Stabilizing Native Low-Rank LLM Pretraining
Abstract: Foundation models have achieved remarkable success, yet their growing parameter counts pose significant computational and memory challenges. Low-rank factorization offers a promising route to reduce training and inference costs, but the community lacks a stable recipe for training models from scratch using exclusively low-rank weights while matching the performance of the dense model. We demonstrate that LLMs can be trained from scratch using exclusively low-rank factorized weights for all non-embedding matrices without auxiliary "full-rank" guidance required by prior methods. While native low-rank training often suffers from instability and loss spikes, we identify uncontrolled growth in the spectral norm (largest singular value) of the weight matrix update as the dominant factor. To address this, we introduce Spectron: Spectral renormalization with orthogonalization, which dynamically bounds the resultant weight updates based on the current spectral norms of the factors. Our method enables stable, end-to-end factorized training with negligible overhead. Finally, we establish compute-optimal scaling laws for natively low-rank transformers, demonstrating predictable power-law behavior and improved inference efficiency relative to dense models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper shows a way to train LLMs so they use fewer numbers without losing accuracy. Instead of storing huge “full” weight matrices, the model stores each big matrix as the product of two smaller ones. This is called low-rank factorization and can make training and running the model cheaper. The problem: training this way from the very start often becomes unstable and breaks. The authors propose a simple fix, called Spectron, that keeps training stable and lets these smaller, “factorized” models match the performance of regular large models while using fewer parameters.
What questions are the authors trying to answer?
- Can we train LLMs from scratch using only low-rank (smaller) weights and still get the same quality as regular, full-size models?
- Why do low-rank models tend to become unstable during training?
- Can we fix that instability in a simple, efficient way?
- If we can train this way, how should we best spend our compute: on more parameters or on more training data, to get the best results?
How did they approach the problem?
Think of a big weight matrix as a large, heavy table of numbers. Low-rank factorization writes that big table as two skinny tables multiplied together: if the big matrix is W, they write it as . This cuts memory and compute, but it causes a hidden problem: the two skinny tables can “stretch” in opposite ways (one grows while the other shrinks) and still multiply to the same W. That freedom can make certain “strength” measures of the update blow up, which destabilizes training.
Key ideas in simple terms:
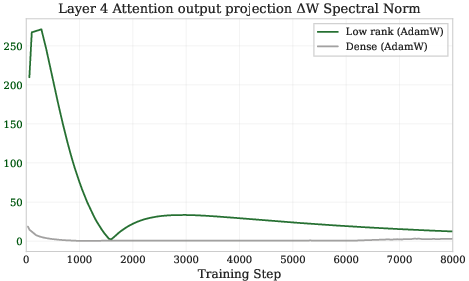
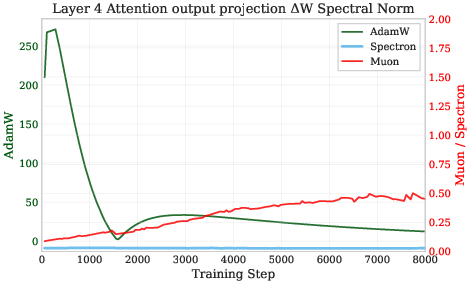
- Spectral norm is like a “volume knob” that measures how much a layer can amplify its input. If this knob gets too high, activations can explode and training can fail.
- Low-rank updates naturally push this knob too high because the two factors A and B can drift in risky ways.
- Spectron is a “speed limiter” for updates. It does two things: 1) Orthogonalization: it reshapes the update so its directions don’t amplify each other. You can think of this like moving straight along safe axes rather than diagonally in a risky direction. 2) Spectral renormalization: it scales the update size based on the current “volume knob” of A and B, so the combined change to W stays within a safe bound each step.
How it’s implemented (everyday analogy):
- Measure how “loud” the current factors are (estimate their spectral norms) using a quick test called power iteration.
