The Magic Correlations: Understanding Knowledge Transfer from Pretraining to Supervised Fine-Tuning
Abstract: Understanding how LLM capabilities transfer from pretraining to supervised fine-tuning (SFT) is fundamental to efficient model development and data curation. In this work, we investigate four core questions: RQ1. To what extent do accuracy and confidence rankings established during pretraining persist after SFT? RQ2. Which benchmarks serve as robust cross-stage predictors and which are unreliable? RQ3. How do transfer dynamics shift with model scale? RQ4. How well does model confidence align with accuracy, as a measure of calibration quality? Does this alignment pattern transfer across training stages? We address these questions through a suite of correlation protocols applied to accuracy and confidence metrics across diverse data mixtures and model scales. Our experiments reveal that transfer reliability varies dramatically across capability categories, benchmarks, and scales -- with accuracy and confidence exhibiting distinct, sometimes opposing, scaling dynamics. These findings shed light on the complex interplay between pretraining decisions and downstream outcomes, providing actionable guidance for benchmark selection, data curation, and efficient model development.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how skills in LLMs move from one training stage to the next. Think of building an LLM like training an athlete:
- Pretraining is like the athlete reading tons of books and doing general practice to learn about the world.
- Supervised fine-tuning (SFT) is like getting a coach who gives focused drills and instructions to make the athlete follow rules better and perform tasks as asked.
The main goal is to see whether how well a model does during pretraining (its “practice scores”) can predict how well it will do after SFT (its “game-day scores”). The paper also studies whether the model’s confidence (how sure it feels about its answers) stays meaningful across these stages.
Key Objectives and Questions
The paper asks four simple questions:
- Do models keep the same ranking from pretraining to SFT? In other words, if Mix A beats Mix B during pretraining, does Mix A still beat Mix B after SFT?
- Which tests (benchmarks) are good at predicting how a model will do after SFT—and which ones aren’t?
- What changes when models get bigger? Do the patterns of what transfers from pretraining to SFT stay the same?
- Does a model’s confidence match its correctness (called “calibration”)? And does that pattern carry over from pretraining to SFT?
How They Did It (Methods)
The researchers trained two sizes of LLMs:
- A smaller model with about 240 million parameters.
- A larger model with about 1 billion parameters.
“Parameters” are like knobs inside the model that get tuned during training—more parameters usually means a bigger, more capable model.
They trained these models on 9 different mixes of data, including:
- General web text (from sources like RefinedWeb, FineWeb-Edu, DCLM).
- Code (from datasets like StarCoder and The Stack v2).
- Curated knowledge (like Wikipedia, research papers, and Q&A sites).
After pretraining, they fine-tuned the models on a focused instruction dataset (Tulu-v2-mix), which helps the model follow directions and answer questions more reliably.
Then, they tested the models on 20 benchmarks grouped into four skill categories:
- Commonsense (e.g., HellaSwag, PIQA)
- Science (e.g., ARC, SciQ)
- Natural Language Inference (NLI) (e.g., MNLI, RTE)
- Semantic Understanding (e.g., QQP, WiC)
To understand what transfers from pretraining to SFT, they used correlations. A correlation is a number that tells you how much two things move together. Here, they looked at:
- Accuracy correlation: Do pretraining scores predict SFT scores?
- Confidence correlation: Do pretraining confidence patterns predict SFT confidence patterns?
- Intra-category coherence: Do tests within the same category (like all science tests) move together when you change the training data?
- Alignment (calibration): Within one model, do higher-confidence predictions tend to be the correct ones?
If “correlation” feels abstract, think of it like this: If every time a player practices well, they also perform well in the match, the practice-to-match correlation is high. If practice scores don’t match performance, the correlation is low or even negative.
Main Findings
Here are the most important takeaways, described plainly. Each point has a short explanation to help you understand why it matters.
