Goldilocks RL: Tuning Task Difficulty to Escape Sparse Rewards for Reasoning
Published 16 Feb 2026 in cs.LG and cs.AI | (2602.14868v1)
Abstract: Reinforcement learning has emerged as a powerful paradigm for unlocking reasoning capabilities in LLMs. However, relying on sparse rewards makes this process highly sample-inefficient, as models must navigate vast search spaces with minimal feedback. While classic curriculum learning aims to mitigate this by ordering data based on complexity, the right ordering for a specific model is often unclear. To address this, we propose Goldilocks, a novel teacher-driven data sampling strategy that aims to predict each question's difficulty for the student model. The teacher model selects questions of appropriate difficulty for the student model, i.e., questions that are neither too easy nor too hard (Goldilocks principle), while training the student with GRPO. By leveraging the student's performance on seen samples, the teacher continuously adapts to the student's evolving abilities. On OpenMathReasoning dataset, Goldilocks data sampling improves the performance of models trained with standard GRPO under the same compute budget.
The paper introduces Goldilocks RL, a dynamic teacher-student framework that selects tasks of optimal difficulty to maximize the learning signal in reasoning models.
It demonstrates significant improvements in sample efficiency and validation accuracy across various model scales compared to standard GRPO approaches.
The framework reduces wasted compute by focusing on prompts near the decision frontier, where reward variance is highest, ensuring effective use of training data.
Goldilocks RL: A Teacher-Driven Curriculum for Efficient Reinforcement Learning on Reasoning Tasks
Motivation and Context
Addressing the computational inefficiency of reward-sparse RL for reasoning in LLMs, the paper "Goldilocks RL: Tuning Task Difficulty to Escape Sparse Rewards for Reasoning" (2602.14868) formalizes and empirically investigates the intersection between curriculum learning and outcome-based RL. The authors identify key deficiencies in conventional curriculum strategies: history-based schedules fail to generalize and are computationally impractical in web-scale RL, while category-based curricula mischaracterize instance-level difficulty. Goldilocks RL introduces a zero-shot utility estimator—a teacher trained online to select tasks of optimal difficulty for the current capabilities of a reasoning model, thereby maximizing the RL learning signal and avoiding wasted compute on trivial or infeasible examples.
Goldilocks Framework: Theory and Implementation
The Goldilocks architecture is a two-agent framework: a dynamically trained teacher, and a student model fine-tuned via RL. The student executes RL updates (GRPO or variants) on data scheduled by the teacher, while the teacher is updated asynchronously to predict the mean reward uncertainty (learning potential) per prompt. Unlike prior CL schemes, the teacher makes selection decisions in a streaming fashion without requiring repeated student exposures or external metadata.
