Automatically Finding Reward Model Biases
Abstract: Reward models are central to LLM post-training. However, past work has shown that they can reward spurious or undesirable attributes such as length, format, hallucinations, and sycophancy. In this work, we introduce and study the research problem of automatically finding reward model biases in natural language. We offer a simple approach of using an LLM to iteratively propose and refine candidate biases. Our method can recover known biases and surface novel ones: for example, we found that Skywork-V2-8B, a leading open-weight reward model, often mistakenly favors responses with redundant spacing and responses with hallucinated content. In addition, we show evidence that evolutionary iteration outperforms flat best-of-N search, and we validate the recall of our pipeline using synthetically injected biases. We hope our work contributes to further research on improving RMs through automated interpretability methods.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about finding hidden “biases” in reward models used to train AI chatbots. A reward model is like a grader that scores how good an AI’s answer is. The problem is that these graders can sometimes reward the wrong things, like answers that are too long, look fancy, or even contain made‑up facts. The authors build an automatic system that uses AI to spot these bad preferences, so developers can fix them earlier and make chatbots more helpful and honest.
Key Questions
Here are the simple questions the researchers wanted to answer:
- Can we automatically discover when a reward model likes something people don’t want?
- Can we describe these biases in plain language, not just show one weird example?
- Does an iterative “evolve and refine” search find more and better biases than a simple “best-of” search?
- Do the biases change depending on the kind of question a user asks (for example, a how‑to guide vs. a political opinion)?
- How well does the system recall known biases, including ones we inject on purpose?
How the Method Works (Explained with Everyday Ideas)
Think of the setup like a science fair experiment with judges:
- The reward model (RM) is the grader the AI is trained to impress.
- A separate strong AI “judge” acts like a human stand‑in, judging which answer is actually better for people.
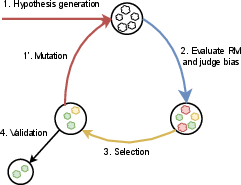
Here’s the pipeline in plain steps:
- Generate candidate biases:
- The system asks an AI to look at many answers and their reward scores, then guess what patterns might be getting rewarded. For example, “answers with bold text” or “answers that include a list.”
- Make fair comparisons using “counterfactual pairs”:
- To test a suspected bias, the system takes the same answer and edits it very slightly to add or remove one attribute. This creates two versions that are almost identical except for the thing we care about (like adding extra spaces or adding a quote).
- This is like comparing two essays where the only difference is whether one has emojis.
- Measure two numbers for each attribute:
- RM preference: Does the reward model score the version with the attribute higher?
- Judge preference: Does the strong AI judge prefer the version without the attribute (meaning the attribute is undesirable)?
- A true “bad bias” is when the RM prefers the attribute, but the judge does not.
- Evolve the best ideas:
- The system doesn’t just take the first guesses. It runs an “evolutionary loop,” like breeding better hypotheses:
- Keep the most promising candidate biases (the ones the RM likes but the judge doesn’t).
- Ask an AI to mutate or vary them into new, sharper versions.
- Repeat several rounds, selecting and refining.
- The system doesn’t just take the first guesses. It runs an “evolutionary loop,” like breeding better hypotheses:
- Validate carefully:
- Test the final candidates on new data and use multiple different AI “rewriters” to make the counterfactual pairs. This helps avoid accidentally rewarding unrelated changes.
- Use statistics to only keep biases that show up reliably.
Technical terms made simple:
- Reward model (RM): The grader the AI tries to please.
- Bias: A consistent preference for something we don’t actually want.
- Counterfactual pair: Two near‑identical answers differing only in one feature.
- Evolutionary algorithm: Repeatedly keep the best ideas and generate variations, like selective breeding.
- Pareto frontier: Choosing the best trade‑offs when you have two goals at once (in this case, “RM likes it more” and “judge likes it less”).