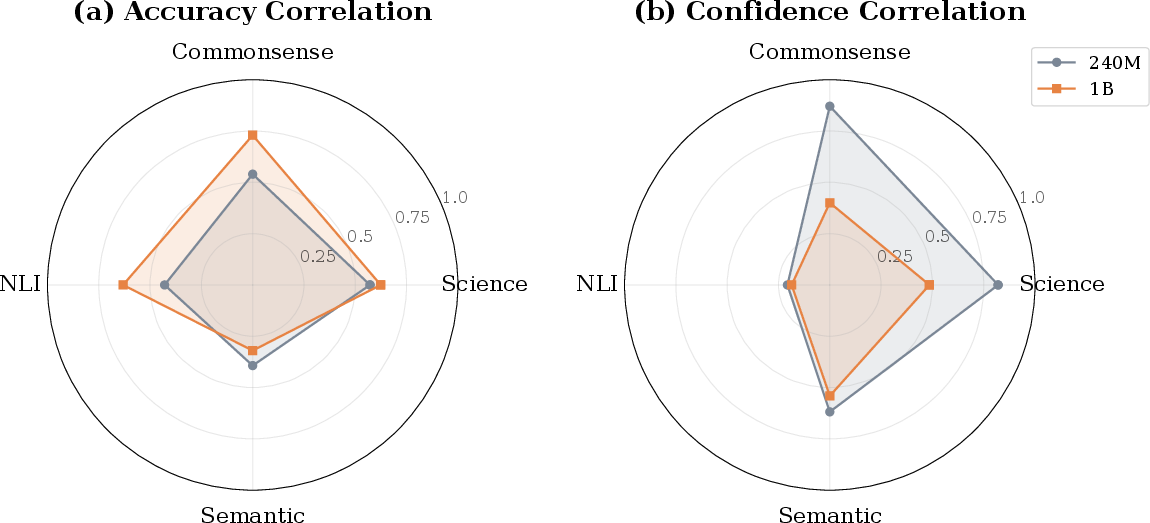
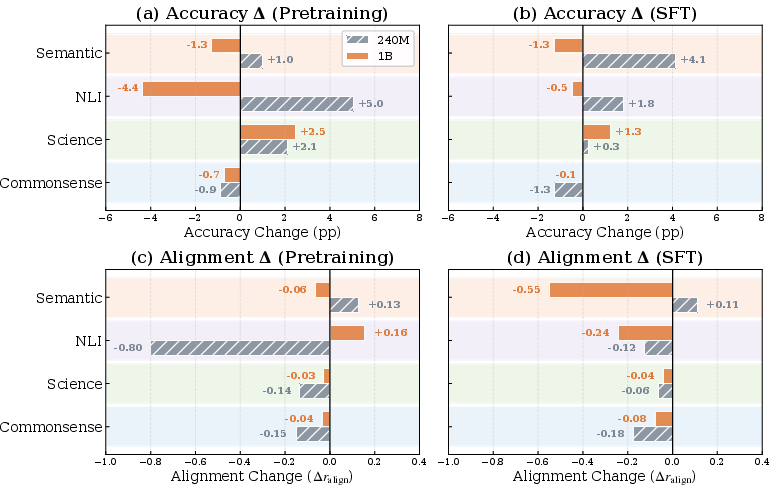
1) Bigger models keep accuracy patterns, smaller models keep confidence patterns
- Larger models (1B) are better at keeping their accuracy rankings from pretraining to SFT.
- Smaller models (240M) are better at keeping their confidence patterns from pretraining to SFT.
- Why this matters: Accuracy and confidence are different. Accuracy = being right. Confidence = feeling sure. Bigger models may change how they “feel” about answers during SFT, even if they stay good at being right.
2) Transfer depends on the type of skill
- Science and Commonsense tests are strong predictors. If a model does well in these during pretraining, it tends to do well after SFT too.
- NLI and Semantic tests are weaker predictors. Success before SFT doesn’t reliably predict success after.
- Why this matters: If you want to choose good early tests to judge models or data, pick Science and Commonsense. Be careful using NLI or Semantic tests for early decisions.
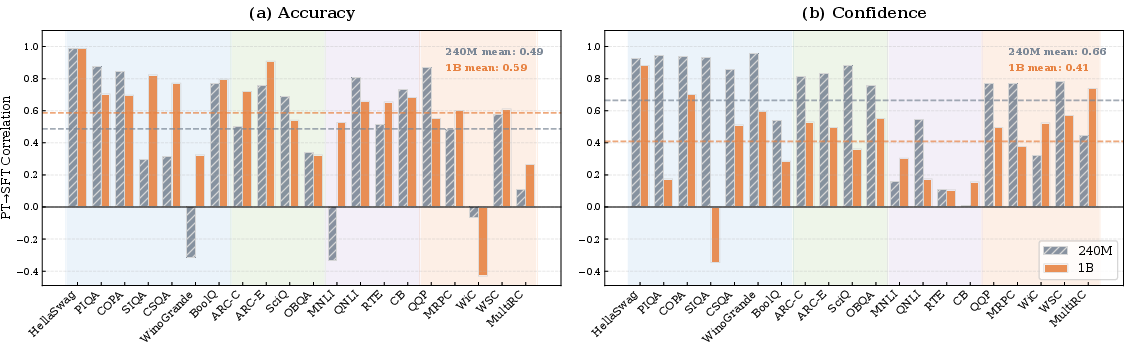
3) Some benchmarks are unreliable for early prediction
- WiC, MultiRC, WinoGrande, and MNLI often fail to predict post-SFT performance well.
