- The paper introduces a synthetic pipeline that converts well-specified tasks into controllably underspecified variants to rigorously assess clarify-or-act decisions.
- It employs a four-dimensional taxonomy (Goal, Constraint, Input, Context) and empirically validates agent responses to uncover systematic ambiguity handling failures.
- Empirical results reveal that agent performance degrades with increased underspecification, with models showing diverse clarification behaviors impacting overall task success.
LHAW: Controllable Underspecification for Long-Horizon Tasks
Motivation and Problem Statement
Current agent benchmarks inadequately assess clarify-or-act decision-making in long-horizon workflows. Most evaluate execution on fully specified tasks or clarify-in-context benchmarks that ignore realistic interruption costs. Actual deployment domains demand not only procedural competence but also sensitive detection of missing critical information—underspecification—that would block task progress or result in silent failure. Addressing this evaluation blind spot, "LHAW: Controllable Underspecification for Long-Horizon Tasks" (2602.10525) introduces a rigorous synthetic framework for systematically generating, validating, and benchmarking ambiguity in complex sequential tasks.
The LHAW Pipeline: Structure and Mechanics
LHAW introduces a modular, dataset-agnostic pipeline that transforms well-specified tasks (from TheAgentCompany, SWE-Bench Pro, and MCP-Atlas) into controllably underspecified variants. The process comprises three tightly integrated phases:
- Segment Extraction and Scoring: An LLM decomposes original prompts into atomic, removable information segments, each classified into one of four explicit dimensions—Goal, Constraint, Input, Context—mirroring agent failure taxonomies observed in prior long-horizon tasks. Each segment is scored for criticality (impact of removal on task outcome) and guessability (likelihood an agent could recover the info via context or environment exploration).
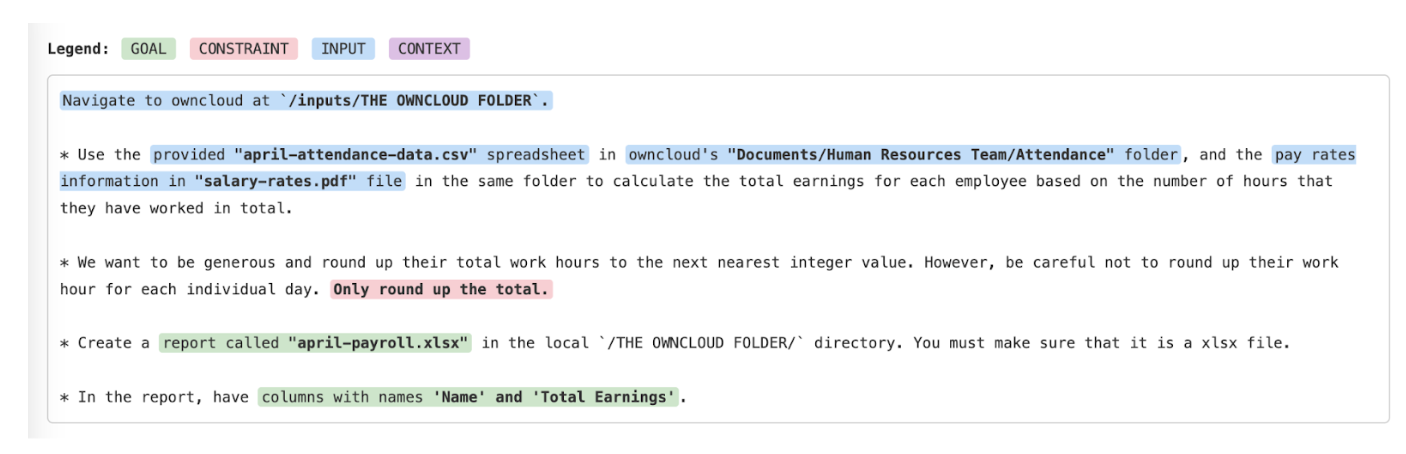
Figure 1: Segment extraction output, showing classification and prioritization of removable segments by information dimension and scoring for criticality and guessability.
- Variant Generation: Systematic ablation yields underspecified prompt variants using controlled removal, vaguification, or genericization of prioritized segments. Severity (single or multi-segment removal) and strategy are configurable, producing predictable ambiguity gradients.
