LUCID: Attention with Preconditioned Representations
Published 11 Feb 2026 in cs.LG | (2602.10410v1)
Abstract: Softmax-based dot-product attention is a cornerstone of Transformer architectures, enabling remarkable capabilities such as in-context learning. However, as context lengths increase, a fundamental limitation of the softmax function emerges: it tends to diffuse probability mass to irrelevant tokens degrading performance in long-sequence scenarios. Furthermore, attempts to sharpen focus by lowering softmax temperature hinder learnability due to vanishing gradients. We introduce LUCID Attention, an architectural modification that applies a preconditioner to the attention probabilities. This preconditioner, derived from exponentiated key-key similarities, minimizes overlap between the keys in a Reproducing Kernel Hilbert Space, thus allowing the query to focus on important keys among large number of keys accurately with same computational complexity as standard attention. Additionally, LUCID's preconditioning-based approach to retrieval bypasses the need for low temperature and the learnability problems associated with it. We validate our approach by training ~1 billion parameter LLMs evaluated on up to 128K tokens. Our results demonstrate significant gains on long-context retrieval tasks, specifically retrieval tasks from BABILong, RULER, SCROLLS and LongBench. For instance, LUCID achieves up to 18% improvement in BABILong and 14% improvement in RULER multi-needle performance compared to standard attention.
The paper introduces LUCID, an RKHS-based preconditioning method that decorrelates keys to deliver sharp, accurate retrieval even at very long sequence lengths.
The method decouples attention sharpness from temperature, overcoming softmax limitations and providing significant improvements in needle-in-haystack tasks across extended contexts.
Empirical results show LUCID achieving robust performance with minimal computational overhead, supporting state-of-the-art long-context reasoning and adaptation.