- Why this matters: These tasks involve subtle language understanding that SFT seems to reorganize. Don’t lean on these as your main early indicators.
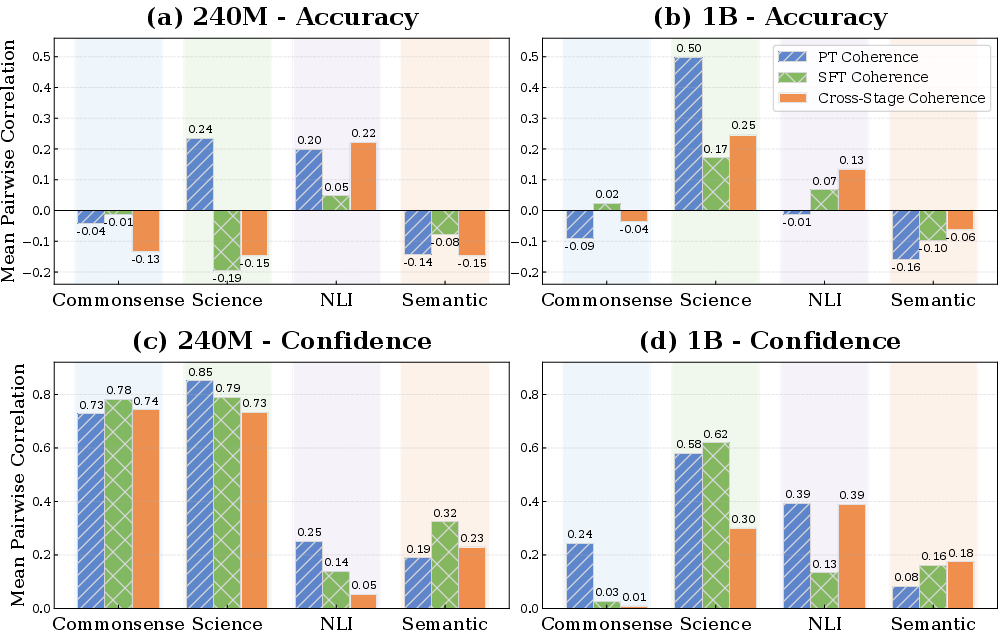
4) Inside-category behavior changes with scale
- In smaller models, benchmarks in the same category often “compete”: improving one can hurt another.
- In bigger models, that competition often flips to “synergy”: improving one can help others in the same category (especially in Science).
- Why this matters: For small models, tuning for one benchmark might harm related ones. For bigger models, improvements can spread to similar tasks.
5) Confidence and correctness match better for Science than for Commonsense or Semantic
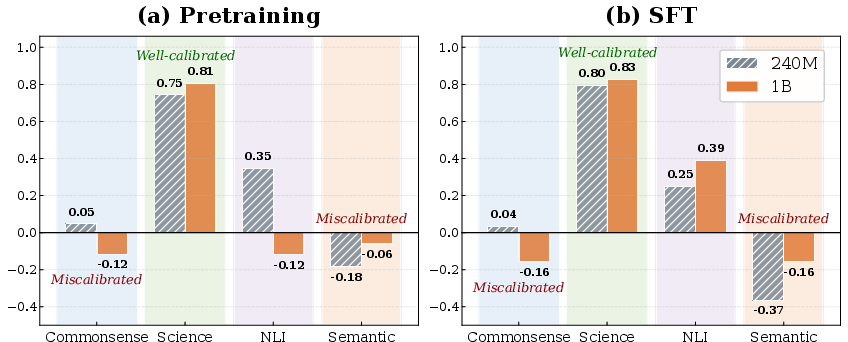
- Science tasks show strong calibration: when the model is confident, it’s usually correct.
