TriGen: NPU Architecture for End-to-End Acceleration of Large Language Models based on SW-HW Co-Design
Abstract: Recent studies have extensively explored NPU architectures for accelerating AI inference in on-device environments, which are inherently resource-constrained. Meanwhile, transformer-based LLMs have become dominant, with rapidly increasing model sizes but low degree of parameter reuse compared to conventional CNNs, making end-to-end execution on resource-limited devices extremely challenging. To address these challenges, we propose TriGen, a novel NPU architecture tailored for resource-constrained environments through software-hardware co-design. Firstly, TriGen adopts low-precision computation using microscaling (MX) to enable additional optimization opportunities while preserving accuracy, and resolves the issues that arise by employing such precision. Secondly, to jointly optimize both nonlinear and linear operations, TriGen eliminates the need for specialized hardware for essential nonlinear operations by using fast and accurate LUT, thereby maximizing performance gains and reducing hardware-cost in on-device environments, and finally, by taking practical hardware constraints into account, further employs scheduling techniques to maximize computational utilization even under limited on-chip memory capacity. We evaluate the performance of TriGen on various LLMs and show that TriGen achieves an average 2.73x performance speedup and 52% less memory transfer over the baseline NPU design with negligible accuracy loss.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TriGen, a new kind of computer chip design (an NPU, or Neural Processing Unit) plus matching software that works together to run LLMs fast on small devices like phones and embedded systems. These devices have limited memory and power, which makes today’s big transformer models hard to run end-to-end. TriGen’s idea is to carefully co-design the software and the hardware so the model runs fully on-device, with less memory movement, lower precision numbers that still keep accuracy, and faster handling of tricky “nonlinear” math steps.
What questions are the authors trying to answer?
In simple terms, the paper tackles three big questions:
- How can we use smaller numbers (like 8-bit instead of 16-bit) for both model weights and activations without breaking accuracy?
- How can we speed up nonlinear functions (like softmax, normalization, and SiLU) that often become bottlenecks as sequence length grows?
- How can we smartly move and reuse data so the chip does more useful work and wastes less time waiting on memory?
How did they do it?
The approach combines three main ideas, each with an everyday analogy to make it clearer.
- Smaller numbers that still act “big enough” (Microscaling, MX)
- Analogy: Imagine you and your friends share one magnifying glass to read tiny text. Each person holds a small card (an 8-bit integer), and the group shares one magnifier (a scale) to see the real value clearly. This lets you store and move smaller cards but still read accurately when needed.
- What it is: TriGen uses MXINT8, an 8-bit format with a shared scale (exponent) per group. It also adds a simple, precise internal format called FI32 to keep intermediate results accurate while staying efficient.
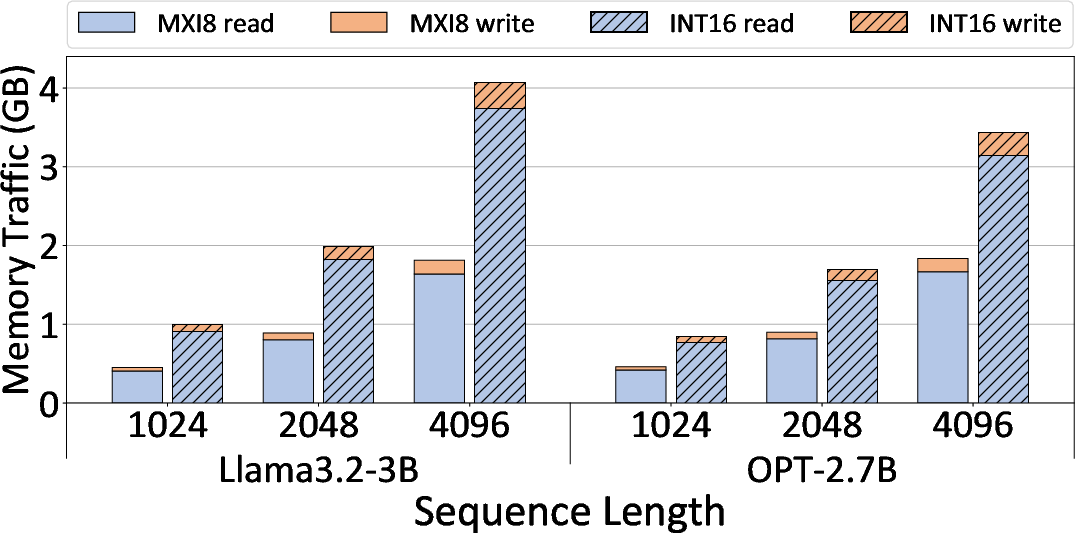
- Why it helps: 8-bit data halves memory and compute cost compared to 16-bit, and it shrinks the KV cache too. That’s huge on devices with tiny on-chip memory.
- Fast nonlinear math using lookup tables (LUTs)
- Analogy: Instead of recalculating a hard math problem every time, you look it up in a smart, small “cheat sheet” and, if needed, do a tiny correction.
