Retrieval-Aware Distillation for Transformer-SSM Hybrids
Abstract: State-space models (SSMs) offer efficient sequence modeling but lag behind Transformers on benchmarks that require in-context retrieval. Prior work links this gap to a small set of attention heads, termed Gather-and-Aggregate (G&A), which SSMs struggle to reproduce. We propose retrieval-aware distillation, which converts a pretrained Transformer into a hybrid student by preserving only these retrieval-critical heads and distilling the rest into recurrent heads. We identify the essential heads via ablation on a synthetic retrieval task, producing a hybrid with sparse, non-uniform attention placement. We show that preserving just 2% of attention heads recovers over 95% of teacher performance on retrieval-heavy tasks (10 heads in a 1B model), requiring far fewer heads than hybrids that retain at least 25%. We further find that large recurrent states often compensate for missing retrieval: once retrieval is handled by these heads, the SSM backbone can be simplified with limited loss, even with an $8\times$ reduction in state dimension. By reducing both the attention cache and the SSM state, the resulting hybrid is $5$--$6\times$ more memory-efficient than comparable hybrids, closing the Transformer--SSM gap at a fraction of the memory cost.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at a way to make big LLMs cheaper and faster while keeping their ability to “look back” in a story and use earlier information. It focuses on mixing two kinds of models:
- Transformers, which are great at remembering and retrieving details from the whole text.
- State-Space Models (SSMs), which are much more memory-efficient but not as good at exact retrieval.
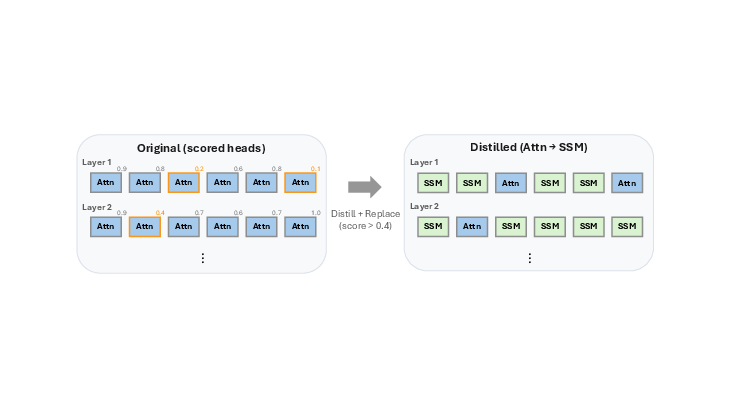
The main idea is to build a hybrid model that keeps only the small parts of a Transformer that are truly needed for retrieval, and replaces the rest with efficient SSM parts. The authors show you can keep just around 2% of the Transformer’s “attention heads” and still get most of the performance on tasks that need retrieval, while using much less memory.
What questions did the researchers ask?
In simple terms, they asked:
- Which exact parts of a Transformer are responsible for looking back and pulling the right information from earlier in a text?
- Can we keep only those retrieval-critical parts and replace the rest with cheaper SSM parts?
- If we do that, how much performance do we keep, and how much memory do we save?
- Once retrieval is handled by those Transformer parts, can we make the SSM side even smaller without losing much accuracy?
How did they do it?
Think of a Transformer like a team of “attention heads” — little workers that each look at the text in different ways. Some of these heads are special: they handle retrieval. The paper calls them “Gather-and-Aggregate” (GA) heads.
- “Gather” heads pack local info (like a key and its value in a list) into a marker token.
- “Aggregate” heads scan those markers across the whole text to find the one that matches your question.
Here’s the approach, step by step:
- Identify the retrieval-critical heads
- They set up a simple “dictionary” test: the model sees pairs like “scallops: 50” and later gets asked “scallops?” The model must retrieve “50.”
- They turn off (ablate) one attention head at a time and see how much accuracy drops on this test.
- Heads that cause big drops are the important retrieval heads.