- Make the gradient update “well-behaved” (orthogonal) using a fast procedure (Newton–Schulz), so it won’t cause spikes.
- Scale the update down just enough so the overall change to the big matrix W stays within a safe limit, like setting a speed cap.
Importantly, this adds very little extra work (under 1% more compute), unlike some previous methods that need to keep full-sized copies around and pay about 25% extra compute.
What did they find, and why does it matter?
Here are the main results, presented simply:
- Stable from-scratch low-rank training: With Spectron, the authors trained LLMs entirely with low-rank weights (no backup full-rank versions) without crashes or loss spikes.
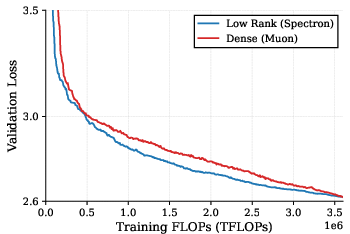
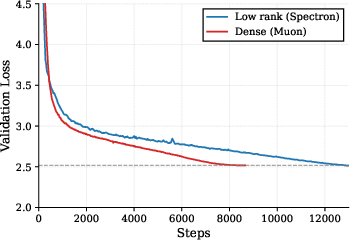
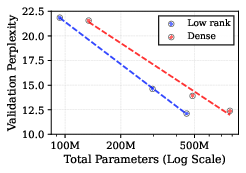
- Matches dense performance at equal compute: A low-rank model with about 42% fewer parameters reached the same final validation loss as a much larger standard model when both used the same total training compute.
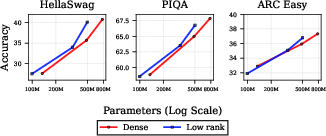
- Better results than baselines: Spectron beat “naive” training and also beat a prior “self-guided” method that needed full-rank help, achieving lower perplexity (a measure of how well the model predicts text) and higher accuracy on tasks like HellaSwag, PIQA, and ARC Easy—while using less extra compute than those baselines.
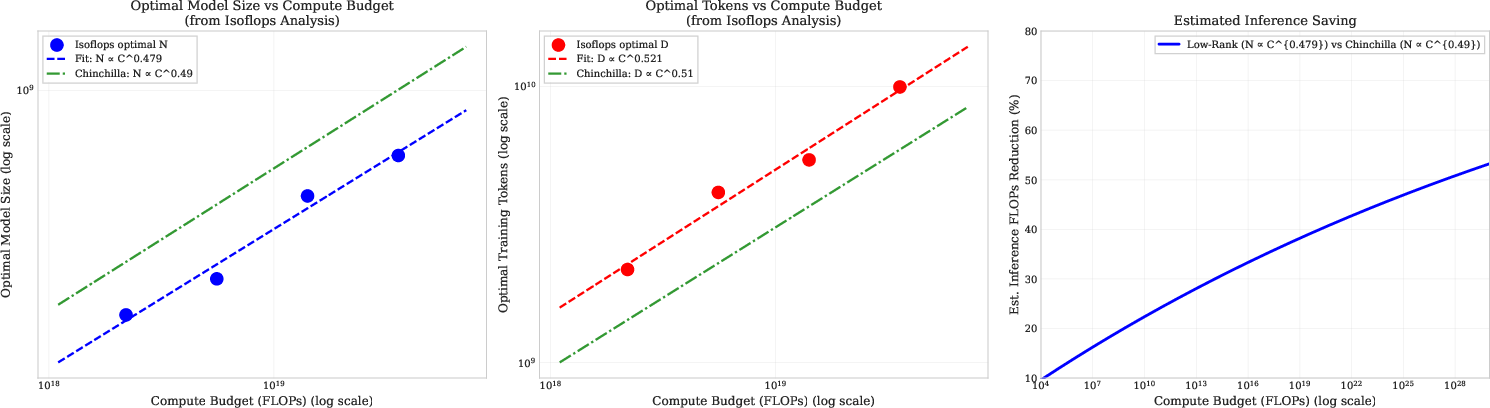
- Predictable scaling laws: The authors mapped out how to best split a fixed training budget between model size and data tokens for low-rank models. The sweet spot looks very similar to known laws for standard models, but low-rank models tend to be smaller and trained on a bit more data to be compute-optimal.
