Demo-ICL: In-Context Learning for Procedural Video Knowledge Acquisition
Abstract: Despite the growing video understanding capabilities of recent Multimodal LLMs (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge, rather than their ability to learn and adapt from dynamic, novel contexts from few examples. To bridge this gap, we present Demo-driven Video In-Context Learning, a novel task focused on learning from in-context demonstrations to answer questions about the target videos. Alongside this, we propose Demo-ICL-Bench, a challenging benchmark designed to evaluate demo-driven video in-context learning capabilities. Demo-ICL-Bench is constructed from 1200 instructional YouTube videos with associated questions, from which two types of demonstrations are derived: (i) summarizing video subtitles for text demonstration; and (ii) corresponding instructional videos as video demonstrations. To effectively tackle this new challenge, we develop Demo-ICL, an MLLM with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization, jointly enhancing the model's ability to learn from in-context examples. Extensive experiments with state-of-the-art MLLMs confirm the difficulty of Demo-ICL-Bench, demonstrate the effectiveness of Demo-ICL, and thereby unveil future research directions.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI systems to learn new skills from examples inside a task, especially with videos. Think of it like this: you watch a short cooking tutorial that shows the steps to make Mexican rice, and then you’re asked questions about a new cooking video. The AI should use what it learned from the tutorial (the “demo”) to figure out what happens next in the new video. The authors call this idea “Demo-driven Video In-Context Learning” (Demo-ICL), and they also build a new test (a benchmark) to measure how good different AI models are at it.
What questions does the paper try to answer?
The paper asks simple but important questions:
- Can AI models learn a new process (like a recipe or a DIY repair) by watching or reading a few examples, and then apply that knowledge to a different, related video?
- Does giving the AI a text guide (steps written out) help more than giving it a video demo?
- Can the AI pick the best demo from a pile of videos before using it to answer questions?
How did they do it?
To make this work and test it fairly, the authors built three versions of the Demo-ICL task:
1) Text-demo In-Context Learning
The AI sees a target video plus a short text “instruction sheet” (like “Step 1: wash rice; Step 2: heat oil; Step 3: add onions…”). Then it gets a question such as “What should happen next?” The idea is the AI must match the current video moment to the right step and predict the next step.
2) Video-demo In-Context Learning
The AI sees a target video plus a demonstration video of a similar task. Again, it’s asked a question like “Given what you saw, what comes next?” This time, the AI has to learn the steps from the demo video and transfer that knowledge.
3) Demonstration Selection
The AI sees the target video and several candidate demo videos (some are relevant, some are not). It must first pick the most helpful demo (for example, choose “Mexican rice” instead of “fried rice” or “pasta”), and then use it to answer the question.
To build a strong test for these tasks, they:
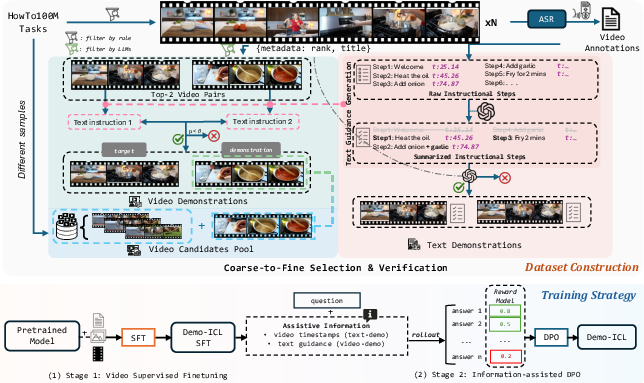
- Collected instructional YouTube videos (with subtitles and timestamps) from a public dataset called HowTo100M.
- Summarized the videos’ subtitles into clear step-by-step text instructions using LLMs, so the demos are neat and easy to follow.
- Paired similar videos as demonstration examples, and created questions focused on “what happens next?” to make sure you really need the demo to answer.
- Built a benchmark called Demo-ICL-Bench with 1,200 questions covering the three tasks.
To train their own model (also called Demo-ICL), they used a two-step approach:
- Video Supervised Fine-Tuning: First, they trained the model on lots of image and video tasks so it understands visuals and steps well.