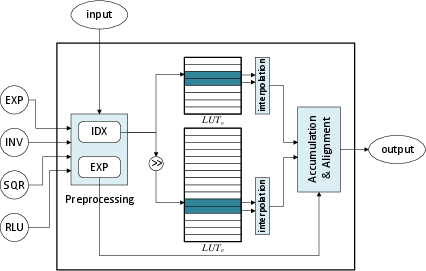
- What it is: TriGen builds a fast, accurate LUT unit co-designed with the software. It approximates functions like exponential, inverse square root, softmax parts, and SiLU by:
- Preprocessing the number (split into an exponent and a fraction),
- Looking up values in compact tables,
- Using simple interpolation and a tiny “error fix” table to get very close to the true value.
- Why it helps: It removes the need for special heavy math hardware and avoids converting data to bigger formats. That cuts latency and saves power.
- Smart scheduling and tiling of dataflow
- Analogy: If your suitcase is small, you pack clothes in the right order, keep the items you’ll reuse on top, and avoid repacking. You also coordinate with travel buddies so no one blocks the aisle.
- What it is: TriGen’s compiler chooses:
- Which part of the math “stays put” on chip (stationary),
- How to cut big matrices into tiles that fit on limited SRAM,
- How to balance work across multiple compute cores or multiple NPUs,
- How to minimize trips to DRAM (off-chip memory), which are slow and power-hungry.
- Why it helps: Even a very fast chip can be slowed down by memory. The scheduler co-optimizes compute and data movement so the chip stays busy and efficient.
Extra software tricks that matter:
- Fuse away costly transposes: By rearranging the math for attention (especially the V projection), TriGen avoids explicitly transposing MX-format tensors, which would be expensive and inaccurate.
- Masking without extra work: During attention, TriGen uses the LUT pipeline and partial sums to “zero out” masked positions without a separate multiply step.
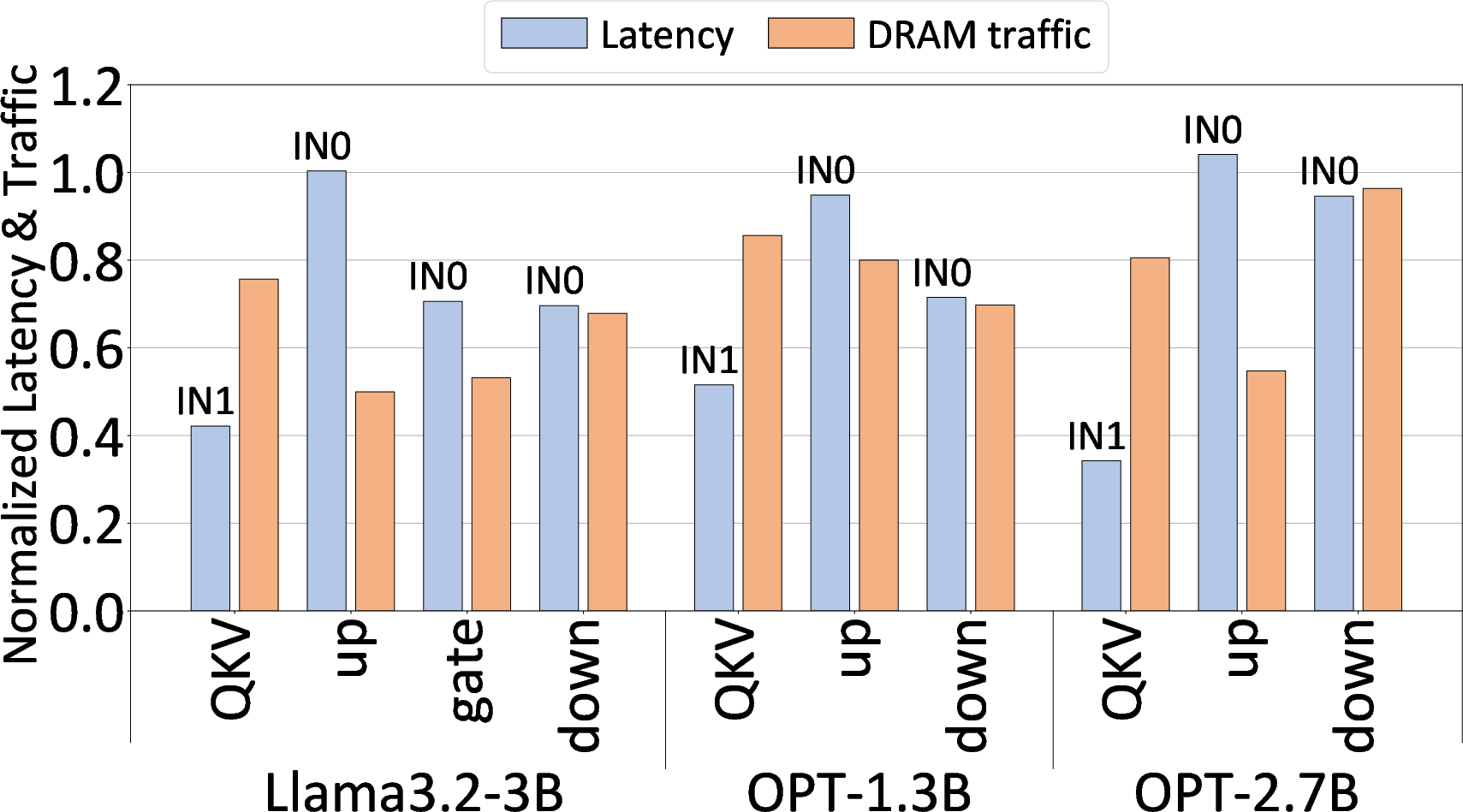
- Batch Q/K/V projections: It loads just the needed weights for heads that fit in on-chip memory and processes them efficiently to minimize repeated memory reads.
