MOSS-Audio-Tokenizer: Scaling Audio Tokenizers for Future Audio Foundation Models
Abstract: Discrete audio tokenizers are fundamental to empowering LLMs with native audio processing and generation capabilities. Despite recent progress, existing approaches often rely on pretrained encoders, semantic distillation, or heterogeneous CNN-based architectures. These designs introduce fixed inductive biases that limit reconstruction fidelity and hinder effective scaling. In this paper, we argue that discrete audio tokenization should be learned fully end-to-end using a homogeneous and scalable architecture. To this end, we first propose CAT (Causal Audio Tokenizer with Transformer), a purely Transformer-based architecture that jointly optimizes the encoder, quantizer, and decoder from scratch for high-fidelity reconstruction. Building on the CAT architecture, we develop MOSS-Audio-Tokenizer, a large-scale audio tokenizer featuring 1.6 billion parameters, pre-trained on 3 million hours of diverse, general audio data. We show that this simple, fully end-to-end approach built from homogeneous, causal Transformer blocks scales gracefully and supports high-fidelity reconstruction across diverse audio domains. Across speech, sound, and music, MOSS-Audio-Tokenizer consistently outperforms prior codecs over a wide range of bitrates, while exhibiting predictable improvements with increased scale. Notably, leveraging the discrete tokens from our model, we develop the first purely autoregressive TTS model that surpasses prior non-autoregressive and cascaded systems. Furthermore, MOSS-Audio-Tokenizer enables competitive ASR performance without auxiliary encoders. Our findings position the CAT architecture as a unified, scalable interface for the next generation of native audio foundation models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces a new way to turn sounds (like speech, music, and everyday noises) into small, reusable pieces called “tokens,” so that computers can understand and create audio as easily as they handle text. The authors build a large, simple system called MOSS-Audio-Tokenizer (based on a design they call CAT) that learns directly from raw audio to produce high-quality tokens. These tokens work well for many tasks, such as speaking from text (text-to-speech, or TTS) and understanding speech (automatic speech recognition, or ASR), and they scale up smoothly when you give the model more data or make it larger.
Key questions the paper asks
Here are the main questions the paper tries to answer:
- Can we design a single audio tokenizer that works well across speech, music, and general sounds, without using complicated parts or special tricks?
- Can this tokenizer be trained end-to-end (meaning all parts learn together) using only Transformers, so it’s easier to scale up?
- Can it produce high-quality audio at different bitrates (from low detail to high detail) and still work in real time?
- Do the tokens it creates help build better audio models, like an all-autoregressive TTS system that beats older methods and strong ASR without extra encoders?
How they did it (methods and ideas, in simple terms)
Think of audio tokenization like turning a song into LEGO pieces: each piece captures a bit of what the sound is. A good set of LEGO pieces should let you rebuild the song so it sounds almost the same and also be easy for a “LLM” to predict piece by piece.
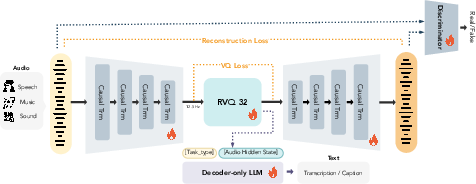
The CAT architecture (Causal Audio Tokenizer)
- “Transformer-only”: Instead of mixing different kinds of neural networks, CAT uses only Transformers (the same type of model that powers many language AIs). This keeps the design simple and scalable.
- “Causal” means it only looks at the past, not the future. Imagine telling a story one word at a time without peeking ahead—this makes it match how we generate audio step-by-step and keeps latency low for streaming.
- End-to-end training: The encoder (compresses audio), quantizer (turns it into tokens), decoder (rebuilds audio), and even critics (discriminators) all learn together. That’s like training a whole orchestra at once, rather than each instrument separately.
Turning sound into tokens: Residual Vector Quantization (RVQ)
- Quantization is like drawing with a limited set of colored pencils. RVQ adds several layers of pencils: the first layer captures the broad strokes, and each extra layer adds more detail.
