Prescriptive Scaling Reveals the Evolution of Language Model Capabilities
Abstract: For deploying foundation models, practitioners increasingly need prescriptive scaling laws: given a pre training compute budget, what downstream accuracy is attainable with contemporary post training practice, and how stable is that mapping as the field evolves? Using large scale observational evaluations with 5k observational and 2k newly sampled data on model performance, we estimate capability boundaries, high conditional quantiles of benchmark scores as a function of log pre training FLOPs, via smoothed quantile regression with a monotone, saturating sigmoid parameterization. We validate the temporal reliability by fitting on earlier model generations and evaluating on later releases. Across various tasks, the estimated boundaries are mostly stable, with the exception of math reasoning that exhibits a consistently advancing boundary over time. We then extend our approach to analyze task dependent saturation and to probe contamination related shifts on math reasoning tasks. Finally, we introduce an efficient algorithm that recovers near full data frontiers using roughly 20% of evaluation budget. Together, our work releases the Proteus 2k, the latest model performance evaluation dataset, and introduces a practical methodology for translating compute budgets into reliable performance expectations and for monitoring when capability boundaries shift across time.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑language summary of “Prescriptive Scaling Reveals the Evolution of LLM Capabilities”
1) What is this paper about?
This paper is about making simple, reliable rules that tell you: “Given a certain amount of training compute (computer power used to train a LLM), how good can the model get on real tests after the usual extra training steps?” The authors call this “prescriptive scaling”—turning a compute budget into realistic performance expectations.
They study thousands of LLMs and show that the best scores models can reach at each compute level follow a predictable S‑shaped curve. They also check if these rules stay true over time as new models and techniques appear.
2) What questions did the researchers ask?
They focused on a few practical questions:
- If I have a fixed compute budget to train a model, what score can I realistically expect on a benchmark after post‑training (the extra tuning that helps a model follow instructions and reason better)?
- Do these compute‑to‑score rules keep working as newer models come out?
- Which tasks quickly hit a ceiling (where more compute doesn’t help much), and which keep improving?
- Are some recent math test scores suspiciously high because the test questions leaked into training data?
- Can we estimate these curves cheaply, without testing every model?
3) How did they study it?
They gathered a huge amount of data:
- Public leaderboards with thousands of models tested on standard benchmarks (like MMLU‑Pro for knowledge and MATH for math reasoning).
- A new dataset they built, called Proteus‑2k, with over 2,000 fresh evaluations of open‑weight models released after the latest leaderboard cutoff.
Then they did three main things:
- They looked at the “capability boundary” for each task: the top scores that models achieve at each compute level. Instead of averaging all models, they focused on the upper edge (think: “what the best models can do” at a given compute).
- They fit a simple S‑shaped (sigmoid) curve that increases with compute and then levels off. This curve is easy to understand: it says scores climb as you put in more compute, but the gains shrink and eventually flatten.
- They tested whether curves learned from older models still predict the top scores of newer models.
To save time and money, they also designed a smart selection method that chooses only a small, informative set of models to test, while still getting nearly the same curve.
Helpful analogies:
- Capability boundary = the “speed limit” for scores at a given compute. Many cars (models) drive below it, but the fastest ones trace the limit.
- Sigmoid (S‑curve) = scores rise quickly early on, then gains slow down, like learning a new skill.
Key terms in simple words:
- Compute/FLOPs: how much total calculation power a model used during training.
- Post‑training: extra steps (like instruction tuning) that polish a base model so it follows instructions and reasons better.
- Quantile (top 2%): focusing on the best‑performing models at each compute level instead of the average.
4) What did they find, and why is it important?
Main findings:
- The top achievable scores follow an S‑curve of compute. For most tasks, this curve is stable over time: the best you can do at a given compute is fairly predictable.
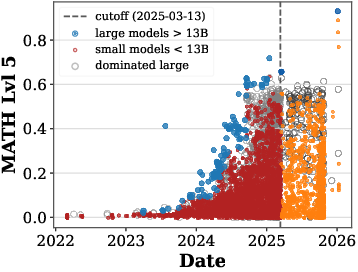
- A big exception is math reasoning. The curve for math keeps moving up over time, meaning new methods are boosting math performance even at the same compute levels.