Hardware at a glance:
- A controller (RISC-V), multiple deep-learning cores, a tensor unit, and shared on-chip memory (about 1 MiB).
- A 32×32 multiply-accumulate array with mixed-precision support and a post-processing pipeline that handles bias, rescaling, nonlinear LUTs, and output formatting.
- Support for multi-NPU synchronization so several NPUs can cooperate without stalling.
What did they find, and why is it important?
Main results:
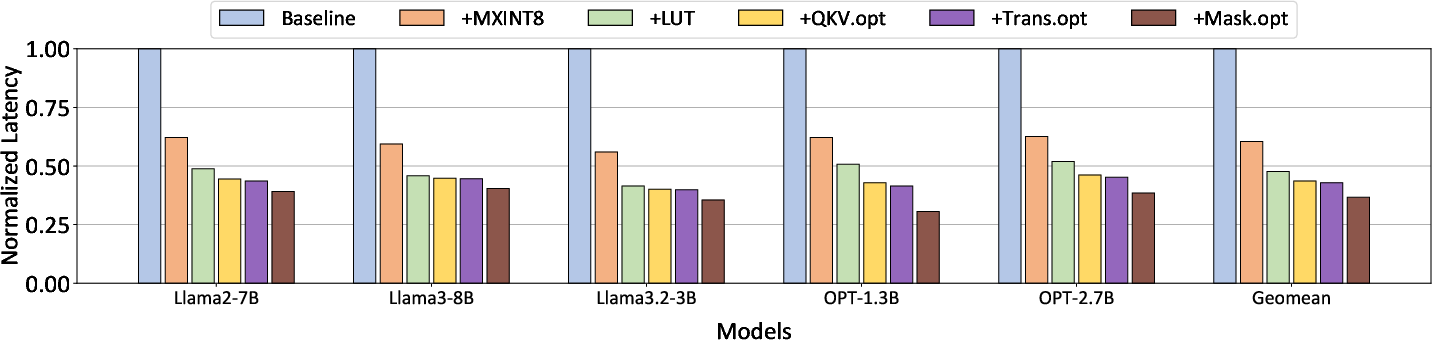
- Speed: On several LLMs, TriGen is on average 2.73× faster than a baseline NPU.
- Memory movement: It reduces memory transfers by 52%.
- Accuracy: It keeps accuracy nearly the same as higher-precision baselines, despite using 8-bit activations and low-bit weights.
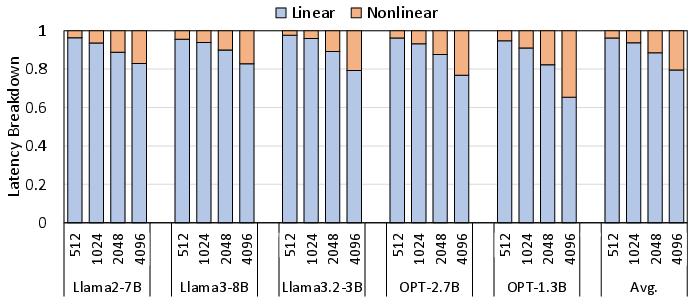
- Nonlinear ops: As sequences grow (e.g., 2K–4K tokens), nonlinear functions take a bigger slice of time; TriGen’s LUT approach keeps those from becoming a bottleneck.
Why that matters:
- On-device systems have very limited on-chip memory and constrained bandwidth to DRAM. If you don’t reduce precision for activations too—and if you don’t schedule data well—the chip spends more time moving data than computing.
- Prior work often used 16-bit activations to keep accuracy, which increases latency and power. TriGen shows a practical path to 8-bit activations with minimal accuracy loss.
- Eliminating specialized nonlinear hardware and still being accurate simplifies design and saves area and power.
What’s the impact?
In plain terms, this research helps bring truly capable LLMs to small devices:
- Faster responses and longer battery life on phones, wearables, and cars because the chip moves less data and does fewer heavy calculations.
- Better privacy and lower cost, since more can be done on-device without sending data to the cloud.
- Support for longer inputs (like longer documents) without nonlinear functions becoming a time sink.
- A blueprint for future edge-AI chips: co-design the model, number formats, hardware, and compiler together instead of treating them separately.
Big picture: TriGen shows that careful software-hardware co-design—using smart number formats, LUT-based nonlinear math, and resource-aware scheduling—can make end-to-end LLM inference practical on memory-limited devices, with strong speedups and almost no loss in accuracy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, formulated to be actionable for future research.
- End-to-end accuracy with MXINT8: Provide comprehensive accuracy results for TriGen using MXINT8 activations and low-bit weights across multiple LLMs, datasets, and tasks (beyond perplexity), including long-sequence (≥4k, ≥8k) and downstream task performance (e.g., QA, summarization, instruction-following).
- MX configuration specification: Define the exact microscaling scheme (group size, sharing axis, per-tensor vs. per-channel vs. per-group scales, update policy) and quantify its impact on accuracy, memory, and latency; include calibration/training procedures and runtime scale update rules.