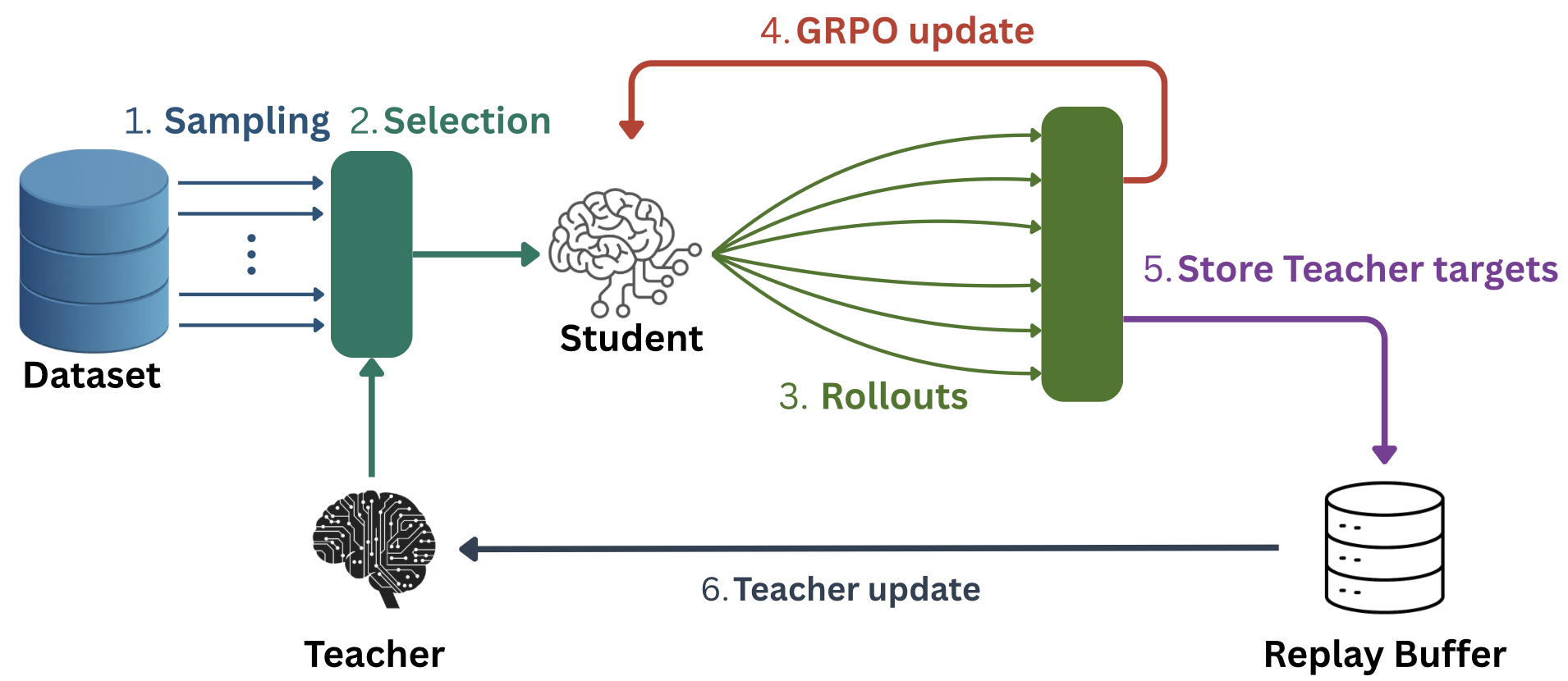
Figure 1: Overview of the Goldilocks Framework. The training cycle proceeds as follows: (1) Kcandidate questions are sampled; (2) the Teacher selects the optimal one; (3) the Student generates rollouts; (4) Student updates via GRPO; (5) Teacher targets are computed; (6) Teacher updates asynchronously.
The framework exploits a theoretical insight: with outcome supervision and group-relative policy optimization, the policy gradient's norm is proportional to pq(1−pq), where pq is the probability the student solves the prompt. Maximum gradient is achieved on prompts near the "decision frontier" (pq≈0.5), while confidently solved or intractable tasks contribute zero signal and inhibit learning progress. Goldilocks RL formalizes this by explicitly training the teacher to predict and select prompts with high reward variance for the student.
Technical Details
The student is a Transformer LM (e.g., Qwen2.5, Phi-4, Olmo2) trained via GRPO. Rollouts per prompt are grouped, and rewards decomposed into format compliance and final correctness (binary). The teacher, parameterized as a lightweight LM with a head, predicts the empirical standard deviation of group reward as a utility proxy, constraining the range by a scaled sigmoid. A candidate set of K prompts is periodically drawn; using ϵ-greedy, the teacher selects the one with maximal predicted utility (exploitation) or at random (exploration).
Rollout feedback is used to compute empirical success rates and to update a replay buffer, from which the teacher's regression head is periodically updated on the MSE loss targeting observed grad norms.
Empirical Evaluation
Experiments are conducted on OpenMathReasoning (Moshkov et al., 23 Apr 2025) with >3M chain-of-thought math problems, using several model scales and architectures. Baselines are standard GRPO-trained policies under identical global batch size and compute budgets. All key experiments normalize training steps by effective policy device allocation, controlling for total compute.
Tabled results demonstrate consistent improvement in sample efficiency and final validation accuracy across student scales with Goldilocks:
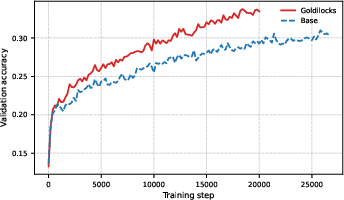
Validation accuracy evolves faster and saturates at higher levels for Goldilocks-tuned models, with particularly pronounced efficiency gains at fixed compute.
Figure 2: Evolution of validation accuracy over training steps.
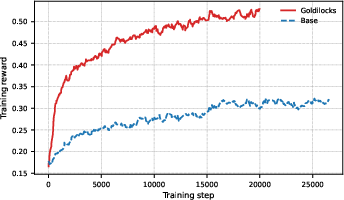
Goldilocks students consistently attain higher training accuracy and learning rates versus baseline GRPO, indicating more frequent optimizations on non-trivial, frontier tasks.
