- The paper presents ALIVE, a unified audio-video generation model that leverages a dual-stream transformer architecture with UniTemp-RoPE for precise cross-modal synchronization.
- It employs a rigorous multi-stage data curation and cascaded refiner pipeline to upscale content to 1080p while preserving audio fidelity and visual clarity.
- Evaluation results demonstrate that ALIVE outperforms existing models, offering robust improvements in audio quality, motion, and overall synchronization.
ALIVE: Unified Audio-Video Generation with Synchronized, Lifelike Content
Motivation and Challenges in Joint Audio-Video Generation
The paper addresses the transition from text-to-video (T2V) generation to unified audio-video synthesis, a direction motivated by the need for immersive, expressive multimedia content generation. Synchronized audio-video generation presents distinct technical challenges: producing natural, multi-lingual speech, achieving robust audio-visual synchronization (especially in multi-speaker lip-sync), scaling high-quality data curation pipelines, and establishing rigorous, multi-dimensional benchmarks for joint evaluation. ALIVE is proposed as a solution, advancing the MMDiT architecture to a joint Audio-Video DiT framework, incorporating temporally aligned cross-modal fusion and precise temporal mapping for synchronization.
Model Architecture
ALIVE builds upon Waver 1.0, retaining the Wan2.1-VAE for video latent compression and dual text encoders (Flan-T5-XXL and Qwen2.5-32B-Instruct) for semantic conditioning. The core architecture is a Joint Audio-Video DiT, structured as a "Dual Stream + Single Stream" Transformer, integrating modality interaction via TA-CrossAttn and explicit temporal alignment via UniTemp-RoPE.
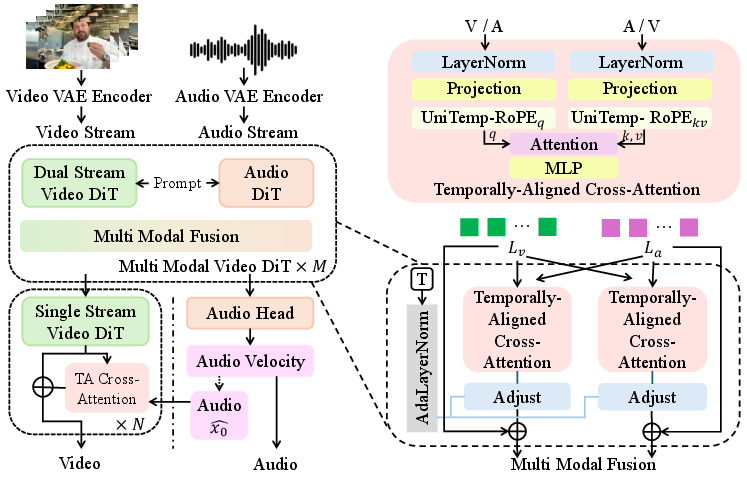
Figure 1: Architecture of ALIVE, illustrating Audio-Video DiT interaction.
The audio branch utilizes WavVAE for latent compression and an Audio DiT backbone with 32 Transformer blocks, supporting both direct speech transcript and global acoustic prompt conditioning. Structured prompt templates disentangle speech content from audio description, allowing precise linguistic and stylistic control.
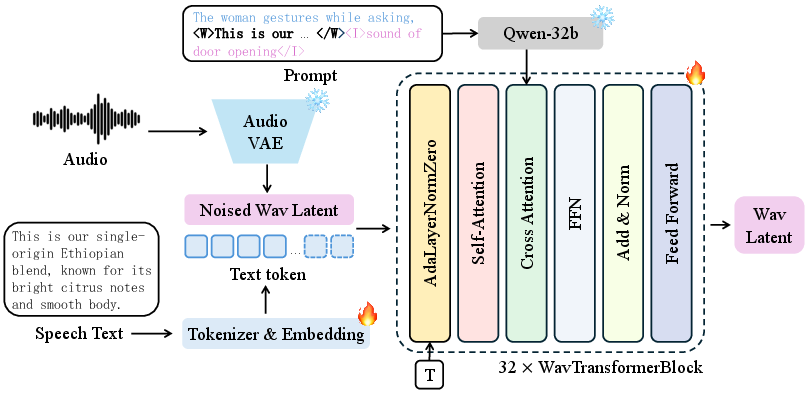
Figure 2: Architecture of the Audio DiT, highlighting speech-driven and descriptive prompt conditioning.
