Conversational Image Segmentation: Grounding Abstract Concepts with Scalable Supervision
Abstract: Conversational image segmentation grounds abstract, intent-driven concepts into pixel-accurate masks. Prior work on referring image grounding focuses on categorical and spatial queries (e.g., "left-most apple") and overlooks functional and physical reasoning (e.g., "where can I safely store the knife?"). We address this gap and introduce Conversational Image Segmentation (CIS) and ConverSeg, a benchmark spanning entities, spatial relations, intent, affordances, functions, safety, and physical reasoning. We also present ConverSeg-Net, which fuses strong segmentation priors with language understanding, and an AI-powered data engine that generates prompt-mask pairs without human supervision. We show that current language-guided segmentation models are inadequate for CIS, while ConverSeg-Net trained on our data engine achieves significant gains on ConverSeg and maintains strong performance on existing language-guided segmentation benchmarks. Project webpage: https://glab-caltech.github.io/converseg/



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to understand and follow more natural, everyday requests about images. Instead of just finding simple objects (like “the left-most apple”), the authors want computers to answer intent-driven questions that people actually ask, such as “which surfaces are safe for hot cookware?” They call this new skill Conversational Image Segmentation (CIS), which means turning a sentence into a precise “highlight” of the right pixels in a picture.
What questions does the paper ask?
The paper explores a few simple but powerful questions:
- Can we make computers highlight parts of an image based on everyday, intent-focused instructions, not just object names and positions?
- Can we train models to understand abstract ideas like safety, function, and physical stability from a single image?
- Can we create lots of high-quality training examples automatically, without asking humans to draw pixel-perfect outlines every time?
How did the researchers do it?
To answer these questions, they built three main things: a new test, an automatic data-making system, and a model that combines image understanding with language.
Building a new test (ConverSeg)
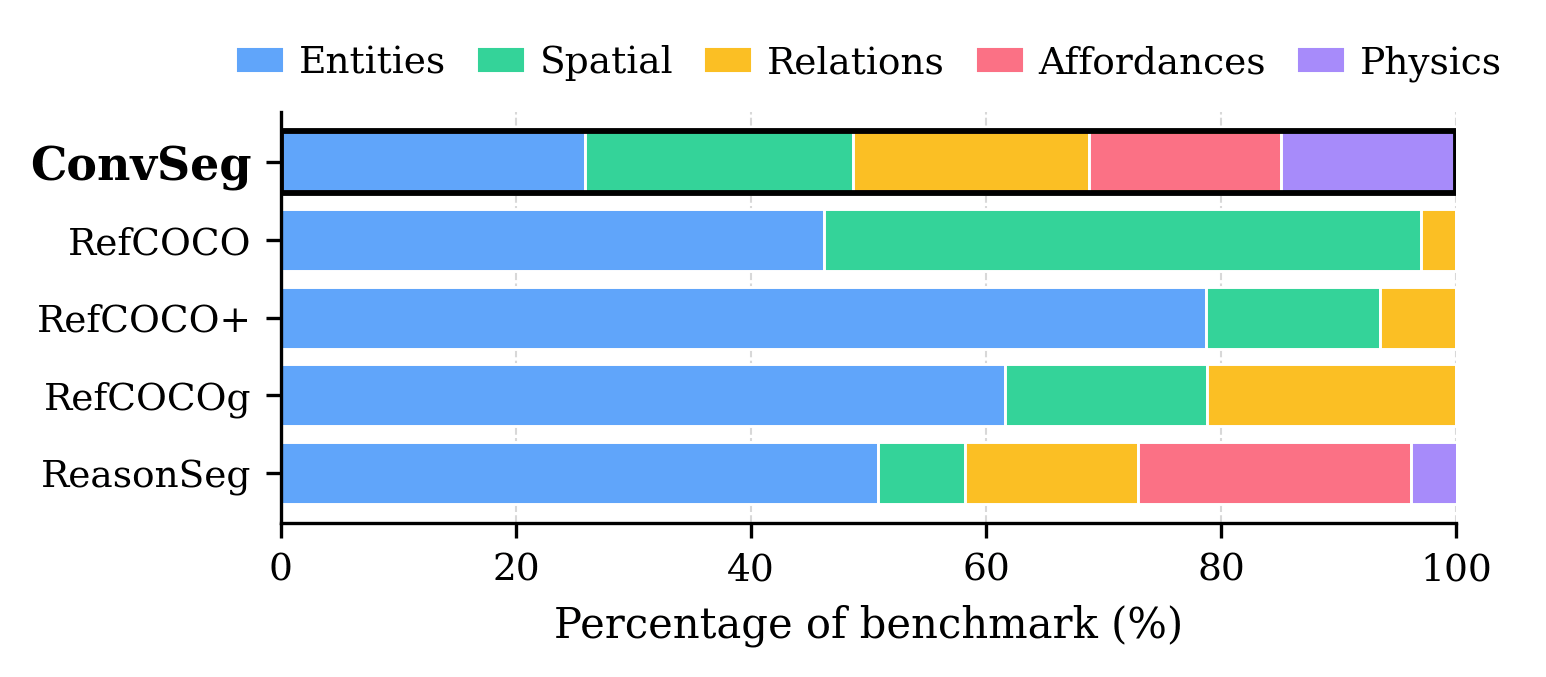
They created a benchmark called ConverSeg, which is a “fair test” set of image-and-instruction pairs with correct masks (the exact areas that should be highlighted). These prompts go beyond “find the cat” and cover five families of concepts:
- Entities: “the bicycle with a basket”
- Spatial Layout: “items blocking the walkway”
- Relations/Events: “the player about to catch the ball”
- Affordances/Functions: “surfaces suitable for hot cookware”
- Physics/Safety: “objects likely to tip over”
Each pair is checked by humans to make sure the instruction makes sense and the highlighted area is correct.
