Co-Design and Evaluation of a CPU-Free MPI GPU Communication Abstraction and Implementation
Abstract: Removing the CPU from the communication fast path is essential to efficient GPU-based ML and HPC application performance. However, existing GPU communication APIs either continue to rely on the CPU for communication or rely on APIs that place significant synchronization burdens on programmers. In this paper we describe the design, implementation, and evaluation of an MPI-based GPU communication API enabling easy-to-use, high-performance, CPU-free communication. This API builds on previously proposed MPI extensions and leverages HPE Slingshot 11 network card capabilities. We demonstrate the utility and performance of the API by showing how the API naturally enables CPU-free gather/scatter halo exchange communication primitives in the Cabana/Kokkos performance portability framework, and through a performance comparison with Cray MPICH on the Frontier and Tuolumne supercomputers. Results from this evaluation show up to a 50% reduction in medium message latency in simple GPU ping-pong exchanges and a 28% speedup improvement when strong scaling a halo-exchange benchmark to 8,192 GPUs of the Frontier supercomputer.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about helping supercomputers run faster by letting GPUs talk to each other directly, without making the CPU get involved every time. The authors designed a new way to use MPI (a popular tool for moving data between computers) so that GPUs can send and receive messages on their own. They built it, plugged it into real software, and tested it on two big supercomputers.
The main questions the paper asks
- Can we remove the CPU from the “fast path” of communication so GPUs can send/receive data sooner?
- Can we do this while keeping the familiar MPI style that many scientific programs already use?
- Can it be easy to program, safe (no data races or wrong deliveries), and still very fast?
- How much faster does this make real programs on large supercomputers?
How they approached it (in simple terms)
First, a few quick translations:
- CPU vs GPU: Think of the CPU as the manager and the GPU as a huge team of workers. Normally, the workers must ask the manager a lot, which slows things down.
- Network card (NIC): The mail carrier for sending data to other computers.
- Latency: The wait time before anything starts moving.
- Bandwidth: How much data you can push per second once things are moving.
- MPI: A standard way programs send messages. Two-sided MPI means both the sender and receiver agree before data is delivered, like a handshake.
- Halo exchange: Neighbors in a grid pass their border data to each other, over and over. It’s common in simulations (like weather or physics).
The problem: Today, even when data sits in GPU memory, sending it usually involves the CPU to launch work and to synchronize (wait for) the GPU. Each of those little waits adds microseconds, which adds up across billions of messages.
The idea: Keep MPI’s two-sided style but let the GPU manage the sending and receiving itself. The authors do this with two simple building blocks:
- A Queue: A “to-do list” connected to a GPU stream (a GPU’s ordered line of tasks). You can add “start this send,” “wait for that receive,” etc., and the GPU follows the list without dragging in the CPU.
- Match: A one-time setup step that pairs sends with receives in advance. It’s like exchanging phone numbers ahead of time so messages go to the right person without more paperwork later.
Under the hood (analogy-friendly version):
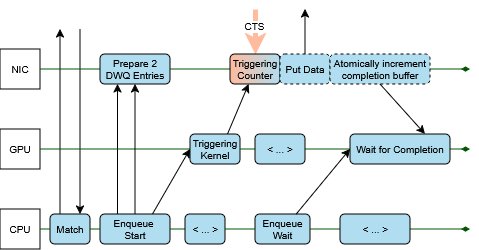
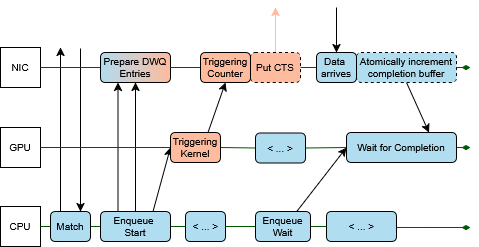
- Triggering counters: Think of a small scoreboard the GPU can bump to say “go now.” When the counter hits a number, the network card automatically performs a send or marks a receive as done—no CPU needed.
- Deferred work queues: “Do this later” instructions for the network card. They only execute when their trigger (the counter) reaches a certain value.
- Tiny “done” signals: After a send finishes, the NIC updates a tiny spot in memory (like flipping a flag). The GPU watches that spot to know, “this message is done.”
Receiver readiness (the safe delivery rule):
- With normal two-sided MPI, you can’t drop a package into the receiver’s buffer until the receiver says it’s ready.
