- The paper reveals that keypoint proximity from multi-scale extraction without NMS significantly degrades matching accuracy, particularly for detectors like SiLK and ORB.
- It systematically decouples detector and descriptor roles, showing that detector choice overwhelmingly impacts performance within transformer-based matchers.
- The fine-tuning approach produces a detector-agnostic matcher that achieves up to 9.9% increase in AUC and strong zero-shot performance across diverse keypoint detectors.
Summary of "Understanding and Optimizing Attention-Based Sparse Matching for Diverse Local Features" (2602.08430)
The paper systematically analyzes the training, deployment, and generalization mechanics of transformer-based sparse image matching models, with a particular focus on LightGlue. The authors expose a critical design oversight: the detrimental influence of nearby keypoints, often arising via multi-scale extraction and omission of non-maximum suppression (NMS), on matching accuracy. They empirically demonstrate that this factor, though previously overlooked, severely degrades the performance for certain detectors, such as SiLK and ORB, when used with attention-based matchers.
Detector and Descriptor Dichotomy
Through rigorous decoupling experiments, the authors dissect the respective impacts of detectors and descriptors on matching performance within the transformer framework. Their analysis establishes that, in most cases, detectors dominate the outcome, while descriptor choice is largely secondary. Notably, for binary features (e.g., ORB), descriptor limitations are more pronounced, though attention mechanisms in LightGlue are able to partially compensate for their deficiencies.
Critical Role of Suppressing Nearby Keypoints
The examination reveals that enabling NMS or enforcing single-scale extraction is essential for successful model training and inference, especially when employing detectors prone to repeated keypoints (e.g., multi-scale R2D2, SiLK). Enabling NMS for SiLK and Dedode detectors yields absolute gains of up to 9.9% in AUC@5° pose estimation (Figure 1).

Figure 1: LightGlue matching results for SiLK with and without NMS. Without NMS, the keypoints are cluttered and often fail to match, while NMS yields more reliable matches.
Generalization and Zero-shot Matching
The authors revisit the prevalent assumption that transformer-based models are feature-dependent and hence require retraining for each new detector. Through systematic baseline and fine-tuning studies, they show that existing descriptors from learned features generalize well across detectors, provided the attention-based matcher is trained or fine-tuned with diverse keypoints. This led to the development of a detector-agnostic model, demonstrating remarkable zero-shot performance: the fine-tuned matcher achieves comparable or superior accuracy compared to model specialized for individual detectors (Figure 2, Figure 3).
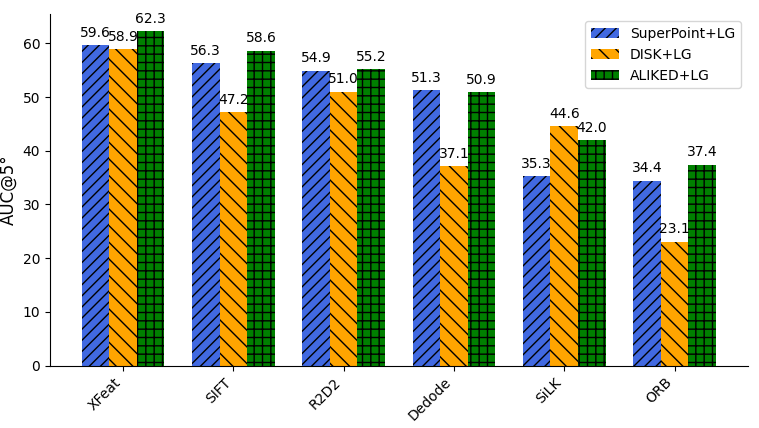
Figure 2: Applying official LightGlue models to novel detectors on MegaDepth-1500 results in degraded pose estimation; naive transfer performs poorly.
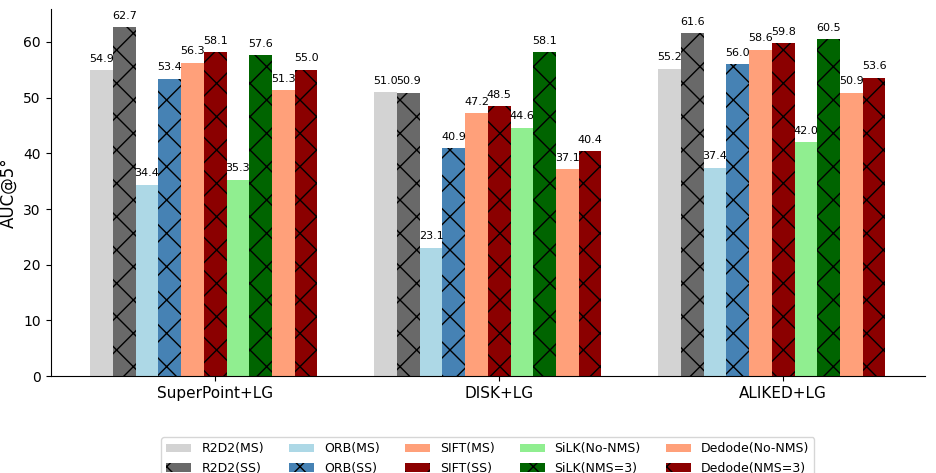
Figure 3: Removing nearby keypoints using NMS or single-scale extraction achieves consistent gains in matching accuracy across different matchers.
Fine-tuning Approach and Detector-Agnostic Model
A novel fine-tuning approach incorporates correspondence supervision from a range of detectors, freezing descriptor network weights. This process results in a universal matcher. Experimentally, fine-tuned LightGlue models close the performance gap for cross-detector matching, demonstrating that the detector biases, not descriptors, are the main performance bottleneck. The fine-tuned models achieve strong results even for detectors not seen during training, and they are robust to detector-specific idiosyncrasies (Figure 4).
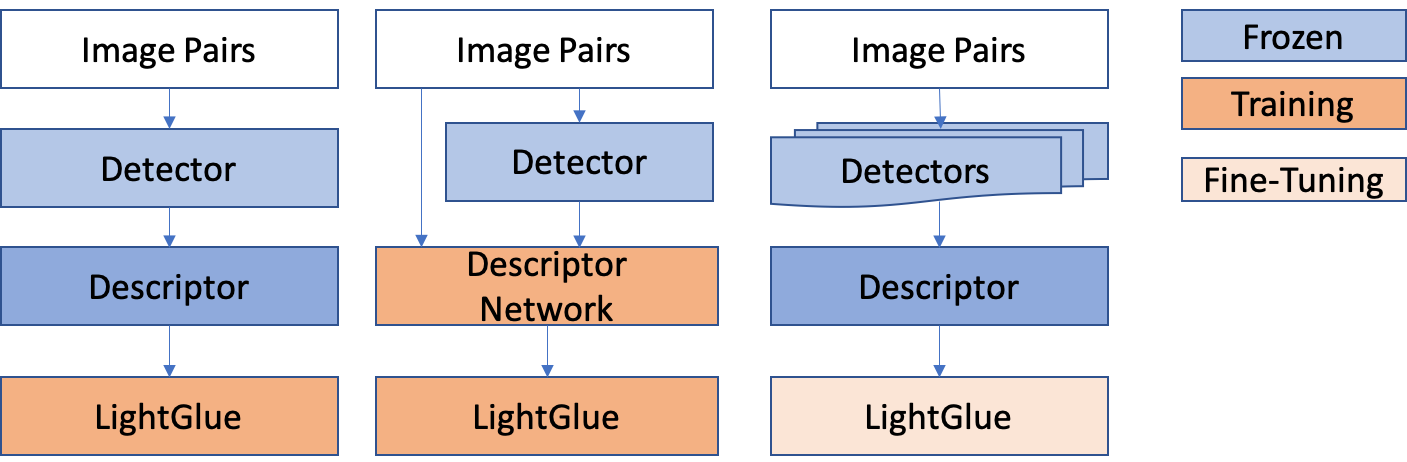
Figure 4: Standard LightGlue training (left) versus joint descriptor+matcher training (middle) and the fine-tuning methodology (right) for detector-agnostic matching.
Strong Numerical Results
- MegaDepth-1500 pose estimation: Fine-tuned models using the ALIKED descriptor outperform individually trained specialist LightGlue models, achieving average AUC@5°/10°/20° scores of 59.7/73.8/84.0 versus 56.9/70.7/81.1 for specialists.
- Image Matching Challenge 2021: Fine-tuned model enables zero-shot matching for ORB keypoints, yielding 64.8 mAA@10° (multi-view) compared to 52.0 for nearest neighbor; the approach rescues performance for binary features previously considered incompatible with attention-based matchers.
- Visual Localization: On the Aachen Day-Night dataset, fine-tuned models localize up to 71.4% of night queries (0.25m/2° threshold) with ORB keypoints and pre-trained LightGlue, outstripping non-attention baselines and specialist models.
- Detector ensemble: Detector-agnostic matching enables single-model ensembles, yielding further gains without retraining (Figure 5).
Visual Demonstrations