- Build the hybrid model
- Keep only the top-k most important heads (often just 10–20 out of 512), leaving them exactly as they were in the Transformer.
- Replace all other attention heads with SSM-based “recurrent” heads that are much more memory-efficient.
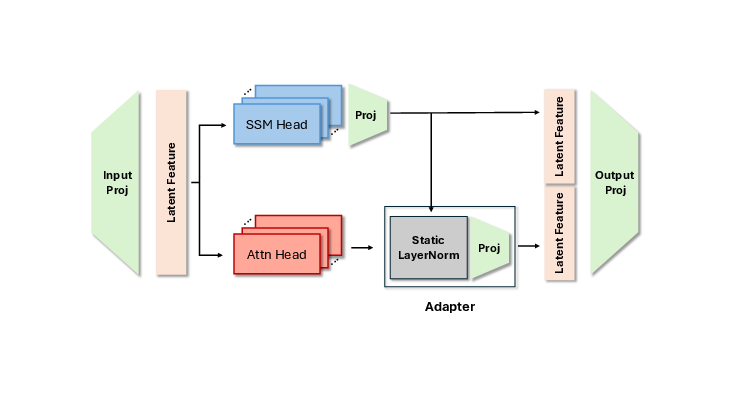
- Add a simple normalization step so the kept attention heads and the new SSM heads blend smoothly.
- Distill (train) the hybrid to copy the teacher
- Use a “teacher–student” process (distillation) where the original Transformer is the teacher.
- First align the hybrid’s intermediate outputs to match the teacher’s.
- Then train the whole hybrid to mimic the teacher’s final predictions.
Analogy: Imagine the Transformer is a student who takes detailed notes and uses many bookmarks to find things. The researchers figure out which bookmarks are essential for finding answers. They keep those few bookmarks and switch the rest of the note-taking to a smaller, more efficient notebook (the SSM). Then they train the new student to perform like the original.
What did they find, and why is it important?
Key results:
- Keeping just 2% of attention heads (about 10 out of 512) preserves over 95% of the original Transformer’s performance on retrieval-heavy tasks. That’s far fewer heads than other hybrid methods, which often keep 25–50%.
- Retrieval-heavy benchmarks (like tasks that require multi-step reasoning or recalling a specific earlier detail) jump dramatically when those few heads are kept. Example improvements:
- KV-Retrieval accuracy goes from around 13% to about 99% after keeping the top 10 retrieval heads.
- Other retrieval-focused tasks (like SWDE, Lambada, MMLU, and GSM8K) show strong gains too.
- Memory usage drops by 5–6× compared to comparable hybrids, because:
- Fewer attention heads means a much smaller “KV cache” (the shelf of all past tokens that attention needs to store).
- The SSM “state” can be made much smaller (up to 8× smaller) once retrieval is handled by the kept attention heads, with only limited performance loss.
- The gains come from exactly the preserved GA heads. Visualizations and ablation checks confirm that retrieval behavior stays concentrated in those kept attention heads, as designed.
Why it matters:
- Retrieval is the main reason Transformers outperform pure SSMs on many tasks. If you can isolate just the parts that do retrieval and keep them, you can make models that are both strong and efficient.
- This makes long-context use cheaper, faster, and more practical on real hardware.
What does this mean for the future?
This approach shows that “smart selection” beats “keeping a lot just in case.” By carefully preserving the few attention heads that truly handle retrieval and replacing the rest with efficient SSM parts, we can:
- Build models that are close to Transformer-level on retrieval tasks but use far less memory and compute.
- Run longer contexts and faster inference on limited hardware.
- Simplify SSM backbones, because they no longer need to act like long-term memory — the preserved attention heads do that job.
The authors note a few open questions:
- Will the same small set of heads be enough for much larger models?
- Are there retrieval types (like complex multi-hop reasoning) that need different heads than those found by the simple dictionary test?
- Could sharing or tying KV caches across layers cut memory even more?