Making training data automatically (the data engine)
Drawing thousands of perfect masks by hand is hard. So they built an AI-powered pipeline that creates its own training data in stages, like a careful assembly line:
- Understand the scene: A vision-LLM (VLM) writes short descriptions of regions in the image (e.g., “large elephant walking to the left”).
- Find the region: Another AI predicts a box for that description; a segmentation tool (SAM2) turns that box into a precise shape (a mask).
- Check quality: A VLM double-checks that the mask matches the description and refines it if needed.
- Write conversational prompts: Using concept-specific guidance, the system generates practical, intent-based prompts (e.g., “things that could prop a door”) and picks which regions they apply to.
- Verify alignment: A VLM confirms that the final mask truly matches the prompt.
They also generate “negative” prompts on purpose (plausible instructions that don’t match anything in the image) to teach the model to say “nothing here” when appropriate.
This engine produced 106,000 prompt–mask pairs across all five concept families, without human drawing.
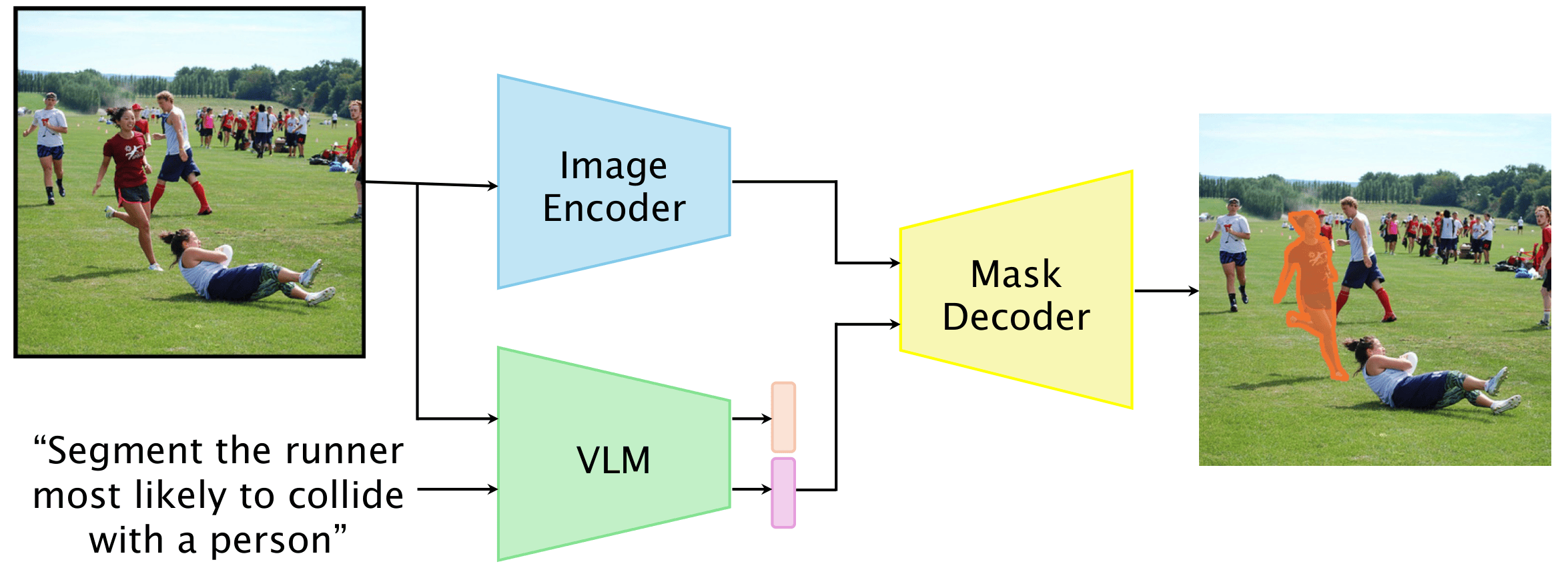
The model (ConverSeg-Net)
The model, ConverSeg-Net, fuses two strengths:
- A high-quality segmentation backbone (SAM2) that is very good at drawing pixel-accurate masks.
