Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory
Abstract: AI Memory, specifically how models organizes and retrieves historical messages, becomes increasingly valuable to LLMs, yet existing methods (RAG and Graph-RAG) primarily retrieve memory through similarity-based mechanisms. While efficient, such System-1-style retrieval struggles with scenarios that require global reasoning or comprehensive coverage of all relevant information. In this work, We propose Mnemis, a novel memory framework that integrates System-1 similarity search with a complementary System-2 mechanism, termed Global Selection. Mnemis organizes memory into a base graph for similarity retrieval and a hierarchical graph that enables top-down, deliberate traversal over semantic hierarchies. By combining the complementary strength from both retrieval routes, Mnemis retrieves memory items that are both semantically and structurally relevant. Mnemis achieves state-of-the-art performance across all compared methods on long-term memory benchmarks, scoring 93.9 on LoCoMo and 91.6 on LongMemEval-S using GPT-4.1-mini.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Mnemis: Dual-Route Retrieval on Hierarchical Graphs for Long-Term LLM Memory” (for a 14-year-old)
What is this paper about? (Overview)
This paper is about helping AI chatbots remember things from long conversations and find the right memories when you ask a question later. The authors build a new memory system called Mnemis that lets an AI both:
- quickly find similar past messages, and
- carefully scan a “big picture” map of everything it knows.
By combining these two ways, the AI answers questions more accurately, especially when the answer is spread across many places or requires a complete list.
What problems are they trying to solve? (Key objectives)
In simple terms, the paper asks:
- How can an AI remember and retrieve important moments from long, messy histories without reading everything every time?
- How can it avoid missing small but important details hidden in long texts?
- Can it do both fast matching (quick recall) and careful planning (big-picture reasoning) at the same time?
How does it work? (Methods explained with analogies)
Think of the AI’s memory like a super-organized school binder.
- Episodes = the full pages of your notes (raw messages from the past)
- Entities = key terms or characters (people, places, items)
- Edges = connections between entities (who did what, when, and how)
- Categories = folders that group related entities (like “Cities,” “Health,” “Sports”)
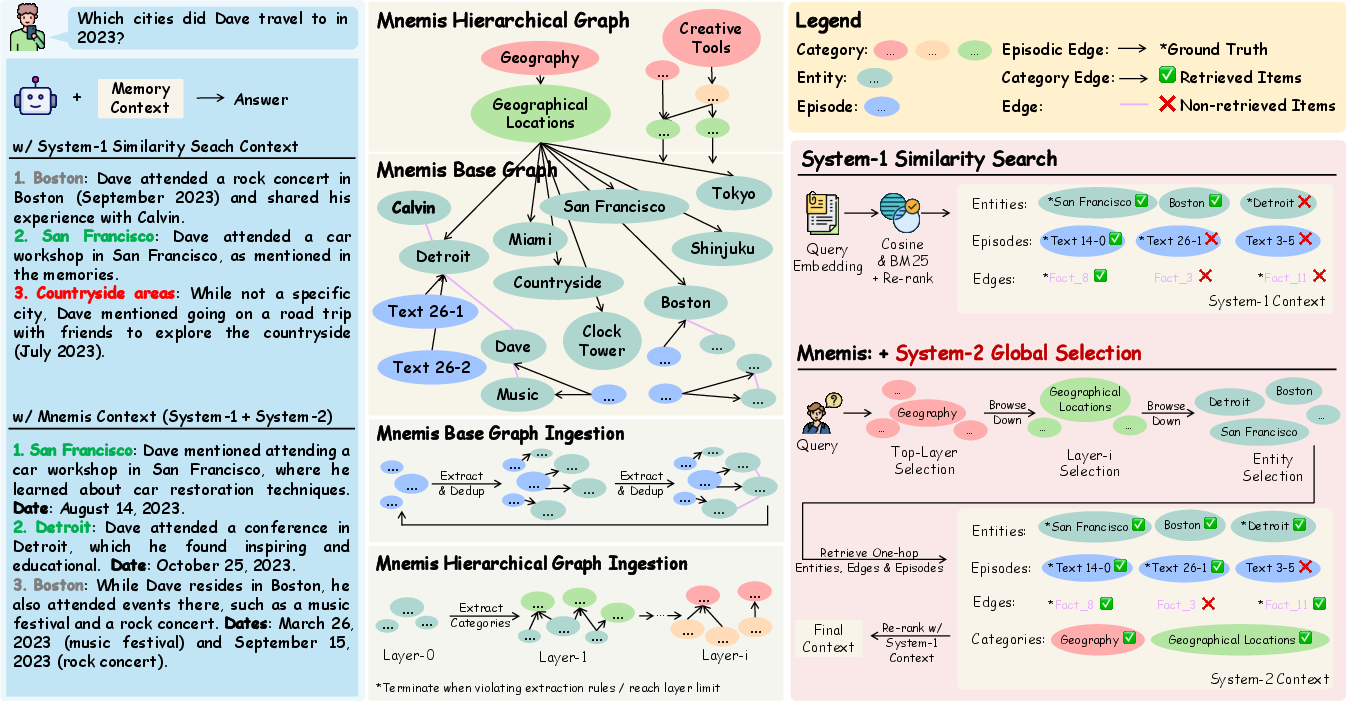
Mnemis uses two “routes” to find answers:
- Two kinds of “thinking” (inspired by psychology)
- System-1 (fast): Like doing a quick Google search. It looks for text that sounds similar to your question. This is fast and usually good enough, but can miss things that are phrased differently or buried in long text.