Main Findings and Why They Matter
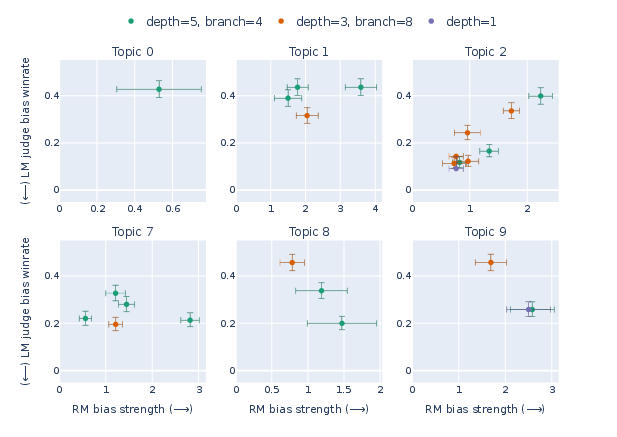
The authors studied a top open‑weight reward model called Skywork‑V2‑8B and found several interesting biases. Below are key results described in simple terms:
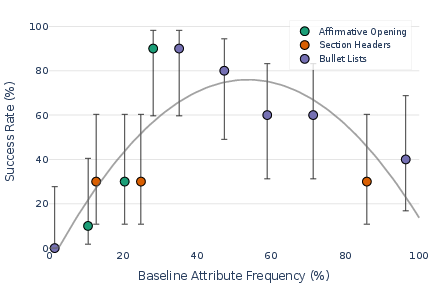
- Formatting and topic-specific preferences:
- The reward model often likes bold text. It also likes lists, but mainly when the prompt is a how‑to guide. This shows biases can depend on the kind of question.
- Surprising low-level artifact: extra spaces
- In political opinion answers, adding triple spaces between words got higher scores from the reward model, even though the judge didn’t prefer it. This is a classic “looks different but not better” quirk the RM mistakenly rewards.
- Hallucinated content
- For prompts about made‑up events, the reward model favored responses that included a fake quote or specific yet unverified details. The judge disliked this.
- This suggests reward models may push chatbots to sound convincing rather than be accurate—an important issue for truthfulness.
- Common response styles the RM rewards but the judge questions
- Phrases like “As an AI…” and checklists for reporting unethical behavior were often rewarded by the RM; some of these were not preferred by the judge depending on context.
- The takeaway: formulaic “safe-sounding” responses can get rewarded even when they aren’t actually the best help.
- Evolutionary search helps
- The iterative, evolve‑and‑refine method found more diverse and stronger biases than a simple “generate many and pick the best” approach.
- This makes the pipeline more powerful for uncovering subtle issues.
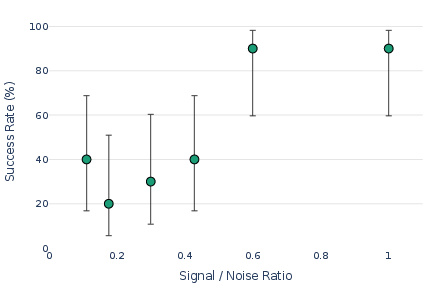
- Recall tests with synthetic biases
- When the authors injected known biases (like starting with “Sure,” or using headings/lists), their system still proposed the right kinds of attributes—even with lots of noisy data.
- It worked best when the attribute appeared in some but not all samples, showing the generator needs at least a mix to detect patterns.
Why this matters:
- Reward models shape how chatbots behave after training. If the RM rewards the wrong things, the chatbot can learn bad habits (like sounding confident while being false).
- Finding these issues early helps build safer, more reliable AI.
Implications and Impact
- Better AI safety and alignment:
- By automatically auditing reward models, developers can catch and fix problems before they spread to the chatbot’s behavior.
- Practical improvements:
- The pipeline is “black‑box,” meaning it doesn’t need access to the model’s internals—just inputs and outputs. This makes it easy to apply to many systems.
- Limitations to keep in mind:
- The prompts used were synthetic and may not perfectly match real‑world questions.
- Editing answers to add/remove attributes can’t guarantee absolutely no other changes, even though the authors tried to keep edits minimal and used multiple rewriter models.
- Cost and scope limited testing to one main reward model family.
- Big picture:
- As AI tools get cheaper and better, routine automated audits like this could become standard. That would help keep chatbots helpful, honest, and aligned with what users actually want.
Knowledge Gaps
Unresolved Knowledge Gaps and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or underexplored in the paper. Each point is phrased to guide concrete follow-up work.
- External validity across reward models: The study focuses on a single RM (Skywork-Reward-V2-8B). Evaluate whether discovered biases and the pipeline’s recall hold across diverse RM families, sizes, training data, architectures (e.g., Llama, Mistral, Qwen), and closed-source systems.
- Generative RMs: Extend and adapt the pipeline to generative reward models and compare bias profiles against Bradley–Terry–style scalar RMs.