- The authors keep that rule by having the receiver send a small “clear-to-send” signal that the sender’s GPU waits for. So delivery only happens when it’s safe—still without CPU steps.
Where they built it:
- On HPE Slingshot 11 networks using libfabric features (counters and deferred work queues). These hardware/software tools make the “trigger and go” idea possible.
A real example they integrated:
- Cabana/Kokkos StreamHalo (for halo exchanges). The GPU enqueues: start receives → pack data → start sends → wait for completion → unpack data. It’s the same logic, just done by the GPU with the Queue and Match tools, so it runs smoother and faster.
What they found (and why it matters)
They ran two kinds of tests:
- Ping-pong microbenchmark (two GPUs trade messages back and forth):
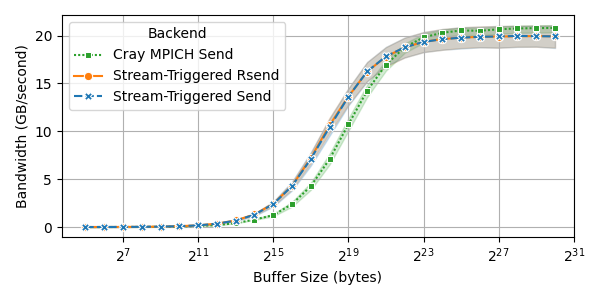
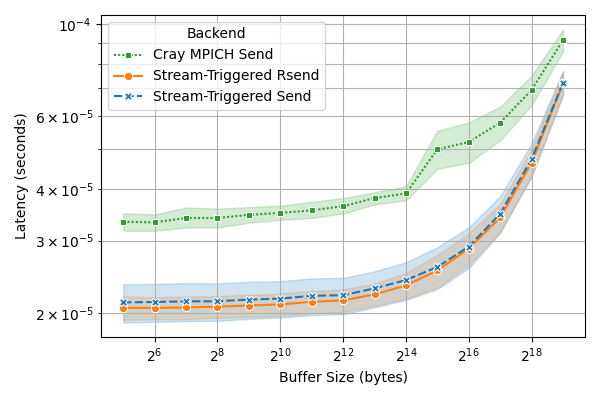
- Latency dropped by up to about 50% for small-to-medium messages (the sizes many real apps use a lot).
- Bandwidth improved in the mid-size range.
- For very large messages, the standard MPI could be slightly faster, but the overall pattern still favors the new method for common sizes.
- Halo exchange strong scaling (a realistic pattern in many simulations):
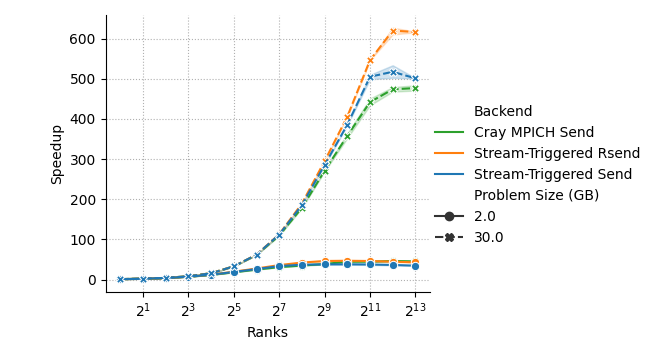
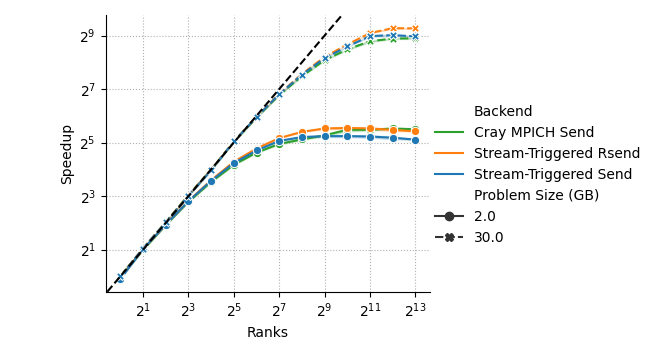
- On ORNL’s Frontier supercomputer (up to 8,192 GPUs), their approach sped things up by about 28% at very large scale compared to the system’s standard MPI.