- Commonsense and Semantic tasks show miscalibration: the model can be confident even when it’s wrong.
- Why this matters: Trust model confidence more in Science tasks. Be cautious in Commonsense and Semantic tasks.
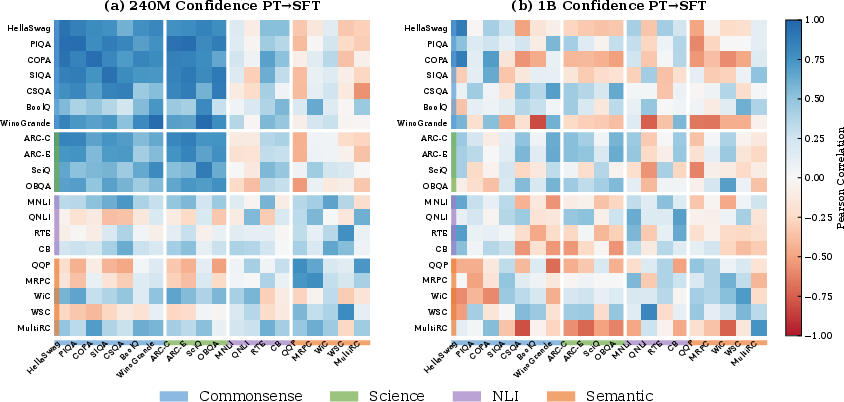
6) Confidence structure can persist strongly
- For smaller models, the “shape” of confidence across benchmarks looks very similar before and after SFT.
- Why this matters: For small models, if a benchmark reveals a confidence pattern during pretraining, you can often expect it to stick after SFT.
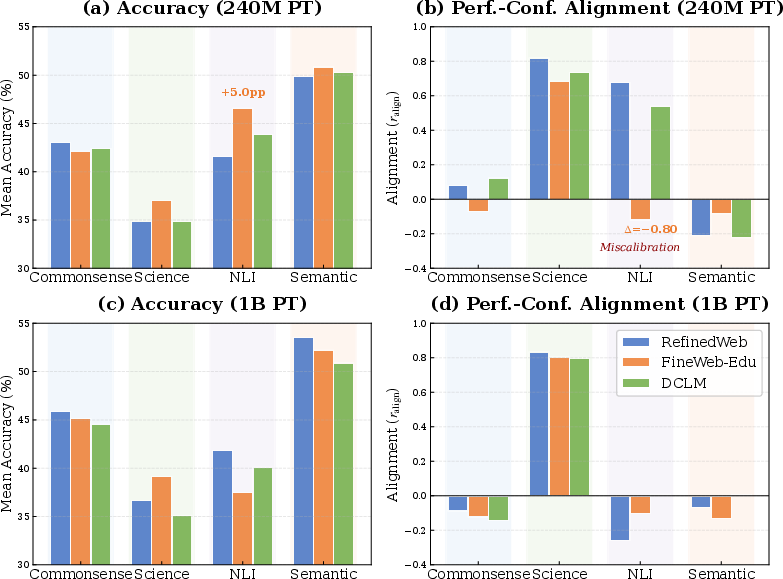
7) Filtering for educational content has trade-offs
- Using strictly educational web data (FineWeb-Edu) can boost some scores (like Science) but may hurt calibration or flip effects depending on model size.
- Why this matters: Data curation choices that look good for small models may not scale to big models. Always test your data choices at multiple sizes.
Why It Matters (Implications and Impact)
Here’s what someone building or evaluating LLMs can take away:
- Choose smarter early tests: For early decisions (like picking data or allocating compute), rely more on Science and Commonsense benchmarks. Be cautious with NLI and Semantic tasks and with benchmarks like WiC, MultiRC, WinoGrande, and MNLI.
- Don’t assume confidence will transfer: At larger scales, confidence patterns often change during SFT. If you need reliable confidence, plan to calibrate after SFT.
- Scale changes the game: What works at 240M may not work at 1B. Test data mixtures and benchmark choices across multiple sizes before committing.
- Calibrate by domain: Trust model confidence more in Science tasks. Treat confidence with skepticism in Commonsense and Semantic tasks unless you’ve validated calibration.
- Data curation is powerful but tricky: Educational filtering can help accuracy in Science but may hurt calibration or reverse effects in NLI depending on scale. There’s no one-size-fits-all data strategy.
