- The paper presents robust training recipes that combine Continued Pretraining, Supervised Finetuning, and Preference Optimization to enhance long-context visual document QA.
- It leverages a large-scale PDF corpus with recursive query refinement and hard negative mining to address real-world document length diversity.
- Results demonstrate SOTA performance on MMLongBenchDoc, with notable gains from context targeting and the use of explicit page indices.
Authoritative Summary: "How to Train Your Long-Context Visual Document Model" (2602.15257)
Overview and Motivation
The paper systematically investigates strategies for training vision-LLMs (VLMs) capable of handling exceptionally long context windows (up to 344K tokens) for visual document question answering (VQA). While prior work has addressed long-context modeling in the video and text domains, robust, reproducible recipes for long-document VLMs remain absent. The authors bridge this gap through rigorous ablations on model architectures, data pipelines, and training procedures, culminating in state-of-the-art (SOTA) performance on MMLongBenchDoc and its manually corrected variant, MMLBD-C.
Corpus Construction and Data Engineering
To enable scaling, the authors construct a large corpus (250K PDFs, 16M pages) via recursive refinement of search queries spanning diverse categories, augmented with the PDFA English split (2M PDFs, 18M pages) (Figure 1). Hard negatives are mined from page embeddings to facilitate challenging RAG and distractor scenarios. The document distributions are visualized (Figure 1), revealing key aspects of real-world length and topical diversity, essential for generalization.
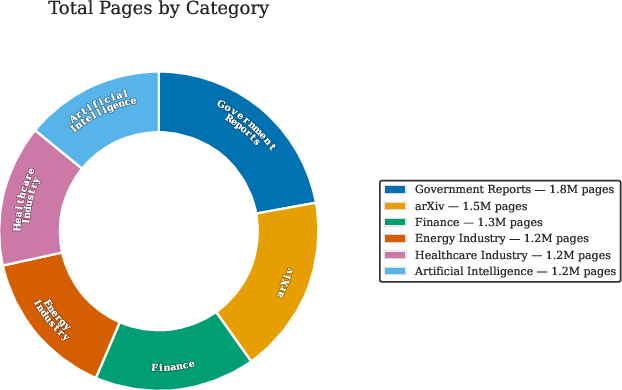
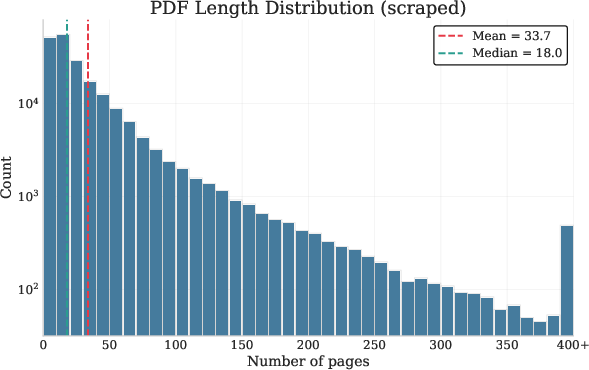
Figure 1: Corpus composition and page-length distribution, highlighting the scale and heterogeneity of foundational PDF data.
Additionally, length statistics of the synthetic CPT and SFT data indicate that ProLong’s context is heavily skewed toward short examples, while the paper’s own corpus contains genuinely long sequences (Figure 2).
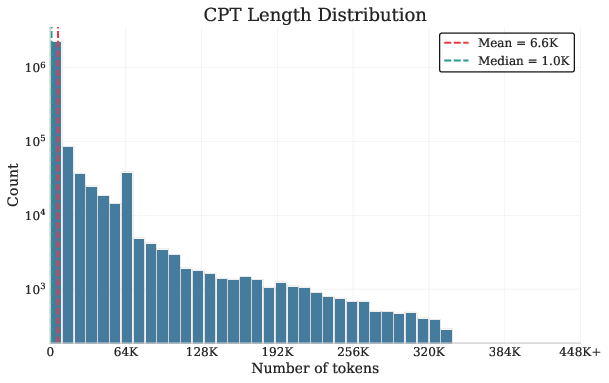
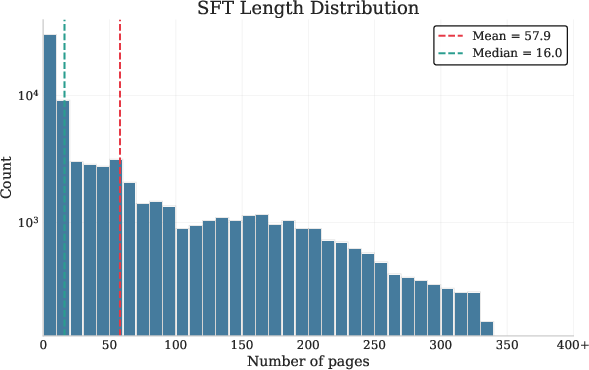
Figure 2: Length distributions for CPT and SFT examples, illustrating the bias and coverage in training data.
Training Approach and Methodological Ablations
The study evaluates three principal training paradigms:
- Continued Pretraining (CPT): Task-engineered synthetic data (Fill-in-the-Middle, Unshuffle, Key/Position Retrieval, Counting) are leveraged to extend context window capacity without requiring strong teachers. Ablations reveal that CPT improves text long-context performance (e.g., +4.9–7.3 on HELMET) and that tasks such as FIM and Unshuffle disproportionately contribute to gains (see task ranking). Notably, CPT is not strictly additive to SFT—SFT alone suffices for visual LC-Average in many cases.