- A compact vision-LLM (like Qwen2.5-VL) that understands both images and text.
Think of SAM2 as a “master colorer” that can fill in the right shape crisply, and the VLM as the “instruction interpreter” that figures out exactly what the sentence means in the context of the image. Lightweight adapters connect the text understanding to the mask-making parts, so the model can “translate” words into the exact area to highlight.
Training strategy (curriculum learning)
They used a “curriculum,” like leveling up in a video game:
- Phase 1: Start simple. Train on literal tasks (e.g., “segment all the chairs”), basic referring expressions (from datasets like RefCOCO), and open-vocabulary regions.
- Phase 2: Get advanced. Fine-tune on the conversational, intent-based prompts produced by their data engine, while mixing some earlier tasks to avoid forgetting.
They trained the model to make its masks match ground truth using standard loss functions (think of these as scoring rules that reward correct coloring and penalize mistakes).
What did they find?
- On their new ConverSeg benchmark, the proposed model outperforms strong baselines, especially for the hardest prompts about affordances and physics/safety.
- The 3B model achieves around 71%–72% on ConverSeg’s main split, slightly above the previous best baseline. Scaling the language part from 3B to 7B brings further gains.
- Importantly, it doesn’t lose performance on older, object-focused benchmarks like RefCOCO; it stays competitive there too.
- The biggest improvements show up exactly where current models struggle: prompts requiring physical understanding, safety, and functional use (e.g., “items at high spill risk” or “surfaces safe for cutting”).
- Their automatic data engine produces training examples that transfer well to real tests, meaning you can scale up supervision without hiring lots of human annotators.
Why this matters: Many tasks in robotics, AR, and assistive tech require understanding what people mean, not just identifying objects. For example, “Which suitcase can I take without disturbing the stack?” needs reasoning about support and stability, not just finding “suitcase.”
Why does it matter?
- More natural interaction: This research moves computer vision closer to how people talk and think, enabling systems that follow practical, intent-driven instructions.
- Safety and usefulness: Understanding affordances and physical risks can help robots and smart devices act safely in homes, hospitals, and warehouses.
- Scalable training: The automatic data engine dramatically reduces the need for pixel-perfect human labeling, making it faster and cheaper to improve models.
- Broad impact: Better grounding of abstract concepts could enhance apps like AR assistants, content moderation, and educational tools that explain scenes with common-sense reasoning.
Key terms explained
- Segmentation mask: A precise “color-in” of the exact pixels that match an instruction in an image.
- Benchmark: A shared, high-quality test set used to fairly compare different models.
- Vision-LLM (VLM): An AI that looks at images and reads text together, connecting what it sees to what it’s told.
- Affordance: What an object allows you to do (e.g., a chair affords sitting).
- Physics/Safety reasoning: Understanding stability, support, and hazards from a single picture.
In short, this paper builds the tools and training needed for computers to highlight exactly what people mean in an image—even for abstract, intent-focused requests—and shows that doing so is both possible and practical at scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper, organized by theme to guide future research.
Benchmark and annotations
- Limited benchmark size and diversity: ConverSeg includes only 1,687 human-verified samples (subset from COCO val), risking overfitting to COCO-like scenes and insufficient coverage of long-tail settings (e.g., industrial, outdoor, medical, underrepresented geographies).
- Ambiguity of abstract prompts is unquantified: No inter-annotator agreement or multi-annotation study to assess subjectivity for intent/affordance/physics prompts (e.g., “comfortable seating,” “likely to tip”), nor mechanisms to encode multiple valid ground truths.
- Evaluation split bias: The SAM-seeded evaluation split may bias in favor of SAM-based architectures (including ConverSeg-Net) and under-penalize boundary/shape errors that deviate from SAM priors.
