Olmix: A Framework for Data Mixing Throughout LM Development
Abstract: Data mixing -- determining the ratios of data from different domains -- is a first-order concern for training LMs. While existing mixing methods show promise, they fall short when applied during real-world LM development. We present Olmix, a framework that addresses two such challenges. First, the configuration space for developing a mixing method is not well understood -- design choices across existing methods lack justification or consensus and overlook practical issues like data constraints. We conduct a comprehensive empirical study of this space, identifying which design choices lead to a strong mixing method. Second, in practice, the domain set evolves throughout LM development as datasets are added, removed, partitioned, and revised -- a problem setting largely unaddressed by existing works, which assume fixed domains. We study how to efficiently recompute the mixture after the domain set is updated, leveraging information from past mixtures. We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update. Over a sequence of five domain-set updates mirroring real-world LM development, mixture reuse matches the performance of fully recomputing the mix after each update with 74% less compute and improves over training without mixing by 11.6% on downstream tasks.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about choosing the right “recipe” of training data for LMs. Big LMs learn from many kinds of text (like web pages, code, books). How much of each kind you use matters a lot. The authors introduce Olmix, a framework that helps:
- pick a good data mix (the “recipe”), and
- keep that mix strong and efficient as the available datasets change over time.
They built and tested Olmix while training OLMo 3, a family of open language and reasoning models.
The big questions the paper asks
Here are the two main questions, in everyday terms:
- How do we set up a good way to find the best data “recipe”? (Which small test runs to do, how many, what math to use to predict success, and how to deal with limited data.)
- When our data collection changes (we add, remove, split, or fix datasets), how can we update the recipe quickly without redoing tons of work?
How they approached it (methods, explained simply)
Think of training as cooking, and each data type (like code or web text) as an ingredient. The “mixture” is your recipe: how much of each ingredient to use.
The authors use a three-step plan (often called an “offline mixing schema”) to choose a recipe:
- Try lots of small “practice” batches
- They train many small, cheaper “proxy” models on different recipes.
- Each proxy model is like a taste test: “If we used more code and less web text, how well does the model do on math, coding, and quiz questions?”
- Learn a prediction rule from those taste tests
- They fit a simple math formula (a “regression model”) that takes a recipe as input and predicts how well a larger model would do.
- This lets them guess which recipes will work best without having to train a big model for each one.
- Pick the best recipe (respecting limits)
- They use the prediction rule to find the recipe with the best predicted performance.
- They add practical constraints so the recipe doesn’t ask for more data than exists (to avoid repeating the same examples too many times, which can hurt learning).
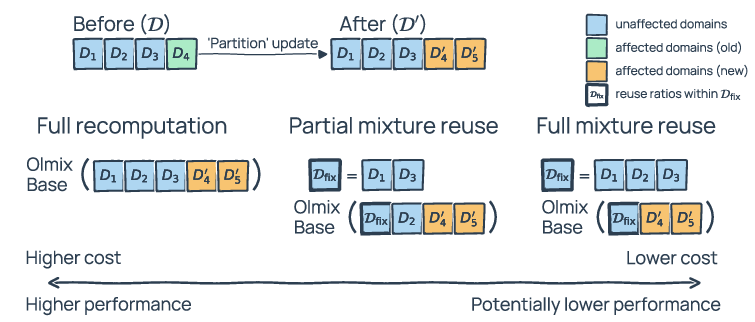
Then they address the second problem: recipes need updating as data changes. Instead of starting over, they introduce “mixture reuse,” which means keeping the parts of the old recipe that still make sense and only recalculating the parts affected by the change:
- FullMixtureReuse: Keep the relative amounts of the unchanged ingredients the same, and only re-balance the changed parts plus the overall total.
- PartialMixtureReuse: Like FullMixtureReuse, but also allow some untouched ingredients to be re-tuned if they strongly interact with the changed parts. This can improve quality a bit more with a small extra cost.
Along the way, they carefully study and simplify a bunch of design choices:
- How big should the small “practice” models be?
- How many practice runs do you need?
- How do you choose which recipes to try in your practice runs?
- What kind of prediction formula works best?
- Should you predict performance one task at a time or all together?
- How do you handle limited data?
- How do you solve for the final recipe (exact math vs. search), and should you nudge the solution toward a reasonable default?
What they found (and why it matters)
Below is a short list of the main findings, phrased simply:
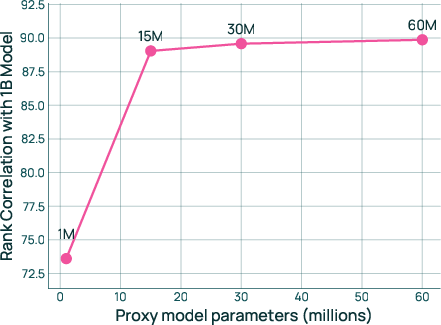
- You don’t need huge practice models, but very tiny ones are unreliable
- Very small proxies (around 1M parameters) weren’t dependable.
