Experiential Reinforcement Learning
Abstract: Reinforcement learning has become the central approach for LMs to learn from environmental reward or feedback. In practice, the environmental feedback is usually sparse and delayed. Learning from such signals is challenging, as LMs must implicitly infer how observed failures should translate into behavioral changes for future iterations. We introduce Experiential Reinforcement Learning (ERL), a training paradigm that embeds an explicit experience-reflection-consolidation loop into the reinforcement learning process. Given a task, the model generates an initial attempt, receives environmental feedback, and produces a reflection that guides a refined second attempt, whose success is reinforced and internalized into the base policy. This process converts feedback into structured behavioral revision, improving exploration and stabilizing optimization while preserving gains at deployment without additional inference cost. Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks. These results suggest that integrating explicit self-reflection into policy training provides a practical mechanism for transforming feedback into durable behavioral improvement.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Overview
This paper is about teaching AI systems (especially LLMs) to learn from their own experiences more like humans do. Instead of just trying something, getting a score, and guessing what to change next time, the AI goes through a loop: try → reflect on what went wrong/right → try again with the new idea → lock in the improvement. The authors call this Experiential Reinforcement Learning (ERL).
What Questions Did the Researchers Ask?
- Can we help AI learn faster and better when feedback is rare or comes late (like only finding out if you won a game at the end)?
- If the AI reflects on its mistakes in words, can that reflection guide a better second try?
- Can the AI “internalize” these fixes so it does the improved behavior automatically later, without needing extra steps or time?
How Did They Do It? (Methods)
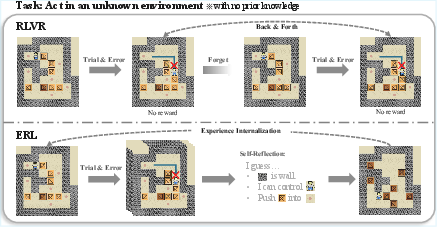
Imagine a student practicing a tough puzzle:
- First, they try to solve it.
- Then they read the result (success/failure) and think: “What went wrong? What should I do differently?”
- They write a short note to themselves (a reflection).
- They try again, following their own advice.
- If the second try works better, they study that good solution so next time they can do it right on the first try—no notes needed.
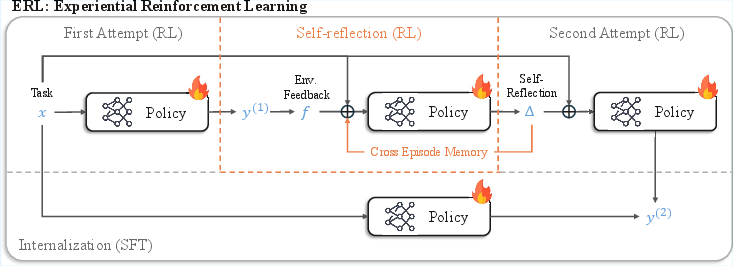
That is ERL in everyday terms. Here’s how it works for the AI:
The learning cycle
The AI follows a simple loop on each task:
- First attempt: The AI gives an answer.
- Feedback: The environment gives a signal (a number or text) about how good that answer was.
- Reflection: The AI writes a short, clear message to itself about how to improve next time. Think of this as a mini “coach’s note.”
- Second attempt: The AI tries again, now guided by its reflection.
- Reinforcement: If the second try is better, the AI is rewarded, which strengthens that behavior.
Keeping the lessons
Two extra ideas make this stick:
- Memory: Helpful reflections can be saved (like keeping good notes in a notebook) so similar future tasks benefit from past lessons.
- Internalization: The AI practices doing the improved behavior from the original input alone. In other words, it learns to perform the “better second attempt” directly as its first attempt in the future. This means at deployment it doesn’t need to spend extra time reflecting—it’s already built in.
Compared to standard reinforcement learning (which mostly uses a single number score and trial-and-error), ERL turns feedback into step-by-step advice the AI can immediately use, then permanently learn.
What Did They Find?
The authors tested ERL on:
- FrozenLake: a grid world where you try not to fall into holes.
- Sokoban: a puzzle game where you push boxes to targets (requires careful planning).
- HotpotQA: multi-step question answering using tools to search for information.