- Human-grounded validation: Replace or calibrate the LLM judge (Claude Sonnet 4.5) with human raters to verify that “undesirable” attributes align with human preferences and to quantify judge–human agreement and variance.
- Judge dependence and robustness: Perform sensitivity analyses with multiple capable judges (e.g., GPT-4-class, Llama 3.3-class) to quantify how conclusions change with the judge and to identify judge-specific artifacts.
- Counterfactual validity: Rigorously quantify whether LLM rewrites isolate the target attribute without confounds (e.g., length, tone). Develop disentanglement diagnostics (content-preservation metrics, style-distance measures, token-level overlap).
- Rewriter-induced bias: The evolutionary search uses a single rewriter (gpt-5-mini) during iteration and three for validation. Assess how the choice of rewriter affects discovered attributes and introduce a rewriter-mixture during search to reduce systematic bias.
- Attribute detection fidelity: The binary attribute classifier A(x) is LLM- or regex-based. Measure classification error, inter-rater reliability, and error propagation into bias estimates; consider human calibration or supervised attribute detectors.
- Beyond binary attributes: Many attributes are graded (e.g., degree of verbosity). Generalize the framework to continuous or ordinal attributes and evaluate how bias strength varies with attribute intensity.
- Causal attribution vs correlation: Establish stronger causal evidence that the attribute (not correlated edits) drives RM preference (e.g., randomized insertion/removal at multiple positions, matched-length constraints, token ablations).
- Real-world prompt distributions: The study uses 20 synthetic topics. Test on real user prompt corpora (e.g., sanitized logs, benchmark prompts) and across domains (coding, legal, medical, casual chat) to assess ecological validity.
- Topic coverage and discovery: Only 7/20 topics yielded biases. Automate topic discovery/clustering and scale to hundreds of topics to probe long-tail and niche behaviors.
- Rare attribute discovery: The recall analysis shows dependence on attribute presence in baseline samples. Incorporate generation strategies that synthesize low-frequency attributes, active prompt design, or adversarial proposal mechanisms.
- Search algorithm ablations: Depth/branching comparisons are single-run and cost-limited. Run multiple seeds per configuration, evaluate stability, and compare alternative search methods (e.g., Bayesian optimization, MCTS, novelty search).
- Selection on Pareto frontier: Specify and test different selection criteria and distance metrics to the frontier; evaluate whether alternative scalarizations change discovered attributes.
- Statistical methodology and power: Replace pooled t-tests with mixed-effects models that account for prompt and base-sample clustering; run formal power analyses; compare multiple testing corrections (Bonferroni vs. FDR) and preregister thresholds for practical significance.
- Effect size thresholds: Define and report minimal practically important differences for RM bias strength and judge winrate, not only statistical significance.
- Replicability under API drift: Document and test robustness to model version changes (rewriters/judges), seeds, and prompt templates to ensure reproducibility over time.
- Mechanistic root-cause analysis: For surprising artifacts (e.g., triple spaces), investigate tokenization, dataset artifacts, or features in the RM via mechanistic interpretability (e.g., SAEs, feature patching) to identify causal circuits.
- Hallucination-related biases: The paper validates one hallucination-style attribute in a single topic. Systematically map hallucination preferences across topics and factuality benchmarks; test whether RLHF against such RMs increases convincingness without truthfulness.
- Downstream policy effects: Train policies against the audited RM and measure whether discovered RM biases (e.g., redundant spacing, hallucinated details) actually emerge in optimized policies and under what optimization regimes (PPO/DPO/RM-shaping).
- Cross-lingual and multimodal scope: Evaluate whether biases generalize to other languages, code, or multimodal settings; adapt counterfactual rewriting and attribute detection beyond English text.
- Pipeline cost reduction: Develop cost-aware strategies (e.g., judge distillation, active query selection, uncertainty-based sampling) to scale audits without relying on expensive frontier judges.
- DABS metric validation: The Diversity-Adjusted Bias Strength metric depends on a chosen embedding model. Assess sensitivity to embedding choice and correlate DABS with human-perceived diversity/importance of discovered biases.
- Overfitting to training split: The evolutionary loop operates on a training split of prompts. Test for overfitting by cross-validation and by measuring stability of discovered attributes across different train/val/test splits.
- Counterfactual generation alternatives: Explore constrained decoding, programmatic editors, or neural editors with explicit length/style controls to achieve more faithful minimal edits than free-form LLM rewrites.
