Discovering Differences in Strategic Behavior Between Humans and LLMs
Abstract: As LLMs are increasingly deployed in social and strategic scenarios, it becomes critical to understand where and why their behavior diverges from that of humans. While behavioral game theory (BGT) provides a framework for analyzing behavior, existing models do not fully capture the idiosyncratic behavior of humans or black-box, non-human agents like LLMs. We employ AlphaEvolve, a cutting-edge program discovery tool, to directly discover interpretable models of human and LLM behavior from data, thereby enabling open-ended discovery of structural factors driving human and LLM behavior. Our analysis on iterated rock-paper-scissors reveals that frontier LLMs can be capable of deeper strategic behavior than humans. These results provide a foundation for understanding structural differences driving differences in human and LLM behavior in strategic interactions.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper compares how humans and LLMs think and act in a simple strategy game: rock-paper-scissors played many times in a row. The goal is to understand where LLMs behave differently from people, and why. To do that, the authors use a tool called AlphaEvolve that helps discover small, readable computer programs that explain and predict players’ choices. These programs make it easier to see what “mental strategies” humans and LLMs might be using.
Key Objectives
The study asks three main questions:
- Do LLMs play repeated rock-paper-scissors better than humans?
- Can we automatically find simple, understandable models that explain the behavior of both humans and LLMs?
- What specific strategy differences (like how they model their opponents) account for any performance gaps?
How They Did It
First, here’s the game setup in everyday terms:
- Players face different computer “bots” with patterns you can exploit if you notice them.
- Each match has 300 turns. You get 3 points for a win, 0 for a tie, and -1 for a loss.
- Some bots are “nonadaptive” (they follow fixed, predictable habits), while others are “adaptive” (they watch you and try to counter your next move).
They used two kinds of data:
- A real human dataset where 411 people played against 15 bots.
- New LLM datasets where several models—Gemini 2.5 Pro and Flash, GPT 5.1, and an open-source model called GPT OSS 120B—played the same way against the same bots.
Then they modeled behavior in two steps:
- Predicting choices: Build models that look at the recent move history and predict what the player will choose next.
- Discovering models with AlphaEvolve: AlphaEvolve asks an LLM to write small Python programs that explain behavior well. The tool scores each program on:
- How accurately it predicts choices (using cross-validation so it generalizes, not just memorizes).
- How simple it is to understand (using a software metric called “Halstead effort,” which roughly counts how complex the code is).
They compared AlphaEvolve’s programs to standard baselines:
- Nash equilibrium: The “perfectly rational” strategy for rock-paper-scissors—choose rock, paper, scissors equally at random. It’s unexploitable, but not how humans actually play.
- A behavioral game theory model (an enhanced version of “Experience-Weighted Attraction” that learns from context).
- A recurrent neural network (RNN): Very flexible and accurate, but hard to interpret (it’s a black box).
Finally, they focused on the “simplest-but-best” programs—models that are nearly as accurate as the best ones but much easier to understand.
What They Found
The results are easiest to grasp in two parts: performance and “how” the strategies work.
Performance
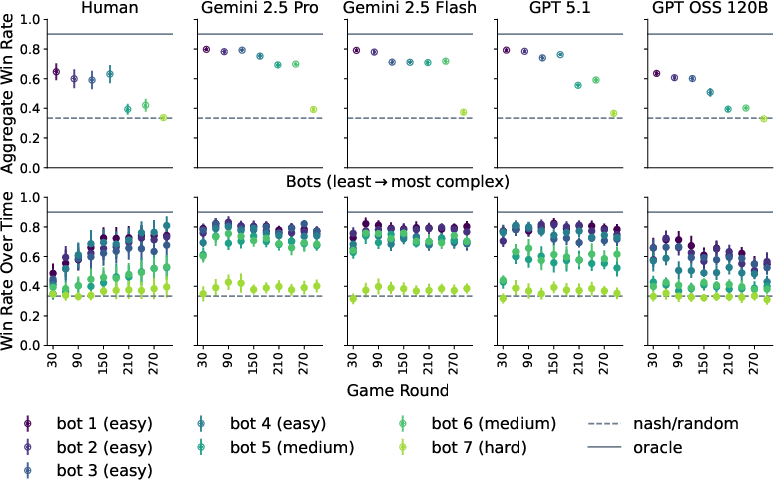
- Strong LLMs (Gemini 2.5 Pro/Flash and GPT 5.1) beat humans overall against many of the bots. They notice exploitable patterns faster and reach high win rates earlier in the game.
- Humans eventually learn patterns too, but more slowly, so their total points are lower.