Overall, the paper provides a clear recipe: find and keep the few “retrieval bookmarks,” swap the rest for efficient SSMs, and distill the hybrid to act like the teacher. The result is a model that closes most of the Transformer–SSM performance gap on retrieval, while being far more memory-friendly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, to guide future research.
- Scalability to larger models: It is unknown whether retaining ~2% of attention heads suffices for models >3B parameters; quantify how the number and distribution of G&A heads scale with model size and depth.
- Generality across architectures: Validated only on Llama-3.2-1B and Qwen2.5-1.5B; assess transfer to other families (e.g., Mistral, Gemma, RWKV/RetNet-style hybrids) and to base vs. instruct-tuned teachers.
- Context-length robustness: Retrieval and accuracy were not evaluated beyond 4k tokens; test at 8k–128k to see if a tiny set of heads still preserves long-context retrieval and how memory/performance trade-offs evolve.
- Probe dependence: Head selection relies on a synthetic KV-retrieval task; evaluate whether the same heads drive performance on multi-hop, compositional, cross-document retrieval, or programmatic copying.
- Stability of head importance: No analysis of variance across random seeds, training checkpoints, or input distributions; measure how head rankings shift across datasets and whether a single global ranking is reliable.
- Task-specific vs global selection: Static “top-k” heads may be suboptimal for diverse tasks/domains; explore dynamic or input-conditional routing/gating that activates different head subsets per example.
- Alternative importance metrics: Only ablation-based scoring was used; compare to gradient-, Fisher-, or Shapley-based attributions and assess correlation with retrieval-heavy downstream gains.
- Cost of head ranking: Per-head ablation on the teacher can be compute-intensive; design and benchmark more efficient head-importance estimation procedures with similar fidelity.
- Separation of roles (Gather vs Aggregate): The method preserves heads by overall retrieval sensitivity, not by explicit role; investigate whether explicitly preserving complementary gather/aggregate roles yields better performance per head.
- Persistence and drift of retained heads: Retained heads are fine-tuned end-to-end; study whether retrieval-specific functionality drifts during training and whether freezing or regularizing these heads improves stability.
- Coupling between attention and SSM: Ablations show some SSM heads still influence retrieval, preventing aggressive state shrinkage; develop architectural constraints or regularizers to cleanly disentangle retrieval (attention) from recurrence (SSM).
- Minimal SSM state needed: State-size reductions were explored only down to d_state=4–64 with 20 heads; map the full trade-off between number of retained heads and minimal d_state across tasks and context lengths.
- Choice of SSM replacement: Only DiscreteMamba2 was used for replaced heads; evaluate other SSMs (e.g., Mamba-2 variants, Gated Delta Nets, RetNet-like mixers) and hybrid mixers for compatibility and performance.
- KV-cache sharing and compression: The hybrid does not enforce KV sharing across layers or GQA/MQA tying; integrate KV sharing/compression and quantify additional memory and bandwidth savings without accuracy loss.
- Throughput and training cost: Claims of throughput gains are not fully quantified; report prefill/decoding speedups, training wall-clock, and memory-bandwidth utilization on real hardware.
- Robustness and OOD generalization: No assessment under domain shifts, noisy inputs, adversarial prompts, or rare-token regimes; evaluate whether retrieval-aware hybrids maintain advantages off-distribution.
- Fine-grained token/perplexity analysis: Perplexity improvements are attributed to retrieval tokens qualitatively; provide quantitative token-level breakdowns (e.g., by Zoology taxonomy) to validate where gains occur.
- Interaction with quantization/pruning: Effects of INT8/INT4 quantization or structured pruning on the few retained heads and reduced SSM state are unexplored; test whether compression undermines retrieval specialization.
- Long-horizon reasoning tasks: Benchmarks did not include multi-hop QA (e.g., HotpotQA), code-level copying/trace tasks, or chain-of-thought long-form reasoning; evaluate to test retrieval-head sufficiency beyond current suite.