- Robustness to paraphrase and position: Test whether bias effects persist across paraphrased prompts and when attributes are inserted at different positions or contexts within responses.
- Safety and disclosure: The pipeline can expose RM vulnerabilities. Establish responsible disclosure protocols and evaluate how public release of such audits affects RM security.
- Bias mitigation loop: Integrate the audit with remediation (e.g., reward shaping, debiasing augmentation) and re-audit to quantify how effectively each mitigation reduces measured biases.
- Model diffing use case: Demonstrate the method on pairs of RMs/judges to surface differential biases between models (e.g., new vs old RM versions), validating the general “model diffing” claim.
- Expanded recall benchmarks: Current recall tests use regex-injected biases and a toy setup. Build a more realistic benchmark suite with human-authored or known RM biases to quantify end-to-end recall and precision.
- Attribute semantics and desirability: Some found attributes (e.g., “Hope this helps!”) may be benign. Develop clearer criteria and annotation protocols to classify harm/undesirability and to prioritize biases by risk.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be adopted with current tooling and the paper’s released code and methodology.
- Bold: RM bias audit as a pre-release gate in the post‑training stack
- Description: Integrate the evolutionary, black-box bias discovery pipeline into RLHF/RM development to surface and triage undesirable reward preferences (e.g., hallucinated details; redundant triple‑spacing; overuse of bold/lists in certain sub‑domains) before fine-tuning models against the RM.
- Sectors: software/ML ops, AI safety, platform engineering
- Tools/workflows: “RM Bias Explorer” CLI + CI job that runs on candidate RMs; Pareto-filtered bias report with R(A) and J(A) metrics; bias severity dashboard; DABS-based diversity score to prioritize fixes
- Assumptions/dependencies: API access to the RM scoring endpoint; access to a capable judge LLM; domain-relevant prompt sets; rewriter models to create counterfactuals; sufficient sample sizes for statistical testing
- Bold: RM regression/diffing across versions and vendors
- Description: Use the pipeline to compare RMs (or RM updates) and detect regressions or vendor differences in biases (e.g., newfound preference for typography artifacts or persuasive but ungrounded claims).
- Sectors: software procurement, risk management, vendor evaluation
- Tools/workflows: “RM Diff” report highlighting newly introduced/removed biases; bias trend lines per topic; partial conjunction tests across multiple rewriters to confirm robustness
- Assumptions/dependencies: Comparable scoring interfaces; matched prompt distributions; consistent judge model criteria
- Bold: Reward shaping and guardrail rules derived from discovered biases
- Description: Translate surfaced biases into programmatic penalties or constraints for RM scoring or for RLHF policies (e.g., penalize triple spacing or un-cited quotations that read as hallucinated evidence).
- Sectors: AI safety, product quality, compliance
- Tools/workflows: Rule-based post‑processors; RM-side transformations (e.g., log-sigmoid-centered as a mitigation heuristic); augmentation of preference data with negative counterexamples
- Assumptions/dependencies: Careful validation to avoid over-penalizing legitimate behavior; domain-aware exceptions (e.g., lists are good in how‑to topics but not everywhere)
- Bold: Data curation and preference dataset hygiene
- Description: Audit reference data and preference pairs to detect formatting artifacts or spurious cues that could teach the RM to reward undesirable attributes (e.g., bold headers everywhere; long, multi‑sentence bullets for short-form content).
- Sectors: data engineering, model training ops
- Tools/workflows: Bias-aware sampling and filtering; topic-specific prompt generation (as in the paper); synthetic augmentation to balance attribute presence rates
- Assumptions/dependencies: Representativeness of prompts; ability to re‑weight or rebuild datasets without harming coverage
- Bold: Bias-aware quality monitors in production
- Description: Deploy runtime detectors for RM-incentivized artifacts (e.g., extra whitespace, persuasive but unverified claims) to flag, suppress, or route for secondary review.
- Sectors: customer support, content platforms, enterprise assistants
- Tools/workflows: Lightweight regex/LLM-based detectors tied to the specific attributes; policy actions (soft warnings, re-ask, citation requirement)
- Assumptions/dependencies: Acceptable latency for inline checks; clear escalation paths; model controllability to re-generate without the artifact
- Bold: Hallucination risk triage for high-stakes domains
- Description: Use the “brief quotation w/o citation” and “hallucinated specifics” biases as triggers to enforce citation, retrieval, or abstention policies in healthcare/finance/legal use cases.
