- The paper introduces a novel decoupled framework that uses reinforcement learning to optimize reasoning-driven multimodal embeddings.
- The methodology integrates structured Traceability Chain-of-Thoughts with text, bounding boxes, and video keyframes for explicit evidence tracing.
- Experimental results on MMEB-V2 and UVRB show improved retrieval scores and robustness, validating state-of-the-art performance across modalities.
Reinforcement Learning for Reasoning-Driven Multimodal Embeddings: The Embed-RL Framework
Motivation and Background
Universal Multimodal Embedding (UME) models constitute a critical infrastructure for robust cross-modal retrieval, localization, and semantic understanding. Prior approaches including contrastive dual-encoder models (e.g., CLIP, BLIP) and MLLM-based discriminative approaches offer scalability but suffer from modality gap issues and limited reasoning capacity. Recently, MLLM architectures have been leveraged to fuse generative reasoning (e.g., Chain-of-Thought, CoT) into UME, leading to enhanced semantic alignment. However, existing generative embedding regimes introduce several key limitations: (1) generated CoTs predominantly focus on text and are not explicitly optimized for task-relevant retrieval, (2) joint gradient-driven optimization of contrastive and generative heads leads to objective conflicts and noisy representations, and (3) the inability to exploit structured visual evidence such as bounding boxes undermines fine-grained cross-modal alignment.
Embedder-Guided Reinforcement Learning (EG-RL)
