UniT: Unified Multimodal Chain-of-Thought Test-time Scaling
Abstract: Unified models can handle both multimodal understanding and generation within a single architecture, yet they typically operate in a single pass without iteratively refining their outputs. Many multimodal tasks, especially those involving complex spatial compositions, multiple interacting objects, or evolving instructions, require decomposing instructions, verifying intermediate results, and making iterative corrections. While test-time scaling (TTS) has demonstrated that allocating additional inference compute for iterative reasoning substantially improves LLM performance, extending this paradigm to unified multimodal models remains an open challenge. We introduce UniT, a framework for multimodal chain-of-thought test-time scaling that enables a single unified model to reason, verify, and refine across multiple rounds. UniT combines agentic data synthesis, unified model training, and flexible test-time inference to elicit cognitive behaviors including verification, subgoal decomposition, and content memory. Our key findings are: (1) unified models trained on short reasoning trajectories generalize to longer inference chains at test time; (2) sequential chain-of-thought reasoning provides a more scalable and compute-efficient TTS strategy than parallel sampling; (3) training on generation and editing trajectories improves out-of-distribution visual reasoning. These results establish multimodal test-time scaling as an effective paradigm for advancing both generation and understanding in unified models.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What this paper is about (a quick overview)
This paper shows how to teach one AI system to “think out loud” and improve its own answers step by step when working with both words and pictures. Instead of making one guess and stopping, the AI plans, checks its work, and edits its result over several rounds. The authors call their approach UniT (Unified Multimodal Chain‑of‑Thought Test‑time Scaling).
In short: it’s about helping an AI that can read, write, and draw to slow down, reason, and fix mistakes—just like a student who double‑checks and revises their homework.
2) The big questions the paper asks
The authors set out to answer a few simple but important questions:
- Can one single AI model handle planning, checking, and fixing across both text and images without switching between different tools?
- If we train it on short, step‑by‑step examples, will it still learn to handle longer, more complicated problems at test time?
- Is it better to improve one result over several rounds (sequential) than to make lots of separate guesses and pick the best (parallel)?
- Does practicing both “making” (image generation/editing) and “understanding” (visual reasoning) make the AI more reliable overall?
3) How they did it (the approach, with simple explanations)
To teach the AI to reason and revise, the authors built a training pipeline and an inference (test‑time) strategy.
Here’s the idea in everyday terms:
- Imagine you ask an AI: “Make a picture of a brown dog wearing a red collar, catching a blue frisbee in a sunny park.”
- The AI draws something.
- A “checker” looks at the picture and explains what’s wrong (“No frisbee,” “collar is the wrong color,” “park doesn’t look sunny”), then suggests specific edits.
- An “editor” makes those fixes.
- Repeat until the picture meets the instructions.
This loop creates training examples that show how to think, check, and improve step by step.
To do this at scale, they used an “agentic” data creation process (multiple helper AIs) to build high‑quality training data:
- Start with a user prompt (the request).
- Generate an initial image.
- Have a vision‑LLM (a “checker”) explain what’s wrong and propose edits (this is the “chain of thought”).
- Apply the edits with an image editor.
- Repeat until the result looks right.
From these loops, the model learns three useful “habits of mind”:
- Verification: checking if the result really follows the instructions.
- Subgoal decomposition: breaking a big task into smaller steps (“first add the frisbee, then fix the collar, then brighten the lighting”).
- Content memory: remembering what’s already in the image across rounds so it stays consistent (the same dog stays the same dog).
After collecting about 12,000 of these multi‑round examples, they fine‑tuned a single unified model (called Bagel) so it could do everything itself—plan, generate, check, and edit—without needing those separate helper AIs at test time.
Finally, at test time they control how much “thinking and editing” the model does with a simple knob: the number of rounds. The more rounds you give it, the more chances it has to reason, check, and improve. They call this test‑time scaling.
Two ways to spend compute (time/effort) at test time:
- Sequential (step‑by‑step): Make one result, reflect on it, edit it, and repeat. Like revising a draft.
- Parallel (best‑of‑N): Make many different results once and pick the best. Like writing 10 drafts and choosing one.