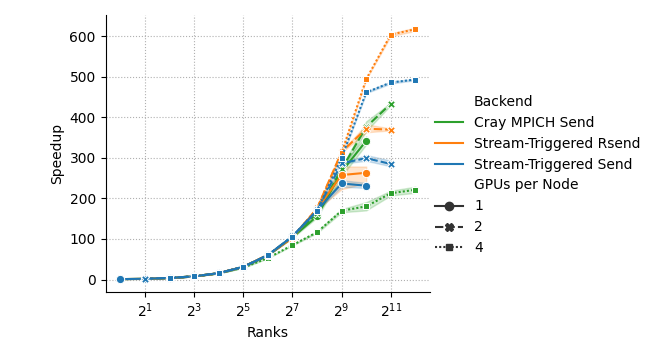
- On LLNL’s Tuolumne system, trends were similar. The new method especially helped when using more GPUs per node.
- Big picture: When you scale to lots of GPUs, avoiding small delays (CPU involvement, extra synchronizations) can have a big impact on total runtime.
Why this matters:
- Many scientific and AI applications run lots of small-to-medium messages and rely on strong scaling (speeding up as you use more GPUs). Cutting latency there can save huge amounts of time and energy.
- This approach keeps the familiar two-sided MPI style, so programmers don’t have to rewrite their apps in a totally different model.
What this could change going forward
- Faster simulations and AI training: Less waiting means results sooner and potentially lower energy use.
- Easier adoption: Because the design mostly preserves how MPI already works, existing frameworks (like Kokkos/Cabana) can upgrade with fewer changes.
- Broader impact: As more networks support “triggered” features, GPU-driven (CPU-free) communication can become the norm, making large-scale computing smoother.
- Future directions: Extend this to more MPI features (like collectives), support more types of networks, and refine resource handling so it remains robust at even larger scales.
In short, this paper shows a practical way for GPUs to “send text messages” to each other without always asking the CPU for permission, keeping things safe and familiar while making large-scale computing faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes and evaluates a CPU-free, MPI-based GPU communication abstraction implemented on HPE Slingshot 11 via libfabric/CXI. While promising, several issues remain unresolved and merit targeted investigation:
- Portability beyond HPE Slingshot 11/CXI: The design relies on provider-specific features (GPU-triggerable counters, DWQs, FI_REMOTE_WRITE-triggered atomics). It is unclear how to realize equivalent functionality on other NICs/providers (e.g., Mellanox/InfiniBand, NVIDIA GPUDirect RDMA, Intel Ethernet) or across libfabric providers lacking these extensions.
- GPU read limitations for CXI counters: The approach circumvents the inability of GPUs to read CXI counters by triggering fi_atomic updates to host memory. Generality and performance of this workaround on other providers, and the impact if providers cannot trigger atomics from FI_REMOTE_WRITE, remain unaddressed.
- Lack of collective offload support: Deferred work queues currently support only point-to-point. A path to CPU-free GPU-triggered collectives (e.g., allreduce, broadcast), or alternatives leveraging hardware collectives, is not provided.
- MPI standard compliance and evolution: The proposed Match API permanently pairs persistent requests and disallows matching persistent and non-persistent requests, altering MPI semantics. How this integrates with the MPI standard (e.g., MPI 5.x), impacts existing applications, and could be standardized is unclear.
- Interaction with MPI partitioned communication: The work references MPIX_Pbuf_prepare and partitioned communication but does not explore integrating the Queue/Match abstractions with partitioned requests to handle dynamic buffer readiness while remaining CPU-free.
- Semantics coverage gaps in MPI features: Support for MPI wildcards (e.g., MPI_ANY_SOURCE/TAG), generalized requests, cancellation (MPI_Cancel), error handling, and derived datatypes (non-contiguous/strided layouts) is not discussed; feasibility of CPU-free implementations for these features is unknown.
- Readiness handling overheads and correctness: The CTS handshake for non-ready sends (even counter semantics, FI_REMOTE_WRITE monitoring) is not formally analyzed for race conditions, ordering guarantees, or pathological cases (e.g., unexpected messages); latency overhead of CTS vs ready-send is not quantified in complex patterns.
- Resource exhaustion and backpressure: DWQ entry scarcity can stall Enqueue_start on the CPU; a concrete, portable fallback (e.g., progress thread, adaptive throttling) is not implemented or evaluated. Impacts on large, irregular workloads with many outstanding operations are unknown.
