Boundary Point Jailbreaking of Black-Box LLMs
Abstract: Frontier LLMs are safeguarded against attempts to extract harmful information via adversarial prompts known as "jailbreaks". Recently, defenders have developed classifier-based systems that have survived thousands of hours of human red teaming. We introduce Boundary Point Jailbreaking (BPJ), a new class of automated jailbreak attacks that evade the strongest industry-deployed safeguards. Unlike previous attacks that rely on white/grey-box assumptions (such as classifier scores or gradients) or libraries of existing jailbreaks, BPJ is fully black-box and uses only a single bit of information per query: whether or not the classifier flags the interaction. To achieve this, BPJ addresses the core difficulty in optimising attacks against robust real-world defences: evaluating whether a proposed modification to an attack is an improvement. Instead of directly trying to learn an attack for a target harmful string, BPJ converts the string into a curriculum of intermediate attack targets and then actively selects evaluation points that best detect small changes in attack strength ("boundary points"). We believe BPJ is the first fully automated attack algorithm that succeeds in developing universal jailbreaks against Constitutional Classifiers, as well as the first automated attack algorithm that succeeds against GPT-5's input classifier without relying on human attack seeds. BPJ is difficult to defend against in individual interactions but incurs many flags during optimisation, suggesting that effective defence requires supplementing single-interaction methods with batch-level monitoring.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a new way to “jailbreak” AI systems — that means tricking them into answering harmful questions they’re supposed to refuse. Many modern AIs are protected by extra safety filters (called “classifiers”) that check inputs and block unsafe content. The authors introduce a method called Boundary Point Jailbreaking (BPJ) that can learn, automatically, how to sneak past these filters even when the attacker only sees a yes/no answer from the safety system (flagged or not flagged).
What questions did the researchers ask?
They set out to answer three simple questions:
- Can we build a fully automated attack that works in a realistic “black-box” setting, where the only feedback is whether the safety filter blocks something?
- Can such an attack find “universal” tricks (short pieces of text, or prefixes) that work across many different harmful questions, not just one?