- System-2 (slow and careful): Like using a library’s subject catalog. You start at broad topics (e.g., “Geography”), then drill down to subtopics (e.g., “Cities”), then pick specific items (e.g., “Detroit”). This gives a global view and helps you not miss anything important.
- Organizing the memory into two graphs
- Base graph (for fast search): Stores episodes, entities, and edges (connections). It’s like a detailed index so the AI can quickly find similar stuff.
- Hierarchical graph (for careful browsing): Groups entities into layers of categories, from general to specific. It follows three simple rules:
- Minimum concept abstraction: categories should be specific enough to be useful (not too vague).
- Many-to-many mapping: one item can belong to multiple categories (e.g., “Detroit” could be under “Cities” and also under “Travel Destinations”).
- Compression efficiency: each higher layer should be smaller and more summarized than the layer below, so browsing top-down is efficient.
- Finding information (two retrieval routes)
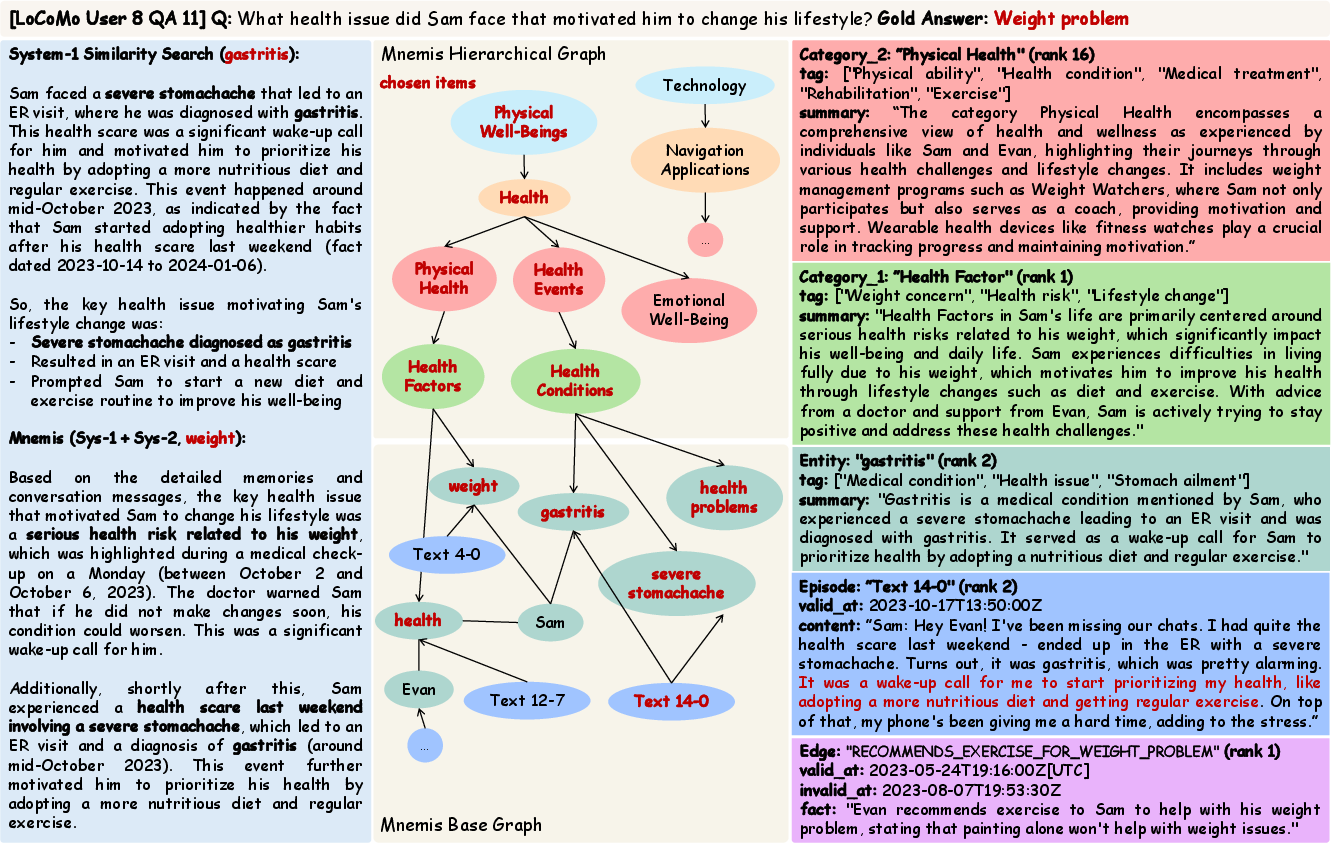
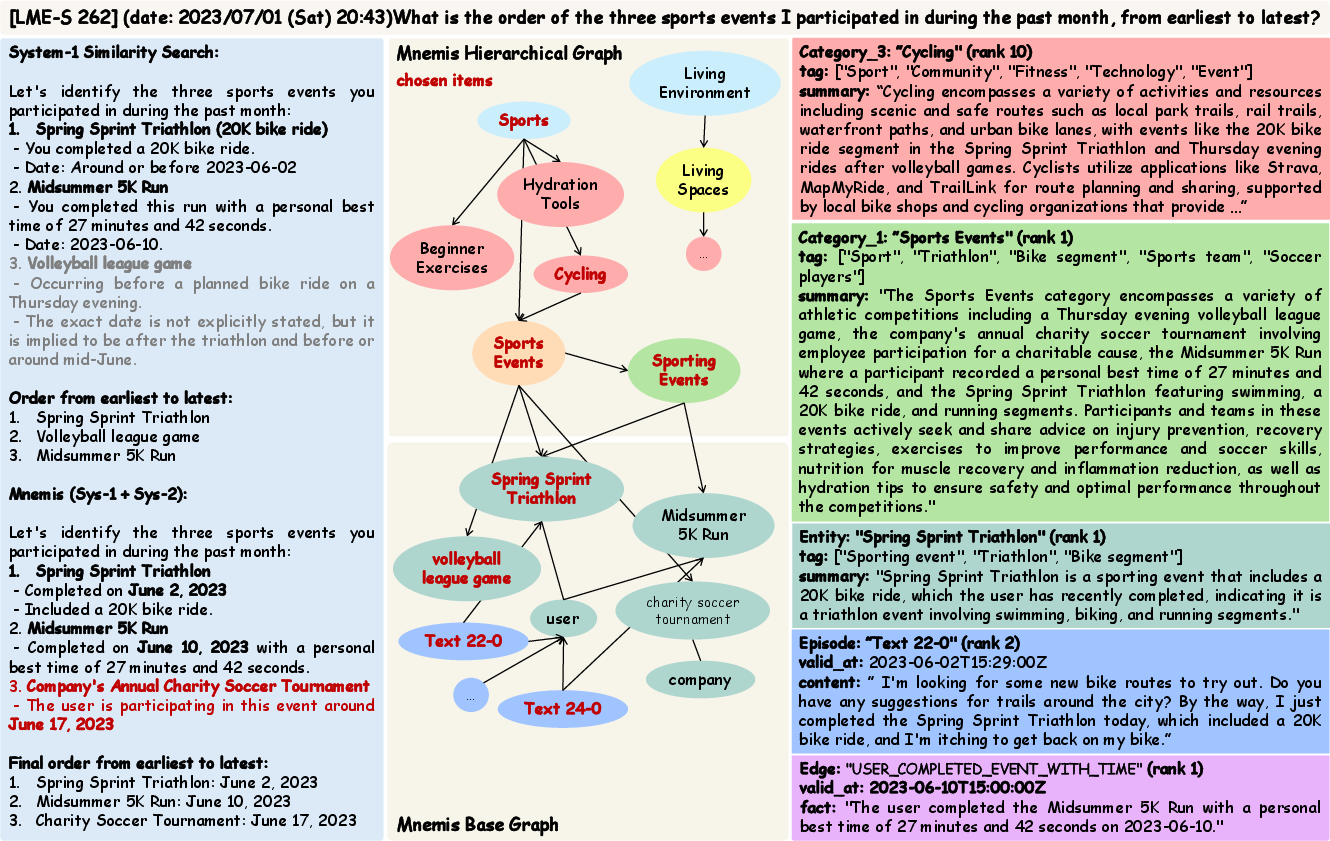
- System-1 similarity search: The AI computes how “close” the meanings are between the question and the stored items (like matching meanings, not just exact words). It also uses keyword search. Then it merges and reorders the results to pick the best few.
- System-2 global selection: The AI starts at the top of the category map and chooses relevant categories layer by layer, until it reaches specific entities. Then it pulls all related episodes and connections about those entities.
Finally, the AI combines results from both routes and re-ranks them to build a short, focused context for answering.
A simple example: Question: “Which cities did Dave travel to in 2023?”
- System-1 might miss “Detroit” if it’s mentioned only once in a long message with different wording.
- System-2 starts at “Geography” → “Cities” → finds all city mentions tied to Dave in 2023, so it’s less likely to miss one.
What did they find? Why does it matter? (Main results)
In tests (benchmarks are like official exams for AI memory):
- On LoCoMo (long conversations), Mnemis scored 93.9/100 with GPT-4.1-mini.
- On LongMemEval-S (very long histories), it scored 91.6/100 with GPT-4.1-mini.
- It beat other memory systems and also did better than just shoving the whole conversation into the model.
Why this is important:
- AIs used over months or years can’t read their entire history every time; it’s too slow and expensive.