- The weaker open-source model (GPT OSS 120B) does worse than humans and even gets worse over time—suggesting trouble using long histories effectively.
- AlphaEvolve’s discovered programs predict behavior better than the classic behavioral model and about as well or better than the black-box RNN, while still being interpretable.
Strategy differences inside the discovered programs
Across both humans and LLMs, the simplest-but-best programs share two core ideas:
- Value-based learning: Imagine a small “score table” (called a Q-table) that tracks how good each choice is in different situations. The program updates these values based on recent rewards, gently fading older memories.
- Opponent modeling: The program counts what the opponent tends to do and uses that to predict their next move.
Where they differ:
- Humans and the weaker LLM track opponent behavior in a simpler way (just overall frequencies like “how often do they play rock?”).
- Strong LLMs track more detailed patterns, like “what does the opponent tend to play given what they played last turn?” and even “given both players’ last moves.” In other words, their opponent models are higher-dimensional and more nuanced.
- This richer opponent modeling explains why strong LLMs exploit bots earlier and better than humans.
A common human-like quirk called “choice stickiness” (tending to repeat the last move) shows up in some models too.
Why It Matters
This work has a few big takeaways:
- LLMs aren’t perfect stand-ins for people. In games that require reading and exploiting patterns in others’ behavior, frontier LLMs can be more strategically sharp than average human players.
- If researchers or companies use LLMs to simulate human behavior (for surveys, markets, negotiations), they should be careful—LLMs may learn and react differently, especially in repeated interactions.
- AlphaEvolve offers a way to monitor and understand behavior in an interpretable way—without relying on the model’s “thought text,” which isn’t always trustworthy. It can help spot where LLMs diverge from human strategies.
- As LLMs get better, their “theory of mind” abilities (understanding what others will do) may be improving too, at least in simple settings like rock-paper-scissors.
Limitations and future directions
- The study looks at average human behavior; expert humans might use more complex opponent models.
- It focuses on one game. Testing other games (like negotiations or market scenarios) would show how general these differences are.
- The paper doesn’t try to make LLMs more human-like; future work could explore how to align strategies to human expectations when needed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper and that future work could address:
- External validity beyond IRPS: Do the findings (LLMs’ superior opponent modeling) hold in other repeated games (e.g., Matching Pennies, Prisoner’s Dilemma, Stag Hunt), general-sum/coordination settings, stochastic or partially observable games, and with different horizon lengths?
- Human–LLM interactions: How do results change when LLMs play humans (and vice versa) rather than bots? Are performance and learned models in human–LLM or LLM–LLM matches consistent with bot-based results?
- Memory and fairness: LLMs receive full round histories; humans have limited working memory. What happens if LLM inputs are restricted to the last k rounds, or if interfaces equalize memory across agents?
- Prompting and decoding sensitivity: How robust are LLM behaviors and inferred models to prompt wording, system instructions, chain-of-thought settings, temperature/top‑p, and other decoding parameters?
- Agentic scaffolds and tools: How do planning modules, external memory, reflection loops, or tool use affect LLM strategic behavior and the discovered mechanisms?
- Coverage of model families: Results rely on a small set of LLMs at one point in time. Do conclusions generalize across more families/sizes (including mid‑tier open-source models), versions, and scaling trends?
- Variability across runs: What is the run-to-run variance in LLM behavior and discovered programs under different random seeds and sampling settings?
- Opponent class breadth: Beyond the provided adaptive/nonadaptive bots, can LLMs counter‑exploit higher‑order adaptive opponents (e.g., ones requiring level‑k ToM or higher-order Markov dependencies)? What are their failure modes?
- Human heterogeneity: The study fits “average” human behavior. How do results change with hierarchical/mixture models that capture individual differences, subtypes (novices vs experts), or prior experience?
- Incentives and fatigue: Humans likely face motivation and fatigue over 300 rounds; LLMs do not. How do matched incentive schemes, shorter tasks, rest breaks, or simulated fatigue controls affect comparative performance?
- Mechanistic validation: Discovered program mechanisms are descriptive. Can targeted interventions (e.g., bots engineered to require specific dependency orders), ablation/lesion tests, or causal probes confirm that inferred components (e.g., conditional opponent models, counterfactual updates) drive behavior?
- Stability and multiplicity of solutions: Many programs lie on the Pareto frontier. How stable are discovered mechanisms across AlphaEvolve runs, training splits, and different ε thresholds for “simplest‑but‑best”? Quantify code‑level similarity across runs.
- Interpretability metric validity: Halstead effort is a proxy. Do human ratings (e.g., by cognitive scientists) or alternative complexity metrics (AST node count, cyclomatic complexity, description length) agree with “interpretable” selections?