UniTemp-RoPE remaps discrete modality indices to a continuous temporal coordinate, aligning audio (higher granularity) and video sequences for cross-attention. Temporally-Aligned Cross-Attention mechanisms inject normalized cross-modal signals, preventing optimization collapse due to modal distribution shifts.
Audio-Video Refiner and High-Resolution Generation
The model is initially trained at 480p. A cascaded audio-video refiner enables 1080p generation by upscaling and refining output, ensuring visual fidelity augmentation does not degrade audio quality or synchronization by maintaining a frozen Audio DiT and clean audio latents throughout training.
Data Curation and Processing Pipeline
ALIVE introduces a rigorous multimodal data processing pipeline consisting of sequential stages: video quality pre-processing, captioning, audio filtering, subject ID correction, clarity filtering, and strategic data balancing. Each stage integrates vision and audio models, MLLMs, and CV-based pipelines to enforce alignment, clarity, and sample fairness.
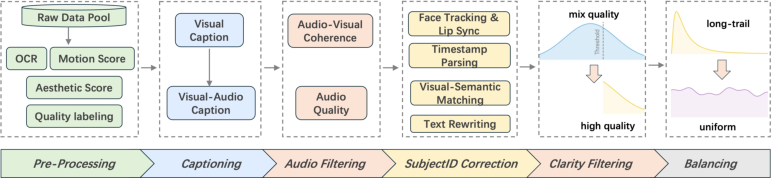
Figure 3: Overview of the multi-stage data processing pipeline for AV curation.
Subject ID correction addresses MLLM shortcomings in speaker-label attribution by employing face tracking, lip-sync detection, rule-based mapping, visual-semantic alignment, and narration rewriting, yielding robust subject-to-speech correspondence.
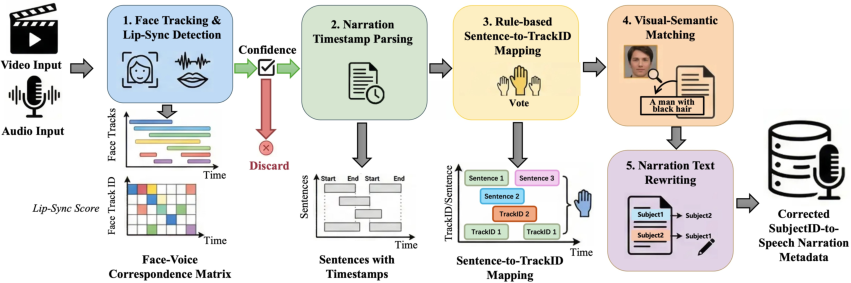
Figure 4: Detailed Subject ID correction pipeline for accurate speaker attribution.
The labeling system operates hierarchically across nine top-level domains, mapping visual concepts to diverse audio events, enabling targeted balancing and filtering.