- FI32 numerical semantics: Clarify FI32 signedness, overflow/underflow behavior, rounding modes, normalization, and conversion costs; provide formal error bounds for ACC exponent alignment and FRAC aggregation, and demonstrate stability across transformer blocks.
- Softmax implementation details: Specify the full softmax pipeline under low precision (exp, sum, division), whether log-sum-exp is used, and quantify numerical stability/accuracy for high-variance attention scores and long contexts in MXINT8/FI32.
- RoPE support: Describe how rotary position embeddings are implemented (e.g., LUT-based sin/cos), their precision and memory footprint, and measure end-to-end accuracy/latency impacts under MXINT8.
- LUT coverage and impact: Extend LUT design beyond reciprocal/ISQR/exp/SiLU to GELU, tanh, sigmoid, and other LLM-relevant functions; provide end-to-end accuracy impact, latency/area of LUT access and interpolation, and formal error bounds across operational ranges.
- LUT error propagation: Quantify how LUT approximation errors affect attention distributions, normalization, and activation outputs (e.g., bias in softmax weights), with per-layer sensitivity and tight error budgets.
- Elimination of SFU vs. LUT trade-offs: Provide synthesized area, frequency, power, and latency comparisons of LUT-based nonlinear processing versus conventional SFUs/VPUs on a specific process node; include TOPS/W and TOPS/mm².
- Baseline clarity and reproducibility: Fully specify the baseline NPU (datatypes, MAC array size, SRAM/DRAM bandwidth, frequency, compiler/tile policies) used for the 2.73× speedup and 52% DRAM reduction to enable fair, replicable comparisons.
- Energy and thermal evaluation: Report energy per token, power draw, and thermal behavior under realistic on-device conditions; compare to FP16 activation baselines and analyze DVFS effects.
- Memory system characterization: Detail on-chip buffer sizes (IBUF/WBUF/OBUF), banking, interconnect, DMA behavior, off-chip bandwidth assumptions (bus width, frequency), bank conflicts, and arbitration; provide sensitivity analyses.
- KV cache management: Describe how K/V tensors are stored in MXINT8 (or other formats), compression policies, precision impacts over long contexts, sliding-window attention, and memory mapping strategies to minimize DRAM traffic.
- Dataflow optimizer formalism: Present the optimizer’s cost model (DRAM traffic, compute overlap, SRAM constraints), search complexity, guarantees (e.g., near-optimality bounds), and generalization beyond matmul (e.g., elementwise, reductions, transposes).
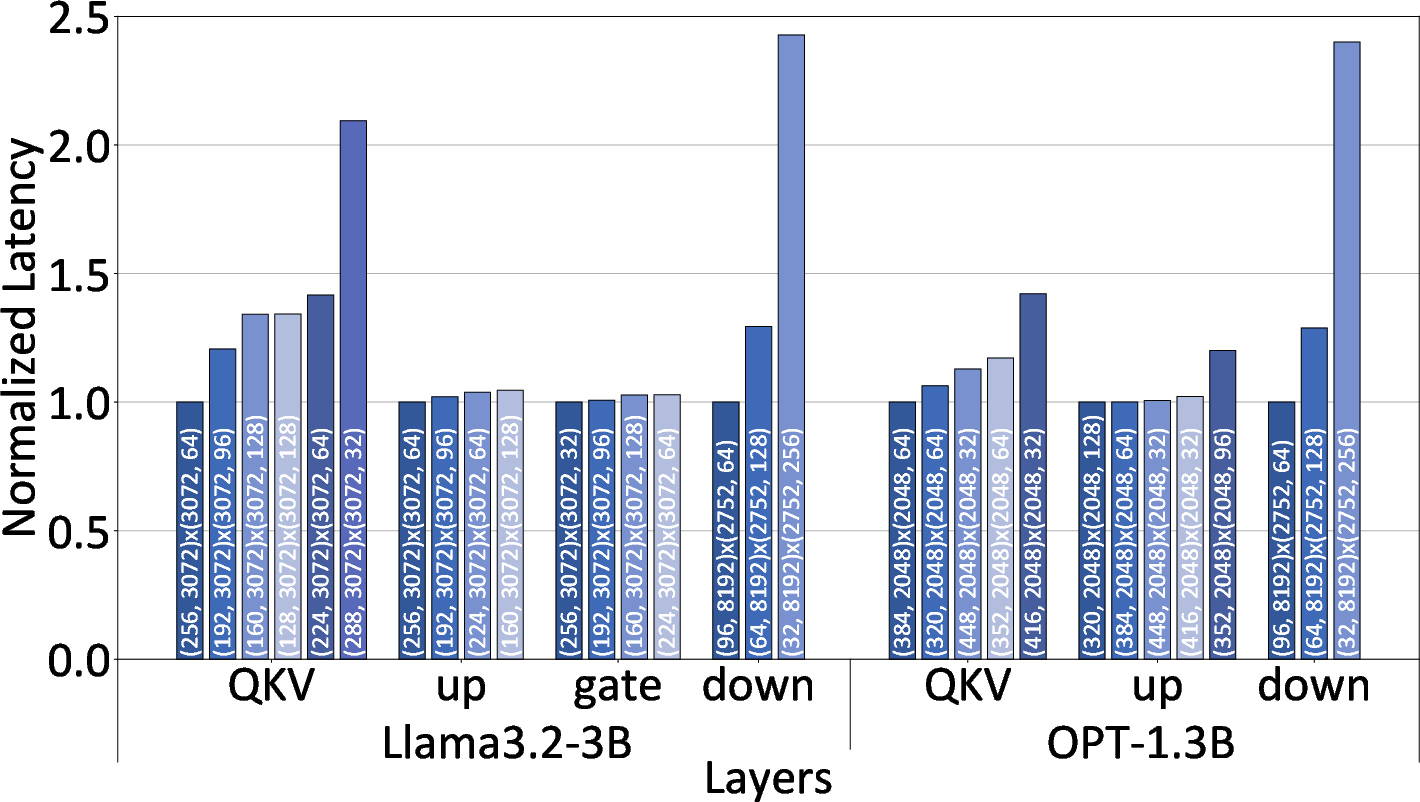
- Shape mismatch and underutilization: Analyze MAC array underutilization for non-multiple-of-32 dimensions, padding strategies, and their effects on throughput and energy; propose adaptive tiling to mitigate utilization loss.