- Synthesis LLM bias: AlphaEvolve uses Gemini 2.5 Flash to propose code. Do different synthesizer LLMs (or ensembles) discover different mechanisms, especially when modeling their own family’s behavior?
- Cross-generalization without re-fitting: The paper re-fits parameters on each target dataset. How much structure truly transfers zero‑shot (fixed parameters), or under limited fine‑tuning?
- Baseline breadth: Compare to additional structured baselines (e.g., Bayesian ToM models, recursive reasoning/level‑k with memory, HMMs, memory‑augmented RL). For CS‑EWA, test longer contexts (L>2) and alternative sophistication assumptions.
- Payoff and horizon sensitivity: Do conclusions persist under different payoff matrices (e.g., 1/0/−1), reward shapings, or shorter/longer horizons that alter learning signals and engagement?
- Knowledge leakage and OOD robustness: Could LLMs rely on priors about typical RPS bots? Evaluate with adversarial or randomized pattern bots, and unseen opponent families, to test out‑of‑distribution generalization.
- Evaluation metrics: Complement normalized likelihood with calibration (e.g., Brier scores), long-horizon predictive accuracy, change‑point detection, per‑bot phase analyses, and behavioral micro‑statistics.
- Explicit opponent-model probes: Elicit LLMs’ forecast distributions over opponent moves each round and assess calibration/consistency with their choices and discovered program structures.
- Classic IRPS biases in LLMs: Quantify primary salience (initial Rock), win‑stay/lose‑shift, choice stickiness, and compare their strength to human baselines across time.
- Data efficiency and compute: Report AlphaEvolve’s compute budget and search efficiency; characterize learning curves (data needed to uncover mechanisms) and compare to RNNs.
- Presentation modality confounds: Humans received a UI and feedback stream; LLMs saw textual prompts. Test whether presentation format and information layout affect behavior and discovered mechanisms.
- Causal claims about counterfactual updates: The Gemini SBB program appears to use counterfactual outcomes. Validate by hiding unchosen outcomes or altering feedback to see if the behavior degrades as predicted.
- History-length ablations: Systematically limit the history available to LLMs and to the learned programs to quantify dependence on higher‑order temporal structure and the minimum context needed for superior performance.
- Parameter uncertainty: Report confidence intervals or posterior distributions over program parameters and assess whether between‑agent differences remain under parameter uncertainty.
- Cross‑game transfer of mechanisms: Do program structures learned in IRPS transfer to other games without architecture changes, indicating general strategic reasoning rather than task‑specific heuristics?
Practical Applications
Immediate Applications
The following applications can be deployed with current tools, datasets, and organizational practices, drawing directly from the paper’s findings (LLMs exhibit deeper/faster opponent modeling than humans in IRPS) and methods (AlphaEvolve for interpretable behavioral model discovery with multi-objective simplicity–fit optimization).
- Strategic capability audits for deployed LLM agents
- Sectors: software, customer service, procurement/negotiation, finance, e‑commerce, gaming
- What: Integrate an AlphaEvolve-based pipeline to extract interpretable “behavioral programs” from interaction logs (e.g., chats, negotiations, games) to assess if agents are performing opponent modeling, how sophisticated it is, and how it evolves over session length.
- Tools/workflows: “BehaviorScope” audit job in CI/CD; IRPS-like micro-probes; Pareto-frontier reports with Halstead effort; cross-generalization matrices to compare model families.
- Assumptions/dependencies: Access to sufficient interaction logs; consent/PII safeguards; compute for bilevel optimization; acceptance that discovered programs are descriptive rather than causal.
- Risk assessments for “manipulative” or overly strategic behavior
- Sectors: healthcare (patient-facing chat), education (tutors), finance (client advisory), public sector (citizen services)
- What: Use discovered opponent-modeling structures to flag potential strategic exploitation risks (e.g., upsell or pressure tactics) and throttle or constrain agent behavior accordingly.
- Tools/workflows: Policy checkers that detect level-1+ opponent models; rules to down-weight conditioning on user history; alignment dashboards.
- Assumptions/dependencies: Clear policy definitions of “manipulation”; reliable detection metrics; willingness to trade performance for safety.
- Calibrating the use of LLMs as human proxies in research and market studies
- Sectors: academia, market research, policy analysis
- What: Before using LLMs as “digital twins,” run IRPS-style diagnostics and cross-generalization analyses to quantify divergence from human strategies; apply correction factors or avoid proxying in high-stakes studies.
- Tools/workflows: Pre-study proxy validation suite; similarity scores between SBB (simplest‑but‑best) programs for humans vs. each LLM.