LUCID: Attention with Preconditioned Representations
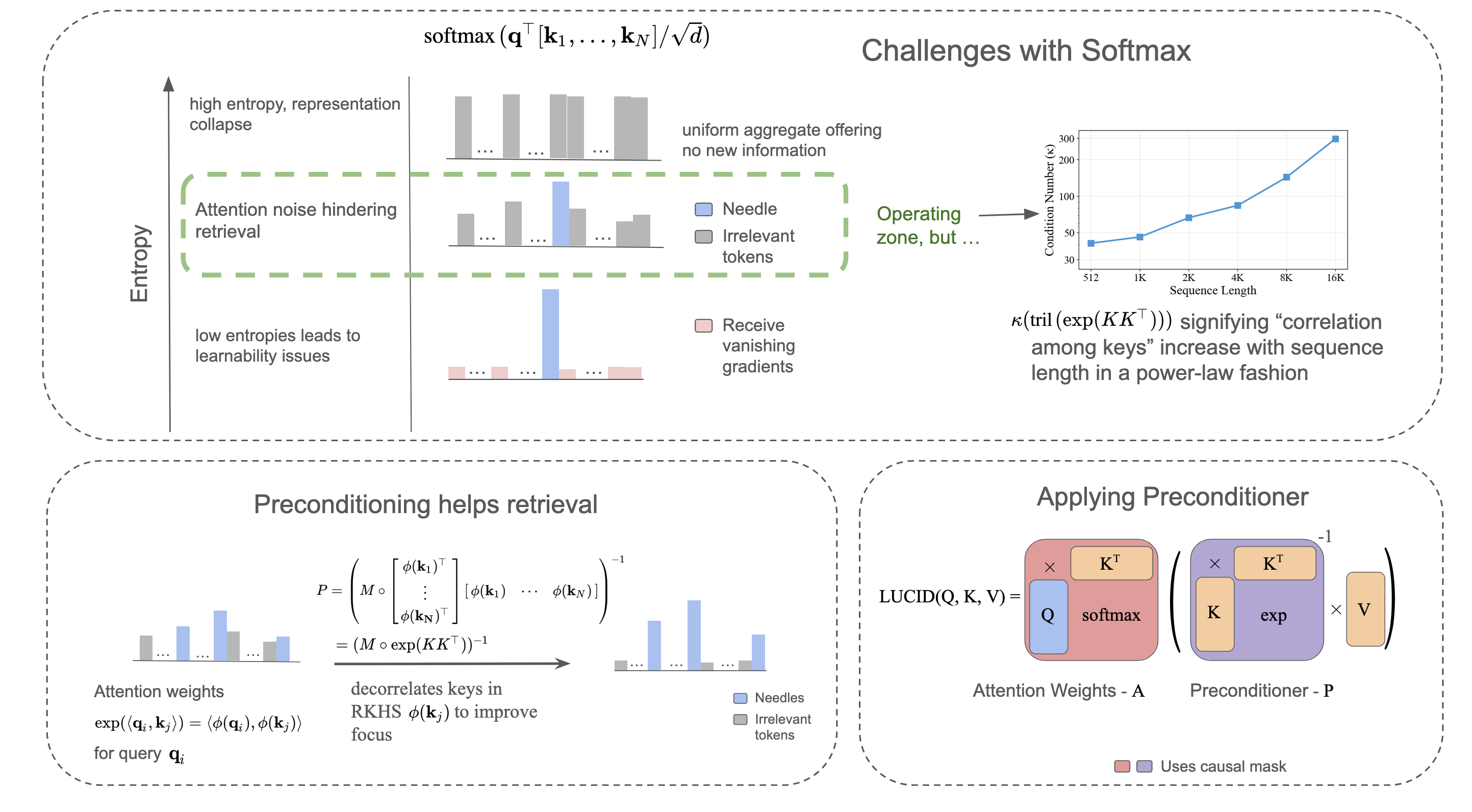
Introduction and Motivation
The Transformer architecture’s reliance on softmax-based dot-product attention has propelled significant advancements in language modeling, in-context learning, and retrieval. However, as sequence lengths increase, softmax attention suffers from fundamental limitations—dilution of attention caused by the diffusion of probability mass over irrelevant tokens (attentional noise), and instability and learnability hurdles when the temperature is tuned to sharpen attention. Notably, attempts to decrease softmax entropy for sharper distributions directly compromise gradient flow, leading to vanishing gradients and stagnated learning.
LUCID Attention is introduced as an architectural solution that applies a preconditioner—derived from key-key similarities in a Reproducing Kernel Hilbert Space (RKHS)—to the attention mechanism. By decorrelating the keys in RKHS, LUCID enables the query to focus more sharply and accurately on relevant information even as the contextual window scales to 128K tokens, all while maintaining the computational complexity of standard attention.
Method: Preconditioning in RKHS
The key innovation in LUCID is the application of a preconditioner matrix to the attention computation, constructed as the inverse of the masked, exponentiated key-key Gram matrix. This preconditioner decorrelates the keys in RKHS, where attention probabilities are proportional to the inner product of exponential feature maps. The standard softmax is retained (with typical temperature), and sharp, high-fidelity retrieval is achieved by deconvolving the value aggregation through the preconditioner—thus sharpness and learnability are decoupled.
Figure 1: The attentional noise challenge in softmax attention due to high entropy and correlated keys, and schematic of LUCID’s preconditioner mechanism.