- No negative-evaluation protocol: Although negatives are used in training, there is no test set or metric assessing false-positive behavior when no valid region exists (e.g., “no wine glass present”).
- Single-image modality only: Event, physics, and safety concepts are evaluated from static images; the benchmark does not include video, depth, or 3D information where many physical/temporal inferences would be better grounded.
- Language scope: Prompts appear to be English-only; cross-lingual generalization and multilingual evaluation are unexplored.
Data engine and supervision quality
- Circularity and verifier dependency: The generate–verify loop relies on a single (closed) VLM (Gemini-2.5-Flash) for both generation and verification, risking confirmation bias and uncalibrated systematic errors in labels and prompts.
- Unknown error rates in auto-labels: There is no quantitative audit of the precision/recall of the data engine’s stages (box prediction, SAM2 mask quality, VLM verification), nor a human spot-check of a random sample of training data to estimate noise rates.
- Negative data validity: “No-valid-mask” negatives are verified only by the same VLM; no human validation or cross-model verification is reported to guard against mislabeled negatives.
- Open-vocabulary detection bottleneck: The pipeline depends on Moondream3 for boxes; its recall/precision on abstract, attribute-rich, or relational concepts is not reported and likely limits coverage of regions used in prompt generation.
- Attribution leakage and reproducibility: Reliance on closed-source VLMs for generation/verification impedes reproducibility and may conflate improvements with proprietary model behavior; ablations with fully open pipelines are absent.
- Domain coverage and bias: Meta-prompts and VLM generations may encode cultural or normative biases (e.g., “safe storage” assumptions); bias audits and fairness checks across demographics or environments are not provided.
Task definition and scope
- “Conversational” vs. single-turn: The task is single-pass grounding; multi-turn dialogue, context carryover, coreference resolution across turns, and user intent clarification are out of scope but central to “conversational” interaction.
- Ambiguity resolution and intent modeling: No mechanisms for interactive disambiguation, uncertainty communication, or user preference modeling when multiple plausible masks satisfy a prompt.
- Non-visual or latent properties: Prompts like “objects that might be hot” or “sharpness” are not reliably inferable from a single RGB image; the task lacks a principled treatment of latent variables, priors, or auxiliary cues (e.g., metadata, thermal).
- Granularity and compositionality: The benchmark lacks targeted tests for compositional constraints (e.g., count + ordinality + affordance), relational chains, or nested references; no fine-grained taxonomy of reasoning primitives with per-primitive metrics.
Model and training
- Frozen image encoder dependency: The image backbone (SAM2) is frozen, which may limit adaptation to abstract cues, non-COCO domains, and small/thin structures; effectiveness of end-to-end fine-tuning or alternative backbones remains untested.
- SAM prior limitations: The decoder’s priors may bias segmentation toward object-like regions and struggle with amorphous/stuff regions or function-defined extents (e.g., “areas affording rest”).
- Reasoning capacity and trade-offs: The model forgoes explicit multi-step reasoning or tool use; the conditions under which chain-of-thought or iterative refinement would measurably help abstract grounding remain unexplored.
- Uncertainty estimation and calibration: No predictive uncertainty, abstention mechanisms, or calibration analysis are provided—crucial for safety-critical affordance/physics decisions.
- Negative training side-effects: While negatives are used in training, the effects on over-rejection, brittleness to paraphrases, or distributional shift are not analyzed.
- Robustness and adversarial behavior: Sensitivity to prompt paraphrase, compositional reordering, adversarial phrasing, and out-of-vocabulary concepts is unmeasured.
Evaluation methodology
- Metrics for abstract concepts: Sole reliance on gIoU may be inadequate when multiple non-identical masks could be “correct”; no set-based, coverage/precision, or human-judgment-tolerant metrics are reported.
- Cross-benchmark generalization: Generalization to non-COCO datasets (e.g., LVIS, OpenImages, ADE20K, and real robotic scenes) is not evaluated; risk of overfitting to COCO distributions persists.
- Failure mode taxonomy: Qualitative examples are given, but a systematic categorization with frequencies (e.g., occlusion, small objects, spurious attribute cues) is missing.
- Data leakage checks: Potential overlaps between training images (COCO train, SA-1B) and evaluation (COCO val) are not addressed; de-duplication or near-duplicate filtering is unreported.
Broader applicability and deployment
- Real-time and resource constraints: Inference latency, memory footprint, and throughput on edge or robot hardware are not reported; trade-offs between model size and deployment constraints remain open.