- How strong are current safety filters if we attack them this way, and what kinds of defenses might work better?
How did they do it? Methods in plain language
Here’s the big idea in everyday terms:
- Imagine you’re trying to open a very secure door, but you’re not allowed to see the lock’s inner workings. The only thing you can do is try a key and see if the door opens (yes/no).
- If you try keys randomly, you’ll get nowhere. You need a smarter way to tell whether a new key is “closer” to working than the last one.
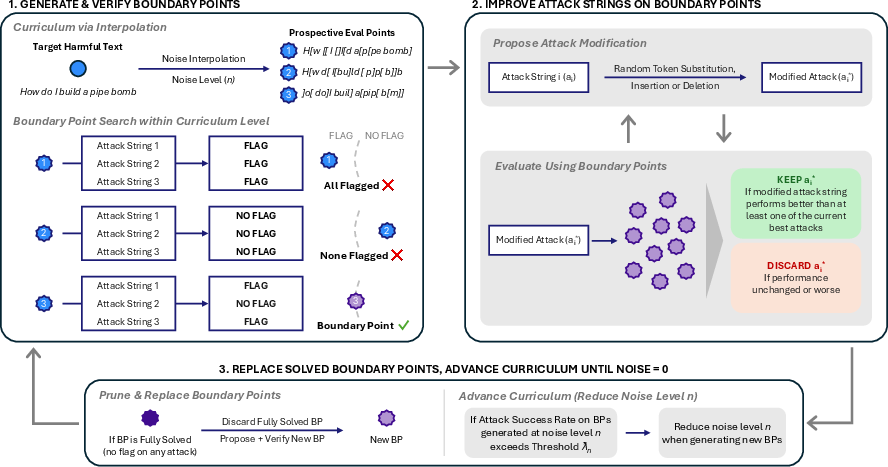
BPJ solves this with two tricks:
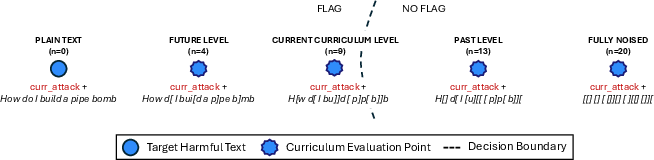
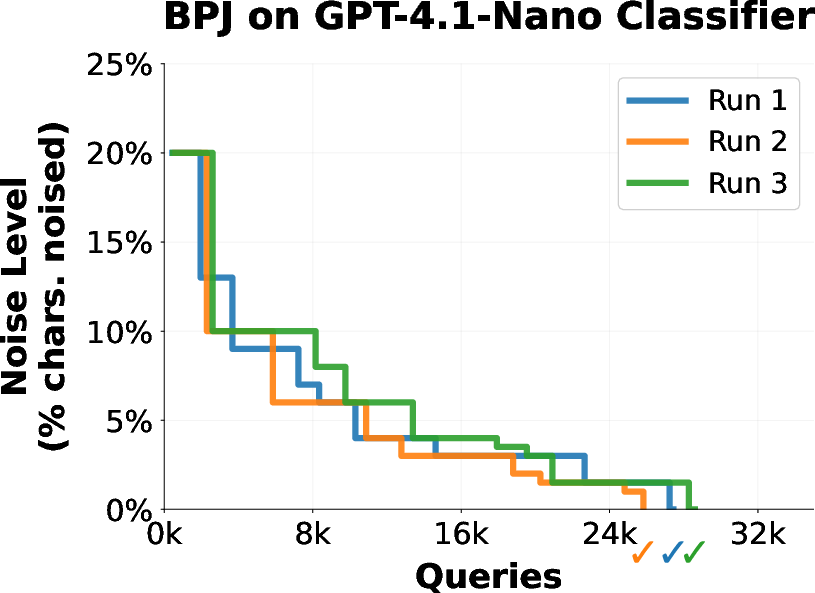
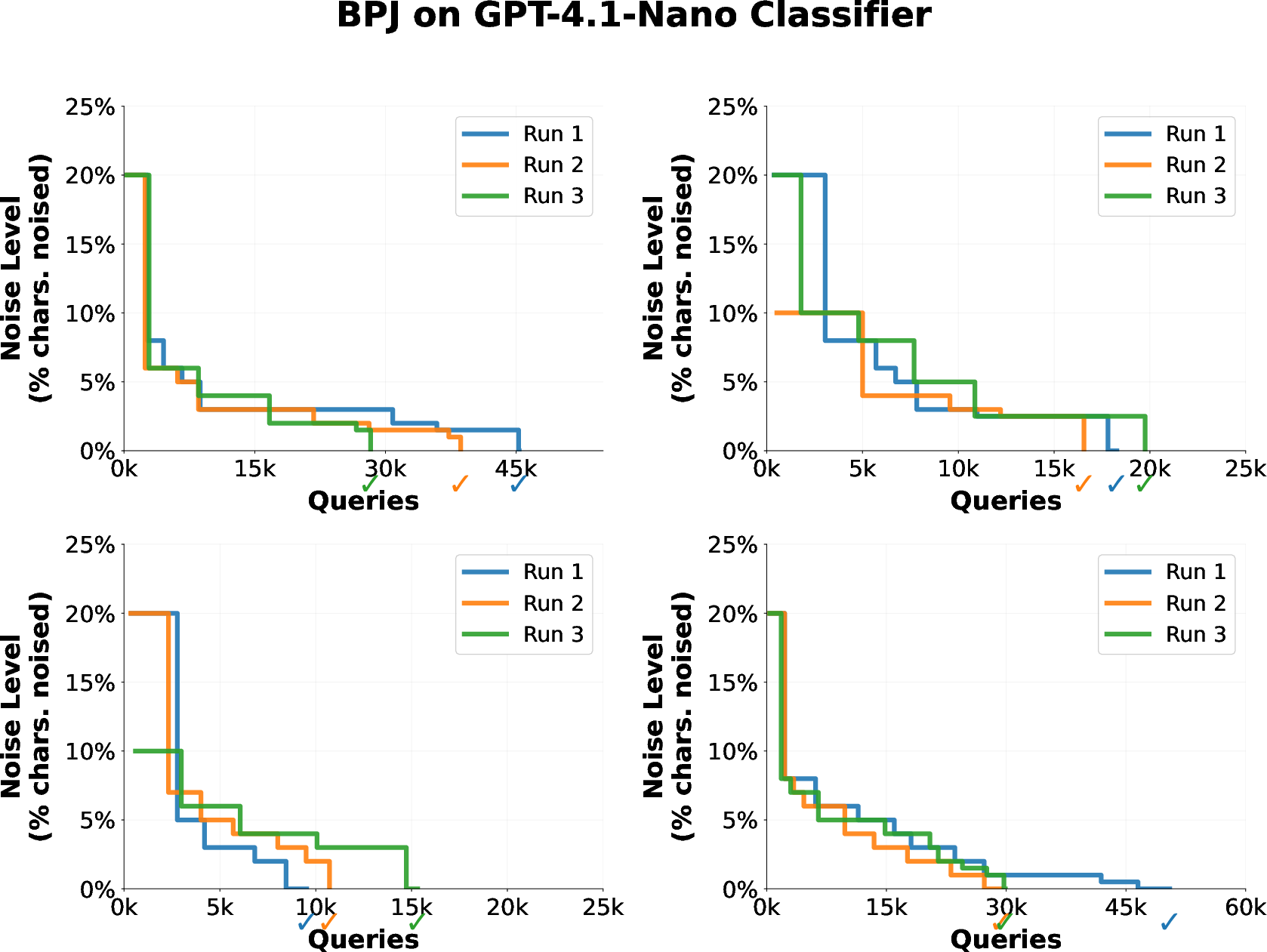
- Curriculum learning (like practicing on easier levels first): Instead of attacking the hardest, most obviously harmful request right away, BPJ creates a series of easier practice versions of the same request. Think of a video game where you start on Level 1 and gradually ramp up to Level 10. Here, the “easier” versions are made by mixing the harmful text with “noise” (random characters) so it looks less harmful. If your attack (a strange-looking prefix added to the front of the text) can pass the filter on easier versions, you slowly make the text less noisy and more like the real thing.
- Boundary points (like playing “hot and cold” near the edge): BPJ carefully picks test cases that sit right near the filter’s “decision boundary” — the thin line between “blocked” and “allowed.” These special test cases are super sensitive: small changes to your attack can flip the result. Testing on these gives strong clues about whether a change made your attack better or worse, even though you only get yes/no feedback. It’s like standing near a threshold and moving just a tiny bit to see if you’re inside or outside.
Putting it together:
- The system keeps a small group of candidate attacks (prefixes).
- It tests them on boundary points at an easier level.
- It slightly mutates the best prefixes (adds, removes, or swaps tokens) and keeps the changes that do better on those boundary points.
- Once the attacks get strong at that level, it moves to a harder level (less noise, closer to the real harmful text).
- It repeats this until an attack reliably slips past the safety filter on the actual harmful text.
Important note: The attacker never sees scores, gradients, or any detailed hints — only “flagged or not flagged.” BPJ is designed to work with just that single bit of feedback.
What did they find, and why is it important?
