- The paper introduces Flow-Factory, a modular RL framework for efficient flow-matching model fine-tuning.
- It decouples models, RL trainers, and rewards using a registry-based abstraction with YAML configuration.
- Memory optimization and a unified multi-reward system yield a 13% GPU memory reduction and 1.74× training speed gain.
Flow-Factory: A Modular Framework for Reinforcement Learning in Flow-Matching Models
Motivation and Background
Diffusion and flow-matching models underpin recent advances in generative modeling across visual and multimodal domains, providing robust mechanisms for mapping noise to data distributions via learned continuous-time velocity fields. However, aligning such generative models with non-differentiable or human preference-driven objectives necessitates the adoption of reinforcement learning (RL)-based fine-tuning. While methods like Flow-GRPO and DanceGRPO have demonstrated the effectiveness of policy gradients and SDE-based exploration for flow-matching architectures, practical RL adoption lags due to three primary bottlenecks: fragmented codebases tightly coupled to models or algorithms, inefficiencies and memory constraints in RL fine-tuning, and a lack of flexibility in reward model specification.
Flow-Factory addresses these core challenges by establishing a modular and extensible RL framework specifically tailored to flow-matching models. Its design is grounded in registry-based modularity, preprocessing for memory efficiency, and unified multi-reward support, providing a platform for rapid, reproducible, and scalable research across algorithmic and architectural innovations.
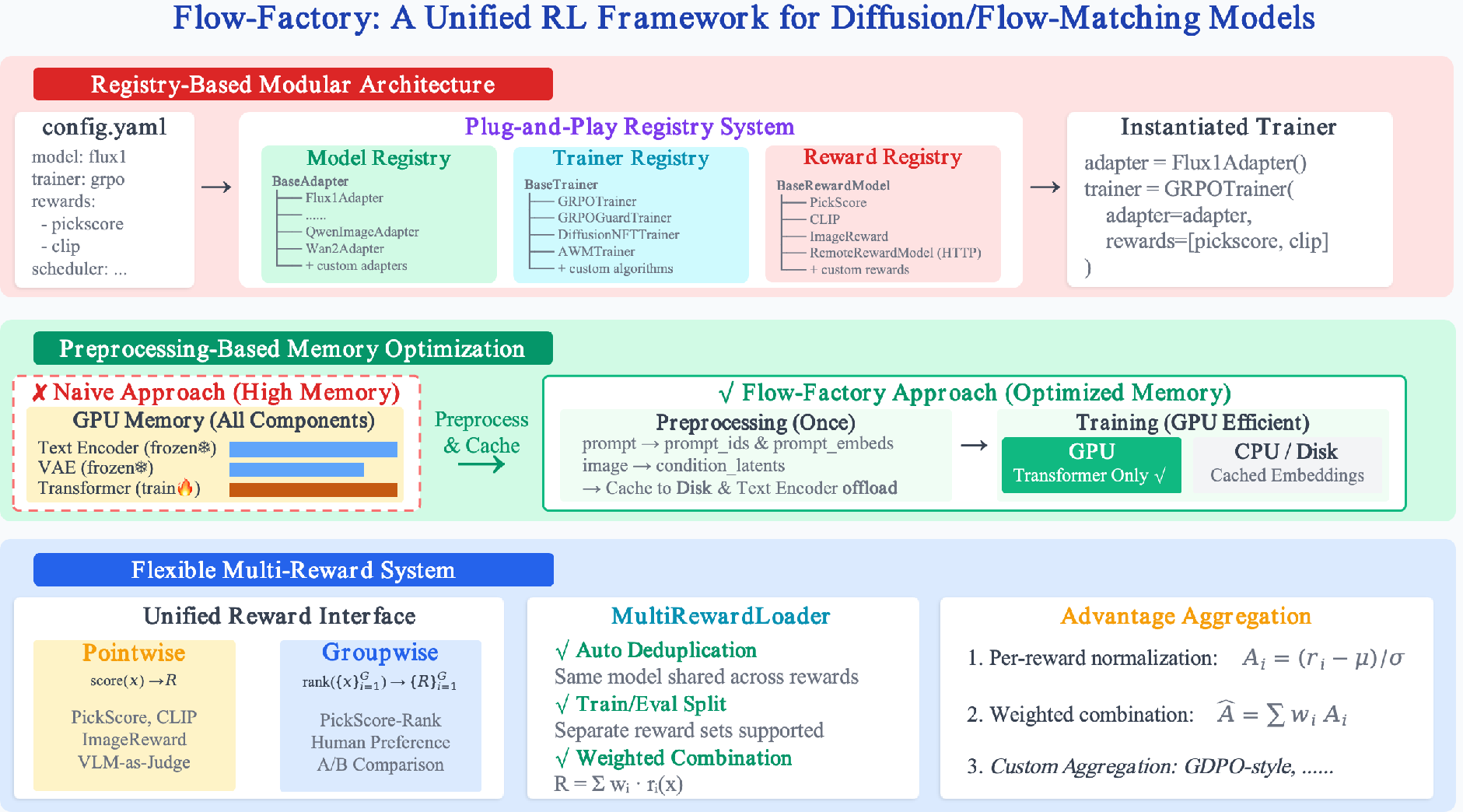
Figure 1: Overview of the Flow-Factory architecture highlighting registry-based component decoupling, preprocessing for memory efficiency, and flexible multi-reward support.