- Combining fast searching with careful top-down browsing helps the AI find complete and correct answers, especially for multi-step questions, time-based reasoning, and “find all that apply” tasks.
What does this mean for the future? (Implications)
If AI assistants can remember and retrieve information like this:
- They’ll be better long-term helpers (tutors, customer support agents, personal assistants) who don’t forget important details.
- They’ll handle complex questions more reliably because they won’t miss relevant but hard-to-find facts.
- Future work could include other types of data (like images or audio) and even smarter ways to browse the memory map.
In short, Mnemis shows that mixing quick matching (System-1) with careful, global reasoning (System-2) helps AI remember and answer better over the long run.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper; each item is phrased to be directly actionable for future research.
- Incremental hierarchy maintenance: The hierarchical graph is “periodically rebuilt” rather than incrementally updated. Develop algorithms for online, consistency-preserving updates (insertions, deletions, reassignments) that avoid full rebuilds while keeping category assignments stable over time.
- Scalability and cost control: Reported token usage and runtime for ingestion and global selection are very large (e.g., tens of millions of tokens; ~1–4k seconds per stage). Provide complexity analysis, cost caps, caching strategies, and budget-aware traversal policies that keep System-2 costs predictable at scale.
- Query coverage gap in System-2: About 10% of LoCoMo queries yielded no System-2 results. Diagnose failure modes (e.g., ambiguous category names, shallow or overly compressed hierarchies) and design fallback strategies (query reformulation, alternative traversals, or hybrid planning).
- Temporal reasoning limitations: System-2 uses an unchanged query during top-down selection and is noted to be weaker for temporal questions. Explore timeline-aware nodes/edges, temporal path planning, and query decomposition/planning that reconstruct event sequences and state changes.
- Unspecified hyperparameters for hierarchy: The compression ratio
n, maximum number of layers, and node reduction thresholds are not detailed nor ablated. Systematically study sensitivity, selection criteria, and auto-tuning for these hierarchy parameters. - Hierarchy quality metrics: “Minimum Concept Abstraction” and “Compression Efficiency Constraint” are design goals, but no quantitative metrics are reported. Define and measure hierarchy quality (specificity, coverage, redundancy, branching factor, information compression vs. retrieval utility).
- Cycle and consistency guarantees: With many-to-many mappings, the hierarchy is not a tree and the paper does not state acyclicity or consistency constraints. Specify and enforce DAG properties, detect/prevent cycles, and evaluate downstream effects on traversal correctness.
- Category naming and ontology alignment: LLM-generated category names/tags may drift, be inconsistent, or overlap semantically. Investigate ontology-guided category construction, controlled vocabularies, and alignment with external taxonomies to reduce ambiguity.
- Entity canonicalization and coreference: Entity de-duplication is described (full-text + name embeddings), but precision/recall are not measured. Quantify extraction quality, coreference resolution accuracy, synonym handling, and the effect of mis-merges on retrieval.
- Edge typing and semantics: Edges are modeled as generic “facts” with
valid_at/invalid_at; relation types, directionality, and temporal semantics are under-specified. Introduce typed relations, temporal constraints, and confidence scores to improve reasoning and conflict resolution. - Contradiction handling and memory updates: The framework does not detail how conflicting edges or outdated facts are detected and reconciled beyond
invalid_at. Design policies for versioning, conflict resolution, and controlled forgetting/pruning under evolving histories. - Structure-aware re-ranking for System-2: Because System-2 returns unordered items, a cross-encoder re-ranker is used, but structure-awareness is not described. Develop graph-informed re-rankers that exploit traversal paths, node levels, and relation types to fuse System-1 and System-2 results.
- Search explosion and traversal policy: System-2 has “no strict top-
k” constraint. Define traversal budgets (breadth/ depth limits), path scoring, branch-and-bound, or learned planners to prevent combinatorial explosion while preserving coverage. - Robustness to adversarial and noisy inputs: LoCoMo adversarial category is excluded; robustness to prompt injection, memory poisoning, noisy sessions, and misleading categories is not assessed. Evaluate and harden the system against adversarial and noisy histories.
- Generalization beyond two benchmarks: The evaluation is limited to LoCoMo and LongMemEval-S. Test across diverse domains (enterprise logs, medical notes, code repositories), longer horizons, and non-conversational corpora to validate generality.
- Multimodal memory integration: Multimodal support is listed as future work. Specify how entities, edges, and categories will incorporate images, audio, video, and structured data, and how System-2 traversal will align across modalities.
- Backend LLM dependence: Performance gains are correlated with stronger backend LLMs (GPT-4.1-mini vs. GPT-4o-mini). Evaluate memory extraction and traversal using open/models with lower capacity, and quantify quality-cost trade-offs for practical deployments.
- Embedding dimension/storage constraints: The choice to reduce embeddings to 128 dims is cost-driven; only RAG performance was ablated across embedders. Study how embedding dimension and model choice affect Graph-RAG components and System-2 selection in the full pipeline.