- Data dependence during distillation: Sensitivity to the composition/size of distillation corpora is not reported; quantify how dataset mixtures affect preservation of retrieval behavior and head functionality.
- Catastrophic interactions with MLPs/norms: Non-mixer components are transferred but not analyzed for interaction effects with the hybrid mixers; probe whether MLP/norm adaptations are needed for best hybrid performance.
- Layerwise head placement patterns: While non-uniform placement emerges, there is no systematic study of optimal layer positions for retained heads; map layer–head importance and its causal impact on retrieval tasks.
- Extensibility to cross-attention/multimodal settings: The approach targets self-attention; investigate whether retrieval-aware selection applies to cross-attention heads (e.g., vision–language or RAG pipelines).
Practical Applications
Immediate Applications
Below are concrete use cases that can be deployed today by leveraging retrieval-aware distillation to create memory-efficient Transformer–SSM hybrids that preserve only the retrieval-critical attention heads and replace the rest with SSMs.
- Memory-efficient long-context inference for enterprise LLMs (Software, Enterprise SaaS)
- What: Compress existing Transformer LMs into hybrids that retain just ~2% of heads for in-context retrieval while cutting KV cache and SSM state, achieving 5–6× lower memory at similar accuracy on retrieval-heavy tasks.
- How/tools: “Retrieval-Aware Distiller” pipeline (head ablation + hybrid construction + distillation), integration with serving stacks (e.g., TGI, vLLM), FlashAttention for the few retained heads, optimized SSM kernels for DiscreteMamba2.
- Workflows/products: Cost-efficient customer support/chatbots, contract or legal document analysis, large-context document review.
- Assumptions/dependencies:
- Access to teacher model weights and permission to modify/distribute distilled hybrids.
- Compute budget for head ranking and distillation.
- Paper’s results are strongest on ~1–1.5B models; mild risk extrapolating to larger/very different architectures.
- The synthetic KV probe correlates with downstream retrieval in the deployment domain.
- On-device assistants with offline operation (Consumer tech, Mobile)
- What: Ship assistants that summarize emails/messages, do offline Q&A, or maintain longer conversation history within mobile memory limits.
- How/tools: Hybrid runtime with tiny KV cache (2% heads) and small SSM states (e.g., d_state ≈ 8), Metal/NNAPI-optimized SSM kernels; couple with on-device ASR/TTS.
- Workflows/products: Privacy-first personal assistant that works in airplane mode; extended local memory without cloud calls.
- Assumptions/dependencies:
- Efficient fused kernels for SSM+attention on handset NPUs/GPUs.
- Licensing for local deployment of a teacher-derived hybrid.
- Edge and IoT analytics over long streams (Robotics, Manufacturing, IoT)
- What: Process long-horizon sensor or log sequences on devices with small compute/memory budgets (e.g., drones, wearables).
- How/tools: ROS-compatible hybrid nodes; streaming token-by-token processing with constant-memory SSM and minimal KV attention.
- Workflows/products: Predictive maintenance, fault detection, long-horizon state tracking on embedded devices.
- Assumptions/dependencies:
- Real-time kernel support and deterministic latency (SSM + sparse attention).
- Task-specific validation for domain retrieval (may need domain-tuned probes).
- On-prem healthcare summarization and triage (Healthcare)
- What: Summarize EHR timelines, clinical notes, and medication histories on hospital servers with constrained GPUs, preserving retrieval accuracy.
- How/tools: Distilled hybrids deployed on on-prem clusters; integrate with existing EHR viewers; reduced KV memory enables longer context windows per GPU.
- Workflows/products: Clinical note summarizers, timeline-aware triage assistants, discharge preparation.
- Assumptions/dependencies:
- Compliance (HIPAA/GDPR), model validation on clinical datasets.
- Domain-specific head-ranking probes to ensure retrieval relevance beyond generic KV tasks.
- Low-cost long-context code assistance (Software engineering)
- What: Provide long-file/codebase context on consumer GPUs/CPUs (e.g., laptops) by shrinking KV footprint 5–6× while preserving retrieval heads.