- Stream scheduling deadlocks: The paper notes reliance on using high-priority streams to avoid GPU scheduling deadlocks but does not quantify risks, provide detection/mitigation strategies, or measure sensitivity to stream priorities under load.
- Triggering cost on the GPU: Enqueue_start uses GPU actions (kernel or stream write) to increment counters. The overhead of these triggers (vs. kernel launch elimination) is not measured, nor are trade-offs among HIP/NVIDIA stream write variants, warp-level triggering, or cooperative groups.
- Memory registration and RMA key exchange costs: The Match stage performs RMA key exchange and setup; the cost, scalability, and reuse strategy (e.g., amortization across epochs) are not quantified. Impacts on applications with dynamic communication patterns or frequent changes in buffer sets are unclear.
- Intra-node GPU communication: The evaluation focuses on inter-node NIC-mediated paths. Performance and viability of the approach for intra-node GPU-GPU copies (PCIe/NVLink/xGMI) and heterogeneous paths (CPU memory, unified memory) are unexamined.
- Large-message bandwidth regression: Stream-triggered transfers underperform Cray MPICH for ≥8–16MB messages; the root causes (e.g., NIC injection limits, DWQ batching, lack of pipelining, GPU/NIC overlap) are not analyzed, and optimization strategies are not proposed.
- Overlap with computation: The evaluation does not quantify overlap between compute and communication enabled by the stream-queued design, nor identify scheduling patterns that maximize overlap in real applications.
- Applicability beyond halo exchanges: Only ping-pong and Cabana halo exchanges are evaluated. Behavior for collectives, many-to-many, irregular sparse, graph, or all-to-all patterns (typical in ML and HPC) is unknown.
- Multi-GPU-per-process and mixed workloads: The design’s behavior with multiple GPUs per MPI process, multi-tenant nodes, mixed CPU/GPU communication patterns, and heterogeneous processes (e.g., different communicators or asymmetric participation) is not addressed.
- Fault tolerance and recovery: The API and implementation do not discuss handling network or process failures, timeouts, retransmissions, or recovery of matched persistent pairs, especially given permanent pairing semantics.
- Debuggability and tooling: Programmer burden and debugging support for Queue/Match usage (e.g., detecting unmatched or misordered requests, stall analysis, visibility into DWQ state and counters) remains an open usability question.
- Security and memory protection: Direct NIC writes into user GPU buffers raise questions about memory protection, isolation, and key lifetimes; policies for safe key revocation and isolation across jobs are not discussed.
- Interoperability with existing MPI implementations: Practical paths to adoption in mainstream MPI stacks (MPICH, Open MPI, Cray MPICH) and coexistence with CPU-driven operations within the same application are not evaluated.
- Topology-aware and multi-rail optimizations: The approach does not consider NIC multi-rail configurations, adaptive routing, or topology-aware triggering that could improve performance and resilience at scale.
- Quantitative overheads of Queue/Match: The costs of initializing Queue objects, matching requests, and enqueueing operations (vs. standard non-persistent MPI) are not broken out, making it hard to predict net benefit across different message sizes and usage patterns.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s CPU-free MPI GPU communication API (stream-triggered persistent MPI with Match and Queue) and its Slingshot-11/libfabric CXI implementation. Each item names who benefits, what to do, expected impact, enabling tools/workflows, and key assumptions/dependencies.
- Industry + Academia (HPC/CFD/Climate/Materials): Accelerate stencil/halo-exchange–heavy GPU applications on Slingshot-11 systems
- What to do: Replace CPU-driven Isend/Irecv paths with stream-triggered persistent MPI sends/receives using Match, Queue, Enqueue_start/all, Enqueue_wait/all in halo exchange phases. Prefer ready-send paths when semantics allow.
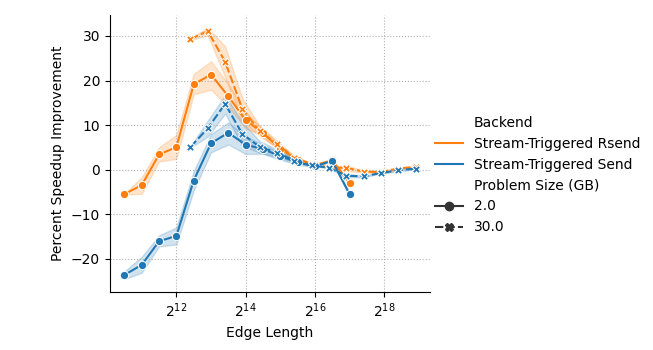
- Expected impact: Reduced medium-message latency (12–59% reported) and improved strong scaling; up to 28% speedup at 8,192 GPUs (Frontier) for halo-exchange benchmark. Lower CPU overhead.