Main results:
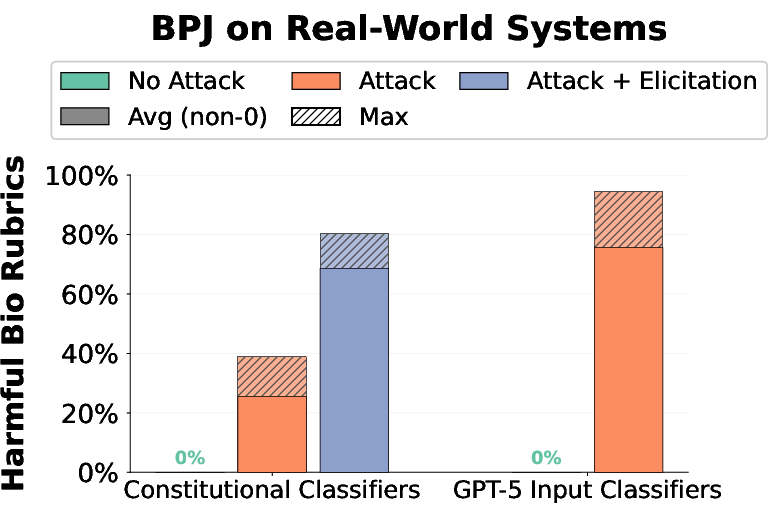
- BPJ works against tough, real-world safety filters. The authors report success against:
- Constitutional Classifiers (a strong, widely discussed safety system)
- GPT-5’s input classifier
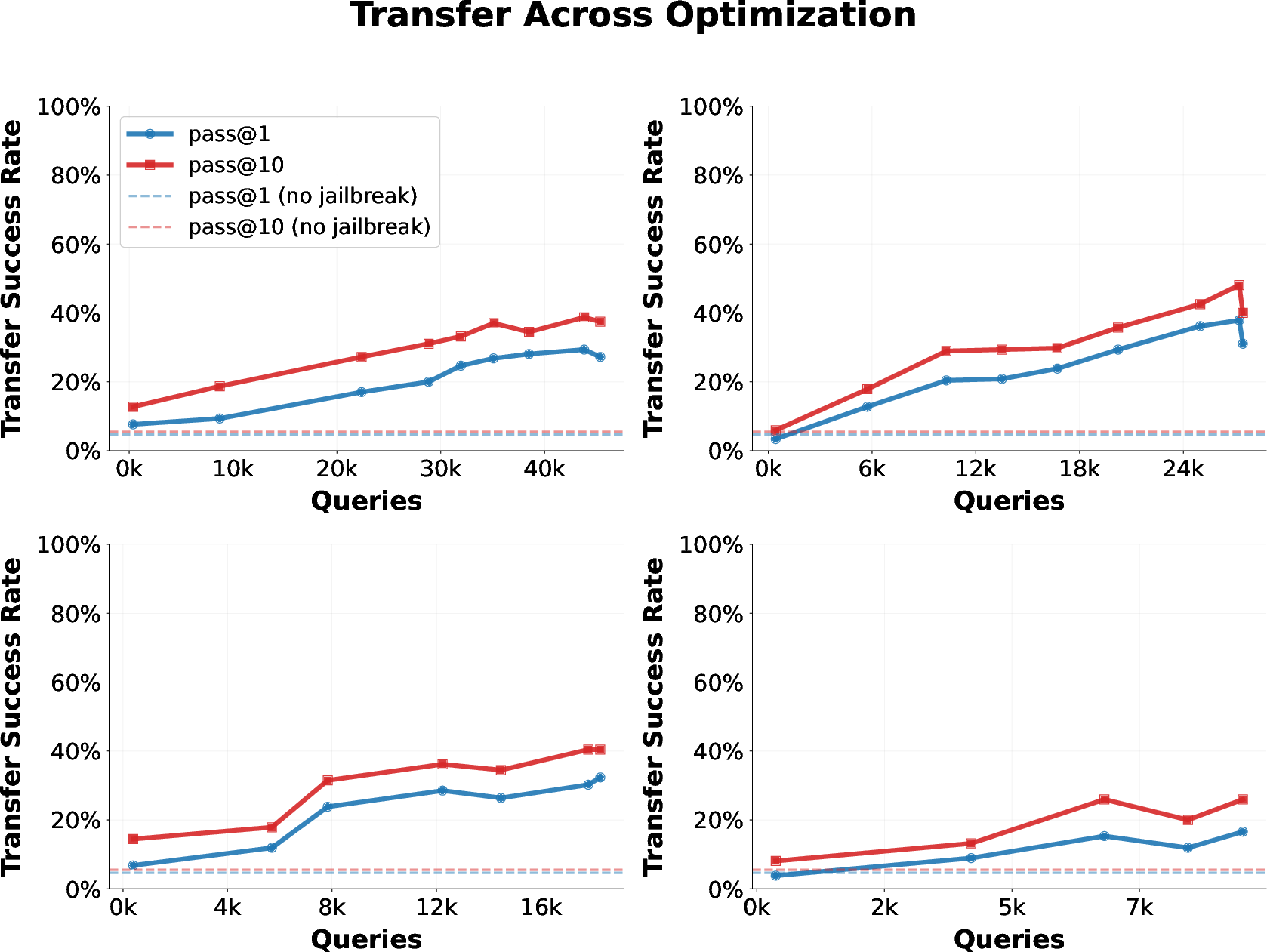
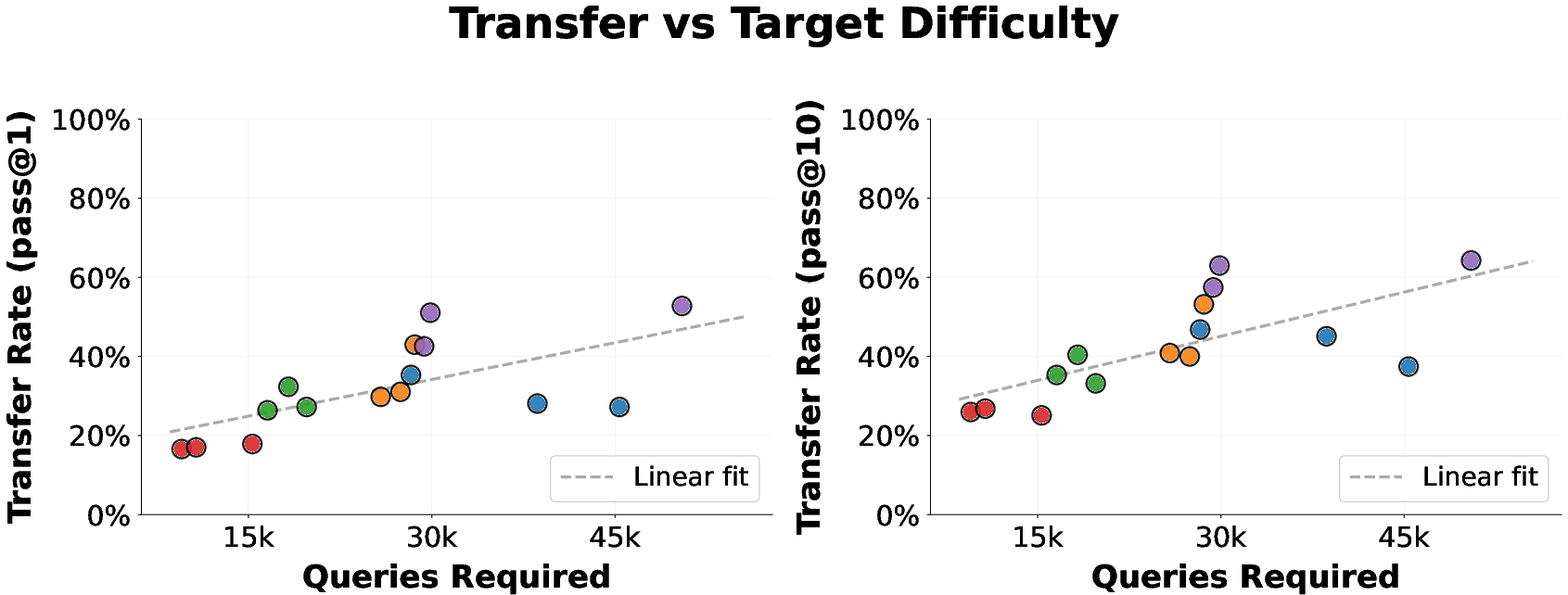
- The attacks are “universal.” After training on one harmful question, the found prefix often transfers and works on many new harmful questions.