- Information-Assisted Preference Optimization (DPO): Then they improved the model by repeatedly showing it pairs of answers and teaching it to prefer the better one. “Information-assisted” means they gave the AI useful hints (like timestamps or short text explanations of the demo) while training, so it could learn how to use demos more effectively. You can think of this like a coach pointing to the right moment in a tutorial and saying, “Look here—this is the important part.”
What did they find?
Their benchmark turned out to be hard—even for top AI models:
- With text-based demos, a strong commercial model scored around 46% correct.
- With video-based demos, it dropped to about 32% correct.
- Humans did much better overall (around 80% across tasks), showing the gap between current AI and real in-context learning.
Their Demo-ICL model improved over many open-source models:
- On text-demo tasks, Demo-ICL reached about 43% accuracy (better than most similar-sized open-source models).
- On video-demo tasks, it reached about 32% (again competitive and better than several baselines).
- In the “pick the right demo” task, it also did better than many others.
They also showed why video-demo learning is extra tough:
- AI models struggle to match the timing and actions between the demo video and the target video.
- Giving the model more frames (more video snapshots), matching the exact next-step clips, or adding subtitles/text helps a lot—because it makes the “what comes next?” link clearer.
Finally, they tested Demo-ICL on other video benchmarks (general video understanding and video knowledge tests) and found it stayed competitive, showing the training strategy is useful beyond just this one benchmark.
Why is this important?
Learning from demonstrations is how people learn: we watch a tutorial, understand the steps, and then try it ourselves. Teaching AI to do this could help in many areas:
- Robotics: A robot can learn new tasks from a few videos of humans doing them, then repeat the steps in new situations.
- Education: AI tutors could watch instructional videos and explain the steps to students in simple terms, or help practice “what comes next?”
- Video search and assistance: AI could choose the most helpful tutorial from a big set and guide you through it while you work.
The paper shows that true “in-context” learning from videos is still hard for AI, especially matching steps across different videos. But the Demo-ICL benchmark and model give researchers a clear target and a starting point to improve.
Takeaway
The authors created a realistic way to test whether AI can learn procedures from demos (text or video) and apply them to new videos. They also built a model and training method that make steady progress on this challenge. While there’s still a big gap to human performance, this work moves AI closer to learning like we do—by watching, understanding, and then doing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps, limitations, and open questions the paper leaves unresolved. Each item is phrased to enable targeted follow-up by future researchers.
- Benchmark coverage and representativeness: Demo-ICL-Bench (1,200 questions) is built exclusively from HowTo100M instructional videos; its domain diversity (e.g., non-cooking procedures, DIY, medical, industrial) and representativeness across tasks, cultures, and contexts remain unquantified.
- Language and modality scope: The dataset filters by language and evaluates without subtitles or audio, yet many instructional videos rely heavily on narration; the impact of multi-lingual subtitles, speech, and audio cues on demo-driven ICL remains unexplored.
- Next-step only evaluation: Tasks primarily assess predicting the immediate “next step”; multi-step planning, long-horizon procedure tracking, and global plan consistency are not evaluated.
- Scale of demonstration selection: The selection task uses a small pool (ground-truth pair + 3 distractors); performance and retrieval behavior at realistic scales (hundreds to thousands of candidate videos) is unknown.
- Demonstration quality sensitivity: There is no systematic study of how demo-driven ICL degrades under imperfect demonstrations (e.g., missing steps, noisy ASR, stylistic variations, conflicting procedures), nor standardized robustness protocols.
- Temporal alignment ground truth: Video-demo ICL lacks step-level ground-truth alignments between demonstration and target videos; without alignment annotations, it is hard to measure or train explicit temporal correspondence.
- Metrics beyond accuracy: Evaluation relies on answer accuracy; alignment quality, temporal grounding scores, rationale faithfulness, and procedural consistency metrics are missing.
- Human evaluation details: “Human accuracy” is reported without inter-annotator agreement, criteria, or protocol; replicability and reliability of the human baseline are not established.
- Baseline comparability: Prompting strategies, inference-time settings (e.g., context formatting, sampling), and frame sampling protocols for baselines are not fully standardized/transparent, limiting fair comparability.