- Sensor fusion and 3D grounding: Integration with depth, stereo, tactile, or motion cues to better ground physical/functional concepts is not explored.
- Safety and risk assessment: For tasks like “safe storage” or “likely to tip,” there is no end-to-end evaluation of downstream safety outcomes, nor protocols for fail-safe behavior.
- Continual and active learning: How to update the model with new concepts, correct errors via user feedback, or actively query for disambiguation is not addressed.
- Multilingual and cross-cultural generalization: How concept interpretations vary across languages/cultures and how to adapt prompts and models accordingly is unstudied.
Open research directions (concrete next steps)
- Collect multi-annotator, multi-mask labels for abstract prompts and introduce agreement-aware metrics and evaluation protocols.
- Build a multi-turn CIS benchmark with dialogue context, coreference, and clarification turns; include uncertainty prompts and user feedback loops.
- Create a negative evaluation split and report false-positive rates and calibration under “no valid mask” conditions.
- Replace or augment verifier VLMs with cross-model or human spot-checks; publish noise audits for each data engine stage.
- Introduce video/depth CIS tasks to evaluate temporal/physical reasoning; add physics-informed priors or simulators for affordance/safety grounding.
- Evaluate and mitigate bias in prompts and masks across demographics, environments, and cultural norms.
- Test end-to-end trainable backbones, non-SAM decoders, or hybrid geometric/learning approaches to reduce dependence on SAM priors.
- Report inference latency/memory and optimize for edge deployment; investigate lightweight reasoning modules or sparse decoding for speed.
- Expand cross-domain evaluation (e.g., robotics, indoor navigation, driving, AR) and multilingual CIS datasets with culturally aware prompt sets.
Practical Applications
Overview
Below are practical, real-world applications deriving from the paper’s findings and innovations in Conversational Image Segmentation (CIS), the ConverSeg benchmark, ConverSeg-Net, and the AI-powered data engine. Applications are grouped by deployment horizon and, where relevant, linked to sectors and potential tools/products/workflows. Assumptions and dependencies that affect feasibility are noted per item.
Immediate Applications
- Healthcare — safety-aware environment scans in hospitals
- Use case: Segment “sharp instruments,” “surfaces suitable for sterile placement,” or “items blocking patient pathways” from room photos for rapid checklist verification.
- Tools/workflows: Mobile audit app using ConverSeg-Net; CIS overlays to guide nurses/techs; snapshot + mask export to EHR task lists.
- Assumptions/dependencies: Domain-specific fine-tuning on clinical settings; HIPAA/privacy controls; consistent camera angles/lighting.
- Robotics (home/service) — risk-aware pick/place perception
- Use case: Ground “objects likely to tip,” “where to safely store a knife,” “stable surfaces for hot cookware” to inform grasp planning and placement.
- Tools/workflows: RGB capture → ConverSeg-Net → mask-to-candidate regions → downstream grasp planner; edge deployment on robot host.
- Assumptions/dependencies: Depth sensing for 3D safety margins; uncertainty calibration; domain adaptation to household scenes; latency constraints.
- Warehouse/logistics — stack stability and removal planning
- Use case: Segment “easily removable packages,” “load-bearing boxes,” and “blocked walkways” to assist operators or autonomous carts.
- Tools/workflows: CIS-enabled visual audit; integration with WMS dashboards; periodic photo capture from aisle cams.
- Assumptions/dependencies: Camera coverage; policy thresholds for actionability; fine-tuning for industrial packaging/materials.
- Facility management/occupational safety — visual hazard audits
- Use case: Identify “blocked emergency exits,” “trip hazards,” “sharp tools left out,” “surfaces unsafe for hot equipment.”
- Tools/workflows: CIS-powered mobile inspection tool; image capture, prompt bank (affordances/physics/safety), automatic overlay reports.
- Assumptions/dependencies: Site-specific prompt templates; reviewer-in-the-loop to confirm; standards mapping (OSHA/local codes).
- Retail operations — planogram and customer safety checks
- Use case: Segment “items inside containers,” “leftmost three cups,” “obstructions in aisles” from shelf/aisle images.
- Tools/workflows: Store audit app; masks exported to compliance report; exception queue for manual validation.
- Assumptions/dependencies: Shelf variability; fine-tuning for brand packaging; frequent lighting changes.
- Education (K–12, higher ed) — visual affordance/physics teaching aids
- Use case: Highlight “surfaces that afford cutting,” “objects prone to rolling,” or “mechanisms requiring human effort” in classroom materials.