- Assumptions/dependencies: Acknowledgment that IRPS is a diagnostic, not a full proxy for complex human behavior; prompt/control parity with human instructions.
- Model selection guidelines for long-interaction strategic tasks
- Sectors: procurement, customer retention, game AI, multi-agent simulations
- What: Prefer frontier LLMs (e.g., Gemini 2.5, GPT‑5.1) over smaller open-source models for long-context strategic tasks; avoid models showing degradation over time (as observed with GPT OSS 120B).
- Tools/workflows: Capability scorecards; time-to-exploitation metrics; regression gates for long-session performance.
- Assumptions/dependencies: Tasks genuinely require long-context strategy; cost/latency trade-offs are acceptable.
- Human training and coaching with adjustable LLM sparring partners
- Sectors: education, corporate training, esports/games, negotiation coaching
- What: Create training modules where LLM opponents’ opponent-modeling complexity can be dialed up/down (using SBB program structures) to scaffold human strategic skill development.
- Tools/workflows: IRPS-derived curricula; adjustable “level‑k” opponent modules; progress analytics.
- Assumptions/dependencies: Transfer from game to real-world strategies varies by domain; ethical use in training contexts.
- Difficulty scaling and fair play in online games
- Sectors: gaming, e-sports
- What: Use interpretable opponent-modeling components to auto-scale AI opponent difficulty to match human abilities and prevent “unfair” exploitation.
- Tools/workflows: Skill caps on model conditioning depth; telemetry-based adjustments.
- Assumptions/dependencies: Robust telemetry; player consent; fairness definitions.
- Continuous monitoring of model updates for strategic behavior changes
- Sectors: software (LLM product teams), regulated industries
- What: Treat opponent-modeling sophistication as a tracked capability; run regression tests post-update to detect emergent shifts (e.g., deeper conditional modeling).
- Tools/workflows: IRPS-style probes in model eval suites; change-point alarms; human-in-the-loop review.
- Assumptions/dependencies: Stable prompt scaffolds; standardized evals across versions.
- Guardrails to limit opponent modeling in consumer-facing bots
- Sectors: consumer apps, customer support, sales
- What: Enforce policies that prevent conditioning on fine-grained user histories for action selection in sensitive contexts.
- Tools/workflows: Runtime detectors that block/rewrite programmatic strategies leveraging 3×3×3 conditional opponent models; policy attestations.
- Assumptions/dependencies: Business acceptance of reduced conversion metrics; robust runtime enforcement.
- Benchmarking and clustering of LLM families by strategic behavior
- Sectors: AI procurement, MLOps, academia
- What: Use cross-generalization matrices to cluster models with similar strategic behavior and select models aligned to organizational risk tolerance.
- Tools/workflows: “Model behavior map” reports; portfolio selection dashboards.
- Assumptions/dependencies: Sufficiently rich evaluation datasets; stable behaviors across prompts/domains.
- Early-stage method transfer to other repeated games with available logs
- Sectors: marketplaces (auctions, bidding), ad-tech, traffic routing simulations, robotics swarms
- What: Apply AlphaEvolve to existing repeated-game logs (e.g., auctions) to extract interpretable strategies used by agents (human or AI).
- Tools/workflows: Data connectors; template programs for chosen game; multi-objective program search.
- Assumptions/dependencies: Accurate game formalization; sufficient sequence length; domain-specific payoff mappings.
Long-Term Applications
These applications require additional research, scaling, generalization beyond IRPS, or new standards and infrastructure.
- Sector-wide strategic capability standards and audits
- Sectors: finance, healthcare, public sector, platforms
- What: Establish regulatory or industry standards requiring routine audits of LLM strategic behavior (e.g., opponent modeling depth) for consumer-facing or market-facing systems.
- Tools/workflows: Standardized test suites (beyond IRPS), certification protocols, capability disclosures.
- Assumptions/dependencies: Consensus on definitions/thresholds; policy adoption; third-party auditors.
- Strategic alignment training: shaping ToM/opponent modeling to desired levels
- Sectors: AI safety, platform trust & safety
- What: Incorporate behavior-model-informed objectives into fine-tuning (e.g., RLHF) to encourage benign strategic reasoning and avoid exploitative dynamics in human interactions.
- Tools/workflows: Losses that penalize deep conditional opponent modeling in specific contexts; curriculum design.
- Assumptions/dependencies: Reliable detection/measurement of targeted mechanisms; minimal performance regressions elsewhere.
- Robust human proxy frameworks with correction layers
- Sectors: social science, market research, policy forecasting
- What: Build simulation frameworks that adjust LLM outputs via mechanism-level corrections (derived from SBB programs) to better reflect human strategic behavior.