- Frame sampling constraints: Evaluation mostly uses 32 frames (with small ablations); the effect of frame rate, sampling strategy (keyframe vs. uniform), input length, and adaptive frame selection on ICL performance is underexplored.
- Audio-informed ICL: Ablations show large gains when adding ASR captions, yet evaluation prohibits subtitles; the role of audio/ASR at test time and how to best integrate speech with visual demonstrations is not studied.
- Model scale and scaling laws: Only a 7B Demo-ICL is reported; how demo-driven ICL performance scales with model size, data size, and context length is unknown (e.g., scaling laws for video ICL).
- Generalization beyond HowTo100M: Transfer to other instructional domains (COIN, Cross-Task), non-instructional long videos, or real-world tasks (e.g., robotics imitation, procedural assembly) is not empirically validated.
- Contamination risk: Many baselines (and the training corpus) leverage instructional video datasets; potential overlap or indirect contamination (procedural priors) with Demo-ICL-Bench is not formally audited.
- Reward model specification: The DPO reward model architecture, training data, and calibration are not described; whether human preference labels outperform the proposed auto-generated assistive signals remains open.
- Privileged information in DPO: Information-assisted DPO injects timestamps/captions during data generation; the extent to which models depend on such privileged signals—and how well they generalize when these are absent at test—needs quantification.
- Iterative DPO stability: The iterative preference training approach may accumulate biases from self-generated responses; convergence properties, error compounding, and safeguards against drift are not analyzed.
- Error taxonomy: There is limited fine-grained error analysis (e.g., misalignment errors, step-boundary confusion, object/action recognition failures); a taxonomy would guide targeted method improvements.
- Retrieval pipeline realism: Demonstration selection relies on LLM-based title similarity and manual filtering; integrating scalable, reproducible video retrieval (e.g., embedding-based ANN, cross-modal RAG) and comparing retrieval strategies is an open need.
- Procedural variability handling: Real procedures often vary (ordering, substitutions, omissions); the benchmark does not quantify tolerance to legitimate procedural variants vs. strict matching.
- Rationale and faithfulness: The model’s explanations/rationales (if any) are not evaluated for faithfulness to video evidence and demonstrations; methods to ensure grounded reasoning remain unexplored.
- Data generation bias: LLM-generated instructions and pairing decisions may introduce bias/hallucinations; the proportion of human verification and its impact on dataset reliability are not reported.
- Reproducibility and resource barriers: Training requires 64× A100 80G GPUs and millions of samples; lighter-weight recipes, ablations on compute/data budgets, and reproducible training configs are not provided.
- Open-source artifacts: Availability and completeness of released benchmark annotations (step timestamps, alignment labels), code, reward models, and training data for reproducibility are unclear.
- Safety/ethics considerations: Potential risks of learning from user-generated instructional content (unsafe advice, misleading demos) and responsible use policies are not discussed.
Practical Applications
Below is an overview of practical, real-world applications enabled by the paper’s task (Demo-driven Video In-Context Learning), benchmark (Demo-ICL-Bench), and model/training pipeline (Demo-ICL with video SFT + information-assisted DPO). Each item notes sectors, example tools/products/workflows, and key assumptions/dependencies affecting feasibility.
Immediate Applications
- Demo-ICL-Bench for capability auditing and evaluation
- Sectors: Software/AI platforms, Academia, Policy/testing labs
- What: Use Demo-ICL-Bench to benchmark multimodal models on procedural understanding (especially “next-step” reasoning from text/video demonstrations). Establish internal red-teaming and regression testing for product releases.
- Tools/Products/Workflows: “Demo-ICL-Bench-as-a-Service,” CI pipelines that run Demo-ICL tasks on candidate models; public leaderboard for demo-driven video ICL.
- Assumptions/Dependencies: Dataset licensing and distribution; compute for video evaluation; consistent evaluation protocols; versioning of model prompts and frame sampling.
- Instructional video search and recommendation with demo-aware reranking
- Sectors: Media/Streaming, EdTech, Search
- What: Improve retrieval by selecting the most relevant video demonstrations for a target task (the paper’s “demonstration selection”), not just by title/metadata similarity but by procedural alignment.
- Tools/Products/Workflows: “Demo-aware Reranker” for video search; step-aligned similarity scoring; query-time retrieval that considers step coverage.