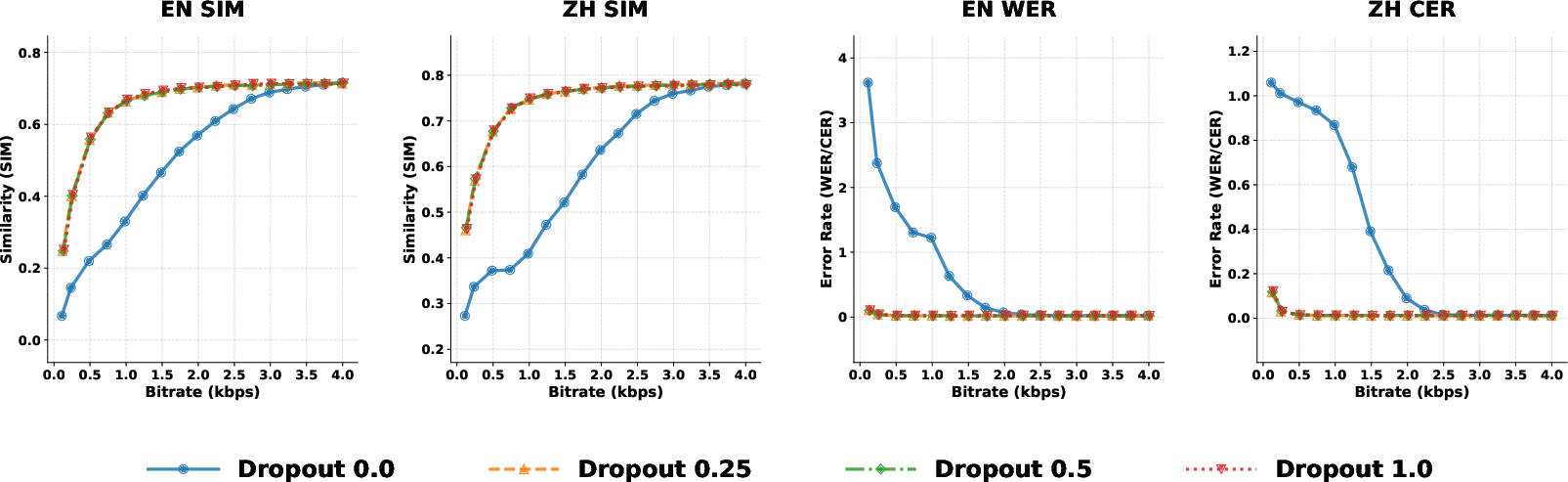
- Variable bitrate: You can choose how many RVQ layers to use. Fewer layers = smaller files and faster generation; more layers = higher quality.
- Quantizer dropout: During training, the model sometimes practices with fewer layers, so it stays strong even when you reduce detail later.
Making tokens useful for meaning and sound
- Reconstruction loss: The model learns to rebuild audio so it sounds very close to the original (like training your ears to notice detailed differences).
- Adversarial training: A “critic” network judges if the audio sounds real; the generator learns to impress it. This sharpens sound quality.
- Semantic alignment via audio-to-text: The tokenizer feeds its representations to a small LLM that predicts captions or transcripts (ASR). This helps the tokens carry meaning (not just sound), which is handy for tasks like speech understanding.
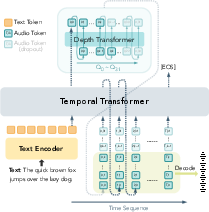
Bitrate-controllable speech generation (CAT-TTS)
- Autoregressive generation: The TTS model predicts tokens step-by-step, like writing a sentence one word at a time.
- Two Transformers:
- Temporal Transformer models time (how sounds change over moments).
- Depth Transformer models RVQ layers (from coarse to fine detail).
- Progressive Sequence Dropout: During training, the TTS model sometimes uses only the first few RVQ layers. This teaches it to speak well at different bitrates, so you can dial in quality vs. speed at inference time.
Main findings and why they matter
- High-quality reconstruction across speech, sound, and music: MOSS-Audio-Tokenizer beats previous open-source codecs at many bitrates and keeps getting better as you increase bitrate and model size.
- First fully autoregressive TTS that outperforms strong non-autoregressive and multi-stage systems: It achieves very low word error rates (few mistakes in the spoken words) and high speaker similarity (it sounds like the target voice), in English and Chinese.
- Competitive ASR without extra encoders: You can build speech recognition directly from its tokens, simplifying the system.