The Embed-RL framework introduces a decoupled pipeline synthesizing a supervised Embedder and a Reasoner, the latter optimized through reinforcement learning with explicit reward signals from the frozen Embedder. The central insight is to utilize the Embedder as a stable reward model, decoupling generative and embedding gradients while aligning the Reasoner's T-CoT (Traceability CoT) outputs toward modalities and objective properties most relevant for retrieval.
The EG-RL architecture advances through the following core mechanisms:
- Data Pipeline: Samples are subjected to multimodal chain-of-thought annotation, filtering, and sub-sampling, enhancing the dataset's modal diversity and alignment with semantic objectives.
- T-CoT Reasoning: The Reasoner synthesizes structured, stepwise, and modality-specific reasoning chains, explicitly encoding text keywords, spatial bounding boxes, and temporal video keyframes. These enriched T-CoTs are concatenated with input streams and serve as critical embeddings fodder, enabling explicit evidence tracing in the matching pipeline.
- Reward Construction: EG-RL leverages a composite reward comprising (a) a format compliance component, ensuring reasoning chains conform to modal and logic constraints, (b) an outcome-based reward quantifying improvements in retrieval and similarity margins as evaluated by the frozen Embedder, and (c) a process-level reward promoting query-target T-CoT alignment via a listwise discriminator.
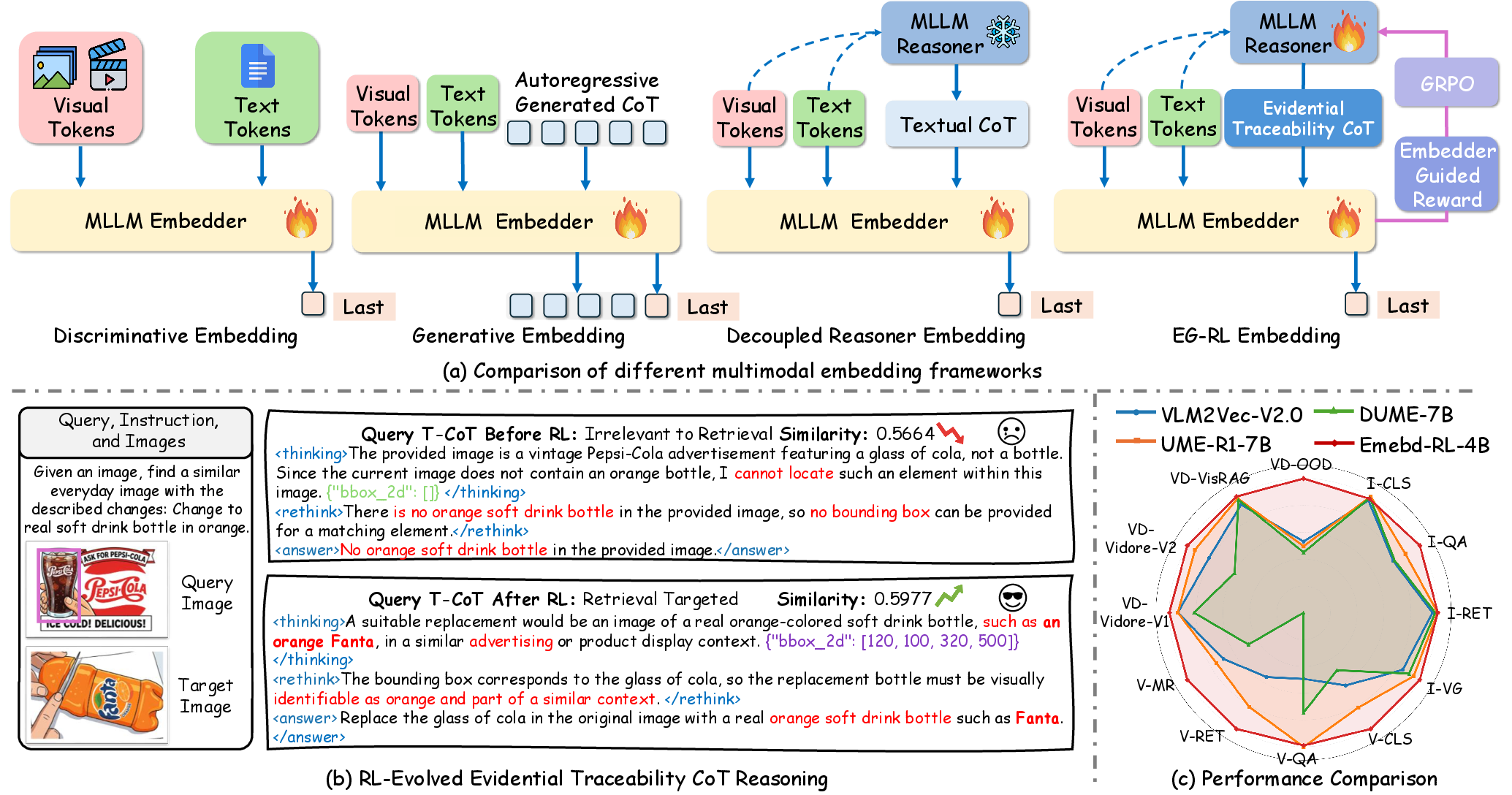
Figure 1: Multimodal embedding optimization via Embedder-Guided Reinforcement Learning. Panel (b) visualizes the optimization loop for evidential Traceability CoT.