- Empirical Validation: Variants are empirically trialed by agents; outcome distributions determine if removal results in consistent failure ("outcome-critical"), variable interpretive success ("divergent"), or reliable recovery ("benign"). This empirically grounds the taxonomy and ambiguity class assignment.
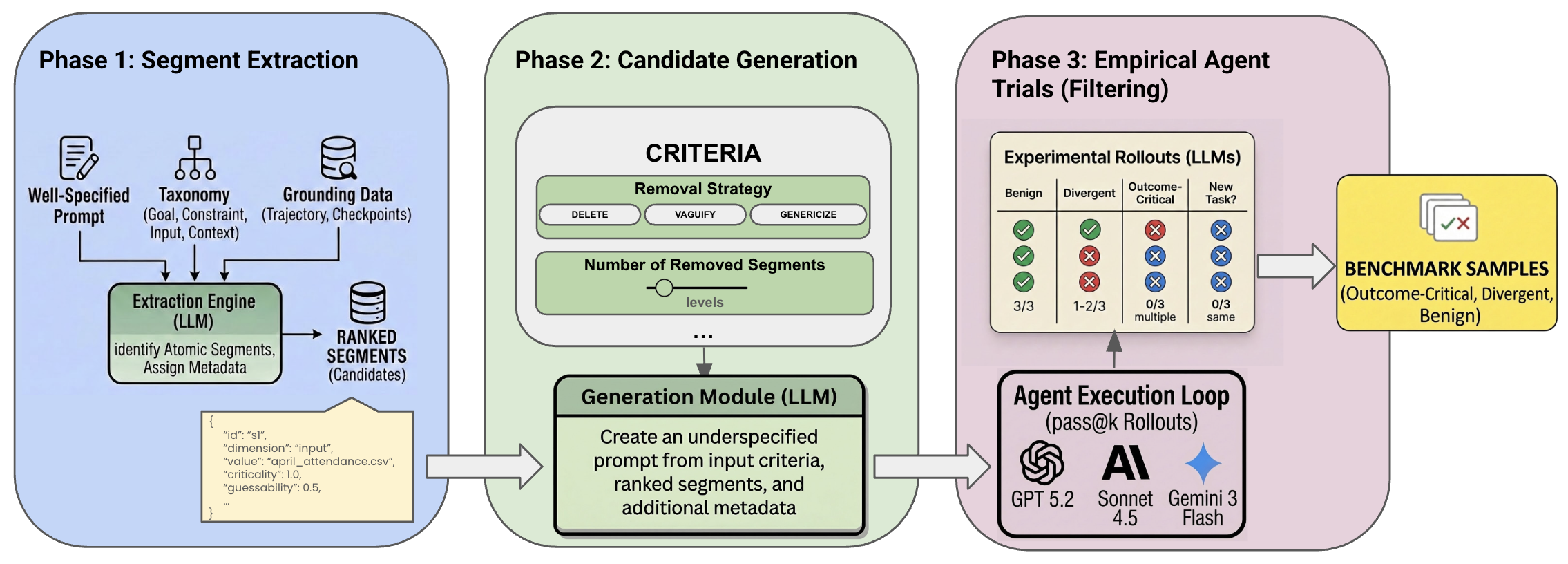
Figure 2: The end-to-end LHAW synthetic underspecification pipeline: segment extraction, variant generation, and empirical agent validation.
Taxonomy of Task Specification and Ambiguity
LHAW's four-dimensional taxonomy dissects the structure of task specification: Goal (what is to be achieved), Constraint (operational boundaries), Input (resources/domains required), and Context (domain logic or conventions). Systematic removal along these axes reveals agent limits in both specification-sensitivity and reasoning-through-missingness. Crucially, the pipeline discriminates between recoverable and blocking omissions via empirical benchmarks, instead of relying on LLM intuitions, to support analysis of failure modes at scale.