- Fair, controlled baseline comparisons: Several baselines use “reported performance” with heterogeneous model/backbone settings. Re-run baselines under a controlled environment (same judge, LLM, embeddings, budgets) to ensure fair head-to-head comparisons.
- Reproducibility of hierarchy construction: LLM-driven hierarchy creation may be non-deterministic; seeds, prompts, and sampling parameters are not detailed. Provide reproducibility protocols and measure variance across runs.
- Dynamic budgeting and context assembly: The final context caps (
top-kepisodes,2kentities/edges) are fixed, and increasingkimproved results. Explore dynamic budgeting that adapts to query type and memory size, and quantify context assembly trade-offs. - Privacy, compliance, and governance: The paper does not discuss PII handling, consent, encryption, access controls, or retention policies for long-term memories. Define privacy-preserving ingestion, secure storage, and user-governed forgetting/compliance mechanisms.
- Real-time, online operation: Database latency and parallelism materially affect runtime; concurrency, streaming ingestion, and online answering are not addressed. Engineer and evaluate an online pipeline with bounded latency suitable for agent deployments.
- Failure analysis and diagnostic tools: Beyond a few win cases, there is no systematic error analysis linking retrieval failures to hierarchy properties or extraction errors. Build diagnostic tooling to trace query-to-path decisions, identify bottlenecks, and guide corrections.
Practical Applications
Immediate Applications
The following applications can be deployed with current LLMs, graph databases, and the Mnemis open-source implementation. They exploit the dual-route retrieval (System-1 similarity + System-2 global selection) to improve coverage, accuracy, and auditability in long-horizon memory tasks.
- Customer Support Memory Middleware — sector: software, customer service
- Use case: Give agents and chatbots a comprehensive view of a customer’s history across tickets, chats, emails, and product telemetry; answer enumerative queries such as “List all actions taken on ticket 123 and related incidents last quarter.”
- Tools/workflow: Neo4j + Graphiti ingestion for Episodes/Entities/Edges; Mnemis hierarchical categories over products/issues/resolutions; dual-route retrieval assembled into answer context; deploy as a microservice behind CRM/helpdesk (e.g., Zendesk, Salesforce Service Cloud).
- Assumptions/Dependencies: Access to historical data, robust PII handling and governance, embedding quality for technical jargon, top‑k tuning to control cost/latency.
- Sales/CRM Intelligence Assistant — sector: finance, software
- Use case: Recall multi-session interactions and preferences to answer “Which products did we discuss with ACME in Q3 and which objections were raised?” or “Which cities did the rep visit with this account in 2024?”
- Tools/workflow: Base graph over meeting notes/emails; hierarchical categories for account, stakeholders, topics, stages; re-ranking to fuse similarity + global enumeration; context fed to the answer LLM in the CRM sidebar.
- Assumptions/Dependencies: CRM/communications connectors; privacy consent; entity deduplication across aliases; manageable ingestion token cost.
- IT Operations and Incident Review — sector: software, ops
- Use case: Enumerate historic incidents and changes across systems; answer “List all services impacted by the March outage and the configuration changes that preceded it.”
- Tools/workflow: Log ingestion (Episodes), Entities for services/configs, Edges for events/relationships with valid_at; hierarchical categories by system/impact type; global selection ensures coverage when similarity signals are weak.
- Assumptions/Dependencies: Log normalization, time fields captured; domain-specific prompts for extraction; reliable mapping of services.
- Legal Case Memory for Matter Management — sector: legal
- Use case: “Enumerate all filings referencing clause 7.3 and list counterparties and dates” across a long case history.
- Tools/workflow: Document ingestion; entity extraction for parties/clauses; edges capturing references/citations with temporal validity; categories by clause/topic/procedure; dual-route retrieval to get complete coverage.
- Assumptions/Dependencies: Accurate extraction from heterogeneous legal documents; confidentiality controls; audit trails for provenance.
- Healthcare Patient Messaging and Admin Assistant (non-diagnostic) — sector: healthcare
- Use case: Summarize longitudinal patient communications: “List all lifestyle changes and travel events in the past year” to support admin triage and referrals.
- Tools/workflow: Episodes from portal messages; Entities for conditions/medications/lifestyle; hierarchical categories under Physical Health, Health Factors; System‑2 traversal excels at enumerative coverage.
- Assumptions/Dependencies: Strict HIPAA/PHI compliance; avoid clinical decision advice without formal validation; domain ontologies (e.g., SNOMED) helpful.
- Education: Personal Tutor Memory — sector: education
- Use case: Track a student’s progress across sessions to answer “Which algebra skills were practiced in 2025 and where did errors persist?”
- Tools/workflow: LMS integration; Entities for skills/assignments; edges for attempts/outcomes; hierarchical categories by curriculum/topic; dual-route retrieval for “find all items that …” queries.
- Assumptions/Dependencies: PII consent; standardized skill taxonomy; alignment with grading policies.
- Developer Assistant with Project Memory — sector: software engineering
- Use case: “List APIs changed in 2024 and the issues they addressed” across repos/issues/PRs.