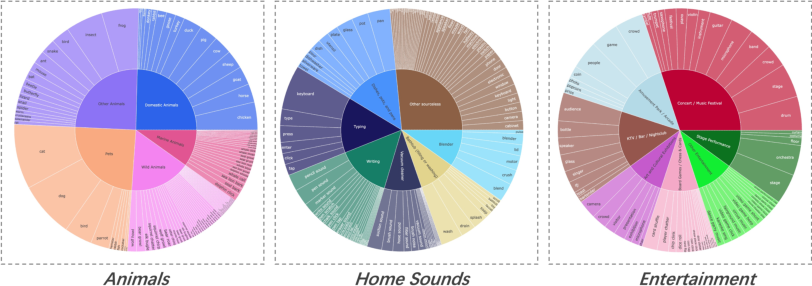
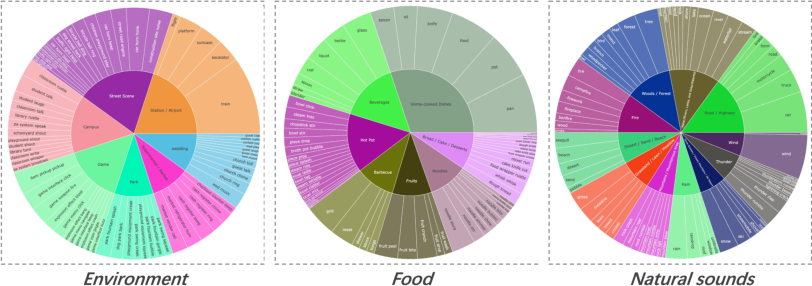
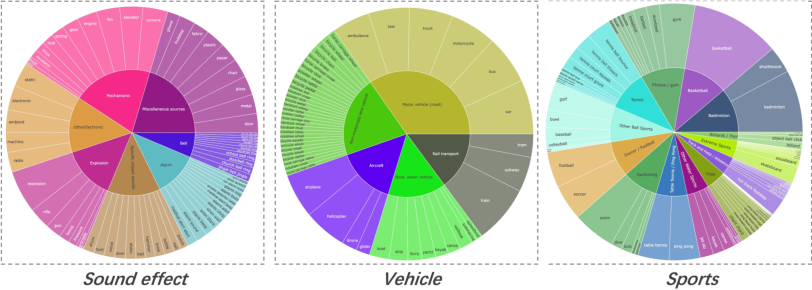
Figure 5: Hierarchical structure of visual tags and subcategories in the labeling system.
Hierarchical Data Filtering
A staged filtering funnel progressively tightens criteria from initial joint-training to SFT and high-resolution refinement, sequentially purifying the data pool for foundational learning, prompt fidelity, aesthetic improvement, and ultra-high-resolution generation.
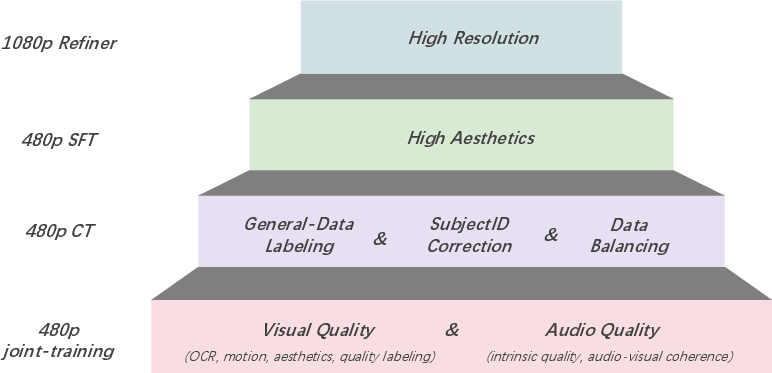
Figure 6: Data filtering funnel for incremental quality refinement across training phases.
Training and Inference Recipes
The multi-stage curriculum leverages large-scale TTS pretraining and multi-condition instruction tuning for Audio DiT, staged full-parameter joint training for T2VA/I2VA/R2VA, and specialized refiner training for 1080p output. Modalities exhibit disparate convergence and sensitivity, necessitating asymmetric learning rates: VideoDiT aggressively updates, AudioDiT preserves domain knowledge to mitigate catastrophic forgetting under distributional shifts.
Aesthetics optimization relies on synthetic data with high visual fidelity and meticulous mixing strategies, achieving a 25.41% visual quality win rate post-finetuning (vs. 10.65% baseline), without audio degradation.

Figure 7: Before and after high-aesthetic finetuning comparison—enhanced vibrancy, clarity, composition.
Inference exploits multi-condition CFG and adapted APG for synchronized guidance, with cross-attention dropout fortifying modal independence and prompt engineering aligning user queries to training distribution, achieved via LLM-driven schema rewriting and retrieval-augmentation.