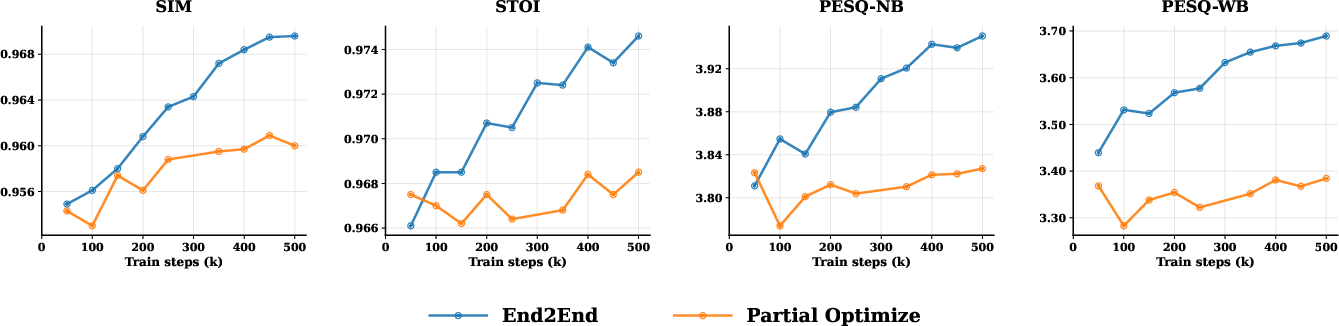
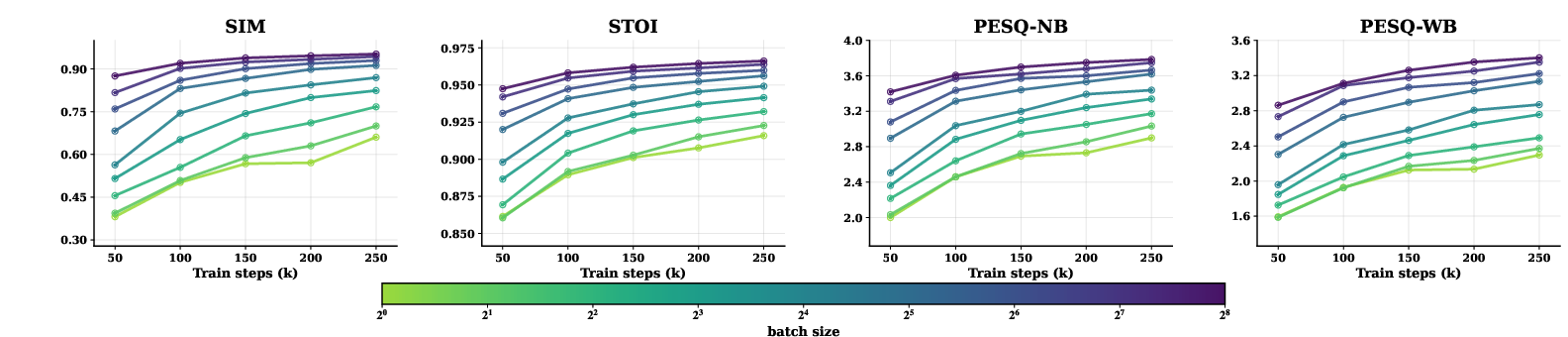
- Predictable scaling: The model gets steadily better when you:
- Train end-to-end (instead of freezing parts),
- Increase model size,
- Increase training batch size.
- This is important because it means more data or compute gives reliable gains—just like with big text models.
- Streaming and low latency: Because it’s causal and runs at a low frame rate (12.5 frames per second), it’s practical for real-time applications.
What this means for the future
- A unified “audio interface” for AI: Just like text tokenizers made LLMs powerful and simple, this audio tokenizer could become the standard way future audio AIs understand and generate sound.
- Easier, more scalable systems: Using only Transformers and end-to-end training removes complexity, making it simpler to build and grow audio foundation models.
- Flexible quality and speed: Variable bitrate lets apps pick between faster, lighter generation or richer, higher-quality sound—useful for phones, streaming, and games.
- Better multimodal AI: Strong, semantically rich audio tokens help connect sound with language and vision, paving the way for truly native audio-LLMs.
In short, this paper shows that a simple, Transformer-based, end-to-end tokenizer trained at scale can be the backbone for next-generation audio models—making them higher-quality, easier to build, and more powerful across many audio tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps that remain unresolved and could guide follow-up research.
- Data transparency and contamination: The 3M-hour corpus is not described (domain/language breakdown, licenses, overlap with evaluation sets), leaving uncertainty about data bias, contamination, and reproducibility.
- Language coverage and generalization: Results focus largely on English and Chinese; performance across low-resource languages, code-switching, diverse accents, and phonotactics remains untested.
- Domain breadth: “General audio” is evaluated on AudioSet/MUSDB subsets; robustness across rare sound events, extreme dynamics (e.g., percussive transients, ultrasound-like content), and atypical acoustic scenes is not assessed.
- Sampling rate and multichannel support: The model targets 24 kHz mono; behavior at 16/44.1/48 kHz and for stereo/ambisonics/spatial audio is unreported.
