- The paper introduces a ground-truth-aware Gt-Margin score that quantifies token confidence differences to guide the unmasking order in masked diffusion language models.
- It develops a bidirectional Transformer-based planner trained via learning-to-rank to approximate the oracle unmasking order, yielding significant performance improvements on reasoning tasks.
- Empirical results demonstrate that early-stage, context-sensitive unmasking order is critical for enhancing structured logical reasoning and overall model output quality.
Ground-Truth-Guided Unmasking Order Learning in Masked Diffusion LLMs
Introduction and Motivation
Masked Diffusion LLMs (MDLMs) offer a flexible alternative to autoregressive (AR) generation by iteratively reconstructing masked tokens in arbitrary order, effectively decoupling the "what-to-unmask" and "where-to-unmask" decisions during text generation. While existing training objectives for MDLMs optimize token-level prediction (focusing on what-to-unmask), the crucial inference-time decision of where-to-unmask remains largely implicit and is typically delegated to heuristic confidence scores or, more rarely, to costly reinforcement learning-based planners.
The paper "Where-to-Unmask: Ground-Truth-Guided Unmasking Order Learning for Masked Diffusion LLMs" (2602.09501) addresses the question of how to design an efficient, supervised mechanism for determining unmasking order. The authors introduce Gt-Margin, a ground-truth-aware, position-wise oracle score based on the model’s probability margin for the correct token over its strongest competitor. Using Gt-Margin, they demonstrate that strongly improved generation—particularly for structured logical reasoning tasks—is attainable by emphasizing easy-to-hard ordering during decoding. The core contribution is the formulation and supervised training of an unmasking planner that imitates Gt-Margin, providing a deployable solution that requires no changes to the token model or additional RL rollouts.
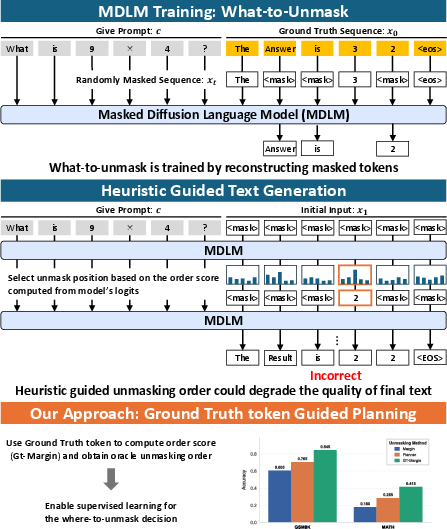
Figure 1: MDLMs learn what-to-unmask but leave where-to-unmask implicit, and heuristic scores (e.g., Margin) can yield incorrect outputs. Gt-Margin enables a planner that imitates the oracle ordering, boosting reasoning accuracy without modifying the token model.
Analysis of Ground-Truth-Guided Ordering
Gt-Margin as Oracle Ordering
The authors formalize the unmasking order problem as a learning-to-rank (LTR) task. At each step, the masked positions are ranked and unmasked according to a score. Standard inference-time heuristics such as Top-Prob (maximum token probability) or Margin (difference between top-1 and top-2 probabilities) provide only a weak signal. By contrast, the Gt-Margin score directly incorporates ground-truth information: for each masked position, it is the difference between the model’s probability for the correct (ground-truth) token and its highest alternative. Large margins denote contextually easy positions for immediate unmasking.
Empirical evaluation demonstrates substantial improvements from oracle ordering. For example, on GSM8K, the difference between using the Margin heuristic (accuracy 0.605) and the Gt-Margin oracle (accuracy 0.845) is profound, with analogous improvements on MATH and Sudoku. Notably, heuristic orderings tend to degenerate to monotonic unmasking (e.g., nearer left-to-right), while Gt-Margin enables adaptive jumps to contextually easy targets.
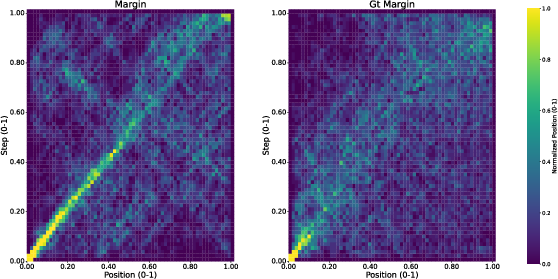
Figure 2: Unmasking-order heatmaps on GSM8K—Margin collapses to near-diagonal (monotonic), whereas Gt-Margin exhibits context-sensitive, adaptive selection across positions.