They compare these two strategies head‑to‑head.
4) What they found (main results and why they matter)
Here are the key takeaways, written plainly:
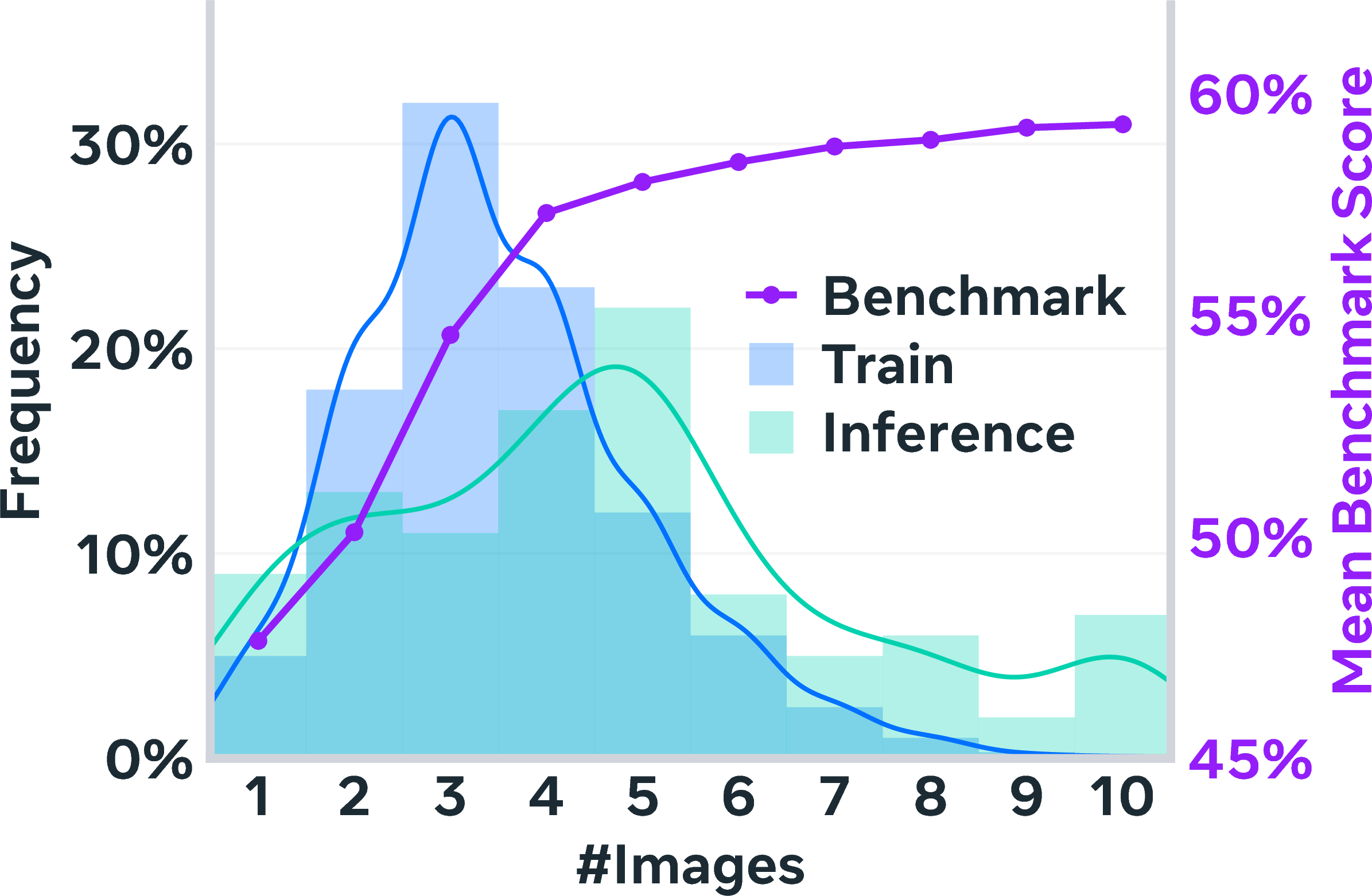
- The model learned to handle longer problems than it saw in training.
