iCoT~\cite{deng2024explicitcotimplicitcot}: a latent reasoning method that distills CoT into query representations via curriculum learning;"
- KV-cache: A memory of key and value tensors used by attention to efficiently reuse past computations. "Chunk representations can access the history via attention layers and the KV-cache."
- Latent reasoning: Implicit reasoning performed within hidden states or compressed representations rather than explicit text. "Empirically, Thinking States outperforms other latent reasoning methods on multiple reasoning tasks, narrowing the gap to CoT on math problems"
- Length generalization: The ability of models to extrapolate performance to longer sequences than seen during training. "we employ a length generalization setting, drawing on the known extrapolation capabilities of recurrent models~\cite{delétang2023neuralnetworkschomskyhierarchy}."
- Multi-hop QA: Question answering that requires reasoning across multiple pieces of information. "matches or exceeds CoT accuracy on multi-hop QA and state-tracking tasks, and achieves significant speedups compared to CoT on all tasks."
- Multi-hop reasoning: Logical inference that chains multiple steps or facts to reach an answer. "\citet{yang2025largelanguagemodelsperform} showed that LLMs can arrive at correct answers on queries that inherently require multi-hop reasoning."
- Next-token prediction: The language modeling objective of predicting the next token given prior context. "After this forward pass, the Thinking Block {} is trained to predict via standard next-token prediction, in parallel over all chunks."
- Out-of-distribution (OOD): Data that differs from the training distribution, used to test generalization robustness. "Table~\ref{state-tracking-results} reports out-of-distribution (OOD) accuracy for each training regime."
- Parametric Knowledge (PK): An evaluation regime focusing on knowledge embedded in model parameters rather than fine-tuning data. "In Parametric Knowledge (PK), examples are filtered to reflect the knowledge of the base LLM, isolating whether a method improves retrieval and manipulation of existing knowledge in the base model."
- Pause tokens: Special tokens with no semantic meaning that grant extra compute time before output generation. "\citet{goyal2024thinkspeaktraininglanguage} introduced ``pause tokens'' during pretraining---tokens without semantic meaning that give the model extra computational steps before producing output, improving performance on downstream reasoning tasks."
- Pooling layer: A layer that aggregates variable-length sequences into fixed-size vectors. "Compression Block {}: A Transformer encoder with a pooling layer that maps any variable-length reasoning sequence into a fixed-size state"
- Prefill: The phase where input tokens are processed before generating outputs, often affecting latency. "This can significantly increase latency during query prefill."
- Reinforcement Learning: A training paradigm where models optimize behaviors based on reward signals rather than supervised targets. "training the model with reinforcement learning to produce helpful rationales."
- Recurrent mechanism: A process where state information is iteratively updated and fed back to influence future computation. "We introduce Thinking States, a recurrent reasoning mechanism that generates natural-language thoughts while processing the input, without increasing the context length."
- Speculative Thinking: An exact algorithm to accelerate prefill by assuming trivial states and iteratively correcting when needed. "\subsection{Fast Prefill with Speculative Thinking}\label{method-prefill}"
- State ambiguity: An error pattern where the model reasons about the wrong intermediate quantity due to unclear target specification. "We identify a distinct error pattern we term state ambiguity: in many GSM queries, the quantity of interest is specified only in the final clause and may be difficult to anticipate earlier."
- State tracking: Tasks requiring the model to monitor and update quantities that evolve through the input. "State tracking tasks require monitoring quantities that evolve throughout the input~\cite{illusionofstate, kim2023entitytrackinglanguagemodels, li2025howlanguagemodelstrack}."
- Teacher-forcing: A training technique that feeds gold intermediate outputs to the model to condition subsequent predictions, enabling parallelization. "Thinking States can be trained with teacher-forcing the thoughts, enabling fully parallel training and avoiding the computational overhead of backpropagation through time."
- Teacher model: A stronger model used to provide supervision signals or alignments for training another model. "This alignment is obtained either via a strong teacher model, e.g., Gemini 2.5-Flash \cite{comanici2025gemini}"
- Thinking Block: A lightweight decoder that generates natural-language thought sequences from deep representations. "Thinking Block {}: A lightweight Transformer decoder (one layer in our experiments) that autoregressively generates a reasoning sequence"
- Thinking States: The proposed method that generates and injects compact reasoning states during input processing. "We propose Thinking States, a method that performs reasoning {\em while} the input is processing."
- Token chunks: Contiguous groups of tokens processed together to manage recurrence and state updates. "Thinking States reasons by iteratively processing token chunks."
- Transformer decoder: The generative component of a Transformer that produces sequences conditioned on encoded representations. "A lightweight Transformer decoder (one layer in our experiments) that autoregressively generates a reasoning sequence"
- Transformer encoder: The component that encodes sequences into representations, often used to compress variable-length inputs. "A Transformer encoder with a pooling layer that maps any variable-length reasoning sequence into a fixed-size state"
- Variable Assignment (Vars): A synthetic state-tracking task involving multiple interacting integer variables. "Variable Assignment (Vars): tracking multiple interacting integer variables, yielding more complex state dynamics."
- Wall-clock speedup: Measured time reduction in execution compared to a baseline, reflecting real performance gains. "For efficiency, we measure wall-clock speedup relative to CoT on a single A100-80GB GPU."
Collections
Sign up for free to add this paper to one or more collections.