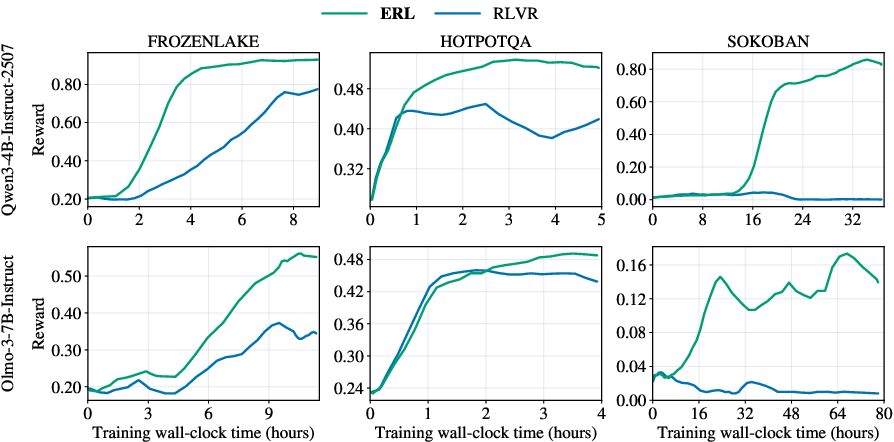
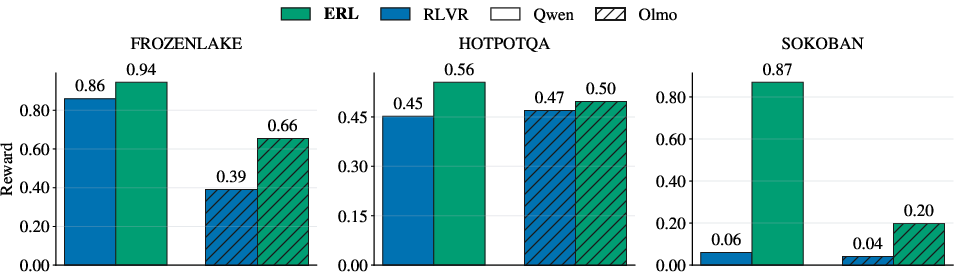
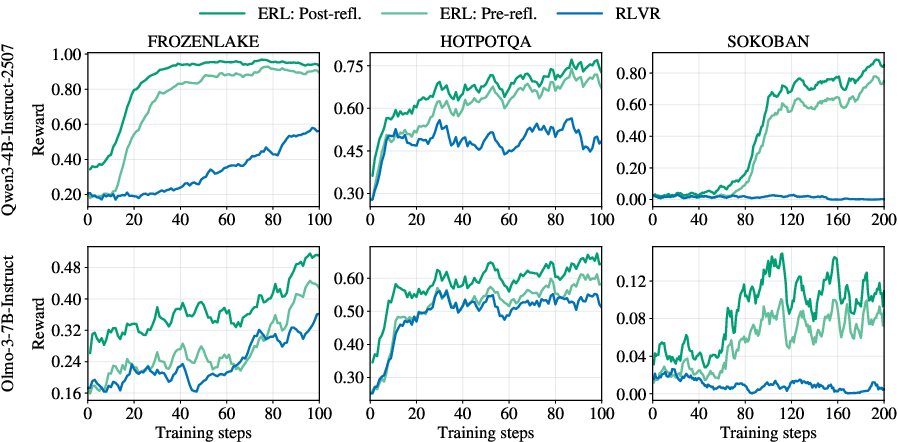
Across different AI models and all three tasks, ERL learned faster and ended with better performance than the usual method. The improvements were especially big in harder, multi-step environments with sparse rewards.
Key results include:
- Much larger gains in complex puzzles: up to about +81% in Sokoban and +27% in FrozenLake.
- Solid gains in multi-step question answering (HotpotQA): up to about +11%.
- Reflection helped the AI fix itself within the same episode: second attempts guided by reflection were consistently better than first attempts.
- Removing the reflection step hurt performance the most, showing reflection is the core driver. Memory usually helped too by reusing good ideas across tasks.
Why It Matters
- Faster learning from few signals: Many real-world tasks only tell you if you succeeded at the end. ERL helps AIs use that limited feedback more effectively by turning it into actionable advice.
- More stable training: Instead of wandering around with trial-and-error, the AI makes focused adjustments based on its reflections.
- No extra cost at use time: Because improvements get internalized, the AI can perform better without doing the reflection step when it’s deployed. That means better results without slowing down.