- Even though it was trained on shorter reasoning chains (about 3–4 rounds), at test time it comfortably handled longer chains (about 5 rounds). This means “thinking more” at test time works—even beyond what it practiced.
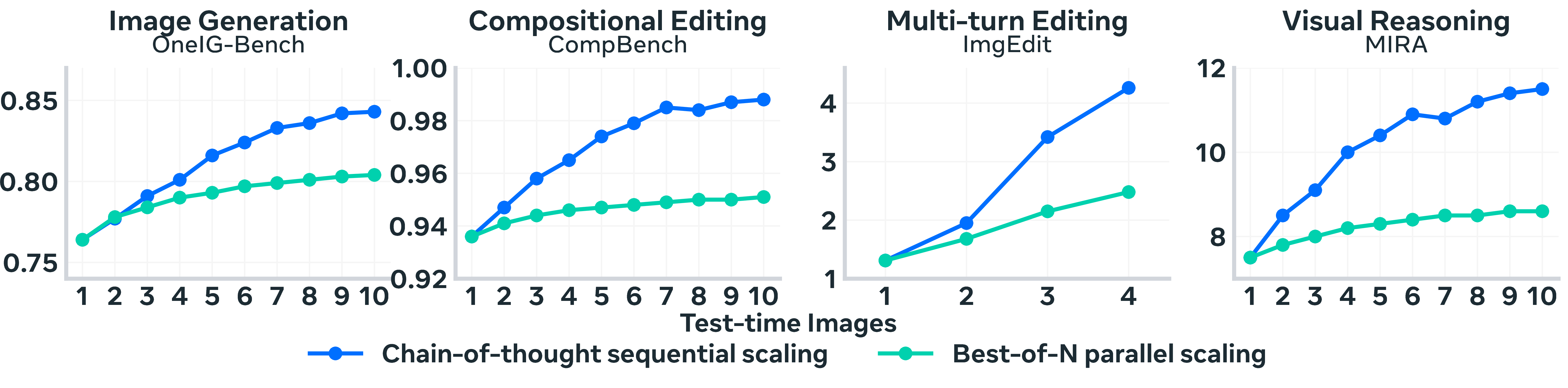
- Step‑by‑step revision (sequential) beats many independent guesses (parallel) for the same compute.
- It reached similar or better quality while using about 2.5x less generation work than best‑of‑N sampling. In other words, fixing and improving one draft is more efficient than spinning up lots of unrelated drafts.
- It improved both making images and understanding images:
- Compositional generation (following complex prompts): strong gains over single‑pass generation (e.g., around +10% on OneIG).
- Multi‑object editing: better accuracy and quality (+ improvements on CompBench).
- Multi‑turn editing (fixing the same image over several user turns): big boosts in human ratings (more than double in their tests), thanks to better memory and consistent edits.
- Visual reasoning (answering questions about images, puzzles, or patterns): large improvements (e.g., ~+53% on one reasoning test), showing that the “think‑check‑fix” habit helps with understanding too—not just drawing.
- The three learned habits—verification, subgoal decomposition, and content memory—each mattered:
- Removing any one of them hurt performance. For example, without content memory, multi‑turn editing dropped a lot because the model forgot what it had already changed.
Why this matters: these results show that giving a single, unified model time to think and iterate at test time is a powerful, general trick that improves both creation and comprehension across text and images.
5) What this could mean (implications and impact)
- Smarter creative tools: Image generators and editors that can follow complex instructions more faithfully by checking and revising instead of guessing once.
- More reliable assistants: Systems that solve visual puzzles, analyze images, or follow multi‑step editing requests can reason in steps, verify their work, and remember context over several turns.
- A simple “quality knob”: You can trade a bit more time (more rounds) for better results when you need it.
- Broad reach: The same strategy could extend to video, audio, and other media, not just still images.
A few caveats:
- More rounds mean more compute (time/money). Future work will make this faster and smarter about when to stop.
- Some tough cases remain (fine‑grained physical logic, very tangled instructions). Better checkers and physics‑aware reasoning could help.