- Proxies with ~15M+ parameters worked much better; they used ~30M in practice.
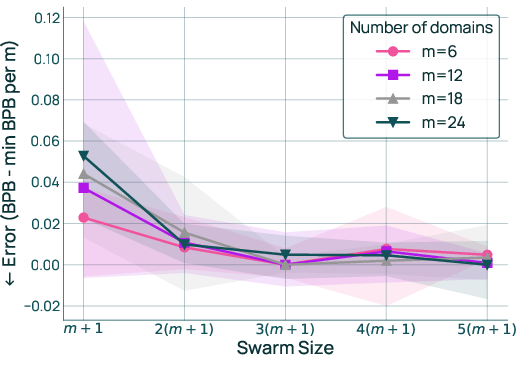
- The number of practice runs should grow roughly with the number of data types (domains)
- If you’re mixing m domains, about 3×(m+1) practice runs was a good rule of thumb.
- That’s much cheaper than what some people expected.
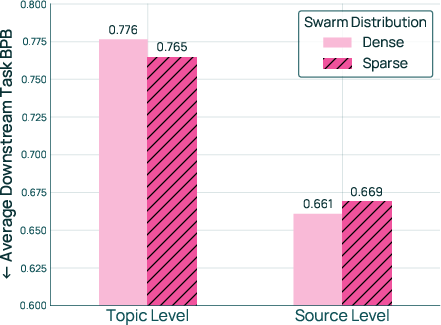
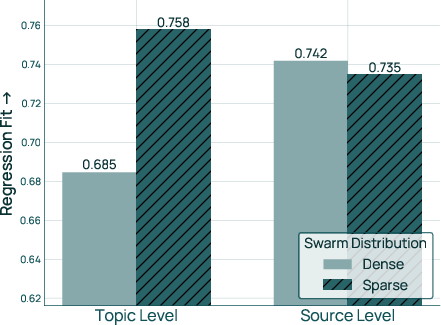
- How you pick trial recipes depends on the domain type
- For “topics” (fine-grained buckets like “sports,” “adult content,” etc.), it’s better to try some recipes that focus on subsets (sparse sampling), because some topics are not helpful and should be down-weighted or excluded.
- For “sources” (bigger, curated groups like “Wikipedia,” “books,” “code”), it’s better to try recipes that include all sources (dense sampling).
- Start your practice near a reasonable default
- Centering on the “natural distribution” (proportional to how much data each domain has) or a strong prior both worked well.
- A very weak prior hurt results.
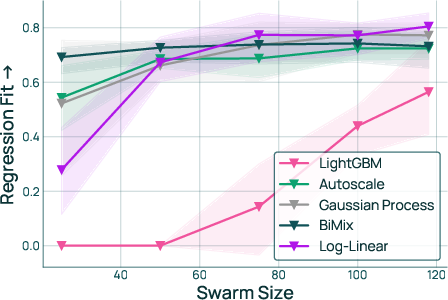
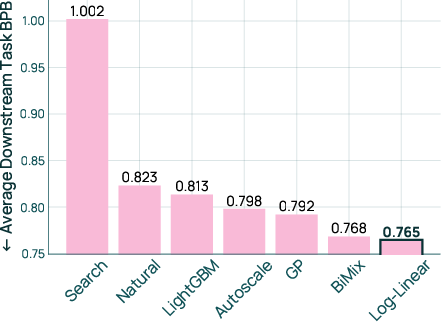
- A simple prediction formula worked best, especially with enough practice runs
- A “log-linear” model (a simple, interpretable formula) gave the best predictions and the best final recipes when the practice set was sufficiently large.
- Predicting per task (math, code, QA) and then averaging gave better results than predicting only the overall score.
- Respect data limits during the final recipe pick
- Enforce the “don’t repeat the same data too many times” rule in the final optimization step.
- This both keeps things realistic and improves results. Tight or loose limits noticeably change the chosen recipe, as they should.
- How to pick the final recipe
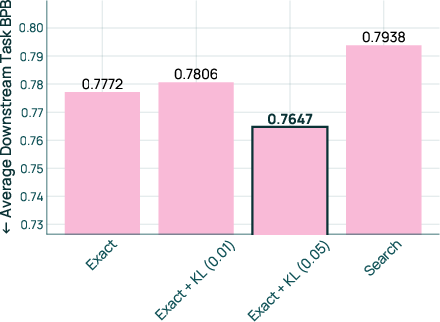
- Using an exact solver with a gentle nudge back toward the natural distribution (a small “regularization” push) performed best.
- Pure exact optimization on the prediction sometimes overcommitted due to noise; a small nudge made the result more reliable.
