Learning on the Manifold: Unlocking Standard Diffusion Transformers with Representation Encoders
Abstract: Leveraging representation encoders for generative modeling offers a path for efficient, high-fidelity synthesis. However, standard diffusion transformers fail to converge on these representations directly. While recent work attributes this to a capacity bottleneck proposing computationally expensive width scaling of diffusion transformers we demonstrate that the failure is fundamentally geometric. We identify Geometric Interference as the root cause: standard Euclidean flow matching forces probability paths through the low-density interior of the hyperspherical feature space of representation encoders, rather than following the manifold surface. To resolve this, we propose Riemannian Flow Matching with Jacobi Regularization (RJF). By constraining the generative process to the manifold geodesics and correcting for curvature-induced error propagation, RJF enables standard Diffusion Transformer architectures to converge without width scaling. Our method RJF enables the standard DiT-B architecture (131M parameters) to converge effectively, achieving an FID of 3.37 where prior methods fail to converge. Code: https://github.com/amandpkr/RJF



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI image generators to work better with “smart features” taken from powerful vision models (like DINOv2 and SigLIP). These features live on the surface of a high‑dimensional sphere, not in ordinary flat space. The authors show that the usual training method for diffusion transformers struggles because it ignores this curved, spherical shape. They fix the problem by making the model move along the sphere’s surface (instead of cutting straight through it) and by gently adjusting the training to account for the sphere’s curvature. This lets standard diffusion transformers learn faster and make higher‑quality images without needing to make the models much bigger.
Key Questions and Goals
The paper asks simple questions:
- Why do standard diffusion transformers fail when trained directly on strong visual features?
- Is the problem that the models are too small (not enough “capacity”), or is it something else?
- How can we change the training so the model respects the true shape (geometry) of these features?
The goal is to make regular diffusion transformers work well on these curved feature spaces without expensive changes to the model size, and to improve image quality and training speed.
Methods (Explained Simply)
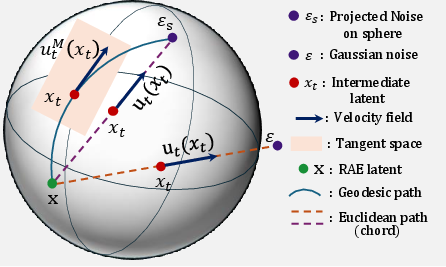
Think of Earth as a sphere. If you want to go from one city to another, the shortest path on Earth’s surface is a curved arc (a “geodesic”), not a straight line through the planet. The paper says today’s methods force the model to walk straight through the “inside” of the sphere (off the surface), which doesn’t make sense for these features.
Here’s what they do instead:
- Riemannian Flow Matching (RFM): They teach the model to move along the sphere’s surface using spherical interpolation (called SLERP). This is like following a flight path along the globe rather than tunneling through Earth.
- Tangent directions: At any point on the sphere, the “allowed” directions are those that stay on the surface, kind of like walking along the ground rather than digging down. The model learns these surface directions (tangent vectors) instead of trying to go inward or outward.
- Jacobi Regularization: On a sphere, paths can “focus” or “spread” because of curvature (like how lines of longitude get closer near the poles). This can make some mistakes more harmful than others. The authors add a smart weighting to the training loss that pays more attention to errors where they would grow bigger due to curvature. Think of it as putting extra care into parts of the route where a small steering mistake would send you far off course.
In practice:
- They project both the data features and the noise onto the sphere (so everything stays on the surface).
- They use SLERP to define the training path (a smooth arc) instead of a straight line.
- They train the model to predict surface‑aligned velocities (directions to move) and weight the training based on curvature (Jacobi Regularization).
- During sampling (generation), they “rotate” along the surface using a closed‑form update so the path stays on the sphere.
Main Findings and Why They Matter
The paper’s experiments show:
- The problem isn’t that the models are too small. The real issue is geometric: straight‑line training paths force the model into “off‑surface” regions where these features don’t live. The model wastes effort fixing the wrong things.
- Switching to surface paths (RFM) dramatically improves training and image quality. Adding Jacobi Regularization improves it even more.