Overall: UniT shows that teaching one AI to plan, check, and revise across words and images—step by step—makes it noticeably better at both making things and understanding them.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues that future work could address, organized to be concrete and actionable.
- Dependence on teacher models for data synthesis: Quantify and mitigate the bias/error propagation from Flux Pro and Qwen3‑VL into UniT (e.g., compare training with weaker/stronger teachers, measure sensitivity to verifier/editing errors, and assess how teacher mistakes shape learned verification heuristics).
- Limited data scale and diversity: Establish scaling laws for trajectory count/length and prompt diversity, and evaluate whether 12k trajectories suffice across long‑tail compositional prompts, rare attributes, and complex spatial relations.
- Generalization across architectures: Validate UniT on multiple unified model families (e.g., Janus, Emu3, Chameleon) and diffusion‑augmented variants to confirm portability beyond Bagel; report any architecture‑specific adaptations.
- Lack of adaptive budget policies: Replace fixed round budgets with learned or RL‑based adaptive allocation (per‑example), including confidence‑aware early stopping and compute‑performance trade‑off curves.
- Unreliable verification and “reflection hallucinations”: Develop calibrated, uncertainty‑aware verifiers (e.g., ensembles, process reward models, or external VLM verifiers) to reduce false positives/negatives in self‑critique and prevent unnecessary/harmful edits.
- Constraint- and physics-aware refinement: Integrate explicit constraints, 3D/geometry checks, or differentiable physics/simulation to address fine‑grained spatial reasoning, perspective, occlusions, and physical plausibility that iterative edits currently fail to correct.
- Fair compute accounting in sequential vs. parallel comparisons: Reevaluate conclusions when including selection/verification costs, stronger re-rankers (learned reward models), or majority-vote/self‑consistency to ensure claims about efficiency hold under matched total compute.
- Latency and memory scaling beyond C=10: Profile end‑to‑end latency, peak memory, and context growth; test KV‑cache reuse, image token compression, or external memory to sustain longer (>10) rounds without quality collapse.
- Training trajectory length vs. test-time generalization: Systematically vary training chain lengths and measure how they shape beyond‑training generalization; study curriculum/budget‑forcing schedules that optimize extrapolation.
- Guidance hyperparameters: Provide sensitivity analysis of nested text/image classifier‑free guidance (CFG) scales; explore adaptive, learned guidance schedules per round/task and their impact on alignment and consistency.
- Evaluation breadth and rigor: Add human preference studies for text‑to‑image generation, report statistical significance/variance, and employ robustness‑oriented metrics (beyond CLIP/LPIPS) that better reflect multi‑constraint satisfaction.
- Real-user distribution shift: Test on in‑the‑wild interactive prompts and conduct user studies to evaluate instruction interpretation, satisfaction, and usability of budget forcing and multi‑turn editing UX.
- Reproducibility gaps: Release full training/inference code, detailed hyperparameters, dataset statistics, and seeds; clarify Bagel model size, tokenizer settings, image resolution/tokenization, and training schedules to enable replication.
- Lack of RL or verifier‑guided training: Explore reinforcement learning with outcome/process reward models for multimodal chains (e.g., preference models for alignment and image fidelity) to improve reflection quality and edit selection.
- Search strategies beyond sequential chains: Compare to tree‑ or graph‑based editing (MCTS/beam search over edits), hybrid sequential‑parallel strategies, and verifier‑guided branch‑and‑bound to test whether more structured search outperforms linear refinement.
- Degradation loop detection and mitigation: Design mechanisms (edit scoring, rollback checkpoints, change‑point detection, or edit‑distance gating) to avoid quality‑regression cycles when verification misfires.
- OOD domain generalization: Evaluate on distinct domains (medical, satellite, sketches, cartoons), resolutions, and camera models to assess robustness and failure patterns under larger distribution shifts.
- Safety, bias, and misuse: Assess sensitive content generation/editing, demographic and cultural biases, and include guardrails (filters, watermarks) given that TTS may amplify undesirable content if not constrained.
