- The paper demonstrates that intervening in the first few chain-of-thought steps reduces jailbreak attack success rates by 30–60%.
- It employs a lightweight auxiliary safety reward model that injects corrective prefixes with minimal divergence from the base policy.
- Empirical evaluations across multiple benchmarks confirm that SafeThink recovers safety without costly retraining and maintains reasoning accuracy.
Safety Recovery in Multimodal Reasoning Models via Early Inference-Time Steering
Motivation and Problem Context
Recent progress in multimodal large reasoning models (MLRMs) has been largely driven by explicit chain-of-thought (CoT) reasoning and reinforcement-learning (RL) based post-training. These advances have enabled state-of-the-art models to achieve high performance on challenging multimodal tasks. However, empirical evidence demonstrates that RL-driven reasoning-centric post-training substantially degrades safety alignment, as indicated by substantial increases in jailbreak attack success rates (ASR), especially under adversarial prompting and vision-language fusion scenarios.
The central question addressed is: Can safety be recovered in high-reasoning MLRMs without sacrificing post-training performance gains? Prior inference-time defenses—such as input-based refusal, safety prompting, and output truncation—pose undesirable trade-offs: brittle safety under attack and/or loss of reasoning utility.
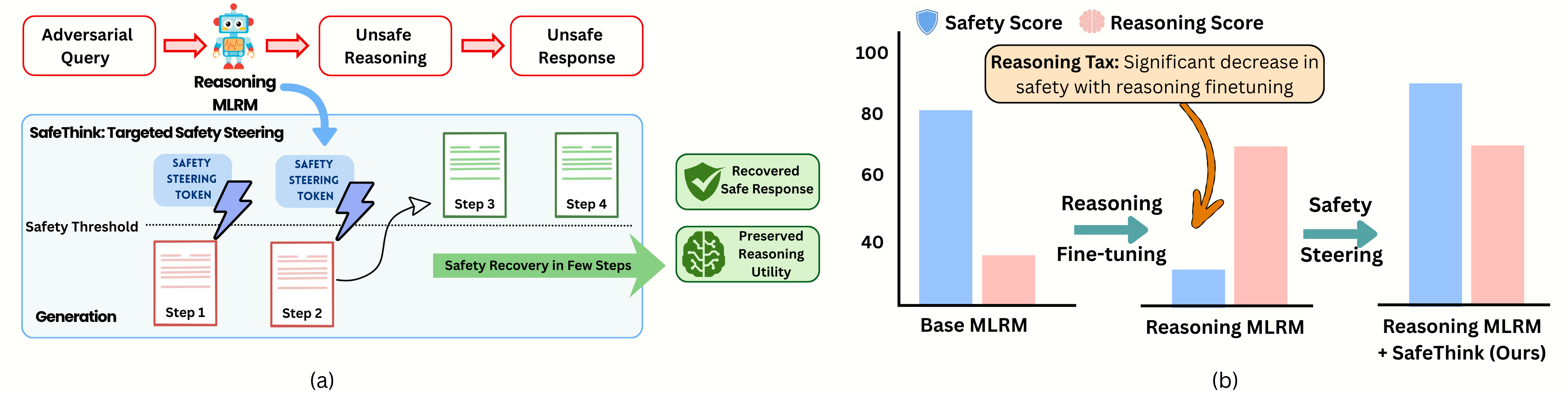
Figure 1: SafeThink enables intervention at the earliest evidence of unsafe reasoning, typically within the first few chain-of-thought steps, thereby redirecting generation toward safe yet effective completions.
Satisficing as Safety Alignment Principle
Rather than pursuing the maximization of safety objectives—which fosters undesirable conservatism and impedes task performance—the paper frames safety alignment as a satisficing constraint: ensure that model generations reliably exceed a predefined safety threshold, and enforce this threshold efficiently at inference time.