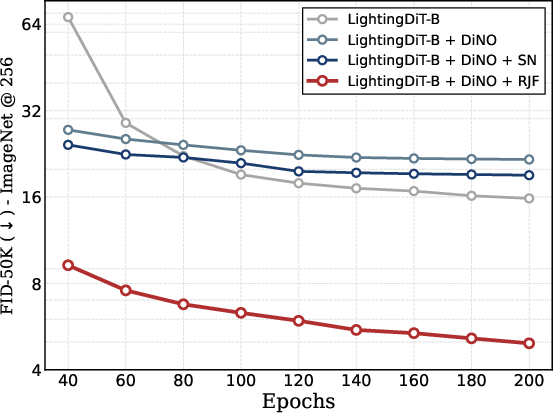
- With their method, a standard‑size diffusion transformer (DiT‑B, about 131M parameters) trains well and produces strong results without “width scaling” (making the model wider and more expensive).
- They report much better FID scores (a common image quality metric where lower is better). For example, where standard methods fail to converge or get poor FIDs (like ~22), their approach reaches FIDs around 6–7 in typical training and as low as 3.37 with guidance and longer training.
- The improvement holds across different model sizes (B, L, XL), different architectures, and different feature encoders (DINOv2, SigLIP, MAE). This means the fix is general, not tied to one specific setup.
Why this matters:
- You get higher‑quality images faster.
- You don’t need to build bigger, more expensive models to make it work.
- Respecting the true geometry of the feature space makes training simpler and more reliable.
Implications and Impact
This research shows that understanding the “shape” of your data can be more important than just adding more model capacity. By designing training to follow curved paths on the sphere and by accounting for curvature effects, standard diffusion transformers can learn rich, semantic features efficiently. This could:
- Make future generative models faster to train and cheaper to run.
- Encourage using strong, pretrained feature encoders directly, avoiding complex extra losses or big model changes.
- Inspire similar geometry‑aware methods in other areas where data naturally lies on curved spaces (like angles, rotations, or normalized embeddings).
In short, the paper’s message is: don’t force a straight path through a curved world. If you move along the surface and adjust for curvature, you unlock better learning with the tools you already have.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of concrete gaps and open questions left unresolved by the paper, intended to guide future research.
- Empirical universality of the hyperspherical assumption:
- The paper asserts near-zero radial variance and strict confinement to a sphere due to LayerNorm, but does not quantify this across:
- Different layers, heads, and token types (e.g., register tokens) within DINOv2.
- Diverse encoders (SigLIP, MAE) and datasets beyond ImageNet-1K.
- Training regimes (fine-tuned vs frozen encoders) and resolutions.
- A comprehensive audit (norm statistics, angular distributions, curvature estimates) is needed to validate that “hard shell” geometry consistently holds.
- Manifold characterization beyond the ideal sphere:
- Real representation spaces may be anisotropic (ellipsoidal), stratified, or product manifolds (e.g., token-wise submanifolds) rather than constant-curvature spheres.
- How does RJF perform when the latent geometry deviates from ? Can RJF be generalized to learned Riemannian metrics or non-spherical manifolds (e.g., hyperbolic, toroidal)?
- Theoretical guarantees for manifold flow matching:
- The paper does not provide a proof that Riemannian flow matching with SLERP and tangent-space velocity fields satisfies the continuity equation on and converges to the target data distribution.
- Formal analysis is needed to ensure equivalence to Euclidean flow matching in terms of consistency and asymptotic correctness, including measure preservation under the manifold ODE.
- Optimality of SLERP as the probability path:
- SLERP is the shortest geodesic path, but is it optimal for the chosen cost and transport structure on the sphere (e.g., Wasserstein geodesics under the spherical metric)?
- Under what conditions (data-noise angle distributions, curvature, dimensionality) is SLERP superior to alternative manifold paths (e.g., geodesic shooting, parallel transport along learned directions)?
- Jacobi regularization: derivation and optimality
- The paper introduces a weighting with limited theoretical exposition (supplementary referenced but not provided here).
- Is this weighting optimal for minimizing endpoint error or maximizing FID? How sensitive is performance to the exact functional form, and can it be learned or adapted online?
- Provide error propagation bounds that justify the curvature-aware weighting in high dimensions.