- Data contamination and leakage: Strengthen de‑duplication beyond 5‑gram (semantic and image‑level dedup), audit overlap with teacher/model pretraining corpora, and report contamination checks for all benchmarks.
- Metric limitations: Quantify correlation of CLIP‑based and local metrics with human judgments for compositional correctness; include ablations showing when metrics mis-rank outputs and how that affects conclusions.
- Content memory capacity and context limits: Measure identity/attribute retention over many rounds and long contexts; study how context length and image history size affect recall, drift, and error accumulation.
- Data filtering thresholds and curation design: Analyze sensitivity to LPIPS and other filter thresholds, and whether stricter/looser filters change learned behaviors (e.g., minimal-change rounds vs. meaningful edits).
- Source of gains (data vs. method): Disentangle contributions from chain‑of‑thought data, unified architecture, and CFG; include ablations comparing UniT to a modular teacher‑student pipeline with matched compute to isolate where improvements originate.
- Extending to additional modalities: Prototype UniT for video/audio (temporal consistency, cross‑frame memory, and budget forcing over frames), and study whether cognitive behaviors transfer to temporal reasoning/editing.
- Robustness to adversarial or conflicting instructions: Evaluate on ambiguous, contradictory, or adversarial prompts and propose strategies (conflict detection, constraint reconciliation) for stable refinement.
Glossary
- Agentic data synthesis: Automated generation of training trajectories by multi-model agents to induce desired behaviors. "Agentic data synthesis to induce cognitive behaviors through multi-round trajectories."
- Autoregressive approaches: Generative modeling that predicts the next token in a sequence; here extended to both text and image tokens. "Autoregressive approaches extend next-token prediction to both text and discrete image tokens."
- Best-of-N sampling: A parallel inference strategy that generates N candidates and picks the best according to a selection criterion. "Parallel scaling generates multiple independent candidates and selects the best via criteria such as best-of-N sampling"
- Budget forcing: A mechanism to control inference compute by enforcing a fixed number of reasoning/generation rounds. "We adapt budget forcing~\citep{tyen2024lamini} from text-only to multimodal test-time scaling."
- Chain-of-thought (CoT): Explicit step-by-step reasoning traces used to plan, verify, and refine outputs. "chain-of-thought sequential scaling outperforms best-of-N parallel scaling across generation and reasoning benchmarks."
- Classifier-free guidance (CFG): A guidance technique that mixes conditional and unconditional predictions to steer generative models. "classifier-free guidance (CFG) schemes applied in a nested manner"
- Content memory: The capability to retain and use information about visual content across multiple refinement rounds. "content memoryâmaintaining understanding of visual content across rounds through unified multimodal context."
- Diffusion models: Generative models that iteratively denoise to produce images from noise. "image generation via diffusion models dominates wall-clock time"
- EOS: The end-of-sequence token that signals termination of generation. "we suppress EOS, append ``Let's edit the image", wait for reasoning completion, then force image generation."
- HPSv3: A human preference scoring model used to select the best image among candidates. "Parallel scaling generates independent images and selects the best via HPSv3~\citep{ma2025hpsv3}."
- Interleaved multimodal inputs and outputs: Mixed sequences of text and images handled within a single model context. "as they naturally handle interleaved multimodal inputs and outputs."
- KV-cache reuse: Reusing transformer key/value caches across rounds to accelerate inference. "including speculative decoding, KV-cache reuse across rounds, and early stopping when the model determines satisfaction"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric for measuring visual changes. "perceptual editing distance below LPIPS "
- Majority voting: Selecting an answer based on the plurality of independent model outputs. "or majority voting~\citep{irvine2023rewardingchatbotsrealworldengagement}"
- Monte Carlo Tree Search: A stochastic tree-based search algorithm used to explore solution spaces with guided rollouts. "Tree-based methods such as Monte Carlo Tree Search"
- Out-of-distribution: Data or tasks that differ from the training distribution, used to test generalization. "out-of-distribution visual reasoning on MIRA"
- Parallel scaling: Test-time strategy that generates multiple independent outputs simultaneously. "Parallel scaling generates multiple independent candidates and selects the best via criteria such as best-of-N sampling"
- Process reward models: Models that evaluate intermediate reasoning steps to guide search and refinement. "using process reward models~\citep{lightman2023letsverifystepstep, wang-etal-2024-math, wang2024helpsteer2opensourcedatasettraining} to guide structured search."