Takeaway
Experiential Reinforcement Learning trains AI to learn like a thoughtful student: try, reflect, retry, and then make the lesson automatic. This simple idea—turning feedback into useful self-advice and then baking it into the model—leads to faster learning and stronger performance on challenging tasks. It points toward future AI systems that continually improve from their own experiences in a human-like, efficient way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of unresolved issues and open questions that future work could address:
- Scope of environments: ERL is validated on three tasks (FrozenLake, Sokoban, HotpotQA). It remains unclear how ERL performs in broader domains (e.g., program synthesis, mathematical problem solving with formal verifiers, web navigation, robotics/continuous control, multimodal tasks).
- Model scale and diversity: Results are limited to two mid-sized instruction-tuned models (4B and 7B). Do ERL’s gains persist for larger frontier models, smaller models (<2B), non-instruction-tuned bases, or multilingual LMs?
- Baseline breadth: The comparison is only against RLVR with GRPO. How does ERL fare against alternative baselines such as:
- Inference-time reflection methods (e.g., Self-Refine, Reflexion) with and without training-time distillation.
- Other RL optimizers (PPO variants, A2C, Q-learning, off-policy RL).
- Feedback-conditioned distillation frameworks (e.g., RLS-D-style teacher–student setups).
- Strong supervised or hybrid baselines (e.g., SFT with CoT-enhanced datasets, DPO/IPO).
- Compute and efficiency accounting: ERL introduces an extra reflection and a second attempt plus a distillation step. The paper “equalizes per-task rollouts,” but does not quantify:
- Token-level training cost (tokens processed per update).
- End-to-end wall-clock training cost including internalization.
- Memory footprint and retrieval overhead.
- Inference-time latency trade-offs (even if reflection is disabled at deployment).
- Statistical robustness: Results lack reporting of variance across multiple random seeds, confidence intervals, or statistical significance tests. How sensitive are ERL’s improvements to seed and initialization?
- Hyperparameter sensitivity: The gating threshold τ governs both retry triggering and memory storage; its selection and sensitivity are not analyzed. What adaptive or learned gating strategies yield better stability and performance?
- Number of retries: ERL uses a single reflection-and-retry (two attempts). What is the optimal number of reflective retries per episode, and does performance saturate or degrade with more iterations?
- Internalization ablation: The paper does not ablate the internalization (distillation) step. How much of ERL’s performance gain depends on distillation versus RL updates? What happens if distillation is disabled or replaced (e.g., learned critics, contrastive objectives)?
- Credit assignment for reflection: Reflections receive reward equal to . This assumes causal efficacy of reflection on the second attempt. How robust is this attribution when improvements stem from unrelated exploration or stochasticity? Can counterfactual/causal estimators improve reflection credit assignment?
- Off-policy instability: Distillation uses off-policy data; stabilization techniques are mentioned but not analyzed. What are the convergence properties and failure modes when mixing on-policy RL with off-policy distillation, and how do different schedules or KL constraints affect stability?
- Reflection content and structure: “Structured reflection” is central, yet the paper does not specify the reflection format/template, length constraints, or evaluation of reflection quality. Which reflection schemas (checklists, error taxonomies, plans) work best across domains?
- Memory design and retrieval: The cross-episode reflection memory m is underspecified. Open questions include:
- Capacity limits, pruning/forgetting strategies, confidence weighting, and indexing.
- Retrieval relevance (how reflections are selected/conditioned).
- Preventing propagation of erroneous reflections (seen in Sokoban Olmo3-7B case).
- Robustness to feedback quality: ERL relies on textual feedback f from the environment. How does performance change with:
- Minimal or purely scalar feedback (no text).
- Noisy, sparse, contradictory, or adversarial feedback.
- Delayed feedback that spans long horizons.
- Generalization and transfer: Internalization aims to remove dependence on reflection at deployment, but cross-task generalization is untested. Do ERL-trained policies transfer to unseen environments or variations without re-training or reflection?
- Safety and reward hacking: Reflection-guided improvements may exploit reward functions. Are there safeguards to detect and mitigate reward hacking, unsafe behaviors, or spurious shortcuts during reflection and memory consolidation?
- Exploration metrics: The claim that ERL “reshapes exploration” is not quantitatively supported. Can we measure changes in exploration efficiency (e.g., coverage, entropy, diversity of trajectories) and link them to reflection quality?