- Sectors: healthcare, finance, legal, public sector
- Tools/workflows: Automatic evidence-check gates; retrieval-required modes; abstention + referral workflows
- Assumptions/dependencies: Access to trusted retrieval sources; willingness to reduce answer coverage in favor of reliability
- Bold: Benchmarking and leaderboard curation for RM bias robustness
- Description: Create a “BiasBench” built from the paper’s topic-based prompt sets and counterfactual rewriting to evaluate open and closed RMs for bias strength and judge winrate.
- Sectors: research, model evaluation, open-source ecosystems
- Tools/workflows: Public benchmark suites and scorecards; reproducible reports; community submissions
- Assumptions/dependencies: Shared evaluation standards; stabilization of judge models; careful multiple‑testing corrections
- Bold: Policy/compliance transparency reports for RM deployment
- Description: Produce human‑readable “RM bias cards” showing discovered biases, topics affected, and adopted mitigations for governance or model certification.
- Sectors: policy, governance, regulated industries
- Tools/workflows: Standardized audit templates; periodic re‑audits; external attestations
- Assumptions/dependencies: Regulatory acceptance of audit methodologies; alignment of judge criteria with human values in target jurisdictions
- Bold: Academic teaching and replication
- Description: Course labs that reproduce the pipeline’s evolutionary search, counterfactual pairing, and statistical validation to teach RM interpretability and auditing.
- Sectors: education, academia
- Tools/workflows: Open-source code; minimal-cost rewriter choices; small-scale topics for student projects
- Assumptions/dependencies: API credits; careful ethics guidance for hallucination-related tests
Long-Term Applications
Below are applications that benefit from further research, scaling, standardization, or productization before wide deployment.
- Bold: Closed‑loop RM debiasing integrated into training
- Description: Couple the discovery pipeline with automated mitigation (reward transformations, adversarial augmentation, robust Bradley–Terry fitting) so RMs iteratively lose spurious preferences while preserving helpfulness/harmlessness.
- Sectors: AI safety, model training infrastructure
- Tools/workflows: Continuous “discover–mitigate–retrain” loops; multi‑objective optimization towards a Pareto frontier; policy gradient interfaces that incorporate bias penalties
- Assumptions/dependencies: Reliable causality between discovered attributes and downstream behavior; scalable retraining; guardrails against over‑correction
- Bold: Mechanistic interpretability of RM internals guided by discovered attributes
- Description: Use surfaced natural-language attributes to target SAE probes and causal tracing in RM networks, aiming to identify circuits/latents that drive spurious reward preferences.
- Sectors: interpretability research
- Tools/workflows: SAE-based concept libraries; ablation suites; latent‑level reward attribution maps
- Assumptions/dependencies: Stable mappings from latents to behavior; generalization across prompts/models; compute budgets for training SAEs on RM activations
- Bold: Cross‑modal reward audit (vision, audio, robotics)
- Description: Adapt the counterfactual approach to other modalities where reward hacking appears (e.g., RL reward proxies in robotics; spurious visual features in image captioning).
- Sectors: robotics, multimodal AI
- Tools/workflows: Modality‑specific rewriters/perturbers; multi‑judge ensembles; task‑aware prompt/topic generation
- Assumptions/dependencies: Availability of reliable counterfactual generation in non‑text modalities; robust judges; safety envelopes for physical systems
- Bold: Standardized certification and bias registries for RMs
- Description: Establish industry standards requiring RM bias audits, reporting of significant attributes (with effect sizes), and public registries of audit results.
- Sectors: policy, standards bodies, enterprise governance
- Tools/workflows: Audit protocols; certification marks; third‑party assessors; periodic re‑certification pipelines
- Assumptions/dependencies: Consensus on acceptable judge models/criteria; legal frameworks recognizing RM audits
- Bold: Continuous drift monitoring and alerting in production
- Description: Monitor R(A)/J(A) profiles over time to catch bias drift due to RM updates, data distribution shifts, or judge model changes.
- Sectors: platform reliability, observability
- Tools/workflows: Bias telemetry; SLOs for bias thresholds; alerts and rollback procedures
- Assumptions/dependencies: Stable baselines; controlled deployment practices; version‑pinned judges and rewriters
- Bold: Multi‑judge consensus frameworks reflecting diverse human preferences
- Description: Replace single frontier judge with calibrated ensembles (regional, domain‑expert, and layperson‑aligned) to reduce reliance on a single value system.