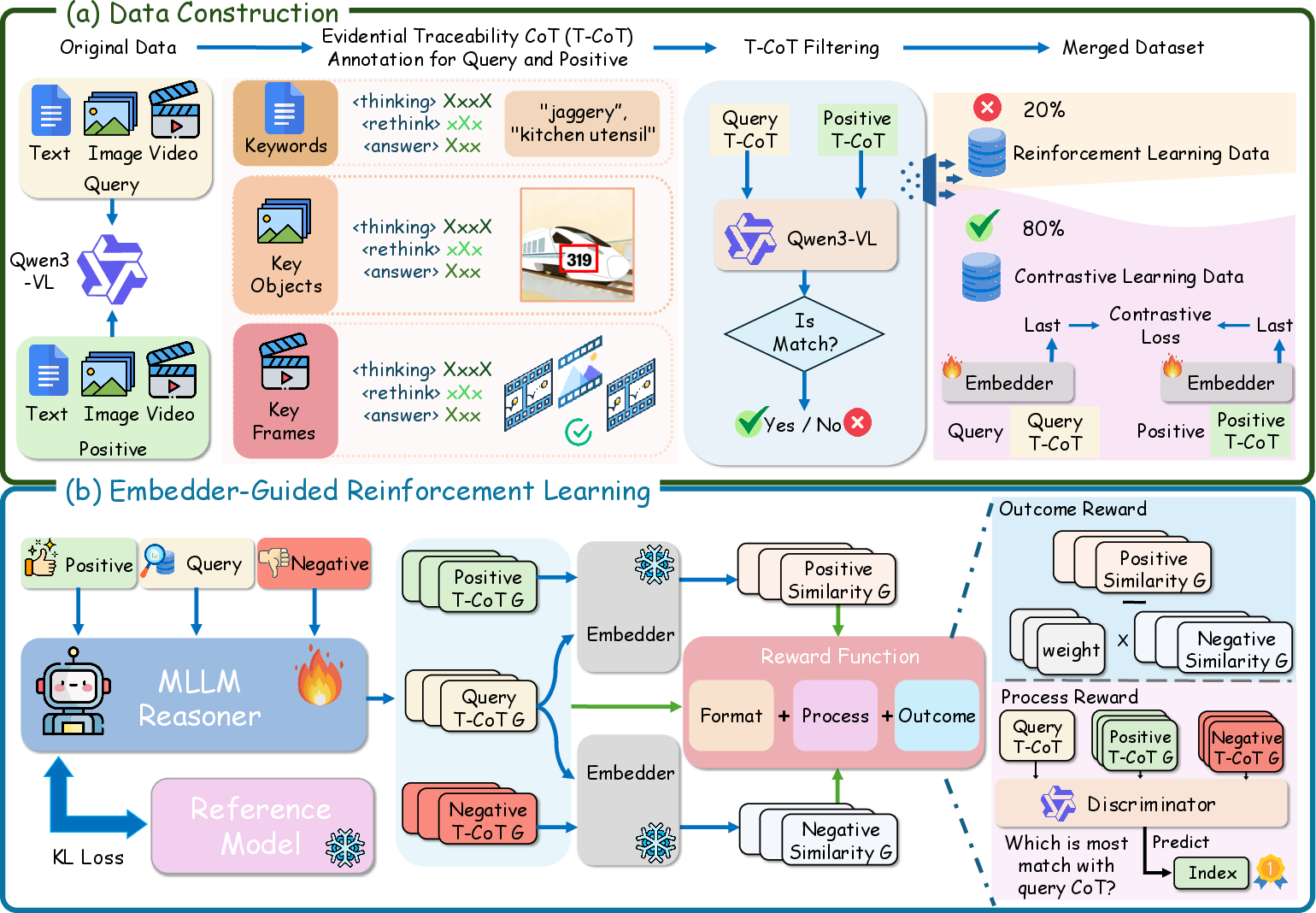
Figure 2: Data construction and the EG-RL optimization flow, showing annotation, hard negative sampling, and dual-headed reward-based RL.
Experimental Results and Empirical Analysis
Experimental results on MMEB-V2 and UVRB demonstrate strong outperformance over SOTA baselines (e.g., VLM2Vec-V2, GME, UME-R1, LamRA, Unite). Under computational constraints, Embed-RL consistently achieves the highest or second-highest aggregate and per-task scores across modalities, including image, video, and visual document tasks. Notably:
- On MMEB-V2, Embed-RL-4B achieves an overall score of 68.1, outstripping the second best baseline by 3.6 points.
- Video retrieval in UVRB shows equally robust gains, with the model leading or matching all baselines on mean R@1 and exhibiting clear generalization across coarse-grained, fine-grained, and long-context paradigms.
Ablation studies reinforce the necessity of both the process and outcome reward signals; excising either degrades embedding quality and test performance, particularly in fine-grained video and grounding tasks. Removing T-CoT and using only raw input leads to catastrophic performance collapse, verifying the criticality of evidential and multimodal reasoning for robust alignment.
The discriminative power of the framework is visualized via intra-modal and inter-modal similarity margin expansion pre- and post-RL tuning.

Figure 3: Visualization of reasoning-driven embeddings, illustrating the explicit evidence-tracing CoT in retrieval tasks.
