Self-Evolving Recommendation System: End-To-End Autonomous Model Optimization With LLM Agents
Abstract: Optimizing large-scale machine learning systems, such as recommendation models for global video platforms, requires navigating a massive hyperparameter search space and, more critically, designing sophisticated optimizers, architectures, and reward functions to capture nuanced user behaviors. Achieving substantial improvements in these areas is a non-trivial task, traditionally relying on extensive manual iterations to test new hypotheses. We propose a self-evolving system that leverages LLMs, specifically those from Google's Gemini family, to autonomously generate, train, and deploy high-performing, complex model changes within an end-to-end automated workflow. The self-evolving system is comprised of an Offline Agent (Inner Loop) that performs high-throughput hypothesis generation using proxy metrics, and an Online Agent (Outer Loop) that validates candidates against delayed north star business metrics in live production. Our agents act as specialized Machine Learning Engineers (MLEs): they exhibit deep reasoning capabilities, discovering novel improvements in optimization algorithms and model architecture, and formulating innovative reward functions that target long-term user engagement. The effectiveness of this approach is demonstrated through several successful production launches at YouTube, confirming that autonomous, LLM-driven evolution can surpass traditional engineering workflows in both development velocity and model performance.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching an AI system to improve YouTube’s video recommendation models on its own. Instead of humans doing lots of trial-and-error to make the “what to watch next” suggestions better, the system uses powerful LLMs to think up ideas, write code, run tests, and decide what works. The goal is to make recommendations that keep users satisfied in the long run, not just to get quick clicks.
Key Objectives
The paper focuses on three simple questions:
- How can we automatically try smarter ideas for recommendation models, not just tweak small settings?
- How can we design better “rewards” for training the model—ways to measure success that match real user happiness?
- How can we run more experiments faster and safely, so good ideas reach users sooner?
Methods and Approach
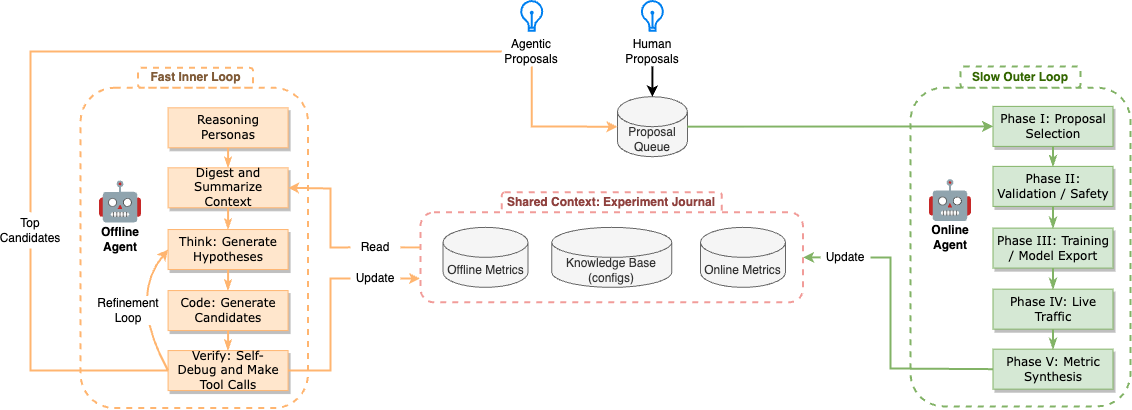
Think of this system like a sports team with two kinds of games: quick practice matches and important official games. The AI agents use the practice matches to test many ideas cheaply, then only bring the best ones to official games with real fans watching.
Two-Agent System
- Offline Agent (the “practice coach”): Runs fast, low-cost tests to try many ideas. It looks at past results, writes code changes, and checks if they help in quick simulations or data analyses.
- Online Agent (the “game-day manager”): Runs careful, safe A/B tests with real users to see if the ideas actually improve important business goals (like watch time and satisfaction).
What Each Agent Does
To keep the system smart and organized, the AI acts like different specialists:
- Optimizer specialist: Tweaks how the model learns (like adjusting learning speed or picking a different training algorithm). It uses a simple score called “loss” to judge improvement during practice.