- Tools/workflows: Cabana/Kokkos StreamHalo drop-in; application kernels enqueue pack/compute/unpack and MPI operations on the same GPU stream; use high-priority comm streams.
- Assumptions/dependencies: HPE Slingshot 11 NICs with libfabric CXI provider supporting deferred work queues (DWQ) and counters; GPU can perform stream write operations (e.g., ROCm hipStreamWriteValue64); persistent MPI requests; app can adopt ready-send for best results; DWQ entries (~500) are sufficient; no blocking operations inside Enqueue_start.
- Academia + National Labs (Performance Portability): Upgrade performance-portable frameworks
- What to do: Integrate stream-triggered MPI backends into Kokkos- and Cabana-based libraries/components beyond halo exchange (e.g., neighborhood collectives, ghost region updates).
- Expected impact: Transparent speedups in existing solvers when building on Frontier/Tuolumne-class systems, preserving developer ergonomics.
- Tools/workflows: Add a StreamHalo-like abstraction in domain frameworks (e.g., Trilinos/Cabana modules) with runtime selection of CPU-driven vs. GPU-triggered paths.
- Assumptions/dependencies: Persistent operations on both ends; tagged message patterns fixed across iterations; code changes to create and reuse persistent requests and queues.
- Industry (Molecular Dynamics/Reservoir/Seismic): Faster time-stepping in point-to-point dominated GPU codes
- What to do: Convert iterative message patterns (neighbor lists, domain decomposition) to persistent requests that are matched once per run, then enqueue GPU-triggered starts/waits per timestep.
- Expected impact: Better overlap and lower latency between short kernels and message bursts; improved throughput for 4KB–1MB messages.
- Tools/workflows: LAMMPS/Kokkos backends, GROMACS custom halo code, domain-specific wrappers to allocate Match’d persistent requests during setup.
- Assumptions/dependencies: Stable communication partners/tags and fixed buffer semantics per iteration; tuned thresholds to fallback to standard MPI for very large messages (≥8–16MB).
- Industry + Academia (Large-scale ML training on Slingshot): Lower per-step latency in point-to-point phases and custom pipeline-parallel exchanges
- What to do: Use stream-triggered point-to-point exchanges for activation/gradient boundary transfers between pipeline stages or expert routing in MoE models where two-sided semantics are convenient.
- Expected impact: Reduced iteration latency and less CPU contention; complementary to NCCL collectives.
- Tools/workflows: PyTorch custom CUDA/HIP extensions invoking persistent MPI requests + GPU queues for point-to-point ops; maintain collectives in NCCL/RCCL.
- Assumptions/dependencies: Slingshot 11 + ROCm stack; readiness semantics handled (ready-sends preferred); collectives remain out of scope of DWQ (point-to-point only).
- HPC Centers (Operations/Benchmarking/Procurement): Immediate benchmarking and deployment pilots
- What to do: Pilot stream-triggered MPI in facility codes (stencil miniapps, CabanaGhost) and report speedups; publish center guidance for enabling GPU-initiated comm streams.
- Expected impact: Demonstrate reduced latency and CPU utilization; inform facility best practices and user training.
- Tools/workflows: Benchmark harnesses (ping-pong, halo exchange); modulefiles enabling CXI provider and ROCm; runbooks on stream priority configuration.
- Assumptions/dependencies: Users can set stream priority; CXI provider version supports GPU-triggered counters and DWQs; monitoring for DWQ pressure.
- Industry (Energy/Automotive/Aerospace R&D): Shorter design cycles via faster parameter sweeps
- What to do: Apply stream-triggered paths to structured-grid CFD/CAE solvers used in parametric studies; choose ready-sends for regular iteration schedules.
- Expected impact: Faster sweep throughput on Slingshot-based supercomputers; better utilization windows.
- Tools/workflows: MPI persistent setup phase per configuration; automated switching heuristics for message-size thresholds.
- Assumptions/dependencies: Decomposition and neighbor sets remain stable; message patterns repeat.