In short, this paper shows that “practice scores” don’t always predict “game-day scores” the same way for all skills or model sizes, and that being sure is not the same as being right. With the right benchmarks and careful testing across scales, teams can make better choices about training data, evaluation, and deployment.
Knowledge Gaps
Gaps, Limitations, and Open Questions
Based on the content of the paper, the following knowledge gaps, limitations, and open questions are identified for further exploration in future research:
- Understanding of Model Confidence Dynamics: While the paper identifies confidence reorganization during supervised fine-tuning (SFT) for larger models, it does not deeply explore the underlying mechanisms of this phenomenon. Future work could quantify how specific aspects of SFT lead to changes in model confidence.
- Benchmark Incoherence Within Categories: The paper notes that certain benchmarks do not cohere within their capability categories, yet does not propose methods to address such incoherences. Investigating whether this observation holds across broader sets of benchmarks and identifying causes could improve benchmark design.
- Scale-Dependent Effects of Data Curation: The reversal of effects from educational content filtering (FineWeb-Edu) at different scales suggests a nuanced interaction between data curation and model scaling. More expansive investigations involving various model architectures and alternative data curation strategies are needed to develop best practices.
- Inconsistent NLI Scaling Patterns: The paper highlights anomalous scaling behaviors in Natural Language Inference (NLI) tasks. Systematic exploration across a wider range of model sizes and architectures could provide insights into the unique characteristics of NLI tasks.
- Impact of Training Regime Variations: This study uses a uniform supervised fine-tuning dataset (Tulu-v2-mix). Exploring the impact of different SFT data selections, amounts, and training methodologies on cross-stage correlation patterns might reveal ways to optimize fine-tuning processes.
- Calibration and Alignment Robustness: While the paper suggests that miscalibration is an issue, particularly with commonsense and semantic tasks, it does not propose solutions to improve alignment between model confidence and accuracy. Future research should focus on techniques for enhancing model calibration, perhaps by integrating varying post-hoc calibration techniques during both pretraining and fine-tuning.
- Limitations of Small Model Proxy: The reliance on 240M as a proxy during earlier stages raises concerns about the validity of certain data curation decisions when scaled. Verifying how these decisions scale with larger models or different initial conditions remains an open question.
- Evaluation Beyond Select Sample Benchmarks: The paper's conclusions largely hinge on a select set of benchmarks. Expanding the analyses to include a wider range of tasks, including adversarial and emergent property evaluations, can better capture a model's comprehensive capabilities.
These gaps suggest fertile grounds for further investigation to refine models' training processes, benchmarking, and performance evaluations in the context of deep learning and LLMs.
Glossary
- Accuracy-Confidence Correlation: A metric correlating accuracy and confidence to quantify calibration alignment. "Accuracy-Confidence Correlation ($r_{\text{align}$)."
- Adversarially-constructed, out-of-distribution test sets: Evaluation datasets intentionally built to be outside the training distribution to stress-test models. "abandon IID benchmarks in favor of adversarially-constructed, out-of-distribution test sets"
- Bayesian leaderboard model: A probabilistic model for ranking that accounts for latent skill and item difficulty. "we create a Bayesian leaderboard model"
- Benchmark contamination: The inadvertent inclusion of test data in training corpora, inflating benchmark performance. "documented widespread benchmark contamination in modern LLMs"
- Calibration fingerprint: The characteristic pattern of a model’s confidence across inputs. "the model's calibration ``fingerprint''---its level of uncertainty about specific inputs---derived from pretraining that persists despite the perturbations of SFT."
- Calibration quality: The degree to which model confidence aligns with correctness. "How well does model confidence align with accuracy, as a measure of calibration quality?"
- Chinchilla scaling laws: Compute-optimal scaling rules refining prior scaling relationships for LLMs. "refined it with the Chinchilla scaling laws"
- Compute-Optimal LLMs: Training regimes that optimally allocate compute relative to model size and data. "Training Compute-Optimal LLMs"
- Confidence reorganization: The restructuring of a model’s confidence patterns across training stages. "larger models undergo more confidence reorganization during SFT despite better accuracy preservation."
- Cosine learning rate scheduling: A training schedule where the learning rate varies following a cosine function. "5 epochs of SFT with cosine learning rate scheduling."