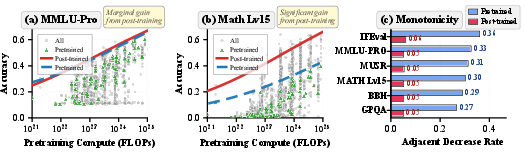
- Compute predicts a model’s potential better than raw “base” (pre‑trained) scores. After post‑training, models with more compute almost always can reach better top scores—even if their base checkpoints looked messy or inconsistent.
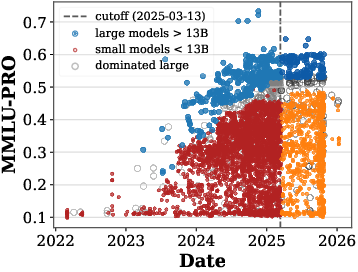
- Some tasks “saturate”: small models can already score very high, and larger models don’t gain much more. Other tasks, especially knowledge‑heavy ones (like MMLU‑Pro), still benefit from larger models and don’t saturate as quickly.
- They checked for “contamination” (when test questions accidentally show up in training data) on a recent math contest benchmark (AIME‑2025). Comparing it with another math set, they found no clear evidence of inflated scores due to contamination.
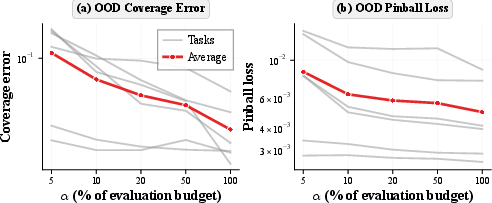
- You don’t need to test every model to estimate the boundary. With a smart selection strategy, you can recover nearly the same S‑curve using about 20% of the usual evaluation cost—and sometimes as little as 5%.
Why this matters:
- It gives engineers a practical “budget‑to‑score map”: if you can spend X compute, you can expect around Y performance after post‑training.
- It helps teams plan and compare recipes, and it flags when a task’s “ceiling” is moving (like in math), which is a good sign of ongoing algorithmic progress.
- It saves time and money on evaluations by focusing on the most informative models.
- It helps benchmark creators monitor when tests are saturating and when new, harder tests are needed.
5) What’s the bigger impact?
- Better planning: Teams can set realistic targets and avoid over‑ or under‑spending on compute.
- Clearer progress tracking: If the boundary shifts, we know something genuinely new is happening (e.g., better methods for reasoning).
- Smarter benchmarks: Knowing which tasks saturate helps the community design fresh, harder tests that track real improvements.
- Efficient evaluations: The sampling method makes large‑scale measurement cheaper and quicker.
- Open resources: The paper releases the Proteus‑2k dataset and code so others can reproduce and extend the work.
In short, the paper turns a messy landscape of models and training tricks into a simple, practical rule: the best possible scores at a given compute follow a predictable S‑curve, usually stable over time—except in fast‑moving areas like math, where the bar keeps rising. This helps everyone plan, measure, and improve LLMs more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list highlights concrete gaps and unresolved questions that future work could address to strengthen or extend the paper’s prescriptive scaling framework.
- Compute measurement uncertainty and standardization
- Many models have imprecise or incomparable pre-training FLOP estimates (e.g., varying counting conventions, MoE activation sparsity, hardware efficiency); the impact of compute measurement error on boundary estimates is not quantified or corrected.
- Omitted covariates beyond compute
- Capability boundaries are conditioned only on log-pretraining-compute, ignoring architecture class, pretraining data mixture/quality, post-training method (SFT vs. RLHF/DPO), post-training compute, and inference-time techniques; the magnitude of residual confounding remains unknown.
- Post-training and inference-time compute disentanglement
- The mapping uses base-model pretraining FLOPs only; contributions from post-training compute (and test-time compute such as CoT, self-consistency, or retrieval) are not modeled, so the boundary may conflate different compute sources.
- Generalization to new recipe classes and architectures
- The framework flags boundary shifts ex post (via under-coverage), but does not provide early-warning indicators or causal attribution when qualitatively new families (e.g., new MoE designs, sparse attention, longer-context regimes) enter.
- Model selection bias in observational data
- Leaderboards and Proteus-2k likely sample non-representatively (over-reporting strong checkpoints and families); the effect of submission/selection bias on high-quantile boundary estimation is not assessed.