- Sensitivity and ablation of time sampling and schedules:
- Time sampling via Logit-Normal and the “shift factor” is a nontrivial modification. The paper does not disentangle its contribution from RJF and Jacobi weighting.
- Full ablations on time distribution, , number of steps, and step-size schedules are needed to establish robustness and identify best practices.
- Handling antipodal and near-antipodal cases:
- On , geodesics are not unique at antipodal points. The paper does not discuss numerical stability or path selection when and are (near-)antipodal.
- What strategies (e.g., random great-circle selection, regularization) ensure stability and unbiased training in such regimes?
- Multi-token and structured latents:
- The method treats and as vectors, but DiT operates over sequences of tokens with attention. Are geodesic flows defined per-token, jointly across tokens, or on a structured manifold of sequences?
- How do inter-token correlations and attention-induced geometry affect RJF? Is there benefit in modeling a product manifold or a coupled manifold for token sets?
- Decoder–geometry interaction and radius scaling:
- The observation that increasing inference projection radius () improves FID contradicts the training manifold norm (). Why does decoder confidence prefer larger norms?
- A principled analysis is needed to study the decoder’s sensitivity to feature magnitudes and whether training should incorporate radius scaling or norm-aware calibration to avoid train–test mismatch.
- Prior distribution on the sphere:
- Normalizing Gaussian noise yields (approximately) a uniform distribution on , which may be misaligned with the data distribution.
- Would learned or anisotropic spherical priors improve transport and convergence? How does prior choice impact FID and semantic fidelity?
- Generalization beyond ImageNet-256 and limited epochs:
- Results are reported at resolution with 80–200 epochs. How does RJF perform at higher resolutions, on diverse datasets (COCO, LAION, Places), and under longer training schedules?
- Assess transfer to other modalities (audio, video, 3D) where representation manifolds may differ significantly.
- Fairness of comparisons and compute:
- Baselines differ in epochs and architectural details; wall-clock time, FLOPs, and memory are not reported. It’s unclear how much of RJF’s gains stem from geometric changes versus training budget differences.
- Provide matched-compute comparisons and speedups relative to width scaling with explicit resource reporting.
- Robustness and stability:
- No analysis of training stability (e.g., gradient norms, divergence spikes) or inference robustness (drift under exponential map integration).
- Systematic studies of sensitivity to hyperparameters (learning rate, EMA decay, batch size), numerical precision, and integrator choices are needed.
- Impact on likelihood, calibration, and diversity:
- Evaluation relies on FID/IS/Precision/Recall; no assessments of likelihood proxies, sample calibration, mode coverage, or human preference.
- Include measures that reflect semantic correctness, compositionality, and diversity beyond FID/IS to substantiate “semantic fidelity” claims.
- Applicability to guidance and conditioning:
- RJF is shown with classifier-free guidance, but generalization to richer conditioning (text, layout, multimodal prompts) is unclear.
- How should manifold geometry be handled when conditioning vectors reside on different manifolds (e.g., text embeddings on a distinct hypersphere)?
- Interplay with width scaling and other remedies:
- While RJF reduces the need for width scaling, the paper does not explore combined strategies (e.g., modest width increase + RJF) or compare to alternative remedies (noise projection, tangent-space flows, manifold score matching).
- Establish whether RJF complements or replaces these strategies across model sizes.
- Encoder choice and layer selection:
- Performance on SigLIP and MAE improves but remains far from state-of-the-art. Which layers (pre/post-LayerNorm, registers) yield best manifold properties for RJF?
- Provide a protocol for selecting encoders/layers that maximize RJF effectiveness.
- Continuity equation and divergence terms on manifolds:
- Flow matching avoids explicit divergence terms in Euclidean space via conditional path construction. On , the equivalent manifold continuity constraints and volume element changes (area measure) are not analyzed.
- Clarify whether RJF implicitly satisfies these constraints or if corrections (e.g., manifold divergence penalties) are needed.
- Effects of dimensionality and curvature:
- The paper claims geodesic focusing in positive curvature affects error propagation; quantitative studies of how curvature and ambient dimension change training dynamics and generalization are missing.
- Provide scaling laws (FID vs , curvature) and controlled experiments across dimensionalities.