- Reusing old recipes saves a lot of compute without losing much quality
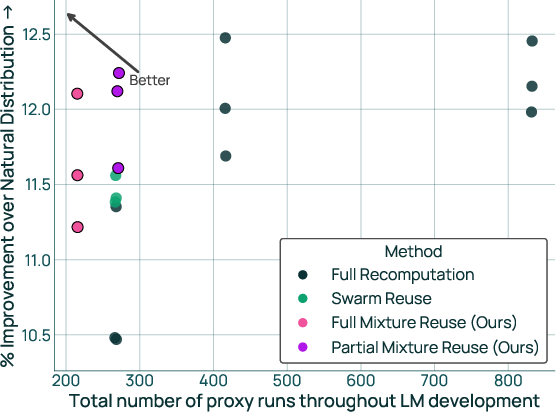
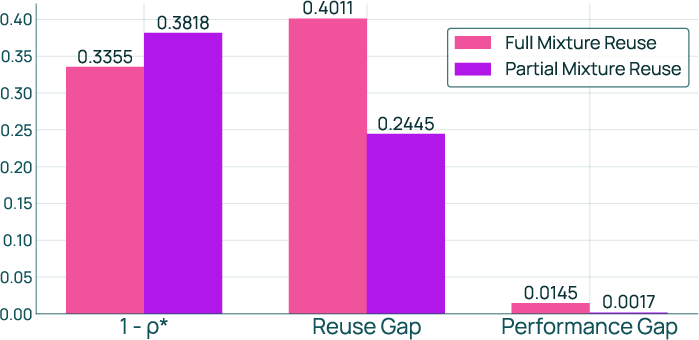
- In a real, 5-step development process ending with 64 domains, FullMixtureReuse matched 95% of the benefit of fully recomputing a fresh recipe each time, while using 74% fewer practice runs.
- PartialMixtureReuse did even better (98%) while still saving 67% of the practice runs.
- Compared to training with the natural distribution (no fancy mixing), reuse-based mixes improved performance by about 11.6% on downstream tests.
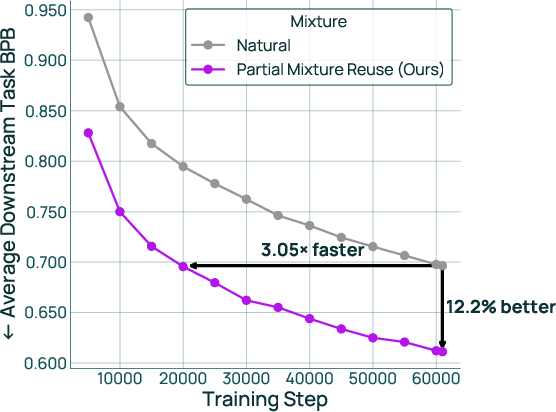
- The best reused recipe was also about 3× more data-efficient (reaching the same final performance in roughly one-third the training steps).
Why this matters
- It turns a messy, expensive trial-and-error process into a clear playbook.
- Teams can train better models faster and cheaper by:
- running the right number of practice runs,
- using a simple, effective prediction model,
- respecting data limits,
- and reusing previous recipes smartly as data evolves.
- This makes continuous LM development (where datasets change often) much more practical.
- The approach helps avoid overfitting to tiny data pools and reduces wasted compute, which is good for both budgets and the environment.
Simple takeaway
Olmix is a practical framework for choosing and updating the “data recipe” for training LLMs. It shows how to do enough small tests, use a simple prediction tool, honor real data limits, and reuse past work so you get nearly the same quality as starting from scratch—while saving a lot of time and compute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains uncertain, missing, or unexplored in the paper, phrased to help future researchers design concrete follow-ups.
- Generalization across scales: Findings (e.g., proxy-to-target transfer, optimal swarm size , solver choices) are validated primarily with 30M proxies and 1B targets; it remains unknown how they transfer to larger targets (e.g., 7B–32B+) and different training budgets.
- Cross-architecture robustness: All experiments use decoder-only OLMo-style models; it is unclear if conclusions hold for different architectures (e.g., Mixture-of-Experts, encoder-decoder), context lengths, or tokenizers.
- Proxy size threshold robustness: The “≥15M parameters” proxy reliability threshold is shown for one data regime; a systematic method to pick proxy size for other domain sets, target sizes, or budgets is missing.
- Metric transferability: The framework optimizes average bits-per-byte (BPB) across tasks; the extent to which BPB-optimized mixes improve accuracy-based or human-evaluated metrics (e.g., chain-of-thought, long-form quality) remains untested.
- Task weighting and multi-objective goals: The method uses a macro-average over 52 tasks; how to set task weights for product priorities, safety-critical tasks, or risk-sensitive objectives (e.g., worst-case over task families) is not investigated.
- Domain granularity selection: Results depend on whether domains are topics or sources; a principled procedure to choose/learn the right granularity (or hierarchical mixing) is not provided.
- Interaction effects between domains: The log-linear surrogate captures additive effects over ; higher-order interactions (synergies/antagonisms between domains) are not modeled or tested.
- Theoretical sample complexity: O() swarm size is supported empirically; a formal sample complexity analysis (and conditions under which O() breaks) is missing.