- Benchmark coverage and task diversity
- Analyses focus on six NLP benchmarks; extension to other capability domains (e.g., coding, multimodal tasks, safety alignment tasks, long-context reasoning) remains untested.
- Extrapolation beyond observed compute ranges
- Boundaries are evaluated only within overlapping compute ranges; behavior (and uncertainty) for larger future budgets is not modeled, nor are credible extrapolation intervals provided.
- Uncertainty quantification for capability boundaries
- The paper reports pinball loss and coverage but does not provide confidence bands for the quantile curves (e.g., bootstrap or Bayesian intervals), hindering decision-making under uncertainty.
- Single-quantile focus and boundary shape flexibility
- Emphasis on τ=0.98 yields an “attainable” envelope but ignores other upper quantiles; the trade-off between optimism and robustness across τ is not systematically studied, and potential quantile-crossing issues are not addressed.
- Sigmoid parameterization misspecification risk
- While sigmoids perform well on average, tasks with broken-scaling or multi-phase progress may require more flexible monotone models; criteria for when sigmoid is insufficient (and how much error it induces) are not established.
- Temporal non-stationarity diagnostics and forecasting
- Math reasoning shows shifting boundaries, but the framework lacks predictive models for when and how fast boundaries will move (e.g., linking shifts to data curation improvements or algorithmic innovations).
- Contamination assessment power and scope
- The AIME-2025 analysis uses a simple cross-benchmark linear-logit shift test with modest sample size and p=0.15; sensitivity to small but operationally meaningful contamination levels is likely low, and broader contamination diagnostics across tasks are not provided.
- Pretrain–post-train gap decomposition
- The observed gaps between pretrained and post-trained performance are task-dependent, but the relative contributions of pretraining data, alignment method, and post-training data quality are not disentangled.
- PCA latent-factor result underexplored
- Only the first PC aligns with compute; the nature of other PCs (e.g., what capabilities they capture, and which levers drive them) is not analyzed, nor is how to incorporate multi-factor boundaries into prescriptions.
- Robustness to evaluation protocol heterogeneity
- Differences in prompts, decoding, normalization, and leaderboard pipelines can shift scores; the extent to which protocol variance biases boundary estimates is not quantified, nor are adjustments proposed.
- Measurement noise and finite-sample benchmark variance
- Benchmarks with high run-to-run or prompt-sensitivity variance can blur upper quantiles; the model does not account for repeated-measure variability or de-noise estimates.
- Size-based saturation analysis limitations
- The size–time boundary model uses parameter count and a late-period indicator; it does not distinguish model types (dense vs. MoE), tokens seen, or data enhancements, which may confound “size effects.”
- Frontier-model external validity
- Frontier fits on GPQA use a small set with known compute; robustness across more frontier tasks, different evaluation providers, and hidden-compute models remains untested.
- Cold-start and shift-robust active design
- The balanced I-optimal design relies on a nominal θ0 and metadata-only selection; how to initialize and adaptively correct the design when θ0 is misspecified or when new families appear is unresolved.
- Active design objective fidelity
- The design optimizes a local Fisher-information proxy for a nonlinear quantile objective; the gap between this proxy and true predictive performance under pinball loss is uncharacterized.
- Cost model realism in evaluation budgeting
- Assuming evaluation cost scales linearly with parameter count may be inaccurate (sequence length, batch throughput, decoding strategies, retrieval); design performance under richer cost models is not evaluated.
- Handling duplicate or derivative checkpoints
- Many leaderboard entries are minor variants or merges of the same base; the impact of correlated entries on quantile estimation and design selection is not addressed.
- Compute vs. data-size trade-off modeling
- The framework uses FLOPs as the primary axis; explicit modeling of tokens seen, data curation/quality metrics, and their interaction with compute is absent, limiting causal interpretability.
- Retrieval-augmented and tool-use models
- Models that rely on external tools or retrieval at evaluation time blur “capability” vs. “resource” boundaries; the framework does not incorporate or control for such test-time augmentation.
- Fairness and subgroup performance boundaries
- Attainable boundaries are estimated on aggregate scores; subgroup- or topic-conditional boundaries (e.g., by subject within MMLU-Pro) are not analyzed, leaving distributional fairness unexamined.
- Policy for boundary updates and monitoring
- The paper suggests refitting when under-coverage appears but does not formalize thresholds, monitoring protocols, or drift-detection procedures for operational deployment.