- Tools/workflow: Source + issue tracker ingestion; Entities for modules/APIs; edges for changes/issues/PR links; categories by subsystem/component; re-ranking to combine code-aware embeddings with global enumeration.
- Assumptions/Dependencies: Code-specific extraction prompts; repository scale; embedding models tuned for code/text.
- Meeting and Decision Log Assistants — sector: enterprise software
- Use case: “Enumerate decisions made in Q2 with owners and follow-ups” across months of transcripts.
- Tools/workflow: Speech-to-text to Episodes; Entities for decisions/owners/actions; edges with timestamps/dependencies; categories for initiatives/teams; System‑2 traversal ensures comprehensive coverage.
- Assumptions/Dependencies: ASR quality; accurate decision/action extraction; periodic hierarchical rebuild for freshness.
- Compliance Evidence Aggregation — sector: compliance, audit
- Use case: “List all controls tested for SOC 2 in 2025 and associated evidence” across scattered artifacts.
- Tools/workflow: Episodes from tickets/docs; Entities for controls/evidence; edges for mappings; hierarchical categories by framework/control; dual-route retrieval provides complete coverage for enumerative checks.
- Assumptions/Dependencies: Control taxonomy availability; precise control-to-evidence mapping; auditability and data lineage.
- Security Operations Memory (SOAR/SIEM) — sector: cybersecurity
- Use case: “Enumerate machines affected by malware family X in the past 6 months and remediation steps.”
- Tools/workflow: Entity extraction for hosts/IOC; edges for alerts/remediations with valid_at; categories by threat family/asset type; System‑2 traversal to ensure comprehensive search.
- Assumptions/Dependencies: Real-time ingestion; deduplication at scale; false-positive management; secure graph DB operations.
- Research Lab Knowledge Management — sector: academia, R&D
- Use case: “List hyperparameters used in all experiments on dataset Y and corresponding outcomes.”
- Tools/workflow: Electronic lab notebooks and code logs to Episodes; Entities for datasets/models/hyperparams; edges for runs/results; categories by task/dataset/model family; dual-route retrieval for structured enumeration.
- Assumptions/Dependencies: Standardized experiment logging; data privacy; domain-specific extraction prompts.
- Personal Digital Memory Assistant — sector: consumer, daily life
- Use case: “Which cities did I travel to in 2023?” “What recurring purchases and subscriptions did I make last quarter?”
- Tools/workflow: Connectors to calendars/receipts/emails/locations; hierarchical categories for Geography, Finance, Subscriptions; System‑2 browsing is well-suited for enumerative questions.
- Assumptions/Dependencies: Consent and data security; on-device storage preferred; connectors across ecosystems (email, calendar, banking).
Long-Term Applications
These applications require further research, scaling, domain adaptation, or governance. Many depend on expanding beyond text, optimizing hierarchical maintenance, or formalizing safety, privacy, and provenance.
- Multimodal Long-Term Memory (text+audio+images+video) — sector: robotics, healthcare, education
- Use case: Agents recall visual scenes (“All objects placed on bench A this week”), clinical imaging patterns, classroom whiteboard notes.
- Tools/workflow: Multimodal entity and edge extraction; hierarchical categories across modalities; global selection over semantic hierarchies.
- Assumptions/Dependencies: Multimodal LLMs and embeddings; reliable vision/audio extraction; privacy constraints for images/video.
- Federated, Privacy-Preserving Memory OS — sector: enterprise, government
- Use case: Organization-wide memory graphs spanning teams/agencies with strict access control and audit trails.
- Tools/workflow: On-device or edge memory shards; federated/global selection with secure aggregation; signed edges and provenance tracking.
- Assumptions/Dependencies: Policy and regulatory alignment; differential privacy or secure enclaves; identity/role-based access control; interop standards.
- Learned Global-Selection Policies and Planning — sector: software, agent frameworks
- Use case: Train a policy that optimally traverses the hierarchy for different query types (temporal vs enumerative vs causal).
- Tools/workflow: Reinforcement learning or supervised traversal policies; evaluation with task-specific benchmarks; integration with chain-of-retrieval methods.
- Assumptions/Dependencies: Training data with traversal labels; stable APIs for graph access; generalization across domains.
- Real-Time Incremental Hierarchy Maintenance — sector: all
- Use case: Maintain categories as memory grows without periodic full rebuilds; adapt categories when new entities arrive.
- Tools/workflow: Streaming ingestion; online clustering/categorization under compression constraints; change detection and re-linking.
- Assumptions/Dependencies: Efficient online algorithms; cost controls for LLM-based updates; consistency guarantees.
- Domain Ontology Integration (e.g., SNOMED, ICD, GAAP, MITRE ATT&CK) — sector: healthcare, finance, cybersecurity
- Use case: Map extracted entities/edges to standardized ontologies for interoperability, reporting, and compliance.
- Tools/workflow: Entity linking; ontology-aligned categories and edges; validation and coverage checks.