- Cheaper inference: Because low-rank models end up smaller for the same quality, running them (inference) can be significantly cheaper—potentially up to around half the cost at large scales.
Why this matters: Training from scratch with low-rank weights was considered too unstable to be practical. Spectron shows it can be done reliably, which opens the door to building strong models that are lighter and cheaper to run.
What’s the impact and why should we care?
- More accessible AI: If you can train high-quality models with fewer parameters and without fancy workarounds, more labs and companies (with less hardware) can build and deploy useful LLMs.
- Lower inference costs: Smaller models that perform just as well are faster and cheaper to serve. This helps with on-device AI, energy savings, and scaling services to many users.
- Clear training recipe: Spectron gives a simple, low-overhead checklist—orthogonalize the update and scale it to keep the spectral norm in check—that practitioners can adopt.
- Guidance for planning big trainings: The scaling law results help teams decide how big to make the model and how much data to use for a given compute budget.
- Broader potential: The same stability ideas may help other architectures (like multimodal models) train efficiently with low-rank layers from the start.
In short, this paper provides a practical method to make “do more with less” a reality for LLM pretraining: you can train smaller, stable, low-rank models from scratch and still reach the quality of bigger, standard models—saving memory and cutting future inference costs.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work could address to strengthen and generalize the paper’s claims.
- Scope beyond LLaMA-style decoder-only transformers: Validate Spectron on encoder–decoder models, vision transformers, and multimodal architectures to assess generality.
- Scaling to frontier regimes: Test stability and performance for model sizes >1.5B parameters and training budgets beyond ~3.6e19 FLOPs (e.g., 1e21–1e23) to confirm behavior at realistic large-scale pretraining.
- Hyperparameter sensitivity of the spectral bound: Systematically study how to set and schedule
η(the global constraint radius) to ensureρ < 1in practice, its interaction with learning rate, and robustness across tasks and scales. - Accuracy and robustness of spectral norm estimation: Quantify error from using 1-step power iteration; analyze failure modes when the spectral norm is underestimated and evaluate trade-offs for larger
k_power. - Numerical stability of Newton–Schulz orthogonalization: Analyze effects of iteration count (
k_ns), mixed precision (BF16/FP16), and conditioning on large matrices; provide guidelines where Newton–Schulz may diverge or degrade. - Composite update bound under realistic optimizers: Provide a formal analysis of how momentum, decoupled weight decay, gradient clipping, and adaptive learning rates affect the bound on
||ΔW||_2and whether the inequality remains valid under these dynamics. - Factorization of embeddings and LM head: Explore native low-rank training when embedding matrices and the output head are factorized, including tied embeddings; quantify stability and performance impacts.
- Rank selection strategy: Move beyond a fixed
r = 0.25 n—investigate per-layer rank allocation, dynamic rank scheduling over training, and data-dependent adaptive rank selection. - Layer-specific behavior and diagnostics: Extend spectral norm measurements from a single attention output projection to all layers and submodules (Q/K/V projections, MLP up/down projections) to identify which components drive instability.
- Interaction with normalization and residual paths: Analyze how Spectron interacts with pre/post LayerNorm, residual scaling, and activation distributions; verify that
Δy_rmsbounds translate to stable activations network-wide. - Optimizer dependence: Compare Spectron’s behavior when combined with AdamW, Adafactor, Lion, and SGD with momentum; quantify differences relative to Muon and identify required modifications for each optimizer.
- Overhead beyond FLOPs: Report wall-clock speed, GPU memory footprint, kernel efficiency, and distributed training communication overhead; include hardware-specific benchmarks to validate the claimed sub-1% overhead.