- Cross-benchmark transfer reliability: How well improvements on one benchmark predict improvements on related benchmarks after training transitions. "This measures cross-stage cross-benchmark transfer reliability---whether capability improvements during pretraining generalize to related tasks after SFT."
- Cross-Stage Accuracy Correlation: The correlation of benchmark accuracy between pretraining and SFT across data mixtures. "Cross-Stage Accuracy Correlation ($r_{\text{acc}^{\text{stage}$)."
- Cross-Stage Confidence Correlation: The correlation of benchmark confidence between pretraining and SFT across data mixtures. "Cross-Stage Confidence Correlation ($r_{\text{conf}^{\text{stage}$)."
- Data attribution: Techniques to trace which training examples contribute to specific model capabilities. "Data attribution methods enable fine-grained analysis of which training examples contribute to specific capabilities."
- Data curation: The process of selecting, filtering, and organizing training data to shape model behavior. "Critical decisions regarding data curation, mixture composition, and resource allocation are often made..."
- Data mixture: A specific composition of multiple data sources and proportions used for training. "on 9 distinct data mixtures (\autoref{tab:data_mixtures})."
- Decoder-only transformer: A transformer architecture using only the decoder stack for autoregressive generation. "We train a suite of decoder-only transformer models at two scales"
- Educational content filtering: Selecting web data based on educational criteria to improve reasoning tasks. "showed that educational content filtering improves certain reasoning benchmarks."
- HELM framework: A multi-dimensional LLM evaluation framework covering accuracy, calibration, robustness, and fairness. "The HELM framework~\citep{liang2022holistic} introduced multi-dimensional evaluation spanning accuracy, calibration, robustness, and fairness."
- IID benchmarks: Benchmarks assuming independent and identically distributed samples between train and test splits. "abandon IID benchmarks in favor of adversarially-constructed, out-of-distribution test sets"
- Intra-category coherence: The degree to which benchmarks within the same capability category co-vary under data changes. "consistently exhibit negative intra-category coherence on accuracy."
- Instruction tuning: Post-training adaptation that reorganizes model behavior using instruction-following objectives. "substantially reorganized during instruction tuning."
- Instruction-following data: Curated datasets of instructions used for SFT to adapt model behavior. "followed by supervised fine-tuning (SFT) on curated instruction data"
- Item response characteristics: Properties of benchmark items that affect how models respond, such as difficulty. "analyzed benchmark difficulty and item response characteristics"
- Model calibration: The agreement between predicted probabilities and empirical correctness. "\paragraph{Model Calibration.}"
- Miscalibration: Systematic mismatch where model confidence does not reflect accuracy. "systematic miscalibration that persists through SFT."
- Natural Language Inference (NLI): Tasks assessing entailment and contradiction between text pairs. "Natural Language Inference (\textcolor{NLI}{NLI}): MNLI~\citep{williams2018mnli}, QNLI~\citep{wang2019gluemultitaskbenchmarkanalysis}, RTE~\citep{wang2019superglue}, CB~\citep{wang2019superglue}"
- Pearson correlation: A statistical measure of linear correlation used to assess transfer and alignment. "Each bar shows the Pearson correlation between PT and SFT performance on the certain benchmark across data mixtures."
- Performance-confidence alignment: The correlation between task accuracy and model confidence across benchmarks. "Performance-confidence alignment ($r_{\text{align}$) varies by category."
- Pretraining (PT): The initial training phase on large corpora to acquire general capabilities. "Pretraining (PT), where the model acquires foundational knowledge from massive textual corpora"
- Proxy models: Smaller-scale models used as stand-ins to predict outcomes for larger models. "upon small-scale proxy models"
- Scaling dynamics: How transfer patterns and coherence change as model size increases. "Scale Dynamics: How do transfer patterns shift with model scale?"
- Scaling laws: Empirical relationships between performance and factors like parameters, data, and compute. "has been extensively studied through scaling laws"
- Temperature scaling: A post-hoc calibration technique that rescales logits to improve probability calibration. "proposed temperature scaling as a post-hoc remedy."
- Transfer learning: Leveraging knowledge from one training stage or task to improve performance on another. "extended scaling analysis to transfer learning settings"
- Within-stage confidence correlation: The correlation structure of confidence across benchmarks within the same training stage. "Within-stage confidence correlation comparison."
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the paper’s correlation protocols, category-specific transfer findings, and calibration insights.