- Assumptions/Dependencies: Licensing/access to ontologies; robust entity resolution; domain expert curation.
- Memory Provenance, Attribution, and Safety — sector: policy, governance
- Use case: Regulated environments require traceability: “Which source document, timestamp, and model produced this memory edge?”
- Tools/workflow: Signed episodic edges; lineage metadata; timeliness/validity checks; risk flags; explainable re-ranking.
- Assumptions/Dependencies: Provenance instrumentation; storage overhead; policy-defined retention and redaction.
- Government and Public Service Case Memory — sector: public sector
- Use case: Lifelong case histories across agencies (social services, housing, healthcare) with safe, consented access; enumerate benefits received, case actions, outcomes.
- Tools/workflow: Inter-agency connectors; categories aligned with public program taxonomies; governance gates for access and audits.
- Assumptions/Dependencies: Legal frameworks for data sharing; consent management; equitable access and bias controls.
- Financial Advisory and Portfolio Memory — sector: finance
- Use case: Long-term investor preference and event memory; “Enumerate risk concerns expressed and portfolio changes after major market events.”
- Tools/workflow: Entities for accounts/assets; edges for transactions/advice sessions; categories by asset class/risk profile; dual-route retrieval for coverage.
- Assumptions/Dependencies: Regulatory compliance (KYC/AML/Suitability); secure connectors; robust temporal reasoning.
- Lifelong Learning Records and Skill Graphs — sector: education, workforce development
- Use case: National or enterprise-scale skill memory; enumerate competencies practiced, assessments passed, and gaps over years.
- Tools/workflow: Standardized skill ontologies; cross-institution connectors; categories by skill frameworks; longitudinal analytics.
- Assumptions/Dependencies: Common standards; cross-platform data sharing; fairness and portability.
- Autonomous Agents with Persistent Memory for Long Tasks — sector: software, robotics
- Use case: Agents executing multi-week projects or missions rely on structured memory to avoid drift; enumerate pending dependencies and prior decisions.
- Tools/workflow: Mnemis as the memory substrate for agent frameworks; planning integrated with global selection; safe rollback and audit.
- Assumptions/Dependencies: Reliability guarantees; sandboxing; failure recovery; robust temporal sequencing beyond enumerative queries.
- Energy and Asset Lifecycle Memory — sector: energy, manufacturing
- Use case: “Enumerate assets replaced/upgraded and their failure modes over 5 years” to inform maintenance strategies.
- Tools/workflow: IoT/SCADA ingestion; Entities for assets/components; edges for maintenance events/failures; categories by asset class/site.
- Assumptions/Dependencies: Industrial connectors; high-volume ingestion; domain prompts for technical signals.
- Scalable Literature and Knowledge Review — sector: academia, pharma
- Use case: “Enumerate all papers that evaluate method X on dataset Y with negative results” for systematic reviews.
- Tools/workflow: Paper ingestion; Entities for methods/datasets/results; edges for claims/citations; categories by field/topic/subtopic; global selection for comprehensive coverage.
- Assumptions/Dependencies: Access to full texts; claim extraction accuracy; disambiguation of method names and variants.
Notes on Feasibility and Performance
- Where enumerative coverage is critical (finding “all items”), System‑2 global selection over the hierarchical graph is a strong fit; for complex temporal sequencing, augment with explicit temporal edges (valid_at/invalid_at), specialized temporal prompts, or learned traversal policies.
- Cost and latency depend on ingestion token budgets and database performance. Immediate deployments should:
- Limit top‑k judiciously, cache frequently accessed categories, and batch updates.
- Consider smaller rerankers and embeddings with MRL (multi-resolution) to reduce cost while preserving quality.
- Privacy, compliance, and provenance are essential for healthcare, finance, legal, and public sector deployments. Adopt signed edges, lineage metadata, and access controls.
- Domain adaptation requires tailored extraction prompts and taxonomies; success hinges on quality entity/edge extraction and deduplication.
- Mnemis is currently text-centric; many long-term applications need multimodal extraction and cross-modal hierarchies.
Glossary
- Ablation Study: An experimental analysis technique where components of a system are removed or varied to assess their individual contributions. "Ablation Study"
- Abstention: An evaluation setting where a model may choose not to answer when uncertain. "designed to evaluate five core memory abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention."
- BM25: A ranking function used in information retrieval to score documents based on term frequency and document length. "selecting Episodes, Entities, or Edges via text matching (BM25) or embedding similarity (cosine)."
- Category Edges: Directed links in the hierarchy connecting a higher-layer category to its child nodes (categories or entities). "Category Edges. A category edge links a higher-layer category to its child nodes (either lower-layer categories or entities)."
- Category Nodes (Categories): Abstract, high-level concepts that group semantically related lower-layer nodes. "Category Nodes (Categories). A category represents an abstract, high-level concept derived from lower-layer categories (or entities at layer 0)."
- community detection algorithms: Graph algorithms that partition nodes into densely connected groups (communities). "GraphRAG constructs its hierarchy using community detection algorithms, where each lower-level node is assigned to a single parent."