Framework Architecture and Design
Registry-Based Component Decoupling
Flow-Factory architecturally disentangles models, RL trainers, and reward modules by introducing standardized interfaces—BaseAdapter, BaseTrainer, BaseRewardModel, and SDESchedulerMixin. Through a global registry system, new models or algorithms can be introduced by subclassing the corresponding base classes with minimal code, reducing integration complexity from O(M×N) for M models and N algorithms to O(M+N). Instantiation is configuration-driven; users combine any supported model, trainer, or reward through declarative YAML files. This abstraction also enables systematic ablation and benchmarking, as every supported method can be evaluated under rigorously controlled conditions.
Preprocessing-Based Memory Optimization
State-of-the-art flow-matching pipelines incorporate substantial frozen submodules (e.g., text/image encoders, VAEs), which tax GPU memory despite being invariant to fine-tuning. Flow-Factory resolves this by precomputing and caching all condition embeddings before training. During RL fine-tuning, only the transformer backbone remains resident on GPU, enabling substantially larger batch sizes and reducing per-step computation via elimination of redundant encoding.
Flexible Multi-Reward System
A key innovation is the unified multi-reward system supporting both pointwise and groupwise rewards, addressing emerging needs for relative ranking- or multi-objective-based optimization. The system features (i) unified interfaces for reward models, (ii) automatic deduplication (preventing redundant model loading even for overlapping reward configurations), and (iii) fully configurable aggregation with support for both simple weighted summation and group-decoupled normalization (GDPO-style). These features are integral for supporting prototypical RL settings as well as advancing multi-signal and preference-driven model tuning.
Supported Algorithms and RL Methods
Flow-Factory incorporates implementations for several state-of-the-art RL algorithms used with flow-matching models:
- Flow-GRPO and Variants: Flow-GRPO leverages stochastic SDE-based sampling for effective RL exploration while maintaining flow match alignment. Flow-Factory abstracts multiple SDE schedules and supports variants such as MixGRPO (with ODE/SDE mixing for efficiency) and GRPO-Guard (addressing bias and reward hacking via regulated clipping and reweighting).
- DiffusionNFT: Operating via a forward-process contrastive objective, DiffusionNFT eschews explicit likelihoods or SDEs in favor of reward-weighted policy separation, offering computational and conceptual flexibility.
- Advantage Weighted Matching (AWM): AWM directly overlays RL-derived advantages as weights within the flow-matching pretraining objective, providing a more seamless alignment between reinforcement and standard supervision.
- Solver Agnosticism and Sampling Flexibility: Algorithms that decouple reward collection from trajectory dynamics allow experimentation with arbitrary scheduling and ODE solvers during data generation, balancing computational cost and quality.
Experimental Evaluation
Fidelity and Reproducibility
Flow-Factory faithfully reproduces the published reward curves and visual improvements of reference implementations, confirming that modular abstraction does not impair algorithmic behavior or stability.