- Swarm sampling beyond Dirichlet: Only Dirichlet-based distributions (dense/sparse, different priors) are studied; alternative space-filling designs (e.g., Latin hypercube, low-discrepancy sequences, constrained experimental design) could reduce further but are unexplored.
- Adaptive swarm design: Rules to automatically choose sparse vs. dense swarms based on diagnostics (e.g., held-out fit, domain coverage, posterior uncertainty) are not provided.
- Uncertainty-aware optimization: The surrogate’s prediction uncertainty is ignored; robust or risk-averse optimization (e.g., penalizing high-variance regions, Bayesian optimization with uncertainty) is not explored.
- Regularization tuning: The KL regularization strength () is chosen empirically; a principled procedure to set (e.g., via validation, stability criteria, or PAC-Bayes bounds) is absent.
- Constraint modeling beyond repetition: Only per-domain repetition caps are considered; realistic constraints (licensing, cost per token, compute to preprocess/filter, toxicity caps, legal compliance) are not integrated into the solver.
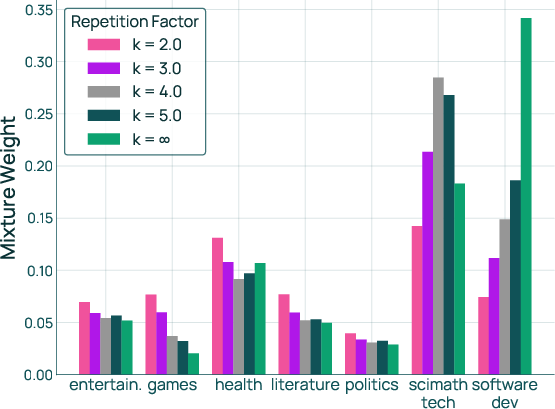
- Domain-specific repetition tolerance: A single global is assumed; domains differ in repetition sensitivity/quality—learning or estimating domain-specific caps or diminishing-returns curves is not addressed.
- Overlap and dedup across domains: Cross-domain duplication and shared content can distort effective repetition; the framework does not account for overlap-aware constraints or measurements.
- Data quality signals: The surrogate depends only on mixture ratios; integrating domain-level quality features (e.g., perplexity, toxicity, document depth, filtering scores) to inform the regression is left unexplored.
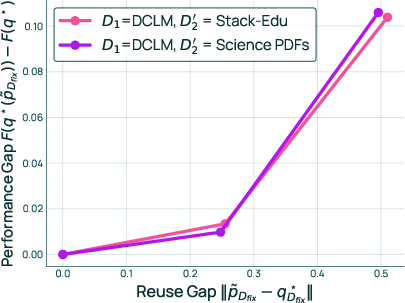
- Mixture reuse decision rules: FullMixtureReuse and PartialMixtureReuse are presented, but there is no algorithmic criterion to decide when to reuse vs. recompute (e.g., tests based on measured coupling, influence estimates, or predicted performance drift).
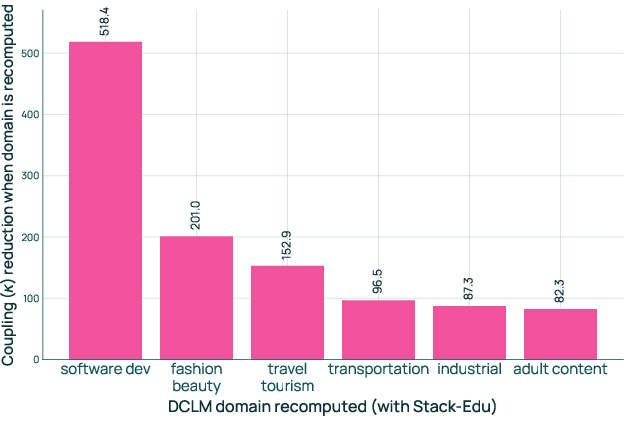
- Selecting domains for PartialMixtureReuse: How to choose which “unaffected” domains to recompute to reduce coupling (and by how much) is not formalized; automated selection strategies are an open problem.
- Guarantees for mixture reuse: Only qualitative analysis is given (ratio drift and coupling); formal bounds on performance loss under reuse and estimators to predict this loss before retraining are missing.
- Robustness to large domain shifts: Reuse is evaluated over five updates to 64 domains; behavior under more extreme updates (massive additions/removals, large re-partitioning, or substantial domain revisions) is not assessed.
- Long-horizon stability: Accumulated error from repeated reuse across many updates (e.g., 10–20+ iterations) and its mitigation (e.g., periodic partial/full resets) are not studied.
- Online/offline hybrid strategies: The framework is purely offline; combining mixture reuse with online reweighting during the final run (e.g., warm-start online controllers from offline surrogates) is untested.
- Domain taxonomy evolution: When domains are redefined (merge/split, renaming, ontology changes), mapping old ratios to new domains reliably is non-trivial and left unspecified.
- Generalization across corpora and modalities: Experiments focus on English web-style corpora; multilingual, multimodal, or highly specialized domains (e.g., biomedical, legal) remain unevaluated.