- Tool-use specifics in HotpotQA: The tool configuration, retrieval pipeline, and failure analyses are not detailed. How do different toolkits, retrieval quality, and web environments affect ERL’s gains, and can ERL help mitigate tool unreliability?
- Reward design sensitivity: FrozenLake/Sokoban use terminal +1/0 rewards; HotpotQA uses token F1-based partial rewards. How sensitive are ERL gains to alternative reward shaping, curriculum learning, and intermediate verifiers?
- Memory harms and mitigation: The no-memory variant sometimes outperforms full ERL, suggesting memory can propagate early inaccuracies. What mechanisms (confidence scores, human-in-the-loop vetting, decay/forgetting, ensemble reflection filters) reduce memory-induced harm?
- Separate reflection policy: ERL uses the same model for attempts and reflection. Would a specialized reflection head/model (or a learned critic) improve reflection quality, reduce interference, or stabilize training?
- Scheduling and mixing objectives: The timing and relative weighting of policy-gradient updates versus distillation are not explored. What schedules (e.g., alternating phases, ratio tuning) or multi-objective optimizers yield better convergence?
- Data contamination and priors: Although explicit rules are withheld, pretrained LMs may already know environment semantics. How do pretrained priors interact with reflection, and can ERL still learn when priors are misleading or absent (out-of-distribution settings)?
- Evaluation breadth and diagnostics: Beyond aggregate rewards, the paper lacks qualitative analyses of learned strategies, reflection exemplars, error taxonomies, and failure case studies. Such diagnostics would guide targeted improvements to reflection templates and memory.
- Reproducibility and transparency: Key implementation details are relegated to appendices (not provided here). Open questions include code availability, evaluation seeds, hyperparameters, reflection prompts, and memory management specifics to ensure reproducibility.
- Ethical and privacy considerations: Persisting cross-episode reflections may store sensitive or proprietary content. What privacy-preserving memory mechanisms (filtering, redaction, differential privacy) are viable without degrading performance?
Glossary
- Advantage estimate: A value used in policy gradient methods to measure how much better an action performed compared to a baseline, guiding the strength of updates. "The advantage estimate is computed from the associated rewards."
- Agentic reasoning: A setting where LLMs act as agents making multi-step decisions with actions and observations to solve tasks. "Across sparse-reward control environments and agentic reasoning benchmarks, ERL consistently improves learning efficiency and final performance over strong reinforcement learning baselines, achieving gains of up to +81\% in complex multi-step environments and up to +11\% in tool-using reasoning tasks."
- Cross-episode reflection memory: A persistent store of reflections that were effective, reused to stabilize and guide future reflections. "Here, denotes a cross-episode reflection memory that persists successful corrective patterns discovered during training."
- Credit assignment: The problem of determining which actions in a sequence are responsible for the eventual outcome or reward. "These challenges become more pronounced in agentic reasoning tasks, where multi-step decisions could amplify small errors and obscure credit assignment."
- GRPO: A specific policy-gradient optimization algorithm used to train models with reinforcement learning. "In our experiments, we train Olmo-3-7B-Instruct \citep{olmo2025olmo3} and Qwen3-4B-Instruct-2507 \citep{yang2025qwen3technicalreport} using both standard RLVR and our proposed ERL paradigm, with GRPO \citep{shao2024deepseekmathpushinglimitsmathematical} serving as the underlying policy-gradient optimizer in all cases."
- Importance sampling: A technique to correct for distribution shift between data used for learning and the current policy, improving stability of off-policy updates. "To ensure stable training, we adopt common reinforcement learning techniques such as clipping, KL regularization, and importance sampling."
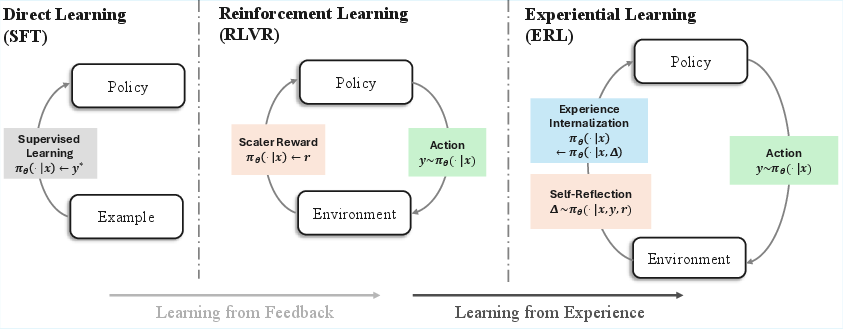
- Internalization: The process of consolidating improvements discovered during training (e.g., via reflection) into the base policy so they persist without extra context at inference. "We therefore introduce an internalization step that converts reflection-guided improvements into persistent policy behavior."