- Failure modes and bias analysis:
- No inspection of class-wise failures, biases, or mode collapse under RJF. Does manifold-constrained transport exacerbate or mitigate known biases in representation encoders?
- Include fairness, class-conditional fidelity, and rare-class performance analyses.
- Reproducibility details:
- Key hyperparameters for RJF (e.g., for Logit-Normal time sampling, shift factor , integrator steps) are not fully ablated or justified.
- A detailed recipe and sensitivity plots would improve reproducibility and adoption.
- Extensions to stochastic flows and SDEs on manifolds:
- The method uses deterministic ODEs; stochastic manifold SDEs (e.g., score-based diffusion on ) may offer robustness and diversity benefits.
- Open question: can manifold scores and stochastic samplers outperform RJF while preserving geometry?
- Token-level geometry-aware attention:
- Attention operations assume Euclidean vector spaces. How should attention be adapted to respect manifold constraints (e.g., tangent-space attention, geodesic distances) without breaking DiT architectures?
- Understanding why RJF improves semantics specifically:
- The paper reports gains in IS and precision, attributing them to geometric alignment. A causal analysis (e.g., controlled experiments isolating angular learning) would validate this hypothesis.
- Practical guidance for deployment:
- Clear guidelines are missing on when to use RJF (encoder types, layer normalization presence), how to detect geometry gaps, and how to tune Jacobi weighting and radius scaling in practice.
These gaps suggest concrete directions for theoretical analysis, broader empirical validation, and practical methodology improvements to solidify RJF’s claims and extend its applicability.
Practical Applications
Immediate Applications
The following applications can be deployed now using the proposed Riemannian Flow Matching with Jacobi Regularization (RJF), the open-source implementation, and widely available representation encoders (e.g., DINOv2, SigLIP, MAE).
- Efficient high-fidelity image generation with standard DiT architectures (Software/Media/Gaming/Advertising)
- Description: Replace Euclidean Flow Matching with RJF in latent diffusion pipelines that operate on representation encoder features, achieving state-of-the-art FID without width scaling.
- Tools/Products/Workflows:
- RJF training plugin for DiT-B/L/XL models with geodesic integrator and tangent-space projection.
- “RJF-PyTorch” library wrappers that abstract SLERP interpolation, Jacobi weighting, and exponential map sampling.
- Integration with existing RAE decoders (e.g., DINOv2-B + RAE).
- Assumptions/Dependencies:
- Representation features lie on a hypersphere (due to LayerNorm) and are suitable for geodesic trajectories.
- Availability and quality of RAE decoders to map manifold latents back to pixels.
- Class-conditional pipelines can be used immediately; text conditioning may need adaptation.
- Training cost and energy reduction via geometry-aware objectives (Energy/Policy/ML Ops)
- Description: Achieve convergence without width scaling by switching objectives (EFM → RJF), cutting compute, training time, and energy use while improving fidelity.
- Tools/Products/Workflows:
- “Geometry-aware training policy” for internal ML governance that mandates manifold-respecting objectives when using representation encoders.
- Compute savings estimator comparing RJF vs Euclidean FM training footprints.
- Assumptions/Dependencies:
- The convergence gains observed on ImageNet-256 generalize to target datasets/resolutions.
- Organizational willingness to update training recipes and compliance tracking.
- Edge-friendly generative apps using smaller models (Mobile/AR/VR)
- Description: Deploy DiT-B (~131M params) with RJF to deliver high-quality generation on consumer devices or efficient servers.
- Tools/Products/Workflows:
- On-device RJF-inference pipelines with geodesic integrators and 50-step sampling.
- SDKs for mobile developers to incorporate RJF-based generators into creative apps.
- Assumptions/Dependencies:
- RAE decoder footprint and latency are acceptable on target hardware.
- Proper tuning of projection radius at inference (e.g., R ≈ 45 improved FID in experiments).
- Representation-aware synthetic data generation for downstream vision tasks (Robotics/Autonomous Driving/Healthcare Imaging)
- Description: Use RJF generators to produce semantically faithful, class-conditional synthetic images that improve classifier/detector training.
- Tools/Products/Workflows:
- Data augmentation pipeline with RJF generators and classifier-free guidance for label-consistent synthesis.