- Tools/workflows: CIS-enabled lesson prep; slides with overlays; AR demos on tablets.
- Assumptions/dependencies: Curated prompt sets; non-safety-critical usage acceptable with occasional ambiguity.
- Software and content creation — intent-based selection in editors
- Use case: Text-driven selections like “segment items blocking the walkway,” “objects being actively examined,” “containers with spill risk” for quick edits or annotations.
- Tools/workflows: Plugins for photo/video editors using ConverSeg-Net; one-pass mask creation; refinement tools.
- Assumptions/dependencies: Generalization to diverse consumer images; quality expectations managed for complex/abstract prompts.
- Smart home apps — household safety guidance
- Use case: From kitchen/living room photos, segment “safe knife storage,” “surfaces suitable for hot pans,” “clutter zones” to suggest organization actions.
- Tools/workflows: Mobile app with predefined prompt library; masks trigger suggestions/tips; optional IoT linkage (notifications).
- Assumptions/dependencies: Domain fine-tuning for common appliances/materials; user consent and privacy.
- Annotation acceleration — CIS-assisted dataset labeling
- Use case: Rapid mask bootstrapping with conversational prompts to reduce manual effort in building niche vision datasets (affordances/safety).
- Tools/workflows: Integrate the data engine to synthesize prompt–mask pairs; human verification; import to labeling platforms.
- Assumptions/dependencies: QA loop remains essential; licensing of source images; prompt coverage tuned to task.
- AR overlays (headsets/phones) — situational guidance in static scenes
- Use case: On-device overlays for “items blocking walkways,” “surfaces safe for placing cookware,” “areas suitable for seating.”
- Tools/workflows: Lightweight CIS inference; on-device caching; prompt preset menus; single-frame capture and overlay.
- Assumptions/dependencies: Limited to images or slow video; compute constraints; careful UX to handle uncertainty.
Long-Term Applications
- Embodied robots with conversational tasking (HRI)
- Use case: Multi-turn interaction (“Which items could prop the door?” “Pick a stable one and place it safely”) with closed-loop perception, physics, and control.
- Tools/workflows: CIS + streaming video segmentation + 3D perception + physics engines; integrated task planner.
- Assumptions/dependencies: Robust video grounding; tactile sensing; safety certification; strong uncertainty handling.
- Construction and industrial site safety monitoring
- Use case: Continuous detection of “unstable loads,” “fall hazards,” “unauthorized storage of hot equipment,” “blocked pathways.”
- Tools/workflows: CIS extended to video; deployment on CCTV/DVR; integration with EHS systems; event triage workflows.
- Assumptions/dependencies: Domain-specific training on materials/structures; temporal reasoning; privacy/regulatory compliance.
- Elder care and home safety assistants
- Use case: Persistent identification of “trip hazards,” “clutter near walking aids,” “unsafe object placements” to reduce fall risk.
- Tools/workflows: Multi-camera monitoring; alert systems; caregiver dashboards; mask provenance tracking.
- Assumptions/dependencies: High reliability requirements; user consent; false positive mitigation; long-term generalization.
- Drones/field inspection — safe landing and loose-object detection
- Use case: Segment “surfaces suitable for landing,” “objects likely to fall” on rooftops/scaffolding; support autonomous decisions.
- Tools/workflows: CIS + 3D mapping (SLAM) + physics heuristics; AVI/maintenance workflows.
- Assumptions/dependencies: Depth and pose estimation; domain fine-tuning; environmental robustness (wind, lighting).
- Autonomous vehicles and mobile robots — subtle hazard semantics
- Use case: Identify “debris likely to roll,” “unstable cargo,” “objects blocking pedestrian flow” beyond category-only perception.
- Tools/workflows: CIS fused with lidar/radar; trajectory planners consuming affordance/safety masks; real-time constraints.
- Assumptions/dependencies: Multisensor fusion; stringent latency; extensive safety validation.
- 3D/volumetric CIS for digital twins and AR navigation
- Use case: Affordance/safety masks in 3D spaces for route planning, safe placement, and spatial layout optimization.
- Tools/workflows: CIS + 3D reconstruction; semantic mapping; AR route overlays.
- Assumptions/dependencies: Accurate 3D scene understanding; consistent cross-view grounding; scalable storage.
- Advanced manipulation planning with tool substitution
- Use case: From prompts like “items that could serve as a shovel,” plan grasps and uses for novel tools in unstructured environments.
- Tools/workflows: CIS affordance masks → material/shape classifiers → physics-informed planners → execution.