- Prompt adherence: The degree to which generated content follows the given textual instruction. "independent control over prompt adherence and visual consistency."
- PSNR: Peak Signal-to-Noise Ratio; an image fidelity metric (in decibels). "PSNR(dB)"
- REBASE: An inference-time search method that structures exploration and refinement. "and REBASE~\citep{wu2024inference} occupy a middle ground"
- Self-refinement: Iterative self-critique where models analyze deficiencies and improve their outputs over rounds. "Self-refinement approaches~\citep{madaan2024self} exemplify this by having models explicitly reason about deficiencies and produce progressively better solutions."
- Sequential scaling: Test-time strategy that iteratively refines a single output across multiple rounds. "Sequential scaling~\citep{snell2024scalingllmtesttimecompute, hou2025advancinglanguagemodelreasoning, lee2025evolvingdeeperllmthinking} enables iterative refinement where models critique and improve outputs across multiple rounds."
- Speculative decoding: An acceleration technique that drafts and verifies tokens to speed up generation. "including speculative decoding, KV-cache reuse across rounds, and early stopping when the model determines satisfaction"
- SSIM: Structural Similarity Index; a perceptual metric for image quality. "SSIM"
- Subgoal decomposition: Planning by breaking complex instructions into smaller, sequential steps. "subgoal decompositionâbreaking complex instructions into sequential planning steps"
- Test-time scaling (TTS): Allocating additional compute during inference for extended reasoning and refinement to improve performance. "test-time scaling (TTS)âallocating additional computational resources during inference through extended chain-of-thought reasoning, verification, and iterative refinement"
- Unified integrated transformers: Architectures that tightly couple language modeling and diffusion within a single transformer. "Unified integrated transformers~\citep{deng2025emerging, liang2024mixture, janusflow2024, shi2024llamafusion, transfusion} deeply integrate language modeling and diffusion within single architectures."
- Unified multimodal models: Single architectures that perform both understanding and generation across modalities like text and images. "Unified multimodal models~\citep{deng2025emerging,wu2025janus,zhou2024transfusion} aim to merge vision, language, and more modalities into a single architecture capable of both understanding and generation."
- Verification: Evaluating whether outputs satisfy the instructions or constraints. "verificationâevaluating outputs against instructions"
- Vision-LLM (VLM): A model that jointly processes and reasons over images and text. "A vision-LLM then performs verification - evaluating whether the output satisfies the prompt."
- Visual fidelity: Preservation of image quality and realism during edits or generation. "quality preservationâmaintaining visual fidelity through iterative refinement rather than degradation"
- Visual reasoning: Performing reasoning tasks grounded in visual content or images. "visual reasoning on MIRA"
Practical Applications
Immediate Applications
Below is a concise set of practical use cases that can be deployed with current capabilities, each noting sectors, potential tools/workflows, and key assumptions or dependencies.
- Iterative image editing copilot for creatives (media, advertising, design)
- What: A plugin for tools like Photoshop/Figma that uses UniT’s sequential chain-of-thought (CoT) and content memory to verify instructions, decompose edits into subgoals, and refine images across rounds without degrading quality.
- Tools/workflows: “Budget slider” to control refinement rounds; nested classifier-free guidance (CFG) to balance prompt adherence vs. visual consistency; audit log of reasoning steps; early stopping when verification passes.
- Assumptions/dependencies: Unified multimodal model fine-tuned on multi-round trajectories; GPU-backed inference; guardrails for over-editing; base generation/editing fidelity good enough to avoid physics/attribute-binding errors.
- Requirements-driven compositional generation for product mockups (e-commerce, manufacturing marketing)
- What: A generator that breaks complex briefs (objects, attributes, spatial relations) into sequential plans, verifies constraint satisfaction, and refines to brand-aligned mockups.