Significance and Temporal Locality of Ordering
To isolate when the unmasking order exerts maximal influence, the authors perform a stepwise replacement analysis. When only early unmasking steps deviate from the Gt-Margin oracle (by substituting with heuristic or random order for just 10% of the trajectory), performance degrades drastically on all datasets except those with deterministic structure (e.g., Sudoku under some settings). This indicates that the initial phase of decoding imposes a strong inductive bias that later steps cannot correct.
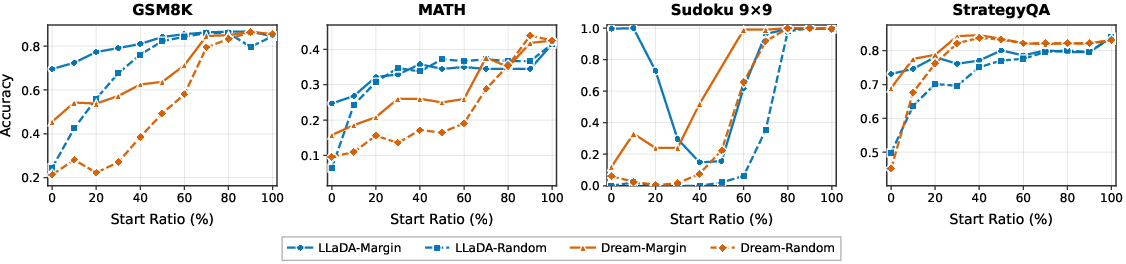
Figure 3: Early-stage deviations from Gt-Margin degrade final accuracy—early ordering decisions are disproportionately critical.
Further, hybrid decoders using Gt-Margin for the first n% of steps and heuristic orderings afterward recover most of the oracle’s benefit for n near 50%. This underscores that oracle-style ordering mainly matters when the context is highly entropic and uncertainty is widespread.
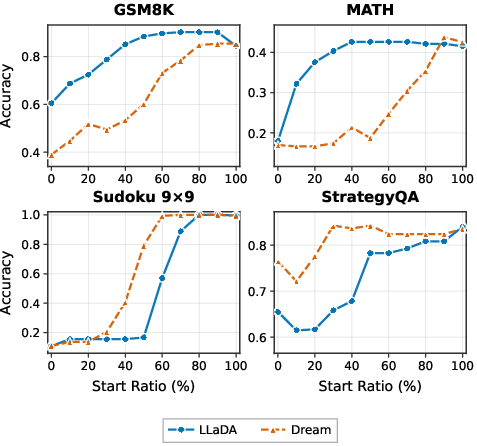
Figure 4: Using Gt-Margin for roughly the first half of decoding is enough to secure most of its performance gain.
Oracle Distillation: Planner Training via Learning-to-Rank
Planner Architecture and Training
Recognizing that Gt-Margin is infeasible at inference due to its ground-truth dependence, the authors train a dedicated planner to approximate the oracle’s ordering from observed input alone. The planner is structured as a bidirectional Transformer with a lightweight MLP head, operating over the masked sequence plus an auxiliary reconstruction (the token model’s argmax at masked positions). The LTR objective specifically targets accurate top-k predictions using PiRank’s differentiable NDCG@k surrogate.
The training regime generates partially masked inputs via stochastic, rank-conditioned masking to ensure the planner’s exposure matches realistic inference-time states, and uses oracle-derived rankings for direct supervision.
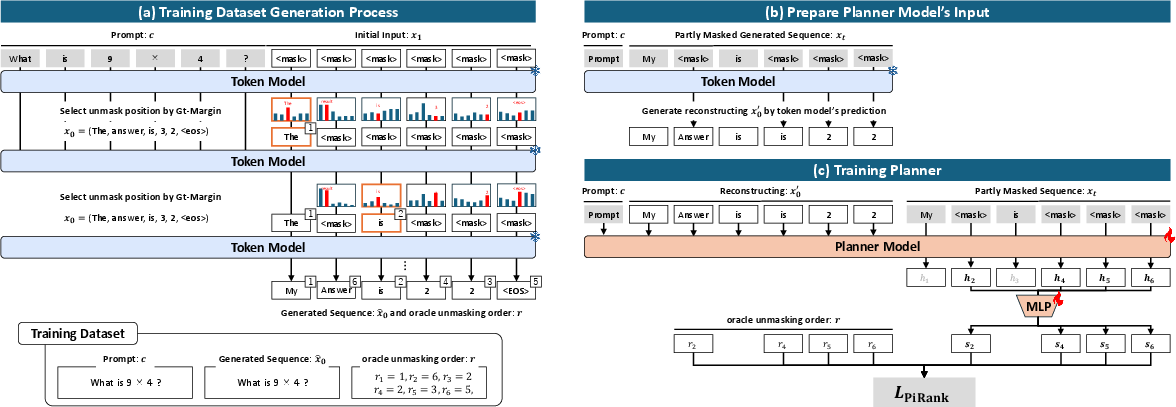
Figure 5: Overview of planner training—oracle unmasking order is distilled by generating partially masked states and training the planner to rank positions according to Gt-Margin.