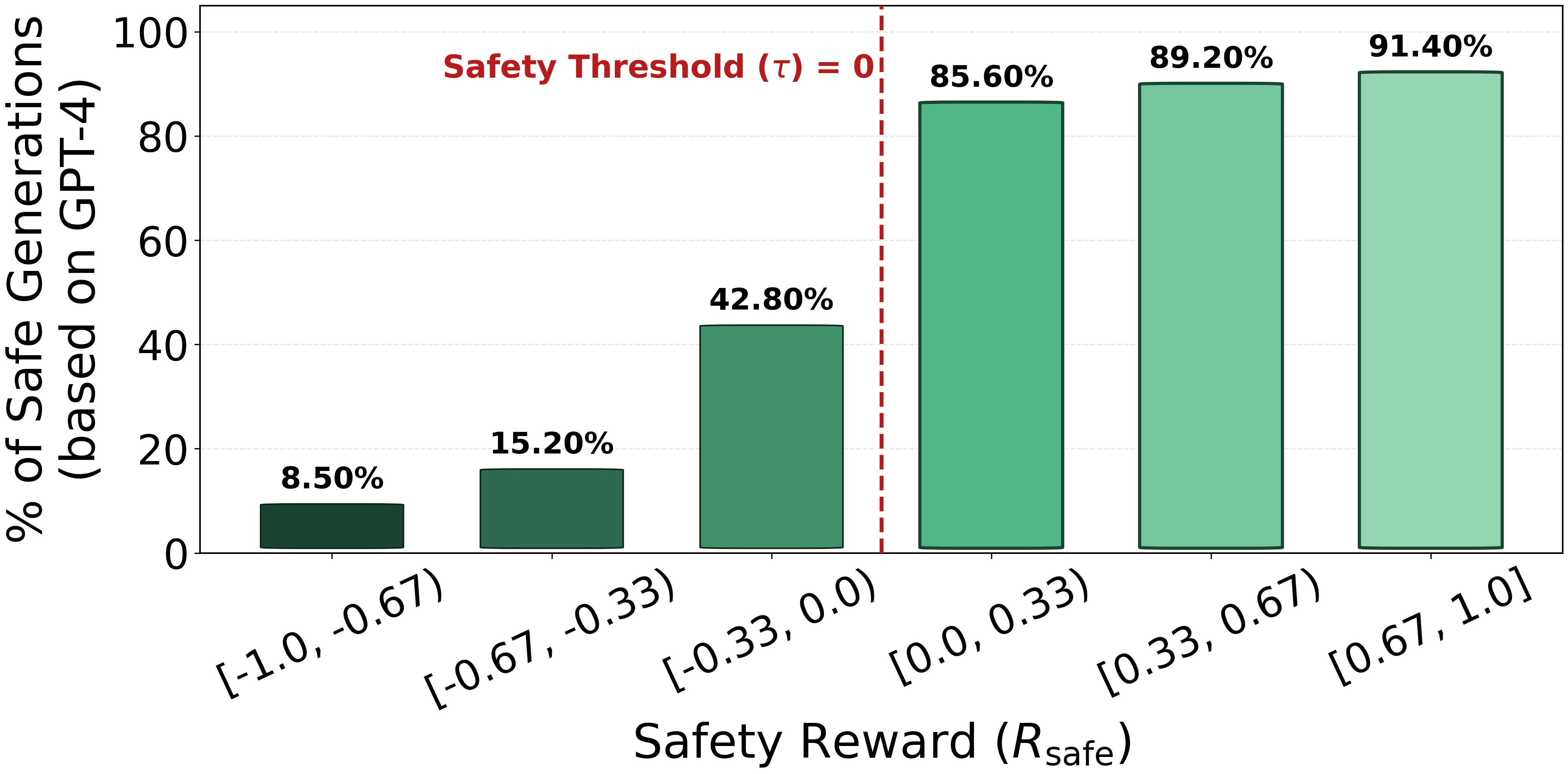
Figure 2: Safety rates, as assessed by GPT-4, saturate above the threshold τ=0, empirically validating the threshold-based constraint Rsafe≥τ for functional safety alignment.
This perspective aligns with bounded rationality and avoids further erosion in reasoning capability beyond the safety threshold.
SafeThink: Lightweight Inference-Time Early Steering
Conditional Trace Monitoring and Steering
SafeThink continuously monitors the model reasoning trace at inference time via an auxiliary safety reward model. When the safety score of an intermediate reasoning step drops below threshold τ, the system conditionally injects a short corrective prefix—a learned safety steering token, e.g., “Wait, think safely.” This locally reconditions the next-step distribution, increasing coverage of safe continuations with minimal KL divergence from the base policy.
Figure 3: Tokens with explicit safety cues (“Wait, think safely”) uniquely achieve high safety reward with low KL divergence, ensuring safety steering minimally disturbs base policy trajectory.
