- The paper introduces the Bayesian Neural Network Process (BNNP), which meta-learns flexible weight-space priors through amortised inference.
- It employs a layerwise conditional variational framework with a PP-AVI objective to achieve high fidelity in approximate posteriors and scalable training.
- The study demonstrates that carefully designed meta-learned priors coupled with quality inference can significantly enhance Bayesian neural network performance.
Introduction and Motivation
The paper presents the Bayesian Neural Network Process (BNNP), a variational meta-learning framework that enables meta-learning of weight-space priors for Bayesian Neural Networks (BNNs) by amortising inference across datasets. The research is motivated by the inadequacy of conventional priors in weight space—such priors are rarely interpretable or well-matched to the complex structure of real-world data. Standard choices, e.g., isotropic Gaussian priors, reduce BNNs to smoothers akin to Gaussian Processes, precluding effective hierarchical representation learning. In contrast, the BNNP leverages ideas from Neural Processes (NPs), casting the weights of a BNN as a latent variable and enabling both amortised inference and the meta-learning of flexible priors. This framework enables the study of Bayesian deep learning under well-specified priors and supports enhanced probabilistic meta-learning, including regimes of large context sets or severe data-starvation.
The BNNP performs amortised inference over BNN weights by meta-learning a prior across a collection of datasets, treating the entire set of weights as the latent variable in a NP-like architecture. Amortised inference is realised through layerwise conditional variational posteriors, with pseudo-likelihood parameters generated by task-specific inference networks.
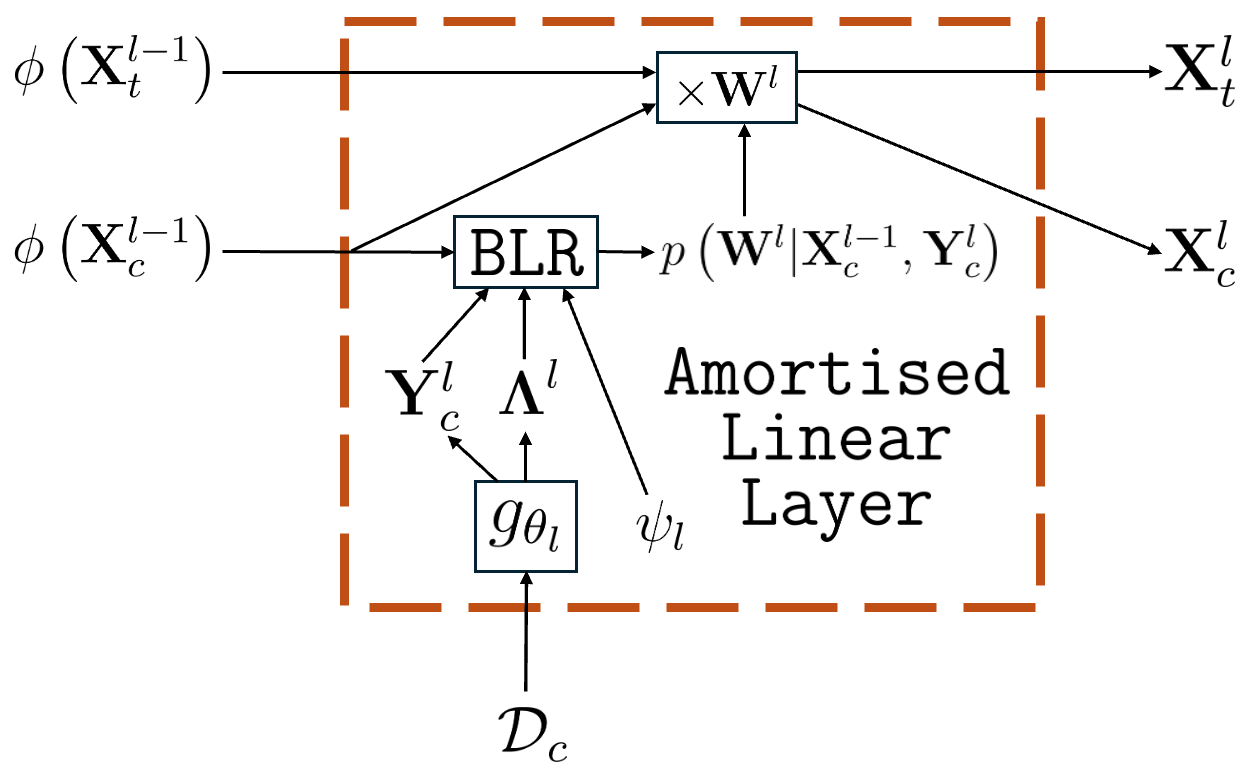
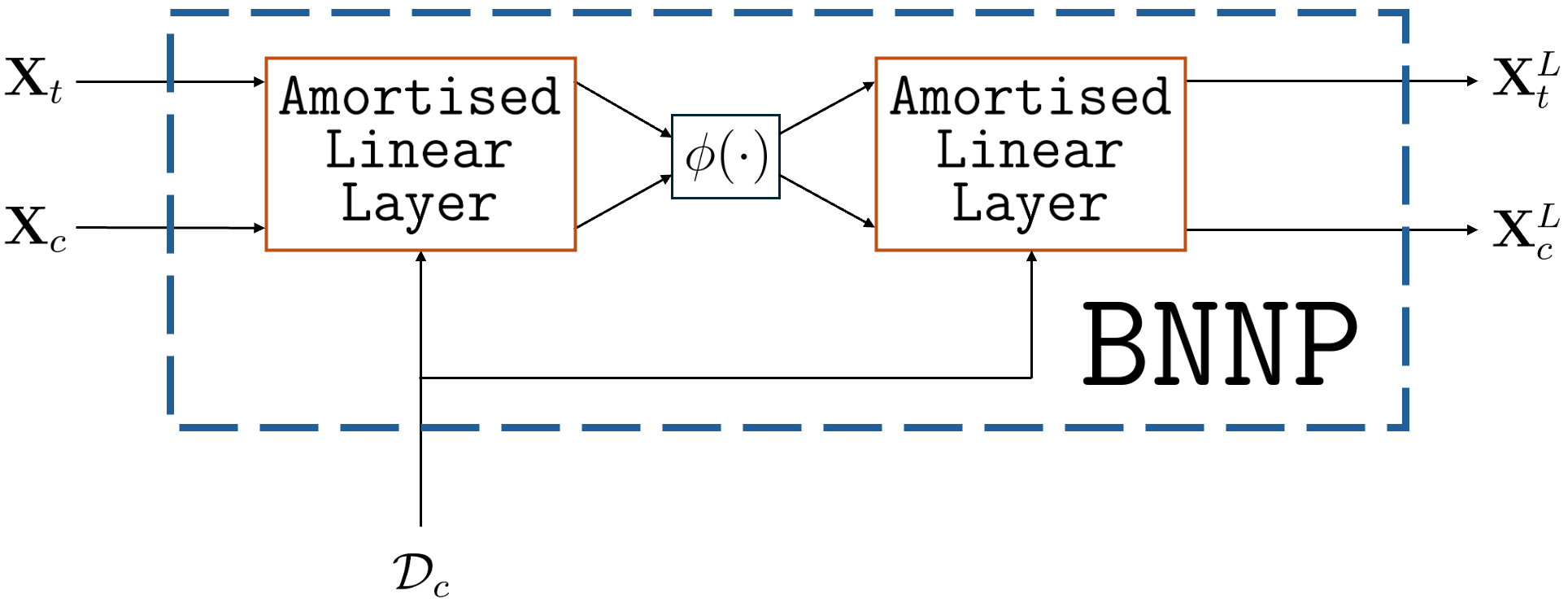
Figure 1: Computational diagrams of (a) the amortised linear layer, and (b) a BNNP with one hidden layer of activations.
The BNNP recursively infers posterior weights layerwise; pseudo-observations per layer are produced via a learned inference network, and each conditional posterior can be computed in closed form under Gaussian assumptions. This layerwise formulation, together with inference network parameterisation, permits efficient amortisation across datasets and supports tractable minibatching and online updates.
Variational Training and the PP-AVI Objective
Training of the BNNP is based on the posterior-predictive amortised variational inference (PP-AVI) objective, which combines the log posterior predictive density on the task’s target set with the standard evidence lower bound (ELBO) on the context set. This joint objective enforces three desiderata: accurate approximate posteriors, a prior that captures the data-generating process, and high-quality predictions. The approach is compatible with stochastic gradient training on large meta-datasets and supports within-task context set minibatching via sequential Bayesian updates, enabling scalability without sacrificing posterior accuracy.