- KL regularization: A regularization method using Kullback–Leibler divergence to keep the updated policy close to a reference policy, stabilizing training. "To ensure stable training, we adopt common reinforcement learning techniques such as clipping, KL regularization, and importance sampling."
- Long-horizon planning: Reasoning and planning over sequences with many steps where early actions affect much later outcomes. "Sokoban requires long-horizon planning and recovery from compounding errors, making performance sensitive to how well the agent reasons about environment dynamics."
- Off-policy data: Data generated by a different policy than the one currently being optimized, which can introduce instability if not handled carefully. "Notably, the internalization stage in ERL naturally involves off-policy data, which can introduce additional instability."
- Policy gradient: A family of reinforcement learning methods that optimize the parameters of a policy directly via gradients of expected reward. "Importantly, ERL preserves the underlying RLVR objective: policy gradients remain reward-driven, but operate over a richer trajectory structure that includes explicit behavioral correction."
- Reinforcement Learning with Verifiable Rewards (RLVR): An RL setting where rewards are derived from verifiable outcomes (e.g., correctness checks), used to train LLMs via interaction. "Reinforcement learning with verifiable rewards (RLVR) extends learning into interactive settings by optimizing scalar feedback, allowing agents to improve through trial-and-error; however, corrective structure must still be inferred implicitly from sparse or delayed rewards."
- Scalar rewards: Single numeric reward signals provided by the environment, often sparse, that summarize outcome quality. "RLVR relies on repeated trial-and-error driven by scalar rewards, leading to back-and-forth exploration without durable correction."
- Selective distillation: A training technique that distills only successful reflection-guided attempts into the base model without including the reflection context. "We implement internalization via selective distillation: we supervise the model to imitate only successful second attempts while removing reflection context from the input."
- Self-distillation: A process where a model trains on its own stronger or improved outputs to improve itself further. "while successful second attempts are internalized via self-distillation, so the model learns to reproduce improved behavior directly from the original input without self-reflection."
- Self-reflection: A model-generated critique or analysis of its own prior attempt used to guide a refined retry. "The same model then generates a self-reflection conditioned on this attempt, which is used to guide a second attempt."
- Sparse rewards: Reward signals that occur infrequently (e.g., only at the end of an episode), making learning harder due to limited feedback. "For Frozen Lake and Sokoban, we configure the environments with sparse terminal rewards following \citet{wang2025cogitoergoludoagent} and \citet{guertler2025textarena}."
- Supervised fine-tuning (SFT): Training a model to imitate given examples using labeled data, without interactive feedback. "In supervised fine-tuning (SFT), policies imitate fixed examples, enabling strong pattern reproduction but offering no mechanism for revising behavior once deployed."
- Token-level F1: An evaluation metric computing the harmonic mean of precision and recall at the token level for text answers. "Correctness is evaluated using token-level F1 against ground-truth answers."
- Zero-shot: Performing a task at inference without task-specific training signals or additional context beyond the input. "While reflection and environment feedback provide strong training signals, such supervision is typically unavailable at deployment time, where the model must operate in a zero-shot setting."
Practical Applications
Immediate Applications
Below are near-term, actionable uses that can be deployed with today’s tooling and data, leveraging ERL’s ability to turn sparse/delayed feedback into durable behavioral improvements while keeping inference-time cost low via internalization.
- Software (Dev/QA): Test-driven code agents and CI bots
- Use case: Agents that propose a patch, read compiler/unit-test feedback, self-reflect, retry, and then internalize successful fixes—reducing flaky trial-and-error and inference-time chains-of-thought.
- Tools/products/workflows: IDE plug-ins (e.g., VS Code), CI bots that run “attempt → feedback → reflection → retry → distill” loops; integration with test frameworks (pytest, JUnit) as verifiable rewards.
- Dependencies/assumptions: High-quality unit/integration tests (reward source), safe sandboxing for execution, RL infra (e.g., GRPO/TRL), compute for two attempts + reflection at training time, proper gating to avoid propagating poor reflections.