- Multi-NPU scaling: Specify partitioning strategies (tensor parallel, pipeline parallel), interconnect requirements, synchronization overhead, load balancing, and evaluate scalability and energy/performance trade-offs across 2–N NPUs.
- Compiler/toolchain availability: Document the ISA, code generation, operator fusion passes, quantization pipelines, calibration tooling, and integration with common ML frameworks; provide artifacts for reproducibility.
- Wider mixed-precision exploration: Evaluate INT3/INT2 weights, FP8 variants, or hybrid formats with MXINT8 activations; provide accuracy–performance trade-off curves per layer/operator and model scale.
- Outlier handling under MX: Propose and evaluate algorithms to detect/mitigate activation outliers within MX (without falling back to 16-bit), including dynamic clipping/scaling strategies and their accuracy impacts.
- Quantization scope: Assess quantization of embeddings, normalization/gating parameters, and logits; specify rounding modes and zero-point choices, and measure their contribution to end-to-end accuracy and latency.
- Mask fusion correctness: Provide formal correctness guarantees and heuristics for “skip masked sub-matrix” detection; quantify worst-case overhead, accuracy impact under diverse masks (causal, padding, attention bias), and generalization to bidirectional attention.
- Long-context robustness: Evaluate numerical stability and accuracy for very long contexts (≥8k, ≥32k) and streaming/continuous batching modes, including accumulated rounding errors across autoregressive timesteps.
- Reliability and fault tolerance: Study resilience to bit-flips/ECC events in SRAM/LUT tables, error detection/recovery mechanisms, and their impact on accuracy/performance in on-device conditions.
- PVT and DVFS sensitivity: Characterize performance/accuracy across process, voltage, and temperature corners, and under DVFS; provide guidance for robust operating points on mobile SoCs.
- Coverage of diverse LLM architectures: Test and adapt TriGen for models with different nonlinearities and structures (e.g., GELU, layer norm variants, MoE, sparse attention), and detail any required hardware/software changes.
- FI32 storage overhead: Quantify the SRAM footprint and bandwidth cost of FI32 intermediates (PSUM, CWQ, bias) in end-to-end schedules, and evaluate trade-offs versus pure integer accumulation strategies.
Practical Applications
Immediate Applications
Below are actionable, real-world use cases that can be deployed now or piloted with modest integration, linked to sectors and practical workflows/tools, with assumptions and dependencies noted.
- On-device LLM assistants for smartphones and tablets (consumer electronics, software)
- Use cases: offline summarization, note-taking, translation, email drafting, voice command understanding, and privacy-preserving chat.
- Tools/products/workflows: MXINT8 + INT4 quantization pipeline for Llama/OPT-family models; TriGen-style compiler passes (operator fusion, resource-aware tiling); runtime using TMATMUL and LUT backends; KV-cache in 8-bit.
- Assumptions/dependencies: Hardware must support integer MAC arrays and a LUT-backed nonlinear pipeline or equivalent; models calibrated for MXINT8 activations; 1–4 MiB SRAM available; negligible accuracy loss holds for target tasks.
- Automotive infotainment voice assistants (automotive, software, energy)
- Use cases: offline natural language control for navigation, media, and settings; low-latency responses under tight thermal/energy budgets.
- Tools/products/workflows: TriGen-like NPU IP blocks in SoCs; LUT-based softmax/SiLU; PSUM masking fusion to avoid costly element-wise ops; compiler scheduling tuned for in-vehicle memory bandwidth.
- Assumptions/dependencies: SoCs expose sufficient on-chip SRAM and deterministic scheduling; qualification for automotive-grade reliability.
- Wearables and edge devices (consumer electronics, energy)
- Use cases: smartwatch dictation, quick replies, on-device intent detection with multi-NPU concurrency (e.g., LLM + audio model).
- Tools/products/workflows: Multi-NPU Sync-ID firmware; batched QKV projections to keep parameters resident in SRAM; resource-aware tiling for sub-megabyte memories.
- Assumptions/dependencies: Presence of multiple small NPUs or heterogeneous accelerators; firmware access to synchronization registers.