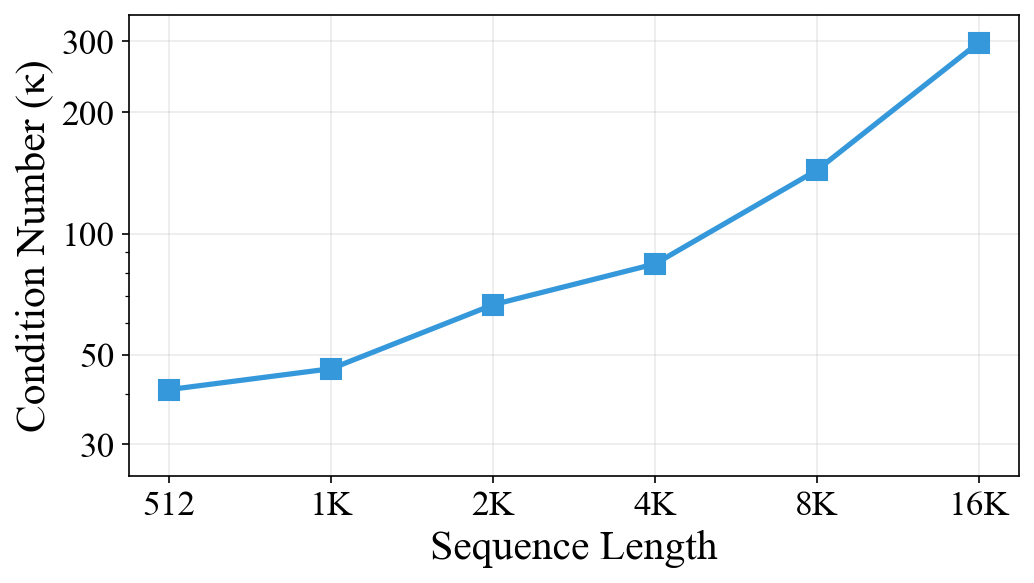
Because the preconditioner leverages the lower-triangular structure induced by causal masks, it is efficiently invertible via forward substitution or specialized GPU kernels. Importantly, as sequence length increases, the condition number of the preconditioner grows, reflecting the accumulation of key correlations and showing LUCID’s necessity as context length scales.
Figure 2: Condition number κ of the LUCID preconditioner matrix increases with sequence length, highlighting amplified key correlation.
Mathematically, the LUCID attention operation can be written as:
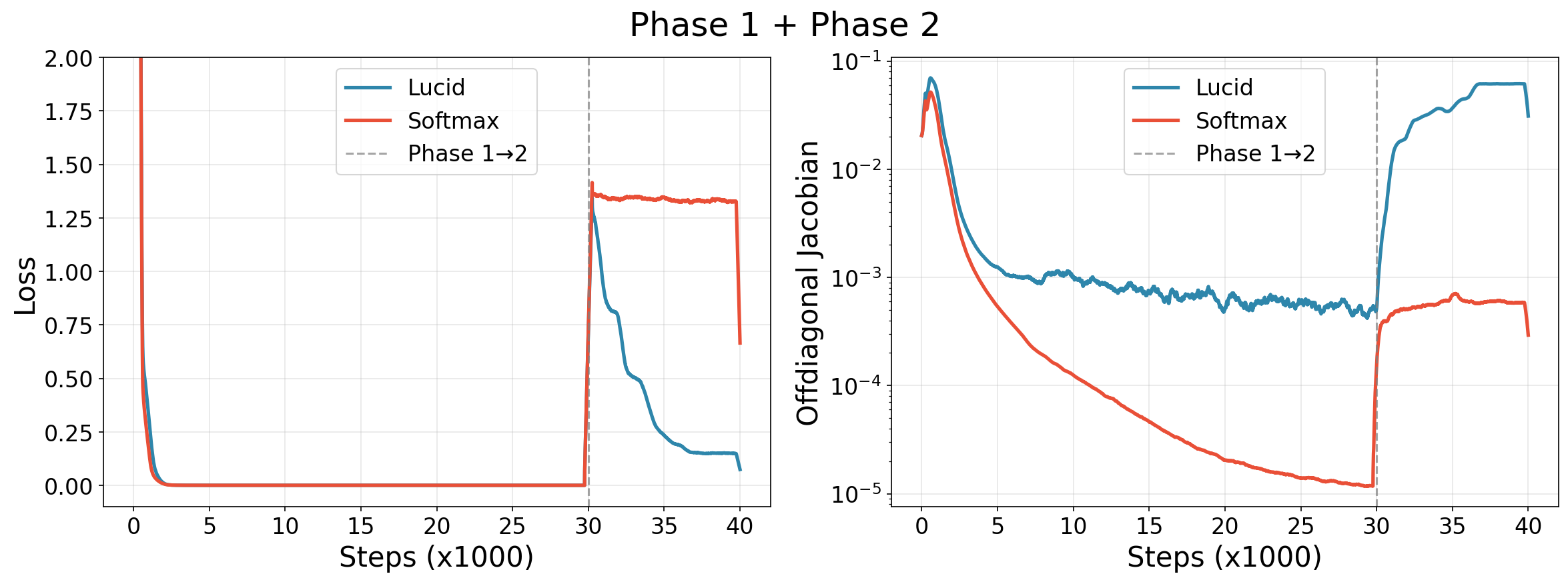
A central theoretical and empirical result is LUCID's ability to achieve precise retrieval (sharp attention) while maintaining robust gradient propagation. In contrast, standard softmax sharpens distributions only at the cost of vanishing gradients as the temperature is lowered toward zero. LUCID decouples retrieval sharpness from temperature, preserving a non-degenerate Jacobian and circumventing learnability failures.