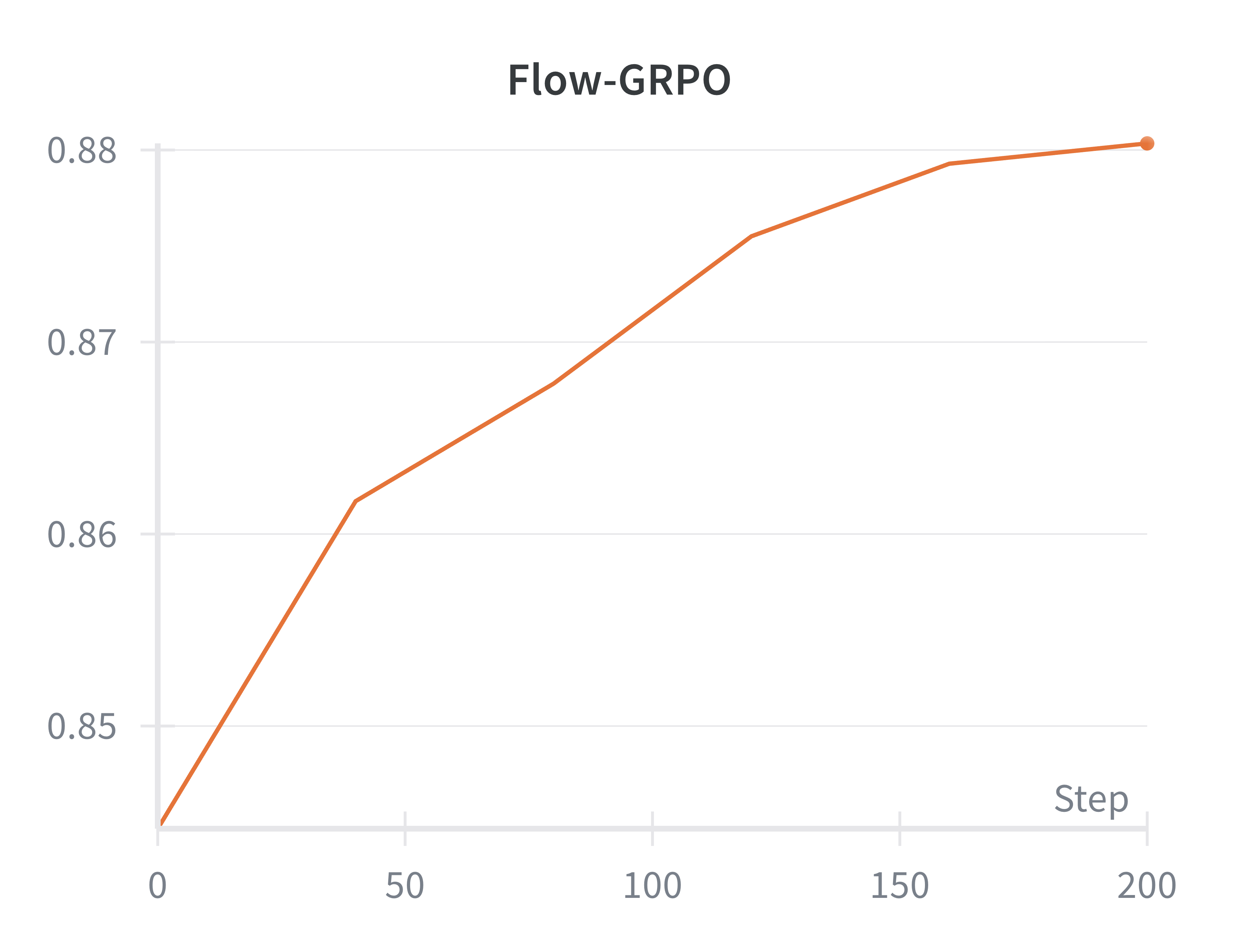
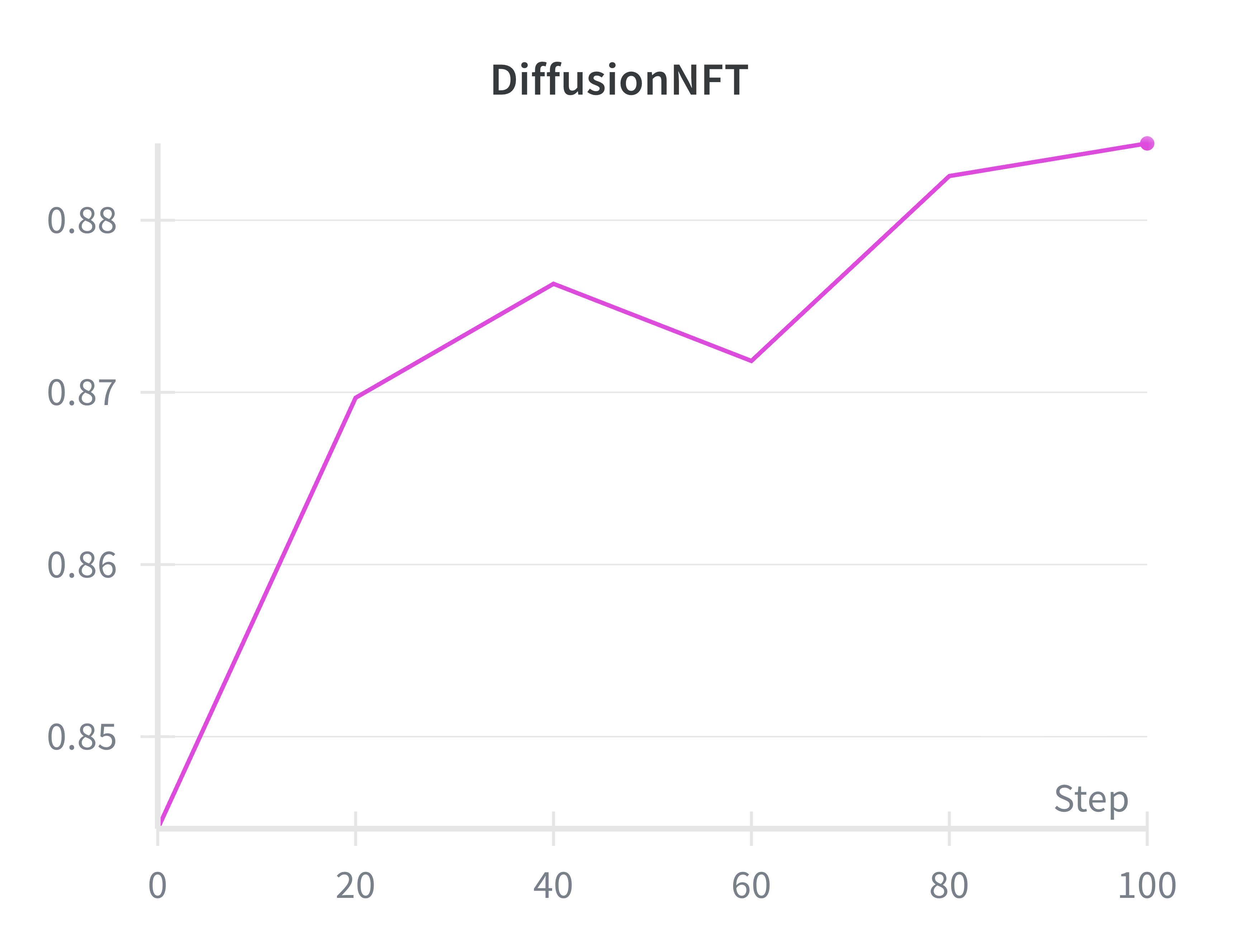
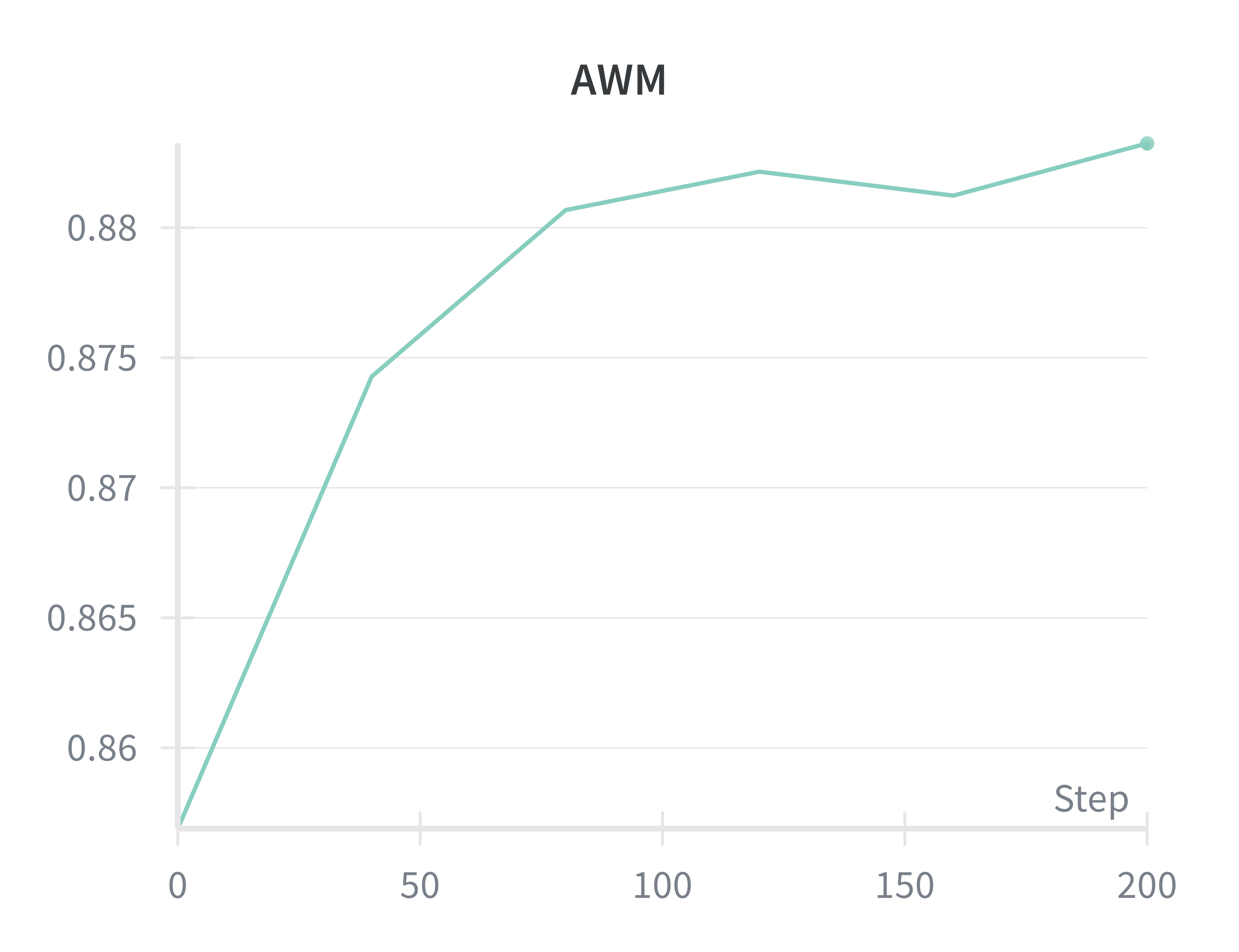
Figure 2: Reproduction of reward evolution for Flow-GRPO, DiffusionNFT, and AWM on Flux.1-dev with PickScore, matching reference implementations.












Figure 3: Qualitative generations across methods; all RL-finetuned models demonstrate superior visual quality relative to the baseline Flux.1-dev.
Memory and Efficiency Gains
The preprocessing-based memory optimization yields a 13% reduction in peak GPU memory and a 1.74× increase in training speed per step. These gains enable the scaling of RL fine-tuning to larger models and batch sizes, even on more modest hardware, thereby democratizing the RL alignment pipeline for broader usage.
Implications and Future Research