Empirical Quality of BNNP Inference
An extensive empirical study demonstrates that the BNNP structure yields approximate posteriors of high fidelity, often closely matching the exact posteriors where closed forms are available. Benchmarking against MFVI, global inducing point VI (GIVI), and correlated VI baselines with varying ranks, the BNNP consistently exhibits lower KL divergence from the true posterior and more accurately closes the ELBO–marginal likelihood gap.
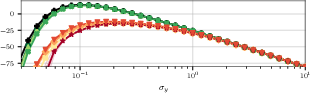
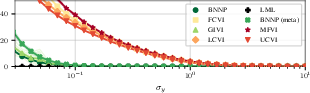
Figure 2: ELBO and KL divergence between approximate and true posteriors for different VI methods. The BNNP well-approximates the true posterior.
The analysis also underscores the sensitivity of inference quality to likelihood noise and shows that BNNP’s fidelity is robust under regimes where mean-field or fully correlated VI approaches degenerate.
Learning Structured Weight-Space Priors
Critically, the BNNP is capable of meta-learning highly structured and expressive priors that match the true data-generating processes. Across synthetic (e.g., sawtooth, Heaviside, ECG functions) and real datasets (e.g., MNIST), the model’s learned priors can replicate observed function statistics and generate plausible sample functions, in contrast to the unstructured behavior of prior handcrafted choices.
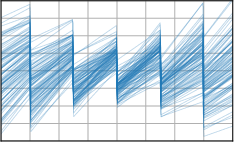
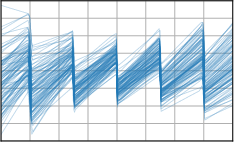
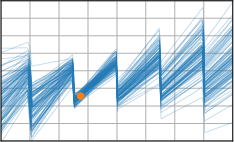
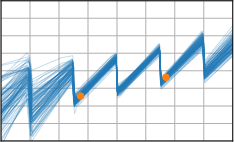
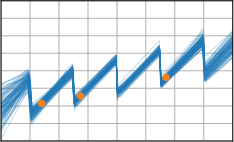
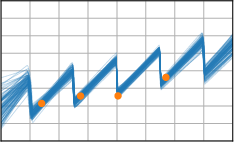
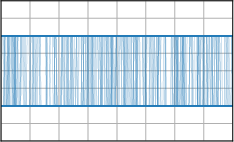
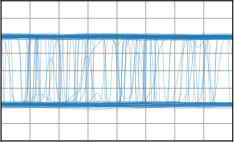
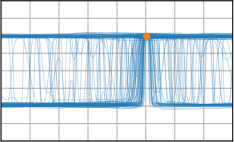
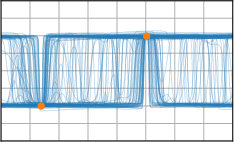
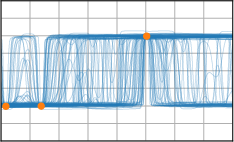
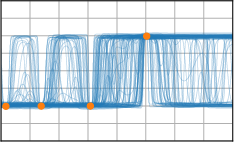
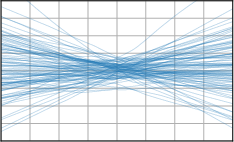
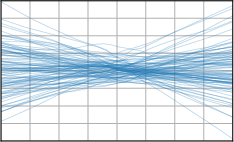
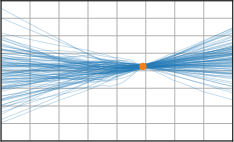
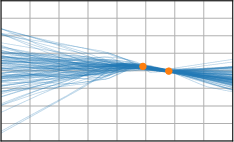
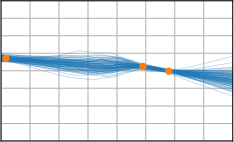
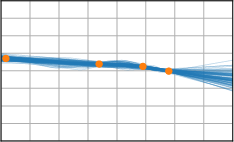
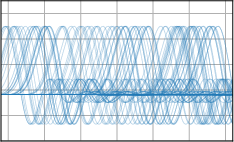
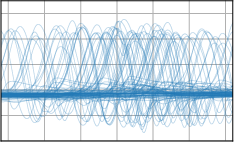
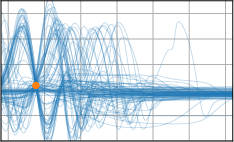
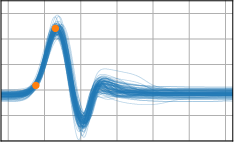
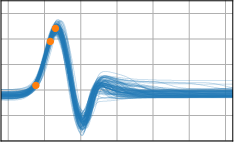
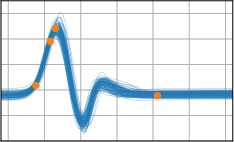
Figure 3: Function samples from the true data-generating process (first column), learned BNNP prior predictive samples (second column), BNNP posterior predictive function samples (remaining columns).