- Portfolio-based benchmark selection and gating for early-stage LLM evaluation
- What to do: Prioritize Commonsense Reasoning and Scientific Reasoning benchmarks (e.g., HellaSwag, PIQA, COPA, ARC, SciQ, OpenBookQA) for pretraining-time decisions; de-emphasize weak predictors like WiC, MultiRC, WinoGrande, and MNLI for early-stage selection.
- Sectors: Software, AI platform vendors, academia.
- Tools/workflows: “Benchmark Risk Map” dashboards that flag high- vs. low-transfer benchmarks; CI pipelines that run category-weighted evaluations before committing to data mixtures.
- Assumptions/dependencies: Requires access to benchmark results and confidence scores; findings observed at 240M/1B scales may vary at larger scales.
- Confidence-aware model selection and calibration monitoring during SFT
- What to do: Track confidence transfer and alignment per category; apply post-hoc calibration (e.g., temperature scaling, per-category thresholds) especially after SFT for larger models where confidence reorganizes.
- Sectors: Healthcare (decision support), finance (risk assessment), enterprise chat assistants.
- Tools/workflows: “CalibWatch” service that logs per-benchmark confidence distributions and alerts on miscalibration drift; per-category temperature scaling jobs after SFT.
- Assumptions/dependencies: Requires reliable probability outputs from the model and per-benchmark confidence logging; larger models often need stage-specific calibration.
- Multi-scale validation before committing to data curation choices
- What to do: Evaluate data mixtures (e.g., FineWeb-Edu vs. RefinedWeb) at two proxy scales (e.g., 240M and 1B) to avoid scale-dependent reversals (observed for NLI).
- Sectors: Model training teams, data curation platforms, academia.
- Tools/workflows: “ScaleShift Validator” that automates A/B comparisons across scales and flags reversals in accuracy and alignment.
- Assumptions/dependencies: Access to compute/training pipelines at multiple scales; conclusions are sensitive to SFT dataset choice (here, Tulu-v2-mix).
- Production task routing and risk controls based on category-level calibration fingerprints
- What to do: Route high-stakes tasks where alignment is strong (Science) to automated flows; require human-in-the-loop or second-model checks for categories with miscalibration (Commonsense, Semantic).
- Sectors: Healthcare triage, finance compliance, legal research, customer support.
- Tools/workflows: Category-aware routers that use per-benchmark confidence thresholds; “Reliability Badges” in UI indicating expected calibration quality per task type.
- Assumptions/dependencies: The alignment patterns come from multiple-choice benchmarks; free-form tasks may need adapted proxies for calibration.
- Early stopping and resource allocation guided by cross-stage accuracy correlation
- What to do: Use PT→SFT accuracy correlations to prune poor-performing data mixtures early, especially for Commonsense and Science where transfer is reliable.
- Sectors: ML Ops, AI startups, cloud providers.
- Tools/workflows: “TransferLab” correlation analytics integrated into training dashboards; automated stopping rules when category-level transfer falls below thresholds.
- Assumptions/dependencies: Correlation estimates need enough mixtures (n=9 in the paper); Pearson correlation reliability depends on variance across mixtures.
- Benchmark design and reporting standards that include cross-stage transfer and calibration
- What to do: Extend evaluation reports to include PT→SFT accuracy and confidence correlations, intra-category coherence, and performance-confidence alignment.
- Sectors: Academia, open-source benchmark maintainers, standards bodies.
- Tools/workflows: HELM-like reports enriched with transfer and calibration matrices; leaderboard entries annotated with transfer reliability tags.
- Assumptions/dependencies: Requires community buy-in and tooling to compute confidence metrics consistently.
- Daily-use guidance for LLM assistants
- What to do: Encourage users to rely more on the assistant’s outputs for scientific fact-based questions and to seek confirmation for commonsense or subtle semantic tasks; present confidence estimates where possible.
- Sectors: Consumer apps, education, productivity software.
- Tools/workflows: UI prompts that show confidence and category reliability; “ask-twice” nudges for low-alignment categories; per-category disclaimers.
- Assumptions/dependencies: Confidence display must be meaningful and calibrated; category classification of user intents needs lightweight heuristics or classifiers.
Long-Term Applications
The following applications require further research, scaling, tooling, or standardization to become broadly feasible.
- Scale-aware data curation optimizers that predict mixture effects for large models
- What to build: Meta-models that learn the mapping from mixture composition to downstream transfer and alignment across scales, reducing reliance on small-model proxies.