- Benchmarks nearing ceiling effects
- For tasks with high late-period small-model ceilings (e.g., Math Lvl 5), the framework does not propose mechanisms to maintain discriminatory power (e.g., dynamic test refresh or adaptive difficulty modeling).
- Reproducibility across evaluation pipelines
- Although code and data are released, cross-pipeline reproducibility (between OLL, Epoch AI, and other aggregators) is not validated, leaving open the risk of pipeline-specific boundaries.
- Ethical and governance considerations
- Prescriptive scaling maps could be used for capability planning; the paper does not discuss safeguards for misuse, or how uncertainty/limits should be communicated to prevent overconfident deployment decisions.
Glossary
- Adaptive sampling: A strategy that selects a subset of models to evaluate under a limited budget while preserving boundary estimation accuracy. "Efficient prescriptive scaling via adaptive sampling: We propose a sampling algorithm that accurately recovers sigmoid capability boundaries under limited computation budget"
- AIME-2025: A contemporary math benchmark based on a standardized exam, used to assess reasoning capability and potential contamination effects. "Our contamination analysis on frontier models finds no clear evidence of AIME-2025 score inflation due to contamination."
- BBH: Big-Bench Hard; a challenging reasoning benchmark for LLMs. "for BBH, GPQA, MMLU-Pro, and MUSR, both diagnostics are stable across periods"
- Budget-Constrained Balanced I-Optimal Design: An experimental design framework that minimizes predictive variance of boundary estimates while ensuring coverage across compute bins under a cost constraint. "Budget-Constrained Balanced I-Optimal Design"
- Binwise constant: A boundary estimator that assigns a constant quantile estimate within predefined log-compute bins. "Binwise constant: partition into bins with edges computed from the training -values only."
- Capability boundary: The high-quantile envelope of attainable post-training accuracy as a function of pre-training compute. "we estimate capability boundaries---high conditional quantiles of benchmark scores as a function of log pre-training FLOPs"
- Contamination: The presence of benchmark items in training data or targeted practice that can inflate evaluation scores. "Our contamination analysis on frontier models finds no clear evidence of AIME-2025 score inflation due to contamination."
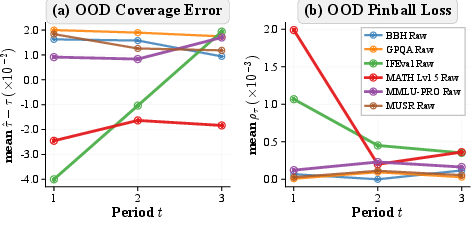
- Coverage error: The signed deviation between empirical coverage and the target quantile level, measuring local calibration of the boundary. "Coverage error."
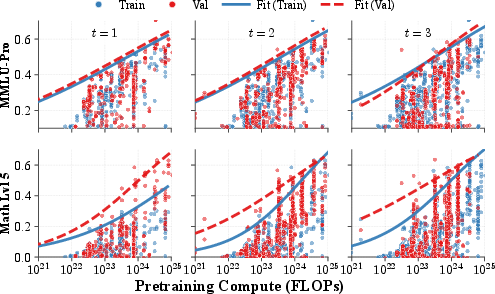
- Cross-temporal transfer: Evaluating whether compute-based boundaries fitted on earlier model generations predict scores for later releases. "We summarize cross-temporal transfer using two diagnostics from \Cref{sec:objective-metrics}"
- Delta method: An approximation technique to propagate parameter uncertainty into predictive variance of the boundary. "The delta method gives an approximate predictive variance of the boundary at "
- Equal-mass binning: A binning strategy that partitions log-compute values into bins with roughly equal counts, respecting group structure. "We use group-aware equal-mass binning on the training -values only"
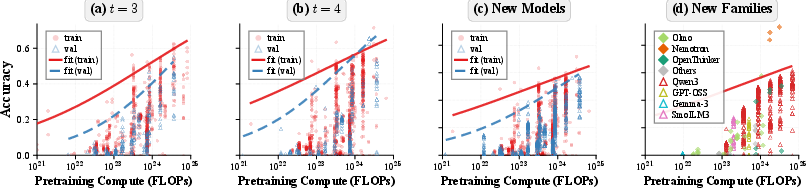
- External validity: The extent to which fitted boundaries generalize beyond the curated leaderboard to newly evaluated or frontier models. "We then use additional slices of the model landscape to probe external validity and robustness of the fitted boundaries."