This property is illustrated in synthetic tasks, where standard attention, after learning difficult retrieval mappings with low entropy, completely fails to adapt to subsequent tasks requiring broader, distributed attention due to a vanishing Jacobian. LUCID, operating with higher attention entropy but decorrelated key space, adapts efficiently in both sharp and distributed attention regimes.
Figure 3: In sequential task learning, LUCID supports rapid adaptation during a retrieval-to-averaging phase transition, while softmax attention with reduced Jacobian magnitude stagnates.
Empirical Results
Needle-in-a-Haystack Retrieval
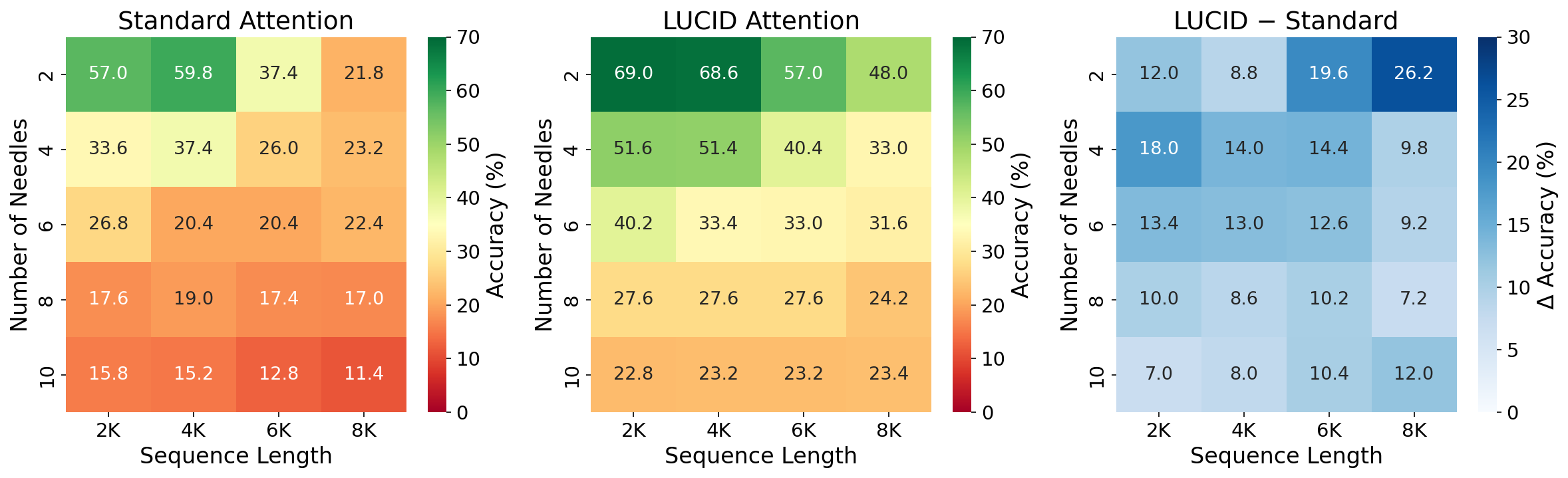
On the multi-needle-in-a-haystack (MNIAH) tasks, LUCID demonstrates clear advantages as contextual difficulty (sequence length and number of distractor “haystack” tokens) increases. Standard Attention’s accuracy plummets in challenging regimes (e.g., 11.4% in the hardest configuration), while LUCID maintains substantially higher accuracy, with improvements of 10–26% particularly prominent at larger sequence lengths.