Early Step Sufficiency
Evaluations demonstrate a sharp phase transition: intervening in only the first 1–3 reasoning steps suffices to redirect nearly all unsafe trajectories toward safety, with diminishing returns from deeper or persistent intervention. This finding holds across six open-source MLRMs and four multimodal jailbreak benchmarks.
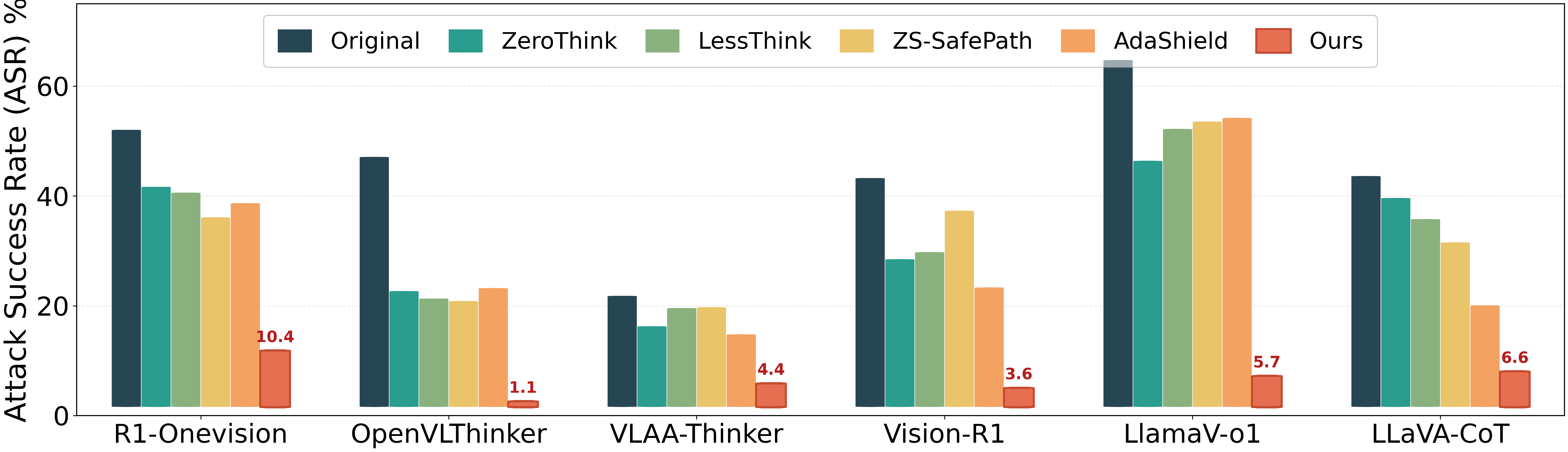
Figure 4: Attack Success Rate (ASR) drops sharply under SafeThink, outperforming baselines by 30–60\% absolute, on JailbreakV-28K.
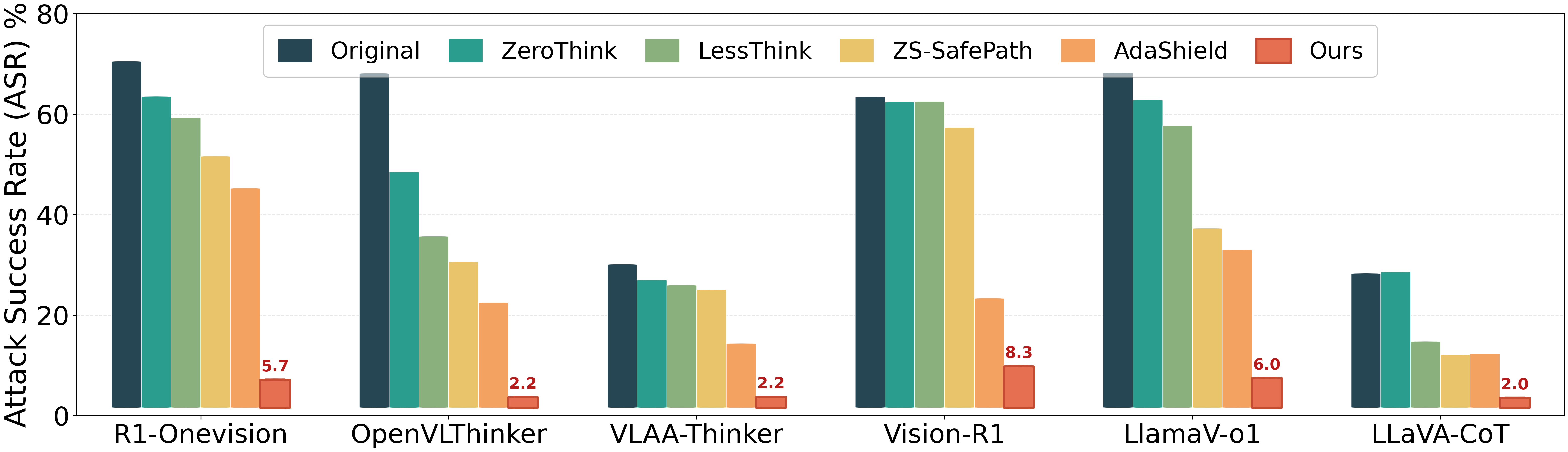
Figure 5: SafeThink dominates on image-based HADES attacks, reducing ASR from 69.1% to 5.7% on R1-Onevision, while baselines remain substantially higher.