Flow-Factory represents a significant advance in the practical application and development of RL for flow-matching models, directly supporting algorithmic innovation, systematic benchmarking, and multi-objective preference alignment. By abstracting the core components and providing efficient, flexible infrastructure, it enables rapid prototyping of new RL loss functions, reward aggregation schemes, and sampling methodologies. The architecture is acutely relevant for researchers working on preference alignment, reward modeling, and scaling RL to increasingly complex generative backbones (including video and multimodal domains).
Pragmatically, Flow-Factory should lower the engineering overhead for reproducible RL experiments, facilitate more rigorous side-by-side evaluations, and accelerate algorithmic development for RL-finetuned foundation models. Modular reward aggregation and deduplication, in particular, will support more sophisticated explorations into mixed-signal and human-feedback-driven alignment, paving the way for decentralized multi-objective RL in next-generation generative systems.
Conclusion
Flow-Factory introduces a principled, modular, and high-efficiency framework for reinforcement learning in flow-matching generative models. By comprehensively decoupling models, training algorithms, and rewards, and by addressing memory bottlenecks and reward specification flexibility, it establishes a robust platform for both foundational research and production-scale deployment of RL-aligned generative models. Its demonstrated reproducibility and practical efficiency gains ensure that it will play a central role in the ongoing evolution of reinforcement learning for generative modeling.