- Compression Efficiency Constraint: A design rule ensuring each layer compresses information effectively by enforcing minimum fan-in and non-increasing node counts across layers. "Compression Efficiency Constraint. To ensure the efficiency of System-2 Global Selection, the hierarchy is regulated by two complementary mechanisms: (1) the compression ratio and (2) the node count reduction rule, which takes effect from layer~2 onward."
- compression ratio: The minimum number of child nodes required under a category to ensure useful aggregation. "The compression ratio constrains the hierarchy at the category level."
- cosine similarity: A measure of vector similarity used to compare embeddings by the angle between them. "computing cosine similarity between the query embedding and the corresponding embeddings"
- de-duplication: The process of merging or removing duplicate items (e.g., entities, edges) identified during extraction. "followed by reflection and de-duplication steps analogous to those used in entity extraction."
- dual-process theory: A cognitive theory distinguishing fast, intuitive processes (System-1) from slow, deliberative ones (System-2). "resembles the System-1 process in dual-process theory"
- embedding model: A model that maps text into vector representations for similarity-based retrieval. "We use Qwen3-Embedding-0.6B as the embedding model"
- embedding search: Retrieval based on nearest neighbors in embedding space rather than exact text match. "embedding search, which retrieves relevant items by computing cosine similarity"
- Episodic Edges: Links connecting entities to all episodes where they appear, enabling episode retrieval from selected entities. "Episodic Edges. An episodic edge links entities to all episodes where they appear."
- episodic memory: Memory about personal experiences or events, used here as inspiration for storing historical interactions. "Inspired by human episodic memory"
- Full-text search: Retrieval technique that matches query terms against textual content using an index. "and full-text search, which retrieves relevant components using BM25 over textual content"
- Global Selection: A System-2, top-down retrieval mechanism that traverses a semantic hierarchy to collect relevant information. "a complementary System-2 mechanism, termed Global Selection."
- Graph-RAG: A retrieval-augmented generation approach that organizes memory as a graph of entities and relations for structured retrieval. "Recent work on graph-based RAG (Graph-RAG) extends RAG by incorporating concepts from semantic memory."
- hierarchical graph: A multi-level structure organizing entities into increasingly abstract categories to support top-down traversal. "constructs a hierarchical graph that provides a complete, global, and structured view of the entire memory"
- hyperthymesia: An extremely rare condition of highly superior autobiographical memory, referenced as an analogy. "treat them like individuals with hyperthymesia"
- LLM-as-a-Judge: An evaluation methodology where an LLM grades answers for correctness. "We employ LLM-as-a-Judge score (0/1) for evaluation"
- Many-to-Many Mapping: A hierarchy design allowing nodes to belong to multiple parent categories to reflect different semantic facets. "Many-to-Many Mapping. Unlike conventional tree-structured hierarchies, Mnemis permits lower-layer nodes to belong to multiple higher-layer categories."
- Minimum Concept Abstraction: A principle guiding category creation to be as specific as possible while still capturing shared semantics. "Minimum Concept Abstraction. While categories are intended to capture the shared semantics of their child nodes, we explicitly prompt the LLM to perform minimal abstraction."
- neo4j: A graph database used as the backend storage for the memory graphs. "We use neo4j as the backend database."
- node count reduction rule: A layer-level constraint requiring that upper layers contain no more nodes than lower layers. "The node count reduction rule, in contrast, constrains the hierarchy at the layer level"
- Quadratic scaling: Computational complexity that grows with the square of input length, characteristic of standard transformer attention. "due to the quadratic scaling of transformers with input length"
- Reciprocal Rank Fusion (RRF): A rank aggregation method that combines multiple ranked lists by summing reciprocal ranks. "reciprocal rank fusion (RRF)"
- Re-ranker: A model that reorders retrieved items to produce a better-ranked context for answering. "Re-ranker. Re-ranker organizes System-1 and System-2 search results to provide a compact context for the answer model."
- Retrieval-Augmented Generation (RAG): A paradigm where external documents are retrieved and provided to a LLM to improve responses. "The prevailing research paradigm is based on retrieval-augmented generation (RAG)."
- System-1 Similarity Search: The fast, embedding/text-similarity-based retrieval route that selects top candidates. "System-1 Similarity Search. This route retrieves the top- Episodes, Entities, and Edges, providing fast and effective retrieval based on semantic similarity."
- System-2 Global Selection: The deliberate, top-down retrieval route that navigates the hierarchy to collect structurally relevant items. "System-2 Global Selection. This route enables deliberate, top-down exploration of memory through the hierarchical graph."
- temporal reasoning: Reasoning over time, sequences, and validity intervals of events or facts. "designed to evaluate five core memory abilities: information extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention."
- top-down traversal: Navigating from higher-level categories to lower-level entities in the hierarchy. "enables top-down, deliberate traversal over semantic hierarchies."
- top-: A retrieval budget specifying the maximum number of items to return. "This route retrieves the top- Episodes, Entities, and Edges"
Collections
Sign up for free to add this paper to one or more collections.