- Bias, safety, and fairness: How different mixes trade off social biases, toxicity, or safety risks is not measured; adding constraints or objectives for equity and safety is not addressed.
- Overfitting to the evaluation suite: Optimizing to a fixed set of 52 tasks risks Goodhart effects; methods to audit or prevent over-specialization (e.g., rotating validation tasks, holdout benchmarks) are not discussed.
- Compute accounting and wall-clock: Savings are reported as “% fewer proxy runs”; comprehensive wall-clock/energy/cost comparisons—including solver time, data curation overheads—are not provided.
- Transfer across tokenizer/architecture changes: Reuse across changes in tokenization schemes or model architectures is not evaluated; methods to adapt mixes under such shifts are an open question.
- Curriculum/scheduled mixing: The work assumes static for the target run; whether schedule-based mixtures (curricula) outperform fixed mixes, and how to derive schedules from the surrogate, is unexplored.
- Validation of BPB-to-accuracy link at larger scales: While prior work suggests BPB correlates with accuracy, direct validation that BPB-minimizing mixes maximize accuracy for 7B–32B+ models is missing.
- Comparative compute–performance tradeoff: Head-to-head comparisons with dynamic approaches (e.g., DoReMi/DoGE) under equalized compute budgets are absent; it is unclear when offline + reuse is preferable versus dynamic methods.
- Sensitivity to domain count : Most in-depth results are for topics; whether O() scaling, regression fit, and solver behavior hold for (e.g., hundreds of domains) is unverified.
- Automated prior selection: When strong priors are unavailable, the natural distribution is used; strategies to learn or adapt priors from preliminary runs or metadata are not explored.
- Statistical validation of regression fit: Model selection uses Pearson correlation on held-out mixes; analyses of heteroskedasticity, outliers, or cross-validation strategies (and their impact on downstream performance) are missing.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, organized by sector and role. Each item notes key dependencies or assumptions that may impact feasibility.
- Software/AI industry (foundation model training)
- Adopt OlmixBase in LM pretraining pipelines to systematize data mixing and cut compute costs.
- Actions: use 30M-60M proxy models; set swarm size to K ≥ 3(m+1); fit per-task log-linear regressions; choose sparse swarms for topic-level domains and dense swarms for source-level domains; solve with an exact convex solver plus KL regularization (λ ≈ 0.05); enforce repetition constraints during optimization (not in swarm sampling).
- Outcomes: ~11.6% downstream improvement vs natural distribution, 3.05× data-efficiency, and up to 74% reduction in proxy runs when re-mixing after domain updates.
- Assumptions/dependencies: access to Olmix code/data; availability of per-task BPB evaluation; adequate proxy compute; high-quality domain partitioning; proxy-to-target transfer holds at your scales.
- Integrate mixture reuse into MLOps for evolving datasets.
- Actions: implement FullMixtureReuse when domain updates are small and task coupling is low; use PartialMixtureReuse when reused domains are strongly coupled with updated ones (to recover up to 98% of full recomputation gains at 67% fewer proxy runs).
- Tools/products/workflows: “Mixture Reuse Orchestrator” to detect update types (add/remove/partition/revise), estimate coupling, and select reuse strategy; CI/CD hooks for automated rebalancing; dashboards for mix deltas and predicted performance.
- Assumptions/dependencies: simple telemetry for task-domain coupling; consistent downstream evaluation; governance process to approve mix changes.
- Data repetition governance in data-constrained training
- Actions: formalize and enforce a repetition cap k via optimization constraints; instrument training data loaders to respect per-domain caps p_j ≤ k·N_j/R.
- Tools/workflows: “Data Repetition Guardrail” policy and executor; red-team checks to detect over-repetition or memorization risks.
- Assumptions/dependencies: accurate counts of available tokens per domain; chosen k aligned with performance vs. memorization risk tolerance.
- Sector-specific deployments
- Healthcare (clinical and biomedical LMs)
- Use repetition constraints to cap oversampling of scarce clinical notes; center swarms on known-good priors (e.g., PubMed proportion) and reuse mixtures as hospital systems add/remove datasets.
- Product/workflow: “ClinicalMix Planner” for safe allocation across EHR notes, guidelines, literature; mixtures auto-adjust with new sources.
- Assumptions/dependencies: de-identified data availability; strict audit of repetition to manage privacy/memorization; domain coupling monitored (e.g., clinical QA vs. biomedical reasoning).
- Finance (analyst and compliance LMs)
- Employ mixture reuse for frequent additions (quarterly filings, earnings calls); per-task regressions prioritized for code-like tasks (parsing) and QA tasks (financial QA).
- Product/workflow: “FinMix Rebalancer” to rebalance weights when new SEC filings arrive, keeping compute within budget.
- Assumptions/dependencies: robust domain partitioning (filings/news/research); availability of downstream finance task suite and BPB telemetry.
- Education (tutoring and content LMs)
- Balance textbooks, teacher-created content, and forum Q&A; cap repetition on exam datasets to reduce overfitting; reuse mixtures as curricula change.