- Evaluation kits measuring precision/recall and domain shift reduction.
- Assumptions/Dependencies:
- Availability of suitable conditioning (class labels or other metadata).
- Responsible use and validation in domains with safety or clinical constraints.
- Diagnostics for geometry interference in ML pipelines (Software/ML Ops/Academia)
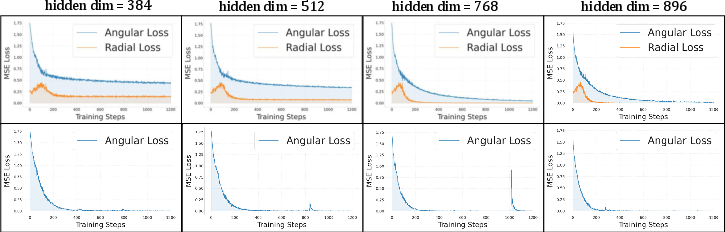
- Description: Introduce a “geometry audit” step that decomposes training losses into radial vs angular components to detect Euclidean–manifold mismatch.
- Tools/Products/Workflows:
- Plug-ins to log angular/radial loss, measure feature norms, and verify tangent-space consistency during training.
- Visualization utilities for SLERP paths vs Euclidean chords.
- Assumptions/Dependencies:
- Accurately characterizing representation geometry (hyperspherical norm concentration).
- Access to internal training signals and metrics.
- Reproducible research and teaching modules (Academia/Education)
- Description: Adopt RJF and the provided code as a baseline for manifold-aware generative modeling coursework and research labs.
- Tools/Products/Workflows:
- Jupyter notebooks demonstrating SLERP, tangent-space projections, Jacobi weighting, and geodesic sampling.
- Benchmark suites comparing RJF vs Euclidean FM on ImageNet-like tasks.
- Assumptions/Dependencies:
- Stable open-source code and datasets suitable for instruction.
- Institutional support for updating curricula.
Long-Term Applications
These applications require additional research, scaling, validation, or adaptation to other manifolds/modalities.
- Multimodal manifold-aware generative modeling (Software/Media/3D/Audio/Video)
- Description: Extend RJF beyond hyperspheres to other Riemannian manifolds (e.g., product manifolds, hyperbolic space) for audio, video, and 3D generative models where features exhibit non-Euclidean geometry.
- Tools/Products/Workflows:
- “Manifold-agnostic RJF” library with pluggable geodesic solvers, exponential maps, and Jacobi weights for diverse geometries.
- Assumptions/Dependencies:
- Accurate characterization of manifold geometry in each modality.
- Derivation and implementation of Jacobi fields under different curvature regimes.
- Text-to-image generators aligned with representation manifolds (Software/Media/Creative Tools)
- Description: Combine RJF with strong text–vision encoders (e.g., SigLIP/CLIP-like embeddings) for semantically faithful T2I generation that respects hyperspherical embedding geometry.
- Tools/Products/Workflows:
- RJF-conditioned T2I pipelines using text embeddings projected to the appropriate manifold.
- Fine-tuning strategies for joint text–image manifold alignment.
- Assumptions/Dependencies:
- Robust conditioning across text embeddings and decoders.
- Dataset diversity and safety filters to prevent misuse.
- Medical image synthesis with rigorous validation (Healthcare)
- Description: Use RJF to generate clinically relevant synthetic data (e.g., rare pathology augmentation) with improved semantic fidelity; validate for diagnostic model training.
- Tools/Products/Workflows:
- Clinical validation protocols, bias audits, and uncertainty quantification for synthetic data.
- Integration into federated/secure training environments.
- Assumptions/Dependencies:
- Regulatory compliance (e.g., FDA, IRB), domain expert oversight, and robust evaluation.
- Domain-specific decoders and encoders suited to medical imaging.
- Sim-to-real domain randomization for robotics (Robotics/Autonomous Systems)
- Description: Employ RJF generators to produce semantically consistent visual variations for training policies and perception modules, improving transfer from simulation to reality.
- Tools/Products/Workflows:
- RJF-based environment stylization engines integrated with robot simulators.
- Evaluation tools measuring transfer performance and robustness.
- Assumptions/Dependencies:
- Encoders that capture task-relevant semantics; controllers able to exploit improved perception.
