- The paper introduces Steerable Policies that use diverse synthetic steering commands to enhance low-level robotic control and embodied reasoning.
- It presents a scalable synthetic annotation pipeline that boosts training data diversity, enabling robust hierarchical control under varying command abstractions.
- Experimental results show that both fine-tuned embodied reasoning and in-context learning VLMs significantly outperform state-of-the-art methods on generalization tasks.
Steerable Vision-Language-Action Policies: Enhancing Embodied Reasoning and Hierarchical Control
Motivation and Background
Robotic policies capable of following open-ended commands for diverse tasks are constrained by the practical limitations of dataset curation and annotation. Pretrained Vision-LLMs (VLMs) provide semantic and perceptual priors, yet existing hierarchical robotic control architectures typically interface VLMs with low-level controllers using sparse task-level language. This fundamentally limits the transfer of generalization, reasoning, and scene understanding capabilities from VLMs to robot actions. The paper "Steerable Vision-Language-Action Policies for Embodied Reasoning and Hierarchical Control" (2602.13193) addresses this bottleneck by introducing Steerable Policies, a new class of Vision-Language-Action models (VLAs) trained to accept a wide spectrum of synthetic steering commands, ranging from subtasks to grounded pixel coordinates.
Steerable Policy Architecture and Command Abstractions
The core contribution is the enhancement of low-level policy controllability via diverse steering command modalities, overcoming dataset bias and linguistic underspecification. Through augmentation of robot trajectory data with synthetically generated commands, Steerable Policies can respond to:
- Task-level language (standard robotic instructions)
- Subtask decomposition (semantic decomposition for behavior composition)
- Atomic motion commands (fine-grained control without scene semantics)
- Gripper traces (sequences of visual coordinates for trajectory following)
- Pointing commands (pixel position-based directives for object localization)
- Combined hybrid commands (composition of modalities to resolve ambiguity and induce complex behaviors)
This broad interface allows high-level controllers to select commands of the optimal abstraction to maximally exploit pretrained VLM capabilities. Steerable Policies thus enable nuanced control via hierarchical policy inference loops—where high-level models send commands of varying abstraction to the low-level Steerable Policy.
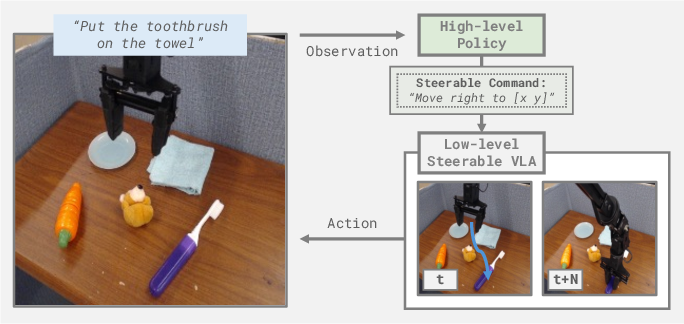
Figure 1: The hierarchical policy inference loop, where a high-level model sends commands to the low-level Steerable Policy.
Scalable Synthetic Command Annotation Pipeline
To scale the training of Steerable Policies, the paper describes an automated pipeline leveraging foundation models for trajectory annotation. Grounded features (bounding boxes, object traces, motion language) are programmatically extracted and combined with VLM queries (e.g., Gemini) to generate synthetic steering commands and post-hoc rationalizations, vastly expanding the diversity of training prompts. This achieves a significant increase in labeled data volume and abstraction range, providing the essential supervision needed for hierarchical embodied reasoning.
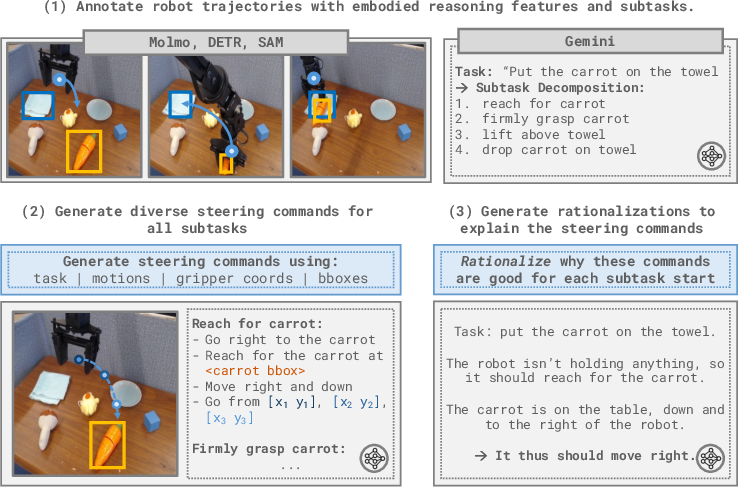
Figure 2: Automated pipeline for annotating robot data with synthetic steering commands, extracting features and generating diverse prompts for VLA training.
Hierarchical Policy Instantiations with VLMs
Two high-level control regimes are considered:
Experimental Evaluation and Results
The evaluation spans both standard and challenging generalization splits (motion, spatial, semantic, and long-horizon tasks) using the Bridge WidowX dataset and OpenVLA codebase. Key findings:
- Oracle human experiments: Allowing unrestricted steering modalities nearly saturates task performance. Individual command styles perform best in different settings; their combination is crucial for robustness, especially for semantic generalization and spatial reasoning.