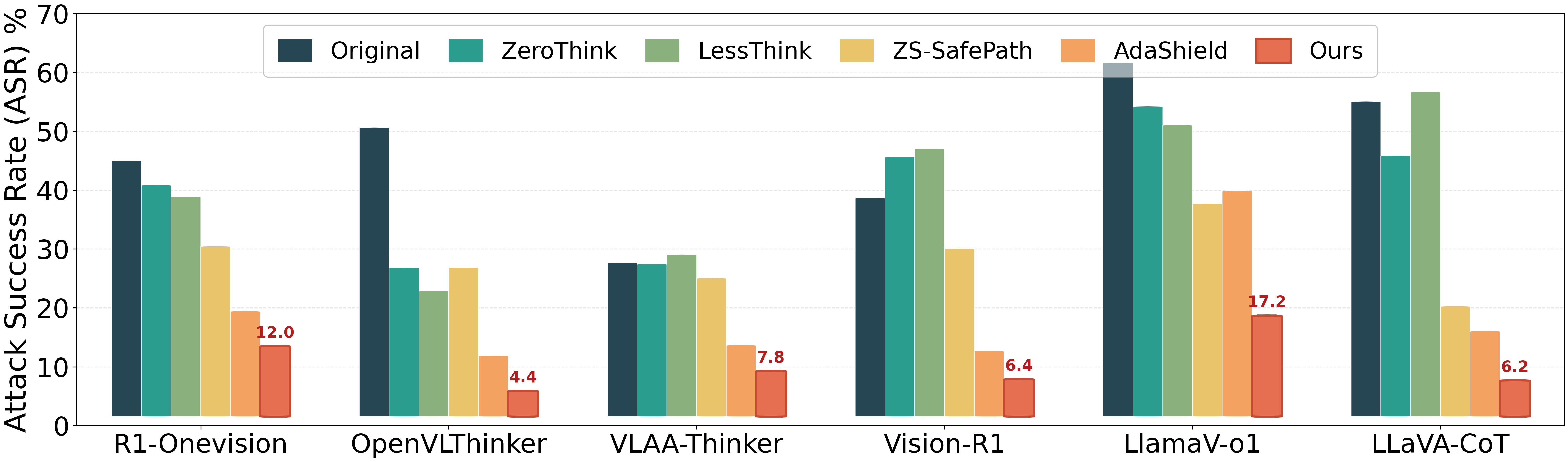
Figure 6: Consistent safety recovery on FigStep visual-typographic attacks: SafeThink achieves the lowest ASR across all MLRMs, e.g., 44.8% absolute reduction for OpenVLThinker.
Empirical Analysis and Robustness
Evaluation Protocol
Across diverse benchmarks (JailbreakV-28K, HADES, FigStep, MM-SafetyBench) and models (R1-Onevision, OpenVLThinker, VLAA-Thinker, Vision-R1, LlamaV-o1, LLaVA-CoT), SafeThink is evaluated against leading inference-time baseline defenses: ZeroThink, LessThink, ZS-SafePath, and AdaShield. Oracle safety evaluators (Llama-Guard-3, Qwen-Guard-3) and human-in-the-loop (GPT-4) are used for robustness validation.