- Enterprise privacy-preserving workflows (finance, healthcare, policy)
- Use cases: local summarization of emails/meetings, document redaction suggestions, basic triage assistants running fully on-device to avoid data egress.
- Tools/products/workflows: MXINT8 activation quantization to fit KV cache; FI32 PSUM accumulation for accuracy; compiler-level fusion of transpose and masking to minimize DRAM traffic.
- Assumptions/dependencies: Acceptable task accuracy with low-precision; device management policies allow local AI; compliance review.
- Reduced energy consumption in existing NPUs via software-side scheduling (energy, software, academia)
- Use cases: lower DRAM traffic (up to ~52% reduction reported) and improved utilization on memory-bound LLM inference by adopting TriGen’s dataflow mapping ideas.
- Tools/products/workflows: Integrate resource-aware stationary/tile selection as a pass in TVM/Triton/XLA; expose per-operator tile knobs; deterministic runtime scheduling.
- Assumptions/dependencies: Access to compiler stack and low-level ISA controls; hardware that supports transposed matmul or equivalent; benefits depend on SRAM capacity and bandwidth.
- LUT-backed nonlinear operations on existing accelerators (software, hardware)
- Use cases: faster softmax, SiLU, normalization in long-context attention where nonlinears can account for ~20% latency at 4k sequence length.
- Tools/products/workflows: Compact+residual LUTs with interpolation; firmware/DSP microcode replacing SFU calls; precomputation of error tables; pipelined with PSUM.
- Assumptions/dependencies: Hardware path to invoke LUTs with exponent-aware scaling; accuracy validated for operational ranges; memory footprint for tables (~kB scale).
- Academic benchmarking and curriculum (academia)
- Use cases: course labs and research projects on SW-HW co-design; reproducing latency breakdowns; studying microscaling and LUT approximations.
- Tools/products/workflows: Open-source benchmarks for attention latency vs. sequence length; quantization calibration scripts; evaluation harness for LUT MAPE/MSE.
- Assumptions/dependencies: Availability of model weights and calibration data; access to a programmable accelerator or simulator.
- Policy guidance toward on-device AI (policy)
- Use cases: RFPs and procurement criteria that favor on-device AI for privacy, latency, and energy; guidance for limiting cloud inference for sensitive contexts.
- Tools/products/workflows: Technical briefs showing 2.73× speedup and memory savings; energy-per-inference metrics; privacy impact assessments.
- Assumptions/dependencies: Stakeholder buy-in; standardized reporting of energy and accuracy; device capability disclosure.
- Developer workflows for LLM deployment on constrained hardware (software)
- Use cases: repeatable pipeline from FP16 to MXINT8/INT4; operator fusion (transpose elimination via TMATMUL equivalence, coalesced masking); head-splitting + batched QKV to fit SRAM.
- Tools/products/workflows: Quantization toolkits (PyTorch/TensorRT plugins) that emit MXINT8; compiler passes for TriGen-style ISA; LUT generator with accuracy reports.
- Assumptions/dependencies: Model families compatible with microscaling (limited outliers); calibration datasets; ability to adjust stationary policy per operator.
Long-Term Applications
These opportunities require further research, scaling, standardization, or hardware productization before broad deployment.
- Mass-market TriGen-class NPU IP in mobile/edge SoCs (consumer electronics, automotive, robotics)
- Use cases: ubiquitous low-power LLM capabilities across phones, AR glasses, appliances, and in-cabin systems.
- Tools/products/workflows: MPA with exponent-aware mixed-precision; PPA with LUT engine; FI32 accumulators; multi-NPU synchronization fabric; ISA and compiler ecosystem.
- Assumptions/dependencies: Silicon design and verification cycles; EDA tooling; vendor ecosystem and SDK support; sustained model accuracy under MXINT8.
- Standardization of MXINT8 and FI32 across ML stacks (software, academia, industry consortia)
- Use cases: cross-vendor portability of models and kernels; consistent calibration pipelines and ONNX/PyTorch dtype support.
- Tools/products/workflows: Quantization specs; ONNX opset extensions; training-time aware quantization and post-training calibration for microscaling.
- Assumptions/dependencies: Community agreement on formats; compiler/runtime support; robust handling of activation outliers.
- Long-context on-device LLMs (software, consumer electronics, enterprise)
- Use cases: 8k–32k token context for meeting assistants, e-readers, code assistants, and document summarizers without cloud dependency.
- Tools/products/workflows: KV cache compression with MXINT8; SRAM-aware tiling; sequence-aware scheduling; LUT-accelerated nonlinears to cap quadratic latency.
- Assumptions/dependencies: Increased on-chip memory or hierarchical caching; careful accuracy validation at long contexts; thermal design margins.
- Multimodal on-device AI (healthcare, education, robotics)
- Use cases: vision-language assistants (e.g., scene description, tutoring) and speech-grounded LLMs in robots and assistive devices.
- Tools/products/workflows: Extend LUT library to GELU/other nonlinears; integrate vision transformer backbones; co-designed dataflow across modalities.
- Assumptions/dependencies: Hardware support for mixed workloads (vision + language); memory partitioning strategies; model retraining for microscaling.