- Sectors: AI labs, data vendors, cloud platforms.
- Tools/products: “MixtureTuner” with learned transfer functions; automated curriculum schedulers that balance accuracy vs. calibration objectives.
- Assumptions/dependencies: Generalization of 240M/1B findings to larger frontier models; diverse SFT regimes beyond Tulu-v2-mix; robust contamination control.
- Category-specific calibration interventions integrated into training (not just post-hoc)
- What to build: Training-time objectives or multi-task heads that optimize both accuracy and alignment per capability category (e.g., stronger alignment for Commonsense/Semantic).
- Sectors: Safety-critical AI (healthcare, transportation), foundation model providers.
- Tools/products: “Calib-aware SFT” frameworks with category-level losses; uncertainty-aware decoders; multi-objective schedulers that trade off accuracy vs. calibration.
- Assumptions/dependencies: Requires principled calibration losses and reliable category labels for training instances; impact must hold for open-ended generation.
- Regulatory evaluation frameworks that mandate cross-stage transfer and calibration reporting
- What to implement: Standards requiring disclosure of PT→SFT transfer metrics, category-level alignment, and scale-sensitivity analyses for deployed LLMs in high-stakes domains.
- Sectors: Policy/regulators, public sector procurement, healthcare/finance compliance.
- Tools/products: Audit templates; certification programs with cross-stage correlation thresholds; compliance dashboards.
- Assumptions/dependencies: Consensus on metrics; repeatable benchmark suites without contamination; legal clarity on confidence reporting.
- Benchmark ecosystems redesigned for transfer reliability and coherence
- What to build: New or refined benchmarks that minimize incoherence within categories, reduce contamination, and better reflect transferability to downstream SFT.
- Sectors: Academia, standards bodies, open-source communities.
- Tools/products: Curated benchmark suites with category coherence tests; item response models to measure transfer sensitivity; dynamic leaderboards that weight items by predictive reliability.
- Assumptions/dependencies: Sustained community effort; stable definitions of capability categories; ongoing empirical validation.
- Task routers and orchestration layers that adapt confidence strategies at scale
- What to build: Orchestrators that learn per-task calibration fingerprints, adapt thresholds post-SFT, and route queries across models specialized in categories with strong alignment.
- Sectors: Enterprise AI platforms, contact centers, knowledge management.
- Tools/products: “Confidence Block Router” that leverages Commonsense–Science calibration structure; multi-model ensembles with category-aware blending.
- Assumptions/dependencies: Accurate intent classification; reliable per-category confidence estimates for generative tasks; latency/cost constraints.
- Predictive models for pretraining→SFT confidence reorganization
- What to build: Methods to forecast confidence changes post-SFT for larger models and incorporate them into training plans (e.g., deciding when to re-calibrate).
- Sectors: ML research, AI tooling vendors.
- Tools/products: Confidence shift predictors; calibration drift simulators integrated into training pipelines.
- Assumptions/dependencies: Requires longitudinal datasets across stages and scales; generalization from multiple-choice to open-ended tasks.
- Sector-specific deployment protocols guided by alignment profiles
- What to build: Domain playbooks specifying where full automation is acceptable (Science-like tasks) and where human oversight or dual-model checks are mandatory (Commonsense/Semantic).
- Sectors: Healthcare diagnostics, legal drafting, financial advice, education.
- Tools/products: Risk-tiered SOPs; red-teaming tailored to low-alignment categories; user-facing reliability signals aligned to task domain.
- Assumptions/dependencies: Mapping of real-world tasks to these capability categories; validated risk models; institutional acceptance.
- Small-proxy-to-large transfer predictors for compute-efficient development
- What to build: Statistical models that translate small-scale correlation profiles into expected large-scale outcomes (including the observed inverse scaling between accuracy and confidence transfer).
- Sectors: AI labs, startups optimizing compute budgets.
- Tools/products: “ProxyTransfer Predictor” integrated with budget planners; confidence-aware scaling laws.
- Assumptions/dependencies: Sufficient cross-scale empirical data; robustness across architectures and SFT datasets.
In summary, the paper’s correlation lens and category-dependent findings enable immediate improvements in evaluation, calibration, and data curation, while motivating long-term tooling and standards that make LLM development more predictable, safer, and cost-efficient across scales and domains.
Collections
Sign up for free to add this paper to one or more collections.