- Academia (Education): Teaching modern GPU communication paradigms
- What to do: Introduce lab modules that contrast CPU-driven vs. GPU-triggered MPI paths (persistent requests, queues, readiness).
- Expected impact: Students gain hands-on experience with latency-critical GPU networking and programming models.
- Tools/workflows: Minimal examples built on libfabric CXI; classroom versions of ping-pong and halo miniapps.
- Assumptions/dependencies: Access to Slingshot-enabled teaching clusters or time allocations on leadership systems.
- Policy (Center-level guidance): Scheduling and energy policy tweaks
- What to do: Recommend policies to (a) reserve one high-priority GPU stream for communication, (b) limit CPU polling threads when using GPU-triggered comm, and (c) track energy per iteration.
- Expected impact: Reduced CPU power draw and improved overall node efficiency; predictable performance.
- Tools/workflows: Scheduler prolog scripts to set environment variables; facility docs on tuning CXI/libfabric knobs.
- Assumptions/dependencies: Sysadmin control over default priorities and environment; metrics collection in place.
- Industry + Academia (Hybrid pipelines): CPU-free kernels-to-communication chaining
- What to do: Build pipelines where kernel N enqueues send and kernel N+1 waits on receive completion counters on the same stream.
- Expected impact: Eliminates CPU launch/sync overheads between compute and communication; improves tail latency.
- Tools/workflows: Create per-iteration enqueue graphs (pack -> send -> wait -> unpack) with persistent requests; optional graph capture if supported.
- Assumptions/dependencies: App logic fits in stream order; careful avoidance of Enqueue_wait before all peers have started.
- Tooling (DevOps/Software): Introduce guarded fast paths and diagnostics
- What to do: Ship a transport-agnostic wrapper that detects Slingshot+CXI with DWQ/counters and switches to stream-triggered mode; else falls back to standard MPI.
- Expected impact: Safe adoption at scale without regressions on non-Slingshot systems.
- Tools/workflows: Feature-detection at init; runtime logging of DWQ utilization; perf counters for completion-latency histograms.
- Assumptions/dependencies: Clean fallback logic; unit tests for matching and readiness logic.
Long-Term Applications
These require further standardization, vendor support, research, or scaling work before broad deployment.
- Cross-vendor, standard MPI support for GPU-triggered persistent operations
- What to do: Propose MPI-standard APIs for Queue and Match semantics; formalize readiness and persistent matching rules; ensure cancelation/progress semantics.
- Impact: Portability across MPI stacks (Cray MPICH, Open MPI, MVAPICH) and devices.
- Dependencies: MPI Forum ratification; consistent libfabric/UCX support for triggered ops and GPU-accessible counters.
- Vendor-neutral NIC support (Infiniband/RoCE/EFA/OPx) for DWQ-like trigger chains
- What to do: Extend OFI/UCX providers with deferred work queues, GPU-writable counters, and FI_REMOTE_WRITE-triggered atomics across NICs.
- Impact: Makes CPU-free two-sided GPU communication widely available (on-prem and cloud).
- Dependencies: NIC firmware/hardware support; security model for RMA keys; provider maturity and performance parity.
- Hardware collectives with GPU-triggered activation
- What to do: Generalize triggered operations to NIC collectives; enable GPU-triggered allreduce/alltoall startup and completion counters without CPU.
- Impact: Big gains for ML and HPC collectives where CPU still appears in the fast path; unifies point-to-point and collective offload models.
- Dependencies: NIC hardware capabilities; libfabric extensions; coordination with NCCL/RCCL and MPI collectives.
- GPU-readable NIC counters and larger DWQ pools
- What to do: Provide GPU-mapped read access to NIC counters and increase DWQ capacity; add backpressure APIs.
- Impact: Simpler completion polling (no atomic write-back indirection), fewer deadlock/resource hazards, higher concurrency.
- Dependencies: NIC design updates; driver+runtime changes; security and coherency guarantees.
- Automated policy for threshold-based transport selection
- What to do: Auto-select stream-triggered vs. CPU-driven paths by message size/traffic pattern; integrate autotuners.
- Impact: Avoids bandwidth regressions for very large messages (≥8–16MB) while maximizing latency benefits elsewhere.
- Dependencies: Runtime telemetry; lightweight models; integration into MPI libraries/frameworks.