Main Results
SafeThink consistently achieves absolute ASR reductions of 30–60\% relative to undefended and baseline models. For instance, on JailbreakV-28K, LlamaV-o1 ASR falls from 63.33% to 5.74%; on HADES, R1-Onevision ASR drops from 69.07% to 5.65%; OpenVLThinker sees ASR decrease by 44.8% on FigStep. Crucially, MathVista reasoning accuracy is preserved within 0.2\% of the original model (Figure 7).
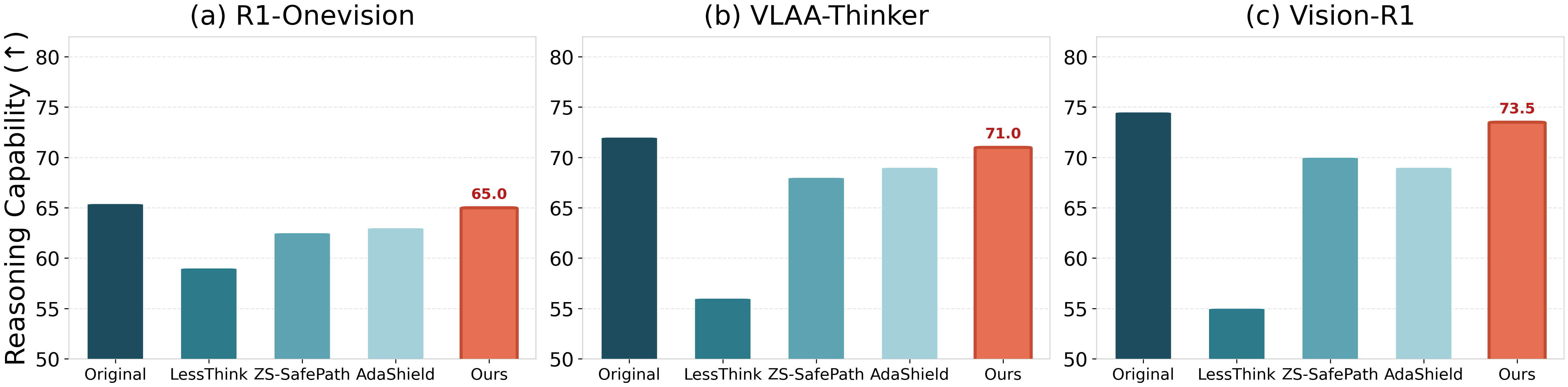
Figure 7: SafeThink preserves original model reasoning accuracy on MathVista, in contrast with truncated/overly conservative defenses.
Qualitative and Modal Robustness
Qualitative analysis verifies that SafeThink neutralizes both text and image-based jailbreaks, even on composite multimodal attacks and when the nature of the unsafe request is camouflaged (Figures 10, 15, 16).
Reward Model and Threshold Robustness
SafeThink's safety gains are robust to the specific choice of safety reward evaluator (Figures 12, 13) and to variations in the safety threshold τ (Figure 8).
Theoretical and Practical Implications
The central empirical finding—that safety recovery is typically "just a few early steering steps away"—imposes strong constraints on theories of failure modes in reasoning-centric RL for MLRMs. The existence of latent safe continuations under adversarial conditioning suggests conditional coverage failure, not permanent erasure of safety behavior. This validates the design of inference-time, locally-triggered, satisficing interventions as both effective and utility-preserving.
Practically, this approach enables post-hoc safety improvement without costly model retraining, aggressive truncation, or ad hoc global rejection. It aligns with policies for responsible deployment of advanced MLRMs in high-stakes domains, where both deep reasoning and robust safety are required.
Conclusion
This work provides compelling evidence that in MLRMs, loss of safety robustness caused by RL-based reasoning enhancement can be mitigated at inference time by lightweight, early-step steering interventions. By operationalizing satisficing safety as a thresholded constraint, and leveraging learned safety tokens, SafeThink achieves near-optimal trade-offs: it suppresses jailbreak ASR to single-digit rates, with essentially no loss in downstream multimodal reasoning performance. Early-step steering offers a domain-agnostic, scalable blueprint for safety recovery in CoT-driven multimodal reasoners.
Outlook
SafeThink introduces a robust, practical inference-time defense architecture for aligning advanced reasoning models. Future research should explore integration with more granular reward modeling, compositional safety-intervention policies, and application to tool-augmented or agentic multimodal systems, enabling safety-aware deliberate reasoning at real-world scale.