- Coordination with control and reinforcement learning pipelines.
- Scenario generation for stress testing in finance and risk (Finance)
- Description: Translate RJF principles to embedding spaces used in financial modeling (e.g., representation learning for market states) to generate realistic stress scenarios.
- Tools/Products/Workflows:
- RJF generators operating on learned market state manifolds; downstream risk analytics dashboards.
- Assumptions/Dependencies:
- Verified manifold geometry of embeddings; careful governance to avoid spurious correlations.
- Domain-specific evaluation metrics beyond FID/IS.
- AutoML compilers that detect geometry and auto-configure training (Software/ML Platforms)
- Description: Build systems that inspect feature geometry (norm concentration, curvature proxies) and automatically select RJF-style objectives, interpolation, and sampling.
- Tools/Products/Workflows:
- “Geometry-aware AutoML” that emits training graphs with SLERP, tangent projections, and Jacobi regularization when appropriate.
- Assumptions/Dependencies:
- Reliable geometry detection; compatibility with heterogeneous frameworks and hardware.
- Safety and watermarking for manifold-aware generators (Policy/Security)
- Description: Develop watermarking and provenance tools tailored to RJF outputs and assess whether geometry-aware generation alters detectability or misuse profiles.
- Tools/Products/Workflows:
- Watermarking schemes that operate in representation space; auditing pipelines for content provenance.
- Assumptions/Dependencies:
- Cooperation with platforms; evolving legal frameworks for generative content.
- Standards and procurement guidance for low-carbon AI training (Policy/Energy)
- Description: Encourage adoption of geometry-respecting objectives (like RJF) in public and private procurement to reduce compute and emissions.
- Tools/Products/Workflows:
- Policy templates specifying geometry-aware training as a preferred practice; reporting of energy savings and model performance.
- Assumptions/Dependencies:
- Clear measurement methodologies; stakeholder alignment on cost–benefit tradeoffs.
- Generalization to dynamic, learned manifolds (Research/Academia)
- Description: Learn manifold geometry jointly with the generator/encoder, adapting RJF to evolving curvature and topology inferred from data.
- Tools/Products/Workflows:
- Joint learning frameworks that estimate metrics and geodesics online; adaptive Jacobi weighting.
- Assumptions/Dependencies:
- Stable optimization under coupled geometry–generator training; robust convergence diagnostics.
Glossary
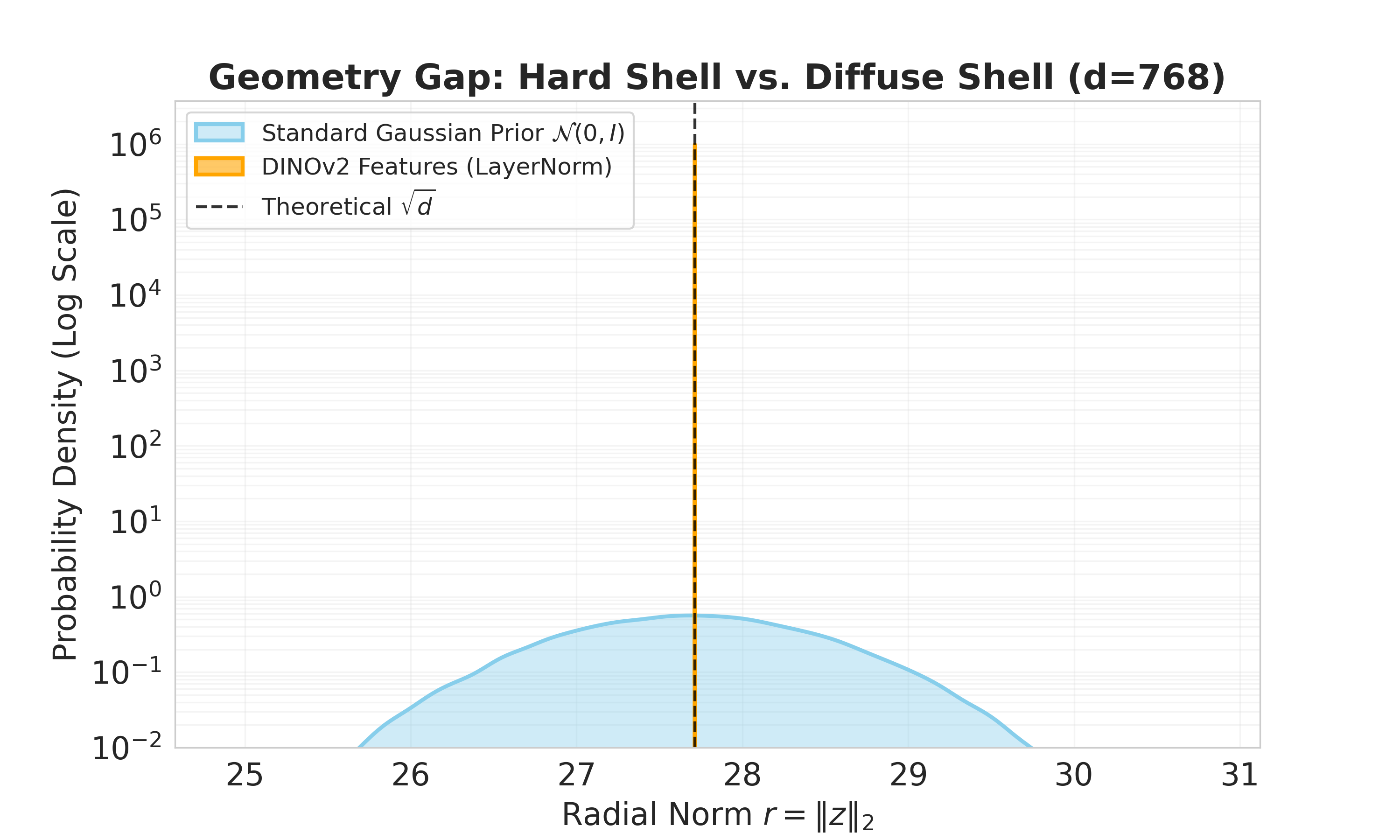