Figure 4: LUCID Attention yields robust improvements over Standard Attention in MNIAH retrieval accuracy, especially as context length and distractor count scale.
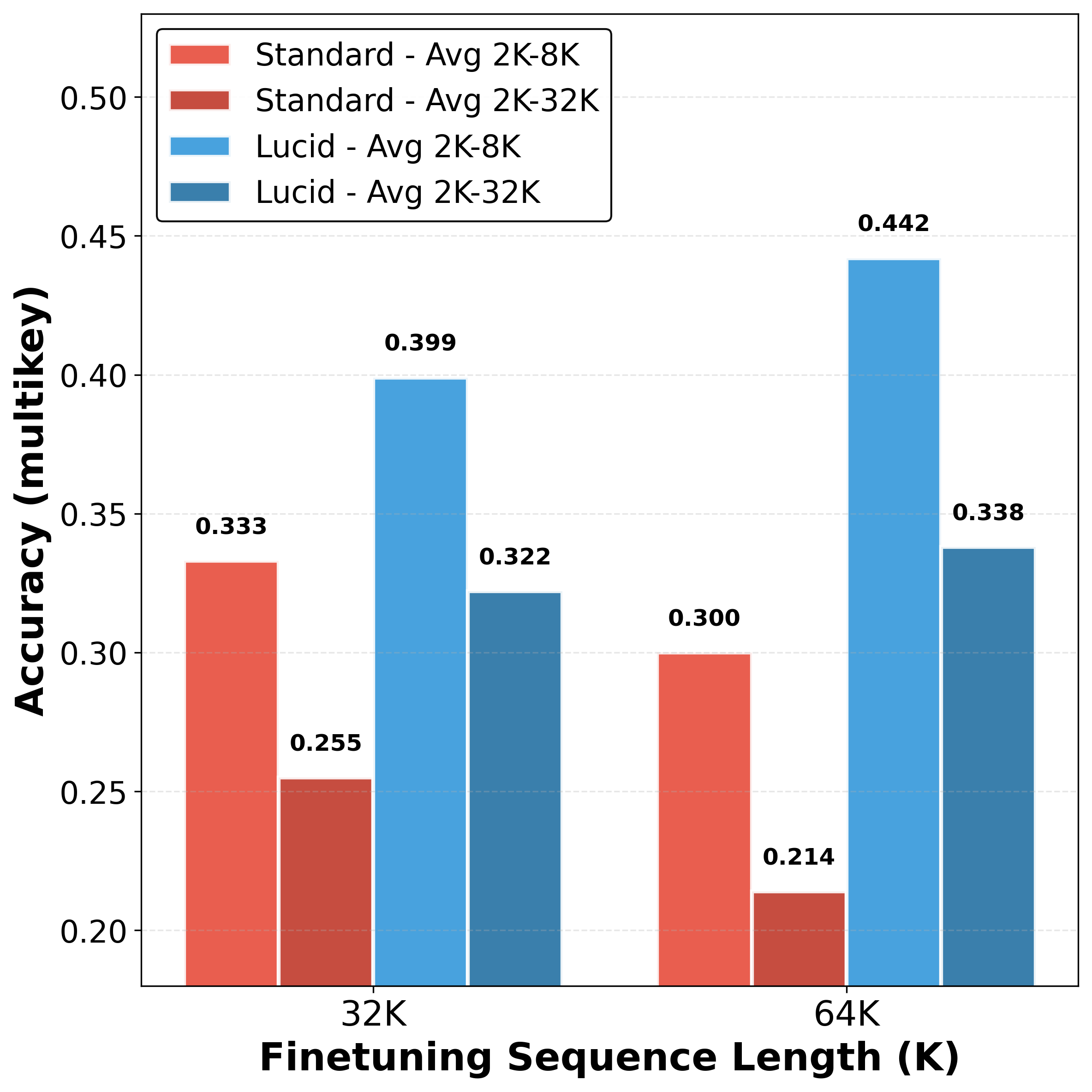
Scaling with Finetuning Length
The margin by which LUCID outperforms Standard Attention increases with the length of finetuning. For example, moving from 32K to 64K sequence length during finetuning increases LUCID’s advantage from +19.8% to +47.3% in multi-needle tasks, substantiating LUCID's claim that its preconditioning becomes even more essential as sequence lengths become large.