- Integration into ML frameworks for pipeline/expert parallelism
- What to do: Add GPU-triggered point-to-point backends for framework-level ops (e.g., expert dispatch, inter-stage activations) while retaining NCCL for collectives.
- Impact: Faster step times for latency-sensitive phases; reduced CPU orchestration overhead at scale.
- Dependencies: Stable APIs in PyTorch/TF/JAX; HIP/CUDA/SYCL support; transport portability across vendors.
- End-to-end GPU-driven simulation pipelines (in-situ/in-transit)
- What to do: Orchestrate compute/comm/analysis/visualization entirely via GPU streams with minimal CPU orchestration.
- Impact: Lower latency for in-situ analytics and steering; better throughput in tightly coupled workflows.
- Dependencies: GPU-triggered I/O/network paths (e.g., GPUDirect Storage coordination), resource scheduling across streams.
- Fault tolerance and resilience with GPU-side progress awareness
- What to do: Design GPU-visible progress and replay checkpoints for persistent operations; support timeouts and recovery.
- Impact: Production readiness for long-running jobs with CPU-free comm in the loop.
- Dependencies: Error reporting from NIC to GPU; MPI error handling extensions; coordination with checkpoint/restart tools.
- Cloud HPC adoption (EFA and beyond)
- What to do: Bring triggered operations to cloud fabrics; expose GPU-triggered MPI to managed HPC/AI services.
- Impact: Broadens access to CPU-free GPU networking, benefiting industry users without on-prem Slingshot systems.
- Dependencies: Provider support (EFA/UCX), cloud driver updates, security and multi-tenant isolation.
- Broader societal impact via faster time-to-solution
- What to do: Apply to national-scale climate/weather, genomics/drug discovery, and energy modeling pipelines to shorten cycle times.
- Impact: Quicker forecasts, faster candidate screening, improved grid simulations—indirect daily-life benefits through better services.
- Dependencies: Productionization in flagship codes (E3SM, MPAS, MOM6, WRF, GROMACS, LAMMPS, OpenFOAM); reproducibility and validation at scale.
- Curriculum and workforce development around GPU-initiated networking
- What to do: Develop advanced courses, MOOCs, and labs covering stream-triggered MPI, persistent ops, and NIC offload features.
- Impact: Prepares the workforce for next-gen exascale and post-exascale systems where CPUs are removed from fast paths.
- Dependencies: Stable APIs; educational allocations on leadership systems; teaching materials and open-source examples.
General assumptions and dependencies that affect feasibility
- Hardware/stack: HPE Slingshot 11 with libfabric CXI supporting deferred work queues and counters; GPU runtime enabling stream write ops (ROCm today; CUDA/SYCL for portability).
- API semantics: Persistent requests must be matched once and reused; only persistent-to-persistent matching supported; users must ensure correctness of ready-sends.
- Resource limits: DWQ entries are finite; avoid enqueuing unbounded starts; ensure Enqueue_wait only after all partners have started.
- Scheduling: Use high-priority GPU streams for communication to avoid deadlock/starvation; avoid blocking kernels in Enqueue_start paths.
- Performance boundaries: Stream-triggered path excels for small/medium messages; for very large messages, libraries may auto-fallback to CPU-initiated paths.
- Security/registration: RMA key exchange performed at Match time; applications must manage memory registration and lifetimes safely.