- Knowledge Management/Enterprise Search: Multi-hop QA and retrieval agents
- Use case: HotpotQA-like tool-using assistants that reflect on failed retrieval/answer attempts and internalize improved multi-hop strategies, then deploy without reflection overhead.
- Tools/products/workflows: RAG pipelines (search APIs), exact/partial-match scoring as programmatic rewards, reflection memory vaults, reflection-distillation dataset builders.
- Dependencies/assumptions: Ground-truth answers or partial-credit metrics, stable tool APIs, privacy controls for storing reflection logs.
- Robotic Process Automation (RPA)/Web Automation: Reliable multi-step task completion
- Use case: Agents filling forms, reconciling records, or orchestrating SaaS workflows with sparse terminal “success/failure” signals; ERL improves recovery from early mistakes and locks-in fixes.
- Tools/products/workflows: Headless browsers, RPA suites (UiPath/Automation Anywhere), programmatic validators to emit rewards, ERL training pipelines integrated with action/observation logs.
- Dependencies/assumptions: Instrumented environments for deterministic success checks, sandboxing, replay buffers for offline ERL training.
- Customer Support Ops: Resolution-quality improvement loops
- Use case: Assistants that propose draft resolutions, reflect using tool- or rubric-based feedback (e.g., detection of policy violations or missing info), retry, and internalize learned corrective patterns.
- Tools/products/workflows: Ticketing integrations (Salesforce/Zendesk), policy/rubric checkers as verifiable feedback, post-resolution human labels for partial reward.
- Dependencies/assumptions: Clear, programmatic feedback signals (beyond noisy CSAT), careful PII handling in reflection logs, reward-delay mitigation (offline replay or synthetic labels).
- Education (Tutoring/Assessment): Step-by-step reasoning with answer keys
- Use case: Math/science question solving with sparse terminal correctness; the tutor reflects on failures and distills improved strategies, removing reasoning overhead at deployment.
- Tools/products/workflows: Auto-graders (exact match/F1, executable checks), tool-use (calculators/retrieval), reflection memory and selective distillation to build “corrected behavior” datasets.
- Dependencies/assumptions: Verifiable answers or executable evaluations, bias controls to avoid overfitting to specific formats, mechanisms to purge flawed reflections.
- Safety/Compliance Assistants: Rule-verifiable moderation/checking
- Use case: Content or policy-compliance checks with verifiable rules (regex/policy matchers); ERL internalizes corrections from failed first attempts to reduce repeated errors.
- Tools/products/workflows: Rule engines, sandboxed validators, dashboards comparing pre/post-reflection rewards.
- Dependencies/assumptions: High-precision rule sets for reward computation, versioned logging for auditability.
- Agent Training Infrastructure (Academia/Industry): ERL as a drop-in training stage
- Use case: Integrate ERL with existing RLHF/RLVR pipelines to improve sample efficiency in sparse-reward tasks; standardized reflection prompts and memory gating.
- Tools/products/workflows: Open-source ERL modules for GRPO/TRL, memory stores with gating thresholds (τ), UI for reflection replay inspection.
- Dependencies/assumptions: Training compute for doubled attempts, alignment with existing KL-regularized RL stacks, organizational policy for storing/inspecting reflection text.
- Cost/Latency Optimization in Deployment
- Use case: Train with reflection but deploy without it—maintaining improved behavior with lower token usage and latency.
- Tools/products/workflows: Selective distillation to “bake in” second-attempt behavior, online A/B testing against baseline RLVR agents.
- Dependencies/assumptions: Sufficient coverage of positive second attempts, monitoring for distribution shift where internalized behaviors may degrade.
Long-Term Applications
These opportunities require further research, scaling, and/or real-world integration beyond current benchmarks (e.g., Sokoban, FrozenLake, HotpotQA), but align closely with ERL’s strengths in long-horizon, sparse-reward environments.
- Healthcare: Clinical decision-support and care-pathway planning
- Use case: Agents that learn from delayed clinical outcomes (e.g., guideline adherence, adverse-event avoidance) by reflecting on initial plans and internalizing improvements.
- Tools/products/workflows: Decision-support dashboards, offline RL with proxy rewards (guideline concordance), auditable reflection logs for M&M reviews.
- Dependencies/assumptions: Ethical approval, robust causal evaluation to avoid outcome confounding, long delays/weak signals, strict privacy and traceability.