- Assumptions/dependencies: Learning physical properties beyond appearance; simulation-to-real transfer; risk management.
- Insurance/property risk assessment from imagery
- Use case: Segment “fire safety violations,” “blocked exits,” “unstable storage” in customer-submitted images for underwriting or claims triage.
- Tools/workflows: CIS scoring; review queues; compliance rules; audit trails.
- Assumptions/dependencies: Fairness and bias considerations; regulatory approval; human-in-the-loop adjudication.
- Smart kitchens and industrial plants — thermal/surface safety
- Use case: Identify “surfaces safe for hot items,” “containers with high spill risk,” extended to “pipes/surfaces safe for heat.”
- Tools/workflows: CIS + thermal sensors; operator guidance dashboards; alerting systems.
- Assumptions/dependencies: Multimodal sensor fusion; domain adaptation; safety thresholds.
- Domain data synthesis as a productized toolkit
- Use case: Use the paper’s AI-powered data engine to bootstrap domain-specific CIS datasets (affordances/safety/events) without heavy manual annotation.
- Tools/workflows: Generate–verify loop with enterprise VLMs; prompt libraries per sector; negative prompt generation for robustness.
- Assumptions/dependencies: Access to capable VLMs; compute budgets; legal/licensing of images; final human QA for critical deployments.
Cross-cutting assumptions and dependencies
- Accuracy and reliability: CIS must generalize beyond COCO-like imagery; abstract prompts can be subjective (e.g., “comfortable seating”).
- Safety-critical deployment: Requires uncertainty calibration, human verification, and regulatory compliance; avoid fully autonomous actions without safeguards.
- Compute and integration: ConverSeg-Net is single-pass and relatively lightweight, but real-time video or on-device use may need model compression and hardware acceleration.
- Data and domain adaptation: Performance depends on training with domain-specific scenes/materials; the paper’s data engine can bootstrap such datasets but still benefits from human QA.
- Multimodal extensions: Many long-term scenarios require depth/thermal sensors, temporal reasoning, or physics simulation beyond static RGB segmentation.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability. "We train with AdamW~\cite{loshchilov2017decoupled}, batch size 6 with gradient accumulation of 8 steps, and a cosine schedule with warmup."
- Affordances: Functional action possibilities or uses that objects or surfaces enable, inferred from visual cues. "affordances, functions, safety, and physical reasoning."
- Bidirectional cross-attention: An attention mechanism where prompt and image features attend to each other in both directions to fuse modalities. "The decoder uses modified Transformer blocks~\cite{vaswani2017attention} with bidirectional cross-attention between prompt and image embeddings."
- Binary cross-entropy: A loss function for binary classification that measures the difference between predicted probabilities and ground truth. "we minimize a weighted combination of binary cross-entropy and Dice loss"
- Chain-of-thought: Multi-step reasoning traces produced during inference to solve complex tasks. "yet rely on heavy backbones and multi-stage inference (chain-of-thought, tool calls), making deployment costly."
- Conversational Image Segmentation (CIS): Segmenting image regions based on intent-driven, high-level natural language prompts requiring functional and physical reasoning. "We address this gap and introduce Conversational Image Segmentation (CIS)"
- ConverSeg: A benchmark of human-verified prompt–mask pairs targeting entities, spatial relations, intent, affordances, functions, safety, and physical reasoning. "We address this gap and introduce Conversational Image Segmentation (CIS) and ConverSeg, a benchmark spanning entities, spatial relations, intent, affordances, functions, safety, and physical reasoning."
- ConverSeg-Net: A single-pass conversational segmentation model that fuses segmentation priors with language understanding. "We also present ConverSeg-Net, which fuses strong segmentation priors with language understanding, and an AI-powered data engine that generates prompt–mask pairs without human supervision."
- Cosine schedule with warmup: A learning-rate schedule that gradually increases at the start (warmup) and then follows a cosine decay. "We train with AdamW~\cite{loshchilov2017decoupled}, batch size 6 with gradient accumulation of 8 steps, and a cosine schedule with warmup."
- Cumulative IoU (cIoU): An overlap metric that aggregates intersection-over-union across instances or steps to summarize performance. "Cumulative IoU (cIoU) results are provided in the Appendix."
- Curriculum learning: A training strategy that introduces tasks in increasing complexity to stabilize learning and improve generalization. "we use a curriculum that gradually increases task complexity"
- Dice loss: A segmentation loss that measures overlap between predicted and ground-truth masks, emphasizing class imbalance handling. "we minimize a weighted combination of binary cross-entropy and Dice loss"
- Generate-and-verify loop: An automated pipeline that iteratively produces candidate data and checks it for correctness using models. "via an iterative generate-and-verify loop, yielding 106K image–mask pairs across all five concept families."