- FLOPs: Floating-point operations; a measure of pre-training compute used as the primary scaling variable. "pre-training FLOPs"
- GPQA: Graduate-level problem QA; a knowledge-intensive benchmark (e.g., GPQA Diamond) used to assess frontier-model capabilities. "for BBH, GPQA, MMLU-Pro, and MUSR"
- I-optimal design: An optimal experimental design objective that minimizes average predictive variance of a model across the input space. "The I-optimal design allocates evaluations to minimize the average predictive variance of the estimated capability boundary across compute regimes"
- I-spline: A flexible monotone, saturating function class used to fit compute–performance boundaries, generalizing sigmoid. "I-spline: a strictly more general function class than sigmoid (a flexible monotone baseline)"
- IFEval: An instruction-following benchmark used to evaluate adherence to specified behaviors. "The main departures occur on MATH Lvl 5 (and to a lesser extent IFEval)"
- In-distribution (ID): Evaluation within the same temporal or compute regime used for fitting, used to assess fit quality. "We report the in-distribution (ID) and out-of-distribution (OOD) performance of these estimators."
- Information matrix: The aggregate of Jacobian outer products used to approximate parameter covariance for boundary estimation. "we define the local information matrix ."
- Jacobian: The gradient of the boundary with respect to parameters, used in variance propagation. "Let denote the Jacobian of with respect to~"
- Leaderboard: A standardized evaluation repository aggregating model scores under consistent protocols. "the Open LLM Leaderboard v1 and v2"
- Log-compute: The logarithm of pre-training FLOPs, used as the predictor variable for boundaries. "We work in log-compute ."
- Logit: The inverse of the logistic function, used to model sigmoid relationships and linearize bounded accuracies. ""
- MATH Lvl 5: A high-difficulty math reasoning benchmark used to track evolving ceilings and temporal shifts. "MATH Lvl 5"
- MATH-500: A math benchmark used alongside AIME-2025 to test for cross-benchmark inflation and contamination. "Since all models post-date MATH-500, any MATH-500 inflation can affect all points"
- MMLU-Pro: An updated, harder knowledge benchmark designed to reduce saturation and better discriminate model capabilities. "MMLU-Pro"
- Monotone spline: A constrained spline ensuring non-decreasing behavior in compute for boundary estimation. "replace the linear predictor with a monotone spline"
- MUSR: A benchmark (e.g., multi-step reasoning) used in leaderboard evaluations to assess complex model behaviors. "for BBH, GPQA, MMLU-Pro, and MUSR"
- Non-stationarity: Time-varying behavior where the attainable boundary shifts, breaking stability across periods. "consistent with non-stationarity of the effective boundary over time."
- Open-weight models: Models whose parameters are publicly available, enabling broad, heterogeneous post-training and evaluation. "In this subsection, we study open-weight models on the Open LLM Leaderboard."
- Out-of-distribution (OOD): Evaluation on later periods or regimes not used in fitting to test temporal generalization. "we fit the -capability boundary on and evaluate out-of-distribution on "
- Pinball loss: An asymmetric loss used for quantile regression that penalizes underestimation more at high quantiles. "Pinball loss (quantile accuracy)."
- Prescriptive scaling: The engineering-oriented mapping from compute budgets to attainable post-training performance levels. "we study prescriptive scaling: given a base-model pre-training compute budget, what attainable post-training performance should we expect on a target benchmark?"
- Proteus-2k: A newly released dataset of model evaluations curated to extend beyond leaderboard coverage. "our work releases the Proteus-2k, the latest model performance evaluation dataset"
- Quantile regression: A statistical method for estimating conditional quantiles, here used to fit attainable boundaries. "via smoothed quantile regression with a monotone, saturating sigmoid parameterization."
- Ridge prior: A regularization term added to the information matrix to stabilize inverse covariance estimation. "we use a ridge prior with "
- Saturation: The phenomenon where benchmark scores approach ceilings, reducing discriminative power over time. "Task-dependent Saturation on Leaderboards"
- Sigmoid capability boundary: A monotone, saturating sigmoid function of log-compute that models the attainable performance envelope. "Sigmoid capability boundaries: Compared with pre-trained model performance, we show that the attainable post-trained performance is much more predictable and is well-characterized by a simple monotone, saturating sigmoid function of log-compute."
