- The paper presents a consolidated set of orthogonal optimizations for 3D Gaussian Splatting, achieving 4.1–5.2× training speedup and up to 30% VRAM reduction while preserving output fidelity.
- It details key improvements such as fused optimizer-backward steps, per-Gaussian gradient computation, and memory coalesced densification to minimize computational overhead.
- The framework extends to 4D dynamic scenes and offers an extensible testbed, paving the way for future integration of second-order optimization and robust anti-aliasing techniques.
Faster-GS: An Analysis and Optimization of 3D Gaussian Splatting
Introduction
"Faster-GS: Analyzing and Improving Gaussian Splatting Optimization" (2602.09999) presents an extensive assessment and systematic improvement of the 3D Gaussian Splatting (3DGS) optimization pipeline. While recent progress in 3DGS has led to a fragmented landscape with numerous optimizations, many of these contributions entangle algorithmic modifications with low-level implementation improvements, impeding fair and comprehensive comparison. This paper consolidates and evaluates the most effective orthogonal optimizations, introduces novel efficient algorithms, and delivers an integrated, high-performance 3DGS baseline that establishes new standards for training speed and resource usage, all while preserving or exceeding the original method's fidelity.
The Faster-GS framework also provides an extensible testbed that enables seamless integration into existing pipelines and transparent benchmarking of future proposals. Notably, all improvements are compatible with the original CUDA-based differentiable rasterization pipeline and are demonstrated to generalize to 4D Gaussian Splatting for dynamic non-rigid scenes.
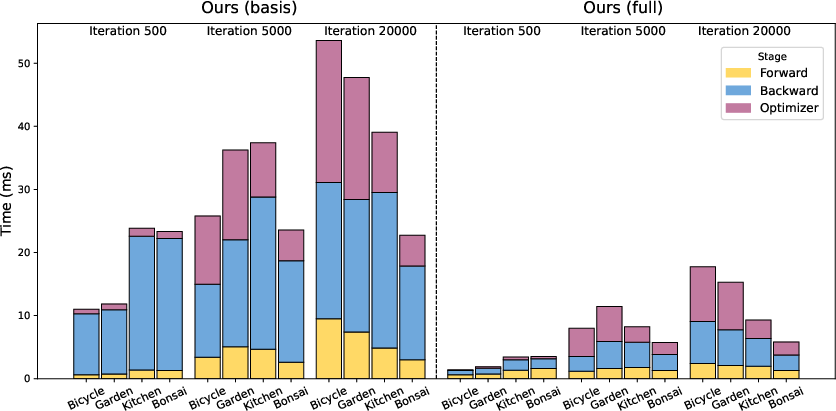
Figure 1: Runtime comparison reveals substantial reductions in both forward/backward pass and optimizer times across optimization stages during Faster-GS training on Mip-NeRF360 scenes.
Methodology: Consolidation and Novel Optimizations
Faster-GS architecture stacks a series of independent, implementation-level optimizations on top of a carefully refactored 3DGS baseline. The approach rigorously avoids algorithmic or representational modifications that could impact visual fidelity or number of primitives, focusing exclusively on enhanced numerical stability, memory efficiency, and reduced compute overhead.
Surveyed Improvements
Key optimizations consolidated from the literature include:
- Precise 2D Gaussian Tile Bounding: Conservatively computes tile intersections using opacity-aware ellipses rather than axis-aligned bounding squares.
- Load-Balanced Tile-Based Culling: Reduces unnecessary rasterization work while minimizing memory and sort requirements.
- Two-Stage Sorting (Depth and Tile): Replaces the original monolithic 64-bit sort, significantly decreasing VRAM load and aggregate time complexity, scalable to large primitive counts.
- Per-Gaussian Backward Pass: Allocates gradient computations by Gaussian, leveraging shared memory and warp-level primitives to minimize atomic operation overhead and eliminate pixel-centric stalls.
- Rasterization Kernel Fusion: Aggressively fuses activation of parameters, memory layout transformations, and spherical harmonics into a condensed CUDA kernel to reduce memory traffic.