- Inference efficiency claims: Provide end-to-end latency and throughput measurements on GPU/CPU for low-rank vs dense models, considering kernel fusion, memory bandwidth, and the two-GEMM path
(A (B^T x)); clarify when low-rank inference is faster in practice. - Long-context regimes: Evaluate stability and quality for larger sequence lengths (e.g., 8K–128K tokens), where attention and projection matrix sizes significantly increase; check if spectral constraints need adjustment.
- Dataset diversity and domain coverage: Replicate on multilingual corpora, code-heavy datasets, math/logic domains, and higher-quality filtered corpora; measure OOD generalization and sensitivity to data cleanliness.
- Broader downstream evaluation: Add more comprehensive benchmarks (e.g., MMLU, GSM8K, BBH, Winogrande, TruthfulQA) with zero-shot and few-shot protocols to verify generalization and reasoning gains under native low-rank training.
- Fine-tuning and alignment: Test instruction tuning, RLHF, LoRA-style adapters, and continued pretraining on factorized bases; assess whether the low-rank parameterization helps or hinders adaptation.
- Failure mode characterization: Quantify frequency and magnitude of loss spikes, gradient blow-ups, activation explosions; provide actionable monitoring (e.g., alarms on
||ΔW||_2,||W||_2,Δy_rms) and recovery strategies. - Theoretical guarantees: Strengthen the theory beyond bounding
||ΔW||_2—e.g., trust-region interpretations, convergence guarantees, or generalization bounds under spectral constraints; clarify conditions under which stability is ensured. - Scaling-law statistical rigor: Report confidence intervals, goodness-of-fit metrics, sensitivity to token quality, and robustness of exponents under alternative fitting procedures; replicate “Approach 3” with explicit methodology and error bars.
- Compute accounting fairness: Precisely account for FLOPs differences of factorized forward/backward passes, optimizer steps, orthogonalization, and spectral estimation; confirm that isoFLOP comparisons are apples-to-apples across all components.
- Distributed training strategies: Develop and benchmark factor-specific sharding, communication compression for A/B factors, and integration with ZeRO/Hybrid Shard; quantify end-to-end savings and scalability.
- Gauge invariance and factor scaling drift: Investigate whether Spectron sufficiently controls
A → λA, B → (1/λ)Bscaling drift, and whether explicit gauge fixing (e.g., rebalancing singular values) improves stability or performance. - Impact of the
ΔA ΔB^Tterm: Empirically measure when the quadratic term dominates (e.g., whenρis not small), and design safeguards or modified bounds to handle regimes where it becomes non-negligible. - Control of
||W||_2, not just||ΔW||_2: Explore regularizers or constraints to directly limit the spectral norm ofWover training (e.g., periodic renormalization) to avoid cumulative drift despite bounded updates. - Representation quality vs. compressibility: Examine whether native low-rank training affects learned feature geometry (e.g., anisotropy, intrinsic dimensionality) and downstream transfer compared to dense training that is later compressed.
- Synergy with quantization: Evaluate compatibility with 8-bit/4-bit quantization during inference and training (e.g., QLoRA-like setups), focusing on accuracy retention and numerical stability in the presence of low-rank factorization.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings on Spectron (spectral renormalization with orthogonalization) for native low-rank LLM pretraining. Each item notes relevant sectors, potential tools/workflows/products, and key assumptions/dependencies.
- Stable native low-rank pretraining to reduce memory and compute costs (software, cloud/AI infrastructure)
- Tools/workflows/products: Spectron optimizer module as a PyTorch/JAX wrapper; plug-in to existing training loops that orthogonalizes gradients (Muon-like) and applies power-iteration-based spectral renormalization; rank planning guide (e.g., r ≈ 0.25 of width) for all non-embedding matrices.
- Assumptions/dependencies: LLaMA-style transformer architectures; availability of Newton–Schulz orthogonalization and power iteration; careful hyperparameter tuning (learning rate, momentum); high-quality pretraining data.