- Size--Time Boundary Model: A model that jointly captures size effects and temporal trends on attainable benchmark performance. "Quantifying Saturation with a Size--Time Boundary Model"
- Upper-tail accuracy: The high-quantile (e.g., 0.98) level of performance achievable at a given compute, summarizing the best observed outcomes. "attainable (upper-tail) accuracy"
Practical Applications
Overview
This paper introduces prescriptive scaling: a practical, empirically validated way to translate a pre-training compute budget (FLOPs) into high-probability, attainable downstream performance after contemporary post-training. The core contributions are:
- Capability boundaries: high-quantile (e.g., 0.98) benchmark performance as a monotone, saturating sigmoid of log compute.
- Temporal validation: boundaries are mostly stable over time for knowledge-oriented tasks, with math reasoning exhibiting a shifting (advancing) boundary.
- Efficient evaluation: a balanced I-optimal design recovers near–full-data frontiers with ~20% (as low as ~5% on some tasks) of the evaluation budget.
- Case studies: task-dependent saturation diagnostics and contamination-oriented shift testing.
- Data/tooling: the Proteus-2k dataset and code for boundary estimation.
Below are actionable applications linked to sectors, tools/workflows that could emerge, and key dependencies.
Immediate Applications
- Compute-to-performance planning and budgeting [Sector: software, finance, MLOps]
- What: Use sigmoid capability boundaries to forecast attainable benchmark accuracy for a given pre-training compute budget, and to set realistic targets in roadmaps.
- Tools/products/workflows: “Capability Boundary Calculator” that accepts target benchmark and quantile (e.g., τ=0.98) and outputs required FLOPs with confidence bands; scenario planning dashboards for CFO/FinOps teams mapping FLOPs to $ cost and energy.
- Assumptions/dependencies: Accurate base-model FLOPs estimates; task-specific stability (math boundaries are less stationary); post-training practices similar to those represented in the observational data.
- Model family selection and post-training triage [Sector: software, academia]
- What: Select base models for instruction tuning or RLHF by prioritizing those whose compute levels put them near the boundary for target tasks, reducing wasted post-training runs on underpowered bases.
- Tools/products/workflows: Boundary-aware model selection in AutoML/MLOps pipelines; gating rules (e.g., “only fine-tune if boundary-predicted score ≥ X”).
- Assumptions/dependencies: Availability of compute metadata for candidate models; benchmarking protocols aligned with those used in boundary estimation.
- Evaluation cost reduction via balanced I-optimal design [Sector: software, energy/green AI, benchmarking]
- What: Cut evaluation compute by ~50–95% using the paper’s balanced I-optimal selection to sample only models most informative for the boundary.
- Tools/products/workflows: An “evaluation subset selector” integrated into CI/leaderboard harnesses that picks models across compute bins to minimize predictive variance; planning for evaluation clusters to reduce energy use.
- Assumptions/dependencies: Parameter count is a reasonable proxy for evaluation cost; availability of a nominal boundary estimate to compute local Jacobians; consistent evaluation pipelines.
- Benchmark maintenance and saturation monitoring [Sector: academia, benchmarking platforms]
- What: Track when capability boundaries approach ceilings (e.g., fast for MATH Lvl 5) and trigger refreshes or task revisions.
- Tools/products/workflows: Boundary drift dashboards; regular “saturation alerts” that recommend when to rotate or redesign tasks; automated reports comparing size–time boundary shifts.
- Assumptions/dependencies: Reliable chronological splits; continuity in evaluation metrics; community consensus on when to “reset.”
- Cross-benchmark contamination/“train-on-test” diagnostics [Sector: academia, policy, compliance]
- What: Use cross-benchmark shift tests (e.g., AIME-2025 vs MATH-500) conditioned on compute to spot anomalous inflation post-release.
- Tools/products/workflows: Leaderboard add-on that flags post-release shifts beyond what compute-scaled performance predicts; audit reports for regulatory filings.
- Assumptions/dependencies: Accurate release dates; overlapping benchmarks with comparable constructs; transparency from submitters.