- Architecture specialist: Redesigns parts of the neural network (like adding new layers or gates) to help the model learn better patterns.
- Reward specialist: Redefines what “good” means during training by analyzing huge logs of user behavior. It looks for signals that match real satisfaction, not just clicks.
How Ideas Turn Into Code and Tests
The AI follows a loop:
- Think: Propose a clear idea (for example, “Reduce clickbait by penalizing short, low-quality clicks.”).
- Code: Write the exact code or configuration change needed.
- Check: Use tools to test the change—either a quick training score for Optimizer/Architecture or big data analysis for Reward ideas.
- Filter and promote: Only the promising ideas move on to live A/B tests with real users.
There’s also an “Experiment Journal” that remembers what was tried before and how it went, so the AI learns from past wins and mistakes.
Main Findings and Why They Matter
Here are the most important results, explained simply:
- Smarter training algorithm: Switching to a training method called RMSprop lowered the practice “loss” score and improved real user metrics. Even tiny percentage gains are huge at YouTube’s scale.
- Faster training: By tuning settings like batch size and training time, the system sped up training by up to 8× without hurting quality. Faster training means more ideas can be tested.
- Better network design: Adding a “gated path” (similar to a GLU) helped the model filter out noise and focus on useful signals, leading to stronger results. Refining activations (like using GELU and layer normalization) improved it further.
- Smarter reward signals: The AI combined several signals—active engagement, how much a user likes a channel, and video quality—into a new reward that better matched long-term satisfaction. This beat the human-designed setup.
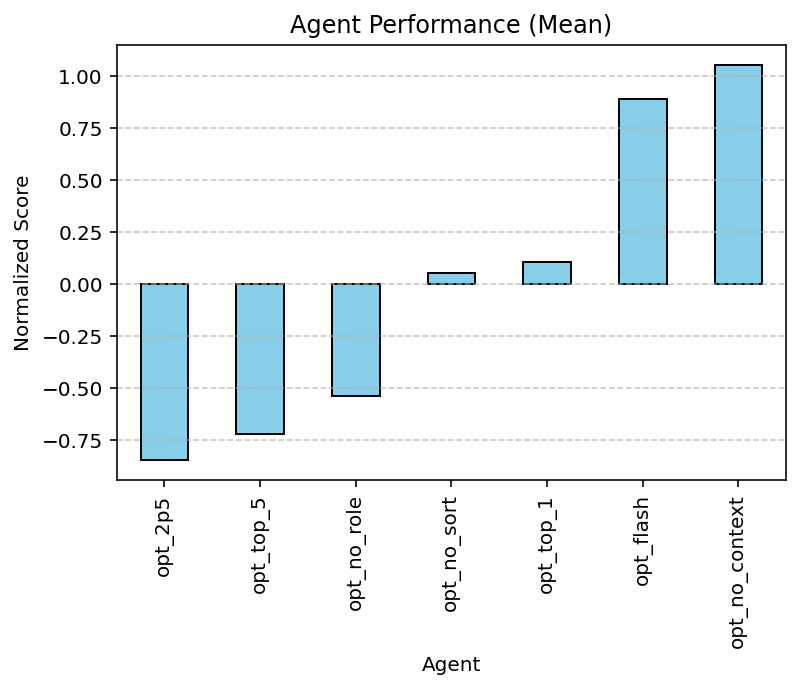
- Why bigger brains help: More powerful LLMs (with better reasoning) consistently found better improvements. Also, giving the AI the right role (“be an expert ML engineer”) and sorted past results made it perform better.
- More experiments, less human effort: The agent-led workflow ran about 10× to 100× more experiments per week than manual engineering, with zero extra human hours per experiment. That speed finds wins humans might never get to.
Implications and Impact
This research shows that AI can act like a skilled machine learning engineer: it can read code, reason about users, write fixes, and safely ship improvements—end-to-end. For users, that means better recommendations that focus on long-term enjoyment, not just quick clicks. For engineers, it shifts the job from doing repetitive setup to setting smart goals, safety rules, and ethics. And because the system learns from history and adapts to new contexts, it could be applied to many other recommendation problems beyond YouTube.