- Tools/workflows: Mechanism-aware simulators; calibration datasets; post-hoc adjustment of conditional dependencies.
- Assumptions/dependencies: Transferability across tasks; validation in diverse populations.
- Real-time behavior interpreters and runtime strategy governors
- Sectors: high-stakes conversational systems, trading assistants, cybersecurity
- What: Stream inference-time traces through a learned interpreter (trained from AlphaEvolve programs) to identify strategy activation and gate actions live.
- Tools/workflows: Low-latency interpreters; policy engines; shadow-mode deployment.
- Assumptions/dependencies: Latency budgets; robust interpretability under distribution shift.
- Multi-domain behavioral model discovery suites
- Sectors: finance (market microstructure), energy (bidding), mobility (traffic negotiation), robotics (multi-robot coordination)
- What: Extend program discovery to domain-specific repeated games to uncover the structural drivers of agent behavior and emergent dynamics.
- Tools/workflows: Domain-specific program templates; causal probes; cross-game generalization tests.
- Assumptions/dependencies: High-quality payoff definitions; rich logs; domain expert oversight.
- Model-driven design of negotiation and procurement agents
- Sectors: enterprise procurement, sales platforms, marketplaces
- What: Use discovered mechanisms to craft agents with controllable strategic profiles (e.g., fast pattern discovery vs. fairness) tailored to counterpart risk profiles and compliance.
- Tools/workflows: Mech‑to‑policy compilers; risk knobs on conditioning depth; compliance attestations.
- Assumptions/dependencies: Legal clarity on acceptable strategic behavior; robust measurement of counterpart impacts.
- Personalized human modeling and skill diagnostics
- Sectors: education, coaching, HR training
- What: Fit individualized SBB programs to users to diagnose strategic biases (e.g., stickiness, conditional rules) and deliver targeted interventions.
- Tools/workflows: Per-user log modeling; feedback dashboards; adaptive curricula.
- Assumptions/dependencies: Data privacy; longitudinal engagement; fair use.
- Safety analytics for emergent higher-order reasoning
- Sectors: AI safety, platform governance
- What: Extend beyond level‑1 opponent modeling to detect emergence of recursive reasoning (level‑k) as models scale or are scaffolded by tools/agents.
- Tools/workflows: New benchmarks; formal tests for recursive modeling; monitoring over scaling experiments.
- Assumptions/dependencies: Valid level‑k detectors; disentangling prompt-scaffold effects.
- Architecture and memory improvements for open-source models
- Sectors: open-source AI ecosystem
- What: Address long-context strategic degradation (as seen with GPT OSS 120B) via memory/caching modules, recurrence, or retrieval-augmented control tailored to repeated interaction settings.
- Tools/workflows: Architectural research; ablation studies; long-horizon evals.
- Assumptions/dependencies: Community collaboration; compute resources; reproducible benchmarks.
- Causal validation and cross-domain generalization research
- Sectors: academia (cog sci, econ, ML)
- What: Design experiments to test whether discovered mechanisms correspond to causal drivers of behavior in humans and LLMs across diverse games (e.g., Prisoner’s Dilemma, auctions).
- Tools/workflows: Pre-registered studies; intervention designs; cross-lab datasets.
- Assumptions/dependencies: Agreement on causal criteria; multi-site collaboration.
- Ethics, consent, and transparency protocols for behavioral modeling
- Sectors: public policy, compliance, platform governance
- What: Establish norms for collecting, analyzing, and acting on behavioral models of users and agents; define disclosure requirements and user controls.
- Tools/workflows: Governance frameworks; transparency UIs; consent management systems.
- Assumptions/dependencies: Regulatory convergence; stakeholder buy-in.
Notes on Key Dependencies and Assumptions
- Domain generalization: Findings are from IRPS; transfer to complex real-world domains requires validation.
- Interpretability proxy: Halstead effort measures code complexity, not human comprehensibility in all cases.
- Descriptive vs. causal: Discovered programs predict well but may not represent the true causal mechanisms.
- Prompting/scaffolds: Results reflect matched human instructions without agentic scaffolds; behavior may differ under tool-use or planning frameworks.
- Data and privacy: Behavioral modeling depends on adequate logs and strict privacy/compliance practices.
- Compute and operationalization: AlphaEvolve entails bilevel optimization and LLM-based code generation; teams need MLOps support to productionize.
Glossary
- Adaptive bots: Opponents that update their strategy based on the player's past actions to exploit patterns. "Adaptive bots track historical sequential dependencies in their opponent's moves, and play to counter the predicted next move with 100\% probability."