- How/tools: IDE plugins backed by hybrid models; caching only retrieval-critical heads; SSM backbone for local modeling.
- Workflows/products: Inline suggestions and refactoring across large repos without expensive GPUs.
- Assumptions/dependencies:
- Distillation from code-specialized teachers; ensure retrieval probes reflect code navigation/linking.
- Cloud inference cost reduction and higher user density (Cloud platforms)
- What: Serve more concurrent sessions per GPU by slashing KV memory bandwidth and cache size.
- How/tools: Scheduler aware of minimal KV cache; hybrid-aware batch/kv-sharing where possible.
- Workflows/products: Multi-tenant LLM services with higher throughput and lower cost per token.
- Assumptions/dependencies:
- Platform support for custom kernels and model variants.
- Monitoring to ensure retrieval performance holds under typical workloads.
- RAG-friendly hybrid models (Enterprise knowledge management)
- What: Combine external retrieval (vector DBs) with minimal in-model retrieval heads to keep long inline contexts manageable.
- How/tools: Integrations with LangChain/LlamaIndex; non-uniform head placement for efficient in-context recall of injected passages.
- Workflows/products: Contract analysis, knowledge base assistants, customer support RAG systems.
- Assumptions/dependencies:
- Pipeline integration and latency budgets; domain-specific adaptation of retrieval probes.
- Financial compliance and stream analytics (Finance)
- What: Real-time scanning of chats/emails/logs with long history on fixed on-prem hardware; risk alerts with long context.
- How/tools: Distilled hybrids on bank datacenters; reduced KV memory to lengthen historical windows.
- Workflows/products: Surveillance tools, trade compliance assistants, post-trade analysis.
- Assumptions/dependencies:
- Strict on-prem deployment policies, auditing; validation against internal datasets.
- Interpretability and model-audit tooling (Academia, Responsible AI)
- What: Identify and preserve retrieval-critical heads; use head ablation as an audit for capability localization.
- How/tools: “KV-Retrieval Head Profiler” to rank heads; ablation dashboards; automatic hybrid design from teacher internals.
- Workflows/products: Capability audits, regression checks after finetuning or pruning.
- Assumptions/dependencies:
- Ability to run controlled ablations and access intermediate activations.
- CI/CD checks for LLM deployments (MLOps)
- What: Add retrieval-head health tests to model release pipelines to catch regressions in long-context behavior.
- How/tools: Synthetic KV-retrieval tests; per-head ablation reports; thresholds for promotion to prod.
- Workflows/products: Continuous quality gates for retrieval-heavy tasks.
- Assumptions/dependencies:
- Extra compute time in CI; test sets that correlate with production retrieval demands.
Long-Term Applications
These opportunities will benefit from further research, scaling, and tooling—especially beyond ~1–2B parameters, additional domains, and hardware/software co-design.
- Scaling retrieval-aware hybrids to larger models (7B–70B+) (Software, Cloud)
- What: Achieve similar 5–6× memory savings and 2% head retention at scale to enable affordable long-context serving.
- Tools/workflows: Large-model head-profiling suites; distributed distillation pipelines.
- Assumptions/dependencies:
- Retrieval head sparsity may change with scale; more complex redundancy and emergent behaviors.
- Task/domain-adaptive head selection and dynamic routing (Software, Multi-domain)
- What: Automatically select different retrieval-critical heads per domain (e.g., code, biomedical) or even per prompt at runtime.
- Tools/workflows: Prompt-conditioned head gates; domain-specific retrieval probes and schedules.
- Assumptions/dependencies:
- Stability and reproducibility of dynamic head routing under latency constraints.
- Training-time regularization to concentrate retrieval into fewer heads (Academia, Model design)
- What: Encourage G&A concentration during pretraining/finetuning for simpler post-hoc distillation.