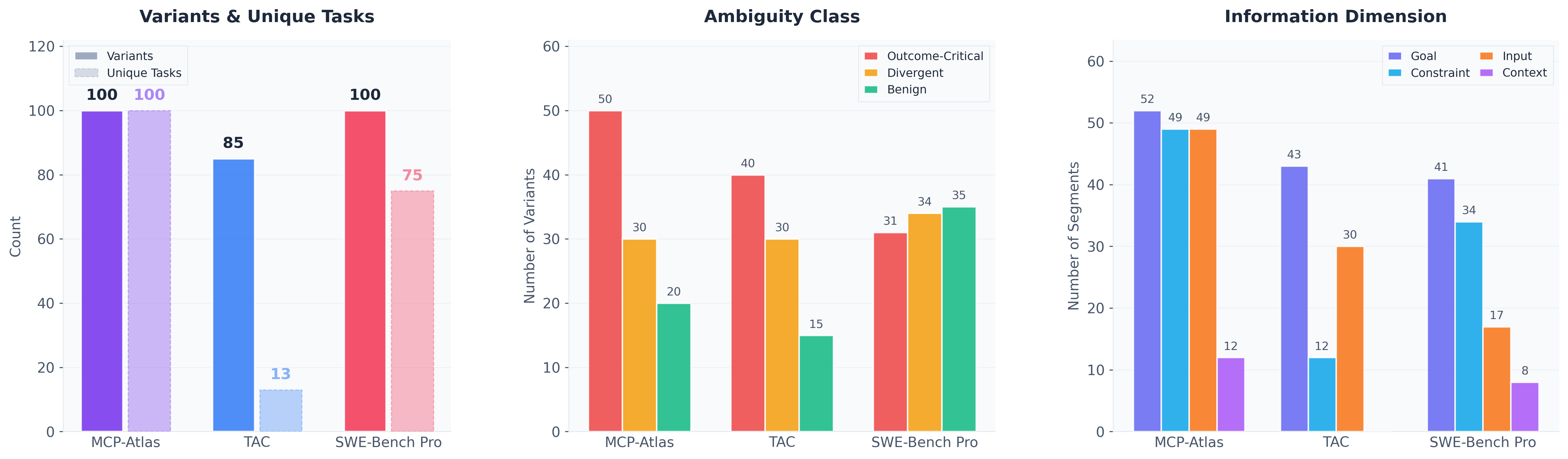
Figure 3: Distribution of LHAW dataset variants across benchmarks, ambiguity classes, and information dimensions, illustrating controllable coverage.
Benchmark Construction and Dataset Properties
The authors curate 285 carefully categorized task variants from three leading agent benchmarks. Selection criteria ensure that variants stem from tasks solvable by agents under full specification, calibrating underscore that performance drop under underspecification is attributed to ambiguity handling, not lack of basic competence.
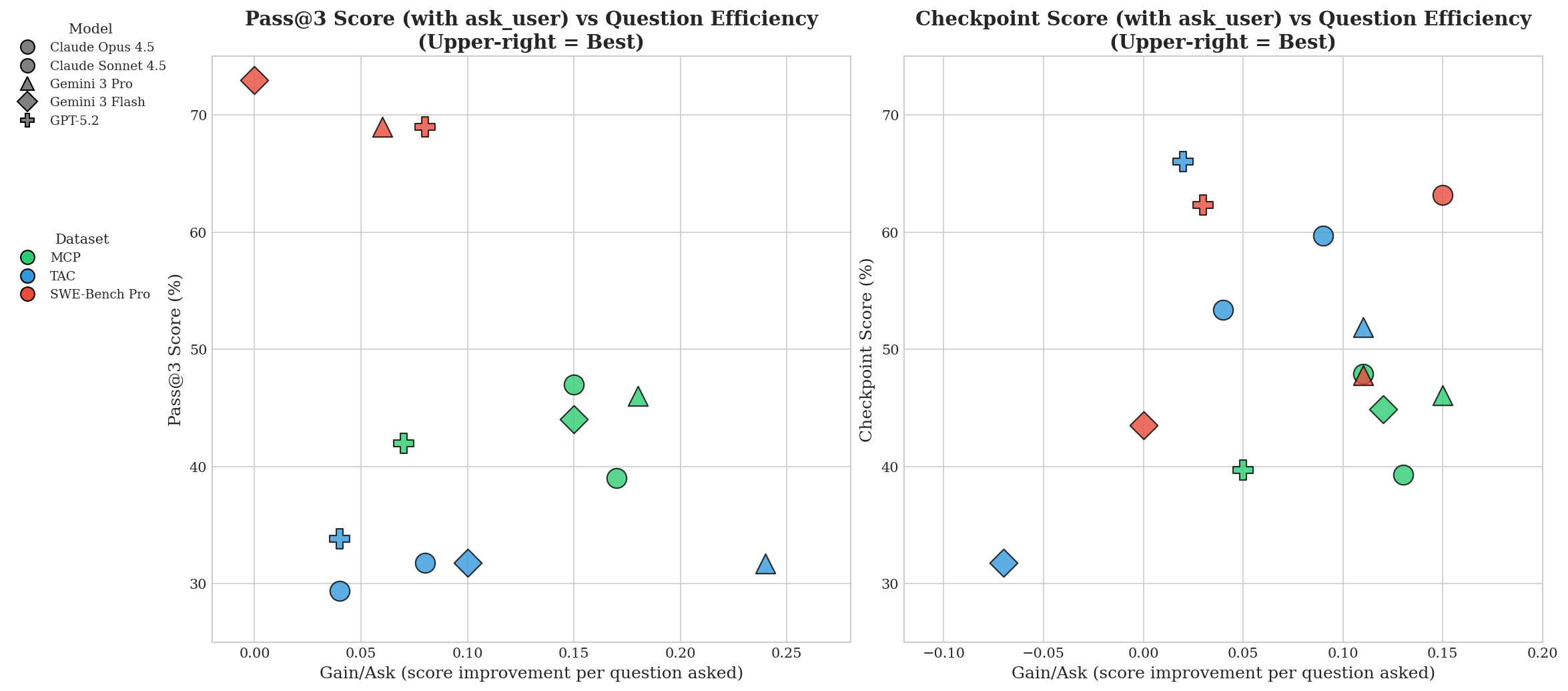
Severity of underspecification is shown to correlate with agent performance degradation and with the marginal value of user clarification, with multi-segment removal yielding markedly steeper difficulty curves. Empirical partitioning—outcome-critical, divergent, benign—is tightly validated, showing near-total failure on outcome-critical variants when no clarification is sought (Table: Outcome-Critical Fidelity).