- Agentic scaffolds: External structures or tools that enhance an agent’s ability to plan or act strategically. "We demonstrate that frontier LLMs win with higher rates and against more complex opponents than humans in IRPS, even without agentic scaffolds."
- AlphaEvolve: An LLM-powered evolutionary program synthesis framework for discovering interpretable models that optimize a fitness objective. "We employ AlphaEvolve, a cutting-edge program discovery tool, to directly discover interpretable models of human and LLM behavior from data"
- Attraction vector: In EWA-style models, a vector of learned action values specific to a context or history. "maintaining independent attraction vectors for every joint history of length ."
- Bayesian Information Criterion (BIC): A model selection metric that penalizes complexity while rewarding goodness-of-fit. "who used the Bayesian information criterion \citep[BIC;] []{watanabe2013widelyapplicable} to evaluate a programmatic model's predictive performance and simplicity."
- Behavioral game theory (BGT): A framework that studies how real agents (often humans) play games, focusing on deviations from perfect rationality. "While behavioral game theory (BGT) provides a framework for analyzing behavior, existing models do not fully capture the idiosyncratic behavior of humans or black-box, non-human agents like LLMs."
- Bilevel optimization: An optimization structure with an outer loop (e.g., program search) and an inner loop (e.g., parameter fitting). "The overall AlphaEvolve procedure amounts to a bilevel optimization process"
- Bonferroni correction: A statistical adjustment to control family-wise error when conducting multiple hypothesis tests. "AlphaEvolve significantly outperforms the CS-EWA baseline (all , Wilcoxon signed rank with Bonferroni correction; )."
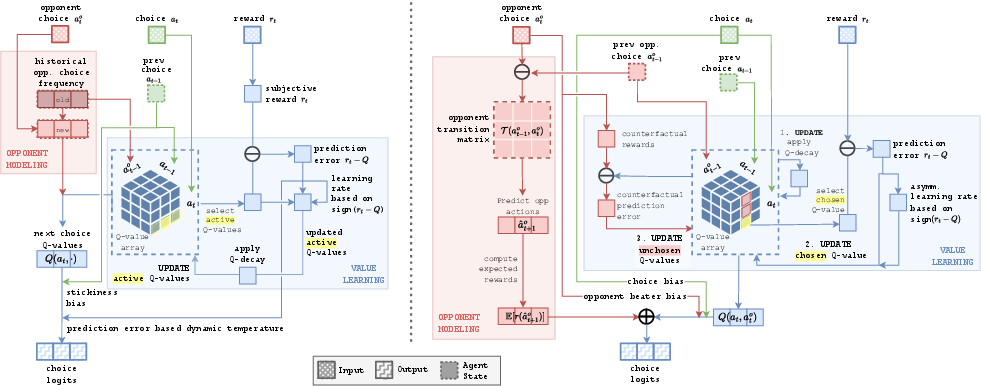
- Choice stickiness: A behavioral bias where an agent tends to repeat its previous action. "Beyond these core components, choice stickiness (previously observed in human IRPS behavior by \citet{eyler2009winningrockpaperscissors}) emerged as the most frequent cognitive bias, appearing in the human, Gemini 2.5, and GPT OSS 120B programs."
- Cognitive biases: Systematic patterns of deviation from rational judgment affecting decision-making. "a simple but foundational testbed that is actively used to study human strategic behavior~\citep{batzilis2019evidence_million}, cognitive biases~\citep{dyson2016negativeoutcomes}, neural processes~\citep{moerel2025neuraldecoding}, opponent modeling~\citep{brockbank2024rrps}, and evolutionary dynamics~\citep{wang2014socialcycling}."
- Cognitive hierarchy theory: A model where players reason at different levels about others’ strategies (e.g., level-1 assumes level-0 opponents). "all agents are characterized by their respective SBB programs as level-1 players in cognitive hierarchy theory~\citep{camerer2004cognitivehierarchy}."
- Conditional response strategies: Rules that condition the next action on the previous outcome (e.g., win-stay-lose-shift). "employ conditional response strategies \citep[e.g., win-stay-lose-shift; ] []{dyson2016negativeoutcomes}."
- Confidence intervals (CIs): Ranges that likely contain the true value of a statistic with a specified confidence level. "Mean and 95\% CIs are displayed, with some CIs not visible due to marker size."
- Counter-exploit: To strategically respond to an exploiter by anticipating and exploiting their exploitative behavior. "this reflects the limited ability of all agents to counter-exploit adaptive bots."
