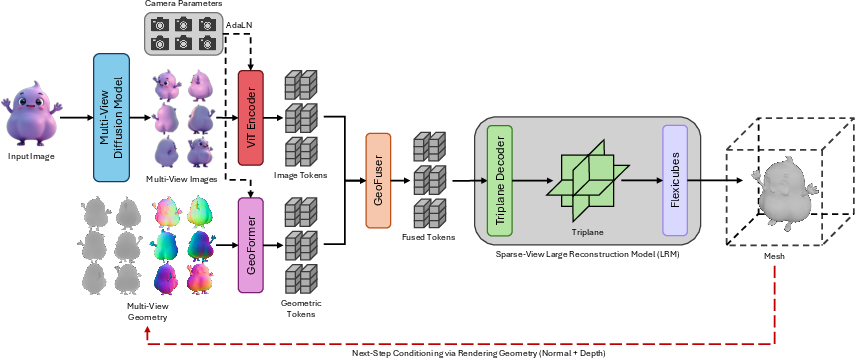
- The paper introduces GeoFusionLRM, a self-correction pipeline that leverages depth and normal cues to refine 3D reconstructions.
- It fuses semantic features with geometric information via a specialized GeoFuser module, outperforming baselines on SSIM and LPIPS metrics.
- Iterative geometry-aware refinement yields notable improvements, though backbone resolution limits recovery of extremely fine structures.
Geometry-Aware Self-Correction for Consistent Single-Image 3D Reconstruction: GeoFusionLRM
Introduction
GeoFusionLRM addresses the problem of geometric inconsistency in single-image 3D mesh reconstruction via Large Reconstruction Models (LRMs), which often yield artifacts such as distorted normals and misaligned surface details despite semantic fidelity. The methodology specifically proposes a geometry-aware self-correction pipeline that iteratively refines mesh outputs by leveraging self-predicted normal and depth maps, making geometric cues a first-class citizen in conditioning for reconstruction and enabling more accurate alignment with the input view.

Figure 1: Qualitative comparison of reconstructions from InstantMesh and GeoFusionLRM on a FLUX-generated synthesized input; GeoFusionLRM achieves sharper normals and greater geometric fidelity.
Architectural Design
The GeoFusionLRM architecture extends a baseline LRM (InstantMesh) with a dual-branch conditioning framework utilizing both semantic and geometric features extracted from intermediate renderings. The semantic stream leverages a vision transformer pre-trained with DINO and camera-conditioned AdaLN layers to encode image-level features, while the geometric stream employs a geometry-aware encoder (GeoFormer), fine-tuned on normal and depth projections.
These token streams are fused at the token level using a lightweight GeoFuser module (a two-layer feed-forward network), producing refined conditioning embeddings that guide the LRM triplane decoder in the mesh generation process. Key architectural highlights:
Quantitative and Qualitative Evaluation
GeoFusionLRM is evaluated on the GSO and OmniObject3D datasets, utilizing PSNR, SSIM, and LPIPS metrics across uniform and benchmark views for both RGB images and normal maps. The model consistently surpasses state-of-the-art baselines (LRM, SPAR3D, LGM, InstantMesh), with the greatest gains in geometric metrics, reflecting the successful integration of geometry-aware conditioning.
Notably, on OmniObject3D benchmark views, GeoFusionLRM achieves a normal map SSIM of $0.926$ and LPIPS of $0.0648$, distinctly outperforming InstantMesh (SSIM $0.918$, LPIPS $0.0769$), with RGB metrics also improved (SSIM $0.916$ vs $0.913$, LPIPS $0.0741$ vs $0.0805$). Improvements are especially pronounced in the high-frequency regions of shape where prior LRMs tend to oversmooth, merge, or hallucinate features.
