- The paper introduces DM0, an embodied-native VLA model that integrates multimodal data from the outset to align semantic, spatial, and physical reasoning.
- The paper employs a three-stage hybrid training pipeline that incrementally refines visuomotor abilities while preventing catastrophic forgetting.
- The paper demonstrates notable performance gains on RoboChallenge benchmarks, achieving a 62.0% success rate in complex, long-horizon manipulation tasks.
DM0: An Embodied-Native Vision-Language-Action Model for Physical AI
Motivation and Framework
The paper "DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI" (2602.14974) proposes a departure from internet-native VLM paradigms by introducing an embodied-native VLA architecture, DM0, specifically targeting the development of generalist robot policies capable of robust physical-world interaction. Conventional models typically follow a Pretrain-then-Adapt pipeline, with physical grounding introduced only at the fine-tuning stage on limited embodied data, resulting in module fragmentation, catastrophic forgetting, and poor intrinsic sensorimotor priors. DM0 addresses these limitations by integrating multimodal and embodied data from the outset, aligning semantic understanding with physical reasoning and motor control through unified, hierarchical training strategies.
Model Architecture
DM0 constitutes a dual-component design: a vision-LLM (VLM) backbone and a Flow Matching-based action expert. The VLM leverages Qwen3-1.7B, augmented by a perception encoder capable of processing multi-view images, proprioceptive states, and language instructions. The Flow Matching module consumes the VLM's representations to generate continuous action trajectories, enabling direct prediction or chain-of-thought (CoT) reasoning followed by action synthesis.
Figure 1: DM0 architecture—VLM backbone and Flow Matching action expert jointly enable multimodal perception, embodied reasoning, and continuous action prediction.
The architecture incorporates flexible inference modes, factorizing the action policy’s output as πθ(l^,at:t+H∣ot,l)=πθ(l^∣ot,l)⋅πθ(at:t+H∣ot,l,l^), where at:t+H is the action sequence and l^ the intermediate textual output.
Training Pipeline and Data Strategy
DM0 employs a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. Each stage is accompanied by a specialized data mixture, progressively transitioning from diversified multimodal grounding toward embodiment specialization.

Figure 2: The curated vision-language dataset fosters embodied reasoning while retaining general multimodal alignment.
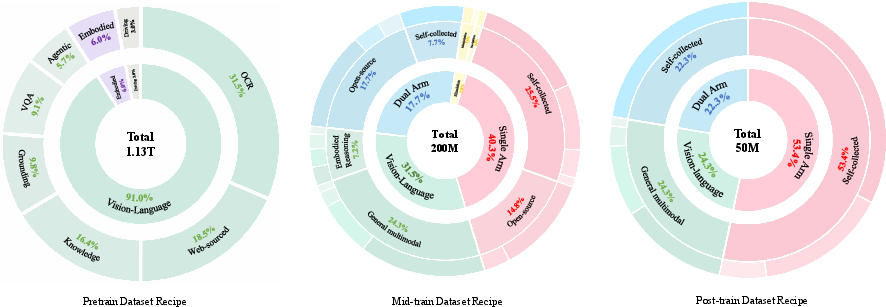
Figure 3: Data mixture ratios across pretraining (1.13T tokens), mid-training (200M samples), and post-training (50M samples) enable gradual specialization.
Pretraining focuses on constructing a multimodal corpus that includes web-sourced knowledge, educational content, OCR, visual grounding, counting, VQA, GUI, driving, and embodied data, facilitating acquisition of semantic, spatial, and physical priors. Mid-training introduces action supervision (discrete and continuous trajectories), with mixture ratios carefully balancing retention of linguistic and visual capacities against embodiment-specific control learning. Post-training narrows the embodiment scope, stabilizing fine-grained visuomotor alignment for deployment on target manipulators.
Hybrid Training and Embodied Spatial Scaffolding
DM0 implements a hybrid gradient insulation strategy: gradients from the action expert are decoupled from the VLM during embodied data training, preventing semantic degradation and catastrophic forgetting—a strong claim not commonly seen in previous architectures. The VLM remains trainable on non-embodied data to preserve general reasoning. Auxiliary objectives structured hierarchically guide the model through subtask prediction, spatial goal localization, trajectory forecasting, and action token generation. The embodied spatial scaffolding mechanism introduces spatial CoT reasoning, constraining action solutions and supporting multi-step abstraction to low-level execution.
Experimental Results and Numerical Evaluation
DM0 is evaluated on the RoboChallenge benchmark, comprising over thirty tabletop manipulation tasks requiring multi-step reasoning, spatial understanding, and precise control. Under specialist training, DM0 achieves 62.0% success rate, surpassing GigaBrain-0.1 by over 10% margin. For generalist settings, DM0 attains 37.3% success rate, outperforming π0.5-Generalist (17.67%) and π0-Generalist (9.0%). Task categories such as "arrange fruits in basket", "plug in network cable", and "sweep rubbish" highlight DM0's superior manipulation and generalization capabilities, especially in long-horizon tasks—contradicting the assumption that purely increased parameter count or internet-native pretraining suffice for embodied generalization.
Multimodal Understanding and Chain-of-Thought Reasoning
Evaluation of mid-training checkpoints demonstrates DM0's retention of core multimodal abilities: VQA, scene understanding, optical character recognition, attribute detection, and spatial grounding. The model consistently predicts subtasks, localizes targets, and generates trajectories, validating spatial CoT capabilities. DM0’s performance extends to mobile agent contexts, implicating its potential for broader embodied AI applications beyond static manipulation.
Implications and Future Work
DM0 substantiates that intrinsic, multi-source physical priors, acquired through unified embodied-native training, yield more robust generalist robot policies than post-hoc adapted internet-native models. Practically, this approach offers superior deployment-ready policies with strong generalization, reduced module fragmentation, and minimal semantic erosion. Theoretically, the hybrid insulation strategy and spatial scaffolding present significant inductive bias advantages, aligning representations with the causal structure of visuomotor decision-making.
Future research directions include scaling DM0's parameter count and data volume to explore emergent physical reasoning phenomena, expanding multimodal input to include tactile and audio signals, and integrating explicit world model capabilities for long-horizon planning and simulation. These endeavours will further probe the scaling laws and architectures underlying embodied general intelligence.
Conclusion
"DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI" provides a systematic approach to embodied VLA policy construction, challenging conventional adaptation paradigms by integrating multimodal, physical grounding from the outset. Its hybrid training, spatial scaffolding, and strong quantitative benchmarks demonstrate the efficacy and necessity of embodied-native design for achieving robust, generalist Physical AI. The paper sets a foundation for scalable, multimodal VLA research and practical deployment in diverse robotic environments.