- Assumptions/Dependencies: Access to ASR transcripts; stable embedding and frame sampling strategy; latency budgets for online reranking.
- Video-to-checklist and step localization for SOPs and tutorials
- Sectors: Enterprise operations (manufacturing, energy, field service), Media/Creator tools, Education
- What: Convert how-to videos into structured, time-stamped checklists using the text-demo pipeline (ASR summarization → step extraction/refinement).
- Tools/Products/Workflows: “Video Step Indexer” that outputs step names, timestamps, required tools; authoring plugins for creators to auto-generate chapters/checklists.
- Assumptions/Dependencies: Quality of ASR; domain-specific terminology; human-in-the-loop review for safety-critical content.
- Next-step suggestion assistants for DIY and cooking
- Sectors: Consumer apps, Smart home
- What: On a phone/tablet, watch a user’s work-in-progress clip, align it to a demonstration, and suggest the next step (“text-demo ICL” and “video-demo ICL”).
- Tools/Products/Workflows: “Procedural Copilot” modes in camera apps; hands-free voice guidance; smart display integrations.
- Assumptions/Dependencies: Low-latency inference; robust step alignment from sparse frames; disclaimers for safety (knives, heat, power tools).
- AR coaching for vocational training and onboarding
- Sectors: Education/Vocational, Defense training, Enterprise L&D
- What: Overlay real-time hints and “what’s next” using video-demo ICL on trainee performance in labs, kitchens, or shop floors.
- Tools/Products/Workflows: “AR Next-Step Coach” on smart glasses; session playback with step-level feedback; instructor dashboards.
- Assumptions/Dependencies: Stable tracking; privacy and consent; network/battery constraints; model confidence calibration.
- Procedure compliance monitoring and quality analytics
- Sectors: Manufacturing, Energy, Field service, Aviation MRO
- What: Compare worker activity to SOP demonstrations to flag skipped/incorrect steps and produce compliance reports (post-hoc analytics; human-in-the-loop).
- Tools/Products/Workflows: “SOP Monitor” for video QA; dashboards highlighting deviations; shift-level analytics.
- Assumptions/Dependencies: Worker privacy/union agreements; clear SOP baselines; data retention policies; error-tolerant thresholds to avoid false positives.
- Surgical and clinical skills training (offline, non-diagnostic)
- Sectors: Healthcare education, Nursing schools
- What: Analyze recorded training sessions vs. canonical clinical procedures; step coverage, timing, and sequencing feedback.
- Tools/Products/Workflows: Simulation lab analytics; OSCE preparation support; step timelines with exemplar comparisons.
- Assumptions/Dependencies: IRB and de-identification; no real-time clinical decision-making; rigorous human review.
- Remote assistance and customer support triage
- Sectors: Consumer electronics, Automotive repair, Home appliances
- What: Users upload a short video of their task; system selects the best demonstration and provides next-step guidance, escalating to human agents as needed.
- Tools/Products/Workflows: “Demo-driven Triage” workflow in support portals; confidence-triggered handoff; after-call summaries with step references.
- Assumptions/Dependencies: Clear confidence estimates; liability disclaimers; robust handling of varied lighting/angles.
- Tutorial quality scoring and “verified steps” badging
- Sectors: Platforms/Marketplaces, E-commerce services
- What: Rate and tag tutorials by how well they align to standard procedures; badge “verified step coverage” to increase user trust.
- Tools/Products/Workflows: Creator analytics; platform-side ranking signals; automated moderation for misleading tutorials.
- Assumptions/Dependencies: Availability of ground-truth SOPs; appeal processes for creators; avoidance of overfitting to specific styles.
- Information-assisted DPO as an MLLM training utility
- Sectors: AI tooling, Academia, Startups
- What: Use the paper’s information-assisted DPO pipeline to bootstrap higher-quality responses for video ICL tasks in new domains (e.g., egocentric, lab experiments).
- Tools/Products/Workflows: “ICL Preference-Training Kit” with assistive info (timestamps, transcripts) to create chosen/rejected pairs.
- Assumptions/Dependencies: Access to a reward model; compute resources; careful curation to avoid information leakage at eval time.