In short, this self-evolving system helps move from “tuning numbers” to “discovering ideas,” making recommender systems both faster to improve and more aligned with what people actually value.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper. Each point is framed to enable actionable follow‑up by future researchers.
- External validity and reproducibility: The system and metrics are proprietary to YouTube; no public datasets, code, or synthetic benchmark tasks are provided to allow independent replication or benchmarking outside Google’s infrastructure.
- Generalization beyond YouTube: Claims of transfer to another “surface” lack detailed evidence (schema differences, magnitude of gains, number of iterations to adapt). It remains unclear how well the approach transfers to non-video domains (e-commerce, news, music) or smaller-scale platforms.
- Causal attribution of gains: Improvements are reported without baselines that control for exploration budget and compute. It is unknown how much lift comes from LLM reasoning vs. simply running more candidates (e.g., random search, Bayesian optimization, or NAS with equal budget).
- Head-to-head baselines: No direct comparisons are reported against strong AutoML/NAS/HPO baselines (e.g., Vizier BO, DARTS, modern evolutionary NAS) under matched compute and experimentation budgets.
- Offline–online alignment: The paper assumes
compute_lossfor optimizer/architecture is a useful proxy, but provides no quantitative study of offline loss correlation with online north‑star metrics, especially under architectural changes. - Reward correlation validity: The Reward persona uses
run_sql_queryto select signals by correlation. There is no evaluation of spurious correlations, confounding, or causal validity; off-policy estimators (IPS/DR), causal discovery, or randomized labeling checks are not applied. - Statistical rigor in online experiments: The paper does not detail sample size calculations, power, sequential monitoring, multiple-testing or false discovery rate control, A/A tests, or long-term holdouts—critical given high experiment throughput.
- Delayed effects and long-term impact: North-star metrics are delayed and noisy, but the duration of A/B tests and the stability of effects over weeks/months are not reported. Long-term retention, creator ecosystem effects, and feedback loops remain unmeasured.
- Slice-level outcomes and fairness: The framework claims to identify under-served slices, but reports no slice-wise results, fairness metrics, demographic impact analysis, or constraints enforcing equitable performance across user groups.
- Reward composition and stability: The composite reward with three new components lacks details on weighting, normalization, calibration, and stability over time. There is no sensitivity analysis or ablation of individual components.
- Safety guardrails and drift: Safety thresholds are mentioned abstractly (“Metric#3 ≤ +1%”) without specifying how they are chosen, tuned, or adapt to non-stationarity; no methodology is given for detecting reward hacking, metric gaming, or model drift.
- Risk of LLM-induced bias: LLM-generated reward logic and architectural changes may encode pretraining biases. There is no bias audit or red‑teaming process described for agent proposals.
- Security and supply-chain risk: The system executes LLM-generated code against production pipelines. There is no formal description of sandboxing, static/dynamic analysis, dependency control, or protections against backdoors and prompt injection.
- Human oversight and governance: The role and authority of human reviewers (when to require approval, how to override, audit trails) are not specified. No process is given for interpreting and approving high-risk changes (e.g., reward redesigns).
- Technical debt and maintainability: There is no discussion of how to manage the accumulation of LLM-generated diffs, ensure readability, guard against architectural fragmentation, or enforce coding standards over time.
- Context management and “knowledge rot”: While “context rot” is cited, the paper does not detail mechanisms for curating the Experiment Journal (deduplication, conflict resolution, relevance filtering, indexing), nor how stale or contradictory evidence is handled.
- Compute and cost accounting: The resource footprint of the Inner Loop’s hundreds of trainings and massive log queries is not quantified. A cost-benefit or energy/carbon analysis is missing, as is capacity planning under heavy experimentation.
- Scheduling and resource contention: There is no description of how the system schedules jobs across shared infrastructure, prevents interference with other production workloads, or prioritizes experiments under finite compute.