For high-dimensional generative tasks such as image super-resolution, the attention-augmented BNNP (AttnBNNP) intrinsically supports sampling from the prior over continuous input domains, yielding coherent data-generating distributions (e.g., MNIST digits) without requiring explicit architectural output alignment.



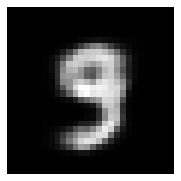







Figure 4: Generative modelling of MNIST digits with the AttnBNNP; prior samples exhibit coherent digit structure and native super-resolution capability.
The Role of Priors versus Approximate Inference
A central experimental result is the demonstration that, even under a strong, well-specified prior, the choice and quality of the approximate inference method significantly affect predictive performance. The BNNP framework is thus used as a scientific probe to contrast various inference algorithms (SWAG, mean-field VI, HMC, SGLD, etc.) under both standard and meta-learned priors on synthetic and real prediction tasks (e.g., precipitation over ERA5).
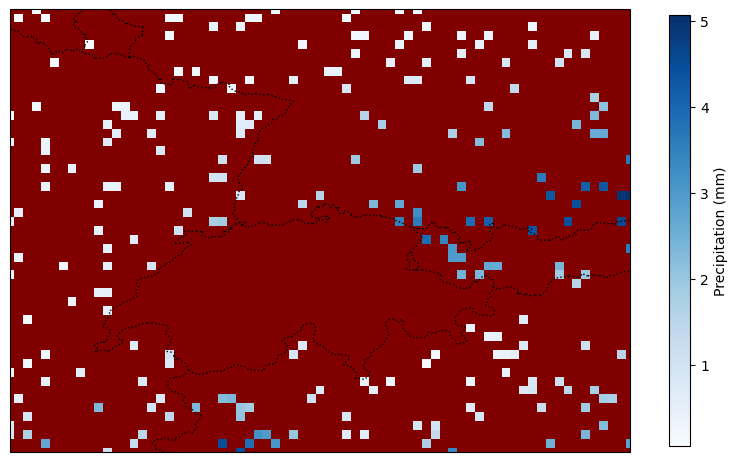
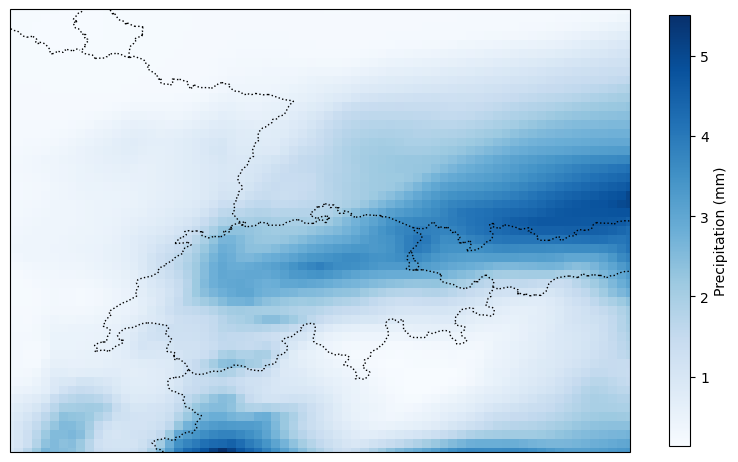

Figure 5: Demonstration of an ERA5 precipitation prediction test task with the BNNP. Predictive uncertainty adapts to missing context, and the model captures prior-driven spatial variance.