- Latency and throughput: No end-to-end measurements (encoder/decoder/TTS) of real-time factor, streaming latency in ms, and throughput on commodity/edge hardware are provided or compared to CNN/hybrid codecs.
- Compute and energy footprint: Training and inference cost (FLOPs, GPU-days, power) for the 1.6B tokenizer and CAT-TTS are not reported; trade-offs vs. smaller variants are unclear.
- Objective vs. subjective fidelity: Music/sound evaluations rely mostly on objective metrics (e.g., Mel-Loss, STFT distance); comprehensive listening tests (MUSHRA, ABX, MOS) with statistical significance across domains are missing.
- Temporal resolution at 12.5 Hz: The impact of the very low frame rate on fine timing (phoneme alignment, onsets, beat tracking, lip-sync alignment) is not measured; minimum viable frame rate for various tasks is unknown.
- Causality-induced delay: Exact encoder/decoder receptive fields, buffering, and latency introduced by patchify/downsampling are unspecified, limiting understanding of streaming constraints.
- Offline vs. streaming trade-offs: No ablation quantifies how strict causality affects peak quality compared to limited lookahead or non-causal variants.
- RVQ design specifics: Codebook sizes per layer, token vocabulary cardinalities, and bitrate mapping are not disclosed, hindering reproducibility and LM integration planning.
- Codebook health: There is no analysis of codebook utilization, perplexity, dead codes, or collapse dynamics across layers and training scales.
- Layer-wise semantics: Which RVQ layers capture semantics vs. fine acoustics remains unprobed; layer-probing or mutual-information analyses could validate claims of “semantically rich” tokens.
- Stability under adversarial training: Training stability, failure modes, and sensitivity to adversarial/discriminator settings are not characterized, especially at billion-parameter scale.
- Scaling laws: Although scaling trends are shown, formal scaling-law fits (e.g., compute–quality exponents, parameter–quantizer co-scaling rules) and compute-optimal frontiers are not provided.
- Semantic supervision ablations: The necessity and weight of the audio-to-text objective (and the attached 0.5B LLM) are not ablated; it is unclear how much semantic supervision is needed for gains without hurting reconstruction.
- ASR results and breadth: Claims of “competitive ASR without auxiliary encoders” are delegated to the appendix; explicit WER/CER across multi-domain/multi-language testbeds and latency analyses are absent from the main text.
- Downstream breadth beyond ASR/TTS: The utility of tokens for speaker verification/diarization, emotion/prosody recognition, sound event detection, and separation/enhancement is untested.
- Integration with multimodal LLMs: No demonstrations of instruction-following, audio QA, or multimodal reasoning using CAT tokens as a unified interface with large LLMs.
- TTS speed–quality–bitrate trade-offs: CAT-TTS lacks detailed inference-time benchmarks (RTF, GPU memory) across bitrates and utterance lengths; comparisons to NAR systems on latency are missing.
- TTS expressivity and controllability: Prosodic metrics (F0/duration RMSE), style control, long-form stability, and emotion/style transfer fidelity are not evaluated; multilingual TTS beyond EN/ZH is untested.
- Variable bitrate control policies: While Progressive Sequence Dropout enables control via RVQ depth, no method exists for content-adaptive bitrate selection or quality prediction to meet latency/bandwidth constraints.
- Error resilience: Robustness to token corruption, packet loss, or bit errors at different RVQ depths (important for streaming/communication use) is not evaluated.
- Robustness to noise and channel mismatch: Behavior under heavy noise, reverberation, clipping, far-field microphones, and sample-rate mismatches is unreported.
- Bias and fairness: No analysis of demographic, accent, or language bias in reconstruction, ASR, or TTS; fairness evaluations and mitigations are absent.
- Privacy and memorization: Risks of training-set memorization and privacy leakage (e.g., membership inference) for a 3M-hour corpus are not assessed.
- Copyright and data governance: The legal status of training data (copyrighted music/speech), licensing, and opt-out mechanisms are not discussed.
- Comparison parity: Cross-model comparisons may differ in sampling rates, training data scale, and discriminator setups; rigorous apples-to-apples evaluations are limited.
- Patchify design ablations: The choice and schedule of hierarchical patching (sizes, depths) and its effect on latency and fidelity are not examined.
- Quantizer–model co-scaling: Although co-dependence is noted, practical rules for jointly scaling quantizer depth, codebook size, and model parameters to avoid bottlenecks are not provided.