Figure 6: Matching ORB keypoints using different methods. Fine-tuned LightGlue model (bottom) yields significantly more correct matches than nearest neighbor baseline or official models.












Figure 7: IMC2021 stereo task, ORB-detected keypoints matched by LightGlue variants. Fine-tuned models obtain more correct matches, especially with ALIKED descriptors.
















Figure 5: Multi-view matching on IMC2021 with a single fine-tuned model (DISK descriptor), applied to DISK, SuperPoint, R2D2, and ORB detectors. The model robustly matches across detector diversity.
Practical and Theoretical Implications
- Deployment: The findings enable practical deployment of transformer-based image matching models in heterogeneous environments, circumventing the need for detector-specific retraining. This is critical for applications such as device/cloud visual localization (e.g., ORB-SLAM).
- Model Compression: The results support recent descriptor compression works, indicating that compact or frozen descriptors suffice within powerful attention frameworks.
- Detection Bias: Attention-based matchers are more sensitive to detector bias than descriptor choice, contradicting prior beliefs and aligning with emerging cross-modality matching paradigms.
- Ensemble Models: Detector-agnostic models allow for efficient ensemble matching strategies; only one matcher is required at inference, simplifying pipelines and boosting accuracy (Figure 5).
Speculation on Future Developments
The paradigm established here paves the way for universal matching models spanning not only detectors and descriptors but also modalities (e.g., cross-modality, cross-device, large-scale pre-training). The technique can be extended to dense matching, foundation-model-guided pipelines, and further compactification for edge deployment. Model architecture modifications to jointly leverage the attention-based matcher and detector characteristics may further optimize performance for binary features.
Conclusion
This paper delivers substantial insights into the mechanics, optimization, and generalization of transformer-based sparse image matching. The identification and mitigation of keypoint proximity effects, systematic delineation of detector and descriptor roles, and demonstration of robust detector-agnostic matching models represent major advances in the practical and theoretical understanding of attention-based matchers. The results suggest a shift away from feature-dependent training, unlocking efficient, universal solutions for both academic and industrial computer vision applications.