- Accessibility supports for stepwise guidance
- Sectors: Assistive tech, Public sector services
- What: Generate step-by-step reminders and checklists from videos for users who benefit from structured guidance (e.g., memory or executive-function supports).
- Tools/Products/Workflows: Companion app with visual checklists; adaptive pacing; multimodal prompts (audio, haptics).
- Assumptions/Dependencies: Personalization; privacy-preserving on-device or edge processing; clear opt-in.
- Robotics research workflows (data discovery and evaluation)
- Sectors: Robotics R&D
- What: Retrieve relevant demonstrations from large video corpora to seed robot learning experiments; evaluate temporal understanding with Demo-ICL tasks before policy learning.
- Tools/Products/Workflows: “Demonstration Retriever” for robot projects; pre-policy validation harness using Demo-ICL-Bench.
- Assumptions/Dependencies: Vision-to-action grounding remains an open challenge; additional control stacks required.
Long-Term Applications
- Watch-and-do household robots that learn from web videos
- Sectors: Consumer robotics, Smart home
- What: Robots watch a few demonstrations (text/video) and adapt the steps to new environments, executing tasks like tidying, cooking prep, or laundry.
- Tools/Products/Workflows: “Video-to-Policy” pipeline combining demo selection, temporal alignment, and control policy learning.
- Assumptions/Dependencies: Robust perception-action grounding; safe manipulation; sim2real transfer; strong safety and failover mechanisms.
- Zero-shot industrial robot programming from demonstrations
- Sectors: Manufacturing, Energy, Logistics
- What: Convert operator-provided videos into executable robot programs with constraints and safety checks; drastically reduce teach pendant time.
- Tools/Products/Workflows: “Procedural Program Synthesis” from video; digital twin validation before deployment.
- Assumptions/Dependencies: Calibration, kinematics mapping, fixture variability handling; compliance with standards (e.g., ISO 10218).
- Universal procedural tutor across domains
- Sectors: EdTech, Corporate training, Workforce development
- What: A multimodal tutor that can guide learners through any procedural skill by retrieving demonstrations, aligning user progress, and adapting instruction in real time.
- Tools/Products/Workflows: “Procedural Copilot SDK” integrated into LMS/authoring tools; auto-generated rubrics; personalized pacing.
- Assumptions/Dependencies: Dynamic step detection in unconstrained settings; robust personalization; comprehensive consent and ethics frameworks.
- Real-time clinical decision support during procedures
- Sectors: Healthcare
- What: Intraoperative or bedside “next-step” and anomaly alerts based on canonical protocols and case-specific demonstrations.
- Tools/Products/Workflows: OR integration; safety cases; human-in-the-loop alerts.
- Assumptions/Dependencies: Regulatory approval (e.g., FDA/CE); clinical trials; extremely high precision/recall; secure on-prem deployment.
- Autonomous field service agents (human-in-the-loop)
- Sectors: Telecom, Utilities, Oil & Gas
- What: AI agents that select demonstrations, plan steps, and guide technicians via AR to complete repairs with fewer truck rolls.
- Tools/Products/Workflows: “Procedural RAG” combining videos, PDFs, schematics; confidence-aware agent workflows.
- Assumptions/Dependencies: Robust retrieval across modalities; connectivity constraints; comprehensive SOP repositories.
- Web-scale procedural knowledge graphs mined from videos
- Sectors: Search, Knowledge management, Foundation models
- What: Build step/tool/variation graphs from large instructional corpora to power planning, content creation, and agent reasoning.
- Tools/Products/Workflows: “Video-to-Procedure Graph Builder”; API for step/variant queries.
- Assumptions/Dependencies: Copyright and platform policies; large-scale ASR and alignment; deduplication and quality control.
- Enterprise “Procedural RAG” unifying videos, documents, and diagrams
- Sectors: Software/Enterprise AI
- What: Retrieval-augmented generation that grounds answers in time-stamped video steps and SOP documents, with citation to specific moments.
- Tools/Products/Workflows: Unified index of step-level segments; timeline-grounded citations in responses.
- Assumptions/Dependencies: Content ingestion pipelines; access controls; governance for updates/versions.