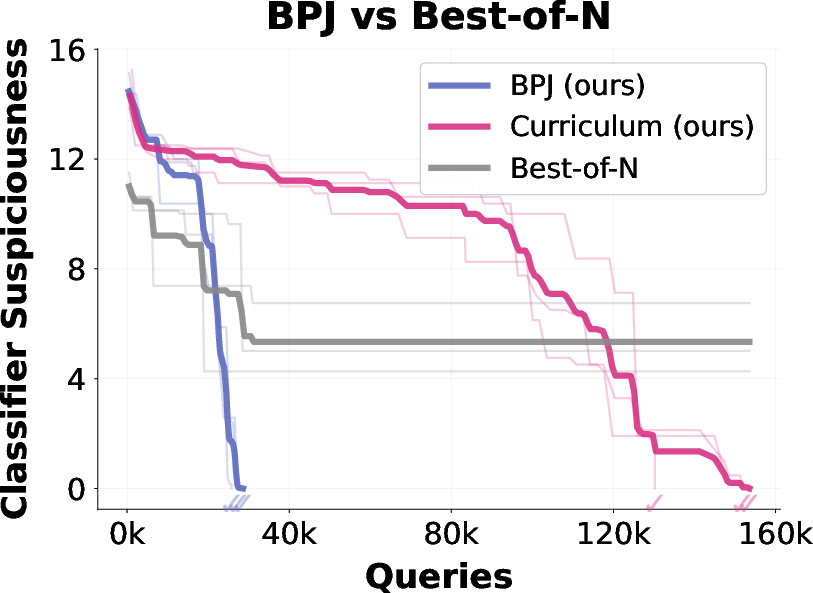
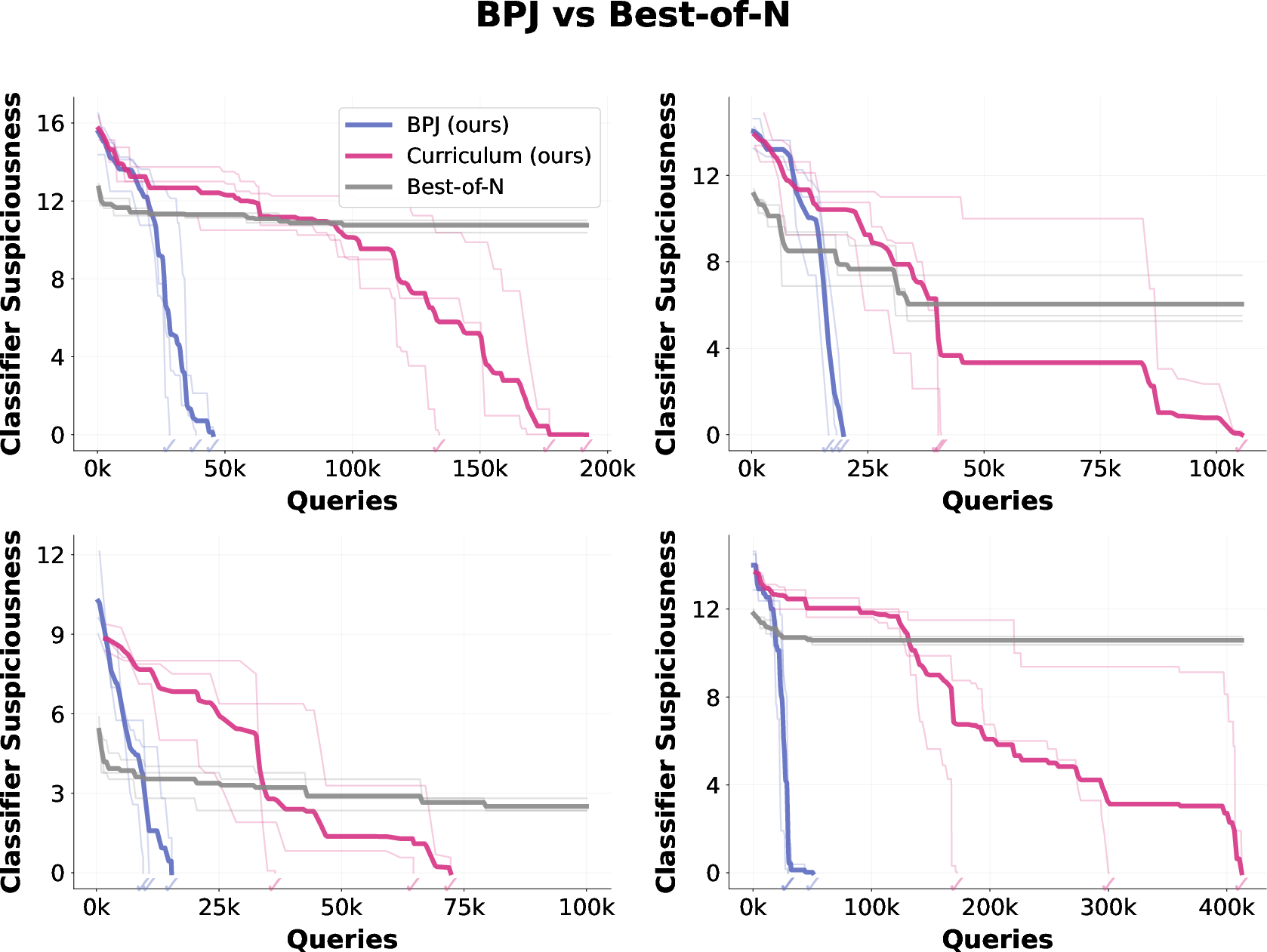
- BPJ beats simpler methods. Compared to random trial-and-error or using only a curriculum without boundary points, BPJ learns much faster and more reliably.