- Cost-aware model scaling and planning via IsoFLOP compute-optimal laws (software, finance/ops for AI teams)
- Tools/workflows/products: Training budget planners that use and ; dashboards that recommend parameter/token allocations for given compute and inference targets.
- Assumptions/dependencies: Budgets and data access comparable to FineWeb-scale; scaling exponents generalize to similar LLM architectures.
- Inference efficiency with dense-equivalent performance at fewer parameters (industry-wide; healthcare, education, finance, call centers, content platforms)
- Tools/workflows/products: Low-parameter LLM deployments with equal-FLOP training; model variants sized using Spectron that reduce inference cost and memory footprint (e.g., 42% fewer parameters with matched performance under equal compute in the paper’s setup).
- Assumptions/dependencies: Workloads where inference cost scales near-linearly with parameters; downstream tasks align with paper’s evaluation (HellaSwag, PIQA, ARC-easy).
- Edge and on-prem deployment of stronger local models (healthcare, industrial IoT, retail, robotics)
- Tools/workflows/products: Hospital/on-device assistants for EHR summarization; factory-floor assistants; robotics controllers; offline tutors on low-end devices.
- Assumptions/dependencies: Latency and privacy requirements favor local inference; model sizes enabled by low-rank pretraining fit device constraints.
- Reduced training instability and waste (software/MLOps)
- Tools/workflows/products: Training pipelines that avoid loss spikes via Spectron’s spectral constraints; higher learning-rate regimes with fewer divergences; improved reproducibility.
- Assumptions/dependencies: Integration into existing optimizer stacks; monitoring of spectral norms; compatibility with distributed training.
- Lower cloud costs and carbon footprint for LLM training and inference (policy, sustainability, enterprise IT)
- Tools/workflows/products: Procurement and sustainability dashboards showing cost and energy savings from native low-rank training; green AI reporting tied to parameter and inference reductions.
- Assumptions/dependencies: Enterprise acceptance of energy metrics; accurate inference cost modeling; consistent data center energy accounting.
- Democratized LLM research and domain pretraining for smaller labs (academia)
- Tools/workflows/products: Domain-specific LLM pretraining (e.g., biomedical, legal) with reduced GPU memory; open-source Spectron implementation for canonical transformer stacks; reproducible recipes replacing dense guidance.
- Assumptions/dependencies: Availability of domain corpora; engineering capacity to deploy Spectron; rank sizing heuristics.
- Privacy-preserving deployments through local inference (healthcare, finance, government)
- Tools/workflows/products: Spectron-pretrained compact LLMs deployed behind the firewall to avoid data egress; compliance-aligned workflows for sensitive data pipelines.
- Assumptions/dependencies: Performance parity on target tasks; sufficient local compute; regulatory acceptance of on-prem LLMs.
- Improved distributed training throughput via lower memory per GPU (software, HPC)
- Tools/workflows/products: Higher effective batch sizes; reduced sharding/communication pressure; compatibility with sharded training (e.g., ZeRO-like regimes) while maintaining factorized weights.
- Assumptions/dependencies: Sharded training stacks accommodate low-rank matrices; network/IO bottlenecks don’t dominate.
- Rapid A/B experimentation on rank and learning rate schedules (academia, industry R&D)
- Tools/workflows/products: Automated sweeps for rank ratios, constraint radii (η), and learning rates using Spectron’s stability; tracking spectral norms as a primary KPI.
- Assumptions/dependencies: Budget for multiple runs; robust spectral-norm logging; consistent pretraining datasets.
- Fine-tuning and continued pretraining with native low-rank weights (software, applied AI)
- Tools/workflows/products: Transition existing dense checkpoints to fully factorized continued pretraining; task-specific adapters added on top of factorized backbones.
- Assumptions/dependencies: Compatibility of checkpoints with factorization; continued pretraining datasets; care with rank selection during conversion.