- Domain adaptation: Procedures for efficient fine-tuning to new domains (e.g., telephony, medical audio, new languages) or for low-resource specialization are not explored.
- Edge deployment: Quantization, pruning, or distillation strategies for on-device/low-power deployment are not presented.
- Security and watermarking: The feasibility of watermarking, content authentication, or forgery detection with CAT tokens is not discussed.
Practical Applications
Immediate Applications
The following are deployable now with the released code/model and standard engineering effort. They leverage CAT’s causal, streaming, Transformer-only tokenizer, discrete RVQ tokens at 12.5 Hz, variable bitrate (0.125–4 kbps), strong reconstruction across speech/sound/music, competitive ASR without auxiliary encoders, and the CAT-TTS recipe with Progressive Sequence Dropout.
- Low-bitrate, streaming audio codec for real-time communications
- Sector: software, telecommunications, gaming, enterprise collaboration, IoT
- Use cases:
- WebRTC/VoIP plugins to cut voice bandwidth to 0.75–2 kbps while preserving intelligibility and speaker identity
- In-game voice chat with adaptive quality under variable network conditions
- Low-bandwidth uplinks for remote sensors and smart-home microphones
- Tools/products/workflows:
- Integrate MOSS-Audio-Tokenizer encoder/decoder as a transport codec in conferencing stacks (e.g., as an ffmpeg/WebRTC module)
- Use variable RVQ depth to adapt bitrate to network load in real time
- Assumptions/dependencies:
- GPU/accelerator preferred for 1.6B model at scale; smaller/distilled variants may be needed for edge devices
- Latency is frame-level and causal, but deployment must validate end-to-end latency budgets and jitter buffering
- Storage-efficient audio datasets and archives with controllable fidelity
- Sector: media platforms, academia, digital archives, ML ops
- Use cases:
- Compress speech/music/sound corpora to 0.75–4 kbps tokens for long-term storage and fast streaming retrieval
- Dataset curation pipelines that gate bitrate by content importance (e.g., higher bitrate for vocals, lower for silence)
- Tools/products/workflows:
- Batch conversion: WAV/FLAC → CAT tokens (RVQ) with per-segment bitrate selection; reconstruct on demand
- Token-native dataloaders for training generative models directly from discrete tokens
- Assumptions/dependencies:
- Compute/storage trade-offs must be profiled; decoding adds inference cost
- Rights management and compliance with archival standards remain required
- Fully autoregressive TTS for IVR, agents, and content creation
- Sector: customer support, education, media, assistive tech
- Use cases:
- IVR and contact-center bots with high speaker similarity at lower bitrates; latency-quality tuning via RVQ depth
- Audiobook and e-learning content generation with consistent timbre and prosody
- Tools/products/workflows:
- Implement CAT-TTS (Temporal Transformer + Depth Transformer) and train with Progressive Sequence Dropout
- Provide a “quality knob” (RVQ depth K) at inference; integrate speaker prompts for zero-shot voice
- Assumptions/dependencies:
- Training CAT-TTS requires substantial data and compute; production may prefer fine-tuning released checkpoints
- Licensing for base LLMs (e.g., Qwen3-1.7B) and speaker data must be verified
- Simplified LLM-based ASR without dedicated encoders
- Sector: software, finance (contact centers), healthcare (dictation), education
- Use cases:
- Embed CAT tokens into a compact LLM for competitive ASR on device or server without a separate audio encoder
- Rapid prototyping of voice-enabled apps by swapping mel-spectrogram front ends for discrete tokens
- Tools/products/workflows:
- Feed quantizer outputs to a 0.5B–2B decoder-only LLM for ASR; fine-tune on target language/domain
- Optional multi-task training for captioning or speaker diarization tags
- Assumptions/dependencies:
- Performance varies by language/domain; fine-tuning on in-domain data is recommended
- For strict on-device deployments, model compression/quantization is needed
- Bandwidth-aware, privacy-conscious audio telemetry for IoT/edge
- Sector: industrial monitoring, smart cities, environmental sensing
- Use cases:
- Stream discrete tokens from microphones to the cloud for event detection and incident triage
- Adaptive bitrate to save power and data costs, raising quality only during detected events
- Tools/products/workflows:
- On-device causal encoder with token streaming; server-side decoding/analytics
- Assumptions/dependencies:
- Tokens are reconstructible and can preserve speaker identity; rely on transport encryption and access control
- Edge constraints require lighter variants or hardware acceleration
- Rapid research and prototyping: replacing mel pipelines with discrete tokens
- Sector: academia, R&D, startups
- Use cases:
- Swap mel-spectrogram front ends with CAT tokens in generative/understanding models to align with Transformer LMs
- Run scaling studies and ablations on batch size/parameters using a homogeneous architecture
- Tools/products/workflows:
- Use Hugging Face model for tokenization; feed tokens to existing GPT-style models
- Assumptions/dependencies:
- Results at 24 kHz and 12.5 Hz frame rate; other sample rates may need adaptation
- Interactive media and gaming: on-the-fly voice and SFX generation
- Sector: gaming, creative tools
- Use cases:
- NPC dialog with consistent persona and dynamic emotion; bitrate-tunable to meet frame time budgets
- Token-level SFX prototyping where generation and playback latency is tightly controlled
- Tools/products/workflows:
- Integrate CAT-TTS into asset pipelines; expose a runtime “quality/latency slider” via RVQ depth
- Assumptions/dependencies:
- Content moderation and IP policies for voices must be enforced; GPU budget and latency must be profiled
- Accessibility: high-fidelity screen readers and speech prostheses
- Sector: healthcare, public sector, education
- Use cases:
- Personalized voices for screen readers with better speaker similarity and clarity at low bitrates
- Voice prosthesis for users with speech impairments using speaker-prompted TTS
- Tools/products/workflows:
- Deploy CAT-TTS with user voice prompts; adjust bitrate for device capability
- Assumptions/dependencies:
- On-device deployment may need distilled models; clinical settings require safety validation and user consent
Long-Term Applications
These applications require further research, scaling, model compression, standardization, or broader data coverage (e.g., more languages, 48 kHz/multichannel, privacy safeguards).
- Unified native audio foundation models
- Sector: software, robotics, consumer AI
- Use cases:
- One model that understands and generates speech, music, and environmental sounds using the same discrete token interface
- Tools/products/workflows:
- Train larger AR models on CAT tokens with multi-task objectives (ASR, captioning, TTS, sound event detection)
- Assumptions/dependencies:
- Significant compute and diverse multimodal data; careful co-scaling of parameters and quantization capacity
- Real-time speech-to-speech translation in a single autoregressive stack
- Sector: telecommunications, media, education
- Use cases:
- Live bilingual conversations with controllable latency and bitrate; consistent speaker style transfer
- Tools/products/workflows:
- Joint training on speech-text parallel corpora with CAT tokens; shared text/audio token space
- Assumptions/dependencies:
- High-quality parallel data; latency control across encode→translate→synthesize; ethical use guidelines
- Standards for discrete audio token streaming and interoperability
- Sector: policy, standards bodies, telecom
- Use cases:
- MPEG-/IETF-style standards for token formats, framing, error resilience, and security
- Tools/products/workflows:
- Reference implementations, test vectors, and compliance suites for token codecs
- Assumptions/dependencies:
- Broad industry consensus; balancing openness with IP protection and model updates
- Privacy-preserving audio analytics on tokens
- Sector: public sector, enterprise IT, compliance
- Use cases:
- Perform analytics on tokens while limiting access to reconstructible waveforms; selective disclosure for audits
- Tools/products/workflows:
- Token-space detectors for PII, toxicity, or copyright; policies to keep raw audio off-storage
- Assumptions/dependencies:
- Current tokens are reconstructible and preserve identity; research into irreversible or obfuscated tokenizations is needed
- On-device assistants and wearables with distilled CAT variants
- Sector: consumer devices, automotive, AR/VR
- Use cases:
- Always-on wake-word, command understanding, and high-quality TTS with sub-watt power budgets
- Tools/products/workflows:
- Distillation/quantization/pruning of CAT and CAT-TTS; NPU/DSP kernels; mixed-precision inference
- Assumptions/dependencies:
- Aggressive compression without significant quality loss; real-time constraints for 24 kHz audio
- Medical and telehealth-grade audio channels and documentation
- Sector: healthcare
- Use cases:
- Low-bitrate, secure teleconsultations; high-accuracy ASR for clinical notes; patient-specific TTS for accessibility
- Tools/products/workflows:
- End-to-end encrypted token transport; HIPAA-compliant logging; domain fine-tuning
- Assumptions/dependencies:
- Regulatory certification, bias testing across patient populations, clinical validation
- Advanced creative tooling: token-native DAWs and structure-aware editing
- Sector: media, music tech
- Use cases:
- Edit music/speech at token level with semantic handles (phrases, instruments, timbre layers); version control in token space
- Tools/products/workflows:
- DAW plugins that decode/encode on the fly and show token tracks; AR models for inpainting/variation
- Assumptions/dependencies:
- Extensions to 48 kHz, multichannel, and spatial audio; UX design for token-level editing metaphors
- Robotics: unified auditory perception and dialogue
- Sector: robotics, manufacturing, service
- Use cases:
- Robots that perceive ambient sounds for situational awareness and interact via low-latency speech on the same token interface
- Tools/products/workflows:
- Train multimodal policies over CAT tokens; event detection + conversational control in one AR loop
- Assumptions/dependencies:
- Robustness to noise/echo; hard real-time requirements; safety and failover mechanisms
- Asset and network energy efficiency at scale
- Sector: cloud/edge infrastructure, energy
- Use cases:
- Reduce backbone bandwidth and storage for massive voice workloads; data-center optimization via token-native pipelines
- Tools/products/workflows:
- Token-based streaming and caching layers; autoscaling by target bitrate
- Assumptions/dependencies:
- Whole-pipeline profiling to ensure compute overhead doesn’t offset bandwidth savings
- Content governance: token-space copyright and deepfake detection
- Sector: policy, platforms, legal
- Use cases:
- Detect copyrighted material or synthetic speech using classifiers trained on discrete tokens
- Tools/products/workflows:
- Token-level fingerprinting and classifiers; audit logs for provenance
- Assumptions/dependencies:
- Classifier robustness across bitrates and domains; evolving adversarial threats require continual updates
Cross-Cutting Dependencies and Considerations
- Compute and deployment: The 1.6B tokenizer is heavy for edge; production often needs distillation, quantization, or smaller variants.
- Latency: Although causal/streaming, real-world E2E latency depends on audio chunk size, buffering, and network; validate against application budgets.
- Audio domains and sample rates: Current results focus on 24 kHz mono; 48 kHz, multichannel, and spatial audio will require extensions.
- Language and fairness: Benchmarks cover primarily English/Chinese; low-resource languages and accents need additional training/evaluation.
- Privacy and security: Tokens are reconstructible and preserve speaker identity; strong encryption, access control, and consent are mandatory.
- Licensing and data: Ensure model and training data licenses fit the intended commercial/clinical use; verify third-party LLM licenses in the stack.
- Safety and misuse: High-fidelity voice cloning requires guardrails (watermarking, consent checks, deepfake detection) in deployment workflows.
Glossary
- Adversarial training: A training setup that uses a discriminator to encourage more realistic outputs via adversarial objectives. "we employ adversarial training with multiple discriminators."
- Audio captioning: The task of generating descriptive text for an audio clip. "including automatic speech recognition (ASR), multi-speaker ASR, and audio captioning."
- Autoregressive modeling: Sequence modeling where each output token is predicted conditioned on previously generated tokens. "we adopt the Temporal Transformer + Depth Transformer architecture for multi-stream autoregressive modeling."
- Automatic Speech Recognition (ASR): Converting spoken audio into text using machine learning models. "including automatic speech recognition (ASR), multi-speaker ASR, and audio captioning."
- Bernoulli random variable: A binary random variable that takes value 1 with probability p and 0 otherwise. "We introduce a Bernoulli random variable"
- Bitrate: The rate of information output measured in bits per second, determining compression level and quality. "The model natively supports variable bitrates ranging from 0.125\,kbps to 4\,kbps"
- Causal attention mask: An attention mechanism that prevents access to future positions, ensuring strict left-to-right conditioning. "using a causal attention mask along the temporal dimension."
- Causal Transformer: Transformer blocks constrained so that each position attends only to past (and current) positions, enabling streaming and AR compatibility. "Both the encoder and decoder are built entirely from causal Transformer blocks"
- Causality: The property that each token or output is computed without using future context. "tokenization should be strictly causal"
- Codebook: A learned set of vectors used in vector quantization to discretize continuous representations. "codebooks are directly optimized via gradient descent"
- Codebook loss: A loss that encourages codebook entries to match encoded representations for stable quantization. "We incorporate a commitment loss and a codebook loss"
- Commitment loss: A loss that penalizes deviation between encoder outputs and their quantized counterparts, encouraging encoder consistency. "We incorporate a commitment loss and a codebook loss"
- Decoder-only LLM: A LLM comprised solely of autoregressive decoder layers (no encoder), predicting tokens left-to-right. "we employ a 0.5B-parameter decoder-only LLM"
- Depth Transformer: A Transformer that models dependencies across quantization layers (depth) within each time step. "we adopt the Temporal Transformer + Depth Transformer architecture"
- Diffusion-based refinement: Using diffusion models to iteratively improve or denoise generated outputs. "diffusion-based refinement"
- Discrete audio tokenizer: A model that converts continuous audio into sequences of discrete tokens suitable for sequence modeling. "Discrete audio tokenizers are fundamental to empowering LLMs with native audio processing and generation capabilities."