- Supervised Finetuning (SFT): Two answer generation pipelines are compared: plain distillation versus a recursive evidence-ranking mechanism. Plain distillation is optimal for MMLBD-C, while recursive extraction boosts overall visual (+1.1 VA), MMLongBench, and SlideVQA scores; this result is consistent across model families. A critical finding is that training on context lengths matching evaluation benchmarks outperforms longer-context training (+1.4–3.0 VA). Explicit page indices as supplemental features yield a strong performance boost (+2.8 VA, +2.8 MMLBD-C).
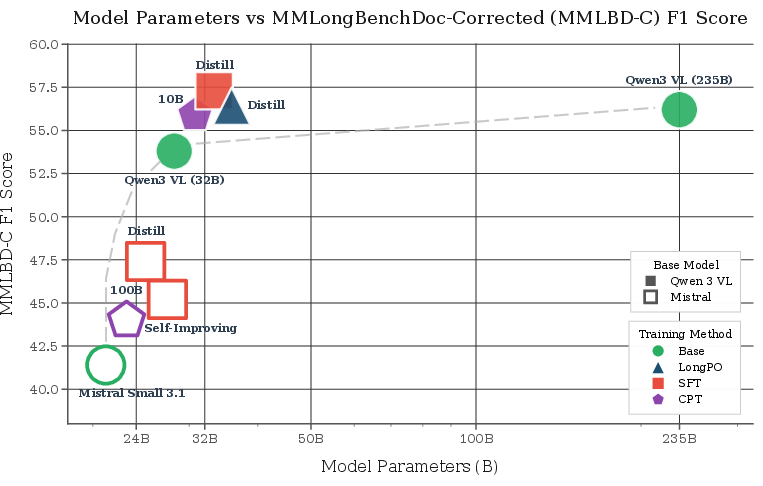
- Preference Optimization (LongPO): Adapted from DPO, LongPO uses a short-to-long context constraint (see formula) with answers from strong teachers (Qwen3 VL 235B). LongPO outperforms SFT on visual LC-Average (+2.1 VA) albeit at substantially higher compute cost (Figure 3). However, for specific metrics (MMLBD-C), SFT with plain distillation remains superior.
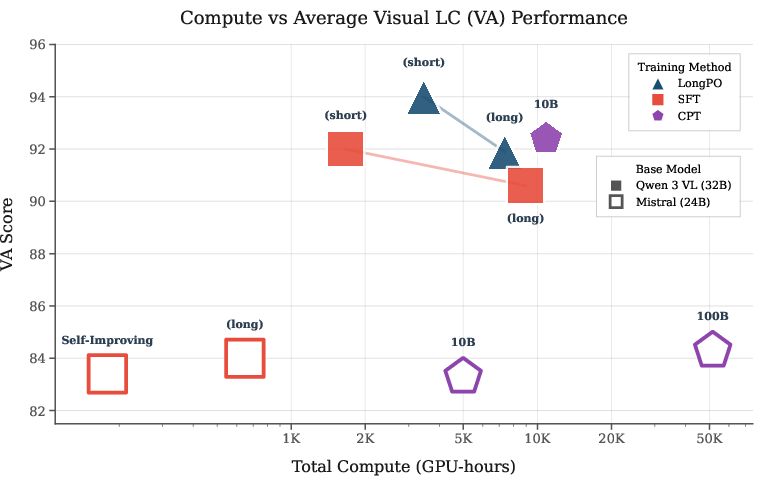
Figure 3: Compute versus VA performance, demonstrating efficiency trade-offs among CPT, SFT, and LongPO.
Evaluation and Benchmarking
Models are rigorously assessed across a suite of visual and textual LC benchmarks, normalized to minimize distributional bias. The primary metrics are Visual-LC Average (VA) and LC Average (LCA), the latter incorporating HELMET and LongBench v2. The authors also introduce MMLBD-C, manually correcting mispairings, ambiguities, typos, and answer errors found in MMLongBenchDoc, substantially improving evaluation quality (Figure 4).




Figure 4: Examples of document-question mismatches, underspecified queries, typos, and incorrect answer labels in the original benchmark.
Strong Numerical Results and Key Claims
Practical and Theoretical Implications
This study offers reproducible, actionable guidance:
- Recipe Openness: All data pipelines, ablation leaderboards, and checkpoints are released, closing the reproducibility gap in SOTA LC-VLMs.
- Data Engineering: Recursively refined queries and hard negatives are critical for robust training.
- Efficient Training: Context targeting, page indices, and model merging are minimal interventions yielding high impact with modest compute overhead.
- Generalization: Cross-modal transfer demonstrates that LC-VLM tasks are not siloed; visual context pretraining can upgrade text-LC performance and vice versa.
On the theoretical side, negative findings (non-additivity of CPT and SFT, performance degradation with upsampled long documents) point to subtle dynamics in curriculum and data distribution, highlighting avenues for future research (e.g., mixed-stage training, replay mechanisms).
Future Directions
Limitations include under-representation of extreme context lengths in typical benchmarks (most <128K tokens), suggesting that—at scale—further benchmarks and datasets are required to stress-test models at 344K and beyond. The interaction between CPT and SFT is not fully understood, especially for additive potential and mixed-modality composition. Extensions could explore mixed-stage curriculum and replay of high-value long-context tasks.
Conclusion
The paper contributes open, large-scale recipes, robust ablations, and SOTA models for long-context visual document understanding. Practitioners can directly deploy interventions such as context targeting and page indices, while the release of MMLBD-C addresses prior evaluation shortfalls. The model recipes and findings accelerate progress toward reliable long-document VLMs, with practical relevance for real-world enterprise and academic workflows, and theoretical significance for multimodal LC transfer and curriculum design.