- Tools/workflows: Loss terms/constraints that penalize diffuse retrieval; curriculum with retrieval probes.
- Assumptions/dependencies:
- Access to pretraining or large-scale finetuning; impact on overall generalization must be studied.
- Hardware–software co-design for hybrid kernels (Semiconductors, Cloud)
- What: Fused kernels for SSM+attention; KV sharing across layers; memory-hierarchy optimizations tailored to sparse head retention.
- Tools/workflows: Vendor support (CUDA, ROCm, Metal), compiler passes, NPU implementations.
- Assumptions/dependencies:
- Ecosystem investment; standardization across frameworks (PyTorch/JAX/TVM).
- Privacy and safety controls via retrieval-head governance (Policy, Responsible AI)
- What: Reduce unintended memorization or data leakage by throttling or auditing specific retrieval heads; certifiable “retrieval budgets.”
- Tools/workflows: Head-level policy toggles, audit logs, red-teaming with controlled ablations.
- Assumptions/dependencies:
- Reliable mapping from heads to behaviors across updates; regulatory acceptance.
- Multimodal hybrids for long-context audio/video/time-series (Media, Autonomy)
- What: Apply retrieval-aware distillation to ASR with long audio context, video understanding with long temporal windows, or multivariate sensor streams.
- Tools/workflows: Multimodal head-probe variants; SSMs specialized for continuous signals.
- Assumptions/dependencies:
- Adaptation of G&A identification to cross-modal attention; benchmarks for multi-hop retrieval in multimodal settings.
- Federated and on-device personalization with small memory budget (Consumer, Healthcare, Finance)
- What: Personalize models on-device without large KV cache; maintain long user history for better personalization.
- Tools/workflows: Lightweight finetuning (LoRA/adapter) atop hybrids; privacy-preserving training.
- Assumptions/dependencies:
- Efficient on-device training/inference pipelines; governance for personal data.
- AutoML for hybrid architecture search (Software tooling)
- What: Automated pipelines that learn which heads to retain and how to size SSM states per layer/task.
- Tools/workflows: NAS integrated with ablation scores and retrieval metrics; cost–accuracy optimizers.
- Assumptions/dependencies:
- Standardized metrics linking probes to downstream performance across tasks.
- Standards and procurement for energy-efficient long-context AI (Policy, Sustainability)
- What: Introduce benchmarks and labels for memory/energy efficiency of long-context models; inform public-sector procurement.
- Tools/workflows: Audited metrics (e.g., per-token Joules at fixed context length), compliance checklists for KV/state footprint.
- Assumptions/dependencies:
- Cross-industry agreement on measurement protocols; alignment with sustainability frameworks.
- Advanced KV sharing and GQA-style tying during distillation (Software, Cloud)
- What: Further shrink KV cache by enforcing intra-/inter-layer sharing while preserving retrieval-critical behavior.
- Tools/workflows: Distillation objectives that encourage KV reuse; new projection tying schemes.
- Assumptions/dependencies:
- New methods to prevent accuracy loss; support in serving frameworks.
- Education in low-resource settings via offline long-context tutors (Education)
- What: Deploy multilingual, curriculum-aware tutors that handle long lesson histories on low-cost hardware.
- Tools/workflows: Domain-tuned retrieval-aware hybrids; curriculum-specific probes for head selection.
- Assumptions/dependencies:
- High-quality local datasets; validation for pedagogy and safety; language coverage.
Notes on cross-cutting dependencies:
- Reproducibility of retrieval-head ranking may vary by domain; domain-specific KV or multi-hop probes may be necessary.
- Kernel maturity for SSMs (e.g., DiscreteMamba2) and mixed attention–SSM execution strongly affects real-world latency.
- Licensing constraints for teacher weights and redistribution of distilled students must be observed.
- Current evidence is strongest for 1–1.5B models and English-centric benchmarks; broader validation is advisable before mission-critical deployment.