- Governance and risk gates tied to compute [Sector: policy, platform governance, enterprise IT]
- What: Map pre-training compute to potential capability (upper envelope) and set tiered approval workflows (e.g., stricter review as boundary exceeds certain thresholds).
- Tools/products/workflows: “Compute-to-risk” policy templates; internal compliance gates that reference boundary levels per task class (knowledge vs reasoning vs instruction following).
- Assumptions/dependencies: Disclosure of training FLOPs; boundary stability for targeted task types; risk metrics mapped to benchmarks.
- Procurement and vendor evaluation [Sector: enterprise IT, government]
- What: Require vendors to disclose base compute and compare claimed scores to predicted boundaries to detect implausible performance claims.
- Tools/products/workflows: RFP checklists embedding capability boundary checks; vendor scorecards showing distance-to-boundary by task.
- Assumptions/dependencies: Standardized compute reporting; comparable post-training pipelines; harmonized evaluation protocols across vendors.
- Pretrain vs post-train ROI analysis [Sector: software, finance]
- What: Prioritize investment in post-training (alignment, instruction tuning) vs raw pre-training scale by comparing gaps to the post-trained boundary across tasks (larger gap on reasoning and instruction following; smaller on knowledge-heavy tasks).
- Tools/products/workflows: Portfolio allocators that recommend dollars to pre-training vs post-training for each target capability.
- Assumptions/dependencies: Task mix matches benchmark proxies; costs and benefits of post-training are stable; up-to-date boundaries.
- Cloud/edge deployment sizing for task fit [Sector: software platforms, edge/IoT]
- What: Choose model sizes per application (e.g., smaller models for tasks near the small-model boundary; larger models where knowledge capabilities scale).
- Tools/products/workflows: Deployment planners that align device constraints with capability boundaries by task; SKU guidance for model-serving products.
- Assumptions/dependencies: Target task aligns with benchmark; on-device constraints; boundary validity for fine-tuned variants.
- Curriculum/content design in edtech and L&D [Sector: education]
- What: Match model selection and prompting strategies to tasks where smaller models suffice (or not), e.g., knowledge retrieval vs multi-step reasoning modules.
- Tools/products/workflows: Content pipelines that select model family by task boundary; QA policies that escalate to larger models for reasoning-heavy items.
- Assumptions/dependencies: Alignment between benchmarks and curricular tasks; consistent instruction-tuning quality.
- Meta-research and dataset use [Sector: academia, open-source]
- What: Use Proteus-2k to replicate or extend observational scaling analyses, benchmark drift studies, and boundary calibration.
- Tools/products/workflows: Reproducible notebooks for boundary fitting; dataset-as-a-service endpoints for academic benchmarking labs.
- Assumptions/dependencies: Licensing/attribution compliance; representativeness of post-2025 releases.
Long-Term Applications
- Capability boundary certification and reporting standards [Sector: policy, industry consortia]
- What: Formalize “capability boundary certificates” for models, audited by third parties, to standardize reporting in procurement and regulation.
- Tools/products/workflows: Certification bodies; standardized FLOPs disclosure and verification protocols; boundary-based labeling.
- Assumptions/dependencies: Industry adoption; legal frameworks; robust methods for verifying compute and post-training changes.
- Compute-governance thresholds tied to capability [Sector: public policy, safety]
- What: Link compute thresholds (e.g., at 10X FLOPs) to expected capability bands that trigger oversight, eval requirements, or export controls.
- Tools/products/workflows: Policy playbooks that reference boundary bands; automated compliance checks integrated with training schedulers.
- Assumptions/dependencies: Stable boundaries for critical tasks; enforceable compute accounting; low-regret thresholds despite field evolution.
- Dynamic benchmark pipelines [Sector: benchmarking platforms, academia]
- What: Automatically detect approaching saturation and generate/curate new task variants to maintain discrimination near the boundary.
- Tools/products/workflows: Data factories with human-in-the-loop item generation; adversarial item mining near boundary regions.
- Assumptions/dependencies: Access to high-quality item sources; governance for leakage and fairness; budget for human vetting.
- Red teaming and safety evaluation focused on near-boundary regimes [Sector: safety, security]
- What: Concentrate stress tests where models are most capable (near the boundary) to expose latent risky behaviors.
- Tools/products/workflows: “Boundary-targeted” sampler to choose models/examples for adversarial evaluation; integration into safety CI/CD.