- Tool reliability and evaluation hygiene: For
run_sql_query, the paper lacks details about data leakage prevention, prequential evaluation, train-test splits, query correctness verification, and reproducible query plans at petabyte scale. - Cold-start mitigation: The system struggles with an empty Experiment Journal; there is no proposed bootstrapping curriculum (e.g., curated seed knowledge, simulated tasks, open-source corpora) to mitigate early-stage low-quality proposals.
- Non-stationarity and robustness: The framework lacks mechanisms for change detection, robust optimization under shifting distributions, or rapid rollback and auto-recovery from regressions due to content/user dynamics.
- Candidate selection policy: The Online Agent’s FIFO queue is simplistic. There is no formal treatment of exploration policies (e.g., bandits), prioritization by expected value of information, or dynamic allocation of traffic based on interim results.
- Parameterization of the bi-level problem: The bi-level formulation is given, but there are no algorithms or theoretical results (e.g., regret bounds, convergence guarantees) for optimizing Φ under delayed noisy feedback.
- Interpretability for stakeholders: LLM-generated changes, especially to rewards, may be difficult for product/legal teams to interpret. No interpretability tooling or documentation standards are provided.
- Failure analysis: The paper reports wins but provides limited post-mortems of failed or harmful launches, limiting understanding of failure modes and how the system learns from them.
- Dependency on a single LLM family: Ablations cover Gemini 2.5 Pro vs. Flash for one task (optimizer), but the robustness to other models (e.g., GPT, Llama, Mistral), cost-performance tradeoffs, and failure behaviors across models remain unknown.
- Prompt and persona sensitivity: Persona framing and context sorting matter for the optimizer task; similar ablations are missing for architecture and reward tasks, leaving open how brittle those discoveries are to prompt tweaks.
- Latency and integration constraints: There is no discussion of inference-time costs (e.g., new architectures increasing serving latency, memory), or constraints across multi-stage recommender pipelines (candidate generation, ranking, re-ranking).
- Ethical boundaries and content policy: While “business intent” is mentioned, the paper does not specify how ethical constraints (e.g., avoiding harmful content amplification, ensuring diversity/exploration) are encoded, enforced, and audited in reward design.
- Creator/user strategic responses: The possibility that creators adapt to new reward signals (metric gaming) is unaddressed; no monitoring plan exists for strategic manipulation after reward launches.
- Counterfactual evaluation: The approach lacks an offline counterfactual evaluation layer (IPS/DR/CAE) to pre-screen reward/architecture changes before live A/B, which could reduce online risk and compute.
- Robustness to hallucinations: The linter persona is said to catch syntax errors, but there is no quantitative report on hallucination rates, semantic bugs detected, or their downstream impact.
- Granularity of safety thresholds: Safety guardrails are described at aggregate metric level; there is no discussion of per-slice, per-country, or per-device guardrails and localized abort criteria.
- Governance of multi-objective trade-offs: How the system encodes and navigates trade-offs among competing business metrics (e.g., watch time vs. satisfaction vs. content diversity) is not formalized; no Pareto analysis or constrained optimization is presented.
- Attribution and credit assignment: With multiple concurrent changes (optimizer, architecture, reward), there is no framework for attributing gains to specific components or interactions, limiting learning efficiency.
- Lifecycle management and rollback: Details on canarying, stepwise ramp-up, automatic rollback thresholds, and post-launch monitoring windows for regressions are minimal.
- Knowledge transfer and few-shot adaptation: Beyond anecdotal transfer, there is no systematic study on few-shot adaptation strategies (e.g., meta-learning) for new surfaces/schemas with minimal data/context.
- Quantifying novelty of discoveries: The “Gated Path” and activation refinements are described qualitatively; there is no metric or taxonomy for novelty and reuse across surfaces to prevent rediscovery of well-known ideas.
- Impact on developer workflow: While claiming zero hours per experiment, the paper does not quantify overhead for maintaining agents, prompts, tools, and monitoring, nor the human time needed for reviewing high-risk changes.
- Legal and privacy constraints: The paper does not address data governance, privacy compliance, or consent when LLM agents access code, logs, or potentially sensitive data.