- Discriminator: A network trained to distinguish real from generated signals, providing adversarial feedback to improve generator quality. "including the encoder, quantizer, decoder, causal LLM, and discriminator"
- End-to-end optimization: Jointly training all components of a system under a unified objective rather than in stages. "optimized jointly in an end-to-end manner."
- Factorized vector quantization: A quantization scheme that factorizes codes to simplify training and stabilize codebook learning. "each quantization layer in CAT adopts factorized vector quantization"
- Feature matching loss: A loss that aligns intermediate features of real and generated signals to stabilize adversarial training. "including the adversarial loss, feature matching loss and discriminator loss"
- Frame rate: The frequency (in Hz) at which tokens are produced per second from audio. "a low token frame rate of 12.5\,Hz"
- Hierarchical quantization structure: A multi-layer quantization scheme where coarse tokens are refined by successive residual layers. "utilizing the tokenizer's hierarchical quantization structure."
- Inductive bias: Built-in architectural assumptions that guide learning toward certain functions or structures. "These designs introduce fixed inductive biases"
- Knowledge distillation: Transferring knowledge from a teacher model to a student via alignment objectives. "align the encoder and quantizer representations with self-supervised speech models through distillation objectives."
- Mel-spectrogram: A time–frequency representation using the mel scale, commonly used in speech/audio modeling. "we adopt a multi-scale mel-spectrogram loss"
- Multi-scale STFT (MS-STFT) discriminator: A discriminator that evaluates audio at multiple STFT window sizes/hops to capture structures at different scales. "incorporating a multi-scale STFT (MS-STFT) discriminator"
- Multi-task learning: Training a model on multiple objectives/tasks simultaneously to improve generalization and representation quality. "We use multi-task learning to enable CAT to achieve both strong alignment with text and high-quality audio reconstruction."
- Non-autoregressive (NAR): Models that predict outputs in parallel rather than sequentially, reducing latency but changing dependencies. "outperform prior non-autoregressive and cascaded approaches"
- Patchify operations: Converting a continuous signal into fixed-size patches/vectors for Transformer processing and hierarchical compression. "we insert patchify operations between Transformer blocks"
- Perceptual Evaluation of Speech Quality (PESQ): An objective speech quality metric correlating with human perception. "speech metrics (SIM, STOI, and PESQ)"
- Progressive Sequence Dropout: A training strategy that randomly truncates RVQ depth to make generation robust across bitrates. "we propose Progressive Sequence Dropout"
- Quantizer dropout: Randomly disabling some quantization layers during training to enable variable-bitrate robustness. "enable quantizer dropout during training."
- Residual vector quantization (RVQ): A quantization method where residuals are progressively quantized by multiple codebooks/layers. "we employ residual vector quantization (RVQ)."
- RVQGAN: A framework combining residual vector quantization with GAN-based training for high-fidelity audio reconstruction. "Most existing methods adopt an RVQGAN-style framework"
- Short-Time Fourier Transform (STFT): A time–frequency transform computed over short windows to analyze non-stationary signals. "short-time Fourier transform (STFT)"
- Short-Time Objective Intelligibility (STOI): An objective measure of speech intelligibility based on short-time analysis. "speech metrics (SIM, STOI, and PESQ)"
- Speaker similarity (SIM): A metric that evaluates how closely generated speech matches a target speaker’s identity. "speaker similarity (SIM)"
- Stop-gradient operator: An operation that prevents gradients from flowing through certain tensors during backpropagation. "denotes the stop-gradient operator"
- Streaming encoding and decoding: Processing that emits tokens and reconstructions incrementally with low latency, suitable for real-time use. "enabling streaming encoding and decoding."
- Temporal Transformer: A Transformer modeling dependencies along the time dimension of token sequences. "The Temporal Transformer captures long-range dependencies along the temporal dimension"
- Text-to-Speech (TTS): Generating spoken audio from textual input. "purely autoregressive TTS model"
- Variable-bitrate: The ability to operate across different token depths/bit budgets to trade off quality and efficiency. "variable-bitrate speech generation"
- Word Error Rate (WER): An ASR metric measuring transcription errors as a percentage of words. "exhibiting low word error rate"
Collections
Sign up for free to add this paper to one or more collections.