- Product/workflow: “CurriculumMix” that updates the mix per term and tracks student-task performance shifts.
- Assumptions/dependencies: representative educational task suite; controlled access to sensitive student data; topic-level sparse swarms favored to drop low-signal domains.
- Software/dev tools (code LMs and assistants)
- Mix repositories, issue trackers, and Q&A; use per-task models to optimize for coding capabilities; apply mixture reuse when new repos or languages are added.
- Product/workflow: “CodeMix Tuner” integrated with repo ingestion pipelines; exact solver with KL regularization keeps mix close to trusted baselines.
- Assumptions/dependencies: high-quality deduplication; reliable code evaluation tasks; careful repetition caps for niche languages.
- Multilingual models (fair allocation across languages)
- Apply repetition caps to avoid overfitting low-resource languages while maintaining coverage; sample sparse swarms at topic level to identify low-signal content to exclude.
- Product/workflow: “LangMix Allocator” to set per-language caps and monitor downstream parity across language tasks.
- Assumptions/dependencies: accurate token inventories per language; parity metrics; ability to audit cross-language coupling.
- Academia and research labs
- Reproducible, low-cost mixture studies using proxy swarms
- Actions: run 15M–30M proxies with per-task log-linear regressions; report swarm configuration; publish mixture ratios with BPB correlations; center swarms on natural distributions when priors are uncertain.
- Outcomes: faster iteration on data mixing hypotheses; clearer ablations in papers; standardized reporting of mix choices.
- Assumptions/dependencies: access to Olmix repo/dataset, CVXPY or equivalent solver; consistent BPB evaluation suite.
- Policy and governance
- Mixture reporting and environmental impact
- Actions: document domain weights, repetition caps, and reuse strategy per release; track compute saved by reuse (e.g., 67–74% fewer proxy runs) to report emissions reductions.
- Tools/workflows: “Mixture Governance Dashboard” with versioned mix records and audit trails.
- Assumptions/dependencies: internal compliance processes; willingness to disclose high-level mixing policies; carbon accounting methodology.
- Daily life and small organizations
- Lightweight domain-specific assistants (small-scale LMs)
- Actions: use Olmix on open-source corpora to tailor assistants for internal documentation or niche communities; cap repetition for small datasets; select sparse topic swarms to drop low-signal data.
- Tools/workflows: CLI to import domain folders, run a small proxy swarm, and emit sampling ratios and loaders.
- Assumptions/dependencies: modest GPU budget for proxies; simple task suite to drive per-task regressions.
Long-Term Applications
These use cases extend Olmix’s ideas and require further research, scaling, or tooling maturity before broad deployment.
- MixOps platforms for end-to-end “mixture engineering”
- Description: A managed platform that unifies domain discovery, swarm design, per-task regression, constrained optimization, and mixture reuse—with SLAs, observability, and governance.
- Potential tools/products: “MixOps Studio,” “Domain Coupling Analyzer,” “Mix Budget Planner,” and “Risk & Compliance Guardrails.”
- Dependencies: strong proxy-to-target transfer at large scales (≥70B), robust task telemetry, organizational standards for mix documentation.
- Multi-objective mixture optimization (capability, safety, fairness, cost)
- Description: Extend per-task regressions to multi-objective optimization that balances code/math/QA performance with safety alignment, fairness across languages, and compute/carbon costs.
- Dependencies: reliable multi-objective metrics; convex formulations or efficient solvers; principled regularization to manage noisy surrogates.
- Online/dynamic mixing during pretraining
- Description: Combine offline schema with online adjustments (curriculum schedules, drift-aware updates) to improve sample efficiency while controlling repetition and stability.
- Dependencies: stable update rules; robust convergence under dynamic sampling; safeguards to avoid catastrophic forgetting.
- Automated domain partitioning and embedding-driven reuse
- Description: Generate domains via clustering and semantic signals; blend Olmix’s reuse with embedding-based weighting to transfer ratios when adding novel but related domains.
- Dependencies: validated domain discovery algorithms; coupling estimation from embeddings; guarantees on reuse quality.
- Mixture-aware scaling laws and transfer calibration
- Description: Formalize scaling laws that explicitly account for mixture composition, repetition caps, and proxy-to-target transfer noise; deliver better guidance for K and proxy sizes at new scales.
- Dependencies: longitudinal studies across model sizes and families; statistical calibration of regression noise; theoretical bounds on reuse performance.
- Sector standards and regulation for mixture transparency
- Description: Establish industry norms to disclose high-level mixture policies (caps, priors, reuse strategy), especially for sensitive sectors (healthcare, education, public-sector models).
- Dependencies: policy frameworks; consensus on what to disclose; mappings between mixture choices and risk profiles (privacy, memorization).
- Carbon-aware mixture recomputation scheduling
- Description: Plan recomputation windows and reuse strategies using grid carbon intensity forecasts, minimizing environmental impact while maintaining performance.