Figure 5: LUCID’s multi-needle retrieval accuracy advantage over Standard Attention grows as the finetuning sequence length increases.
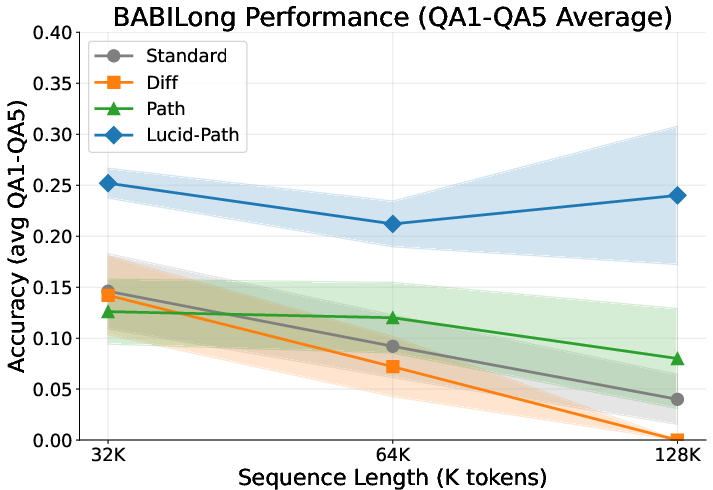
Long-Context Reasoning and Benchmarking
On the BABILong long-context benchmark (32K to 128K tokens), LUCID-PaTH, which integrates LUCID preconditioning with advanced positional encoding, exhibits stable retrieval accuracy across increasing sequence lengths. In contrast, both Standard Attention and contemporary baselines suffer pronounced degradation.
Figure 6: LUCID-PaTH achieves stable, high BABILong retrieval accuracy as context length increases, unlike baseline degradation.
For downstream tasks in LongBench and SCROLLS—which probe multi-document QA, single-document QA, and summarization—LUCID and its PaTH variant achieve the best or near-best F1 and ROUGE scores in the majority of evaluated settings.