- Tools/workflows: Structured prompt templates encoding brand guidelines; automatic verification scores (e.g., CLIP-like, VLM-based); iterative fixes for non-compliance.
- Assumptions/dependencies: Reliable visual verification for subtle attributes; domain-specific guideline encoding; acceptance of added inference latency.
- Multi-turn photo enhancement for consumers (daily life)
- What: A mobile/cloud assistant that preserves subject identity across edits (“remove object”, “change background”, “adjust lighting”) with coherent multi-turn refinement.
- Tools/workflows: On-device caching/KV reuse to reduce latency; user-facing “reasoning trail” toggle; per-step preview + rollback.
- Assumptions/dependencies: Privacy-safe processing; stable content memory; cost-effective cloud serving or efficient on-device variants.
- Visual instruction-following validator in content pipelines (software/content ops)
- What: Automated QA that checks whether generated images meet specifications (objects present, constraints satisfied) and proposes stepwise corrections.
- Tools/workflows: VLM-based verification gates before asset release; confidence thresholds; optional human-in-the-loop review for borderline cases.
- Assumptions/dependencies: Verification has acceptable false positive/negative rates; safe use of CoT logs; clear escalation paths.
- Agentic synthetic data pipeline for multimodal training (academia/ML engineering)
- What: Reproduces the paper’s generation–verification–editing loop to synthesize multi-round trajectories that induce verification, subgoal decomposition, and content memory.
- Tools/workflows: Automated prompt generation, reflection, and editing; quality filters (relevance, regression, minimal visual change); deduplication against test benches.
- Assumptions/dependencies: Access to suitable generators/editors/VLMs; data licensing compliance; compute for curation at scale.
- Visual reasoning tutor for STEM subjects (education)
- What: An interactive tutor that iteratively analyzes diagrams (geometry, puzzles), shows CoT steps, and refines visual explanations based on student prompts.
- Tools/workflows: Budget control by problem difficulty; diagram generation+editing; rubric-aligned verification.
- Assumptions/dependencies: Accuracy safeguards; scope limited to domains where current visual reasoning is reliable; teacher review for assessment integration.
- Sequential scaling to reduce inference compute vs. best-of-N sampling (software/energy efficiency)
- What: Replace parallel sampling/selection with iterative refinement, achieving similar quality with ~2.5× fewer images generated (per paper results).
- Tools/workflows: Switch pipelines to sequential CoT; add early satisfaction checks; KV-cache reuse/speculative decoding across rounds.
- Assumptions/dependencies: Teams accept iterative latency profile; verify that quality matches/beats parallel in target tasks; instrumentation for cost tracking.
- Brand/compliance checker with automated fix suggestions (policy/compliance)
- What: Multi-round checker that flags violations (logo placement, text legibility, accessibility cues) and proposes guided edits until compliance is met.
- Tools/workflows: Policy templates translated into verification prompts; stepwise fixes; compliance scorecard and CoT audit trail.
- Assumptions/dependencies: Policies formalized in machine-interpretable constraints; human sign-off; robust detection of subtle issues.
- Budget forcing controls in generative UIs (software tools)
- What: A “compute budget” knob to specify the number of refinement rounds; system suppresses premature termination and drives additional reasoning/editing steps.
- Tools/workflows: EOS suppression + “Let’s edit the image” prompt injection; round-based checkpoints; final-image selection at the budget limit.
- Assumptions/dependencies: Tuning to prevent degradation loops; user education on budget–latency trade-offs; fallbacks if verification hallucinations occur.
- Benchmarking harness for multimodal TTS (academia/R&D)
- What: Standardized evaluation across sequential vs. parallel scaling with budgets, using OneIG, CompBench, ImgEdit, MIRA metrics and logging round distributions.
- Tools/workflows: Reproducible scripts; compute accounting per image; task-specific metrics; ablation suites for cognitive behaviors and data filters.
- Assumptions/dependencies: Dataset licenses; comparable baselines; compute resources.
Long-Term Applications
The following applications are promising but require further research, scaling, or integration with additional modalities, domains, or safety frameworks.