- Dependencies: integration with carbon data sources; scheduling infrastructure; acceptance of slight performance trade-offs for greener runs.
- Privacy-aware repetition and memorization modeling
- Description: Connect repetition constraints and memorization risk models; adapt caps per domain sensitivity and legal constraints (e.g., clinical notes, proprietary code).
- Dependencies: reliable memorization metrics; legal guidance; per-domain sensitivity catalogs.
- Cross-family transfer guarantees
- Description: Validate how Olmix’s regressions and reuse transfer across architectures and tokenizer schemes; build confidence for heterogeneous fleets and continual upgrades.
- Dependencies: broad empirical validation; adaptation layers for different tokenizers; automated recalibration workflows.
General assumptions and dependencies across applications
- Reliable per-task BPB evaluations and task suites representative of intended capabilities.
- Adequate proxy compute to achieve K ≥ 3(m+1) and proxy sizes ≥15M parameters for trustworthy transfer.
- High-quality domain curation (topics vs. sources), deduplication, and accurate token inventories.
- Access to optimization tooling (e.g., CVXPY) and operational dashboards for governance.
- Organizational willingness to adopt mixture reporting and to standardize reuse strategies.
Glossary
- Bits-per-byte (BPB): A compression-based metric for model performance, defined as the negative log-likelihood per UTF-8 byte. "We measure BPB (bits-per-byte) over gold responses on $52$ downstream tasks spanning math, code, and commonsense QA."
- Chinchilla: A data–compute scaling reference used to describe token multipliers for training regime sizing. "100B tokens (5x Chinchilla)."
- Compute-constrained: A regime where available computation limits training, often assuming effectively infinite data. "Existing mixing methods assume compute-constrained settings with effectively infinite data and provide no way to control repetition."
- CVXPY: A convex optimization library used to solve exact mixture optimization problems. "The exact solver uses CVXPY to compute the optimal mix."
- Data-constrained: A regime where requested training tokens exceed available unique data, causing potential over-repetition. "In practice, LM training is often data-constrained: the target modelâs requested training tokens exceed the available data."
- Data mixing: Determining domain ratios in the training corpus to optimize downstream performance. "Data mixing---determining the ratios of data from different domains---is a first-order concern for training LMs."
- Data provenance: The origin or source of data used to define coarse-grained domains. "coarse-grained sources (defined by data provenance)"
- Data repetition constraints: Constraints that cap the number of times samples from a domain can be reused during training. "Data repetition constraints"
- Dirichlet (distribution): A probability distribution over mixtures used to sample candidate domain ratios. "samples candidate mixes from a Dirichlet distribution with a natural prior (i.e., a mix proportional to the domain sizes)."
- Dirichlet prior: A prior over mixture weights used when sampling swarms to center exploration around plausible mixes. "We test three Dirichlet priors: 1) the natural distribution (based on domain token counts), 2) a strong prior, and 3) a weak prior"
- Domain embeddings: Learned vector representations of domains used to compute weights without proxy retraining. "computes weights directly from domain embeddings without the swarm-based regression approach of offline methods."
- Downstream tasks: Evaluation tasks used to measure generalization of pretrained models. "We then evaluate this model on a suite of downstream tasks."
- Exact solver: An optimization approach that precisely minimizes the surrogate objective under constraints. "The exact solver uses CVXPY to compute the optimal mix."
- Feasible set: The constrained space of allowable mixture weights in optimization. "where denotes the feasible set, which may be the full probability simplex or a restricted subset."
- Function fitting-based offline methods: Approaches that learn a surrogate mapping from mixtures to performance using proxy runs prior to final training. "also described as ``function fitting-based offline methods'' in~\citet{liu2025rethinkingdatamixturelarge}'s survey."
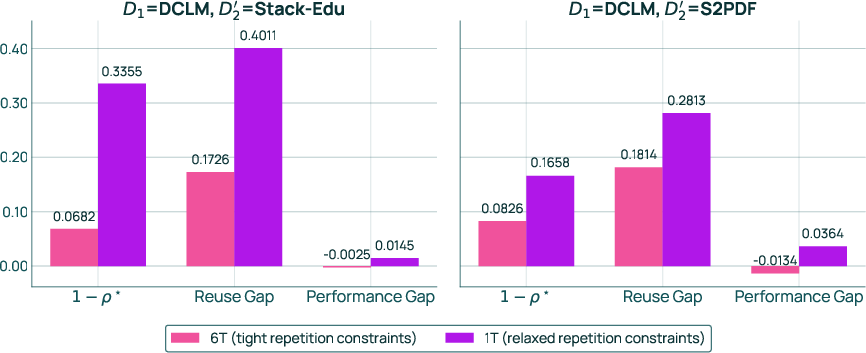
- FullMixtureReuse: A recomputation mechanism that freezes relative weights among unaffected domains and only recomputes weights for affected parts after a domain update. "We propose FullMixtureReuse, a mechanism that reuses the existing mix over the domains that are unaffected by the update."