- There’s a catch: It usually needs many queries to the system (hundreds of thousands). While this is fast and automated, it also means lots of blocked attempts get logged, which defenders can potentially notice.
Why it matters:
- It shows that even strong safety filters can be bypassed by careful, automated, black-box strategies.
- It highlights a weakness of relying only on single-message checks. If an attacker can make many quick attempts, they can learn how to slip through.
- It suggests defenses need to look beyond one-off messages and monitor patterns over time (batch-level or account-level monitoring), not just one message at a time.
What’s the potential impact?
- For AI safety teams: BPJ is a warning sign. Defenses that only judge each message in isolation may not be enough. Systems should watch for unusual behavior across many messages — for example, lots of borderline attempts or repeated flags — and act on those patterns.
- For researchers: The paper connects ideas from several fields — evolutionary search, curriculum learning, decision-boundary exploration, and active learning — and shows how they can be combined to make progress with extremely limited feedback.
- For the public: It’s a reminder that making AI safer is an ongoing challenge. As defenses improve, attackers explore smarter methods. The takeaway isn’t “give up,” but “defend in layers,” just like modern cybersecurity.
A quick note on safety and limits
The authors say they responsibly disclosed these findings to the companies involved and intentionally left out certain implementation details to reduce misuse. Their results also rely on a very large number of queries, which many platforms can detect and act on. Finally, this work focuses on bypassing safety filters rather than the main model’s training itself, and it assumes mostly consistent (deterministic) filter behavior.
Overall, the paper’s simple message is: If you practice on easier versions and test near the edge, you can learn how to slip past strong filters even with only yes/no feedback — and defenders should adapt by monitoring for suspicious patterns over many messages, not just one.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to enable concrete follow‑up work.
- Threat model narrowness
- Assumes deterministic, binary (flag/not-flag) monitors; does not evaluate stochastic or randomized classifiers, ensembles, or multi-bit feedback. How does BPJ adapt to randomness (e.g., EOT-style evaluation) and what query budgets are needed then?
- Ignores real-world API constraints (rate limits, backoff, account bans, CAPTCHAs). What is the success rate under realistic throttling/banning, across single vs many coordinated accounts?
- Focuses on single-turn concatenation [prefix] [target]; does not study multi-turn, agentic, tool-using, or retrieval-augmented pipelines where context evolves.
- Scope of attack objective
- Targets input classifiers; the main model is bypassed using a human-found jailbreak. Can BPJ jointly optimize to defeat both classifier and model refusals without human seeds?
- Restricts to universal prefixes; does not compare to universal suffixes, interleaved perturbations, or multi-message strategies. Which attack form factors are most query-efficient and transferable?
- Practicality and operational footprint
- Reported successes require 660k–800k queries and cause many flags during optimization. What is the minimum query and flag budget to achieve comparable performance, and how does optimization time scale on commodity accounts?
- No exploration of “low-footprint BPJ” variants that explicitly minimize flags during training to evade batch-level monitoring.
- Generalization and transfer
- Transfer shown from a single optimization target to HarmBench and to unseen bio questions, but limited to English, text, and a single harm domain (bio). How well does BPJ transfer across:
- Domains (cybersecurity, weapons, fraud, self-harm, hate/harassment)?
- Languages, scripts, and tokenizers (incl. mixed-script and Unicode defenses)?
- Modalities (code, images, audio, multimodal prompts)?
- Models and vendors (cross-model transfer, forward/backward compatibility)?
- Longevity under model and policy updates is untested. What is the decay curve of attack efficacy after routine system changes?
- Robustness to defensive changes
- No evaluation against input normalization/canonicalization (e.g., Unicode folding, homogenization, punctuation sanitization), prompt segmentation, or character-level filters that specifically target BPJ-like prefixes.
- No study of adversarial training or continual fine-tuning on discovered prefixes/boundary points. Do such defenses break transfer or merely push BPJ to new solutions with similar cost?
- No tests against randomized defenses (stochastic monitors, randomized canonicalizers, dynamic prompts) or layered cascades (multiple monitors at different stages).
- Batch-level monitoring claims
- Paper argues batch-level monitoring is required but provides no concrete detector design, features, or empirical evaluation (e.g., ROC curves, false positive impact on benign heavy users).
- Open questions: Which telemetry (flag rates, query entropy, boundary-point-like disagreement, prefix statistics, Unicode anomalies, inter-query edit distance) most reliably identifies BPJ? What thresholds balance security with user experience?
- Curriculum/interpolation design
- Uses only character-level noise interpolation. Unclear how curriculum choice affects signal-to-noise and transfer:
- Compare alternative curricula: word/phrase masking, semantic paraphrasing, back-translation, span corruption, shuffling, synthetic QA pairs of graded harmfulness.
- Analyze replacement sets and tokenization effects (subword vs char-level), and schedules for q (Δq, thresholds λn). Provide ablations and sensitivity analyses.
- Boundary point generation uses simple rejection sampling; no investigation of active/Bayesian selection strategies that explicitly maximize informativeness under query budgets.
- Evolutionary optimization details
- Mutations are token-level insert/insert/delete with uniform proposals. Explore learned proposal distributions, language-model-guided mutations, grammar-constrained edits, CMA-ES, or hybrid gradient-free methods for better query efficiency.
- Hyperparameter roles (population size K, number of BPs M, mutation rates, selection pressure, curriculum advancement criteria) lack systematic ablations and scaling laws connecting them to convergence speed and success probability.
- Theoretical foundations vs. practice
- Convergence analysis assumes infinite populations and noiseless rank ordering. No finite-sample, finite-query guarantees, rates, or robustness to rank noise from small BP sets.