- Robust tuning of exploration vs. exploitation: The agent is steered by prompt to “balance exploration and exploitation,” but there is no principled mechanism (e.g., UCB/Thompson sampling over ideas) or evaluation of the exploration policy’s efficiency.
- Multi-agent coordination: The two-agent architecture is fixed; open questions remain on adding specialized agents (e.g., fairness, safety, causal inference), conflict resolution among agents, and meta-optimization of agent roles.
Glossary
- A/B testing: Controlled online experiments comparing variants on live traffic to measure causal impact. "orchestrates live A/B tests on a slice of YouTube production traffic"
- Adagrad: An adaptive learning-rate optimizer that scales updates based on historical gradients. "switching from the legacy Adagrad optimizer to RMSprop"
- ablation study: A controlled analysis that removes or varies components to isolate their effect on performance. "we conducted a series of ablation studies focusing on model selection, persona framing, and context management"
- Automated Machine Learning (AutoML): Systems that automate model and hyperparameter selection and training workflows. "Automated Machine Learning (AutoML) \cite{automlsurvey_paper}"
- Bayesian optimization: A sample-efficient strategy for tuning parameters by modeling the objective with a surrogate (e.g., GP) and acquisition. "via Bayesian optimization \cite{bayesian_paper}"
- bi-level optimization: An optimization setup with an inner problem (e.g., training) nested inside an outer problem (e.g., metric selection). "We formulate this task as a bi-level optimization problem."
- Chain-of-Thought: An LLM prompting technique that elicits step-by-step reasoning traces. "Chain-of-Thought \cite{cot_paper}"
- Cold Start Problem: The difficulty of effective operation when there is little or no historical data to guide decisions. "The Cold Start Problem"
- context engineering: The practice of curating, structuring, and ordering past information to improve LLM reasoning quality. "context engineering plays a vital role"
- DCN: Deep & Cross Network, an architecture for explicit and implicit feature interaction modeling. "interaction layers (e.g., DCN \cite{dcn_paper}, Transformers \cite{selfattention_paper})"
- DARTS: Differentiable Architecture Search, a NAS method that relaxes discrete architecture choices to be learned continuously. "standard NAS approaches (e.g., DARTS \cite{dart_paper}, evolutionary search \cite{evolutionarc_paper})"
- Directed Acyclic Graph (DAG): A graph with directed edges and no cycles, often used to orchestrate multi-stage workflows. "a five-phase Directed Acyclic Graph (DAG)"
- Experiment Journal: A persistent, structured record of past trials, code diffs, and outcomes used to inform future proposals. "Experiment Journal"
- Gated Linear Units (GLU): A neural layer that modulates activation through a learned gate, enhancing selective information flow. "Gated Linear Units (GLU) \cite{glu_paper}"
- Gating Path: A learned multiplicative gating mechanism introduced into the architecture to suppress noise contextually. "Gating Path architecture"
- Gaussian processes: A nonparametric Bayesian model used as a surrogate in HPO for uncertainty-aware optimization. "Gaussian processes \cite{gaussian_paper}"
- GELU: Gaussian Error Linear Unit, an activation function that blends linear and nonlinear behavior via Gaussian cdf. "moving from standard sigmoid gates to GELU activations combined with layer normalization"
- Hyperparameter Optimization (HPO): Automated search methods for selecting non-learned parameters (e.g., learning rate, batch size). "Hyperparameter Optimization (HPO) \cite{hpo_paper}"
- Layer normalization: A normalization technique applied across features within a layer to stabilize and accelerate training. "moving from standard sigmoid gates to GELU activations combined with layer normalization"
- Mixture-of-Experts (MoE): An architecture where multiple expert submodels are selectively routed to process inputs. "ranging from attention mechanisms to Mixture-of-Experts (MoE)"
- Neural Architecture Search (NAS): Automated methods to discover neural network topologies within a defined search space. "Neural Architecture Search (NAS) \cite{nas_paper}"
- north star business metrics: Primary, high-level KPIs that reflect long-term product goals and user value. "north star business metrics "