- Edge AI orchestration with multi-accelerator QoS (software, systems)
- Use cases: concurrent execution of multiple models (ASR, LLM, personalization) with deadlock-free synchronization and latency guarantees.
- Tools/products/workflows: Sync-ID instruction semantics extended to cross-accelerator fabrics; runtime schedulers with deterministic dataflow; thermal-aware task allocation.
- Assumptions/dependencies: Heterogeneous accelerator presence; OS/runtime integration; priority and preemption policies.
- Sector-specific, validated on-device assistants (healthcare, finance, public sector)
- Use cases: clinical note summarization on secure tablets; compliance Q&A; offline form-filling and triage.
- Tools/products/workflows: Domain fine-tuning with microscaling-aware quantization; rigorous validation pipelines; audit trails; model cards documenting accuracy trade-offs.
- Assumptions/dependencies: Regulatory approvals; risk management for quantization-induced errors; secure hardware enclaves.
- Energy policy and labeling for AI features (policy, energy)
- Use cases: standardized energy-per-inference reporting; incentives for local inference; eco-labels for AI features on devices.
- Tools/products/workflows: Benchmarks capturing DRAM traffic reductions; lifecycle energy models; certification programs.
- Assumptions/dependencies: Industry collaboration; test protocols; consumer communication standards.
- Developer ecosystem and toolchain maturation (software, academia)
- Use cases: robust compiler backends targeting TriGen ISA; autotuners for tile/stationary policy; model zoo of MXINT8-ready LLMs.
- Tools/products/workflows: TVM/Triton/XLA extensions; autotuning datasets; LUT accuracy validation suites; reference implementations of operator fusions.
- Assumptions/dependencies: Funding and community participation; documentation and training; interoperability with existing ML stacks.
- Robotics and embedded control with local language understanding (robotics)
- Use cases: voice-to-action pipelines on mobile robots/drones; task planning with limited connectivity.
- Tools/products/workflows: Tight integration of LLM with control loops; deterministic scheduling under power constraints; safety validation.
- Assumptions/dependencies: Real-time guarantees; robust fallbacks for misinterpretations; hardware safety margins.
- Secure personal data processing on consumer devices (daily life, privacy)
- Use cases: local summarization of private chats, journals, photos (text annotations) without cloud upload.
- Tools/products/workflows: MXINT8 pipelines that fit memory budgets; extended context for personal histories; opt-in privacy settings.
- Assumptions/dependencies: Usability and trust; device storage and compute budgets; clear privacy messaging.
Each long-term application benefits directly from TriGen’s SW-HW co-design principles—microscaling for activations, LUT-accelerated nonlinears, and resource-aware scheduling—but will require broader ecosystem support, hardware productization, and rigorous accuracy/robustness validation to be realized at scale.
Glossary
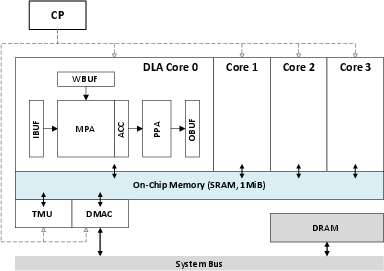
- Accumulator (ACC): A register or unit that accumulates partial sums from MAC operations during matrix computations. "The output result of MPA is accumulated in ACC."
- Arithmetic intensity: The ratio of computation to data movement; higher values generally mean better performance under memory constraints. "to maximize arithmetic intensity and minimize data movement during on-device execution."
- Channel-wise quantization (CWQ): Quantization scheme applying distinct scales per output channel to preserve accuracy. "such as bias (BIAS), partial sum (PSUM), and channelwise rescale (CWQ), where maintaining higher precision is essential."
- Control processor (CP): A lightweight controller (here RISC-V) that orchestrates the NPU’s functional units and instruction flow. "CP is a lightweight RISC-V processor that controls and manages other components."
- Deep learning accelerator (DLA): A specialized compute core optimized for neural network workloads. "An NPU contains CP, four DLA cores, TMU, and 1MiB global buffer (on-chip memory, SRAM)."
- Dequantization: Converting low-precision integers back to higher-precision values for computation. "Frequent dequantization of weight into higher data precision (e.g., FP4 to FP16) incurs severe latency overhead."
- Digital signal processor (DSP): A programmable vector processor often used for signal and numeric operations; here avoided by on-accelerator LUTs. "seamless acceleration of nonlinear function without SFU or companion vector processor such as DSP"
- Feed-forward network (FFN): The MLP sub-block in transformers that applies learned projections and nonlinearities. "A decoder layer consists of attention block and FFN."
- FI32 (Floating Integer 32-bit): An intermediate number format with integer fraction and exponent fields, enabling high-precision accumulation without full floating point. "Furthermore, TriGen incorporates FI32 as an intermediate data type within the architecture's data flow."
- Fully-connected (FC) layer: A dense linear layer performing learned projections. "output projection layer, which performs projection using FC layers."
- General matrix multiplication (GEMM): The standard batched matrix-matrix multiply kernel central to DNNs. "Therefore, total cost (i.e., TOPS/mm2, or TOPS/W) of GEMM operation is significantly reduced."
- Head-splitting: Partitioning attention into multiple heads before projection to enable per-head computation and memory locality. "The head-splitting is performed before projection, enabling tailored attention computation with only the necessary data."