Glossary
- APU: A processor that integrates CPU and GPU on a single package with shared memory; "four MI300A APUs per node, each with 24 AMD EPYC CPU cores and one GPU that share 128GB of high-bandwidth memory"
- Cabana: A C++ performance portability framework for particle and grid applications; "Cabana/Kokkos performance portability framework"
- CabanaGhost: A halo-exchange benchmark built on Cabana to study communication scalability; "a C++-based halo exchange benchmark called CabanaGhost"
- CXI provider: The libfabric provider implementing HPE Slingshot’s CXI interconnect semantics; "HPE libfabric CXI provider"
- Deferred Work Queue (DWQ): Libfabric’s mechanism for enqueuing operations that execute once a counter reaches a target value; "deferred work queue entries (DWQs)"
- Dragonfly network topology: A low-diameter, high-radix interconnect topology used in large HPC systems; "Dragonfly network topology"
- fi_atomic: A libfabric operation that performs an atomic update on a remote or local memory location; "fi_atomic"
- fi_recv: A libfabric operation to post a receive for point-to-point data transfers; "fi_recv operations"
- fi_write: A libfabric one-sided remote write operation that places data directly into a target memory region; "fi_write"
- FI_REMOTE_WRITE: A libfabric event/counter source indicating a remote write to a registered memory region; "FI_REMOTE_WRITE"
- Frontier: ORNL’s exascale Cray EX supercomputer used for GPU-accelerated HPC workloads; "halo-exchange benchmark to 8,192 GPUs of the Frontier supercomputer"
- GCD (Graphics Compute Die): A separately programmable GPU die within some AMD GPUs; "graphics compute dies (GCDs)"
- GPU-initiated communication: Communication triggered from GPU execution without requiring CPU intervention on the fast path; "GPU-initiated, CPU-free communication seeks to provide high-performance communication APIs"
- Halo exchange: A stencil-based communication pattern that exchanges boundary data between neighboring subdomains; "halo exchange communication primitives"
- hipStreamWriteValue64: A ROCm GPU stream operation to write a 64-bit value, used to trigger NIC counters from the GPU; "hipStreamWriteValue64"
- HPE Slingshot 11: HPE’s high-performance network interconnect used in Cray EX systems; "HPE Slingshot 11 network card capabilities"
- Kokkos: A C++ library providing portable parallel execution and memory abstractions across HPC architectures; "Cabana/Kokkos performance portability framework"
- libfabric: A userspace network API defining portable fabric semantics and providers for HPC interconnects; "the libfabric API"
- libmp: An MPI-like two-sided communication library designed for GPU-initiated transfers; "libmp two-sided communication library"
- Memory-mapped I/O: A technique mapping device registers or buffers into the host address space for direct load/store; "memory-mapped I/O region"
- Message matching: MPI’s mechanism that pairs sends and receives using tags, ranks, and communicators; "message matching"
- MI250X: AMD Instinct GPU model with multiple graphics compute dies used in Frontier; "AMD Instinct MI250X GPUs"
- MI300A: AMD Instinct APU combining CPU and GPU with unified high-bandwidth memory; "MI300A APUs"
- NCCL: NVIDIA’s Collective Communication Library for multi-GPU collectives; "NVIDIA NCCL"
- NVSHMEM: NVIDIA’s GPU-centric one-sided communication library based on SHMEM semantics; "NVIDIA's NVSHMEM library"
- OFI (Open Fabrics Interconnect): The abstract interface and ecosystem behind libfabric and its providers; "OFI triggered communication operations"
- Portals: A low-level communication API whose triggered operations influenced OFI/libfabric features; "Portals communication API"
- Ready send: An MPI send semantic assuming the receiver is already posted, enabling lower-latency transfers; "MPI ready send operations"
- Remote Memory Access (RMA) keys: Authorization tokens used to permit remote NICs to access registered memory regions; "RMA communication keys"
- RTS/CTS: Ready-to-Send/Clear-To-Send handshake used to coordinate buffer readiness in two-sided messaging; "Ready-to-Send/Clear-To-Send (RTS/CTS)"
- Stream-triggered communication: Communication operations whose initiation is tied to GPU stream progress via counters/triggers; "stream-triggered API"
- Strong scaling: Scaling a fixed-size problem to more resources to reduce time-to-solution, often latency-bound; "strong scaling workloads"
- Triggering counter: A NIC/libfabric counter that advances with events or GPU writes to fire deferred operations; "triggering counters"
- Tuolumne: LLNL’s Cray EX supercomputer with MI300A APUs used in evaluation; "Tuolumne is a 1,152 node Cray EX supercomputer"
- Writeback buffer: A host memory area where a device writes counter values for polling/visibility; "writeback buffer"
- MPI partitioned point-to-point operations: MPI operations that divide a message into partitions to decouple matching and data movement; "MPI partitioned point-to-point operations"
- MPI persistent operations: MPI requests created once and reused for repeated communication to separate setup from fast-path use; "existing MPI persistent operations"
- MPI progress engine: The mechanism ensuring MPI operations make progress, here tied to GPU streams via queues; "an MPI progress engine abstraction"
- MPI_Queue: A proposed queue abstraction binding MPI persistent operations’ start/wait to a GPU stream; "MPI_Queue_init(&_my_queue, CXI, &_my_stream);"
Collections
Sign up for free to add this paper to one or more collections.