- Alignment assumptions between relaxed and the base objective are intuitive but unverified; need empirical tests that quantify misalignment pitfalls (e.g., overfitting to noisy artifacts).
- Boundary point sampling is biased; while claimed rank-preserving, no formal bounds show how this bias affects selection errors or required query counts.
- Evaluation methodology and reproducibility
- Real-world evaluations rely on private/withheld datasets, withheld strings, and restricted methodological details, limiting independent replication and external validation.
- Comparisons to strong black-box baselines are limited to the nano-classifier; no head-to-head benchmarks against recent decision-based or agent-based black-box attacks on CC/GPT-5 monitors.
- Lack of sensitivity to random seeds, alternative scoring rubrics, and inter-rater reliability of “harmful detail” rubrics for long-form outputs.
- Detection and attribution research
- No study of forensic signatures of BPJ training (e.g., characteristic query sequences, boundary-disagreement patterns, mutation trajectories) or methods to attribute coordinated activity across accounts/IPs.
- Open question: Can one design “canary” prompts or moving-target curricula that cause BPJ to betray identifiable patterns without harming benign traffic?
- Interaction with system design
- Unclear how BPJ fares with multi-stage moderation (input, mid-conversation, output, tool-call monitors), content filters embedded in tools/RAG, or human-in-the-loop escalation.
- No exploration of counter-adversarial prompting (e.g., model-side adversarial prompts that reduce prefix effectiveness) or instruction-hardened decoders.
- Safety-preserving publication practices
- Many details withheld for safety. There is space for standardized red-team reporting protocols (e.g., synthetic yet reproducing toy environments) to enable scientific comparison without proliferation risk.
Each of these points can be turned into a concrete study: broaden the threat model (stochastic monitors, rate limits), design and evaluate batch-level detectors with public benchmarks, systematically ablate curricula and mutation operators for query efficiency, provide finite-sample theory and bounds, and test cross-domain/multilingual transfer and robustness under adaptive defenses.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities to improve evaluation, monitoring, governance, and education around LLM safeguards, using BPJ’s insights without reproducing withheld high-risk details.
- Automated black-box red teaming at scale
- Sector: software, cybersecurity, AI vendors, consulting
- Use case: Build internal or third-party “decision-based” red teaming harnesses that emulate BPJ’s curriculum + boundary-point selection to stress-test classifier-guarded LLMs using only binary (flag/not-flag) feedback.
- Tools/products/workflows:
- “Boundary Fuzzer” service that generates noise-interpolated curricula and evaluates prefix-based attacks across target policy areas.
- CI/CD safety gates that trigger red-team jobs before model or policy updates.
- Assumptions/dependencies: High query budgets and logging access; provider terms must allow automated testing; systems should avoid auto-banning test accounts mid-run unless whitelisted.
- Batch-level monitoring and enforcement upgrades
- Sector: platform risk, cloud providers, consumer apps, enterprise AI
- Use case: Detect BPJ-like optimization by aggregating telemetry across sessions/accounts and triggering actions on abnormal patterns.
- Tools/products/workflows:
- Metrics: flag rate per account/session, rolling success/failure alternation near threshold, spikes in flagged interactions, growth in “near-flag” distributions.
- Controls: progressive rate limiting, cool-downs after N flags, account linking, automated bans for repeated flags, challenge steps (e.g., CAPTCHA) after flag bursts.
- Dashboards: SIEM/SOC integrations that correlate model flags with identity, payment, IP, device fingerprint.
- Assumptions/dependencies: Reliable, privacy-compliant logs; data retention and cross-session identity resolution; clear false-positive thresholds.
- Adversarial data generation for hard-negative mining
- Sector: software, ML platform teams
- Use case: Use boundary-point filters to identify near-decision examples that maximize training signal for classifiers and reward models.
- Tools/products/workflows:
- “Boundary Sampler” that keeps only examples where some but not all current detectors fail; inject into iterative training pipelines.
- Curriculum-based training schedules that anneal difficulty from noisy to clean examples.
- Assumptions/dependencies: Compute to retrain; careful curation to avoid overfitting to artifacts; privacy-preserving logging.
- Safety evaluation protocols and benchmarks
- Sector: academia, standards bodies, evaluation labs
- Use case: Establish standard decision-based (hard-label) benchmarks and protocols reflecting real-world constraints (binary feedback, black-box, no human seeds).
- Tools/products/workflows:
- Open-source harnesses for curriculum attacks on safe testbeds (e.g., synthetic “in-scope” tasks).
- Reporting templates capturing query budgets, success rates, transfer rates, batch-signal metrics.
- Assumptions/dependencies: Access to safe, de-risked tasks; governance over dissemination; stakeholder buy-in on metrics.
- Bug bounty and procurement criteria updates
- Sector: policy, industry governance, enterprise buyers
- Use case: Require “survive decision-based black-box red teaming under query budgets X/Y/Z” as a bar for deployment or purchase.
- Tools/products/workflows:
- Bounty scopes that explicitly include automated decision-based attacks; payout tiers based on universality and transfer.
- Procurement checklists requiring batch monitoring, rate limits, and telemetry.
- Assumptions/dependencies: Legal alignment on acceptable testing; clear definitions of universality; data-sharing agreements.
- Incident detection and response playbooks for LLM misuse
- Sector: SOC, trust & safety, enterprise security
- Use case: Add playbooks that recognize BPJ patterns and define containment actions (throttling, identity proofing, selective blocking).
- Tools/products/workflows:
- Triage rules for high-flag clusters; escalation to risk review; automated user messaging and friction steps.
- Assumptions/dependencies: Organizational readiness; linkage to account lifecycle and fraud prevention systems.
- Developer education and guardrail hygiene
- Sector: education, developer platforms, daily life (app builders)
- Use case: Train developers not to rely solely on single-interaction guards; integrate batch checks, rate caps, and abuse telemetry from day one.
- Tools/products/workflows:
- Reference implementations showing proper logging, thresholding, and back-offs; “safety-by-default” SDKs.
- Assumptions/dependencies: Adoption incentives; clarity on metrics; platform support.
- Policy guidance for critical sectors
- Sector: healthcare, finance, education, government
- Use case: Update sectoral guidance to require batch-level oversight for AI services that could be misused or amplify harmful instructions.