- Fusion of Adam Parameter Updates: Implements a custom, highly fused Adam optimizer that matches PyTorch’s behavior but eliminates redundant buffer accesses and synchronizations, yielding substantial speedups.
Novel Contributions
The paper introduces further orthogonal advancements:
- Memory Coalesced Densification: Inserts z-order reordering during densification phases, ensuring spatial locality of neighboring Gaussians and substantially improving memory access patterns under large working sets.
- Optimizer–Backward Fusion: As parameter updates become dominant at high optimization speeds, Faster-GS optionally integrates optimizer steps directly within the backward pass, merging buffer usage and reducing kernel launches.
- Numerical Robustness: Consistent handling of degenerate cases, improved quaternion stability, carefully managed activation ranges, and detached compensatory anti-aliasing terms prevent instabilities, especially at high optimizer throughput.

Figure 2: Top: Without anti-aliasing, off-res renderings reveal aliasing artifacts. Bottom: Faster-GS with anti-aliasing eliminates such artifacts, yielding robust fidelity under resolution-induced sampling mismatch.
Empirical Results
Training Speed and Memory Efficiency
Extensive experiments span 13 challenging scenes from the Mip-NeRF360, Tanks and Temples, and Deep Blending datasets. Across all benchmarks, Faster-GS achieves 4.1–5.2× speedup compared to the original 3DGS, with VRAM reductions up to 30%. Crucially, all modifications retain baseline fidelity: PSNR, SSIM, and LPIPS are statistically indistinguishable across extensive reruns.
The pipeline's ablation analysis, detailed by per-component profiling, confirms that the most significant individual speedups arise from the fused Adam optimizer (1.3–1.5× independently), per-Gaussian backward, and z-ordering for memory coherency, particularly in scenes with >2M Gaussians. The fusion of optimizer and backward steps further incrementally reduces training time and VRAM, though at some cost to framework extensibility.
On hardware scaling, improvements are more pronounced on newer GPUs, with RTX 5090 delivering >4.8× speedup over 3DGS.
4D Gaussian Splatting
The optimization suite generalizes seamlessly to 4D Gaussian reconstruction of dynamic scenes, as evidenced by a strong 2.8–3× training acceleration (with matched or superior metrics) relative to the dynamic baseline on both synthetic (D-NeRF) and real-world sequences (neural3D video dataset).
Rendering Throughput and Anti-Aliasing
Faster-GS also more than triples inference frame rates compared to 3DGS and facilitates modular integration with anti-aliasing extensions from Mip-Splatting. Experimentation with anti-aliasing shows that high training speed and optimal VRAM usage persist in anti-aliased modes, unlike prior implementations, and the modular kernel fusions stabilize optimization even when aggressive filtering is applied.
Analysis, Limitations, and Prospects
Despite eliminating most data and compute bottlenecks in 3DGS training, Faster-GS observes parameter updates as the final dominant cost at the highest optimization throughput. The results motivate the incorporation of second-order (curvature-aware) optimization approaches and further study of ultra-lightweight view-dependent color representations.
The work intentionally avoids pruning, culling, or compression strategies that affect fidelity; such techniques, when layered on Faster-GS, can push efficiency boundaries even further, though complexities in integration and validation will rise. Similarly, many discussed improvements at the inference/rendering stage could be methodically ported to training pipelines using the Faster-GS modular testbed.
Strong anti-aliasing, robust densification alternatives (e.g., MCMC-based), and detailed studies on Gaussian truncation/opacity behaviors are provided and shown to integrate without negative interaction, broadening the design space for future experiments.
Conclusion
Faster-GS establishes a state-of-the-art, resource-efficient, and fully modular baseline for 3DGS research and deployment. The systematic consolidation and extension of optimization strategies, with rigorous ablation and benchmarking, ensure that the framework achieves very fast training (often under two minutes for full-resolution scenes), robust reproducibility, and extensibility to future algorithmic and architectural advances.
The resulting testbed will accelerate novel method development and benchmark integration, closing a critical gap in the 3DGS research ecosystem that previously hindered unified progress.
References
- "Faster-GS: Analyzing and Improving Gaussian Splatting Optimization" (2602.09999)