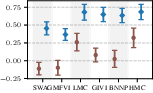
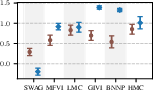
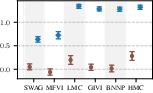
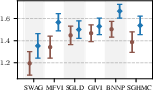
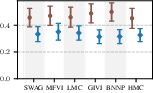
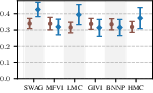
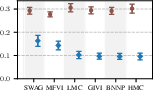

Figure 6: Target-set performance of approximate inference algorithms under a well-specified prior (blue) and a standard BNN prior (brown). The learned prior almost always leads to improved performance.
Results confirm that learned task-specific priors give a consistent boost to all inference schemes, but high-quality approximate inference remains critical for closing the performance gap—no inference algorithm “gets a free lunch” solely from prior learning.
The separation of prior and inference parameters in BNNP decouples the tension between amortised inference fidelity and prior overfitting, a long-standing limitation in NPs. By selectively freezing subsets of prior parameters (e.g., last-layer weights) the BNNP provides a continuum of prior flexibility, allowing practitioners to “tune” the model according to data availability and overfitting risks.
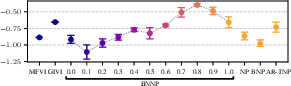
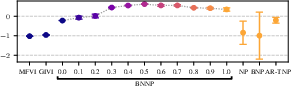
Figure 7: Test-task target-set performance for two meta-learning problems with limited data. BNNPs with partially trainable priors perform the best.
Empirically, partially flexible priors universally outperform either fully flexible or entirely fixed (“broad”) priors for low-data settings (e.g., Abalone and Paul15 single-cell meta-regressions), demonstrating that this “Goldilocks” regime is essential for effective uncertainty quantification and generalisation when ∣Ξ∣ is small.
Online and Minibatch Updates
Inference in the BNNP supports within-task context-set minibatching through sequential updates at every layer—a property uncommon in the neural process literature. Furthermore, a (last-layer) online update scheme allows prediction adaptation when new context points are encountered, efficiently re-using previous inference results when full context reprocessing is intractable.
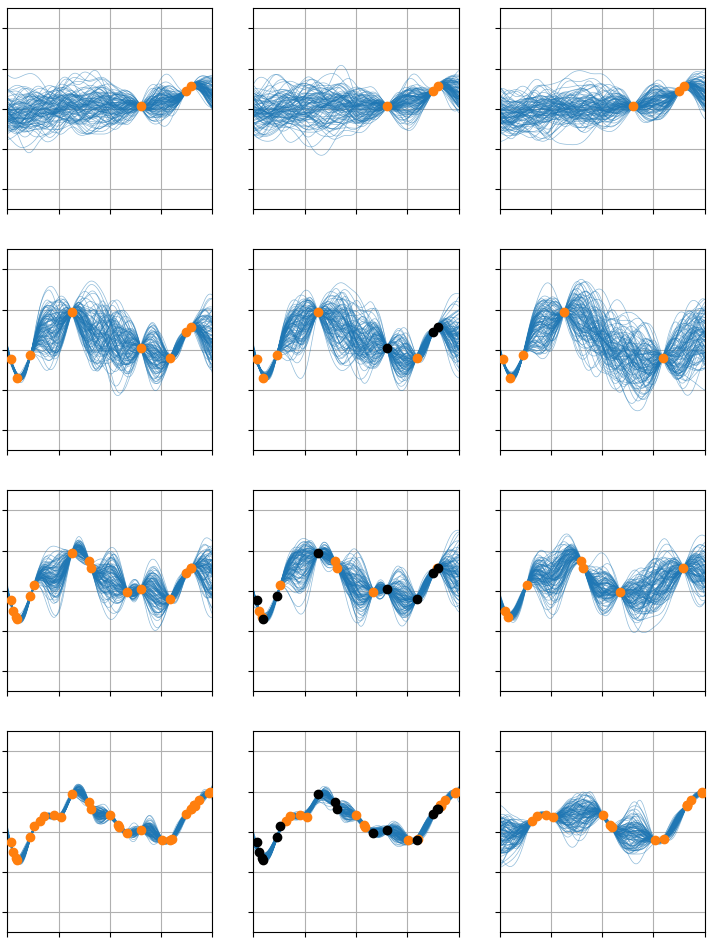
Figure 8: Demo of the online learning scheme: left—full context, center—online updates, right—new data only. Per-row: increasing observed context.