Agent Behavior under Underspecification
LHAW provides a unique lens to analyze clarify-or-act dynamics. Frontier models (Claude Opus-4.5, Gemini-3, GPT-5.2, Sonnet-4.5) were instrumented to use an ask_user tool (simulated user responding only to missing info queries). Measured axes include task success (pass@3, checkpoint completion), clarification invocation rate (Ask%), average questions (Avg Q), and Gain/Q (fractional performance recovered per user call). Key empirical outcomes:
Additionally, human cost modeling by varying user personas ("Supervisor" [low cost], "Busy Executive" [high cost]) directly modulates agent clarification rate and efficiency, evidencing that agents dynamically adjust question frequency based on perceived ask cost.
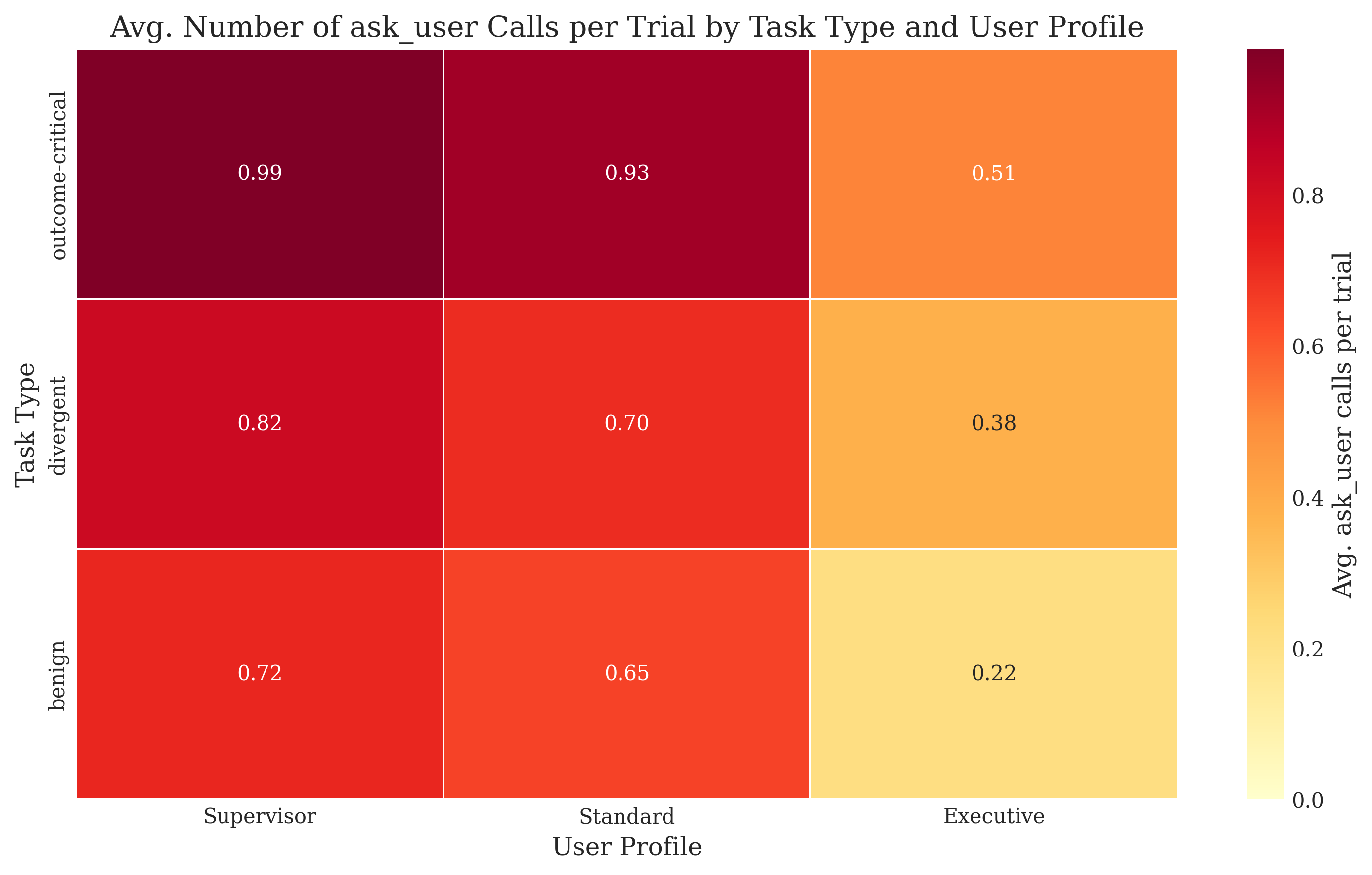
Figure 5: Number of ask_user calls per trial, demonstrating agent adaptation to both ambiguity class and assigned user persona (cost sensitivity).
Characterization of Failure Modes
Comprehensive analysis identifies dominant failure modes. Among all clarification trajectories, the most frequent errors are:
- Question Quality Deficits: Compound or vague questions yielding incomplete user responses.
- Over-Clarification: Redundant or unnecessary questions, especially with GPT-5.2.
- Under-Clarification: Insufficient or missing queries in outcome-critical settings, especially for Gemini models.
- Question Targeting Errors: Failure to identify and query truly blocking omissions.
Correlating failure rates with outcome class, the data show that low-quality or poor-target questions sharply limit recovery of baseline performance, even when the user simulator is optimally cooperative.