- Optimization by PROmpting (OPRO): An approach where LLMs iteratively refine solutions using natural-language prompts as evolutionary operators. "Optimization by PROmpting (OPRO) \cite{opro_paper}"
- persona framing: Prompting strategy that assigns a specific role/identity to the LLM to steer reasoning and outputs. "Persona Framing"
- proxy metrics: Cheaper, offline indicators used to approximate delayed or costly-to-measure objectives. "proxy metrics"
- ReAct: A prompting framework that interleaves reasoning and acting (tool use) to solve complex tasks. "ReAct (Reasoning + Acting) \cite{react_paper}"
- reward engineering: The design and refinement of reward functions to align learning with desired outcomes in RL. "The Semantic Gap in Reward Engineering"
- RMSprop: An optimizer that adapts learning rates using an exponentially decaying average of squared gradients. "Transition to RMSprop"
- state-action value function (Q-function): In RL, estimates expected cumulative reward for taking an action in a state under a policy. "state-action value function "
- Stochastic Gradient Descent (SGD): An iterative optimization method using noisy gradient estimates from minibatches. "Stochastic Gradient Descent (SGD)"
- Swish: A smooth, non-monotonic activation function defined as x·sigmoid(x). "Swish \cite{swish_paper}"
- Toolformer: A framework where LLMs learn to call external tools during inference to improve task performance. "Toolformer \cite{toolformer_paper}"
- Transformers: Sequence models using self-attention mechanisms to capture dependencies without recurrence. "Transformers \cite{selfattention_paper}"
- value-based reinforcement learning (RL): RL methods that learn value functions (e.g., Q-values) rather than policies directly. "a value-based RL approach"
Practical Applications
Immediate Applications
The following applications can be deployed now with moderate integration effort, leveraging the paper’s dual-loop agentic workflow, specialized personas, and safety guardrails.
- Autonomous RecSys optimization for media platforms (Sector: software, media/entertainment)
- Use case: Deploy the dual-loop system to continuously evolve ranking models (optimizer switches, architecture edits like GLU-style gated paths, and composite reward logic penalizing clickbait and boosting quality/affinity).
- Tools/workflows: Offline Think-Code-Verify with optimizer/architecture/reward personas; compute_loss and run_sql_query tools; Experiment Journal; Online DAG for A/B with safety thresholds and auto-abort.
- Assumptions/dependencies: Access to a high-reasoning LLM (e.g., Gemini 2.5 Pro or equivalent), production-grade A/B testing infra, large-scale logs for reward correlation, stringent guardrails for integrity metrics, compute budgets for parallel training.
- E-commerce ranking and personalization (Sector: retail, software, ads)
- Use case: Evolve product ranking with multi-objective reward (conversion, return/defect rate, long-term retention), architecture refinements for item-query gating, and optimizer tuning to speed retrains for seasonal shifts.
- Tools/workflows: Reward persona to synthesize composite signals (e.g., add-to-cart dwell, repeat purchase), Experiment Journal to learn from fraud/regret regressions, Online Agent to enforce revenue and trust-safety SLOs.
- Assumptions/dependencies: Reliable offline proxies for long-term value, feature store integration, privacy-compliant access to user-event logs, policy-enforced thresholds for fairness and churn.
- Advertising ranking and budget optimization (Sector: ads/marketing tech)
- Use case: Redefine reward toward advertiser and user value (ROAS, long-term engagement) rather than short-term clicks; autonomously test auction-side optimizer settings and training batch/epoch schedules to cut costs.
- Tools/workflows: Reward persona for multi-objective synthesis (e.g., CPA + user quality), Online Agent to throttle or abort when attention-quality metrics drift; Experiment Journal for audit of model diffs and metric impacts.
- Assumptions/dependencies: Contracted business metrics (e.g., attribution window definitions), clear safety rails for user experience and advertiser fairness, scalable logging, and A/B systems supporting delayed conversion metrics.
- Social/news feed quality and integrity (Sector: social media, news)
- Use case: Penalize low-quality/clickbait via reward terms (active engagement, quality signals, source affinity), and adopt gated-path architecture to suppress noisy features under specific contexts.