- Gaussian Process regression: A nonparametric regression model with kernel functions used to predict performance from mixture weights. "Gaussian Process regression with an RBF kernel scaled by a signal variance term and augmented with independent Gaussian observation noise."
- Infinite data setting: An assumption where data availability is unbounded, removing repetition constraints. "As the constraint relaxes from $2$ to (the infinite data setting), the mixture weights on high-utility domains, such as software development, monotonically increase."
- Kernel ridge leverage scores: Scores derived from kernel ridge regression used to weight domains based on embeddings. "computing domain weights from learned embeddings using kernel ridge leverage scores, which allows direct transfer to new data without proxy retraining."
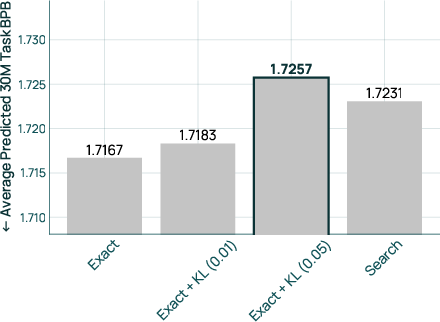
- Kullback–Leibler (KL) regularization: A penalty term that encourages proposed mixes to stay close to a prior distribution. "We recommend using an exact solver with a KL regularization of 0.05 to solve the mixture optimization problem."
- LightGBM: A gradient boosting framework using decision trees applied to regression over mixture–performance pairs. "LightGBM~\citep{lightgbm}: a gradient boosting regression framework using decision trees."
- Log-linear model: A parametric regression model mapping mixture weights to predicted performance via an exponential of linear combinations. "the log-linear model adapted from~\citet{ye2025datamixinglawsoptimizing} achieves the best overall downstream performance"
- Lower-dimensional subspace: A reduced parameter space enabling cheaper recomputation by fixing part of the mixture. "This restricts recomputation (via OlmixBase) to a lower-dimensional subspace, reducing computational cost."
- Mixture optimization: The process of solving for mixture weights that minimize predicted average BPB subject to constraints. "Step 3: Mixture optimization. We propose a mix by solving an optimization problem that uses the regression model as a surrogate for true performance."
- Mixture reuse: Recomputing only parts of a mixture after domain updates by leveraging previous ratios. "We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update."
- Natural distribution: A baseline mixture proportional to domain sizes used for comparison or as a prior. "the natural distribution (a baseline with ratios proportional to domain sizes)"
- Natural prior: A Dirichlet prior centered on the natural distribution during swarm sampling. "Dirichlet with natural prior"
- O(m) sample complexity: The finding that the number of proxy runs needed scales linearly with the number of domains. "Therefore, runs are sufficient for strong performance"
- Offline mixing schema: A three-step framework—swarm, regression, optimization—used to design data mixtures before final training. "Many mixing methods that achieve promising results follow a common offline mixing schema"
- PartialMixtureReuse: A reuse strategy that recomputes weights for selected unaffected domains to reduce coupling effects. "We propose PartialMixtureReuse, an extension of FullMixtureReuse that provides a middle ground between full reuse and full recomputation"
- Probability simplex: The geometric space of nonnegative mixture vectors that sum to one. "which may be the full probability simplex or a restricted subset."
- Proxy model: A smaller model trained on candidate mixtures to learn the mapping from domain ratios to performance. "train a set of smaller proxy models on different mixtures (a ``swarm'')"
- RBF kernel: The radial basis function kernel used in Gaussian Process regression for smooth function approximation. "Gaussian Process regression with an RBF kernel scaled by a signal variance term"
- Regression fit: A measure (e.g., Pearson correlation) of how well the regression’s predictions match true performance. "As an intermediate metric, we also report the regression fit (Pearson correlation between predicted and true per-task BPB) on a held-out set of mixtures."
- Search-based solver: A heuristic that samples candidate mixtures from a distribution and selects the best by predicted performance. "The search-based solver, used in RegMix~\citep{liu2025regmixdatamixtureregression}, samples candidate mixes from a Dirichlet distribution with a natural prior (i.e., a mix proportional to the domain sizes)."
- Spearman rank correlation: A nonparametric measure of monotonic relationship used to assess proxy–target transfer reliability. "We compute the Spearman rank correlation between proxy and target model performance (average BPB) to quantify transfer"
- Swarm: A set of proxy runs on different mixtures used to fit the regression surrogate. "train a set of smaller proxy models on different mixtures (a ``swarm'')"
- Swarm distribution: The sampling distribution over mixtures used to construct the proxy swarm. "RQ3: Swarm distribution. We study the distribution from which swarm mixtures should be sampled."
- Swarm size: The number of proxy runs used to sample the mixture space. "RQ2: Swarm size in terms of number of domains."
- Token budget: The fixed number of tokens allocated for training across domains or languages. "distributes a fixed token budget to maximize uniform coverage across languages while capping repetitions to avoid overfitting on low-resource languages."
Collections
Sign up for free to add this paper to one or more collections.