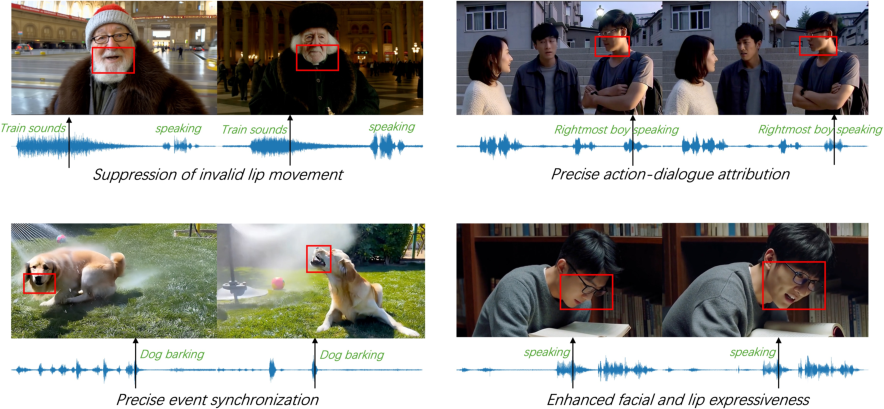
Figure 8: Dual-condition generation: text-only versus additional mutual cross-attention signal.

Figure 9: Prompt engineering amplifies visual quality and distinctive audio event rendering.
Role-Playing Animate: Cross-Modal Reference Conditioning
ALIVE demonstrates reference-guided animation via multi-reference latent conditioning, Ref-Temporal PE Offset, and dual-scale guidance, allowing identity anchoring and character-faithful motion without temporal leakage. Reference conditioning separates identity guidance from scene progression, enabling robust subject consistency.

Figure 10: Reference-driven animation examples—showing strict identity preservation across dynamic scenarios.
Benchmarking and Evaluation
Alive-Bench 1.0 is introduced, covering 264 samples spanning single/multi-speaker, diverse scenarios, languages, and compositional user-like prompts. Evaluation metrics are decomposed across six major axes (motion quality, visual aesthetic, visual prompt following, audio quality, audio prompt following, audio-video synchronization), further split into 22 granular dimensions for diagnostic capability attribution.
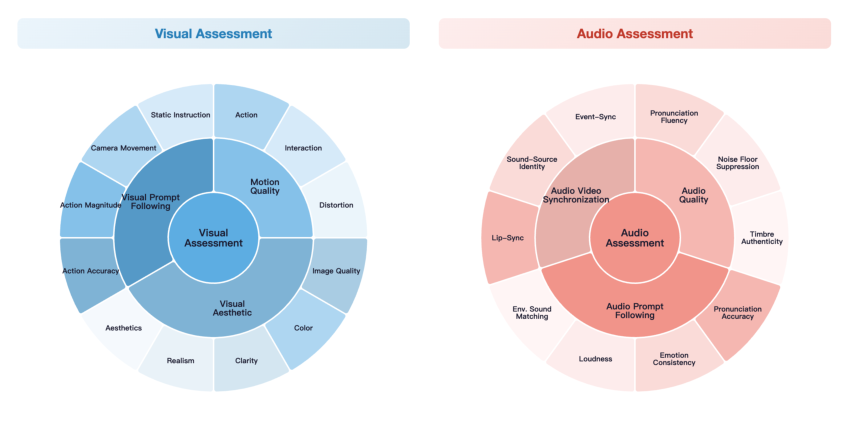
Figure 11: Fine-grained evaluation metric categories for joint AV assessment.
Qualitative and quantitative evaluations reveal ALIVE consistently outperforms leading commercial and open-source models, leading in audio prompt following and cross-modal synchronization, while achieving near-parity in visual and motion domains.
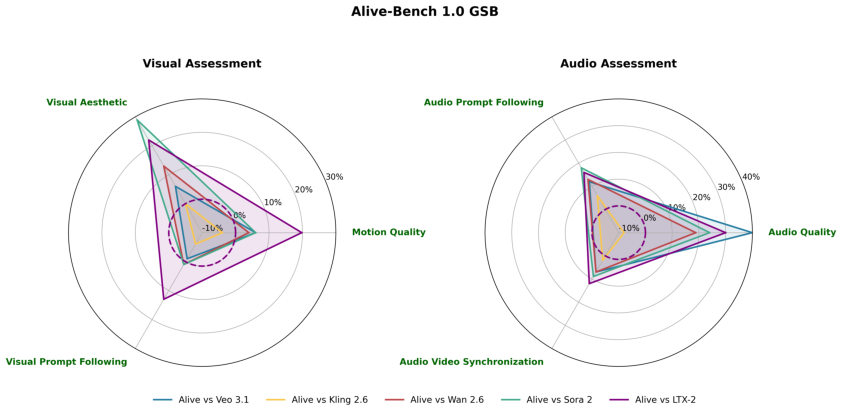
Figure 12: Human evaluation win rates for ALIVE versus Veo 3.1, Kling 2.6, Wan 2.6, Sora 2, and LTX-2.