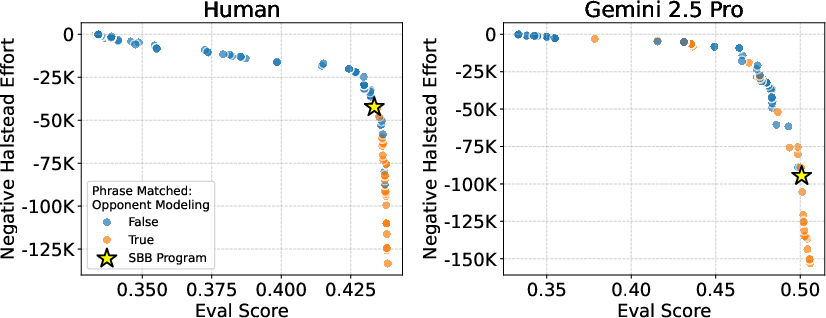
- Counterfactual outcomes: Hypothetical results used for learning or evaluation had different actions been taken. "The Gemini 2.5 Pro program displays more sophisticated opponent modeling than humans and considers counterfactual outcomes during value updates."
- Cross-generalization matrix: A matrix showing how well models discovered for one agent predict behavior in other agents. "We evaluate each SBB program's ability to predict behavior across agents using the cross-generalization matrix in Fig.~\ref{fig:xp_matrix}."
- Cross-validated likelihood: A likelihood-based performance measure evaluated on held-out data folds to assess generalization. "we use a multi-objective fitness function that considers both the cross-validated likelihood of the training dataset, and the Halstead effort."
- Digital twins: Computational proxies intended to mimic human behavior for simulation or analysis. "Understanding differences is crucial for understanding limitations of LLMs as digital twins, improving behavioral alignment to human expectations, and monitoring LLM capabilities."
- Experience-Weighted Attraction (EWA): A repeated-game learning model combining reinforcement and belief-based updates of action values. "While Experience-Weighted Attraction (EWA) \citep{camerer1999experienceweightedattraction} hybridizes reinforcement and belief-based learning for repeated play, and Sophisticated EWA \citep{camerer2002sophisticatedexperienceweighted} incorporates recursive reasoning about opponents, both assume random rematching between rounds."
- Gated Recurrent Unit (GRU): A recurrent neural network architecture designed to capture sequential dependencies efficiently. "we use an RNN based on the Gated Recurrent Unit~\citep[GRU;] []{cho2014propertiesneural}."
- Halstead effort: A software metric estimating the effort required to understand or implement code based on operators and operands. "we employ the Halstead effort, a software engineering heuristic designed to measure the time required to comprehend and implement a program, based on the number of total and unique operators and operands in code"
- Iterated Rock-Paper-Scissors (IRPS): A repeated-play version of RPS used to study strategic learning and opponent modeling. "We compare the behavior of humans and LLMs in the matrix game Iterated Rock-Paper-Scissors (IRPS), a simple but foundational testbed that is actively used to study human strategic behavior~\citep{batzilis2019evidence_million}, cognitive biases~\citep{dyson2016negativeoutcomes}, neural processes~\citep{moerel2025neuraldecoding}, opponent modeling~\citep{brockbank2024rrps}, and evolutionary dynamics~\citep{wang2014socialcycling}."
- Level-1 player: An agent that best-responds assuming opponents are level-0 (do not model the agent). "Since these models directly model opponent choice frequencies and do not recursively consider the agent itself, all agents are characterized by their respective SBB programs as level-1 players in cognitive hierarchy theory~\citep{camerer2004cognitivehierarchy}."
- Maximum likelihood estimation: A parameter estimation method that maximizes the probability of observed data under a model. "A behavioral model is parameterized by a vector , which may be fit to a dataset , using the standard maximum likelihood estimation and stochastic gradient descent (SGD)."
- Matrix games: Strategic games represented by payoff matrices where players choose actions simultaneously. "this paper studies the question through the lens of iterated matrix games."
- Nash equilibrium: A strategy profile where no player can benefit by unilaterally changing their strategy. "The Nash equilibrium, which specifies game-theoretically optimal behavior, prescribes that a rational agent should act randomly to prevent exploitable patterns in behavior from developing~\citep{vonneumann1944theorygames}."
- Nonadaptive bots: Opponents that follow fixed transition rules without learning from the player's behavior. "Nonadaptive bots employ transition-based strategies that map a small amount of historical context to fixed next moves (e.g., playing the move that beats the opponent's prior move) with 90\% probability."
- Normalized likelihood: Likelihood scaled to a baseline for comparability across datasets or models. "To evaluate predictive fit and generalization, model performance is reported as the two-fold cross-validated normalized likelihood~(see App. \ref{app:behavior_modeling})."