- Embodied visual planning for robotics (robotics)
- What: Robots that decompose tasks into visual subgoals, verify scene-state after each action, and iteratively refine plans using multimodal CoT.
- Tools/workflows: Camera-grounded verification; planner–controller loop with visual checkpoints; adaptive compute budgets by task difficulty.
- Assumptions/dependencies: Robust real-world perception; physics-aware reasoning; safe integration with control; extension beyond static images to video/3D.
- Medical imaging decision support and QA (healthcare)
- What: Multi-round verification of image annotations/segmentations against diagnostic criteria, proposing refinements to meet clinical standards.
- Tools/workflows: Domain-specific policies/guidelines encoded as constraints; audit logs; human-in-the-loop review.
- Assumptions/dependencies: Clinical validation and regulatory approval; domain-specialized training; strict safety, privacy, and reliability guarantees.
- Autonomous creative agents for end-to-end campaign production (media/marketing)
- What: Agents that plan briefs, generate assets, verify constraints (brand/safety), and iteratively refine across modalities (text, image, video).
- Tools/workflows: Policy/brand constraint engines; process reward models and RLHF for reflection quality; cross-modal memory.
- Assumptions/dependencies: Long-horizon planning stability; content safety; cost-effective scaling; organizational acceptance.
- CAD and industrial design assistants with physics-aware refinement (manufacturing/engineering)
- What: Stepwise image-to-CAD proposals that maintain geometric and physical constraints, verify each refinement stage, and integrate simulation feedback.
- Tools/workflows: Coupling with geometry kernels and simulators; constraint-satisfaction planning; multi-view consistency checks.
- Assumptions/dependencies: Strong physical reasoning; high accuracy requirements; integration with existing CAD workflows.
- Multimodal education platforms across audio/video (education)
- What: CoT-guided video slides/animations that iteratively refine visual explanations and synchronize narration, adapting compute to learner needs.
- Tools/workflows: Video-editing extensions of UniT; pacing controls; teacher dashboards for oversight.
- Assumptions/dependencies: Reliable video editing/generation; scalable compute; pedagogical validation and accessibility compliance.
- Regulatory audit tools with CoT accountability (policy/governance)
- What: Government/enterprise systems that verify generative content against accessibility, misinformation, and safety standards, retaining CoT audit trails for transparency.
- Tools/workflows: Policy codification; red-teaming verifiers; evidentiary logging of reasoning steps.
- Assumptions/dependencies: Legal standards for AI auditability; privacy-preserving CoT handling; robust verifiers under adversarial content.
- Content moderation with self-refinement (platform safety)
- What: Systems that detect sensitive content, propose edits to remove/obfuscate it, verify the fix, and iterate while preserving utility.
- Tools/workflows: Sensitive-content detectors; iterative edit proposals; human escalation.
- Assumptions/dependencies: High-precision detection; adversarial robustness; ethical guidelines and user consent.
- Adaptive compute orchestration in enterprise pipelines (software/ops)
- What: Budget-aware schedulers that allocate test-time rounds based on prompt complexity, cost targets, and SLA constraints.
- Tools/workflows: Complexity estimators; dynamic budget forcing; observability and cost forecasting dashboards.
- Assumptions/dependencies: Accurate complexity predictors; integration with MLOps systems; clear performance/cost trade-off policies.
- RL-based training for budget-aware multimodal reasoning (academia/R&D)
- What: Reinforcement learning that teaches models to use extended inference compute efficiently (budget forcing), guided by process rewards/verifiers.
- Tools/workflows: Scalable RL infrastructure; process reward models; curriculum that mixes short/long trajectories.
- Assumptions/dependencies: Stable RL for large multimodal models; high-quality reward signals; significant compute.
- Safety-critical visual reasoning in autonomy (transportation)
- What: Multi-round verification and refinement for perception decisions (object detection, occlusions), escalating to human or conservative fallback when uncertain.
- Tools/workflows: Real-time budget controls; uncertainty estimation; integration with planning and safety monitors.
- Assumptions/dependencies: Real-time performance; strong base perception; rigorous validation in regulated environments.
Collections
Sign up for free to add this paper to one or more collections.