- Tools/workflows: Reward persona with run_sql_query to validate correlations with long dwell/retention; safety thresholds for misinformation/harassment integrity metrics in Online DAG.
- Assumptions/dependencies: Integrity metrics and labels, trust-safety policies, transparent abort criteria, compliance with local content regulations.
- MLOps “Agent Orchestrator” productization (Sector: software tooling, platforms)
- Use case: Package the dual-loop system as an internal tool: personas, code-diff linter, job launcher, Experiment Journal, and A/B DAG with safety SLOs. Integrate with Vertex AI/SageMaker/Databricks.
- Tools/workflows: Persona templates (optimizer/architecture/reward), delta-based code diff generation, context-ranked history, FIFO proposal queue with manual overrides.
- Assumptions/dependencies: Organizational buy-in for autonomous changes under guardrails, CI/CD hooks for model code, connectors to data warehouse and experiment servers.
- Training efficiency optimization-as-a-service (Sector: software, infra)
- Use case: Use the optimizer persona to iteratively find batch/epoch/hyperparameter schedules that 2–4× speed training without hurting loss or online metrics; recycle savings to increase exploration bandwidth.
- Tools/workflows: compute_loss-based sorting, Experiment Journal to link efficiency edits to online results, auto-promotion logic for efficiency wins that pass thresholds.
- Assumptions/dependencies: Cost-aware scheduling (quota/priority), accurate loss comparability across optimizer variants, robust monitoring of convergence and overfitting.
- Academic benchmarks and teaching labs (Sector: academia, education)
- Use case: Create a lab/benchmark for “agentic discovery in RecSys” focusing on inner/outer loops, persona ablations, and context sorting; replicate optimizer/architecture/reward findings on public datasets.
- Tools/workflows: Release of Experiment Journal schema, persona prompts, and a safe-to-run A/B simulator; course modules on Think-Code-Verify and bi-level optimization.
- Assumptions/dependencies: Curated datasets with offline/online proxy pairs, IRB guidance for any human-in-the-loop studies, access to mid/large LLMs.
- Enterprise governance patterns for autonomous experimentation (Sector: policy within organizations, risk/compliance)
- Use case: Adopt guardrail templates (forbidden regressions, kill-switches, safe abort logic), Experiment Journal for auditability (diffs + metrics), and human-in-the-loop steering instructions.
- Tools/workflows: Policy bundles for thresholding sensitive metrics, queue prioritization rules, cold-start procedures to reduce risk when the journal is sparse.
- Assumptions/dependencies: Clear RACI for overrides and incident response, model registry/versioning, privacy-by-design logging.
Long-Term Applications
These require additional research, scaling, domain validation, or regulatory frameworks before broad deployment.
- Cross-domain self-evolving RL for healthcare decision support (Sector: healthcare)
- Use case: Reward persona designs composite rewards (short-term physiological responses, adherence, long-term outcomes); offline proxies from EHRs; outer loop validates on prospective or registry data with strict oversight.
- Tools/workflows: Safety-first Online DAG with physician review gates; fairness and harm-minimization personas; simulation-to-real validation.
- Assumptions/dependencies: Regulatory approvals, high-quality causal proxies, stringent explainability/auditability, IRB governance, human-in-the-loop mandates.
- Adaptive learning platforms with mastery-aware rewards (Sector: education/edtech)
- Use case: Evolve content sequencing policies via rewards combining mastery progression, engagement, and retention; architecture edits for student-context gating.
- Tools/workflows: Reward Studio to test mastery/engagement correlations; Online Agent for staged rollouts in classrooms.
- Assumptions/dependencies: Ethical oversight, bias/fairness constraints across student groups, parental consent and privacy compliance.
- Autonomous optimization for financial systems (Sector: finance/fintech)
- Use case: Multi-objective reward design for risk-adjusted returns, client suitability, and long-term retention; optimizer/architecture edits to capture regime shifts.
- Tools/workflows: Stress-testing sandbox as an outer loop proxy; Experiment Journal for compliance audit; guardrails to cap drawdowns and exposure.