- Ambient Euclidean space: The surrounding flat space in which vectors reside; here, the paper notes that encoder features do not occupy it uniformly. "We observe that DINOv2 representations do not populate the ambient Euclidean space but are strictly confined to a hypersphere"
- Classifier-free guidance: A sampling technique that improves conditional generation by adjusting the influence of conditioning signals without a separate classifier. "With classifier-free guidance, the performance reaches SOTA with an FID of 3.37"
- Conditional Flow Matching (CFM): A training procedure that fits a time-dependent vector field to transform a prior to data via sample-specific paths. "Conditional Flow Matching (CFM) trains the model to approximate the conditional vector field generating a specific probability path between a data sample $x \sim p_{\text{data}$ and noise ."
- Continuous Normalizing Flows (CNFs): Generative models defined by continuous-time transformations governed by differential equations. "Flow Matching (FM) \cite{lipman2022flow} is a simulation-free framework for training Continuous Normalizing Flows (CNFs)."
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion/flow models operating in latent or pixel space. "RJF enables standard Diffusion Transformer architectures to converge without width scaling."
- DINOv2: A self-supervised visual representation encoder whose features exhibit hyperspherical geometry. "We observe that DINOv2 representations do not populate the ambient Euclidean space but are strictly confined to a hypersphere"
- Euclidean Flow Matching: A flow matching variant using straight-line (linear) paths in flat space, which can misalign with manifold geometry. "Standard Euclidean Flow Matching constructs linear paths that ignore the manifold geometry."
- Exponential Map: A Riemannian operation that moves along geodesics using a tangent vector, ensuring updates stay on the manifold. "To preserve the constant-speed advantage during sampling, we use Geodesic (Exponential Map) Integration."
- Exponential Moving Average (EMA): A smoothing technique that maintains a weighted average of parameters over training steps. "We ... maintain an Exponential Moving Average (EMA) of weights with a decay of $0.9995$."
- FID (Fréchet Inception Distance): A metric assessing generative image quality by comparing distributions of deep features. "achieving an FID of 3.37 where prior methods fail to converge."
- Flow Matching (FM): A training framework that learns a velocity field to transport a simple prior to the data distribution along a prescribed path. "Flow Matching (FM) \cite{lipman2022flow} is a simulation-free framework for training Continuous Normalizing Flows (CNFs)."