Extensions with Attention and Consistency Limitations
The BNNP’s design enables the inclusion of attention both in encoders (AttnBNNP) and decoders, generalising to transformer-like architectures (“BNAMs”). While attention-based decoders increase expressiveness, they compromise the Kolmogorov consistency of joint predictive distributions—BNAMs no longer represent valid stochastic processes, as the predictive marginal for a subset of inputs can depend on the query set.
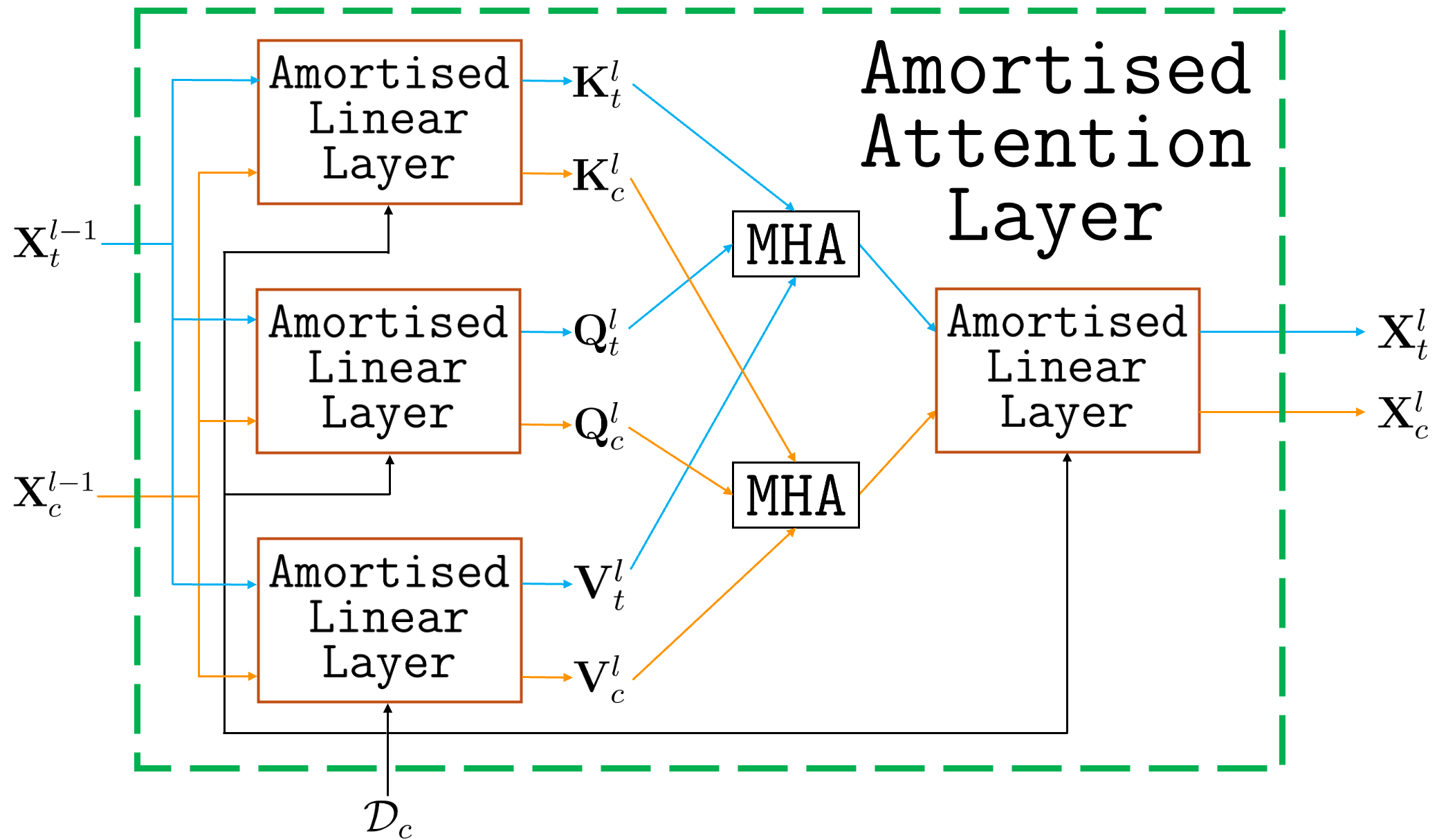
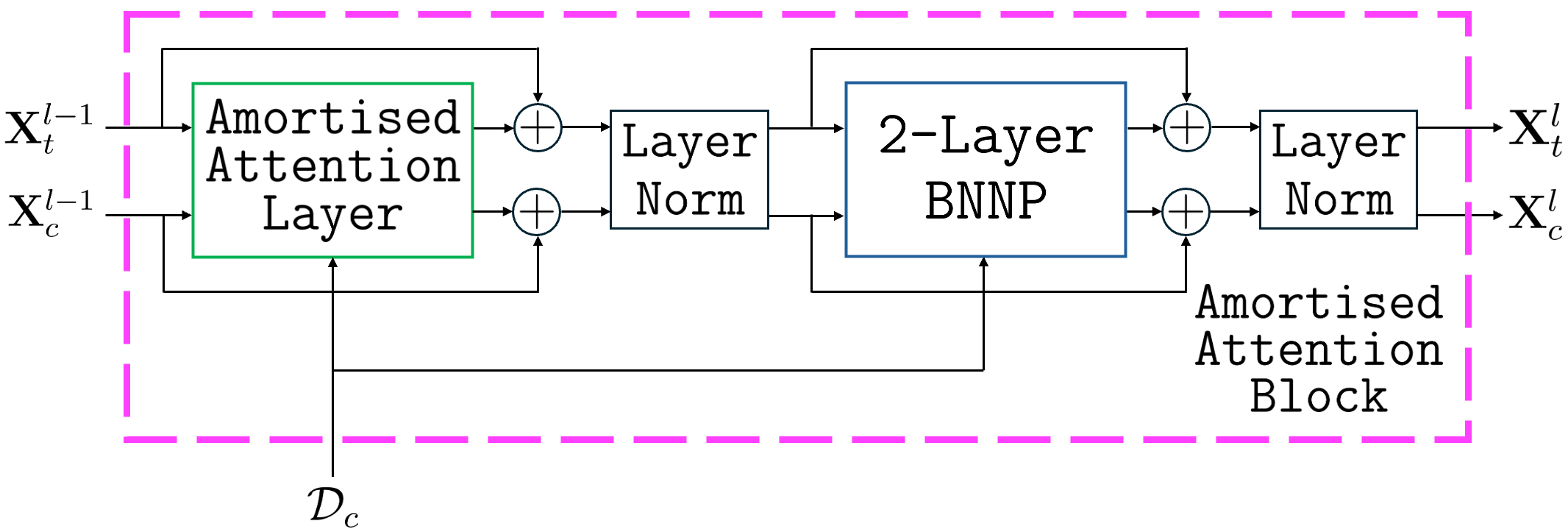
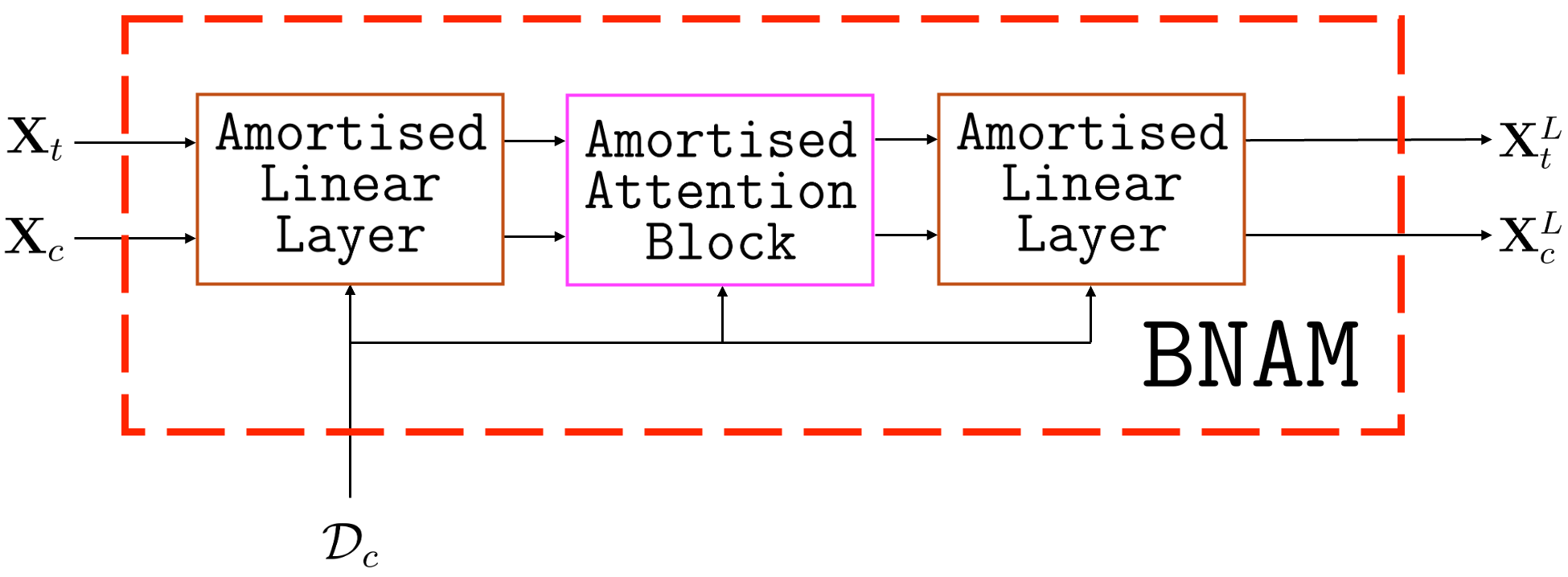
Figure 9: Computational diagrams of the amortised attention layer (a), amortised attention block (b), and BNAM (c).
Experimental demonstrations confirm the breakdown of marginal consistency in the BNAM when OOD target queries are appended post hoc.
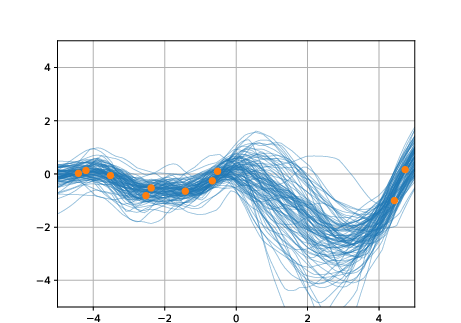
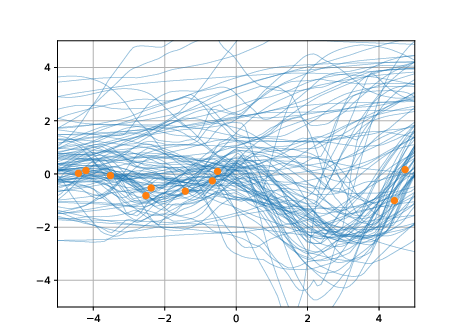
Figure 10: Inconsistent predictive distributions of a BNAM trained on GP-prior data—adding a single OOD target alters all predictions.