Figure 3: Average Training Reward (Success Rate). Goldilocks achieves higher training accuracy significantly earlier.
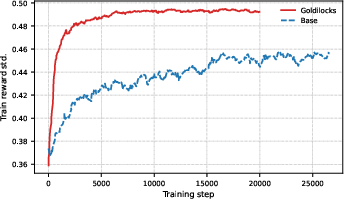
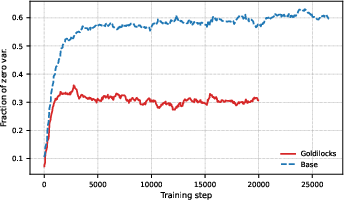
Goldilocks maintains substantially higher reward variance throughout training, suppressing the fraction of zero-variance (all correct/all wrong) batches (thus avoiding zero gradients).
Figure 4: Training Reward Std.
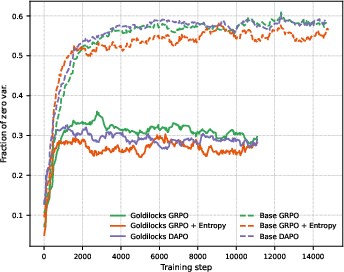
Figure 5: Fraction of questions yielding zero reward variance. Goldilocks reduces "wasted" compute on uninformative samples.
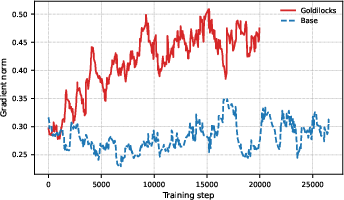
The increased gradient norm during optimization is empirically confirmed, supporting the claim that Goldilocks focuses compute on maximally informative samples.
Figure 6: Optimization Dynamics. Larger gradient norms under Goldilocks enhance learning signal and prevent stagnation.
Teacher Model Analysis
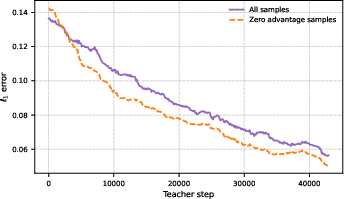
The online-trained teacher rapidly adapts to the student's shifting capability profile, maintaining low error on unseen candidate difficulty estimation.
Figure 7: Teacher Mean Absolute Error (MAE) on unseen samples.
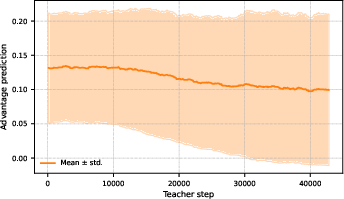
The predicted difficulty distribution adapts as training progresses, with the mean difficulty selected decreasing as regions of the curriculum are mastered.
Figure 8: Evolution of Teacher Predictions. Prediction mean and variance track model proficiency on the task distribution.
Ablations and Robustness
Goldilocks RL's gains are robust to advanced loss formulations (e.g., DAPO), and entropy-regularized objectives, confirming that scheduling non-trivial, high-potential samples provides improvements orthogonal to specific RL loss functions.
Practical and Theoretical Implications
The zero-shot, instance-level scheduling mechanism demonstrates strong generalization: the teacher rapidly infers frontier difficulties on previously unseen data, without resource-draining revisitations. This property renders Goldilocks immediately applicable to massive corpora in both finetuning and potentially pretraining, as the teacher-student cycle can filter and prioritize trillion-token streams for high-utility optimization.
Theoretically, the direct connection between the outcome reward variance and the RL gradient evokes future work on explicit signal-maximizing curricula, scalable resource allocation for multi-agent student-teacher systems, and more fine-grained utility modeling as policy complexity grows. The approach is compatible with further scheduling refinements—such as adaptive candidate set composition, model-based exploration in the data pool, or integration with process-based feedback mechanisms.
Conclusion
Goldilocks RL pioneers efficient RL-based reasoning model scaling by combining outcome-variance-driven sample scheduling with a practical online teacher-student system. It achieves consistently higher data efficiency and performance, demonstrating the value of dynamically tuning task difficulty to match model capability—thereby maximizing the learning signal and compute utilization during RL finetuning for challenging reasoning tasks.