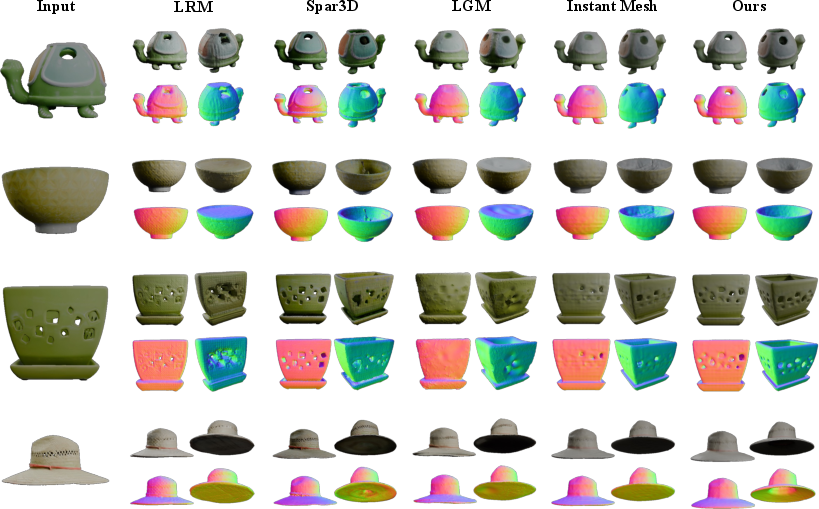
Figure 3: Qualitative comparison on GSO; GeoFusionLRM preserves surface detail and corrects ambiguous regions beyond competing methods.
Ablation and Iterative Analysis
Ablation studies confirm the necessity of both depth and normal conditioning: removing either degrades performance. Further, substituting the proposed fusion mechanism for naive token concatenation or random GeoFormer initialization causes a substantial drop in SSIM and LPIPS, illustrating the importance of learned geometric embeddings and fusion.
Iteration analysis on OmniObject3D demonstrates diminishing returns beyond one refinement iteration, with substantial improvement following the first geometry-aware correction. Computational cost analysis shows the inference TFLOPs and time nearly double compared to InstantMesh, but greatly improved geometric fidelity is achieved.
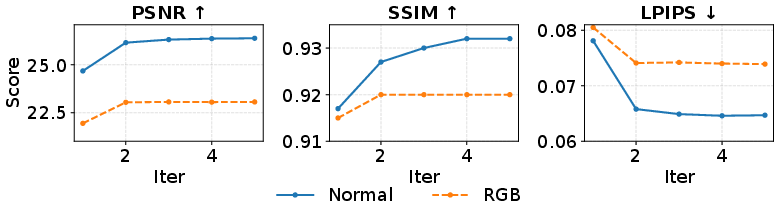
Figure 4: Performance progression over refinement iterations; most improvements materialize with the first geometry-aware pass.
Limitations
Despite enhanced branch coherence and the correction of larger-scale structural errors, the triplane resolution of the InstantMesh backbone inherently limits recovery of extremely thin structures. As shown in detailed plant reconstructions, minor branches and root segments remain unrecoverable. The refinement mechanism is restricted by the underlying representational capacity rather than conditioning alone.

Figure 5: Refinement closes gaps in coarse branches, but fine root segments remain missing due to backbone resolution constraints.
Implications and Future Directions
GeoFusionLRM demonstrates that geometry-aware conditioning can markedly improve mesh fidelity in single-image 3D reconstruction, reinforcing the necessity of structural cues alongside semantic priors. The practical implications are significant for AR/VR, robotics, and content creation workflows requiring precise geometry.
Theoretically, the results validate iterative self-correction frameworks for representation learning, suggesting that feedback from intermediate geometric predictions can serve as an effective regularizer. Future work should investigate extending the fusion framework to incorporate global geometric priors, symmetry, or semantic constraints, and explore higher-resolution backbone strategies to push fine structural recovery.
Conclusion
GeoFusionLRM establishes a geometry-aware self-corrective paradigm for LRMs in single-image 3D mesh reconstruction, integrating normal and depth feedback and achieving enhanced surface consistency and fidelity compared to prevailing baselines. The methodology exposes and corrects systematic geometric errors previously masked in RGB, with empirical validation across large-scale benchmarks. Its iterative design offers a principled pathway for improving structural quality in category-agnostic reconstruction, laying the groundwork for advanced geometry-informed conditioning frameworks in large-scale generative 3D vision.