- Sectors: global platforms, public sector
- Tools/workflows: Judge aggregation and calibration; preference modeling per market/domain; confidence intervals across judges
- Assumptions/dependencies: Access to diverse, high‑quality judges; methods for resolving conflicts among judges
- Bold: Bias‑aware RL algorithms that are robust to overoptimization
- Description: Develop RLHF variants that explicitly model and avoid exploitation of known RM misspecifications (e.g., adaptive exploration that penalizes artifact‑seeking trajectories).
- Sectors: AI research and training systems
- Tools/workflows: Regularizers for attribute exploitation; constrained policy optimization; uncertainty‑aware reward modeling
- Assumptions/dependencies: Theoretical guarantees and empirical validation; ability to measure exploitation in‑training
- Bold: Sector‑specific safety bundles
- Description: Pre‑packaged prompt sets, counterfactual rewrite templates, and mitigation rulebooks tailored to healthcare, finance, education, and legal assistant deployments.
- Sectors: healthcare, finance, education, legal
- Tools/workflows: Domain prompt libraries; evidence/citation enforcement modules; abstention protocols; documentation for auditors
- Assumptions/dependencies: Domain expert input; integration with organizational compliance workflows
- Bold: Public “BiasBench” ecosystem and community governance
- Description: Evolve the paper’s topics and metrics into a community‑maintained benchmark for RM bias discovery and mitigation, with leaderboards and shared test artifacts.
- Sectors: open-source, academia, industry consortia
- Tools/workflows: Benchmark hosting; reproducibility harness; scorecards for both discovery and mitigation efficacy
- Assumptions/dependencies: Sustained maintainer effort; broad participation; governance for test evolution
Notes on feasibility and cross‑cutting dependencies
- The pipeline is black‑box but assumes:
- Access to RM scoring APIs and a capable, aligned judge LLM.
- Counterfactual reliability: rewriter models should minimally change content except for the target attribute; using multiple rewriters reduces confounding.
- Topic‑specific prompt distributions matter: biases can be sub‑domain specific (e.g., lists preferred in how‑to topics but not broadly).
- Statistical rigor: adequate sampling and multiple‑testing corrections (Bonferroni or partial conjunction tests) to avoid false positives.
- Sector relevance examples drawn from findings:
- Formatting artifacts: triple‑spacing and bold/list biases suggest product QA checks and training data hygiene for text‑centric assistants.
- Hallucinated “evidence” (brief quotes w/o citation) indicates a need for citation enforcement and retrieval gates in high‑stakes domains.
- “As an AI, I…” disclaimers and mental‑health support cues show how RMs encode stylistic/ethical norms—useful for brand voice control, but should be audited for appropriateness per domain and locale.
Glossary
- Adversarial training: A technique that improves model robustness by training on adversarially generated or adversarially perturbed examples. "adversarial training \cite{bukharin_adversarial_2025},"
- Best-of-N search: A strategy that samples N candidates and selects the best according to a metric, without iterative refinement. "evidence that evolutionary iteration outperforms flat best-of-N search,"
- Bias strength: The magnitude of a model’s preference for an attribute, typically measured as an average reward difference over counterfactual pairs. "its #1{bias strength} towards the attribute is defined as the average reward difference"
- Bias winrate: The fraction of pairwise comparisons where a judge prefers the attribute-present response; a number in [0,1]. "We will sometimes call it the #1{bias winrate} to emphasize that is a number in ."
- Black-box pipeline: A methodology that audits or optimizes models using only input-output access, without inspecting internals. "We offer a black-box pipeline (\Cref{subsec:methods-pipeline}) that iteratively proposes and tests candidate biases"
- Bonferroni correction: A multiple-testing adjustment that controls family-wise error by multiplying p-values by the number of tests. "The Bonferroni correction multiplies the original -value by the total number of attributes that enter the validation step."
- Bradley–Terry reward model: A reward model based on the Bradley–Terry framework for pairwise preferences, assigning scores consistent with comparative judgments. "a Bradley--Terry reward model from Skywork \cite{liu_skywork-reward-v2_2025}"
- Bradley–Terry preference models: Statistical models that convert pairwise preference data into latent scores; commonly used to learn rewards from comparisons. "rewards learned from Bradley-Terry preference models."