Long-Term Applications
The following applications require further research, scaling experiments, hardware support, or broader ecosystem development to reach full viability.
- Standardization of native low-rank training across multimodal foundation models (vision, speech, VLMs)
- Tools/workflows/products: Spectron-like optimizers extended to cross-attention and modality-specific blocks; unified training recipes for text–image–audio models.
- Assumptions/dependencies: Empirical validation of spectral constraints on non-text architectures; rank strategies per modality.
- Hardware-accelerated low-rank kernels and compilers (semiconductors, cloud platforms)
- Tools/workflows/products: Primitive support for factorized matmul (A·Bᵀ) in GPUs/NPUs; compiler passes that exploit low-rank structure in both training and inference.
- Assumptions/dependencies: Vendor adoption; measurable end-to-end gains beyond software-only implementations.
- Dynamic rank adaptation during training (AutoML, software)
- Tools/workflows/products: Schedulers that adjust ranks by layer over training to optimize compute/inference trade-offs; adaptive Spectron bounds that respond to rank changes.
- Assumptions/dependencies: Robust criteria for per-layer rank changes; stability guarantees for dynamic factorization.
- Federated and decentralized pretraining using low-rank models (policy, telecom, edge computing)
- Tools/workflows/products: Federated pipelines where lower memory enables participation of heterogeneous nodes; privacy-first global pretraining.
- Assumptions/dependencies: Communication strategies tailored for factorized weights; secure aggregation protocols; data availability across nodes.
- Mixture-of-experts (MoE) combined with native low-rank experts (software, cloud AI)
- Tools/workflows/products: Inference-efficient MoE architectures where each expert is factorized; routing that accounts for low-rank capacity.
- Assumptions/dependencies: Stability of MoE training under spectral constraints; routing quality; empirical gains over dense MoE.
- Policy frameworks incentivizing energy-efficient AI training/inference (government, standards bodies)
- Tools/workflows/products: Energy-efficiency benchmarks including spectral-stability metrics; procurement standards favoring low-rank-native models; carbon reporting aligned to scaling laws.
- Assumptions/dependencies: Consensus on measurement standards; collaboration between regulators and industry; lifecycle assessments.
- Rank-aware distributed communication algorithms (HPC, software)
- Tools/workflows/products: Communication overlap and compression schemes exploiting factorized matrices (e.g., extensions of ACCO/PETRA tailored to low-rank); reduced optimizer-state footprint.
- Assumptions/dependencies: Algorithmic innovation specific to factorized layers; careful tuning in large-scale clusters.
- On-device continual learning using factorized updates (mobile, robotics)
- Tools/workflows/products: Lightweight, spectrally constrained updates to adapt models on-device without catastrophic instability; task personalization for assistants and robots.
- Assumptions/dependencies: Reliable gradient collection on-device; memory/computation budgets; safe update policies.
- Cross-domain compute-optimal planning tools with inference costs (enterprise, MLOps)
- Tools/workflows/products: Planners that incorporate / exponents and inference budgets (e.g., tokens processed post-deployment), extending Chinchilla-like analyses to low-rank regimes.
- Assumptions/dependencies: Generalization of scaling laws across domains and languages; standardized inference workload models.
- Theoretical advances in spectral-norm–constrained optimization and generalization (academia)
- Tools/workflows/products: New analyses linking spectral norm bounds to generalization/robustness; guidelines for η scheduling; layer-wise constraint design.
- Assumptions/dependencies: Broader empirical validation; proofs for diverse architectures; integration with regularization strategies.
- Domain-specific compact foundation models for critical infrastructure (energy, logistics, public services)
- Tools/workflows/products: Pretrained low-rank-native models tailored to sector language and workflows, deployed with tight latency and memory constraints.
- Assumptions/dependencies: High-quality domain corpora; safety/robustness certification; long-term maintenance of compact models.