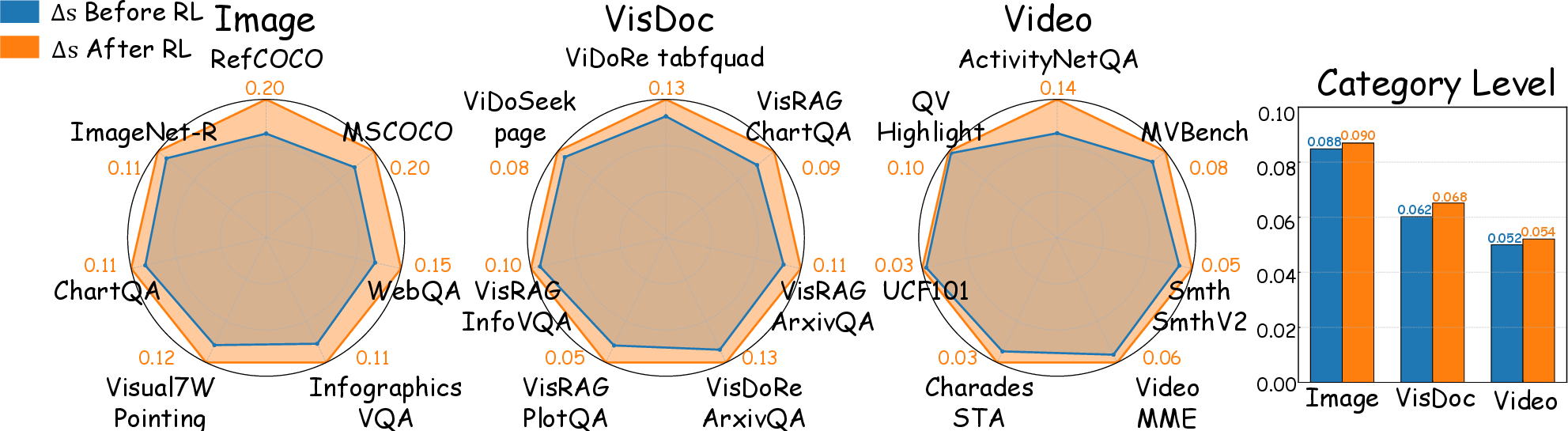
Figure 4: Similarity difference Δs between top-ranked candidates, before and after EG-RL. Post-RL, the margin widens, indicating improved discrimination.

Figure 5: Relationship between traceable evidence utilization (e.g., bounding box or keyframe count) and retrieval metrics across modalities.
Theoretical and Practical Implications
Embed-RL decisively demonstrates that explicitly optimizing reasoning traces—especially those including visual and temporal cues—via RL leads to stronger alignment, higher semantic fidelity in retrieval, and robustness across OOD setups. The framework's decoupling approach elegantly bypasses the gradients interference seen in simultaneous generative-contrastive heads, and the reward-shaping methodology encourages the emergence of interpretable, evidence-aware embeddings.
Practically, the one-pass T-CoT generation, with storage of resultant discriminative vectors, yields negligible retrieval latency compared to generative embedding approaches requiring online reasoning. This makes Embed-RL directly applicable to large-scale retrieval systems and hybrid architectures such as retrieval-augmented generation.
Limitations and Future Work
Notably, reward coefficients are empirically set and not adaptively optimized; further, classification tasks are not fully supported due to dataset filtering. Hard negative mining and dynamic curriculum learning strategies are omitted but expected to enhance discriminative power. The work opens the direction for more rigorous, possibly learnable reward scaling and adaptive weighting mechanisms, as well as more diverse task coverage and curriculum-enhanced contrastive training.
Conclusion
Embed-RL establishes that reasoning-based optimization of multimodal embeddings—anchored by explicit evidence, structured CoT, and reinforcement learning with stable reward models—substantially advances state-of-the-art performance in cross-modal retrieval, bridging previous weaknesses in modality coverage, fine-grained alignment, and out-of-domain generalization. The introduced paradigm suggests new lines of research integrating structured generative reasoning, adaptive reward engineering, and scalable evidence-tracing across all major modalities for universal representation learning.