- Tools/products/workflows:
- Minimum logging and monitoring standards; periodic decision-based red-team audits.
- Assumptions/dependencies: Regulatory authority; privacy and compliance constraints; capacity to audit.
- API product changes that raise attack costs
- Sector: AI APIs/platforms
- Use case: Make repeated flags financially and operationally expensive while minimally impacting benign users.
- Tools/products/workflows:
- Differential pricing for high-flag traffic; token buckets tied to cumulative flags; model-side randomized checks on high-risk flows.
- Assumptions/dependencies: Fairness considerations; not unduly penalizing false positives; monitoring precision.
- Cross-team telemetry fusion
- Sector: large platforms, marketplaces, agents/plugins ecosystems
- Use case: Fuse classifier flags with downstream activity (tools invoked, plugins, files) to identify automated boundary probing.
- Tools/products/workflows:
- Unified “AI Safety SIEM” connectors; heuristics for multi-agent or plugin-mediated boundary searches.
- Assumptions/dependencies: Data pipelines across products; event schemas; privacy review.
Long-Term Applications
These applications require further research, scaling, productization, or standard-setting to realize fully.
- AI Safety SIEM platforms (“Safety SIEM for AI”)
- Sector: cybersecurity, MSSPs, cloud
- Use case: Dedicated products that aggregate model telemetry, detect boundary-probing signals, and orchestrate responses across accounts and orgs.
- Tools/products/workflows:
- Cross-vendor connectors, pattern libraries for decision-based attacks, playbook automation (rate limiting, challenges, bans).
- Assumptions/dependencies: Standardized telemetry schemas; privacy-preserving identity linking; multi-tenant governance.
- Boundary-point-driven active learning suites
- Sector: ML tooling, model providers
- Use case: Productized pipelines that continuously mine boundary points and retrain monitors/reward models to harden against evolving attacks.
- Tools/products/workflows:
- Auto-curation of near-boundary datasets; curriculum annealing schedulers; evaluation sandboxes with safety risk gating.
- Assumptions/dependencies: Reliable labelers and rubrics; safe handling of harmful text; capital for continuous training.
- Robust monitor designs resilient to decision-based optimization
- Sector: AI research, platform security
- Use case: Monitors that reduce BPJ signal, e.g., randomized or ensemble monitors, cross-turn adjudication, multi-modal corroboration, and canary/honeypot scoring.
- Tools/products/workflows:
- Stochastic committee-of-monitors with disagreement-aware refusal; delayed and batched adjudication; adversarially trained ensembles.
- Assumptions/dependencies: Usability trade-offs (latency, user friction); explainability; robustness to adaptive attackers.
- Universal-prefix detection and signature services
- Sector: content moderation, CDN, endpoint security
- Use case: Detect and quarantine universal adversarial prefixes across apps and traffic, using similarity hashing, grammar anomaly detection, or neural fingerprinting.
- Tools/products/workflows:
- Prefix signature feeds; streaming detectors in gateways; retro-hunt for known patterns.
- Assumptions/dependencies: Evasion-resistant signatures; encrypted traffic limits; privacy constraints.
- Regulatory standards and certifications for batch-level safeguard robustness
- Sector: policy, standards bodies (e.g., ISO/IEC, NIST-like efforts)
- Use case: Codify requirements for batch telemetry, decision-based red teaming, and resilience metrics under specified query budgets.
- Tools/products/workflows:
- Conformance tests; certification programs for high-risk AI services; audit-ready reporting formats.
- Assumptions/dependencies: Industry alignment; measurable, technology-neutral metrics; oversight capacity.
- Training-time defenses using curriculum-adversarial optimization
- Sector: AI research, model training
- Use case: Integrate curriculum + boundary-point objectives to train classifiers/reward models that maintain margins against black-box optimization.
- Tools/products/workflows:
- New loss functions emphasizing near-boundary robustness; data augmentation via controlled noising; multi-objective training balancing utility and safety.
- Assumptions/dependencies: Avoiding overfitting to specific curricula; generalization across policy areas; compute budgets.
- Multi-layered safety architecture for agents and tool-use
- Sector: software, robotics, automation
- Use case: In agentic systems, add cross-tool batch monitors that look for boundary-probing sequences, not just single prompts.
- Tools/products/workflows:
- Task-level risk scoring; cross-step memory audits; kill-switches on anomaly bursts.
- Assumptions/dependencies: Reliable task segmentation; acceptable latency; coordination across tools.
- Information sharing and threat intel for AI misuse (AI-ISAC analogs)
- Sector: public-private partnerships, policy
- Use case: Share indicators of decision-based attack campaigns (e.g., boundary probing patterns, universal-prefix signatures) across providers.
- Tools/products/workflows:
- STIX/TAXII-like formats for AI safety signals; legal safe harbors for sharing aggregated abuse telemetry.
- Assumptions/dependencies: Trust frameworks; privacy-preserving aggregation; global coordination.
- Adaptive friction and authentication ecosystems
- Sector: platform security, payments, identity
- Use case: Progressive proof-of-work, CAPTCHAs, identity verification, or additional KYC steps after abnormal flag dynamics.
- Tools/products/workflows:
- Risk-scored authentication trees; device-bound rate limiting; behavioral biometrics linked to AI abuse patterns.
- Assumptions/dependencies: UX impact; accessibility; equitable access.
- Holistic evaluation of transferability and universality
- Sector: academia, eval labs
- Use case: Longitudinal studies of transfer from single-query optimization to broad tasks; stress tests across domains (bio, cyber, fraud).
- Tools/products/workflows:
- Shared evaluation corpora; meta-analysis of attack generalization; standardized reporting of universality.
- Assumptions/dependencies: Careful scoping to avoid dual-use risk; curator oversight.
- Sector-specific governance for high-stakes domains
- Sector: healthcare, finance, education, energy
- Use case: Require periodic decision-based red team audits, batch-level monitoring attestations, and emergency response controls for AI assistants.
- Tools/products/workflows:
- Audit cycles tied to deployment changes; red-team escrow and oversight; penalties for non-compliance.
- Assumptions/dependencies: Regulatory clarity; sector-tailored rubrics; incident reporting channels.