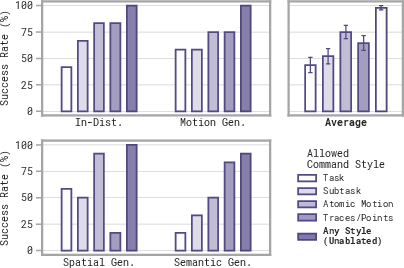
Figure 4: Interactive interface for querying humans for oracle steering commands with support for pixel-based input.
- Embodied reasoning VLM: When integrated with Steerable Policies, fine-tuned high-level reasoners outperform state-of-the-art reasoning VLAs (e.g., ECoT, ECoT-Lite, OpenVLA) by significant margins, especially under motion and semantic distribution shift.
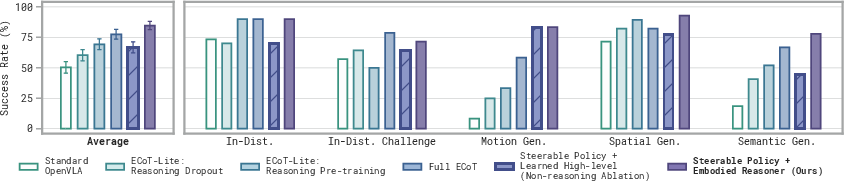
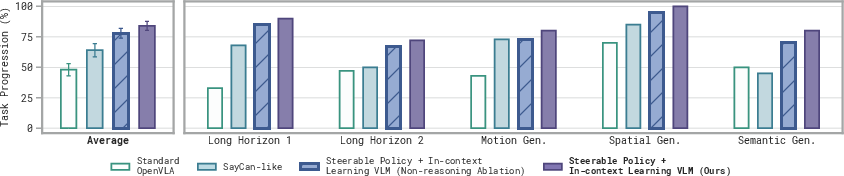
Figure 5: Approach of controlling Steerable Policy with a learned high-level embodied reasoning model outperforms four baselines.
- In-context learning VLMs: High-level VLMs adaptively adjust command abstraction during rollouts, employing corrective strategies when task progress stalls. This leads to strong improvements over baselines restricted to task/subtask-level prompts, directly leveraging scene understanding and reasoning capacities for long-horizon problem solving.




Figure 6: VLM uses in-context learning to ``discover'' the optimal steering abstraction, switching from pointing to motion commands as needed.
Policy Behavior: Manifold of Reasonable Actions
Steerable Policies, when conditioned on underspecified (atomic motion) commands, exhibit intelligent behavior by implicitly marginalizing over all possible tasks enabled by the scene and commanded movement. This “manifold of reasonable actions” enables robust task completion, but highlights the need for abstraction-flexible steering in ambiguous contexts.

Figure 7: Examples of manifold of ``reasonable'' actions; underspecified atomic motion commands induce task-aligned intelligent behaviors.
Implications and Future Directions
The work establishes that increasing low-level policy steerability is necessary for unlocking the full potential of pretrained VLMs in robotics. Diversity of steering command modalities leads to improved compositionality, generalization, and robustness, particularly for open-world or heavily randomized scenarios. The combination of hierarchical control and abstraction-flexible commands enables high-level reasoners (whether fine-tuned or in-context) to dynamically sequence problem-solving strategies, leveraging scene understanding and adaptive reasoning.
Practical implications include:
- Dataset Design: Robotic datasets should prioritize behavioral diversity and richly annotated trajectories to maximize steerability and affordance learning.
- Hierarchical Architectures: Implementing Steerable Policies is agnostic to VLA architecture and can be broadly applied to foundation model-based controllers.
- Learning Frameworks: Future research may explore reinforcement learning to dynamically optimize abstraction selection policies, further improving cross-task transfer and adaptability.
Theoretical implications involve the necessity of flexible interfaces for hierarchical reasoning systems and the limits of subtask-only or single-modality conditioning. Steerable Policies are a step toward operationalizing VLMs’ “disembodied” intelligence in real-world domains.
Conclusion
Steerable Policies, via synthetic command augmentation and hierarchical VLM integration, represent a substantial advance in embodied policy controllability and generalization. By expanding the interface between high-level reasoners and low-level controllers to span multiple abstraction modalities, they enable improved utilization of foundation model competencies for robotic manipulation, task composition, and generalization under distribution shift. The paradigm informs future dataset construction, policy architecture, and hierarchical control strategies in embodied AI.