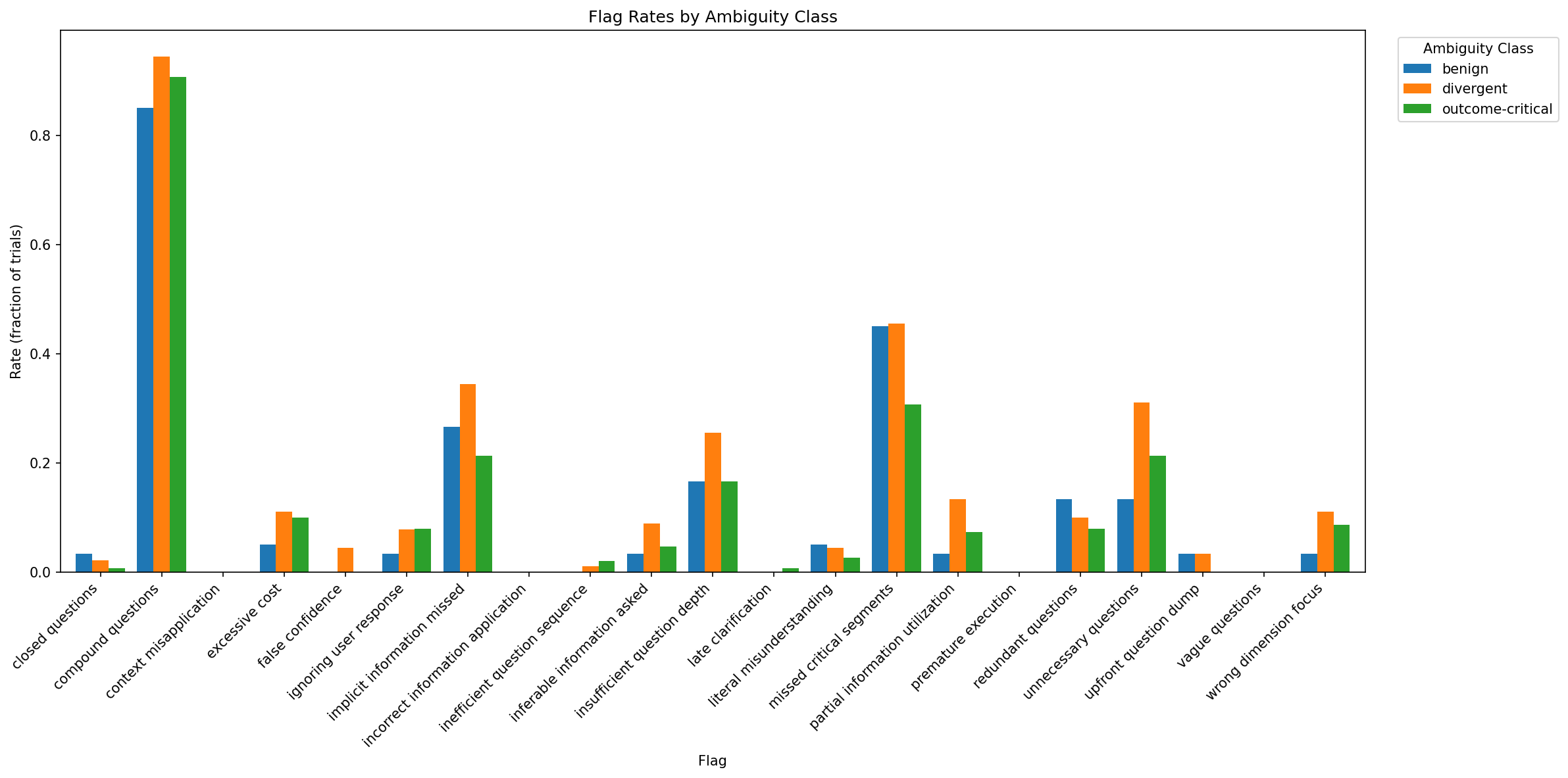
Figure 6: Full taxonomy of ask_user failure modes, with compound questions and missed critical segments as dominant contributors.
Ablations: Prompting Strategies and Robustness
Prompting strategies themselves impact ambiguity sensitivity. More sophisticated agentic frameworks (e.g., Plan-and-Execute, Reflexion, ReAct) increase clarification and partial progress but can sometimes reduce overall task success versus simpler prompting. For the hardest, outcome-critical tasks, Plan-and-Execute and Reflexion show higher checkpoint coverage when clarification is available, but may interfere with agent's natural exploration behavior in less ambiguous settings.
Theoretical and Practical Implications
LHAW's framework exposes the deficiency of current LLM agents in uncertainty quantification and cost-sensitive clarification. Empirically validated outcome-critical variants provide the strongest available testbed for clarify-or-act decisions in real-world, high-stakes, long-horizon workflows. The modular pipeline, classification protocols, and appraised dataset support scalable future benchmarking and agent improvement.
Primary limitations relate to prompt-level ambiguity only (environmental or dynamic context ambiguity is not addressed), and semantic ambiguity or context conflict is outside the present scope. Future research could extend to richer forms of ambiguity, improved user simulation, and integrated decision-theoretic value-of-information models for agent action selection.
Conclusion
LHAW establishes a principled, extensible methodology for controllable underspecification in long-horizon agent benchmarks, empirically validating agent sensitivity to specification and clarify-or-act tradeoffs. This work constitutes a foundation for rigorous, cost-sensitive evaluation of agent clarification behavior, with implications for the design of more reliable, autonomous systems capable of safely navigating ambiguity in practice.