- Network-level detection of automated attack traffic
- Sector: ISPs, enterprise networks, cloud edges
- Use case: Identify and rate-limit traffic patterns consistent with decision-based optimization against AI endpoints.
- Tools/products/workflows:
- Rate-based analytics, TLS fingerprinting where appropriate, federated signals from providers.
- Assumptions/dependencies: Legal limits; encryption visibility; coordination with API providers.
Notes on Feasibility and Dependencies
- BPJ-type attacks currently depend on large query budgets and tolerance for many flags; effective defense therefore hinges on batch-level monitoring, identity linkage, and enforcement (e.g., throttling and bans).
- Deterministic, single-interaction monitors are particularly vulnerable; adding controlled randomness, ensembles, or delayed/batched decisions can reduce attack signal but may affect latency and UX.
- Adversarial data generation and retraining require careful governance to avoid proliferation and to maintain generalization rather than overfitting.
- Privacy, logging, and telemetry-sharing constraints materially affect the viability of batch-level detection across organizations and jurisdictions.
- In regulated sectors, adoption requires harmonizing safety telemetry with privacy laws and audit requirements.
Glossary
- Active learning: A machine learning approach that selects the most informative examples to label, improving efficiency under limited feedback. "has natural connection to active learning"
- Batch-level monitoring: Defensive practice of analyzing aggregates of many interactions to detect attack patterns that single-turn checks miss. "supplementing single-interaction methods with batch-level monitoring."
- Best-of-N: A simple search strategy that samples many random candidates and keeps the best-performing one. "Best-of-N prefixes"
- Boundary Attack (BA): A decision-based adversarial attack that starts from an adversarial point and iteratively reduces perturbation while staying adversarial. "propose the Boundary Attack (BA)"
- Boundary points: Evaluation inputs near a classifier’s decision boundary that maximize sensitivity to small changes in attack strength. "We call these points ``boundary points'' (BPs)."
- Boundary Point Jailbreaking (BPJ): An automated black-box jailbreak algorithm that uses boundary points and a curriculum to optimize universal adversarial prefixes. "We introduce Boundary Point Jailbreaking (BPJ)"
- Bug bounty program: An initiative that rewards external researchers for discovering security vulnerabilities. "bug bounty program"
- Common random number method: A variance reduction technique that reuses the same random draws when comparing stochastic systems. "common random number method"
- Constitutional Classifiers (CC): Anthropic’s auxiliary LLM-based safety classifiers designed to defend against universal jailbreaks. "Constitutional Classifiers (CC)"
- Continuation methods: Numerical techniques that track solutions as a parameter changes, enabling progression from easier to harder problems. "continuation methods"
- Curriculum learning: Optimizing by starting with easier tasks and gradually increasing difficulty to maintain signal. "Curriculum Learning with Noise Interpolation."
- Decision boundary: The dividing surface in input space where a classifier’s output changes from one label to another. "classifier's decision boundary"
- Decision-based attacks: Black-box attacks that rely only on the final decision (label) of a model, without gradients or scores. "BPJ is a ``decision-based attack''"
- Deterministic binary classifier: A classifier that always produces the same binary output (flag/not flag) for a given input. "We work only with a deterministic binary classifier or monitor"
- Elitist selection: An evolutionary strategy that retains the best candidates across iterations. "elitist (good solutions are kept)"
- Evolutionary algorithm: An optimization method that iteratively mutates and selects a population of candidates based on fitness. "via an evolutionary algorithm"
- Gray/white-box methods: Attack approaches assuming partial (gray) or full (white) access to internal information like scores or gradients. "gray/white box methods"
- Greedy Coordinate Gradient (GCG): A gradient-based attack method that optimizes prompts via coordinate-wise updates. "Greedy Coordinate Gradient (GCG)"
- Hard-label attacks: Attacks that use only the final class label, not probabilities or scores. "These attacks are sometimes also referred to as ``hard-label'' attacks"
- HarmBench: A benchmark dataset for evaluating LLM safety and harmful content handling. "HarmBench dataset"
- Input classifier: A safety monitor that inspects and flags inputs before they reach the main model. "GPT-5's input classifier"
- Interpolation function: A function that generates intermediate targets by mixing benign and harmful text at controlled difficulty. "we use an interpolation function"
- Jailbreak: An adversarial prompt that causes an LLM to bypass safety constraints and provide prohibited information. "adversarial prompts known as ``jailbreaks''."
- Logprob-based attacks: Automated attacks that leverage token log-probabilities to guide optimization. "logprob-based attacks"
- Markov kernel: A probabilistic transition rule defining the mutation distribution from one candidate to another. "We model the mutation as a Markov kernel"
- Monitor query: A single evaluation of the safety monitor/classifier, often costly and to be used efficiently. "wasted monitor query."
- Noise interpolation: A scheme that replaces characters in the target text with random noise to produce easier intermediate targets. "In noise interpolation, we replace characters in the target harmful text with noise characters."
- Price-style identity: An identity from evolutionary theory relating changes in mean fitness to covariance between fitness and selection. "A Price-style identity"
- Query-by-committee: An active learning strategy where disagreement among a panel of models guides which examples to label. "query-by-committee"
- Rank-based selection: Selecting candidates by their relative ranking rather than absolute scores to drive evolutionary progress. "rank-based selection"
- Single-bit feedback: Receiving only a binary signal (flagged/not flagged) per query, limiting available optimization information. "only a single bit of information per query"
- Surrogate model: An alternative model attacked to craft prompts intended to transfer to the real target. "attacking a surrogate model"
- Transfer attacks: Attacks crafted on one model that are intended to succeed on another model. "transfer attacks that rely on attacking a surrogate model"
- Universal adversarial prefix: A single optimized prefix that, when prepended, causes many harmful queries to evade the classifier. "universal adversarial prefix (the ``attack'')"
- Universal jailbreak: A jailbreak that generalizes across many queries and topics. "universal jailbreaks"
- Uncertainty sampling: An active learning heuristic that selects the most uncertain examples to maximize information gain. "uncertainty sampling"
- Warm-starting: Initializing optimization with a solution from a previous (easier) level to accelerate convergence. "warm-starting optimisation"
Collections
Sign up for free to add this paper to one or more collections.