- Counterfactual pairs: Matched responses that differ only in a specified attribute, enabling isolation of its effect on model preference. "The method we use is to form #1{counterfactual pairs} of assistant responses to the same user prompt,"
- Diversity-adjusted bias strength (DABS): A metric that sums bias strengths while penalizing semantic redundancy, encouraging diverse discoveries. "We define our metric, the diversity-adjusted bias strength, as"
- Evolutionary algorithm: An iterative search procedure that selects and mutates candidates to approach optimal solutions over generations. "following an evolutionary algorithm \cite{guo_connecting_2023}."
- Frontier LLM-as-judge: Using a cutting-edge LLM to provide preference judgments as a proxy for human evaluation. "we use a frontier LLM-as-judge, Claude Sonnet 4.5 \cite{anthropic_system_2025},"
- Gaussian noise: Random noise drawn from a normal distribution, commonly denoted N(0, a), used to model stochastic variation. "Furthermore, a Gaussian noise is added to both rewards,"
- Generative reward models (RMs): Reward models that generate structured outputs or rationales, not just scalar scores, to guide learning. "including generative RMs \cite{mahan_generative_2024}."
- Hallucinations: Fabricated or incorrect content produced by a model, presented as plausible facts. "such as length, format, hallucinations, and sycophancy."
- Held-out validation split: A reserved subset of data used to assess generalization and validate findings without training influence. "evaluate their RM and judge bias strengths on a held-out validation split of the data,"
- LLM judge: A LLM used to evaluate or rank responses, serving as an automated preference oracle. "lower preference by an LLM judge"
- LSC-transformation (log-sigmoid-centered transformation): A reward transformation that emphasizes improving poor outputs and enables principled aggregation. "a method we term \"LSC-transformation\" (log-sigmoid-centered transformation)."
- Maximal marginal relevance (MMR): A ranking criterion that balances relevance with diversity to reduce redundancy in selected items. "inspired by the concept of maximal marginal relevance \cite{carbonell_use_1998}."
- Mechanistic interpretability: The study of how internal model components implement behaviors, aiming for human-understandable explanations. "present concrete targets for mechanistic interpretability research to better understand."
- Model diffing: Systematically comparing two models to identify attributes or behaviors preferred by one and disliked by the other. "our work may also be of interest for the model diffing line of work"
- One-sided t-test: A statistical test that assesses whether a mean is greater (or less) than a baseline in a single direction. "p-value for the one-sided -test."
- Pareto frontier: The set of candidates that are not dominated on multiple objectives, representing optimal trade-offs. "closest to the Pareto frontier;"
- Partial conjunction test: A statistical procedure that concludes significance only if multiple components are simultaneously significant. "We then conclude the overall significance through the partial conjunction test,"
- Reinforcement Learning from Human Feedback (RLHF): Training that aligns models to human preferences by learning from comparison or instruction data. "reinforcement learning from human feedback (RLHF) is widely adopted in the modern post-training stack"
- Reward hacking: Exploiting misspecified rewards to achieve high scores with undesirable behavior. "a problem usually known as #1{reward hacking} or #1{overoptimization}"
- Reward shaping: Modifying reward functions to guide learning toward desired behaviors and away from exploitations. "reward shaping \cite{papadatos_linear_2024,wang_transforming_2024},"
- RewardBench: A benchmark suite that evaluates reward model performance across tasks. "which tops RewardBench 2 \cite{malik_rewardbench_2025}."
- Semantic clustering: Grouping candidate attributes by meaning to reduce redundancy and improve coverage. "prompting an LLM to perform semantic clustering is more accurate than clustering with embedding models."
- Signal-to-noise ratio (SNR): The relative strength of the desired signal compared to background noise, impacting detection reliability. "Recall rate vs signal-to-noise ratio."
- Sparse auto-encoders (SAEs): Autoencoders with sparse latent activations, used to discover interpretable features. "Sparse auto-encoders (SAEs), first popularized by \citet{bricken_towards_2023},"
- Sycophancy: The tendency of a model to agree with or flatter a user’s viewpoint instead of providing objective answers. "Examples include behaviors such as sycophancy \cite{sharma_towards_2023},"
- Variational methods: Optimization and inference techniques that approximate complex objectives with tractable surrogates. "variational methods \cite{miao_inform_2024}."
- Wilson confidence interval (Wilson CI): A binomial proportion interval with better small-sample properties than the normal approximation. "The confidence intervals are 95\% Wilson CIs with ,"
Collections
Sign up for free to add this paper to one or more collections.