Glossary
- Ablation: Systematically removing or masking a model component to measure its impact on performance. "We add a retrieval-guided step before standard distillation: (1) ablate each attention head in the pretrained Transformer and measure the accuracy drop on a synthetic KV-retrieval probe to obtain a retrieval-importance score;"
- Annealed interleaving: A heuristic placement strategy that gradually reduces the fraction of attention layers according to a schedule. "Annealed interleaving. This strategy applies an annealed replacement schedule under a global stride pattern, progressively reducing the fraction of Attention layers across stages (e.g., 50% → 25% → 12.5%)."
- Associative recall: The ability to retrieve values associated with keys from context, a capability where SSMs are comparatively weak. "\citet{wen2024rnnstransformersyetkey} highlight SSM weaknesses in associative recall, while \citet{repeat_after_me} provide theoretical evidence that SSMs struggle with precise copying operations."
- Attention cache: The memory used to store key-value tensors from attention for retrieval during generation. "By reducing both the attention cache and the SSM state, the resulting hybrid is $5$-- more memory-efficient than comparable hybrids, closing the Transformer--SSM gap at a fraction of the memory cost."
- Attention-map visualizations: Visual analyses of attention weights that reveal where heads focus and how they implement behaviors. "Attention-map visualizations support this interpretation, showing that G{paper_content}A operations concentrate in the preserved heads, consistent with the specialization observed in full-layer hybrids \citep{gather_and_aggregate}."
- Coverage (COV): A metric reporting the fraction of teacher performance retained by the student within a benchmark group. "Coverage (COV) is computed per group as the ratio of the model and teacher group-mean scores."
- DiscreteMamba2: A discretized variant of Mamba-2 designed for compatibility between attention-style and SSM-style mixing during distillation. "\citet{mohawk} also introduce DiscreteMamba2, a discretized Mamba-2 variant used to improve compatibility between attention-style and SSM-style mixing during these alignment stages; we use it as the basis for our SSM replacements."
- Frobenius distance: A matrix norm used to measure differences between token-mixing operators during alignment. "For each layer , MOHAWK matches the teacher attention mixer and the student SSM mixer by minimizing the Frobenius distance between their induced token-mixing operators,"
- Gather Heads: Specialized attention heads that compress local information into summary tokens enabling downstream retrieval. "Gather Heads: These heads compress local information into ``transport'' tokens."
- Gather-and-Aggregate (G{paper_content}A): A mechanism implemented by a small subset of attention heads that performs retrieval by gathering local info and aggregating it globally. "Prior work links this gap to a small set of attention heads, termed Gather-and-Aggregate (G{paper_content}A), which SSMs struggle to reproduce."
- Global stride pattern: A periodic layout rule for placing attention layers at fixed intervals across the network depth. "This strategy applies an annealed replacement schedule under a global stride pattern, progressively reducing the fraction of Attention layers across stages (e.g., 50\% 25\% 12.5\%)."
- GQA-style tying: Sharing of key/value parameters across attention heads (Grouped-Query Attention), used to reduce KV memory. "our distillation does not enforce KV sharing across layers (or within layers via GQA-style tying)."
- Hidden-State Alignment: A distillation stage that matches the outputs of teacher and student blocks by minimizing an L2 loss. "Hidden-State Alignment. After orienting the mixers, MOHAWK aligns the block outputs (e.g., an attention block vs.\ an SSM/mixer block) by minimizing an distance,"
- Hybrid architectures: Models that combine attention and recurrent (SSM) components to balance retrieval capability and efficiency. "To bridge this gap, recent hybrid architectures combine SSM backbones with a small number of attention heads that cache the full sequence history."
- In-context retrieval: Referencing and retrieving information from earlier parts of the input sequence during prediction. "State-space models (SSMs) show strong language modeling capabilities with high efficiency, but their constant-memory design causes them to underperform Transformers on benchmarks that require referencing earlier context---a function known as in-context retrieval"
- KV-cache: The stored keys and values from attention used during autoregressive decoding to avoid recomputation. "Retrieval-Aware minimizes footprint through two mechanisms: (1) a reduced SSM state dimension () lowers constant overhead, and (2) retaining only 2\% attention heads reduces the KV cache."