- Robotics (Real-World): Household and industrial long-horizon tasks
- Use case: Robots that reflect on failed sequences in high-fidelity simulation, internalize improvements, and transfer to real operations with reduced trial-and-error.
- Tools/products/workflows: Sim2real pipelines, reward shaping from task completion or safety constraints, memory-gated reflection libraries.
- Dependencies/assumptions: Reliable simulators, safe exploration, sim-to-real generalization, detection and pruning of bad reflections (as noted by ERL’s memory caveat).
- Finance: Strategy learning with delayed and noisy rewards
- Use case: Trading/portfolio optimization agents that reflect on strategy failures in backtests and internalize better risk-managed behaviors.
- Tools/products/workflows: Offline backtesting + reward shaping (Sharpe, drawdown), stress testing, reflection audit trails.
- Dependencies/assumptions: High risk of overfitting and non-stationarity, regulatory compliance, robust guardrails and human-in-the-loop review.
- Energy/Operations Research: Grid scheduling, logistics, and supply chains
- Use case: Planners that improve from sparse terminal metrics (e.g., on-time rate, energy cost) by reflecting on plan failures and consolidating corrective policies.
- Tools/products/workflows: Digital twins, constraint solvers as verifiable feedback, ERL-enabled planning modules.
- Dependencies/assumptions: Accurate simulators/digital twins, clear KPIs as rewards, safe deployment with override mechanisms.
- Personalized Education: Longitudinal learning strategies and metacognition
- Use case: Tutors that reflect on ineffective interventions across sessions and internalize personalization strategies that improve over time.
- Tools/products/workflows: Longitudinal outcome tracking (learning gains), metacognitive reflection libraries, privacy-preserving storage.
- Dependencies/assumptions: Data minimization and consent for reflection storage, evaluation beyond short-term correctness, fairness audits.
- Scientific Discovery/AutoLab: Experiment planning and error recovery
- Use case: Lab agents that reflect on failed experiments (e.g., synthesis or protocol deviations) and internalize improved hypotheses/protocol tweaks.
- Tools/products/workflows: Lab automation platforms with structured logs as rewards, hypothesis tracing through reflections.
- Dependencies/assumptions: High experimental cost and latency, need for strong causal reasoning and human oversight.
- Multi-Agent Systems: Coordinated reflection and shared memory
- Use case: Teams of agents that share verified reflections to accelerate collective learning under sparse coordination rewards.
- Tools/products/workflows: Reflection-sharing protocols, trust-weighted memory, cross-agent distillation.
- Dependencies/assumptions: Robust verification to avoid propagating harmful priors, provenance tracking, conflict resolution mechanisms.
- Governance/Policy: Auditable experiential training records
- Use case: Standards that require retention and review of reflection and internalization artifacts to improve transparency and accountability in RL-trained agents.
- Tools/products/workflows: Reflection log retention policies, redaction tooling, audit dashboards linking reflections to policy updates.
- Dependencies/assumptions: Legal frameworks for text-log retention, privacy-by-design for reflection content, standardization across vendors.
- Foundation Model Training: Scaling experiential learning as a core primitive
- Use case: Pretraining/continual-learning regimes that embed experience–reflection–consolidation at scale to reduce reliance on undirected exploration.
- Tools/products/workflows: Large-scale reflection memory stores, curriculum learning that gates when to reflect and when to internalize, automated pruning of erroneous reflections.
- Dependencies/assumptions: Significant compute and data-engineering investment, strong safeguards against compounding reflection errors and mode collapse.
Cross-cutting assumptions and design considerations (affecting most applications)
- Reward design and verifiability: ERL’s advantages are strongest when programmatic, even if sparse, reward signals exist (e.g., tests, exact/partial match, validators).
- Reflection quality and memory hygiene: As shown in ablations, poor or early inaccurate reflections can harm performance if persisted; requires gating thresholds (τ), decay, and human/automatic curation.
- Training–deployment gap: Internalization removes the need for reflection at inference, but only if the training covers relevant failure modes; monitor for distribution shift.
- Governance and privacy: Reflection text can contain sensitive environment details; auditability, PII redaction, and retention policies are essential.
- Compute and ops: Training requires two attempts plus reflection per episode; plan for RL infrastructure, logging, and analysis dashboards (e.g., pre/post-reflection reward curves).
Collections
Sign up for free to add this paper to one or more collections.