- Ecosystem tools for “Spectronization” of existing models (software, open source)
- Tools/workflows/products: Conversion kits that factorize trained dense layers and resume training under spectral constraints; validators for spectral stability during migration.
- Assumptions/dependencies: Safe conversion without severe performance drop; rank selection heuristics; community-maintained tooling.
These applications leverage the paper’s core insights: identifying spectral-norm growth as the primary instability in native low-rank training, providing a practical algorithm (Spectron) with negligible overhead, and establishing compute-optimal scaling laws for factorized transformers that enable inference-efficient deployments without sacrificing performance under equal compute.
Glossary
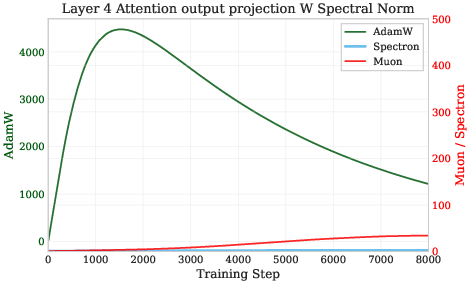
- AdamW: An optimization algorithm that decouples weight decay from the gradient-based update in Adam to improve generalization. Example: "AdamW~\cite{kingma2015adam} (\textcolor{green}{green}, left axis) exhibits explosive growth in all metrics with unconstrained spectral norm dynamics."
- Chain rule: A calculus principle used to compute gradients of composed functions, here yielding the update to a factorized weight. Example: "Via the chain rule, this leads to the composite weight update:"
- Chinchilla laws: Empirical scaling relationships that prescribe compute-optimal trade-offs between model size and training tokens for dense transformers. Example: "establishing scaling relationships analogous to Chinchilla laws~\citep{hoffmann2022an} with exponents $N_{\text{opt} \propto C^{0.479}$ and $D_{\text{opt} \propto C^{0.521}$"
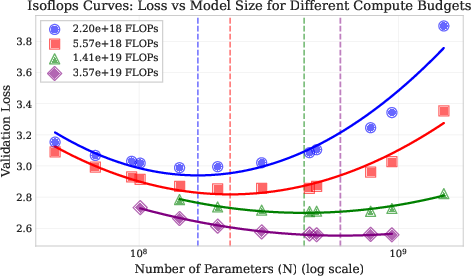
- Compute-optimal scaling laws: Relationships that specify how to allocate training compute between parameters and tokens to minimize loss. Example: "We derive compute-optimal scaling laws for low-rank transformers through isoFLOP analysis across 47M--1.5B parameters and 250M--90B tokens"
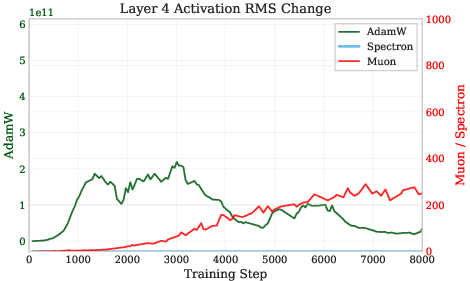
- Exploding activations: A training pathology where activations grow without bound, destabilizing optimization. Example: "triggering exploding activations, and ultimately causing training divergence."
- Gradient orthogonalization: A preprocessing of gradient updates that normalizes singular values (often to unity) to improve stability and efficiency. Example: "Gradient orthogonalization has emerged as a powerful technique for enhancing sample efficiency and optimization stability in deep neural networks \citep{jordan2024muon,bernstein2024old,bernstein2025deriving,ma2024swan}."
- IsoFLOP analysis: A methodology that profiles performance at fixed compute budgets by varying parameters and tokens to find the optimal configuration. Example: "We derive compute-optimal scaling laws for low-rank transformers through isoFLOP analysis across 47M--1.5B parameters and 250M--90B tokens"
- LoRA: Low-Rank Adaptation; a fine-tuning method that adds low-rank adapters to reduce memory and compute during updates. Example: "practitioners leverage low-rank structure to reduce fine-tuning costs through LoRA and its variants~\cite{hu2022lora,dettmers2023qlora,sharmatruth}."