- Instruction Set Architecture (ISA): The set of operations the accelerator supports and their encodings. "TriGen ISA includes the operations below to accelerate whole process of RMSNorm."
- KV cache: The stored keys and values from past tokens used to speed up autoregressive attention. "and it offers the advantage of reducing the total amount of data used in the KV cache."
- LLM: A transformer-based model with billions of parameters used for generative language tasks. "In recent years, numerous research efforts have been conducted to develop accelerators for LLMs."
- Lookup table (LUT): Precomputed table enabling fast approximations of nonlinear functions (e.g., exp, inverse sqrt, SiLU). "By leveraging a novel, fast, and accurate LUT co-designed with software and hardware, TriGen enable the efficient processing of complex nonlinear operations such as softmax, SiLU, and normalization"
- MAC (multiply and accumulate): The fundamental operation in linear algebra kernels, multiplying pairs and accumulating their sum. "Each array performs MAC operations between two input vectors with length of 32 and therefore one MPA performs 32×32 MAC operations at once."
- MAPE (Mean Absolute Percentage Error): An error metric reporting average absolute percentage deviation between approximations and true values. "with a MAPE consistently below 0.1% and a MSE remaining under"
- matmul (matrix multiplication): Core linear operation multiplying two matrices; the backbone of transformer layers. "linear operations such as matmul account for the majority of computations"
- MPA (MAC processing array): A systolic-like array of MAC units used for high-throughput dot products and matrix multiplications. "The MPA leverages a (32 × 32) MAC array to perform single-cycle dot product calculations"
- MSE (Mean Squared Error): An error metric reporting the mean of squared differences between approximations and true values. "with a MAPE consistently below 0.1% and a MSE remaining under"
- MX (microscaling): A number system using shared exponents for groups of integers to retain dynamic range at low precision. "TriGen adopts low-precision computation using microscaling (MX) to enable additional optimization opportunities while preserving accuracy"
- MXINT8: An 8-bit microscaled integer data type enabling low-precision compute with shared exponents. "low-precision LLM inference with native MXINT8 format support"
- Neural processing unit (NPU): A hardware accelerator specialized for neural network inference. "We propose NPU architecture named TriGen that enables: i) low-precision LLM inference with native MXINT8 format support"
- Outlier (in quantization): Activation values with unusually large magnitude that impair uniform quantization accuracy. "the existence of outliers whose values are extremely large compared to the others hinders the activation quantization."
- Partial summation (PSUM): Intermediate accumulation value within a fused operator pipeline. "PSUM serves to aggregate values into TMATMUL's output, enabling direct manipulation of fused LUT inputs."
- Perplexity (PPL): A standard language modeling metric measuring predictive uncertainty (lower is better). "as measured by PPLs."
- Post-processing array (PPA): Hardware pipeline for biasing, de/quantization, LUT-based nonlinearities, and output formatting. "PPA processes activation function such as ReLU, SiLU by referring to LUT."
- Processing element (PE): The basic compute unit inside accelerator arrays used for parallel arithmetic. "maximize PE utilization while reducing DRAM access with software-defined dataflow and tiling strategy."
- RISC-V: An open instruction set architecture used for the NPU’s control processor. "CP is a lightweight RISC-V processor that controls and manages other components."
- RMSNorm (root mean square normalization): Normalization dividing activations by their RMS, commonly used in modern LLMs. "Llama model can be split into two major parts; attention module and FFN and, at the front of them, RMSNorm layers exist."
- Scaled Dot-Product Attention (SDPA): The core attention mechanism computing softmax of scaled query-key dot products applied to values. "In the SDPA process of a softmax layer requiring exponentiation, TriGen strategically manipulates PSUM"
- SiLU (sigmoid linear unit): An activation function defined as x·sigmoid(x), used in transformer MLPs. "nonlinear operations such as softmax, SiLU, and normalization"
- Special function unit (SFU): Dedicated hardware for complex math functions (e.g., exp, sqrt); TriGen avoids needing it via LUTs. "seamless acceleration of nonlinear function without SFU or companion vector processor such as DSP"
- Stationary policy: A dataflow choice that keeps one operand resident on-chip to increase reuse and reduce bandwidth. "such as sub-optimal tile sizes or mis-chosen stationary policies"
- Tensor manipulation unit (TMU): Hardware block for reshaping, transpose, split, and concatenate of tensors. "An NPU contains CP, four DLA cores, TMU, and 1MiB global buffer (on-chip memory, SRAM)."
- Tera operations per second (TOPS): A throughput metric denoting trillions of operations per second. "While existing NPUs often pursue peak TOPS, their effective performance on memory-limited devices is largely constrained"
- TMATMUL: A TriGen instruction performing transposed matrix multiplication with on-array tiling and accumulation. "The TMATMUL, which is a representative operation conducted in MPA, has two input matrices IN0 and IN1"
- Vector processing unit (VPU): A companion vector engine; TriGen’s LUT pipeline removes the need for it. "without additional hardware such as vector processing unit and without any loss of accuracy."
- Weight-only quantization: Quantizing weights to very low precision while keeping activations at higher precision. "Most of those research focused on weight-only quantization, keeping the precision of activation unchanged and preserving accuracy"
Collections
Sign up for free to add this paper to one or more collections.