- Assumptions/dependencies: Regulatory compliance (e.g., suitability rules), robust backtest/forward-test separation, explainability, strict kill-switches.
- Grid and building energy control (Sector: energy, sustainability)
- Use case: Self-evolving controllers optimizing cost, carbon, comfort, and stability; reward persona blends real-time prices, emissions intensity, and comfort violations.
- Tools/workflows: Digital twins as offline proxies; Online DAG for staged deployment on limited circuits; safety SLOs for stability margins.
- Assumptions/dependencies: High-fidelity simulations, fail-safe fallbacks, cyber-physical safety certification.
- Robotics control with delayed objectives (Sector: robotics)
- Use case: Extend LLM-driven reward design to tasks where success is sparse/delayed (maintenance intervals, battery health); architecture personas propose control-topology edits.
- Tools/workflows: Sim-to-real pipelines, Experiment Journal spanning sim and real runs; safety cages/teleoperation abort.
- Assumptions/dependencies: Reliable sim proxies, domain randomization, certification for real-world trials.
- Platform-level “preference co-design” with users (Sector: software, HCI/policy)
- Use case: Let users opt into reward co-creation (e.g., emphasize diversity or novelty); agent proposes small A/B tests tailored to user-declared goals under privacy constraints.
- Tools/workflows: Consent management, differential privacy, user-facing controls mapping to reward terms, safe exploration caps.
- Assumptions/dependencies: UX acceptance, privacy guarantees, mechanisms to prevent echo chambers or harmful personalization.
- Standardized audit and regulatory frameworks for autonomous experimentation (Sector: public policy, standards)
- Use case: Codify Experiment Journal as an auditable artifact; mandate kill-switch and guardrail disclosures; third‑party auditing of agent-generated changes and online impacts.
- Tools/workflows: Standard schemas for diffs/metrics, conformance tests, red-team personas to probe reward hacking.
- Assumptions/dependencies: Multi-stakeholder standards bodies, legal clarity on automated changes and accountability.
- General-purpose “Self-Evolving ML” platforms (Sector: software platforms)
- Use case: Offer an extensible agent layer atop arbitrary ML stacks (RecSys, NLP ranking, time-series forecasting) with domain personas, tool adapters, and safety DAGs.
- Tools/workflows: Persona Packs (optimizer/architecture/reward/fairness/efficiency), Plugin SDK for compute_loss/run_sql_query analogs, cross-cloud deployment.
- Assumptions/dependencies: Mature tool APIs, data governance, cultural readiness for autonomous code edits.
- Fairness and robustness personas (Sector: research, compliance)
- Use case: Add personas that propose anti-bias constraints and adversarial robustness tests, co-optimized with reward; integrate fairness metrics into Online DAG gating.
- Tools/workflows: Counterfactual analysis queries, subgroup metric monitoring, fairness-aware promotion rules.
- Assumptions/dependencies: Representative datasets, agreed fairness definitions, continuous monitoring pipelines.
- Open-source ecosystem and reproducibility (Sector: academia, community)
- Use case: Community standards for Experiment Journal, diff formats, persona prompts; public leaderboards for agentic discovery under compute budgets.
- Tools/workflows: Lightweight outer-loop simulators, seed datasets, evaluation harnesses for persona/context ablations.
- Assumptions/dependencies: Sustainable funding, dataset licensing, responsible release practices to prevent misuse.
Notes on Feasibility and Adoption
- The largest practical gains rely on LLMs with strong reasoning and long-context (as shown by Gemini 2.5 Pro outperforming smaller models); organizations may start with constrained personas and expand as Experiment Journals accumulate.
- Cold-start risk is mitigated by seeding the Experiment Journal with curated baselines and early ablations; delta-based diffs materially reduce hallucinations and integration errors.
- Safety guardrails, kill-switches, and forbidden-regression thresholds are prerequisites for autonomy in production; rigorous audit trails (diffs + metrics) are essential for compliance and trust.
- Success depends on the alignment between offline proxies and delayed online metrics; the reward persona’s correlation analysis is critical but must be validated by careful online experimentation.
Collections
Sign up for free to add this paper to one or more collections.