Implications and Future Directions
The study shows that the BNNP delivers high-quality approximate inference, robust amortisation, and explicit, meta-learned priors that capture the covariance structure of complex real-world data. Critically, simple Gaussian priors in BNNs, once viewed as too restrictive, possess sufficient expressivity for highly structured stochastic processes, opening the way for scientific study and practical deployment of BNNs with data-driven priors.
Practically, BNNPs are essential tools in the probabilistic meta-learning toolkit for settings with few observed tasks and a need for interpretable/controllable generalisation. Theoretical implications include reinforcing that high-fidelity approximate inference remains indispensable even in the meta-learned prior regime and that scalability, consistency, and flexibility must be balanced according to task demands.
The explicit Bayesian meta-learning perspective advocated here aligns with increasingly popular concepts in transformer-based meta-inference and in-context probabilistic inference, suggesting a convergence of Bayesian deep learning and the architecture advances in conditional generative models.
Conclusion
The BNNP framework provides a blueprint for amortising inference and meta-learning hierarchical, interpretable priors in BNNs. It achieves high-quality approximate inference, enables meta-learning of expressive priors aligned with empirical functional statistics, and supplies new practical tools—scalable minibatching, online adaptation, and adjustable prior flexibility—beyond the scope of existing NPs. This architecture is not only of practical value for data-driven uncertainty quantification but also for scientific analysis, dissecting the relative importance of priors and approximate inference in Bayesian neural networks. The results reinforce that the data-driven construction and deployment of well-specified priors are both feasible and necessary for robust Bayesian deep learning.