Evaluation and Ablations
The deployable planner—used in the first half of the unmasking trajectory—yields significant accuracy gains over baseline heuristics, especially on complex reasoning datasets such as GSM8K and MATH. The planner consistently outperforms heuristic approaches, with ablations confirming that:
- Employing planner guidance only in the early trajectory (partial-plan decoding) is more effective than planner-only or heuristic-only orderings.
- Augmenting planner input with the token model’s own argmax predictions at masked positions (the reconstruct-then-plan approach) further improves safe position selection.
Practical and Theoretical Implications
This work rigorously separates the where-to-unmask decision from what-to-unmask in the MDLM paradigm. By demonstrating that state-dependent, easy-to-hard unmasking orders—extractable from ground-truth but previously overlooked by heuristics—undergird accurate reasoning and structured generation, the approach sets a new direction for non-AR sequence modeling. The practical implication is that order-planning can be modularized and enhanced independently of the underlying token model, bypassing the need for costly on-policy RL optimization.
For domains requiring strict logical dependencies (e.g., mathematics, programming), the findings point to early unmasking policies as the locus for further optimization, potentially motivating more explicit modeling of context uncertainty and dependency graphs during decoding. From a theoretical perspective, the results highlight the non-monotonicity and distribution-shifting dynamics that make order selection in MDLMs more consequential than in monotonic AR models.
Dataset and Output Length Characteristics
The effectiveness of order planning is partly modulated by dataset characteristics, such as output length and structure regularity. The paper provides an empirical analysis of output length distributions, noting that right-skewed or longer outputs amplify the impact of order selection, while strictly regular outputs (e.g., Sudoku) respond differently, possibly due to structural constraints.
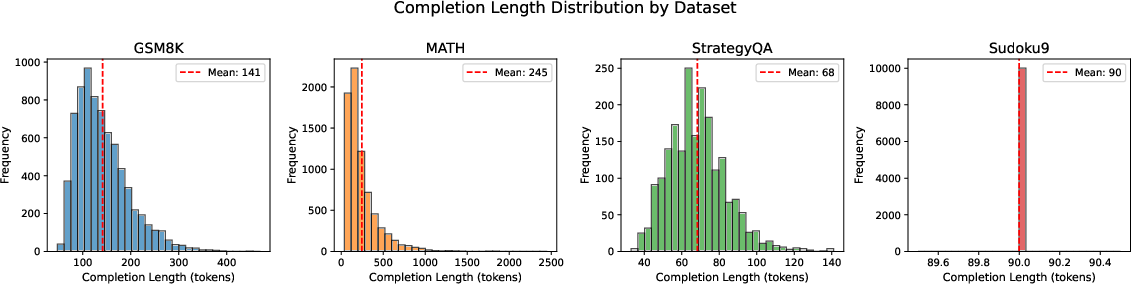
Figure 6: Completion length distributions by dataset—complex logical tasks (GSM8K, MATH) show broad, right-skewed token counts, increasing the impact of unmasking order strategies.
Conclusion
This paper establishes a formal and empirical foundation for learning ground-truth-guided unmasking order in masked diffusion LLMs. It introduces a theoretically justified oracle score (Gt-Margin), demonstrates its decisive effect in the early stages of decoding, and realizes a practical, modular planner via supervised learning-to-rank. The approach enables significant quality improvements in generation—especially for logical reasoning tasks—without any changes to the base token model or reliance on RL-based search. Future avenues could explore dynamic adjustment of planner depth, cross-task generalization, and integration with structured prediction constraints for even broader application in controllable, non-autoregressive language modeling.