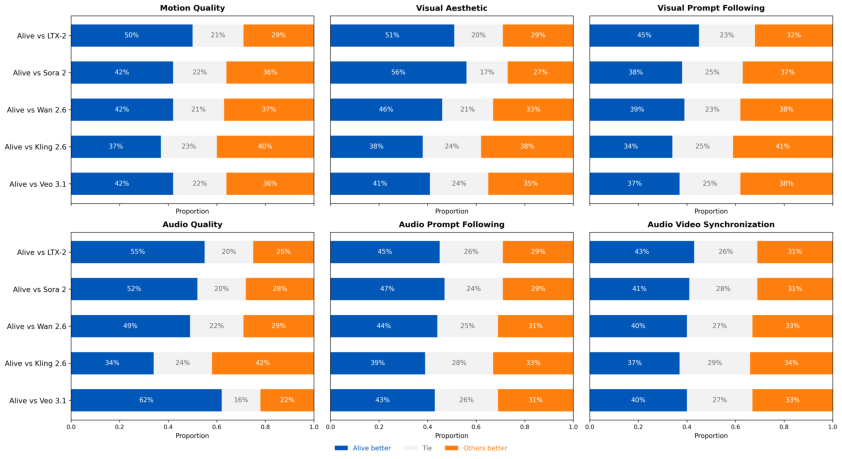
Figure 13: Stacked bar charts—user preference votes, showing ALIVE's balanced dominance across metrics.
On reference-character benchmarks, ALIVE exhibits higher reference-character faithfulness compared to Wan 2.6, with continued advantage on audio dimensions.
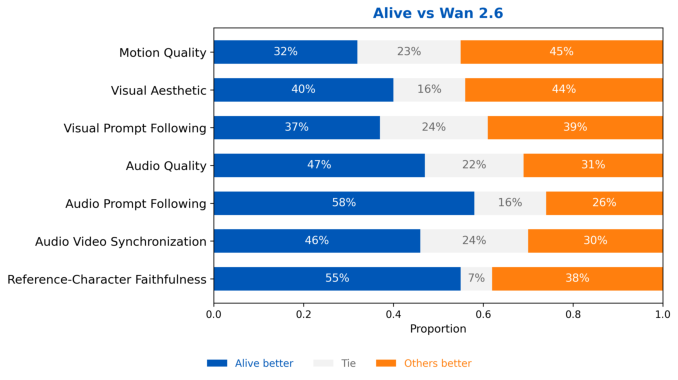
Figure 14: Reference-character human evaluation: ALIVE demonstrates superior identity preservation and synchronization.
Practical and Theoretical Implications
Practically, ALIVE enables end-to-end generation of synchronized, highly realistic audio-video content with robust multi-condition and reference guidance, unlocking applications in personalized content creation, virtual agents, and avatar animation. Theoretically, the joint training paradigm, hierarchical data filtering and reference conditioning design strongly inform future multimodal generative modeling, addressing key modality alignment, data scarcity, and prompt discrepancy issues. The benchmark's fine-grained decomposition provides a template for comprehensive joint-modal evaluation.
Conclusion
ALIVE establishes a well-architected, multimodal framework for synchronized and lifelike audio-video generation. By solving modality synchronization, prompt alignment, and reference conditioning at both architectural and data levels, it achieves robust capability across all major evaluation axes. The model's explicit solutions to audio sensitivity, catastrophic forgetting, and prompt schema alignment, coupled with detailed benchmarks, provide a foundation for continued advancement in unified generative modeling (2602.08682).