- KV-retrieval: A synthetic benchmark that probes a model’s ability to retrieve values associated with keys from context. "We first score attention heads by ablation on a synthetic KV-retrieval task and keep only the high-scoring ones."
- LayerNorm: A normalization operation applied to stabilize feature distributions; here used parameter-free to align attention and SSM outputs. "we apply a parameter-free LayerNorm to the attention outputs, rescaling them to match the mean and variance of the SSM outputs."
- Matrix Orientation: A distillation stage that aligns teacher attention mixers and student SSM mixers by minimizing their operator differences. "Matrix Orientation. For each layer , MOHAWK matches the teacher attention mixer and the student SSM mixer by minimizing the Frobenius distance between their induced token-mixing operators,"
- Memory-bandwidth bottlenecks: Performance limits caused by the cost of moving large KV tensors during attention compared to compute. "While these designs mitigate the memory-bandwidth bottlenecks of full Transformers, they typically place attention using fixed, layer-level patterns"
- MOHAWK: A distillation framework that aligns mixers and hidden states to transfer Transformer knowledge into SSMs/hybrids. "We apply retrieval-aware distillation to Llama-3.2-1B and Qwen2.5-1.5B using the MOHAWK distillation framework \citep{mohawk}."
- Multi-hop reasoning: Tasks requiring sequential inference steps, often stressing retrieval and aggregation over long contexts. "In contrast, the second group comprises Retrieval-Heavy Tasks, which place a stronger emphasis on multi-hop reasoning, mathematical deduction, or sequence-level recall."
- Perplexity: A language modeling metric reflecting how well a model predicts tokens; lower is better. "Perplexity during distillation reveals retrieval as the primary bottleneck."
- Prefill and decoding throughput: Inference performance measures for the initial forward pass (prefill) and token-by-token generation (decoding). "with corresponding gains in prefill and decoding throughput."
- Residual stream: The running representation updated across layers via residual connections, into which block outputs are integrated. "The retained attention heads act as stable ``anchors,'' ensuring the SSMs learn features compatible with the existing residual stream."
- Retrieval-aware distillation: A targeted distillation approach that preserves only retrieval-critical attention heads and replaces others with SSMs. "We propose retrieval-aware distillation, which converts a pretrained Transformer into a hybrid student by preserving only these retrieval-critical heads and distilling the rest into recurrent heads."
- Sliding-window attention: An attention variant limited to a local window to reduce cost while retaining some context. " \citet{hymba} combines quadratic and sliding-window attention with SSMs in a fixed 1:5 ratio."
- State dimension: The size of the SSM’s recurrent state vector controlling its capacity to carry information over time. "even with an reduction in state dimension."
- State-Space Duality (SSD): A technique to map attention parameters to SSM parameters for initialization and alignment. "It leverages State-Space-Duality (SSD)~\citep{mamba2} to initialize new SSM parameters from the teacher Attention weights ;"
- State-space models (SSMs): Recurrent sequence models that maintain a compressed state, offering linear-time, constant-memory processing. "State-space models (SSMs) offer efficient sequence modeling but lag behind Transformers on benchmarks that require in-context retrieval."
- Token-mixing operators: Blocks that combine information across sequence positions (via attention or recurrence) before pointwise transforms. "We view both attention and SSM blocks as token-mixing operators (mix across positions) followed by standard pointwise transformations (e.g., MLPs and residual connections)."
- Transport tokens: Tokens that temporarily store gathered local information for global retrieval (e.g., newline positions in key-value lists). "Aggregate Heads: These heads perform the global retrieval... attend primarily to the ``transport'' tokens (the \textbackslash n positions) across the sequence, identifying the one matching the query and extracting its stored value."
Collections
Sign up for free to add this paper to one or more collections.