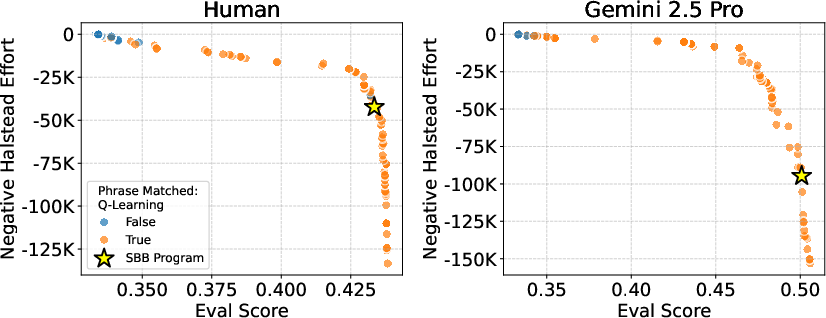
- Occam's Razor: A principle favoring simpler explanations when they fit data nearly as well as complex ones. "Applying Occam's Razor, we study not the best-fit programs discussed in Section~\ref{sec:exp:alphaevolve}, but the simplest programs that fit the data well."
- Opponent modeling: Inferring and tracking the opponent’s strategy to predict and exploit future actions. "Of particular interest is that iterated rock-paper-scissors (IRPS) creates the ideal conditions to investigate the human ability to perform opponent modeling"
- Oracle knowledge: Perfect foreknowledge of the opponent’s policy used as an upper-bound benchmark. "compared to the win rates of a randomly acting player and a player with oracle knowledge of the bot policy."
- Pareto frontier: The set of models that are non-dominated in a multi-objective trade-off (e.g., accuracy vs. simplicity). "Fig.~\ref{fig:pareto_frontier_all} displays the evaluation score of all programs located on the Pareto frontier of training likelihood and negative Halstead effort."
- Programmatic behavioral model: A behavior model explicitly represented as executable code specifying state updates and action probabilities. "A programmatic behavioral model is a model that is represented as a program"
- Q-learning: A reinforcement learning method that updates action-value estimates to guide policy. "Using an LLM judge, we also verify that over the Pareto frontiers of AlphaEvolve programs for humans and Gemini 2.5 Pro, opponent modeling is a concept included in the majority of programs that fit the data well, while Q-learning is present in nearly all programs."
- Q-table: A tabular mapping from states (or contexts) and actions to estimated values used for action selection. "All programs but GPT OSS 120B use a 3x3x3 Q-table representing the value of the current action given the prior joint action, "
- Quantal response equilibria: Game-theoretic models where players choose stochastically with probabilities increasing in expected payoff. "quantal response equilibria~\citep{mckelvey1995quantalresponse}"
- Recurrent Neural Network (RNN): A class of neural networks for modeling sequential data with temporal dependencies. "As a reference point for performance of a highly flexible but black-box statistical learner, we use an RNN based on the Gated Recurrent Unit~\citep[GRU;] []{cho2014propertiesneural}."
- Sequential dependencies: Statistical relationships across time in action sequences used by adaptive bots to predict next moves. "Adaptive bots track historical sequential dependencies in their opponent's moves, and play to counter the predicted next move with 100\% probability."
- Sophisticated EWA: An extension of EWA that incorporates recursive reasoning about opponents’ future responses. "Sophisticated EWA \citep{camerer2002sophisticatedexperienceweighted} incorporates recursive reasoning about opponents"
- Stochastic gradient descent (SGD): An iterative optimization algorithm that updates parameters using noisy gradient estimates. "using the standard maximum likelihood estimation and stochastic gradient descent (SGD)."
- Theory-of-Mind (ToM): The capacity to attribute beliefs, desires, and intentions to others to predict their behavior. "ToM, or the cognitive ability for an agent to understand the beliefs, desires and intentions of others, is a crucial aspect of human social interaction."
- Transition-based strategies: Rules that map recent history to next actions without learning (used by nonadaptive bots). "Nonadaptive bots employ transition-based strategies that map a small amount of historical context to fixed next moves"
- Two-player zero-sum game: A game where one player’s gain is exactly the other’s loss. "Rock-paper-scissors (RPS) is a two-player zero-sum game with well-understood theoretical properties."
- Value-based learning: Learning that updates action values based on received rewards to guide future choices. "Both programs use value-based learning and opponent modeling."
- Wilcoxon signed rank: A nonparametric test comparing paired samples’ median differences. "AlphaEvolve significantly outperforms the CS-EWA baseline (all , Wilcoxon signed rank with Bonferroni correction; )."
Collections
Sign up for free to add this paper to one or more collections.