- Assumptions/dependencies: Valid mapping from benchmarks to risk-relevant capabilities; robust threat modeling.
- Latent capability factor monitoring [Sector: research, analytics]
- What: Track low-dimensional latent “capability axes” (PCA) over time and relate them to compute to forecast shifts in multi-task performance.
- Tools/products/workflows: Capability-factor dashboards for portfolio models; alerts when progress deviates from compute-driven axes.
- Assumptions/dependencies: Consistent multi-benchmark evaluations; stable factor structure; appropriate normalization.
- Multimodal and robotics extensions [Sector: vision, robotics, autonomy]
- What: Apply boundary estimation and budgeted evaluation design to VLMs, speech models, or robot policies, treating pre-training (or sim) compute as the driver.
- Tools/products/workflows: Cross-modal boundary calculators; sim-to-real evaluation samplers with I-optimal designs.
- Assumptions/dependencies: Adequate observational data and compute metadata in new domains; appropriate monotone/saturating parameterizations.
- Insurance and actuarial risk pricing for AI services [Sector: finance, insurance]
- What: Use compute-to-capability boundaries to underwrite liability (e.g., higher premiums for services operating near higher-capability boundaries).
- Tools/products/workflows: Risk models integrating boundary levels and domain-specific loss data; audit trails for compute disclosure.
- Assumptions/dependencies: Availability of incident/claim data; accepted mapping from benchmarks to real-world risk.
- Marketplace/API pricing and SLAs by capability bands [Sector: software platforms]
- What: Price model endpoints and draft SLAs based on predicted capability bands derived from compute and boundary position.
- Tools/products/workflows: Capability-banded pricing tiers; SLA verifications tied to evaluation sampling near customer-relevant tasks.
- Assumptions/dependencies: Transparency into model base compute and post-training updates; fairness and anti-gaming measures.
- Energy-aware R&D portfolio optimization [Sector: energy, sustainability]
- What: Use I-optimal selection to minimize evaluation energy and carbon while keeping boundary estimation accuracy, guiding sustainability goals.
- Tools/products/workflows: Carbon-aware schedulers that prioritize high-information evaluations; green AI reporting integrated with boundary accuracy.
- Assumptions/dependencies: Reliable cost–energy mapping; organizational sustainability targets; cultural acceptance of partial evaluations.
- Standardized vendor attestations and audits [Sector: procurement, compliance]
- What: Require periodic re-estimation of boundaries as recipes evolve, particularly for tasks with shifting envelopes (e.g., math reasoning).
- Tools/products/workflows: Attestation templates that include date-stamped boundary positions; automatic audit triggers when under-coverage appears.
- Assumptions/dependencies: Ongoing data collection; cooperation from vendors; independent auditors.
- Methodological enhancements and personalization [Sector: research, product R&D]
- What: Conditional boundaries by recipe class, data mix, or domain; adaptive quantile targets (e.g., τ per risk tolerance); Bayesian boundary tracking.
- Tools/products/workflows: Recipe-aware boundary libraries; uncertainty-aware planners that pick τ to balance ambition vs risk.
- Assumptions/dependencies: Rich metadata on training recipes; larger observational datasets; agreement on task taxonomy.
Notes on General Dependencies and Limits
- Compute metadata: Many applications require accurate, comparable pre-training FLOPs; closed-source models may not disclose or may estimate noisily.
- Boundary stationarity: Boundaries are more stable for knowledge-heavy tasks (e.g., MMLU-Pro) and less so for math reasoning; users should monitor drift and update fits.
- Benchmark representativeness: Mappings assume benchmarks proxy real tasks; domain shift or narrow benchmarks limit external validity.
- Post-training heterogeneity: Results are conditioned on contemporary practices; a qualitatively new recipe can shift the attainable envelope upward at fixed compute.
- Sigmoid assumption: The monotone, saturating sigmoid fits well in observed data but can mis-specify regions if future dynamics change; I-spline provides a more flexible fallback.
- Evaluation cost proxy: I-optimal design assumes cost scales roughly with parameter count; real-world pipelines may deviate.
These applications enable concrete tools—budget planners, evaluation samplers, governance dashboards—to make scaling decisions more predictable and cost-efficient while providing mechanisms to detect when capability boundaries shift.
Collections
Sign up for free to add this paper to one or more collections.