- Standards, certification, and procurement guidance for multimodal procedural AI
- Sectors: Policy/Regulation, Public sector
- What: Use Demo-ICL-Bench-like tasks to define minimum performance bars and risk categories for demo-driven AI in safety-critical domains.
- Tools/Products/Workflows: Conformance test suites; certification programs; model cards with procedural ICL metrics.
- Assumptions/Dependencies: Multi-stakeholder consensus; periodic benchmark refresh; domain-specific test kits.
- Personalized rehabilitation and sports coaching with closed-loop adaptation
- Sectors: Healthcare, Sports science
- What: Systems that observe movement, align to expert demonstrations, and adapt exercises or drills step-by-step.
- Tools/Products/Workflows: Wearables + camera input; coach dashboards; adaptive regimens.
- Assumptions/Dependencies: Accurate pose/kinematics tracking; safety and injury prevention; clinician oversight where needed.
- Safety monitoring and incident prevention via “what should happen next?” prediction
- Sectors: Energy, Mining, Aviation, Chemical plants
- What: Predict expected next steps in hazardous procedures and alert on deviations; assist incident root-cause analysis with time-stamped step traces.
- Tools/Products/Workflows: Control-room analytics; integration with safety systems; post-incident forensics using step timelines.
- Assumptions/Dependencies: Low false alarm rates; rigorous testing against rare edge cases; secure video handling.
Cross-cutting assumptions and dependencies
- Data and IP: Rights to use and process instructional videos (YouTube and enterprise archives); privacy and de-identification for workplace/healthcare footage.
- Technical performance: Accurate ASR/transcripts; robust temporal alignment from sparse frames; scalable retrieval for demonstration selection; latency for real-time/AR.
- Model development: Access to base MLLMs/visual encoders; compute for SFT and information-assisted DPO; domain adaptation for specialized jargon and tools.
- Safety and governance: Human-in-the-loop oversight for consequential guidance; clear confidence estimates; audit trails; domain-specific validation and regulatory approvals.
- Deployment constraints: On-device or edge inference for privacy/latency; battery and connectivity for mobile/AR; integration with existing LMS, MES, CMMS, and EHR systems.
These applications leverage the paper’s core innovations—demo-driven video ICL tasks, the Demo-ICL-Bench evaluation framework, and the two-stage training with information-assisted DPO—to move from static video understanding toward adaptive, few-example procedural competence.
Glossary
- ASR (Automatic Speech Recognition): Technology that converts spoken audio into text, often with timestamps for alignment. "To obtain high-quality annotations, we use ASR outputs as they offer more detailed descriptions of demonstrated activities compared with video captions."
- Bradley-Terry (BT) model: A probabilistic model for pairwise comparisons that estimates the probability one item is preferred over another. "Following the approach introduced by~\citep{rafailov2024direct}, we can model the human preference distribution using the Bradley-Terry (BT) model~\citep{bradley1952rank}:"
- Chain-of-thought methods: Prompting or training techniques that encourage models to generate intermediate reasoning steps before final answers. "Emerging works add chain-of-thought methods for video understanding and reasoning tasks~\citep{wang2024videocot,han2025videoespresso,arnab2025temporalchainthoughtlongvideo,tian2025ego,zhang2025vitcot,ghazanfari2025chain} encourage stepwise evidence aggregation and explicit explanation,"
- Cross-task transfer: The ability of learned knowledge to generalize from one task to different but related tasks. "HowTo100M~\citep{miech2019howto100m} introduced 1.2 million narrated videos with 136 million clip–caption pairs for procedure recognition and cross-task transfer."
- Demonstration Selection: A task where a model selects the most relevant demonstration from a candidate pool to guide its answer. "3) Demonstration Selection: The model is given the input video and a pool of video candidates (e.g., a pool containing
Mexican rice,''fried rice,'' and ``pasta,'')." - Direct Preference Optimization (DPO): A training method that aligns model outputs with human or learned preferences by directly optimizing a preference-based objective. "To address Demo-driven ICL, we present Demo-ICL with a two-stage training strategy: video supervised fine-tuning, and information-assisted Direct Preference Optimization (DPO) for demo-driven video ICL."