- Geodesic: The shortest path constrained to a manifold, replacing straight lines in curved spaces like spheres. "This ensures the generative process follows the geodesic(shortest path along the curve between two points), staying strictly on the manifold surface."
- Geodesic distance: The angular distance along a manifold (e.g., a sphere) between two points. "where is the geodesic distance (angle) between the data and the noise."
- Geodesic focusing: The phenomenon where geodesics converge due to positive curvature, amplifying certain errors over time. "On a positively curved hypersphere, velocity errors propagate non-linearly due to the focusing of geodesics (similar to how parallel longitude lines eventually meet at the poles)."
- Geometric Interference: A mismatch where Euclidean training objectives force off-manifold trajectories, hindering convergence. "We identify Geometric Interference as the root cause: standard Euclidean flow matching forces probability paths through the low-density interior of the hyperspherical feature space of representation encoders, rather than following the manifold surface."
- Hypersphere: A high-dimensional sphere (e.g., ) on which normalized representation features lie. "explicitly projected onto a hypersphere of fixed radius :"
- Hyperspherical manifold: A curved manifold with spherical geometry whose points have fixed norm, requiring geodesic paths. "violate the hyperspherical manifold of representation space."
- Jacobi equation: A differential equation describing how nearby geodesics diverge/converge, used to derive curvature-aware weights. "Solving the Jacobi equation for a hypersphere yields a geometric weighting factor that scales the loss based on the curvature-induced focusing of geodesics:"
- Jacobi Field: A vector field capturing the separation between geodesics under perturbations, informing error propagation. "we model this error propagation using Jacobi Fields, which quantify the separation between geodesics caused by velocity perturbations."
- Jacobi Regularization: A curvature-aware loss weighting based on Jacobi fields to correct manifold-induced error distortion. "we introduce a Jacobi Regularization derived from Jacobi fields \cite{zaghen2025towards}, which reweights the loss to account for curvature-induced distortion."
- Latent Diffusion Models (LDMs): Diffusion models operating in compressed latent spaces for efficiency and fidelity. "Latent Diffusion Models (LDMs) \cite{rombach2022high, vahdat2021score} that leverage compressed representations of VAE"
- LayerNorm: A normalization technique applied per sample that enforces near-constant feature norms, inducing a spherical shell. "the radial component exhibits near-zero variance due to the ubiquitous application of LayerNorm."
- Logit-Normal: A distribution over [0,1] used to sample time parameters via a logit transform for improved training schedule. "Sample $t_{\text{raw} \sim \text{LogitNormal}(\mu, \sigma)$ on "
- Optimal Transport displacement: The linear interpolation path in Euclidean space that transports mass between distributions. "In the standard Euclidean setting, the simplest probability path is constructed via linear interpolation (Optimal Transport displacement):"
- Representation Autoencoders (RAE): Models that diffuse directly in the feature space of frozen encoders using an autoencoder decoder instead of VAEs. "Representation Autoencoders (RAE) \cite{zheng2025diffusion}, which discard the VAE entirely in favor of diffusing directly within the feature space of frozen representation encoders."
- Riemannian Flow Matching (RFM): Flow matching conducted on a curved manifold, using geodesic paths and tangent-space velocities. "By adopting Riemannian Flow Matching \cite{chen2023flow}, we define the diffusion process directly on the manifold ."
- Riemannian metric: The inner product structure on a manifold defining lengths/angles; here, the sphere’s induced metric. "which is equivalent to the Riemannian metric induced on the sphere:"
- SLERP (Spherical Linear Interpolation): An interpolation method along great-circle arcs on a sphere, preserving constant speed and norm. "The conditional probability path is defined via Spherical Linear Interpolation (SLERP) rather than linear interpolation."
- Tangent space: The linear space of directions at a manifold point where valid velocities must lie. "the velocity vector must essentially lie in the tangent space at every point ."
- Velocity field: A time-dependent vector field that dictates how points move along the probability path during flow/diffusion. "This forces the model to learn a velocity field in undefined regions regardless of the endpoint."
Collections
Sign up for free to add this paper to one or more collections.