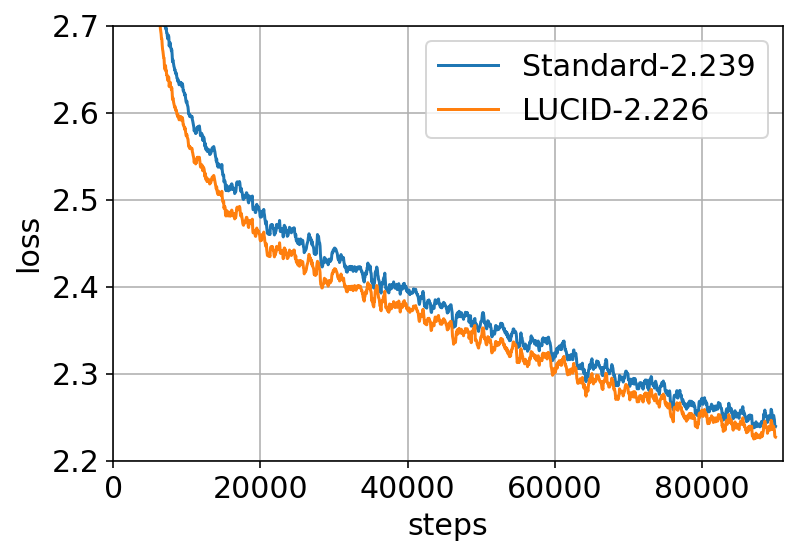
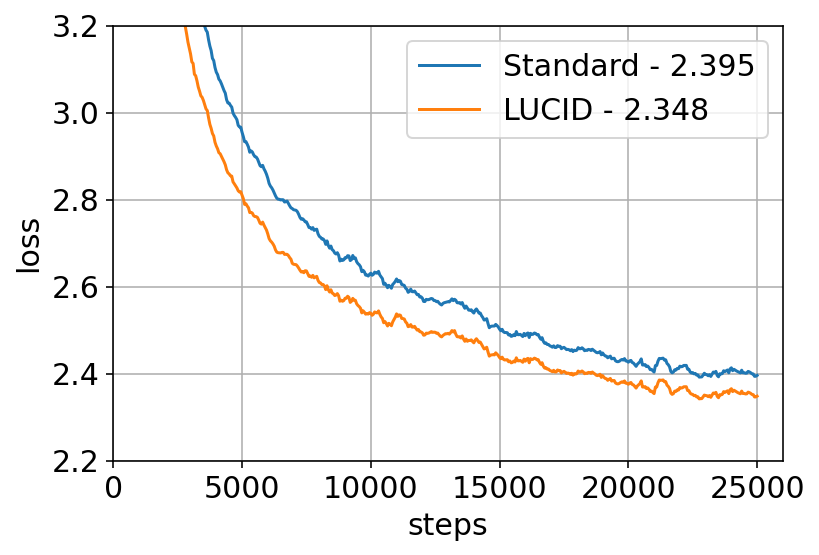
Training Dynamics
When comparing loss curves at large context lengths (4096 and 32,768), LUCID achieves consistently lower validation loss throughout training, with the performance gap increasing as sequence length grows.
Figure 7: LUCID achieves lower validation loss than Standard Attention at both 4K and 32K sequence lengths.
Computational Efficiency
Despite the added triangular linear system solve, LUCID incurs only minor overhead—0–5.5% during training and negligible (<1.5%) during inference on standard GQA/MQA architectures. Ablation confirms that additional compute alone (e.g., increasing baseline training steps) is insufficient to match LUCID’s benefits; improvements are architectural, not simply a function of more training.
Implications and Future Directions
LUCID reframes attention as a quadratic objective in RKHS rather than the standard linear regime, formalizing memory erasure and key decorrelation as architectural priors. Practically, this enables Transformer-based LMs to maintain precision and adaptability in long-context and retrieval-heavy applications. The method is particularly suited for auto-regressive, causal language modeling, as it exploits the masked lower-triangular structure for efficient computation.
However, for bidirectional attention (e.g., in bidirectional encoder architectures or diffusion models), the preconditioner becomes computationally more demanding due to loss of triangular structure, indicating a rich direction for future algorithmic innovation around invertible attention preconditioners in non-causal settings.
Theoretically, LUCID’s distinct treatment of attention as preconditioned regression in RKHS motivates deeper investigation into explicit kernel-based architectures and the relationship between attention mechanisms and structured memory.
Conclusion
LUCID Attention offers a principled and effective architectural remedy for the well-documented issues of attention noise, learnability, and performance collapse in long-context Transformer models. By decorrelating keys in RKHS through a tractable preconditioner, it enables sharp, adaptable retrieval and robust gradient flow at practical computation cost. As applications demand ever-longer context windows and precise in-context reasoning, methods like LUCID present viable architectural directions for scalable, high-fidelity Transformer models.