- Generalized IoU (gIoU): An extension of IoU that penalizes non-overlapping predictions via the smallest enclosing box, improving metric sensitivity. "We report generalized IoU (gIoU) as our primary metric"
- Gradient accumulation: Technique to simulate larger batch sizes by accumulating gradients over multiple steps before updating weights. "We train with AdamW~\cite{loshchilov2017decoupled}, batch size 6 with gradient accumulation of 8 steps, and a cosine schedule with warmup."
- Grounding: Aligning language or abstract concepts with visual regions to produce pixel-accurate masks. "Conversational image segmentation grounds abstract, intent-driven concepts into pixel-accurate masks."
- Instance annotations: Object-level labels and masks for individual instances within images. "sourced from instance (objects) and panoptic annotations (objects and stuff)."
- Intuitive physics: Human-like inference about physical properties and constraints directly from visual input. "We draw inspiration from human vision science~\cite{gibson2014ecological, marr2010vision} and intuitive physics~\cite{battaglia2013simulation}, which demonstrate that people infer functional properties and physical constraints directly from visual input"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models by injecting trainable rank-decomposed matrices. "The Qwen backbone is fine-tuned using LoRA~\cite{hu2022lora} with rank 16 and ."
- MAE (Masked Autoencoders): Self-supervised pretraining method where parts of the input are masked and reconstructed to learn robust visual features. "We adopt the SAM2 image encoder which is an MAE~\cite{he2022masked} pre-trained Vision Transformer (ViT)~\cite{dosovitskiy2020image}"
- Mask decoder: Network component that converts fused image–prompt features into per-pixel foreground probabilities to output segmentation masks. "We adopt SAM2's mask decoder and fully fine-tune it."
- Mask–text consistency check: Verification that a predicted mask matches its textual description in identity, attributes, and location. "Mask–text consistency check."
- Multi-turn grounded dialogue: Interactive, sequential language exchanges that reference and localize image regions over multiple turns. "GLaMM~\cite{rasheed2024glamm} supports multi-turn grounded dialogue"
- Open-vocabulary detection: Detecting objects beyond a fixed label set, using language or embeddings to handle unseen categories. "We choose Moondream3 for open-vocabulary detection and SAM2 for box-conditioned segmentation."
- Panoptic annotations: Unified labeling of both “things” (objects) and “stuff” (background regions) in images. "sourced from instance (objects) and panoptic annotations (objects and stuff)."
- Prompt adapters: Lightweight projection modules that map language token embeddings into the segmentation decoder’s input space. "connected via lightweight prompt adapters."
- Promptable segmentation: Segmentation that can be guided by simple prompts such as points or boxes, rather than fixed classes. "The Segment Anything Model (SAM)~\cite{kirillov2023segment} enables promptable, class-agnostic segmentation from points or boxes"
- RefCOCO/+/g: Standard referring segmentation benchmarks focusing on object-centric and spatial phrases. "RefCOCO/+/g~\cite{yu2016modeling} are standard benchmarks"
- Referring Expression Segmentation (RIS): Segmenting regions referenced by natural-language expressions. "Referring expression segmentation (RIS) localizes regions described by language."
- SAM (Segment Anything Model): A model providing strong class-agnostic segmentation priors from simple prompts like points or boxes. "The Segment Anything Model (SAM)~\cite{kirillov2023segment} enables promptable, class-agnostic segmentation from points or boxes"
- SAM2: An extension of SAM that supports streaming video segmentation while retaining promptable capabilities. "SAM2~\cite{ravi2024sam} extends this to streaming video."
- Set-of-marks numbered overlay: A visualization that indexes discovered regions with numbers to reference them in prompts or verification. "(ii) set-of-marks numbered overlay~\cite{yang2023set}"
- Vision-LLM (VLM): Models that jointly process images and text to perform tasks requiring multimodal understanding. "Recent VLMs add heads for dense prediction"
- Vision Transformer (ViT): Transformer architecture applied to images by treating patches as tokens, enabling scalable vision recognition. "an MAE~\cite{he2022masked} pre-trained Vision Transformer (ViT)~\cite{dosovitskiy2020image}"
- Zero-shot: Evaluating or applying a model to tasks without any task-specific training data. "showing that our conversational training effectively transfers to complex reasoning scenarios zero-shot (i.e., without task-specific supervision)."
Collections
Sign up for free to add this paper to one or more collections.