- Low-rank factorization: Expressing a matrix as the product of two smaller matrices with rank r, reducing parameters and compute. Example: "Low-rank factorization offers a promising route to reduce training and inference costs, but the community lacks a stable recipe for training models from scratch using exclusively low-rank weights"
- Low-rank parameterization: Representing model weights directly in factorized low-rank form during training. Example: "We parameterize non-embedding layer weight matrices of a transformer~\cite{vaswani2017attention} neural network using low-rank factorizations"
- Muon: An optimizer that orthogonalizes hidden-layer updates to control spectral properties and stabilize training. Example: "The Muon optimizer and its variants \citet{jordan2024muon,ahn2025dion,si2025adamuon} preprocess gradients through orthogonalization, achieving faster convergence and improved training dynamics."
- Newton–Schulz iterations: An iterative method to approximate matrix inverses or polar decompositions used here for efficient gradient orthogonalization. Example: "In practice, \citet{jordan2024muon} orthogonalize the updates from SGD with momentum () using efficient Newton--Schulz iterations (Algorithm~\ref{alg:newton_schulz})"
- Power iteration: An algorithm to estimate the largest singular value (spectral norm) of a matrix efficiently. Example: "We implement this constraint efficiently via power iteration-based~\cite{vogels2019powersgd} spectral estimation"
- Rank collapse: A phenomenon where the effective rank of weight matrices diminishes during training, often linked to implicit regularization. Example: "\cite{pmlr-v280-galanti25a} formalized this by proving that SGD with weight decay induces rank collapse in weight matrices."
- RMS norm: Root Mean Square norm; the square root of the mean of squared entries, used to measure vector magnitude or activation variance. Example: "we employ the Root Mean Square (RMS) norm for a vector :"
- RMS-to-RMS operator norm: The maximum amplification factor of entry-wise magnitudes when a matrix maps inputs to outputs measured in RMS norm. Example: "and the RMS-to-RMS operator norm for a matrix , which measures the maximum amplification of entry-wise magnitudes:"
- Scaling invariance: Property of factorized weights where rescaling factors yields the same product, potentially causing instability. Example: "This scaling invariance permits unbounded growth in "
- Singular value decomposition (SVD): Factorization of a matrix into orthogonal matrices and a diagonal matrix of singular values, used in defining orthogonalization. Example: "given a gradient matrix at time step with singular value decomposition "
- Spectral estimation: Estimating spectral quantities (e.g., spectral norm) of matrices during training to enforce stability constraints. Example: "power iteration-based~\cite{vogels2019powersgd} spectral estimation"
- Spectral instability: Training instability driven by uncontrolled growth of spectral norms of updates or weights in factorized models. Example: "We establish the foundational concepts underlying our approach and formalize the spectral instability challenge inherent to low-rank factorized training."
- Spectral norm: The largest singular value of a matrix; measures maximum amplification and is crucial for stability. Example: "uncontrolled growth in the spectral norm (largest singular value) of the weight matrix update as the dominant factor."
- Spectral norm constraint: A bound imposed on the spectral norm of updates to control activation changes and stabilize optimization. Example: "orthogonalized updates as updates under a spectral norm constraint"
- Spectral renormalization: Rescaling updates based on current spectral norms to maintain bounded composite update norms. Example: "We address this pathology through Spectral renormalization combined with orthogonalization"
- Spectron: The proposed method combining spectral renormalization and orthogonalization to stabilize native low-rank training. Example: "we introduce Spectron: Spectral renormalization with orthogonalization"
- Submultiplicative property: A property of norms where the norm of a product is at most the product of norms; used to bound composite updates. Example: "The spectral norm satisfies the submultiplicative property"
Collections
Sign up for free to add this paper to one or more collections.