- In-context learning (ICL): A model’s ability to perform tasks by conditioning on a few examples provided at inference without gradient updates. "In-context learning (ICL) enables models to perform new tasks by conditioning on a few examples at inference."
- Information-assisted DPO: A variant of DPO that augments training with automatically generated contextual information to improve preference data quality. "To overcome these challenges, we propose an information-assisted DPO pipeline that integrates automatically generated assistive information, eliminating the need for manual annotation."
- Logistic function: The sigmoid function used to map values to probabilities in binary preference models. "where I denotes the assistive information, and denotes the logistic function."
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple data modalities such as text, images, audio, and video. "Despite the growing video understanding capabilities of recent Multimodal LLMs (MLLMs), existing video benchmarks primarily assess understanding based on models' static, internal knowledge,"
- Negative log-likelihood: A loss function commonly used in probabilistic modeling and classification to train models by penalizing improbable predictions. "To estimate the parameters of the reward model, we can formulate the problem as a binary classification task and minimize the negative log-likelihood:"
- Oracle settings: Idealized evaluation scenarios where perfect or highly aligned information is provided to the model. "and correspond to successive stages of development, spanning from idealized oracle settings to practical real-world scenarios."
- Preference learning: Techniques for training models to produce outputs aligned with human or learned preferences. "Preference learning has become a critical component in the advancement of LLMs, aiming to fine‑tune outputs to better align with human preferences and improve real‑world applicability."
- Procedure recognition: The task of identifying and structuring the steps in instructional or procedural videos. "HowTo100M~\citep{miech2019howto100m} introduced 1.2 million narrated videos with 136 million clip–caption pairs for procedure recognition and cross-task transfer."
- Reward model: A model that assigns scalar scores to outputs to reflect preference or quality, used to guide training. "We employ a reward model to approximate preferences, and a higher score denotes a stronger preference."
- Semantic similarity: A measure of how closely two pieces of text (or other modalities) match in meaning. "Next, we evaluate the titles of top-ranked videos for each task and select the two with the highest semantic similarity using Qwen2.5-72B."
- Temporal–visual cues: Time-dependent visual signals in videos that inform sequencing, alignment, and reasoning. "This highlights the difficulty current MLLMs face in extracting and transferring temporal–visual cues for effective ICL."
- Video-supervised fine-tuning: Fine-tuning a model using supervised signals derived from video data to improve video understanding. "To address Demo-driven ICL, we present Demo-ICL with a two-stage training strategy: video-supervised fine-tuning and information-assisted direct preference optimization,"
- VideoRAG: Retrieval-augmented generation specialized for video, which retrieves relevant video segments to ground answers. "while some retrieval-based methods like VideoRAG~\citep{tevissen2024towards,ren2025videorag} establish a new paradigm of retrieving video moments and ground answers in cited segments."
- Visual encoder: The component of a multimodal model that converts visual inputs (images or video frames) into feature representations. "The Demo-ICL model is built upon Ola-Video, a highly pretrained multimodal understanding model that integrates OryxViT as its visual encoder to process native arbitrary-resolution visual inputs,"
- Visual grounding: The process of linking textual or symbolic information to specific visual evidence in images or videos. "Through this multi-stage refinement, we obtain precise and reliable textual guidance that captures both the procedural structure of the task and its visual grounding."
- Weakly supervised step parsing: Extracting procedural steps from videos using minimal or indirect supervision rather than dense annotations. "Other instruction-based datasets~\citep{tang2019coinlargescaledatasetcomprehensive,zhukov2019cross} provide fine-grained task annotations or support weakly supervised step parsing across diverse procedures."
- WhisperX: An ASR system that produces accurate transcripts with sentence- and word-level timestamps. "Specifically, we use annotations from HTM-AA~\citep{han2022temporal}, which employs WhisperX~\citep{bain2023whisperx} to generate sentence and word-level timestamps."
- Zero-shot performance: Model performance on tasks without any task-specific training or examples. "current video MLLMs~\citep{video-llava,maaz2024videochatgptdetailedvideounderstanding,zhang2025llavavideovideoinstructiontuning} mainly emphasize zero-shot performance through curated video instruction datasets for open-ended QA, captioning, and dialog capabilities."
Collections
Sign up for free to add this paper to one or more collections.